
Managing and Unifying Heterogeneous Resources in Cloud
Environments
Dapeng Dong, Paul Stack, Huanhuan Xiong and John P. Morrison
Boole Centre for Research in Informatics, University College Cork, Western Road, Cork, Ireland
Keywords:
Architecture, Heterogeneous Resource, Platform Integration, Cloud, HPC.
Abstract:
A mechanism for accessing heterogeneous resources through the integration of various cloud management
platforms is presented. In this scheme, hardware resources are offered using virtualization, containerization
and as bare metal. Traditional management frameworks for managing these offerings are employed and in-
voked using a novel resource coordinator. This coordinator also provides an interface for cloud consumers to
deploy applications on the underlying heterogeneous resources. The realization of this scheme in the context
of the CloudLightning project is presented and a demonstrative use case is given to illustrate the applicability
of the proposed solution.
1 INTRODUCTION
Cloud computing is maturing and evolving at pace.
This evolution is mainly driven by consumer needs
and technological advancement. Recently, there has
been increasing demand to support High Performance
Computing (HPC) applications, such as weather fore-
cast (Krishnan et al., 2014), medical imaging (Serrano
et al., 2014), and fluid simulation (Zaspel and Griebel,
2011). These application have traditionally been con-
fined in clustering environments. To effectively sup-
port these applications and to demonstrate compara-
ble performances in the cloud, specialized hardware
and networking configurations are required. These re-
quirements pose challenges for effectively integrating
and efficiently managing a wide variety of heteroge-
neous resources in clouds.
Currently, several frameworks and platforms ex-
ist for managing virtualized environments (such
as, OpenStack Nova (Nova, 2016)), container
environments (such as, Kubernetes (Kubernetes,
2016), Mesos (Hindman et al., 2011), and Docker
Swarm (Docker Swarm, 2016)), containers in vir-
tualized environments (such as, OpenStack Mag-
num (Magnum, 2016)), bare metal servers (such
as, OpenStack Ironic (Ironic, 2016)), and traditional
cluster management frameworks for High Perfor-
mance Computing and High Throughput Computing
(HPC/HTC) workloads. These frameworks and plat-
forms have sufficiently matured and/or have begun
to find practical applications in many public and pri-
vate clouds. However, in general, current data center
deployment focuses on managing homogeneous re-
sources through a single resource abstraction method.
The scale and diversity of HPC application migrating
to the cloud dictates that multiple resource abstrac-
tion methods should be simultaneously available in a
single cloud deployment.
In this paper, a number of generically applica-
ble techniques are introduced to address the man-
agement challenges associated with the evolution of
the current homogeneous cloud infrastructure into
the heterogeneous cloud infrastructure required to
support HPC applications. We present a unified
platform for managing heterogeneous hardware re-
sources including general purpose Central Processing
Units (CPUs), high performance GPUs, and special-
ized computation units, for example, Many Integrated
Cores (MICs) and Data Flow Engines (DFEs), as
well as cluster computing environments such as High
Performance Computing, High Throughput Comput-
ing (HPC/HTC), and Non-uniform Memory Access
(NUMA) machines, these techniques have been in-
vestigated and applied in the context of the Cloud-
Lightning project (Lynn et al., 2016).
The following explores some relevant related
work and present mechanisms that abstract the un-
derlying virtualization methodologies and exploits
each appropriately to support the diverse ecosystem
of HPC applications hosted on heterogeneous hard-
ware resources. Subsequently, the realization of these
mechanisms in the context of the CloudLightning
Dong, D., Stack, P., Xiong, H. and Morrison, J.
Managing and Unifying Heterogeneous Resources in Cloud Environments.
DOI: 10.5220/0006300901430150
In Proceedings of the 7th International Conference on Cloud Computing and Services Science (CLOSER 2017), pages 115-122
ISBN: 978-989-758-243-1
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
115

project(Lynn et al., 2016) is described. and a demon-
strative use case application is given to illustrate the
applicability of the proposed solution. Finally, some
conclusions are drawn.
2 RELATED WORK
The rapid adoption of cloud computing in both public
and private sectors is resulting in hyper-scale cloud
deployment. This trend poses challenges to cloud
management and cloud architecture design. Exist-
ing cloud platforms regardless whether they make use
of virtualization, containerization or bare metal offer-
ings all focus on the management of homogeneous
resources with respect to the desirable non-functional
requirements, for example, scalability and elasticity.
Google Borg (Verma et al., 2015) is a platform for
managing large-scale bare metal environments used
by Google, internally. Borg manages tens of thou-
sands of servers simultaneously. The Borg architec-
ture consists of three main component types: Borg
masters, job schedulers, and Borglet agents. A typ-
ical Borg instance consists of a single Borg master,
a single job scheduler and multiple Borglet agents.
The Borg master is the central point for managing
and scheduling jobs and requests. A Borg master
and job scheduler are replicated in several copies
for high-availability purpose, however, only a single
Borg master and a single job scheduler are active at
one time. This centralized management approach re-
quires Borg masters and job schedulers (the origi-
nal and all the replicas) to be large enough to scale
out as required. The Borg job scheduler may poten-
tially manage a very high volume of jobs at simulta-
neously, this has made Borg more suitable for long-
running services and batch jobs, since that those job
profiles reduce the loads on the job scheduler. In con-
trast, Fuxi (Zhang et al., 2014) platform from Alibaba
Inc., uses a similar monolithic scheduling approach,
but with incremental communication and locality tree
mechanisms that support rapid decision making.
More contemporary systems are becoming dis-
tributed to address the scalability issue, nevertheless,
masters continue to retain their centralized manage-
ment approach. In contrast, job schedulers are be-
coming ever more decentralized in their management
decisions. This decentralized approach sometimes re-
sults in scheduling conflicts, however, the probabil-
ity of this happening is low. Examples of these sys-
tems include Google Omega (Schwarzkopf et al.,
2013) and Microsoft Apollo (Boutin et al., 2014).
Google Omega employs multiple schedulers work-
ing in parallel to speed up resource allocation and
job scheduling. Since there is no explicit commu-
nication between these schedulers, it cannot be said
that this approach improves resource allocation and
job scheduling decisions, rather it increases the num-
ber of such decisions being made per unit time. Mi-
crosoft Apollo (Boutin et al., 2014) employs a simi-
lar scheduling framework. But it is also incorporates
global knowledge that can be used by each sched-
uler to make optimistic scheduling decisions. Apollo
enables each scheduler to reason about future re-
source availability and implement a deferred correc-
tion mechanism to optimistically defer any correc-
tions until after tasks are dispatched. Identified po-
tential conflicts may not be realized in some situations
since the global knowledge is by definition imperfect.
Consequently, all other thing being equal, by delay-
ing conflict resolution to the latest possible opportu-
nity, at which time they may disappear, Apollo may
perform better than Google Omega. Google Borg,
Google Omega and Microsoft Apollo work with bare
metal servers and schedule jobs onto physical nodes.
In contrast, Kubernetes, Mesos and OpenStack at-
tempt to improve resource utilization by introducing
containerization and virtualization.
Kubernetes (Kubernetes, 2016)(Burns et al.,
2016) is another Google technology and an evolu-
tion of Google Omega. In the Kubernetes system,
schedulers cooperate in making scheduling decisions
and hence attempt to improve resource allocation.
This cooperation comes at the cost of sharing the en-
tire cluster’s status information, whereas, conflicting
scheduling decisions can be avoided, this comes at the
cost of dynamically making the distributed schedul-
ing decisions. Kubernetes is designed to work exclu-
sively with containers as a resource management tech-
nology. It improves service deployment and resource
management in a complex distributed container envi-
ronment.
Apache Mesos (Hindman et al., 2011) is another
management platform which enables multiple differ-
ent scheduling frameworks to manage the same envi-
ronment. This is achieved by employing a coordinator
service assigning resources controls to a single sched-
uler during its decision making processes. This can
potentially lead to an inefficient use of resources when
the request is lightweight and available resources are
significantly large.
OpenStack (Nova, 2016) is an open-source cloud
platform focusing on the management of a virtualiza-
tion environment. OpenStack uses a front-end API
server to receive requests and a centralized coordi-
nator service (nova-conductor) for coordinating var-
ious components (e.g., networking, image, storage,
and compute). The nova-conductor uses a scheduler
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
116

service (nova-scheduler) to find physical server(s) for
deploying virtual machine(s) based on the configura-
tions specified in the user requests (iterative filter) and
together with weight of each of the available physical
server in the cloud. Multiple conductors and multi-
ple scheduler may be created in a OpenStack environ-
ment, these components working a partition domains,
hence conflicts cannot rise.
3 HETEROGENEOUS
RESOURCE INTEGRATION
Different resource hardware types require appropriate
resource management techniques. A goal of this pa-
per is to support resource heterogeneity in pursuit of
HPC in the cloud. A consequence of this goal is the
need to realize a mechanism for integration hetero-
geneous resources and their respectively management
techniques in a single unified scheme. An overview
of the proposed scheme is shown in Figure 1.
In this scheme, hardware resources are virtually
partitioned based on the abstraction methods (vir-
tualization, containerization, bare metal, and shared
queues) most appropriate for the respective hardware
type. A corresponding management framework is
then adopted to manage groups of hardware of the
same type. A central Resource Coordinator compo-
nent is provided as an interface to be used by cloud
consumers to deploy applications on the underlining
resources. More importantly, the Resource Coordina-
tor component coordinates the deployment for cloud
application components on, potentially, various types
of resources across those virtual partitions.
3.1 Service Delivery Work-flow
To fully exploit the benefits offered by these versatile
service and resource options. It is necessary to care-
fully manage the resources used in providing them.
This can be challenging for both the service provider
and for the service consumer, especially when the
components of a cloud application may require to
be deployed on different types of resource. More-
over, leaving aside the difficulties of working with
those heterogeneous hardware environment, to fully
exploit these hardware resources and accelerators, ex-
pert knowledge related to the deployment of cloud ap-
plication components is usually also required. How-
ever, this configuration complexity and deep domain-
specific knowledge should be made transparent to
consumers. The approach is to allow consumers to
compose their tasks into a work-flow of its constituent
service(s). Work-flows of this kind are often referred
to as blueprints.
A cloud application blueprint can be designed us-
ing graphical interfaces. An entity in a blueprint
presents a functional component of the cloud applica-
tion and its associated resources and necessary con-
figurations; connections indicate the communication
channels between components.
A cloud application blueprint is firstly submit-
ted to a Resource Coordinator. Many Resource Co-
ordinators may potentially work in parallel to load-
balance requests arriving at high frequency. Each
cloud application blueprint is processed by a single
Resource Coordinator. The Resource Coordinator de-
composes the blueprint into groups of resource re-
quests depending on the resource abstraction types.
For example, a complex blueprint, requiring coordi-
nating across different management platforms, may
describe an application that requires front-end web
servers to collect data which is subsequently pro-
cessed using accelerators, thus, the resources required
for this blueprint deployment may be a set of vir-
tual machines running on CPUs managed by Open-
Stack, for example, and a set of containers running
on servers having Xeon Phi co-processors and man-
aged by Mesos. After the blueprint decomposition
process, the Resource Coordinator analyses the re-
lationships between the groups of resource requests
and makes further amendments to the blueprint to re-
alize the communications between blueprint compo-
nents that will be deployed across virtual resource
partitions. The Resource Coordinator then forwards
each group of resource requests to designated virtual
resource partitions that are managed by correspond-
ing management platforms.
3.2 Platform Integration
Heterogeneous hardware resources are managed
through various frameworks and platforms. This may
raise interoperability issues, however, as each plat-
form manages a virtual partition of the resources, in
the same management domain, the resulting interop-
erability issues reduced to a technical integration ac-
tion and are not exacerbated by having to consider
the interests of multiple entities. Figure 1 shows
how the integration scheme may use OpenStack
Nova (Nova, 2016) to manage virtual machines, may
use Kubernetes (Kubernetes, 2016), Mesos (Hindman
et al., 2011), and/or Docker Swarm (Docker Swarm,
2016) to manage containers, and may use OpenStack
Ironic (Ironic, 2016) to manage bare metal servers.
Each platform offers a different set of Application
Programming Interfaces (APIs) and utilities for sim-
Managing and Unifying Heterogeneous Resources in Cloud Environments
117
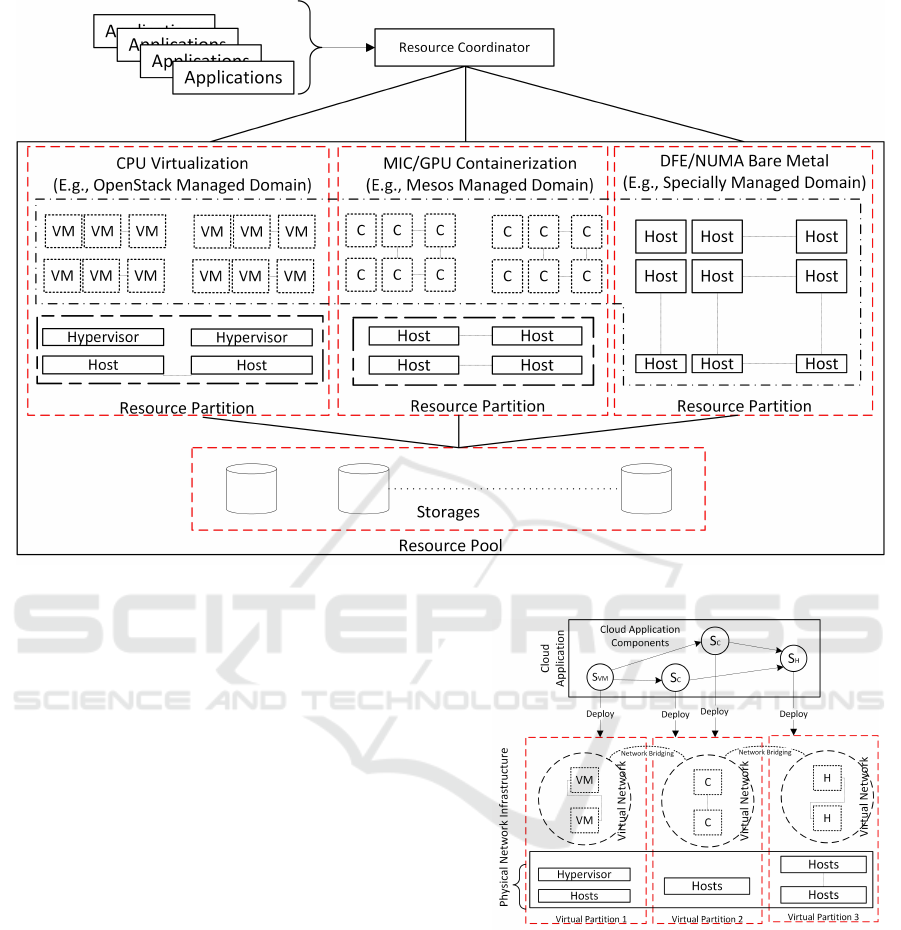
Figure 1: Managing and accommodating heterogeneous hardware resources through multiple integrated platforms.
ilar resource management operations, such as, creat-
ing virtual machines and/or containers. The Resource
Coordinator uses a Plug & Play Interface that defines
a set of common operations for managing underly-
ing resources, and these operations are then translated
to platform-specific API calls or commands using the
Plug & Play implementation modules to carry out ser-
vice deployment processes. Additionally, storage sys-
tems are organized and managed independently. Pro-
cessing units can be easily configured to use volume-
based and/or flat storage systems.
3.3 Networking Integration Strategy
Two schemes are available for networking integra-
tion. The first scheme is to treat networking in each
virtual partition independently as shown in Figure 2.
Cloud application components are deployed indepen-
dently in their corresponding virtual partition and vir-
tual networks are created accordingly within each vir-
tual partition. After the independent cloud application
components deployment, network bridges are created
in order to establish communication channels across
virtual partitions. The scheme does not require any
modification to the respective resource management
frameworks. This gives the flexibility of integrating
other resource management frameworks, for example,
Kubernetes and Docker Swarms. The concerns about
Figure 2: Networking integration scheme 1.
this scheme arise from the differences associated with
each of the networking approaches taken by each of
the the respective resource management frameworks.
Considering that different platforms offer different
type of network services at various level, for example,
an OpenStack managed network often uses the Neu-
tron framework, which offers rich functionalities in-
cluding firewalls, load-balancers, etc., these may not
be available in the container environment if it is man-
aged by Mesos.
The second scheme employs the Neutron frame-
work (OpenStack Neutron, ) for building and manag-
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
118
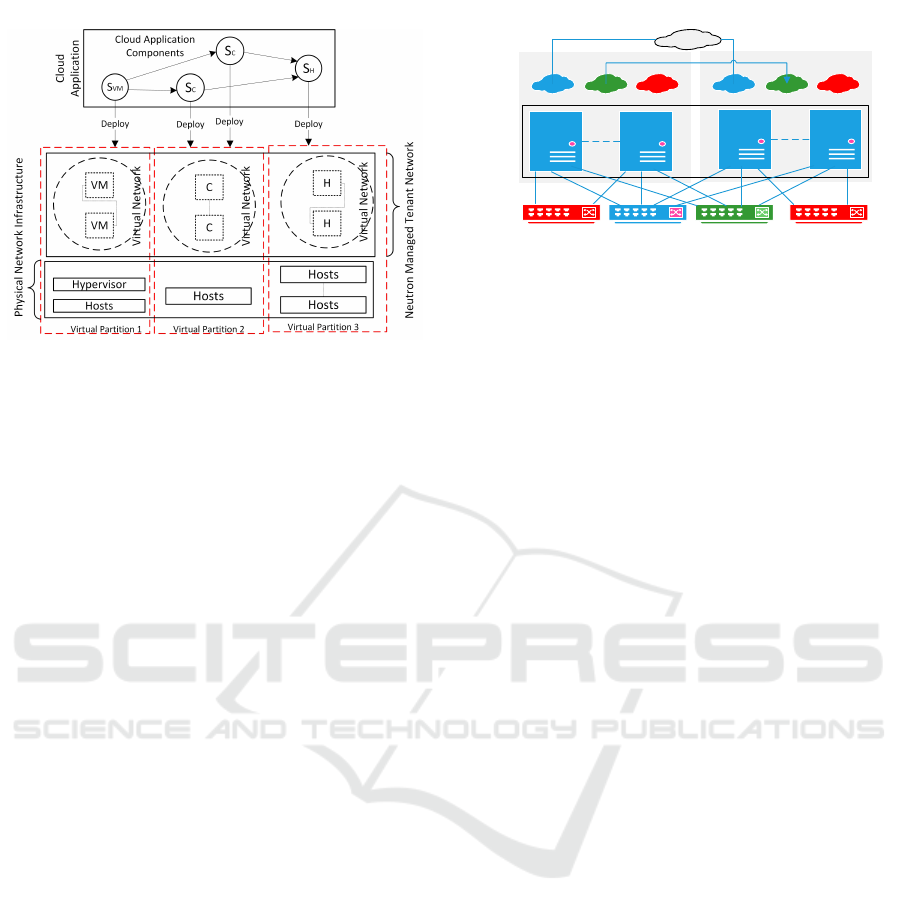
Figure 3: Networking integration scheme 2.
ing virtual network infrastructure. Figure 3 shows the
simplified networking plan. All hardware resources
are connected to the same networking infrastructure,
but logically, they are managed by corresponding
platforms independently. From a consumers perspec-
tive, all resources are in a single resource pool. In the
case that multiple components of a single cloud appli-
cation need to be deployed on both virtual machines
and containers which are managed by different plat-
forms, this requires a dedicated virtual network for the
cloud application over the tenant network. Thus, there
is a need for a unified virtual network infrastructure
management component across all platforms horizon-
tally. In addition, the tenant networks must be man-
aged in a seamless fashion. The second networking
planning scheme adopts OpenStack Neutron for this
purpose. In general, frameworks and services devel-
oped under the OpenStack Big Tent Governance na-
tively support Neutron services. In contrast, container
technologies such as Kubernetes, Mesos, and Docker
Swarm employ different networking models. For ex-
ample, Kubernetes can use Flannel (Flannel, 2016),
Weave Net (WeaveNet, 2016) frameworks operating
in various modes; Docker uses libnetwork (Libnet-
work, 2016) by default. In the context of this work,
the Kuryr network driver (Kuryr, 2016) is employed
to link Neutron and container networks. Thus, con-
sumers of clouds will experience seamless connec-
tions between all types of heterogeneous hardware re-
sources.
4 EMPIRICAL STUDY
The initial implementation and the deployment of the
proposed scheme has been realized in the context of
CloudLightning project (Lynn et al., 2016)[change
to link]. To cover a wide range different types
Internet Domain Bridge Private
Private Net
OpenStack Manage
Virtualization Environment
Bridge NetPublic Net
Private Net
Bridge NetPublic Net
Internet
Mesos Managed Docker
Containerization Environment
Private
Figure 4: Testbed configuration.
of HPC applications in clouds, the CloudLightning
project concentrate on three dispirit use cases: Oil
& Gas simulation, Genomic Processing, and Ray-
Tracing. In the following experiment, the thrird
use case based on the Intel’s Ray-Tracing applica-
tion (Embree, 2016) is used to demonstrate the need
for a unified platform to manage a cloud environment
composed of heterogeneous resources.
4.1 Testbed Configuration
The experimental environment consists of an Open-
Stack managed virtualization environment (Newton
release) which consists of eight Dell C6145 compute
servers in total having 384 cores, 1.4TB RAM, 12TB
storage and a Mesos managed Docker containeriza-
tion environment (v1.1.0) which consists of five IBM
326e servers in total having 10 cores, 40GB RAM,
200GB storage. In this deployment configuration,
all physical servers have multiple dedicated network
connections to three different networks including a
public, a private and a bridge network. The public
network connects to the Internet, the private networks
are private to OpenStack or Mesos, the bridge net-
work provides interconnections between virtual ma-
chines (managed by OpenStack) and containers (man-
aged by Mesos). In the context of OpenStack, the pri-
vate network is equivalent to the Neutron Tenant net-
work, the public and bridge networks are the Neutron
Provider networks. In the Mesos managed Docker
environment, three Docker Bridge networks are cre-
ated with each connecting to the public, private and
bridge network respectively. This deployment con-
figuration is flexible to allow for future platforms, if
needed, to be integrated with the existing environ-
ments.
4.2 Use Case Blueprint
The Intel’s Ray-Tracing application use case is com-
posed of two parts, one is the Ray-Tracing engine
and two is a Web interface. Both the engine and
Managing and Unifying Heterogeneous Resources in Cloud Environments
119
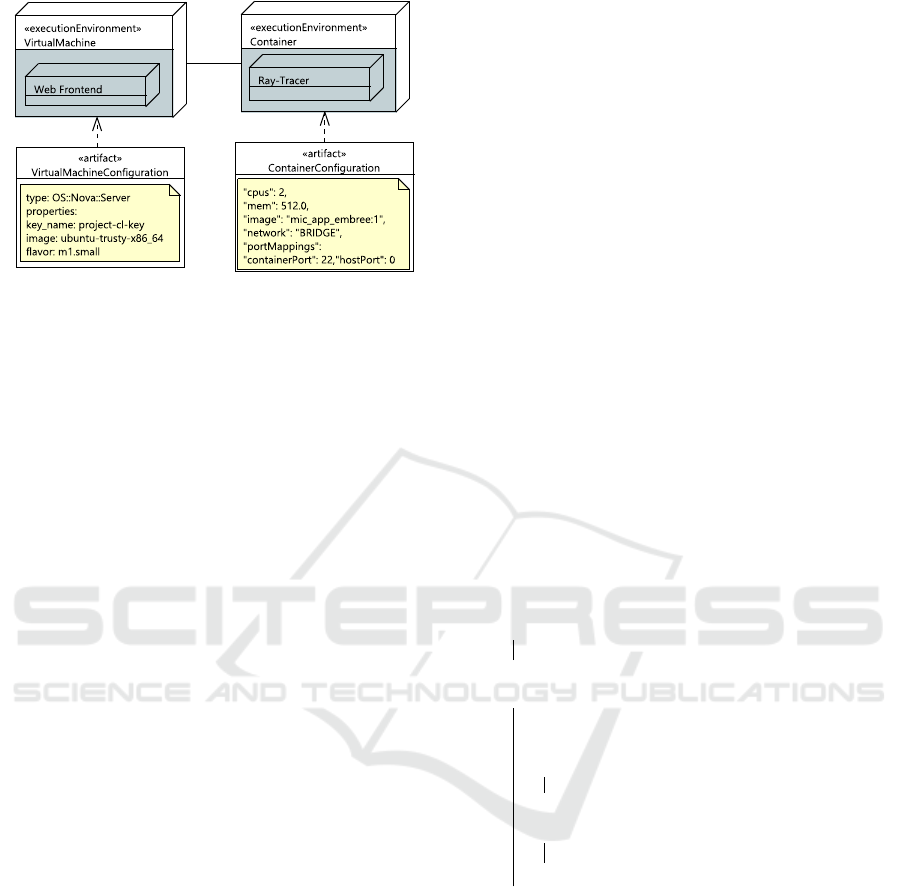
Figure 5: Ray-Tracer use case blueprint.
the Web interfaces should be respectively deployed
on the most appropriate back-end resources includ-
ing virtual machines and containers with access to
hardware accelerators, such as Intel Multiple Inte-
grate Core (MIC). In this experiment, a blueprint is
constructed which specifies that the Web interface
should be deployed on virtual machines and the Ray-
Tracing engine should be deployed in a container.
In particular, it has been demonstrated that the Ray-
Tracing application can gain better performance when
run on MICs (Benthin et al., 2012) (Wald, 2012),
which in general requires containerization or bare
metal servers.
A graphical representation of the use case
blueprint is shown in Figure 5. This blueprint is ex-
pressed using XML. A blueprint consists of four main
components: (1) Execution Environments, specifying
the resource types such as virtual machines, contain-
ers, bare metal, and so on. (2) The Cloud Application,
detailing the software component(s) to be deployed
in an Execution Environment. (3) Artifacts, contain-
ing configurations for each Execution Environment or
cloud application components. (4) Connections, spec-
ifying the connectivity between Execution Environ-
ments.
In the CloudLightning environment, there is a
clear separation of concerns between the cloud appli-
cation description and the resources on which that ap-
plication will eventually run. The CloudLightning en-
vironment uses a SOSM engine to dynamically deter-
mine the most appropriate resources available at that
time within the cloud resource fabric to host a particu-
lar application. These resources are dynamically writ-
ten into the application blueprint once they have been
discovered and a deployment engine subsequently de-
ploys the application component onto those resources
as required. In the CloudLightning system a number
of components including the SOSM engine together
act as the Resource Coordinator.
The Resource Coordinator is responsible for pars-
ing, decomposing and transforming blueprint compo-
nents to a format, that can be understood by the under-
lying cloud management platforms, to facilitate appli-
cation deployment.
The Resource Coordinator categorizes Execution
Environments in to groups based on resource types
(EE-Group), such as virtual machines, containers, or
bare metal. Within each EE-Group, Execution En-
vironments will be further partitioned into separate
groups based on connectivities (C-Group), for ex-
ample, if another given blueprint consists of three
virtual machines without specifying connections be-
tween them, then this blueprint will be partitioned
into one EE-Group and three C-Group within that EE-
Group. In the use case scenario described there, there
are two EE-groups, and one C-Group within each EE-
Group. This grouping can be determined by formu-
lating the blueprint topology into a graph G(V, E) by
identifying connectivities using the Union-Find algo-
rithm as illustrated in Algorithm 1. Where V indicates
the vertices in the graph corresponding to the execu-
tion environments in the blueprint, and E denotes the
edges in the graph corresponding to the connections
between Execution Environments.
Data: G(V, E)
Result: List{C-Group{v}}
for v
i
⊆ V in G do
new C-Group
i
{v
i
}
end
foreach Edge e(v
i
, v
j
) : E do
C-Group
i
= find(e.v
i
);
C-Group
j
= find(e.v
j
);
if C-Group
i
== C-Group
j
then
continue;
end
else
union(C-Group
i
, C-Group
j
)
end
end
Algorithm 1: Blueprint execution environment
grouping using Union-Find.
The algorithm assumes the connections are sym-
metric (if Execution Environment A is connected to
Execution Environment B, then B is connected to A)
and transitive (if Execution Environment A is con-
nected to B, B is connected to C, then A is connected
to C). Additional constraints can be added to make
blueprint connections asymmetric and non-transitive.
When the grouping process is completed, the Re-
source Coordinator seeks connections between C-
Groups across EE-Groups. A connection indicates the
Execution Environments from both C-Groups should
be placed in the bridge network or need to be at-
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
120

blueprint-id: c97e718674c34adf815316ad4cec93cf
heat_template_version: 2016-10-14
resources:
embree_web_frontend:
type: OS::Nova::Server
properties:
image: Ubuntu14.04_LTS_svr_x86_64
flavor: m1.small
key_name: cl-project
networks:
- network: bridge-provider
user_data:
template: |
#!/bin/bash -v
apt -y install httpd
......
Figure 6: Web Frontend in OpenStack managed virtual ma-
chines.
{"blueprint-id" : "c97e718674c34adf815316ad4cec93cf",
curl -X POST -H "Content-type: application/json"
marathon:8080/v2/apps -d ’{
"id" : "embree",
"cpus" : 2,
"mem" : 512.0,
"container" : {
"type" : "DOCKER",
"docker": {
"image" : "mic-app-embree:1",
"network": "BRIDGE",
"portMappings":[{"containerPort":22,"hostPort":0}]
} } }’ }
Figure 7: Ray-Tracer in Mesos managed Docker containers
using Marathon.
tached to the bridge network, to establish cross plat-
form communications. Execution Environments from
completely isolated C-Groups should be placed in a
private network, if Internet access is desired, then
each Execution Environment must be attached to the
public network, independently.
Once the networks are identified, Execution Envi-
ronments with their corresponding configurations in
each EE-Group will be transformed into deployment
templates that are compatible with the correspond-
ing management platforms. The snapshot of the de-
ployment templates of the Ray-tracing application are
shown in Figure 6 and 7. The Resource Coordina-
tor initiates the deployment process and subsequently
manages the life-cycle of the blueprint.
5 CONCLUSIONS
In this work, mechanisms are introduced for pro-
visioning heterogeneous resources through the inte-
gration of various existing platforms in which each
platform manages a set of homogeneous hardware
resources independently. Globally, all types of re-
sources are virtually presented in a unified resource
pool to consumers. It is must be noted that, in some
circumstances, for example, an orchestrated service
that has been deployed on various types of resources
across different platforms, may encounter network
congestion issues. Additionally, as each management
platforms (e.g., OpenStack and Mesos) have their
built-in resource schedulers, the proposed schemes
are limited in how they control and optimize re-
sources at a coarse-grained level. To this end, a uni-
fied cloud platform that can natively support hetero-
geneous hardware is needed. The CloudLightning
project is attempting to provide initial solutions to this
challenge. This sets the directions for the future work.
ACKNOWLEDGEMENT
This work is funded by the European Unions Horizon
2020 Research and Innovation Programme through
the CloudLightning project under Grant Agreement
Number 643946.
REFERENCES
Benthin, C., Wald, I., Woop, S., Ernst, M., and Mark, W. R.
(2012). Combining single and packet-ray tracing for
arbitrary ray distributions on the intel mic architec-
ture. IEEE Transactions on Visualization and Com-
puter Graphics, 18(9):1438–1448.
Boutin, E., Ekanayake, J., Lin, W., Shi, B., Zhou, J., Qian,
Z., Wu, M., and Zhou, L. (2014). Apollo: Scal-
able and coordinated scheduling for cloud-scale com-
puting. In Proceedings of the 11th USENIX Confer-
ence on Operating Systems Design and Implementa-
tion, OSDI’14, pages 285–300, Berkeley, CA, USA.
USENIX Association.
Burns, B., Grant, B., Oppenheimer, D., Brewer, E., and
Wilkes, J. (2016). Borg, omega, and kubernetes. Com-
mun. ACM, 59(5):50–57.
Docker Swarm (2016). https://github.com/docker/
swarm. [Accessed on 15-June-2016].
Embree, I. (2016). https://embree.github.io. [Ac-
cessed on 05-December-2016].
Flannel (2016). https://github.com/coreos/flannel#
flannel. [Accessed on 16-June-2016].
Hindman, B., Konwinski, A., Zaharia, M., Ghodsi, A.,
Joseph, A. D., Katz, R., Shenker, S., and Stoica, I.
(2011). Mesos: A platform for fine-grained resource
sharing in the data center. In Proceedings of the
8th USENIX Conference on Networked Systems De-
sign and Implementation, NSDI’11, pages 295–308,
Berkeley, CA, USA. USENIX Association.
Managing and Unifying Heterogeneous Resources in Cloud Environments
121

Ironic, O. (2016). http://docs.openstack.org/
developer/ironic/deploy/user-guide.html.
[Accessed on 14-June-2016].
Krishnan, S. P. T., Krishnan, S. P. T., Veeravalli, B., Kr-
ishna, V. H., and Sheng, W. C. (2014). Perfor-
mance characterisation and evaluation of wrf model
on cloud and hpc architectures. In High Perfor-
mance Computing and Communications, 2014 IEEE
6th Intl Symp on Cyberspace Safety and Security,
2014 IEEE 11th Intl Conf on Embedded Software and
Syst (HPCC,CSS,ICESS), 2014 IEEE Intl Conf on,
pages 1280–1287.
Kubernetes (2016). http://kubernetes.io/. [Accessed
on 14-June-2016].
Kuryr (2016). http://docs.openstack.org/
developer/kuryr/. [Accessed on 14-June-2016].
Libnetwork (2016). https://github.com/docker/
libnetwork. [Accessed on 16-June-2016].
Lynn, T., Xiong, H., Dong, D., Momani, B., Gravvanis,
G., Filelis-Papadopoulos, C., Elster, A., Khan, M.
M. Z. M., Tzovaras, D., Giannoutakis, K., Petcu,
D., Neagul, M., Dragon, I., Kuppudayar, P., Natara-
jan, S., McGrath, M., Gaydadjiev, G., Becker, T.,
Gourinovitch, A., Kenny, D., and Morrison, J. (2016).
Cloudlightning: A framework for a self-organising
and self-managing heterogeneous cloud. In Proceed-
ings of the 6th International Conference on Cloud
Computing and Services Science, pages 333–338.
Magnum, O. (2016). https://github.com/openstack/
magnum. [Accessed on 13-June-2016].
Nova, O. (2016). http://docs.openstack.org/
developer/nova/. [Accessed on 14-June-2016].
OpenStack Neutron. https://github.com/openstack/
neutron. [Accessed on 14-June-2016].
Schwarzkopf, M., Konwinski, A., Abd-El-Malek, M., and
Wilkes, J. (2013). Omega: Flexible, scalable sched-
ulers for large compute clusters. In Proceedings of
the 8th ACM European Conference on Computer Sys-
tems, EuroSys ’13, pages 351–364, New York, NY,
USA. ACM.
Serrano, E., Bermejo, G., Blas, J. G., and Carretero, J.
(2014). Evaluation of the feasibility of making large-
scale x-ray tomography reconstructions on clouds. In
Cluster, Cloud and Grid Computing (CCGrid), 2014
14th IEEE/ACM International Symposium on, pages
748–754.
Verma, A., Pedrosa, L., Korupolu, M., Oppenheimer, D.,
Tune, E., and Wilkes, J. (2015). Large-scale cluster
management at google with borg. In Proceedings of
the Tenth European Conference on Computer Systems,
EuroSys ’15, pages 18:1–18:17, New York, NY, USA.
ACM.
Wald, I. (2012). Fast construction of sah bvhs on the in-
tel many integrated core (mic) architecture. IEEE
Transactions on Visualization and Computer Graph-
ics, 18(1):47–57.
WeaveNet, W. (2016). https://www.weave.works/
docs/net/latest/introducing-weave/. [Ac-
cessed on 16-June-2016].
Zaspel, P. and Griebel, M. (2011). Massively parallel fluid
simulations on amazon’s hpc cloud. In Network Cloud
Computing and Applications (NCCA), 2011 First In-
ternational Symposium on, pages 73–78.
Zhang, Z., Li, C., Tao, Y., Yang, R., Tang, H., and Xu, J.
(2014). Fuxi: A fault-tolerant resource management
and job scheduling system at internet scale. Proc.
VLDB Endow., 7(13):1393–1404.
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
122
