
Practical Passive Leakage-abuse Attacks Against Symmetric
Searchable Encryption
Matthieu Giraud
1
, Alexandre Anzala-Yamajako
2
, Olivier Bernard
2
and Pascal Lafourcade
1
1
Universit
´
e Clermont Auvergne, BP 10448, F-63000, Clermont-Ferrand, France
2
Thales Communications & Security, 4 avenue des Louvresses, 92622, Gennevilliers, France
Keywords:
Symmetric Searchable Encryption, Leakage, Passive Attacks.
Abstract:
Symmetric Searchable Encryption (SSE) schemes solve efficiently the problem of securely outsourcing client
data with search functionality. These schemes are provably secure with respect to an explicit leakage profile;
however, determining how much information can be inferred in practice from this leakage remains difficult.
First, we recall the leakage hierarchy introduced in 2015 by Cash et al. Second, we present complete practical
attacks on SSE schemes of L4, L3 and L2 leakage profiles which are deployed in commercial cloud solutions.
Our attacks are passive and only assume the knowledge of a small sample of plaintexts. Moreover, we show
their devastating effect on real-world data sets since, regardless of the leakage profile, an adversary knowing a
mere 1% of the document set is able to retrieve 90% of documents whose content is revealed over 70%. Then,
we further extend the analysis of existing attacks to highlight the gap of security that exists between L2- and
L1-SSE and give some simple countermeasures to prevent our attacks.
1 INTRODUCTION
With the growing importance of digital data in every-
day life, it is necessary to have backups and to have
access from anywhere. For these reasons, outsourcing
this digital data to a cloud provider is an enticing so-
lution. However, some of this data, such as legal doc-
uments, banking and medical, the industrial patents
or simply our emails can be sensitive and/or confi-
dential, forcing the user to trust its cloud provider.
Client-side symmetric encryption is the classical an-
swer to the problem of data confidentiality. However,
encryption prevents any server-side processing of the
client data as is the norm on plaintext data. In par-
ticular, a server is not able to answer search queries,
that is given a keyword, retrieve the documents con-
taining that keyword. Symmetric Searchable Encryp-
tion (SSE) schemes introduced in (Song et al., 2000)
aim at retaining this search capability on encrypted
data. SSE scheme is a protocol between a client and
a server. The client owns a sensitive data set but
has limited computational power and storage capac-
ity. The server has a large storage space and high pro-
cessing power, but is not trusted by the client except
for executing correctly the search protocol. The set of
plaintext documents are stored in a DataBase (DB).
An SSE scheme creates metadata that is protected in
an Encrypted DataBase (EDB) and then stored by the
server. From a keyword and his symmetric secret key
the client creates a search token that is sent to the
server who finds the encrypted documents matching
the query with the help of EDB. Such documents
are then sent back to the client for decryption. While
the single keyword query is the basic functionality of
an SSE scheme there exist SSE schemes which allow
the client to add new encrypted documents to the en-
crypted database while retaining the search capability
(Cash et al., 2014; Kamara et al., 2012) and others
which focus on expanding the expressiveness of the
search queries such as Boolean (Cash et al., 2013) and
sub-string search queries (Faber et al., 2015).
The amount of information leaked by a given SSE
scheme to the server is formalized by a leakage func-
tion (Curtmola et al., 2006; Kamara et al., 2012).
The security of the scheme then relies on proving that
this function does not leak more information than ex-
pected. However, it can be used by an honest-but-
curious server (Goldreich, 1998), which dutifully ex-
ecutes the scheme but tries to deduce information on
the stored documents. By its nature, a SSE scheme
reveals to an observer the search and the access pat-
tern. In fact, a client searching twice the same key-
word sends the same query. And so, the server replies
to these queries in the same way. These search and
200
Giraud, M., Anzala-Yamajako, A., Bernard, O. and Lafourcade, P.
Practical Passive Leakage-abuse Attacks Against Symmetric Searchable Encryption.
DOI: 10.5220/0006461202000211
In Proceedings of the 14th International Joint Conference on e-Business and Telecommunications (ICETE 2017) - Volume 4: SECRYPT, pages 200-211
ISBN: 978-989-758-259-2
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

access patterns are used in inference attacks (Islam
et al., 2012; Cash et al., 2015; Pouliot and Wright,
2016) whereas our passive attacks do not use these
information. In this paper, we focus on the infor-
mation revealed by the encrypted database regardless
exchanges between the client and the server. This
model assumes that the adversary can be the server
himself or a malicious person who is able to access
to the encrypted database stored on the server. Based
on deployed SSE schemes, (Cash et al., 2015) define
four leakage profiles L4, L3, L2 and L1, L4 being the
most leaky and L1 the least. Commercially available
SSE solutions are L4 schemes such CipherCloud
∗
and
Skyhigh Networks
†
, L3 schemes such Bitglass
‡
or L2
schemes as ShadowCrypt (He et al., 2014) and Mime-
sis (Lau et al., 2014) while proposed schemes in aca-
demic research are L1 schemes. L4-, L3- and L2-SSE
schemes can be used as a proxy for existing cloud so-
lutions or as extensions in client-side and so do not
require any modification on server-side. Assessing
the practical impact of each of these profiles on the
server knowledge of the protected data is critical for
real life applications. We study the impact of a pas-
sive attacker.
Our Contributions. Only assuming the knowledge
of a small sample of plaintexts in addition to the pro-
tected database given to the server, we design passive
attacks on L4, L3 and L2 leakage profiles. In par-
ticular, our attacks do not rely on observing search
queries. Our attacks exploit the leaked information
the scheme on the encrypted database to find, start-
ing from a sample of plain documents, their identi-
fiers in the encrypted database. Then, knowing these
correspondences, the adversary tries to determine val-
ues of plain keywords in the encrypted database to
recover other documents. Our attack on L4 schemes
uses repetitions and order of keywords in each docu-
ment, our attack on L3 schemes uses order of shared
keywords between documents while our attack on L2
schemes uses only information on shared keywords
between documents. The attack on L2 schemes Their
efficiency and practicality are demonstrated on sev-
eral real-world data sets such as the mailing-list of
Lucene Apache project
§
. In fact, the knowledge of a
small sample of plain documents by an adversary has
a huge impact. With our passive attacks on L4- and
L3-SSE schemes, an adversary knowing only 1% of
plain documents is able to reconstruct 90% of the pro-
tected data at 80%. For our passive attack on L2-SSE
schemes, the knowledge of 1% of plain documents
∗
ciphercloud.com/technologies/encryption/
†
skyhighnetworks.com/product/salesforce-security/
‡
bitglass.com/salesforce-security
§
mail-archives.apache.org/mod mbox/lucene-java-user/
implies the recovering of 70% the protected data at
80%. In this paper, we also deal with the gap of se-
curity that exists between L2- and L1-SSE schemes in
depth and show that L1-SSE are much more robust
against passive attacks while client do not perform
many queries. Finally, we propose trails of counter-
measures for our attacks. Countermeasures for our at-
tacks on L4- and L3-SSE schemes are efficient since
no information can be deduced although the adversary
knows a sample of plain documents. Moreover, they
generate not many false positives. On the contrary,
the countermeasure for our attack on L2-SSE schemes
is generic but requires a not negligible precomputing
phase and generates more false positives.
Related Work. For an active adversary able to plant
chosen documents in the database, (Cash et al., 2015)
present a partial document recovery attack on L3-
and L2-SSE schemes. With the extra ability to is-
sue selected queries, (Zhang et al., 2016) mount a
query recovery attack that works on any dynamic SSE
scheme. These active attacks are very efficient as few
injected files reveal associations between keywords
and search tokens but are different from ours since
we consider only a passive adversary who is not able
to plant document in the database.
Inference attacks based on the observation of
client queries and server responses have been also
proposed. The first one is the IKK Attack, proposed
in (Islam et al., 2012). Its goal is to associate search
tokens to actual keywords, exploiting the data access
pattern revealed by client queries and assuming the
adversary has access to a co-occurrence matrix that
gives the probability for two keywords to appear in a
randomly chosen document. As noted in (Cash et al.,
2015), this matrix needs to be so precise for the at-
tack to succeed, that it seems legitimate to suppose the
adversary has access to the number of documents in
which every keyword appears. With this strong extra
knowledge, they mount a more effective attack named
the Count Attack (Cash et al., 2015). Both attacks
target leakage profiles beyond L1, but the strength of
their assumptions questions their practicality. In com-
parison our attacks do not rely on observing client
queries but only consider the encrypted database as
viewed by the adversary. We compare IKK and Count
attacks to our passive PowerSet attack in Section 6.
Additionally, (Cash et al., 2015) propose a passive
partial document recovery attack for L3-SSE schemes
when the adversary knows plaintext-ciphertext pairs.
Our attacks suppose that we have not plaintext-
ciphertext pairs initially. An other approach, called
Shadow Nemesis Attack, is proposed in (Pouliot and
Wright, 2016). Using a training data set, this infer-
ence attack builds a co-occurrence matrix and reduce
Practical Passive Leakage-abuse Attacks Against Symmetric Searchable Encryption
201

the problem of matching search tokens to keywords to
the combinatorial optimization problem of weighted
graph matching. This attack can be performed on L2-
SSE schemes as our attacks. It uses the encrypted
database and a training data set or partial knowledge
on the original data set whereas our attacks use only
partial knowledge on the original data set. We show
in Section 6 that our PowerSet attack recovers more
keywords with the same knowledge.
Outline. In Section 2, we provide background on SSE
schemes and their security. We recall in Section 3 the
leakage hierarchy of (Cash et al., 2015). We describe
our new passive attacks in Section 4 and demonstrate
their effectiveness in Section 5. We show in Section 6
the gap for an adversary to recover client queries be-
tween L2- and L1-SSE schemes and give countermea-
sures for our attacks in Section 7.
2 SYMMETRIC SEARCHABLE
ENCRYPTION
We introduce notations, then we formalize SSE
schemes and discuss the associated security notion.
Sequences, Lists and Sets. A sequence of elements
is defined as an ordered set where repetitions are al-
lowed. A list is an ordered set where all elements are
distinct. A set is defined as a bunch of distinct ele-
ments with no order. Sequences are guarded by (...),
lists are denoted by square brackets [. ..] and sets by
braces {. ..}. The number of elements of a set E (resp.
list or sequence) is written #E.
Documents and Keywords. Let W = {w
1
,.. ., w
m
}
be a dictionary composed of m distinct keywords and
DB = {d
1
,.. ., d
n
} a set of n documents made of key-
words from W. Each document d
i
is a sequence of
length `
i
, formally d
i
= (w
i
1
,.. ., w
i
`
i
) ∈ W
`
i
. DB is
called the data set. We denote by W
i
the set of dis-
tinct keywords of the document d
i
, i.e. W
i
=
[d
i
]
.
The same objects are described server-side by
introducing the star superscript. Hence, W
∗
=
{w
∗
1
,.. ., w
∗
m
} denotes the set of search tokens as-
sociated to the keywords of W. Similarly, DB
∗
=
{
d
∗
1
,.. ., d
∗
n
}
is the set of ciphertexts of DB where d
∗
i
is the encryption of d
i
, and W
∗
i
is the set of tokens
associated to d
∗
i
. As to emphasize the fact that the as-
sociation between d
i
and d
∗
i
is not known to the server
a priori, an identifier id
i
is used to uniquely represent
d
∗
i
. A data structure EDB is also provided, which con-
tains protected metadata that allows the server to an-
swer search queries.
The list of all indices i such that d
i
∈ DB con-
tains the keyword w is denoted by DB(w). N denotes
the number of pairs (d,w) where d ∈ DB and w ∈ d,
i.e. N = #
(d, w) | d ∈ DB,w ∈d
. Note that, as it
corresponds to a lower bound on the size of EDB,
N can always be computed by the server. Server-
side, the list of the identifiers of all the documents
d
∗
i
∈ DB
∗
associated to the search token w
∗
is writ-
ten EDB(w
∗
). We stress that this information is not
accessible directly from w
∗
and DB
∗
, we need the
extra protected metadata structure EDB. Moreover,
Pos(w, d) denotes the position of keyword w in the
document d.
2.1 Static SSE Schemes
Basic SSE schemes are defined by a symmetric en-
cryption scheme together with an algorithm for setup
and another for search.
As a first step, the client creates two data struc-
tures DB
∗
and EDB as introduced above. Both data
structures are then uploaded to the server. As a sec-
ond step, when the client wants to search for a spe-
cific keyword w, he computes the associated search
token w
∗
with his secret key and sends w
∗
to the
server. From w
∗
and EDB the server is able to re-
turn the identifiers of all encrypted documents match-
ing the client’s search. With the list of identifiers the
client retrieves the encrypted documents, from which
he can obtain the plaintext documents. We stress that
the server should not be able to learn anything about
the client’s query or the returned documents.
Definition Static SSE scheme. Given a symmet-
ric encryption scheme (E
·
(·),D
·
(·)) where E
·
(·)
denotes the encryption algorithm and D
·
(·) de-
notes the decryption algorithm, we define a
static SSE scheme of security parameter λ as
a quartet of polynomial-time algorithms Π =
(Gen,Setup,SearchClient,SearchServer) by:
(K, k) ← Gen(1
λ
) is a probabilistic algorithm run by
the client. It takes as input a security parameter
λ, and outputs two symmetric secret keys K and k
which are both kept securely by the client.
(EDB,DB
∗
) ← Setup(K, k,DB,E
·
(·)) is an al-
gorithm run by the client to set the scheme
up. It takes as input secret keys K and k,
the database DB and the encryption algo-
rithm E
·
(·), and outputs both the protected
metadata EDB and the encrypted documents
DB
∗
= (E
k
(d
1
),.. ., E
k
(d
n
)).
w
∗
← SearchClient(K, w) is a deterministic algo-
rithm run by the client to send a query to the
server. It takes as input the secret key K and a
keyword queried w ∈ W, and outputs the search
token w
∗
∈ W
∗
associated with w. Finally w
∗
is
sent to the server.
EDB(w
∗
) ← SearchServer(EDB,w
∗
) is a determin-
SECRYPT 2017 - 14th International Conference on Security and Cryptography
202

istic algorithm run by the server to answer a
client-query. It takes as input the protected meta-
data EDB and the client-generated search token
w
∗
and outputs EDB(w
∗
): the identifiers of the
encrypted documents containing keyword w. This
list is sent back to the client.
This defines static SSE schemes. Static SSE
schemes allow the client to initialize a protected
database that supports keyword searches but cannot
be updated by opposition to dynamic SSE schemes.
We do not introduce dynamic schemes since their en-
crypted databases can be attacked at least as well as
static schemes.
2.2 Security of SSE Schemes
Introduced by Curtmola et al. in (Curtmola et al.,
2006) and by Kamara et al. in (Kamara et al., 2012),
the leakage function L of a SSE scheme is a set
of information revealed by the SSE scheme to the
server. This leakage function formalizes information
that EDB and the client queries reveal to the server.
The SSE scheme is said to be L -secure if and only
if any polynomial-time adversary making a sequence
Q of queries (i.e. keywords of W) can successfully tell
with only negligible probability whether the protocol
is honestly executed or simulated from the leakage
function L . The L-security proves that no informa-
tion is leaked by the SSE scheme to the server outside
of what is exposed by the leakage function. We fo-
cus on the practical impact on the knowledge of the
protected data.
3 A LEAKAGE HIERARCHY
We recall classes of SSE schemes according to how
much information the protected database leaks, as
first introduced in (Cash et al., 2015).
L4 Leakage Profile. Without any semantic consid-
eration, a document is characterized by its number
of words, their order and their occurrence counts.
Moreover, it is possible to know which words are
shared with any other document. L4-SSE schemes
used by commercial encryption products as Cipher-
Cloud reveal these information, so nothing is lost
about the plaintext non-semantic structure. A SSE
scheme of leakage function L is of class L4 if and
only if L(EDB) =
(w
∗
i
1
,.. ., w
∗
i
`
i
)
16i6n
.
Example. We use the following setup as a
running example to illustrate the different
amounts of leakage revealed to the server. Let
W = {as,call, i,if, me, possible,soon,you} and
d
1
and d
2
, two documents defined over W
where d
1
= (call,me,as, soon,as, possible) and
d
2
= (i, call,you, if,possible). Assume that the search
tokens W
∗
associated to keywords of W are the
following:
W W
∗
as 14
call 76
i 33
if 11
W W
∗
me 25
possible 35
soon 78
you 10
Under L4 leakage, EDB reveals to the
server (76,25, 14,78,14,35) → id
1
and
(33,76,10, 11,35) → id
2
. The server knows
that the document identified by id
1
is of length 6
and has five distinct keywords; it also knows that
one keyword, associated to the token 14, is repeated
twice. The document identified by id
2
contains five
distinct keywords and shares two keywords with the
first document represented by tokens 35 and 76.
L3 Leakage Profile. For keyword search pur-
poses, it is not necessary to know the occurrence
count of each keyword. Then a SSE scheme of
leakage function L is of class L3 if and only if
L(EDB) =
L3
EDB
(id
i
)
16i6n
, where L3
EDB
(id
i
) =
(w
∗
i
1
,.. ., w
∗
i
`
i
)
.
Example. Resuming the running example, the in-
formation revealed by an L3-SSE scheme about
d
1
and d
2
is: (76,25,14, 78,35) → id
1
and
(33,76,10, 11,35) → id
2
. The server does not know
anymore that the token 14 is associated twice to id
1
.
L2 Leakage Profile. L2-SSE schemes, as (He et al.,
2014), only reveal the set of tokens of a document.
The server can still determine which documents con-
tain a given token. A SSE scheme of leakage function
L is L2 if and only if L(EDB) =
W
∗
i
16i6n
.
Example. Resuming the running example, an L2-SSE
scheme reveals about d
1
and d
2
: (14, 25,35,76,78) →
id
1
and (10,11, 33,35, 76) → id
2
. We stress that the
token order is not preserved in EDB: we arbitrarily
sorted the token in ascending order, thus the server
does not know their initial order.
L1 Leakage Profile. With no initial search, L1-SSE
schemes, as (Cash et al., 2014; Curtmola et al., 2006),
leak the least possible amount of information, i.e. the
number N of document/keyword pairs of the data set.
Thus L(EDB) = {N}.
Example. Resuming the running example, the infor-
mation revealed by an L1-SSE scheme looks like:
w
∗
α β γ δ ε ζ η θ ι κ
Id. a b c d e f g h i j
Greek (resp. Latin) letters represent tokens (resp.
identifiers). The server has absolutely no clue about
this correspondence, so it only knows N = 10. If the
client searches for “soon” and “you”, this reveals:
Practical Passive Leakage-abuse Attacks Against Symmetric Searchable Encryption
203

w
∗
α β γ δ ε 35 35 θ ι 78
Id. a b c d e id
1
id
2
h i id
1
Hence, the server learns that documents identified by
id
1
and id
2
share the same keyword of token 35; key-
words of tokens 14 and 35 are both in the document
identified by id
1
.
Effect of Queries on the L1 Leakage Profile.
We study what can be inferred from the protected
database, but it is informative to reflect upon the ef-
fect of queries on the amount of information revealed
to the server. At the end of the search protocol the
client obtains identifiers of the documents matching
its query. Server-side this can be leveraged to as-
sociate search tokens {w
∗
i
1
,.. ., w
∗
i
q
} to their matched
documents {EDB(w
∗
i
1
),.. ., EDB(w
∗
i
q
)}, which corre-
sponds to the definition of the L2 leakage profile given
above. Actually, if all keywords are queried then the
leakage profile L1 collapse to L2. Hence, a passive at-
tack on L2-SSE schemes can be performed on L1-SSE
schemes if all keywords have been queried.
4 ATTACKS
Our attacks aim at recovering information on en-
crypted documents from the knowledge of EDB
stored on the server. Hence, the attacker can be a
curious server or a malicious person who is able to
access the server. These attacks are completely pas-
sive; the only assumption made here is that we know a
(small) sample S of the plaintext documents. We em-
phasize that we do not know any pair of cipher/plain
documents. We stress that this knowledge of a sample
S is in practice a realistic assumption: for instance,
data sets of mails might contain items that have been
transferred outside the scope of the SSE scheme. We
can also imagine a user having a part of its data on a
server and he decides to encrypt all of its data using
a SSE scheme. When the user uploads the encrypted
database, the server has the knowledge of both the old
plain data and the encrypted database. With these sce-
narios, we represent the known sample S by choosing
randomly plaintext documents from DB.
Model. In the first step, each plaintext of S is as-
sociated to its protected information in EDB. This
step is performed using statistical properties that can
be computed independently from the plaintexts them-
selves or from the associated leakage given in EDB.
The performance of this association step heavily de-
pends on the statistic capacity to give unique results
over the data set. Assume we are in the case of a data
set of books and there is one known best-seller in the
data set. An attacker can try to find its identifier in
the encrypted database by checking, for example, if
there is an unique identifier sharing the length of the
known best-seller (L4-SSE schemes) or if there is an
unique identifier sharing the same number of distinct
keywords (L3-SSE schemes).
In the second step, the keywords of the plaintexts
are paired with their tokens. Of course, under L4
and L3 leakage profiles, which preserve the order of
keywords in EDB, this pairing is completely straight-
forward. Finally, correspondences between keywords
and tokens obtained from S can be spread back into
EDB, thus recovering partially or totally the content
of the encrypted documents. This actually has a dev-
astating effect, giving to the server a massive knowl-
edge of DB, as shown in Section 5.
4.1 Mask Attack on L4-SSE
In order to capture keywords number, order and oc-
currence counts, we introduce the mask of a document
d
i
(resp. id
i
), denoted by mask(d
i
) (resp. mask(id
i
)),
as the sequence where all keywords (resp. tokens) are
replaced by their position of first appearance. For ex-
ample, if d
i
= (to,be, or,not, to,be), then mask(d
i
) =
mask(id
i
) = (1, 2,3,4,1, 2).
The idea of the attack is intuitive: for each plain-
text d ∈ S , the mask of d is computed; this mask is
then compared with all masks of corresponding length
computed from EDB. Hopefully, only one mask of
EDB is matching the mask of d, leading to a correct
association. In practice, this is almost always the case
(see Section 5). The entire process is summarized in
Algorithm 1.
Input: EDB, S ⊆ DB
Output: Set of tokens W
∗
rec
⊆ W
∗
associated to
their keyword in W
foreach d ∈ S do
A
d
=
i | `
i
= #d, mask(id
i
) = mask(d)
;
return W
∗
rec
=
W
∗
i
| #A
d
i
= 1
Algorithm 1: Mask Attack.
4.2 Co-mask Attack on L3-SSE
Under L3 leakage the Mask Attack does not apply
anymore as the mask of a document d boils down to
the sequence
1,.. ., #[d]
.
Therefore we introduce the co-resulting mask
of a pair (d
1
,d
2
) of documents, denoted by
comask(d
1
,d
2
). Intuitively, it can be viewed as the
mask of positions of shared keywords in the other
document. We recall that Pos(w, d) is the position of
SECRYPT 2017 - 14th International Conference on Security and Cryptography
204

keyword w in document [d] and define:
comask(d
1
,d
2
) =
Pos(d
1
[i],d
2
)
1≤i≤#W
1
,
Pos(d
2
[i],d
1
)
1≤i≤#W
2
.
We stress that this quantity can be computed di-
rectly from every EDB of profile L3; by abuse of no-
tation this is denoted by comask(id
1
,id
2
).
The general idea of the algorithm is as follows: for
each pair in (d
i
,d
j
) ∈S
2
, the co-resulting mask of the
pair is computed and compared with all co-resulting
masks computed from elements of EDB which have
length #[d
i
] and #[d
j
].
In practice, this kind of exhaustive search would
be particularly inefficient. We instead iteratively con-
struct a set A
t
containing all t-tuples of identifiers such
that the co-resulting masks of all pairs in the t-uple
match the co-resulting masks of the corresponding
pairs in (d
1
,.. ., d
t
) ⊆ S . More formally:
A
t
=
id
i
1
,.. ., id
i
t
such that
∀s,u ≤t, comask(id
i
s
,id
i
u
) = comask(d
s
,d
u
)
.
Hence, the initialization of the Co-Mask Attack con-
sists for the adversary to compute A
2
corresponding to
the pairs of identifiers sharing the same comask that
the first considered pair of plain documents known by
the adversary. Then, to compute A
t
from A
t−1
using
d
t
, we consider for each induced new pair (d
j
,d
t
) the
set C
j,t
of pairs of identifiers (id
i
j
,id
i
t
) with matching
co-resulting masks, such that both id
i
j
and id
i
t
are still
marked as compatible. From the C
j,t
’s, it is easy to
remove all inconsistent t-tuples from A
t
, i.e. for each
j, those having positions j and t not in C
j,t
. When
t reaches #S , the whole search space has been ex-
plored: each component A
#S
[k] composed of only one
element gives the correct association A
#S
[k] = id
k
.
It is worth noting that in practice A
2
is almost al-
ways reduced to one element, and so is A
#S
. In any
case, very few identifiers would remain possible for
a given document in A
#S
. The Co-Mask Attack is
summarized in Algorithm 2. We stress that this at-
tack could be extended to higher order intersections.
In practice, only considering pairs already gives out-
standing results, as shown in Section 5.
4.3 PowerSet Attack on L2-SSE
As the order of keywords is not preserved anymore
under L2 leakage, the co-resulting mask used in the
Co-Mask Attack cannot be computed. Worse, even if
a document is correctly associated to its identifier, in-
ferring the correct association between each keyword
and its token is still a challenge. The PowerSet Attack
addresses both issues.
Input: EDB, S =
d
1
,.. ., d
#S
⊆ DB
Output: Set of tokens W
∗
rec
⊆ W
∗
associated to
their keyword in W
// Consider the first pair of documents
A
2
= {
id
i
1
,id
i
2
| #id
i
1
= #[d
1
],#id
i
2
=
#[d
2
],comask(id
i
1
,id
i
2
) = comask(d
1
,d
2
)}
// Construct A
t
from A
t−1
using d
t
for t = 3 to #S do
A
t
= A
t−1
×
id | #id = #[d
t
]
// A
t
will be reduced by considering all new
pairs (d
j
,d
t
)
foreach j < t do
C
j,t
= {
id
i
j
,id
i
t
| id
i
j
∈ A
t
[ j],id
t
∈
A
t
[t],comask(id
i
j
,id
i
t
) =
comask(d
j
,d
t
)}
A
t
=
a ∈ A
t
|
a[ j],a[t]
∈C
j,t
// Keep consistent t-tuples
if #A
t
= 1 then break
return W
∗
rec
=
W
∗
t
| #A
#S
[t] = 1
Algorithm 2: Co-Mask Attack.
Associating Documents and Identifiers. An L2
leakage still allows to determine which keywords are
shared between two documents. To associate docu-
ments of S to their identifiers, it is therefore tempt-
ing to run the Co-Mask Attack where the co-resulting
mask of a pair of documents is replaced by the car-
dinal of their intersection. Unfortunately this is not
sufficient, since in practice many pairs of identifiers
of EDB share the same number of tokens.
We introduce the power set of order h of a list of
t documents, denoted by PowerSet
t
h
d
1
,.. ., d
t
, and
defined as the sequence of the
t
h
cardinals of all pos-
sible intersections of h elements of the t-uple, i.e.
PowerSet
t
h
d
1
,.. ., d
t
=
#
\
1≤j≤h
W
i
j
1≤i
1
<···<i
h
≤t
.
We stress that this sequence can be computed directly
from every EDB of profile L2; by abuse of notation
this will be denoted by PowerSet
t
h
id
1
,.. ., id
t
.
Example. Let d
1
= (w
1
,w
2
,w
3
), d
2
= (w
2
,w
3
)
and d
3
= (w
1
,w
4
) be three documents. Then, the
PowerSet of order 2 of these three documents is
PowerSet
3
2
d
1
,d
2
,d
3
=
#(W
1
∩ W
2
),#(W
1
∩
W
3
),#(W
2
∩W
3
)
.
The algorithm strives to exploit all available infor-
mation on S, i.e. finding sequences of identifiers such
that cardinals of all intersections of all possible sub-
sets equal cardinals of those computed on S . As this
Practical Passive Leakage-abuse Attacks Against Symmetric Searchable Encryption
205
is a huge search space, it must be explored with care.
Therefore, we iteratively construct a set A
t
containing
all t-tuples of identifiers such that all power sets of
order less than t correspond to the power sets of the
corresponding documents in (d
1
,.. ., d
t
) ∈ S . When t
reaches #S , all information on S has been processed
and singleton components of A
#S
give a correct asso-
ciation.
Hence, the initialization of the PowerSet Attack
consists for the adversary to compute A
2
correspond-
ing to the pairs of identifiers sharing the same num-
ber of distinct keywords. Then, computing A
t
starting
from A
t−1
and candidate identifiers for d
t
requires to
reduce the size of A
t
as fast as possible. This is done
by considering subset intersections of increasing or-
der, thus squeezing A
t
as the combinatorics grow. Let
A
(h)
t
be the set of compatible t-tuples with all power
sets of order up to h:
A
(h)
t
=
id
i
1
,.. ., id
i
t
such that ∀s ≤ h,
PowerSet
t
s
(d
1
,.. ., d
t
) = PowerSet
t
s
(id
i
1
,.. ., id
i
t
)
.
The algorithm then computes the following decreas-
ing sequence, using the procedure Reduce given in
Algorithm 3 to go from A
(h)
t
to A
(h+1)
t
:
A
t−1
×
id | #id = #{d
t
}
= A
(1)
t
⊇ A
(2)
t
⊇ A
(3)
t
⊇ ··· ⊇ A
(t)
t
= A
t
.
Input: S
t
=
d
1
,.. ., d
t
, A
(h)
t
Output: Set of (h + 1)-order candidates A
(h+1)
t
B
t
= A
(h)
t
;
// Consider each subset of (h + 1) elements
containing d
t
foreach 1 ≤ j
1
< ··· < j
h
< t do
C
j,t
= {
(id
i
j
),id
i
t
such that id
t
∈ B
t
[t]
(id
i
j
) ∈ B
t
[ j] and #
id
i
t
∩(id
i
j
)
=
#
d
t
∩(d
j
)
};
B
t
=
b ∈ B
t
|
(b[ j]),b[t]
∈C
j,t
;
// Keep consistent t-tuples
if #B
t
= 1 then break;
return A
(h+1)
t
= B
t
Algorithm 3: Reduce: A
(h+1)
t
from A
(h)
t
.
We stress that, by induction, only subsets contain-
ing d
t
have to be considered. Algorithm 4 summarizes
the first phase of the PowerSet Attack.
In practice, computing A
2
is the most costly part
of Algorithm 4, as the result is sufficiently small
so that adding new documents becomes negligible.
Moreover, experiments produced on chosen data sets
Input: EDB, S =
d
1
,.. ., d
#S
) ⊆ DB
Output: Set of documents S
0
⊆ S associated to
their identifiers in EDB
// Consider the first pair of documents
A
2
=
id
i
1
,id
i
2
such that #id
i
1
= #{d
1
},
#id
i
2
= #{d
2
} and PowerSet
t
2
(id
i
1
,id
i
2
) =
PowerSet
t
2
(d
1
,d
2
)
;
// Construct A
t
from A
t−1
using d
t
for t = 3 to #S do
A
(1)
t
= A
t−1
×
id | #id = #{d
t
}
;
// Consider intersections of increasing order
h to reduce A
t
for h = 2 to t do
A
(h)
t
= Reduce
A
(h−1)
t
;
if #A
(h)
t
= 1 then set A
t
= A
(h)
t
and
break;
return S
0
=
d
t
| #A
#S
[t] = 1
Algorithm 4: PowerSet Attack: documents-
identifiers association.
(Commons, Enron, Gutenberg and Lucene) show that
A
t
is reduced to one element as soon as t ≥ 4.
Associating Keywords and Tokens. The previous
phase associates each document of S
0
with a set of
tokens. Since token ordering is not preserved under
L2 leakage, finding the correct keyword-token associ-
ations remains non-trivial.
To solve this problem, we construct the inverted
index of S
0
, denoted by inv(S
0
), which associates the
keywords w ∈ S
0
and to the identifiers of the docu-
ments containing w. This inverted index is then or-
dered by decreasing number of identifiers to form the
ordered inverted index inv
≥
(S
0
).
Consider first the keyword w
i
having the most
identifiers, and assume that no following keyword has
the same associated identifiers. Hence the intersection
of the sets of tokens associated to w
i
gives a unique
match w
∗
i
. Now, if the second line w
j
of inv
≥
(S
0
) is
also unique, we distinguish two cases: either the in-
tersection of the sets of tokens associated to w
j
gives
a unique match w
∗
j
; or, when identifiers are also as-
sociated to the previous keyword w
i
, we obtain two
tokens. Knowing w
∗
i
from the first association, we
easily deduce the token w
∗
j
associated to w
j
.
Example. Let S
0
= {d
1
,d
2
,d
3
} be a set of three doc-
uments d
1
= (w
1
,w
2
,w
3
), d
2
= (w
3
,w
2
) and d
3
=
(w
1
,w
2
). Inverted indexes inv(S
0
) and inv
≥
(S
0
) are:
inv(S
0
)
w
1
id
1
id
3
w
2
id
1
id
2
id
3
w
3
id
1
id
2
inv
≥
(S
0
)
w
2
id
1
id
2
id
3
w
3
id
1
id
2
w
1
id
1
id
3
SECRYPT 2017 - 14th International Conference on Security and Cryptography
206

Consider the first line of inv
≥
(S
0
). We know that
only w
2
is in d
1
, d
2
and d
3
. Hence W
∗
1
∩W
∗
2
∩W
∗
3
=
w
∗
2
. Now, consider the second keyword of inv
≥
(S
0
)
i.e. w
3
. This keyword is in d
1
and d
2
, but w
2
too. So
W
∗
1
∩W
∗
2
=
w
∗
2
,w
∗
3
, but we already know that w
∗
2
is
the token of w
2
, hence the token of w
3
is w
∗
3
.
Unfortunately, several keywords may be associ-
ated to the same identifiers. In this case, they are com-
pletely indistinguishable and we ignore them when
they appear in the following intersections. This pro-
cess is given in Algorithm 5.
Input: EDB, set S
0
⊆ S of documents
associated to their identifiers
Output: Set of tokens W
∗
rec
⊆ W
∗
associated
to their keyword in W
W
∗
ign
←
/
0 ;
// Contains associated and indisting. tokens
Compute inv
≥
(S
0
);
foreach w ∈ inv
≥
(S
0
) taken in decreasing order
do
A
w
=
T
W
∗
i
| id
i
∈ inv
≥
(S
0
)[w]
W
∗
ign
;
W
∗
ign
= W
∗
ign
∪A
w
;
// Associated (#A
w
= 1) or indisting.
return W
∗
rec
=
A
w
| #A
w
= 1
Algorithm 5: PowerSet Attack: keywords-
tokens association.
4.4 Elements of Complexity
Deriving complexity bounds for our attacks depend
on statistical properties of the targeted data set. We
nevertheless give some elements allowing to compare
the impact of the leakage profiles.
The most relevant data for our attacks is the max-
imum number of identifiers to consider for a docu-
ment of a given length. For each leakage profile,
we have M
L23
= max
d∈DB
#
id | #id = #[d]
and
M
L4
= max
d∈DB
#
id | #id = #d
.
Measurements on our data sets (see Section 5)
show that
√
#DB is a good approximation of these
values.
Mask Attack. For each known document d of S ,
the Mask Attack computes masks for all candidates
of d, i.e. M
L4
masks computation for each document
d. Hence the total complexity for the Mask Attack is
O
#S ·M
L4
mask computations.
Co-Mask Attack. The Co-Mask Attack starts with
the construction of A
2
, i.e. the set of all identifiers
pairs of the encrypted database sharing the same
comask of the two chosen known documents of S .
Hence, constructing A
2
costs M
2
L23
applications of
Table 1: Characteristics of used data sets.
Data sets Content #DB #W N
Commons mailing list 28,997 230,893 3,910,562
Enron emails 490,369 643,818 47,301,160
Gutenberg books 21,602 2,853,955 91,261,811
Lucene mailing list 58,884 394,481 7,952,794
comask since we check all candidate pairs for the ini-
tial comask. We heuristically expect the sets A
t
to de-
crease as t grows. Indeed, if #A
2
≤M
L23
, each associ-
ation of d
t
starts from a smaller set A
t−1
and imposes
greater constraints, thus costing at most #A
2
·M
L23
. In
our experiments with chosen data sets, A
2
is almost
always reduced to one element. Since, we check the
comask for all candidates of each document d of S af-
ter the initialization, we conjecture a total complexity
of O
M
2
L23
+ #S ·M
L23
co-mask computations.
PowerSet Attack. The analysis is much more com-
plex. As the Co-Mask Attack, the PowerSet Attack
starts with the construction of A
2
, i.e. the set of all
identifiers pairs sharing the same number of keywords
of the two chosen known documents of S . Hence,
constructing A
2
costs M
2
L23
intersections cardinals
computations since we check all candidate pairs for
the initial cardinal intersection. Heuristically, the first
pair considered drastically reduces the number #A
2
of
candidates, and the same reasoning as above leads to a
conjectured complexity of O
M
2
L23
+ #A
2
·#S ·M
L23
intersections cardinals computations.
5 EXPERIMENTAL RESULTS
Real-World Data Sets. We implemented and ran the
attacks presented in Section 4 on four different real-
world data sets to evaluate their practical efficiency.
The first data set is the email data set from the En-
ron corporation, available online
¶
. Islam et al. (Islam
et al., 2012) and Cash et al. (Cash et al., 2015) con-
sider emails from each employee’s sent mail. Here,
we choose to took all 490,369 emails of the data sets,
including mails sent from the outside of Enron. The
second and third data sets are mailing lists from the
Apache foundation, namely Apache Commons
k
and
Apache Lucene which is used too in (Cash et al., 2015;
Islam et al., 2012). The last data set is the Project
Gutenberg
∗∗
. We summarize characteristics of used
data sets in Tab. 1.
One email message, one article or one book is con-
sidered as one document. For each document, stop-
¶
cs.cmu.edu/˜./enron/
k
mail-archives.apache.org/mod mbox/commons-user/
∗∗
gutenberg.org/wiki/Main Page
Practical Passive Leakage-abuse Attacks Against Symmetric Searchable Encryption
207

words have been removed. Moreover, we use the stan-
dard Porter stemming algorithm (Porter, 1980) to find
the root of each word of data set documents. We stress
that all processing steps on keywords have been done
considering the result given by the Porter’s algorithm.
Efficiency Measures. We ran our attacks for differ-
ent sizes of S using steps of 1% until 10% then steps
of 10% from 10% to 100%. Here 1% is 1% of the
pairs (d, w) of the data set; this allows us to perform
a fairer comparison between data sets than the usual
per-document measure, as knowing a long document
do not have the same impact as knowing a short one.
The measured success rate is the ratio of
keywords-tokens associations over the set of key-
words of S . Then, these correspondences are spread
back into EDB in order to evaluate their impact on
other documents of the data set. In particular, we mea-
sured the rate of documents of the data set whose key-
words are recovered at 70%, 80%, 90% and 100%.
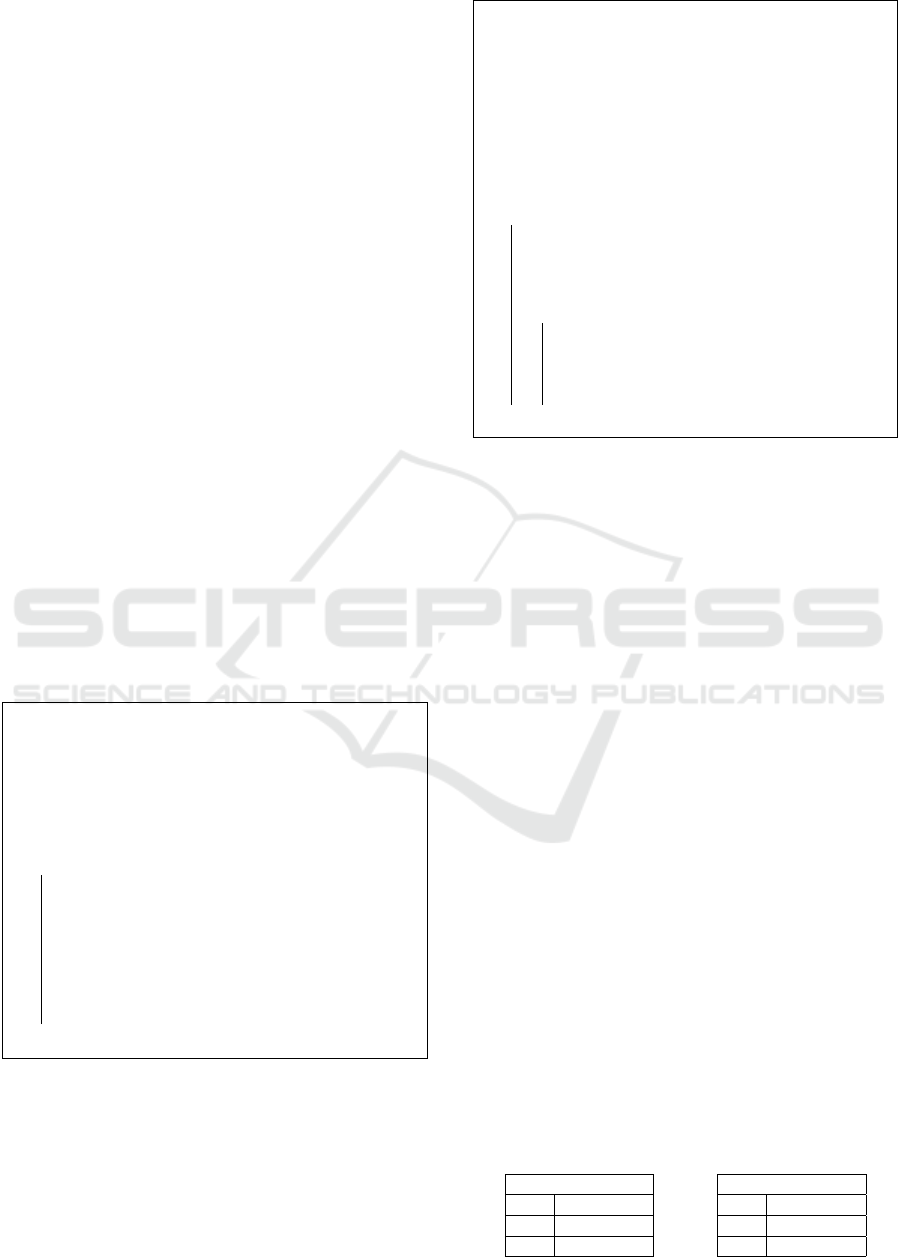
Experimental Results on Lucene. We expose here
the results of our attacks on the Lucene data set. All
timings are measured on a Core i7 using 16 Gb RAM.
Our attacks have a huge impact. If the server only
knows 1% of the Lucene data set, the Mask attack
(resp. the Co-Mask attack) can recover 99% of key-
words present in this sample in 72 seconds (resp. 284
seconds) whereas the PowerSet Attack can even so
recovers 21% of keywords in 489 seconds. The im-
pact on the knowledge of the protected data is illus-
trated with graphs in Fig. 1. For the Mask and the
Co-Mask attacks, the recovering of the 99% of key-
words present in the 1% of the data set allows us to
recover 50% of the protected data at 90%. For the
PowerSet Attack, the recovering of the 21% of key-
words present in the 1% of the data set allows to re-
cover 25% of the protected data at 90%. Details are
presented in Tab. 2. We precise that the impact of
our attacks is the same on the others chosen data sets
(Commons, Enron and Gutenberg)
††
.
Mask Attack. Over 98% of documents have a unique
mask in Lucene data set. This translates into over 99%
keyword-token association rate over the set S in all
cases. Moreover, knowing only 1% of the data set
already allows the server to recover 70% of the key-
words close to all documents; and 3,146 of them are
completely recovered.
Co-Mask Attack. Experiments show that despite the
loss of the frequency information, it remains as effec-
tive as the Mask Attack.
PowerSet Attack. It suffers widely from the loss
of keyword order. Hence, while the documents-
identifiers association performs equally well, the ex-
††
Results for Commons, Enron and Gutenberg are avail-
able online: http://eprint.iacr.org/2017/046.pdf
act association between keywords and tokens plateau
around 20%. Still, the knowledge of 1% of the data
set already allows to recover 80% of the keywords of
more than 70% of the database documents.
Practical Impact. As noted in (Cash et al., 2015),
this reconstruction allows to reveal sensitive informa-
tion even if the order of keywords is not preserved.
Human inspection of the output of our attacks gives a
clear idea of the sense of each document.
6 GAP BETWEEN L2- AND L1-SSE
We discuss the gap for an adversary to recover client
queries between L2- and L1-SSE schemes.
IKK Attack. (Islam et al., 2012) present a passive
query recovery attack on SSE schemes. It requires ac-
cess to a co-occurrence matrix C
W
which represents
the probability for two keywords to appear in a ran-
domly chosen document. The attack also requires the
observation of queries issued by the client and the re-
sponses provided by the server. The adversary is then
able to compute for each pair of search tokens, the
number of documents which match for both. Associ-
ating keywords to search tokens boils down to finding
the minimum of the function F(i
1
,.. ., i
q
) =
∑
1≤s,t≤q
#
EDB(w
∗
s
) ∩EDB(w
∗
t
)
n
−C
W
w
i
s
,w
i
t
2
,
for observed search tokens (w
∗
1
,.. ., w
∗
q
). Since no as-
sumption are made about the amount of leakage ob-
tained from the SSE scheme, we can classify the IKK
attack as an L1 attack with auxiliary information in
the form of this co-occurrence matrix C
W
. To the best
of our knowledge this is the most generic attack on
SSE schemes. Islam et al. justify the access to a co-
occurrence matrix by implying that it could be com-
puted from a data set similar to the one targeted by the
attack. The cost of building C
W
could then be amor-
tized over several data sets. In practice, (Cash et al.,
2015) show that any kind of success with this attack
requires C
W
to have been computed directly from the
plaintext data set DB. Another constraint is that for
the attack to be practical C
W
cannot be built over the
full dictionary; we must assume that all the search to-
kens are associated to a keyword represented in C
W
.
Following Section 3, we can relax the requirements
by considering this attack on an L2 scheme. In this
setting the adversary computes the response set in-
tersections directly from EDB without the need for
search tokens. Complexity-wise, the IKK attack is
costly as minimizing the objective function F requires
the use of simulated annealing (Islam et al., 2012).
SECRYPT 2017 - 14th International Conference on Security and Cryptography
208
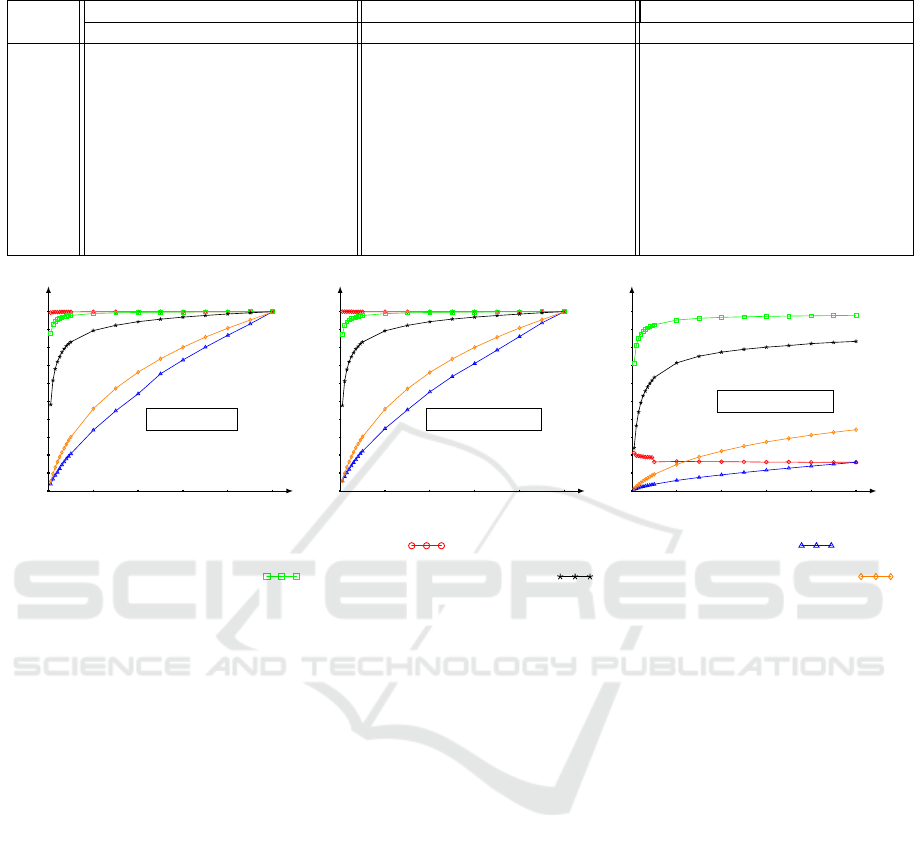
Table 2: Rate of recovered keywords and of 80%, 90% and 100% recovered documents of Lucene data set.
%DB Mask Attack Co-Mask Attack PowerSet Attack
known Rate # 80% # 90% # 100% Rate # 80% # 90% # 100% Rate # 80% # 90% # 100%
1 0.99 0.88 0.48 0.05 0.99 0.87 0.48 0.05 0.21 0.71 0.24 0.14
2 0.99 0.93 0.62 0.10 0.99 0.92 0.61 0.10 0.20 0.81 0.36 0.03
3 0.99 0.95 0.68 0.13 0.99 0.94 0.68 0.13 0.19 0.85 0.44 0.04
4 0.99 0.95 0.72 0.16 0.99 0.95 0.72 0.16 0.19 0.87 0.49 0.04
5 0.99 0.96 0.75 0.19 0.99 0.96 0.75 0.19 0.19 0.89 0.53 0.06
10 0.99 0.98 0.83 0.30 0.99 0.98 0.83 0.30 0.16 0.93 0.63 0.09
20 0.99 0.99 0.89 0.46 0.99 0.99 0.89 0.46 0.16 0.95 0.71 0.15
30 0.99 0.99 0.92 0.57 0.99 0.99 0.92 0.57 0.16 0.96 0.75 0.19
40 0.99 0.99 0.94 0.66 0.99 0.99 0.94 0.66 0.16 0.97 0.77 0.22
50 0.99 0.99 0.96 0.74 0.99 0.99 0.96 0.74 0.16 0.97 0.79 0.25
Success Rate
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 20 40
60
80 100
Mask Attack
% of known dataset
Success Rate
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 20 40
60
80 100
Co-Mask Attack
% of known dataset
Success Rate
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 20 40
60
80 100
PowerSet Attack
% of known dataset
Keyword/token associations over IKeyword/token associations over the dataset
Document recovered >80% Document recovered >90%
Documents fully ecovered
Figure 1: Efficiency of our attacks on Lucene data set depending on the knowledge rate of the server.
Count Attack. The Count attack from Cash et
al. in (Cash et al., 2015) also aims at passively re-
covering queries with the help of queries and a C
W
.
However on top of that, it requires to have access for
each keyword to the number of plaintext documents
that contain it. The adversary is then able to match
search tokens to a set of candidate keywords. Wrong
candidates are then eliminated using C
W
.
Count Attack assumes that the adversary has ac-
cess to the pairs
w
i
,#DB(w
i
)
16i6n
from which
he can compute the set
#DB(w
1
),.. ., #DB(w
n
)
=
#EDB(w
∗
i
1
),.. ., #EDB(w
∗
i
n
)
.
The use of a co-occurrence matrix means that the
Count Attack shares properties with the IKK Attack:
namely we assume that the observed search queries
correspond to keywords in C
W
and we do not need
search queries anymore if we attack an L2 scheme.
Complexity-wise, the Count Attack is orders of mag-
nitude faster than the IKK Attack since we leverage
the extraneous auxiliary information to avoid doing
any numerical optimization step.
Shadow Nemesis Attack. The Shadow Nemesis At-
tack from Pouliot and Wright in (Pouliot and Wright,
2016) presents also a passive query recovery attack on
SSE schemes. First, it uses a training set to build an
approximate co-occurrence matrix C
W
. Then, it build
a second co-occurrence matrix C
0
W
from the encrypted
database with keywords that has been queried. From
C
W
(resp. C
0
W
), they construct the weighted graph G
(resp. H). Pouliot and Wright compare these two co-
occurrence matrix by reducing them to the combina-
torial optimization problem of weighted graph match-
ing. The problem is to find the permutation X that re-
labels the nodes in H so that the permuted graph most
closely resembles G. If A
G
and A
H
are respectively
the adjacency matrices of G and H and using the Eu-
clidean distance denoted k·k
2
, then the goal is to find
X such that minimizes: kA
G
−X ·A
H
·X
T
k
2
.
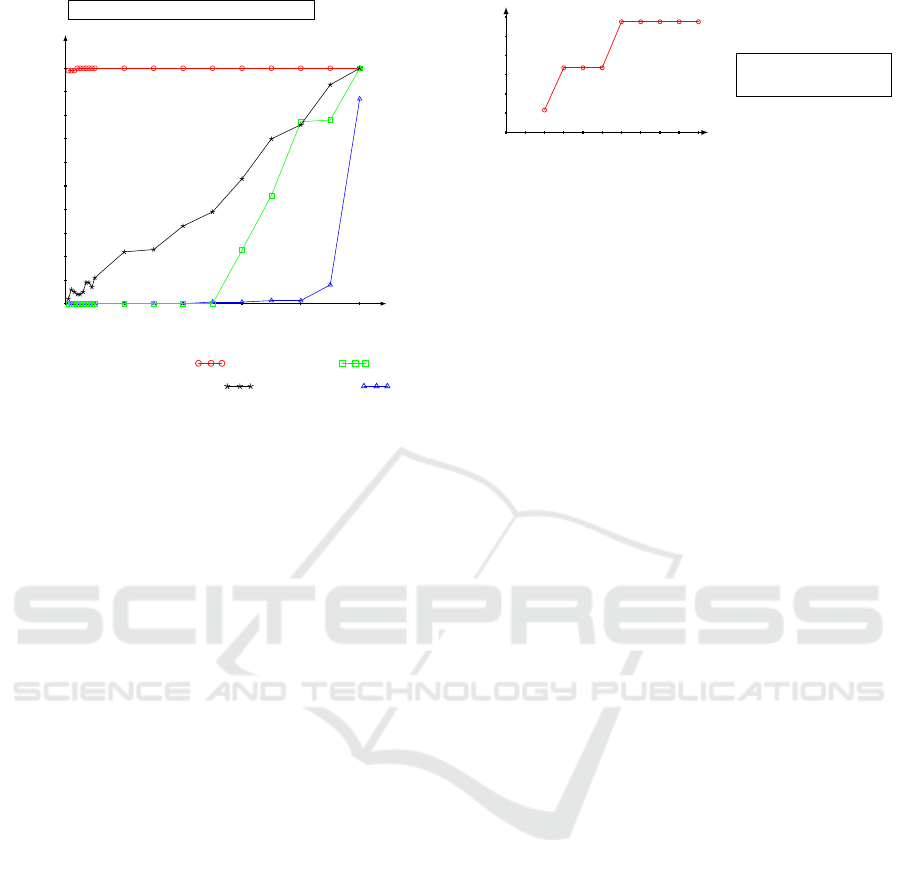
Comparison Between Attacks. We emphasize that
PowerSet and Shadow Nemesis attacks target L2-SSE
while IKK and Count attacks target L1-SSE. We
compare the PowerSet Attack to the previous attacks
with same settings considering the recovered rate of
150 keywords uniformly chosen from the 1 500 most
common keywords. The co-occurrence matrix used
by IKK, Count and Shadow Nemesis attacks is ap-
proached via the sample S known by the adversary.
Figure 2 reveals the gap that exists between L2-SSE
Practical Passive Leakage-abuse Attacks Against Symmetric Searchable Encryption
209
Success Rate
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 20 40
60
80 100
PowerSet vs. IKK/Count/Shadow Nemesis
% of known dataset
PowerSet Attack
IKK Attack
Count Attack
Shadow Nemesis Attack
Figure 2: Most commons keywords recovery rates. Lucene
data set, 1 500 keywords, 150 chosen uniformly.
schemes and L1-SSE schemes which reveal less infor-
mation. Indeed, in spite of auxiliary information and
information from queries used by IKK and Count at-
tacks, Figure 2 shows that L1-SSE schemes are more
resistant to recover client queries. If the adversary
only knows 5% of the data set, our attack can recover
100% of the 150 keywords while the Shadows Neme-
sis Attack recovers only 5% of them and whereas IKK
and Count attacks need to know more than 60% of
data set to recover keywords.
7 COUNTERMEASURES
The countermeasure for the PowerSet Attack is
generic but computationally costly while countermea-
sure for the Co-Mask and the Mask attacks are spe-
cific and computationally efficient.
Countermeasure for the PowerSet Attack. Since
the PowerSet Attack uses information on number of
shared keywords between documents, the idea is to
modify plaintext documents such that there exists at
least α −1 documents having the same keywords for
each document. In this way, when the PowerSet At-
tack is performed, there is at least α different tuples of
identifiers corresponding to the power set computed
from the sample S . Hence, the adversary cannot de-
duce the correct association between plaintext docu-
ments that she knows and their identifiers. To do that,
we are inspired by (Islam et al., 2012). We consider
the database DB as a binary matrix M of size m ·n,
where M
i, j
= 1 if w
i
∈ d
j
and M
i, j
= 0 if w
i
6∈ d
j
.
Since the PowerSet Attack is performed only on the
Cost
0
2
4
6
8
10
12
0 1 2 3 4
5 6
7 8 9 10
Cost of the Power-
Set countermeasure
α values
Figure 3: Cost of the PowerSet countermeasure for different
α values on a sample of 1 000 documents from Commons.
encrypted database and does not require any query,
we modify the matrix M such that for each column
there exist α −1 similar columns. We authorize only
false-positive that is modify a 0 to a 1. Then our aim
is to minimize the number of false-positive, so we use
an algorithm of agglomerative hierarchical clustering
with average distance and the cosine distance as dis-
tance measure (Berkhin, 2006). When each cluster
have at least α documents, if there is at least one col-
umn having 1 to its j-th then we put 1 into the j-th row
of all columns of the cluster. This countermeasure
preserves the size of the original database at the cost
of false-positives. As in (Islam et al., 2012), we de-
fine cost as the ratio of number of documents returned
by the new encrypted database (denoted by q) to the
number of documents returned by the old encrypted
database (denoted by p). That is cost = (q − p)/p.
Fig. 3 shows the evolution of the cost of the coun-
termeasure for different α values when the presented
countermeasure is performed on a sample of 1 000
documents from the data set Commons. The stages of
the cost are explained by the number of documents in
each cluster. In fact, when α = 3, each cluster have
already 5 documents, hence clusters do not change
when α changes from 3 to 5.
Countermeasure for the Co-Mask Attack. The Co-
Mask Attack targets L3-SSE. These schemes leak
the order of keywords first appearance. Assume we
want to keep the relative order of keywords in doc-
uments to allow the scheme to sort replies from the
server in function of the queried keyword position.
As the countermeasure for the PowerSet Attack, we
authorize false positives. The idea is to add a key-
word of W which is not in the initial document. Its
position is randomly chosen when the client builds
the encrypted database. Hence, an adversary know-
ing this countermeasure and a sample S of plain doc-
uments has on one hand a low probability to choose
the same keyword, and on the other hand has a low
probability to choose the same position. This coun-
termeasure decreases the chance to have a match be-
tween comask computed by the adversary from S and
those which are computeddirectly from the encrypted
SECRYPT 2017 - 14th International Conference on Security and Cryptography
210

database. Moreover, we only add one false positive
by document.
Countermeasure for the Mask Attack. The Mask
Attack targets L4-SSE schemes. Assume we want
to keep information on occurrence and order of key-
words for the same reason as above. Again, we au-
thorize false positives. Hence we can add a random
keyword at a random position in each document. In
this way, the mask of the original document does not
correspond to those of the new document. Moreover,
if the adversary tries to find the correct identifier of
a document in the encrypted database, it has a low
probability to find the added keyword and its posi-
tion. A possible alternative to not add false positive
is to choose the added keyword among those of the
original document. This increases the chance for the
adversary to guess the added keyword.
8 CONCLUSION
Prior work (Zhang et al., 2016) taught us that SSE
schemes have no hope of being secure in a setting
where the adversary can inject chosen files. Addition-
ally, (Cash et al., 2015; Islam et al., 2012; Pouliot and
Wright, 2016) have shown that passive observations
of search tokens reveal the underlying searched key-
word when the data set is fully known. This paper
focuses on passive attacks of L4, L3 and L2 schemes
currently used as commercially solutions, e.g. Ci-
pherCloud. The most glaring conclusion is that our
attacks are devastating and have a real impact on the
protected data in the cloud: regardless of the leak-
age profile, knowing a mere 1% of the document sets
translates into over 90% of documents whose content
is revealed over 70%. Moreover, having same knowl-
edge from the data set, we show that we recover same
rate of keywords whether it is with L4- or with L3-
SSE schemes. We show too that the gap of security
that exists between L2- and L1-SSE schemes is impor-
tant since L1 attacks need to know a large amount of
information to recover frequent keywords contrary to
our L2 attack. Our results give a better understanding
of the practical security of SSE schemes and hope-
fully will help practitioners make more secure SSE
schemes. Future work may deal with countermea-
sures in depth and with the study of the degradation
from L1 to L2 in the presence of queries.
ACKNOWLEDGEMENTS
This research was conducted with the support of the
FEDER program of 2014-2020, the region council of
Auvergne-Rh
ˆ
one-Alpes, the Indo-French Centre for
the Promotion of Advanced Research (IFCPAR) and
the Center Franco-Indien Pour La Promotion De La
Recherche Avanc
´
ee (CEFIPRA) through the project
DST/CNRS 2015-03 under DST-INRIA-CNRS Tar-
geted Programme.
REFERENCES
Berkhin, P. (2006). A Survey of Clustering Data Mining
Techniques.
Cash, D., Grubbs, P., Perry, J., and Ristenpart, T. (2015).
Leakage-Abuse Attacks Against Searchable Encryp-
tion. In CCS 2015, New York, NY, USA. ACM.
Cash, D., Jaeger, J., Jarecki, S., Jutla, C. S., Krawczyk, H.,
Rosu, M., and Steiner, M. (2014). Dynamic search-
able encryption in very-large databases: Data struc-
tures and implementation. In NDSS 2014.
Cash, D., Jarecki, S., Jutla, C. S., Krawczyk, H., Rosu,
M., and Steiner, M. (2013). Highly-Scalable Search-
able Symmetric Encryption with Support for Boolean
Queries. In CRYPTO 2013.
Curtmola, R., Garay, J. A., Kamara, S., and Ostrovsky, R.
(2006). Searchable symmetric encryption: improved
definitions and efficient constructions. In CCS 2006.
Faber, S., Jarecki, S., Krawczyk, H., Nguyen, Q., Rosu, M.,
and Steiner, M. (2015). Rich Queries on Encrypted
Data: Beyond Exact Matches. In ESORICS 2015.
Goldreich, O. (1998). Secure Multi-party Computation.
Working Draft.
He, W., Akhawe, D., Jain, S., Shi, E., and Song, D. (2014).
ShadowCrypt: Encrypted Web Applications for Ev-
eryone. In CCS 2014.
Islam, M. S., Kuzu, M., and Kantarcioglu, M. (2012).
Access Pattern disclosure on Searchable Encryption:
Ramification, Attack and Mitigation. In NDSS 2012.
Kamara, S., Papamanthou, C., and Roeder, T. (2012). Dy-
namic Searchable Symmetric Encryption. In CCS
2012.
Lau, B., Chung, S., Song, C., Jang, Y., Lee, W., and
Boldyreva, A. (2014). Mimesis Aegis: A Mimicry
Privacy Shield–A System’s Approach to Data Privacy
on Public Cloud. In USENIX Security 2014.
Porter, M. F. (1980). An algorithm for suffix striping. Pro-
gram.
Pouliot, D. and Wright, C. V. (2016). The Shadow Neme-
sis: Inference Attacks on Efficiently Deployable, Effi-
ciently Searchable Encryption. In CCS 2016.
Song, D. X., Wagner, D., and Perrig, A. (2000). Practical
Techniques for Searches on Encrypted Data. In SP
2000. IEEE Computer Society.
Zhang, Y., Katz, J., and Papamanthou, C. (2016). All
Your Queries Are Belong to Us: The Power of File-
Injection Attacks on Searchable Encryption. Cryptol-
ogy ePrint Archive, Report 2016/172.
Practical Passive Leakage-abuse Attacks Against Symmetric Searchable Encryption
211
