
3D Point Cloud Descriptor for Posture Recognition
Margarita Khokhlova, Cyrille Migniot and Albert Dipanda
Le2i, FRE CNRS 2005, Univ. Bourgogne Franche-Comt´e, France
Keywords:
3D Descriptor, Point Cloud Structure, 3D Posture.
Abstract:
This paper introduces a simple yet powerful algorithm for global human posture description based on 3D Point
Cloud data. The proposed algorithm preserves spatial contextual information about a 3D object in a video
sequence and can be used as an intermediate step in human-motion related Computer Vision applications
such as action recognition, gait analysis, human-computer interaction. The proposed descriptor captures a
point cloud structure by means of a modified 3D regular grid and a corresponding cell s space occupancy
information. The performance of our method was evaluated on the task of posture recognition and automatic
action segmentation.
1 INTRODUCTION
3D pose estimation is a common task in Computer Vi-
sion applications. In the case of a rigid object, pose
estimation seeks to capture the appearanc e of an ob-
ject under certain viewing conditions. This task is
challengin g for natural images due to the ambiguity
of an object repr e sentation in 2D, poor texture and va-
rying view-points. With the introduction of con sumer
3D sensors, this problem has been revisited by rese-
archers developing a broad range of new descriptors.
They may be both handcra fted (Hinterstoisser et al.,
2012) or automa tic (Wohlhart and Lepetit, 2015), and
capture information from both global and local scales.
Non-rig id object pose estimation is inherently
more complicated. A human body is an articulated
object, and its motion can be build up from rigid and
non-rigid motion parts. Articulated pose estimation
seeks to e stimate the configuration of a human body
in a given image or video sequence. Recognition of
body postures is an important step towards the f ully
automatic classification of human motion.
A canonical work on human posture estimation
using RGBD camera data is by Shotton et al. (Shot-
ton et al., 2013), which proposes a r eal-time algorithm
which segments a human body fro m a corresponding
depth map and locates skeleton joints. This algorithm
shows go od results and its variations are widely used
today. However, it has certain limitations: in presence
of severe occlusions and noise, the positions of the
joints cannot be estimated correctly; it gives ap proxi-
mate joint positions and therefore coarse pose estima-
tion and is not able to capture very subtle variations
between posture s. For this reason, joint-based posture
estimation methods, although simple and powerful,
will fail if the initial joints were estimated wr ongly,
which gives the way to low-level attributes based met-
hods.
This paper proposes a simple yet effective descrip-
tor for pose recognition based directly on point cloud
data. The algorithm takes a holistic po se estima-
tion approach, capturing the slightest p osture chan-
ges using accumulated point cloud features. Our des-
criptor is based on the space occupancy for cells of
a modified 3D regu la r grid, super-imposed on a point
cloud. It is tr anslation, scale, and rotation invariant.
Originally, we aim at a descriptor which can be
used for a gait analy sis. The prop osed design sh ould
be able to reliably detect different postures in human
gait, where the prec ision of skeleton data is not suf-
ficient (the K inect reliability is evaluated by (Cippi-
telli et al., 2015) for the side and front (Mentiplay
et al., 2015) views). The second problem addressed
is the symmetry of the gait which should be evalua-
ted based on the point cloud data. However, resulting
descriptor is very general and can be used as an in-
termediate step in a great number of computer vision
applications such as action recognition, gait analysis,
smart homes, assessing the quality of sports actions,
human-computer interaction and others, where pos-
ture estimation is an essential intermediate step. This
work presents the descriptor in the context of action
recogn ition, and postures are estimated from frames
of video sequences fr om MSR Action3D database.
Khokhlova, M., Migniot, C. and Dipanda, A.
3D Point Cloud Descriptor for Posture Recognition.
DOI: 10.5220/0006541801610168
In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2018) - Volume 5: VISAPP, pages
161-168
ISBN: 978-989-758-290-5
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
161

The paper is organized a s follows. Section II over-
views existing meth ods for human posture recogni-
tion. Section III in troduces the descriptor and its pa-
rameters. Section IV describes the data used in ex-
periments proposed in section V. Section VI summa-
rizes the results, proposes possible application s and
outlines th e future work.
2 RELATED WORK
Most methods for human pose estimation are ba-
sed on variations of a so called pictorial struc tu-
res model, which represents human body configura-
tion as a collection of connec ted rigid parts (Chen
and Yuille, 2014)(Jhuang et al., 2013)(Aga rwal and
Triggs, 2006)( Pishc hulin et al., 2013). To model an
articulation, parts of the structur e are parameterized
by their spatial location and orientation.
Holistic approa c hes (Agarwal an d Triggs,
2006)(Pishchulin et al., 2013)(Vieira et al., 2012)
and middle-part (Yang and Ramanan , 2011) based
methods form the other research direction in posture
recogn ition. Holistic appro a ches aim to directly
predict positions of body parts from image featu-
res without relying on an intermediate part-b ased
representation. Part-based approaches first detect
intermediate parts independently or with some
constraints on body joints spatial relations.
Recently researchers significantly advanced pos-
ture recognition from natural images with the increa-
sing popularity of machine learning based approaches
(Tompson et al., 20 14)(Ch´eron et al., 2015)(Chen and
Ramanan, 2017). Cheron et al (Ch´eron et al., 2015)
proposed a new Pose-based Convolutional Neural
Network descriptor (P-CNN) for 2D action recogni-
tion. A pre-trained CNN learns the features co rre-
sponding to 5 pre-selected body parts based on quan-
tized motion flow data for each frame. Chen and Ra-
manan (Chen a nd Ramanan, 2017) extend an estima-
ted 2D mo del, using a neural network, to 3D using a
simple Nea rest Ne ighbor pose matchin g algorithm. A
good review on recent advances in 3D articulated pose
estimation is proposed by Sarafianos et al. ( Sarafianos
et al., 2016). Posture recognition is a part of action re-
cognition, since actions can be modeled as a postures
evaluation in time. Recent works on action recogni-
tion are based on CNNs (Han et al., 2017)(Lan et al.,
2017) a nd learn the the features atom ic a lly, which le-
ads to state-of-the-art results on available datasets.
Despite the significant p rogress made, full- body
pose estimation from natur al images remains a diffi-
cult and a largely unsolved problem du e to numerous
difficulties in real-life applica tions: the many degrees
of freedom of the human body m odel, the variance in
appearance, the changes in viewpoints, and lastly, an
absence of data about an objects’ shape. 3D data give
a new important information which allows for impro-
ving posture recognition results. Depth-based pose
estimation can be categorized into two c la sses.
Generative approaches (Ye and Yang, 2014)(Ga-
napathi et al., 2012) use a geometric or probabilistic
human body model and estimate a pose by minimi-
zing the distanc e between the human model and the
input depth ma p. Human pose estimation is perfor-
med by optimizing the objective function for geome-
tric mo del fitting by the means of variants of itera-
tive closest point (Ganapathi et al., 2012) and graphi-
cal models (Li et al., 20 14) or picto rial structures
(Charles and Everingham, 2011). A recent m ethod by
Wang et al. (Wang et al., 2016) uses several hand-
crafted descriptors to recognize 5 distinct po stures
from the data obtained by a Kinect camera. Their al-
gorithm is based on a simple 3D-2D projection met-
hod and the star skeleton technique. The final p osture
descriptor is composed of skeleton feature p oints to -
gether with a center of gravity. A pre-trained Lear ned
Vector Quantization (LVQ) neural network is used for
classification.
Discriminative approa c hes (Shotton et al.,
2013)(Yub Jung et al., 2015) perform classification
on a pixel level and attempt to detect instances of
body par ts. Shotton et al. (Shotton et al., 2013)
trained a random forest classifier fo r body part
segmentation fr om a single depth image and used
Mean Shift (Comaniciu and Meer, 2002) to estimate
joint locations. Chang et al. (Chang and Nam, 2013)
propose a fast random-forest-based human pose esti-
mation method, where classifier is applied directly to
pixels of the segmented human depth image. Jung et
al. (Yub Jung et al., 2015) used randomized regres-
sion trees and made their algorithm even faster by
estimating th e relative direction to e ach joint to avoid
computationally demanding ag gregating pixel-wise
tree evaluations. The obtained skeleton data can later
be used as the base for action recognition in videos
as in recent Lo g-COV-Net method (Cavazza et al.,
2017).
Most of the work on 3D pose estimation uses
a single depth camer a. The most successful ex-
amples of single view pose estimation are ( Shotton
et al., 2013)(Ye and Yang, 2014)(Yub Jung et al.,
2015)(Chang and Nam, 2013) and most of them use
randomized trees and shape context features for pixel-
wise classification which leads to real-time solutions.
Lately, multi-view depth image based posture re-
cognition approach es acquired the attention of re-
searchers (Shafaei and Little, 2016)( Peng and Luo,
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
162

2016). The recent framework proposed by (Shafaei
and Little, 2016) uses several Kinect sensors an d a
deep CNN architecture. Multi-v iew scenarios allow
to reconstruct 3D point clo uds in the reference space.
The authors use curriculum learnin g (Bengio et al.,
2009) to train the system on purely synthetic data.
Curriculum learning modifies the order of th e trainin g
proced ure, gradually increasing the complexity of the
instances, which hypothetically im proves the conver-
gence speed and the quality of the final local minima.
It is clear that the currently prevailing strategy is
to use Machine Learning methods, specifically rand-
omized trees (Shotton et al., 2013)(Yub Jung et al.,
2015)(Tang et al., 2014), and a huge amount of
training d a ta . Modern posture recognition methods
(Shotton et al., 2013)(Sh afaei and Little, 2016) have
shown to be both effective and efficient in real-time
posture estimation. Similar, f or the following action
recogn ition fro m videos, hand-cr a fted method s were
overshadowed by d e ep learning based methods (Lan
et al., 2017).
This work introduces a new descriptor that estima-
tes 3D human pose from a sin gle point cloud. We are
not attemptin g to out perform machine-le arning ba-
sed algorithms (Shotton et al., 2013)(Yub Jung et al.,
2015), but mostly propose a simple alternative, which
does not require a priori human body model. In con-
trast to (Wang et al., 2016), we do not use a des-
criptor for a g iven posture but aim to use a general
3D point cloud structure. Unlike oth er popular des-
criptors (Shotton et al., 2013)(Yub Jung et al., 2015)
which use depth image features, our descriptor is ba-
sed on a 3D structure and therefore can be used in a
multi-camera scenario.
3 DESCRIPTOR
We propose a handcrafted compact and discriminative
descriptor for a single point cloud. The most similar
descriptor to ours is the Space-Time Occupancy Pat-
terns method proposed by Vieira et al. (Vieira et al.,
2012) for the task of action recognition. Similar to
this work, we propose to divide the 3D space by a
regular grid and base our descriptor on spatial occu-
pancy inf ormation. However, in (Vieira et al., 2012)
researchers compute the final descriptor vector by re-
assigning weig hts based on cells where motion occur-
red. We are concentrated on a description of each sta-
tic frame in ord er to recognize the posture in it. Other
differences include the method of 3D space p artitio-
ning and descriptor cell initialization. Our partitio-
ning is inspired by the 3D partitioning for human re-
cognition fro m 3D po int clouds proposed in (Essma-
eel et al., 2016). Vieira et al. specifically design their
method for video sequences, taking the time dimen-
sion into account. We assume th at every initial frame
posture is more important and temporal information
can be encoded later in the process depending on the
specific application. For the g ait analysis and action
recogn ition, a Hidden Markov Model can be coupled
with a descrip tor to capture the temporal informatio n.
To construct our descriptor for each depth map vi-
deo frame, we perform the f ollowing steps. First, the
2D-3D transformation is done to obtain a point cloud
in 3D space from a depth map. We use a standard
equation f or basic geometric transformations:
X = Z ∗
( j − c
x
)
f
x
; Y = Z ∗
(i − c
y
)
f
y
; Z = z
(1)
where X, Y, Z are the point coordinates in 3D, j and i
are the pixel coordinates, and c
x
, c
y
, f
x
and f
y
are the
intrinsic matrix pa rameters obtained by a calibration
of the Kinect camera. Then the 3D spatial partitioning
is performed. The cen te r of gravity in 3D is calculated
and projected to the ground plane :
C(X , Y, Z) =
∑
n
1
(X, Y, Z)
n
(2)
where n is the total number of points in the point
cloud. A 3D cylinder of varying dimensions with a
base center in the computed centroid projection defi-
nes the space partitioning limits. The height and ra-
dius of the cylinder are varying to adjust for the height
Figure 1: 3D spatial partitioning in 12 sections. Projected
center of gravity is shown in red, fixed point view direction
is shown by a green arrow.
3D Point Cloud Descriptor for Posture Recognition
163

Figure 2: Descriptor spatial partitioning: 3 circles, 8 sec-
tors, 3 sections. Projected center of gravity is shown in red.
of a person. The data about human body proportions
ratio is u sed. A height of a pe rson is estimated, sim -
ply via the minimum and maximum value calculated
for the first static point cloud of a video sequence. To
have an equal grid for all frames of a video sequence,
the normal is fixed based on the viewing point. The
partitioning in sectors starts from the same position
for ea ch video frame.
Figure 1 shows an example of 3D partitioning f or
one of the frames fr om MSR3D dataset. The only pa-
rameters of the descriptor are the number o f sections,
the nu mber of sectors and the number of circles. An
visualization of the descriptor parameters is shown in
Figure 2. For this work, we use only a uniform space
subdividing scheme and the cylinder volume partitio-
ning is then perfor med as:
V = 2πRH (3)
r
n
=
R
n
c
; h
n
=
H
n
h
; s
angle
=
360
n
s
(4)
where R and H are the fixed ra dius and height, r
n
,
h
n
and s
angle
are the circle a nd height intervals and the
angle correspon ding to each sector.
The final descriptor is obtained by calculating the
number of points in each formed 3D cell i.e. the cell
occupancy. The descriptor is normalized by the total
number of points in the point cloud in order to com-
pensate for possible noise or shape differences.
The OpenNI Framework (Consortium et al., ) is
used by many 3D cameras and provides the user with
automatic body recognition and skeleton joints ex-
traction functionality. There fore, we are not addres-
sing the task of background subtraction in our work
and assum e that it is a prior step. For this paper, the
data from an RGBD c amera, where the human is lo-
cated and the background is subtracted, were used to
test the proposed descriptor.
Our descriptor design allows it to be used in a
multiple ca mera views scenario to grant a more relia-
ble and accurate pose description. For example, such
partitioning was successfully employed earlier for hu-
man recognition from complete point clouds (Essma-
eel et al., 2016) based on histograms of normal orien-
tations.
4 TRAINING AND TESTING
DATA
MSR Action3D Dataset (Li et al., 2010) was selected
to perform the experiments an d evaluate th e proposed
descriptor. This is one of the most used RGBD hu-
man action-detection an d recognition datasets. It is
also one of the first RGBD datasets capturing moti-
ons (dated 2010) and it contains a big amount of dif-
ferent actions performed by different persons. It con-
sists o f 20 action types performed by 10 subjects 2 or
3 times. The actions are: high arm wave, horizontal
arm wave, hamm e r, hand catch, forward punch, high
throw, draw an x, draw tick, draw circle, hand clap,
two hand wave, side-boxin g, bend, fo rward kick, side
kick, jogging, tennis swing, tennis serve, golf swing,
pick up & throw. The resolution of the video is not
very high, namely 3 20x24 0 and so is the frame ra te ,
namely 15 fp s. The data was recorded with a depth
sensor similar to the Kinect d evice and contains color
and depth video sequence s. The sequences are pre-
segmented for the backgro und and foreground . An
example of superimposed point cloud s co rrespond ing
to 3 actions from M SR Action 3D dataset is shown
in Figure 3. Skeleton joints data are also provided
with a higher framerate than the depth maps. Ho-
wever, many joints are wro ngly estimated, as can be
seen in Figure 4. For our experimen ts, we had to furt-
Figure 3: Three actions from MSR Action 3D dataset
shown as point clouds: high arm wave, horizontal wave,
golf swing.
her manually segment the d ataset into key postures in
3D. There is no accurate database with full body hu-
man poses as depth maps publicly available, despite
several works where the features which represent the
posture are learned from real and synthetic examples
(Shotton et al., 2013)(Ganapa thi et al., 2010), neither
the data nor the implemen ta tion of these me thods are
available. Recently a new multi-kinect posture data-
set was published (Shafaei and Little, 2016), however,
this one is huge and is not ded ic ated to the global pose
estimation but bo dy p arts segmentation. Since we are
not using any deep learning and proposing a hand-
crafted descriptor, we considered that a well- known
and widely used MSR Action 3D will be sufficient to
perform the test and training to show the capabilities
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
164

Figure 4: Examples of wrong skeleton estimation for MSR
3D dataset, actions ’High Arm Wave’, ’Horizontal Arm
Wave’, ’Hammer’. A person is always facing the camera
straight and his legs are not crossed.
Table 1: Postures selected from the MSR3D dataset.
Posture Training Test
1 Staying relaxed 160 54
2 Forward Kick 102 50
3 Hand lifted 45
◦
29 13
4 Right hand up 137 64
5 Right hand to the left 80 71
6 Clap 59 25
7 Hands wide open 35 13
8 Pick from the ground 33 34
9 Half bend 80 53
10 Full bend 65 69
11 Right leg kick 60 40
12 Right leg kick on side 49 34
13 Throw from the back 134 78
14 Right hand up 42 28
15 Both hands left half bend 62 30
16 Both hands to the left half bend 62 30
17 Both hands to the right half bend 88 37
18 Throw from the front 54 33
and limitations of our method. In this work, we are
aiming to perform a pose recognitio n with out a skele-
ton aligning or human-body parts segmentation. The
number of sequences for each action in MSR Action
3D data set is between 27 and 30. We separated the
data in a tr aining and testin g set, and selected bet-
ween 3 to 7 key poses for each action. For the posture
recogn ition test, 18 well distinguishable poses were
selected. The r esulting dataset structure is explained
in Table 1. All the d ata acquired fro m person 3 were
excluded from the dataset because half of the depth
informa tion was missing. Subjects 1-7 from the da-
taset are used for training an d 8-10 for testing. The
resulting dataset is not very big but corresponds to
our goal to evaluate the descriptive capacities of the
proposed solution.
5 EXPERIMENTS
We perform 3 series of experiments: unsuper vised
clustering of frames in to k -postures in a video se-
quence, posture recognition in one action sequence
and posture recognition for a set of postures. The
average e stima te d time for the descriptor c a lc ulation
(with the 2D-3D transformation perform e d before-
hand) is 0.2 µs on a Intel C602 machine, which is
compatible to th e time of the extraction of feature vec-
tors in (Wang et a l., 2016).
5.1 Unsupervised K-means Clustering
A simplistic way to compa re any two pose descriptors
is to calculate a Euclidean distance between them. At
first, we observed the dynamics of the distance chan-
ges on all the frames of a single video sequence from
the dataset. Figure 5 visualizes the distance compu-
tations for the sequence ’Horizontal Wave’ of MSR
Action 3D dataset. There are 5 distinctive postures in
this action. The result shows that there is a small dis-
tance between similar postures (i.e. consequent fra-
mes, frames in the beginning and the end of the se-
quence corresp onding to the same ’neutral’ posture).
To exploit this trend furthe r, a simple test with K-
means is p erformed, which shows that the descriptor
captures the posture difference well. Automatic key
positions were obtained by performing the K-means
clustering for 3 video sequences when one person is
performing an action 3 times. The optimal number of
basis K was estimated using th e elbow method. Fi-
gure 6 shows the results of this experiment. Qualita-
tive visual analysis shows that automatically detected
poses correspond well with the 5 most different po-
ses in the action ’Horizontal Wave’ selected manu-
ally. These tests work well for each person perfor-
ming a single actio n m ultiple times, but the test for the
whole data gives worse results, probab ly due to the
fact that the neutral posture is dominant in the dataset
and people tend to perform similar actions differently.
Hence, we obtain more interme diate clusters which
do not correspond precisely to key-postur es. Nevert-
heless, the obtained results are interesting enough to
continue the tests and try to evaluate complete posture
recogn ition based on the proposed descrip tor.
Figure 5: Pairwise descriptor distance. T he video sequence
starts and finishes by the same posture. The distance bet-
ween consequent frames is smaller and distinct ’key’ posi-
tions can be viewed as peaks of the graph.
3D Point Cloud Descriptor for Posture Recognition
165

Table 2: Classification results for 5 postures of the action
’Horizontal Wave’ show good results in terms of precision.
Posture initial arm 45
◦
kick arm front left arm right
Precision 0.94 0.81 1 1 1
Recall 1 0.8 0.76 1 0.71
F-measure 0.97 0.82 0.86 1 0.83
5.2 Single Performance Action
A Support Vector Ma chine (SVM) c lassifier was trai-
ned, O ne vs All, in order to classify the postures, fol-
lowed by 3-fold cross validation.
Figure 6: a) Three video sequences are shown as a succes-
sion of cluster centers. In first sequence person is starts to
perform the action faster than in sequence 2 and 3; b) 5 key
postures of the action ’Horizontal Wave’ (selected manu-
ally); c) 5 clusters obtained automatically. Pixel values are
averaged: the darker the color is, the more is the occurrence.
The F-measure, recall and precision were used to
evaluate the performance of the classifier. The main
criteria for our ta sk is precision, but we included re-
call and F-measur e parameters in order to evaluate a
possibility to use the descriptor in a scenario where
accurate retrieval of all postures is essential.
The results for each posture recognition for the
action ’Horizontal Wave’ are summarized in Table 2.
Train and test data for this sequence were segmented
manually ac cording to the scheme intr oduced in the
previous section. This simple test shows excellent r e-
sults in terms of precision for all but one posture.
Figure 7: Confusion matrix for the SVM-based classifica-
tion shows good results for all postures but one.
5.3 Set Retrieval Performance
The test for a single action postu re estimation shows
good results, hence we conducte d an extended version
of this test containing a bigger number of various pos-
tures. A full test for 18 postures was performed with
an SVM. Feature vectors o f the selected postures were
used for training and testing. Figure 7 shows the con-
fusion matrix for the classes obtained by the SVM.
The descriptor parameters (number of sections, cir-
cles and sectors) we re tuned for the best perfo rmance.
We obtained the best results w ith 12 sections, 10 cir-
cles and 10 sectors, corresponding average precision
is 0.94. The parameter tunin g is straight-forward and
shows that the different parameters combinations do
not have much of an effect on performance. The main
observation is that for postures selected the most im-
portant parameter is th e number of sections which
helps to separate the volume by vertical planes. Diffe-
rent com binations of parameters can give slightly bet-
ter or worse results in terms of precision, recall and
F-measure. Corresponding curves obtained for diffe-
rent parameters are sh own in Figure 8.
The results sh ow good performan c e in terms of
precision which is excellent for simple postures. Our
results are comparable with the results of (Wang et al.,
2016) where authors are usin g only 5 distinct postu -
res: standing, sitting, stoop ing, kneeling and lying.
Of these, several postures are similar to ours, plus we
are aiming at more complex and varied postures. The
original dataset of (Wang et al., 2016) is not availa-
ble, but we also performed a test with just 3 very dif-
ferent postures and a similar amou nt o f training and
testing data. As before, the training data and test
data are formed from different subjects. Our postu-
res are: staying, right-hand up, ben ding. The corre-
sponding numbers of training and testing images are:
384/125, 246/125, and 98/103. With this small da-
taset we obtain excellent results in term of precision
and r ecall, all the tests are assigned correctly. Our re-
sults and the results from (Wang et al., 2016) can not
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
166
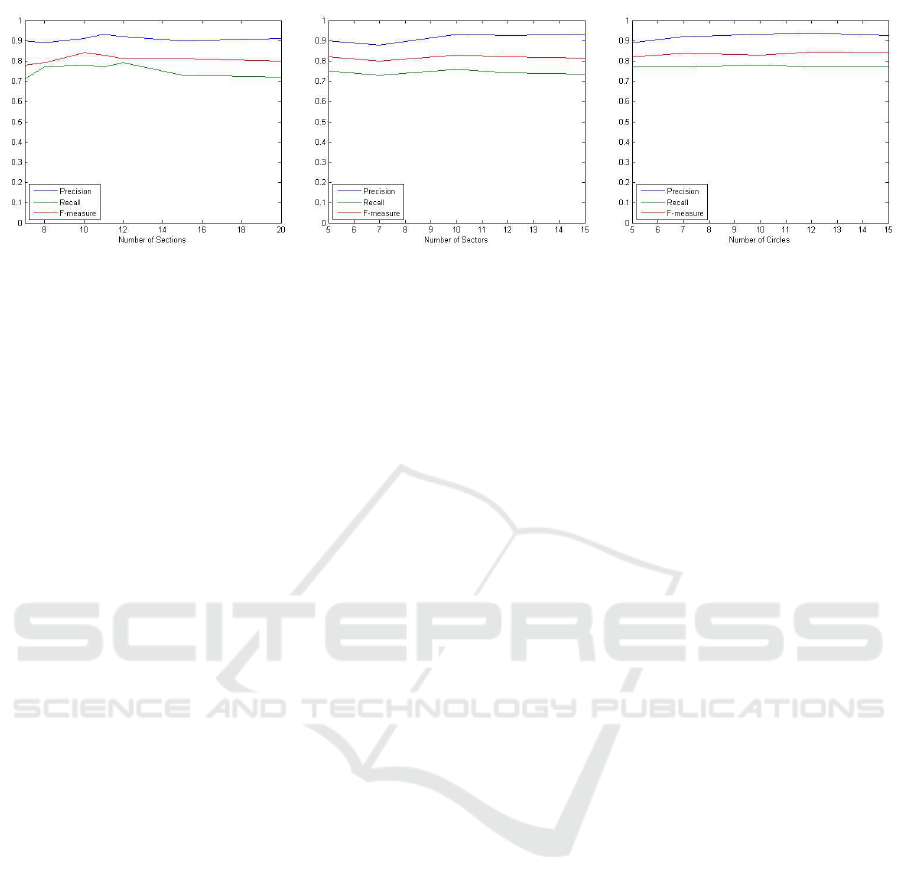
Figure 8: Tuning of t he parameters. Precision, recall and F-measure curves for a) the number of section varies, sectors and
circles fixed to 10; b) the number of sectors varies, sections and circles fixed to 10; t he number of circles varies, sections and
sectors are fixed t o 10.
be directly compared, but this test g ives an idea about
the descriptor capabilities. Wang et al. test their pos-
ture recognitio n method on 80-100 dep th images ta-
ken each for 8 per sons. The recognition rate is also
very high, with some minor errors (for example, for
the first person the r ecognition rate is: 79/80, 99/100,
80/80, 80/80, 7 9/80). It should be mentioned, that
(Wang et al., 2016) uses same subjects for testing and
training, which is probably easier as we have shown
in our tests f rom the previous section.
6 CONCLUSIONS
This paper shows that body pose may be adequately
represented witho ut joint estimatio n. The proposed
descriptor can be used exclusively, or as an advanta-
geous addition to tradition skeleton-joints estimation
methods.
The introduced descriptor works well for captu-
ring the 3D spatial arrangemen t of a point cloud struc-
ture. Experiments show that our method a c hieves
competitive re sults compared to curr ent hand crafted
state of the art descriptors. Learned or trained des-
criptors may give superior performance but critically
depend on the availability of large amounts of labeled
data. Secondly, these architectures don’t generalize
outside their initial domain. Our algorithm is a sim-
ple and elegant solution, when jo int informatio n is not
available or unreliable.
Example applications include action recognition
and gait analysis. For the latter, the descriptor may be
deployed for cycle event or symmetry detection and
evaluation (Auvinet et al., 2015). Another possibility
is to be able to divide a video along the time axis using
posture information in the c ase of misalignm ent. De-
tected postures can be used to temporally align the
data or as key-words describing the action.
There are number of open issues. The descriptor is
noise sensitive, which becomes more apparent if part
of the d epth data is missing. Secondly, the Euclidean
distance metric b e tween two descriptor vectors cur-
rently excludes 3D spatial information. Semantically
different postures can th us result in descriptor vectors
that are near similar.
Future work will address these issues next to de-
veloping an application for real-time gait cycle event
recogn ition.
REFERENCES
Agarwal, A. and Triggs, B. (2006). Recovering 3d human
pose from monocular images. IEEE transactions on
pattern analysis and machine intelligence, 28(1):44–
58.
Auvinet, E., Multon, F., and Meunier, J. (2015). New lower-
limb gait asymmetry indices based on a depth camera.
Sensors, 15(3):4605–4623.
Bengio, Y., Louradour, J., Collobert, R., and Weston, J.
(2009). Curriculum learning. In Proceedings of the
26th annual international conference on machine le-
arning, pages 41–48. ACM.
Cavazza, J., Morerio, P., and Murino, V. (2017). When ker-
nel methods meet feature learning: L og-covariance
network for action recognition from skeletal data.
arXiv preprint arXiv:1708.01022.
Chang, J. Y. and Nam, S. W. (2013). Fast random-forest-
based human pose estimation using a multi-scale and
cascade approach. ETRI Journal, 35(6):949–959.
Charles, J. and Everingham, M. (2011). Learning shape mo-
dels for monocular human pose estimation from the
microsoft xbox kinect. In IEEE International Confe-
rence on Computer Vision Workshops (ICCV Works-
hops),, pages 1202–1208.
Chen, C.-H. and Ramanan, D. (2017). 3d human pose es-
timation= 2d pose estimation+ matching. Computer
Vision and Pattern Recognition (CVPR).
Chen, X. and Yuille, A. L. (2014). Articulated pose esti-
mation by a graphical model with image dependent
pairwise relations. In Advances in Neural Information
Processing Systems, pages 1736–1744.
3D Point Cloud Descriptor for Posture Recognition
167

Ch´eron, G., Laptev, I., and Schmid, C. (2015). P- cnn: Pose-
based cnn features for action recognition. In Procee-
dings of the IEEE international conference on compu-
ter vision, pages 3218–3226.
Cippitelli, E., Gasparrini, S., Spinsante, S., and Gambi, E.
(2015). Kinect as a tool for gait analysis: validation of
a real-time joint extraction algorithm working in side
view. Sensors, 15(1):1417–1434.
Comaniciu, D. and Meer, P. (2002). Mean shift: A robust
approach toward feature space analysis. IEEE Tran-
sactions on pattern analysis and machine intelligence,
24(5):603–619.
Consortium, O. et al. Openni, the standard framework for
3d sensing. URL as accessed on. 2017-09-30.
Essmaeel, K., Migniot, C., and Dipanda, A . (2016). 3d des-
criptor for an oriented-human classification from com-
plete point cloud. In VISIGRAPP (4: VISAPP), pages
353–360.
Ganapathi, V., Plagemann, C., Koller, D., and Thrun, S.
(2010). Real time motion capture using a single time-
of-flight camera. In IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), pages 755–
762.
Ganapathi, V., Plagemann, C., Koller, D., and Thrun, S.
(2012). Real-time human pose tracking from range
data. In European conference on computer vision, pa-
ges 738–751. Springer.
Han, Y., Zhang, P., Zhuo, T., Huang, W., and Zhang, Y.
(2017). Video action recognition based on deeper con-
volution networks with pair-wise frame motion conca-
tenation. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition Workshops,
pages 8–17.
Hinterstoisser, S. , Lepetit, V., Ilic, S., Holzer, S., Bradski,
G. R., Konolige, K., and Navab, N. (2012). Model ba-
sed training, detection and pose estimation of texture-
less 3d objects in heavily cluttered scenes. In ACCV
(1), pages 548–562.
Jhuang, H., Gall, J., Zuffi, S., Schmid, C., and B lack, M. J.
(2013). Towards understanding action recognition. In
Proceedings of the IEEE international conference on
computer vision, pages 3192–3199.
Lan, Z., Zhu, Y., Hauptmann, A. G., and Newsam, S.
(2017). Deep local video feature for action recog-
nition. In IEEE Conference on Computer Vision
and Pattern Recognition Workshops (CVPRW), pages
1219–1225.
Li, S., Liu, Z.- Q ., and Chan, A. B. (2014). Heterogeneous
multi-task learning for human pose estimation with
deep convolutional neural network. In Proceedings of
the IEEE Conference on Computer Vision and Pattern
Recognition Workshops, pages 482–489.
Li, W., Zhang, Z., and Liu, Z. (2010). A ction recognition
based on a bag of 3d points. In IEEE Computer So-
ciety Conference on Computer Vision and Pattern Re-
cognition Workshops (CVPRW), pages 9–14.
Mentiplay, B. F., Perraton, L. G., Bower, K. J., Pua, Y.-H.,
McGaw, R., Heywood, S., and Clark, R. A. (2015).
Gait assessment using the microsoft xbox one kinect:
Concurrent validity and inter-day reliability of spatio-
temporal and kinematic variables. Journal of biome-
chanics, 48(10):2166–2170.
Peng, B. and Luo, Z. (2016). Multi-view 3d pose estimation
from single depth images. Technical report, Techni-
cal report, St anford University, USA, Report, Course
CS231n: Convolutional Neural Networks for Visual
Recognition.
Pishchulin, L., Andriluka, M., Gehler, P., and Schiele, B.
(2013). Poselet conditioned pictorial structures. In
Proceedings of the IEEE Conference on Computer Vi-
sion and Pattern Recognition, pages 588–595.
Sarafianos, N., Boteanu, B., Ionescu, B., and Kakadiaris,
I. A. (2016). 3d human pose estimation: A review
of the literature and analysis of covariates. Computer
Vision and Image Understanding, 152:1–20.
Shafaei, A. and Little, J. J. (2016). Real-time human motion
capture with multiple depth cameras. In IEEE 13th
Conference on Computer and Robot Vision (CRV), pa-
ges 24–31.
Shotton, J., Sharp, T., Kipman, A., Fitzgibbon, A., Fi -
nocchio, M., Blake, A., Cook, M., and Moore, R.
(2013). Real-time human pose recognition in parts
from single depth i mages. Communications of the
ACM, 56(1):116–124.
Tang, D., Jin Chang, H., Tejani, A., and Kim, T.-K. (2014).
Latent regression forest: Structured estimation of 3d
articulated hand posture. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recogni-
tion, pages 3786–3793.
Tompson, J. J., Jain, A., LeCun, Y., and Br egler, C. (2014).
Joint trai ning of a convolutional network and a graphi-
cal model for human pose estimation. In Advances in
neural information processing systems, pages 1799–
1807.
Vieira, A., Nascimento, E., Oliveira, G., Liu, Z., and Cam-
pos, M. (2012). Stop: Space-time occupancy pat-
terns for 3d action recognition fr om depth map se-
quences. Progress in Pattern Recognition, Image Ana-
lysis, Computer Vision, and Applications, pages 252–
259.
Wang, W.-J. , Chang, J.-W., Haung, S. -F., and Wang, R.-J.
(2016). Human posture recognition based on images
captured by the kinect sensor. International Journal
of Advanced Robotic Systems, 13(2):54.
Wohlhart, P. and Lepetit, V. (2015). Learning descriptors
for object recognition and 3d pose estimation. In Pro-
ceedings of the IEEE Conference on Computer Vision
and Pattern Recognition, pages 3109–3118.
Yang, Y. and Ramanan, D. (2011). Articulated pose esti-
mation with flexible mixtures-of-parts. In IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 1385–1392.
Ye, M. and Yang, R. (2014). Real-time simultaneous pose
and shape estimation for articulated objects using a
single depth camera. In Proceedings of the IEEE Con-
ference on Computer Vision and Pattern Recognition,
pages 2345–2352.
Yub Jung, H., Lee, S., Seok Heo, Y., and Dong Yun, I.
(2015). Random tree walk toward instantaneous 3d
human pose estimation. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recogni-
tion, pages 2467–2474.
VISAPP 2018 - International Conference on Computer Vision Theory and Applications
168
