
Rule Generation for Scenario based Decision Support System
on Public Finance Domain
Mesut Çeviker and Özgür Bağlıoğlu
Department of Computer Engineering, Middle East Technical University, Cankaya, Ankara, Turkey
Keywords: Future Prediction, Rule based System, Rule Generation, Public Finance.
Abstract: This study is a part of a larger project called “Ontology Based Decision Support System”. In this document,
we report methodology of the Rule Generation (RG) that is planned to be taken from the knowledge queried
from ontology based Knowledge Extraction System (KES). Rule generation aims producing rules for a rule
based system, which will be used for future prediction of an organization or an organizational unit. The term
“scenario based” implies that the system will do future prediction for possible scenarios of next movements
like different budget scheduling scenarios. Future prediction will be limited to the prediction of parameters
that the organization is willing to know, such as the parameters related to the objectives and the goals on
their strategic plan. In literature, rule generation problems are addressed by variety of different learners; so
what we plan is using a learners system with many learners possibly with different types. The system will be
valuable for merging an ontology based KES and DSS with future prediction capability. In addition, this
will be the first composite system (having mentioned KES+DES) for public finance domain.
1 STAGE OF THE RESEARCH
So far, we made a literature view and architectural
design of the project. We build the public finance
ontology to be used by the KES. In addition, we
mostly decided on the methodology and required
technology to build the system. As the data set, we
chose EU-funded research projects on Community
Research and Development Information Service
(CORDIS) and the EU as the organization. Now we
are working on building the DSS for the projects
completed after 2010, on the evaluation of projects
we are searching the relations between targets and
project contents, and effects of the projects on
complying with the Europe 2020 strategy. Briefly,
doctoral studies are on at the stage of analysing the
pilot organization and realizing the design.
2 OUTLINE OF OBJECTIVES
This study is a part of a larger project called
“ontology based decision support system”. We have
chosen public finance as the pilot domain and the
team includes domain experts as well as other
colleagues working on ontology development and
knowledge extraction. Overall plan of the project is
developing two modules: first, for extracting
knowledge from structured and unstructured data to
feed a rule based decision support system and
second, for the rule based decision support system
making future prediction on both if-then and what-if
type questions. The system is shown in Figure. 1. As
to the benefits of the decision support system (DSS)
the beneficiary organization will be capable of
making future predictions by running simulations.
Therefore, the aim of pilot project is trying different
resource allocation scenarios beforehand and helping
to make the best allocation option for achieving
predetermined strategic goals of the organization. In
general, if such systems are common enough, policy
makers will have tools for Regulatory Impact
Analysis (RGA).
For the what-if type questions, we expect to
propose a generic predicting mechanism with the
ability to make the inferences at a success rate that is
significantly higher than the rate of a RBS with
static rules and significantly close to the answers of
the domain experts.
71
Çeviker M. and Ba
˘
glıo
˘
glu Ö..
Rule Generation for Scenario based Decision Support System on Public Finance Domain.
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)
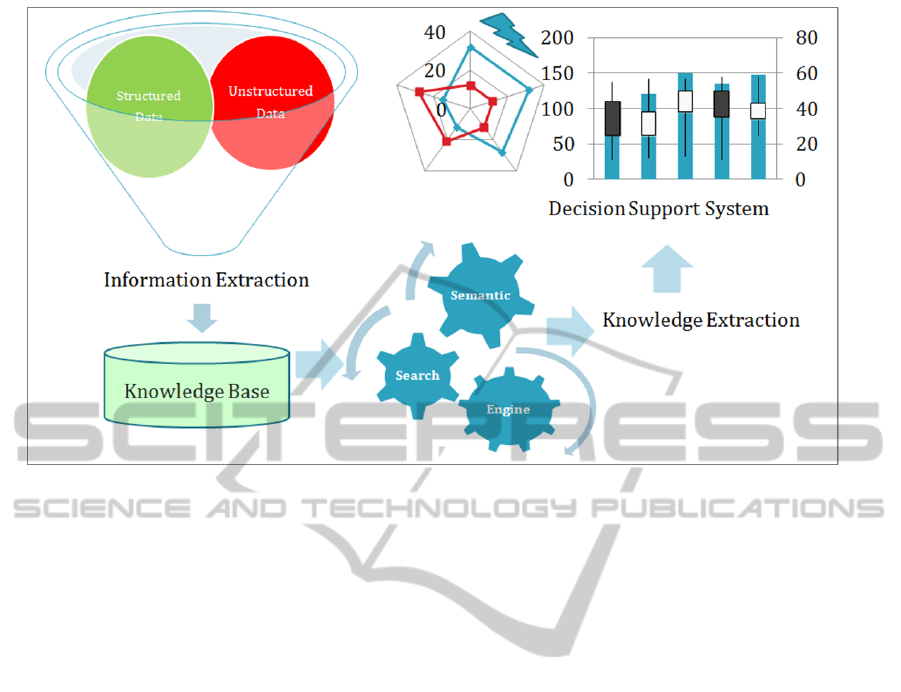
Figure 1: Ontology Based Decision Support System.
3 RESEARCH PROBLEM
Resource allocation for public agencies is a
derivative of portfolio management problem (PMP)
which is central in the modern financial theory. We
can easily define a projection as follows; as the
securities in PMP we have different projects and
programmes in public resource allocation. In PMP,
the target is maximizing the utility of the investor,
while in public resource allocation it is maximizing
the utility function related with the strategic goals
and targets of the organization. Apparently,
problems may be seen as belonging to the same class
but for PMP many financial DSSs have been
proposed and widely used, while for public resource
allocation problem, the tools are limited. Another
research requirement for the domain is estimating
the results of the resource allocations beforehand.
Today the domain experts try to analyse the
outcomes by the help of specific documents and
their experience.
Learning the experience is a main concept in
machine learning and there are constructs like rule
based system (RBS) to store and use the experience.
However, in the problem, a further step that is
predicting the future states of determined parameters
according to the possible moves is still a
challenging. This challenge may be divided into
two: firstly, the possible moves may be unobserved;
secondly making the simulations needs a special
tool, not a standard DSS.
Another subproblem in public resource
allocation is utilizing the structured and unstructured
data automatically. This data includes reports,
articles and documents in any format. Previous
actions, results and analyses are embedded in these
documents and domain experts turn them into
knowledge by manually executing them. Afterwards
they contribute to the finance system by preparing
new documents. The extraction of knowledge in
such an environment can be addressed by ontology
based KESs. For this purpose, parsing the
documents to populate the ontology is another
research challenge.
Our study both includes knowledge extraction
from structured and unstructured data and using the
extracted knowledge in the DSS. Instead of a
conventional DSS, one with making simulations of
possible movement combinations is targeted in the
study. The question that the DSS should answer is
“what is the state of the n
th
target parameter if I
allocate resources in this way? “. For the unobserved
situations we plan to enrich the rule base with the
generated rules.
4 STATE OF THE ART
By a broad approach, decision support systems are
computer-aided systems helping in decision-making
IC3K2014-DoctoralConsortium
72

process, as the name implies (Finlay, 1989). In a
more detailed definition, they have easy-to-use,
interactive interfaces. They are designed especially
for helping in complex management problems by
using the information they store in different formats.
They are expected to be flexible, extendible
information systems (Turban, 1990).
There exist different taxonomies for DSS.
(Power and Sharda, 2009) One choice is classifying
them as model driven and data driven (Dhar and
Stein, 1996). In this study, we plan to use Rule
Based System (RBS), which is an example of model
driven DSS. RBS is a problem solver in a situation-
action manner by formally describing the situation
and the action in if-then rules. RBS builds the
expertise on the fields that need logical reasoning
and practical experience (Buchanan and Duda, 1983)
In literature for prediction problems, time-series
analysis models are commonly used. Time-series
analysis is also helpful in resolving the periodical
behaviours of the independent variables (Shumway
and Stoffer, 2000). However, for unobserved
situation a more advanced predicting mechanism is
needed, such as a rule-based system (Sahoo et al.,
2003). According to the research on prediction (not
primarily on the ‘future prediction’) using RBSs; the
proposed methods analyze past input and output data
of the observations for gathering target output
variables for given input variables. Each set of <
(i
1
,v
1
), (i
2
,v
2
)… (i
n
,v
n
), (o
1
,r
1
), (o
2
,r
2
)… (o
m
,r
m
)>
defines a rule for the system.
For prediction problems where unobserved
situations are expected, researchers also used
Artificial Neural Networks (ANN), Support Vector
Machines (SVM) and similar machine learning
constructs (Min and Lee, 2005) (Khan et al., 2001)
(Han et al., 2006) successfully. However, these
architectures are not so comprehensible; they are
packaged tools answering questions when asked,
while in most cases also reasoning is necessary for
analyzers. To close this gap, in literature, many
methods were introduced for rule extraction by/from
ANNs, SVMs and similar machine learning
constructs (Kuttiyil, 2004), (Augasta and
Kathirvalavakumar, 2012). In addition, rule
induction methods are used for rule generation on
relatively moderate problems (Triantaphyllou and
Felici, 2006). In this study, a composite system that
will use multiple data sets will be build. This yields
that the system will use different rule extraction and
induction methods to work in the most accurate and
efficient way.
Before the review of the literature, let us inform
that we use “rule extraction”, “rule generation”,
“rule induction”, “rule refinement” terms in the
paper. We imply a broader scope for rule generation
including all as in (Mitra and Hayashi, 2000).
Moreover, as we plan to use a RBS with generated
rules, the main research filed is rule generation and
following review is on this direction. The following
part of section is dedicated to review of the rule
generation methods and the data sets that were used
in those studies. The aim is to give the reader the
ability to match best the rule generation method for
his/her data set.
Andrews et al. proposed a classification scheme
for rule extraction techniques by ANNs that can
easily be extended to other classifiers and rule
generation methods. Their scheme is based on
expressive power, translucency, portability, rule
quality, and algorithmic complexity (Andrews et al.,
1995). Later new researches widen the definition
and the scope of the concepts listed above
(Jacobsson, 2005) (Browne, 1997) (Sethi et al.,
2012). We can describe them shortly as below:
Expressive Power; how well the rules presented
to the end user,
Translucency: the degree to which the technique
considers the internal structure of classifier
Portability; the degree to which the technique is
applicable to other classifier architectures
Rule Quality; according to previous studies rule
quality have four aspects (Towell and Shavlik,
1993):
“Rule accuracy—the ability of the rules to
generalize to unseen examples
Rule fidelity—how well the rules mimic the
behavior of the classifier
Rule consistency—the extent to which equivalent
rules are extracted from different networks trained
on the same task (same data set)
Rule comprehensibility—the readability of rules
or the size of the rule set” (Jacobsson, 2005)
Algorithmic Complexity; the total complexity of
the rule extraction steps.
We find it suitable to make the taxonomy of the
rule generation methods according to their
translucency as it is more about the technical
approach of the method and this choice is common
in literature as in (Barakat and Bradley, 2010). From
the translucency view of the methods, we can list
pedagogical and decompositional approaches, plus
the hybrid of them: eclectic approach. We will give
description and examples of the approaches in the
rest of this section.
4.1 Pedagogical Approach
Pedagogical rule extraction methods analyze the
RuleGenerationforScenariobasedDecisionSupportSystemonPublicFinanceDomain
73

inputs and the outputs of the classifiers and treat
them as black boxes, they do not look inside the
internal structure of the classifier. As expressed
before, classifiers are in types of ANNs, SVMs and
similar constructs (Taha and Ghosh, 1996)
(Tsukimoto, 2000).
To overcome the comprehensibility limitation
(black box behavior) of the SVM, Martens et al
utilized rule extraction from SVMs s (Martens et al.,
2007). Actually, this is one of basic reasons for rule
extraction. They compared recent rule extraction
techniques for SVMs and two more techniques for
trained ANNs according to the fidelity, accuracy and
number of the rules. They conducted experiments on
Ripley’s synthetic dataset (Ripley et al., 1994), iris
dataset, the breast cancer dataset, Australian credit
scoring dataset from the University of California at
Irvine (UCI) Machine Learning Repository (MLR)
(Hettich and Bay, 1999) and the bankruptcy data of
firms with middle-market capitalization (mid-cap
firms) in the Benelux countries (Belgium, the
Netherlands and Luxembourg) (Gestel et al., 2006).
They put forward that the performance of the rules
extracted from SVM is slightly less than that of the
SVM. By the way, their research is valuable for the
background information about the rule extraction
methods up to 2006 and the SVMs.
Martens et al. also provided a new approach in
order to increase both the accuracy and the
comprehensibility of the extracted rules. Normally,
the classifiers’ accuracy on classification is better
than the rule sets’ accuracy on the same data set as
seen in (Martens et al., 2007). They ascribed the loss
to the data inconsistency. Naming the process as
active learning, they relabelled the samples after the
training with the labels of the trained SVM. The
wine, balance, sonar, German credit, contraceptive
method of choice datasets from the UCI data
repository (Hettich and Bay, 1999), binary synthetic
dataset of Ripley (Ripley et al., 1994), Belgian and
Dutch credit risk datasets were used to test the new
approach and results show that active learning
increases the accuracy and fidelity. In the study, the
researchers also express that RE methods are better
than rule induction methods for high-dimensional
data having nonlinear relations while rule induction
techniques can perform better on data sets where
data can actually be described in simple rules
(Martens et al., 2009).
Kahramanli and Allahverdi, proposed a new method
for RE from trained adaptive neural networks, which
uses artificial immune systems. Electrocardiogram
(ECG) and Breast Cancer datasets from UCI MLR
were used in tests (Kahramanli and Allahverdi,
2009). They showed ANNs with adaptive activation
functions provide better fitting than classical
architectures with fixed activation functions.
Setiono et al. proposed another ANN based,
recursive RE mechanism that firstly considers some
part of the discrete attributes (the necessary to
generate discrete valued rules) in the rule generation.
If the rule set is not efficient enough, all the discrete
attributes are considered in the second step, finally
continuous attributes are also considered to achieve
the desired accuracy. They have used the German
credit dataset from UCI MLR ((Hettich and Bay,
1999) and the Bene1, Bene2 datasets that were
obtained from major financial institutions in
Benelux countries (Setiono et al., 2008).
4.2 Decompositional Approach
Decompositional rule extraction algorithms utilize
internal structures of the learners, such as the hidden
layers of the ANN, U-matrix of the Self Organizing
Map (SOM), the hyperplane of the SVM or the
weights of internal vectors (Setiono and Liu, 1997).
It is observable that some methods assign linguistic
meanings to the nodes. As the algorithms deal with
the internal nodes, computational complexities for
them get exponential.
As an instance, Li and Chen proposed a SVM
based RE mechanism. Their process includes the
following activities in order; feature selection by
Genetic Algorithm (GA), constructing hyper-
rectangle rules by Support Vector Clustering (SVC),
rule simplification by hyper rectangle combination,
interval extension and dimensionality reduction ((Li
and Chen, 2014). They used six datasets from the
UCI MLR (Hettich and Bay, 1999) to test their
method on extracting classification rules.
In another SVM based method, Wang et al. used rule
extraction for clustering problem on strip hot-dip
galvanizing by defining convex hulls on the hyper-
plane of the SVM. Later, the convex hull defined for
each cluster, formed a rule. Process also includes k-
means clustering preprocess. They applied the
algorithm to real strip hot-dip galvanizing process
(Box and Jenkins, 1976).
Not only supervised learning methods are used
for RE, also methods with unsupervised classifiers
such as SOMs are used. Leng et al. proposed a
hybrid neural network, called the self-organizing
fuzzy neural network (SOFNN), to extract fuzzy
rules from the training data (Leng et al., 2005). The
SOFNN consists of five layers and the first hidden
layer consists of ellipsoidal basis function (EBF)
neurons. The learning method includes adding and
IC3K2014-DoctoralConsortium
74

pruning neurons. For realizing RE, when some
neurons have similar membership functions, they
were gathered in the same group and combined into
a new membership function. They tested their
method on generated data sets regarding to three-
input nonlinear function and pH neutralization
process, in addition to the well-known Box–Jenkins
furnace data set (Box and Jenkins, 1976).
In order to find a new method for RE, Etchellls
et al. proposed an algorithm from the neural network
trained for binary classification using 1-from-N
binary coded ordinal explanatory variables. Their
algorithm, called Orthogonal Search-based RE
(OSRE), reduces the number of the orthogonal rules
for each data point by eliminating those orthogonal
rules for which there is no change in activation, i.e.
redundant conditional clauses in the antecedent part
of the rule are omitted. They have used Monks’ data
(Thrun et al., 1991) and Wisconsin’s breast cancer
data (Bache and Lichman, 2013) to test their method
and compare it with the some other methods
(Etchells and Lisboa, 2006).
A typical decompositional RE method was
proposed by Malone et al. for the automatic
extraction of rules from trained SOMs. Their
technique performs an analysis of the U-matrix of
the network for extracting the components on the
map. Then component boundaries were used to form
basis of the rules. They used Iris, Monks and Lung
Cancer data sets (Bache and Lichman, 2013) in
order to compare their method’s accuracy (Malone
et al., 2006).
4.3 Eclectic Approach
The hybrid of the two approaches; decompositional
and pedagogical is specifically called as “eclectic”
approach. Barakat and Diederich proposed an
example eclectic approach by using SVMs. Their
study is one of the methods showing that methods
applied on ANNs are applicable to SVMs as well.
They used four datasets from UCI MLR: Pima
Indians Diabetes, Heart Diseases, Breast Cancer and
Hepatitis datasets (Bache and Lichman, 2013). They
contributed on evaluating the quality of the extracted
rules by analyzing the number of training patterns,
the leave-one-out accuracy of SVM , the number of
support support models, the number of rules/
antecedents, the classification accuracy of SVM on
test dataset, the accuracy and fidelity of the rules
(Barakat and Diederich, 2006).
4.4 Other Methods
The methods that are classified in the previous
categories mostly use ANN and SVM types and they
are called as RE methods. However, there are many
methods producing rules using different techniques
and not in the previous categories, as we will
mention below.
Predicting the price gains in the first day of
Initial Public Offering (IPO) has been a popular
subject and Quintana et al. proposed a rule-based
system utilizing genetic algorithms for the
predictions about the gains (Quintana et al., 2005).
They have constructed the rule-base using 840 past
IPOs as training set. They have parameterized an
IPO by filling some predefined variables for the IPO
and the price gain. The rules, i.e. if lb
1
< v
1
< ub
1
,
lb
2
< v
2
< ub
2
… lb
7
< v
7
< ub
7
then gain is r
1
, are
produced from these existing IPOs. For the outlier
cases, they have utilized genetic algorithm with
Michigan approach.
For Complex Event Processing (CEP), Margara
et al. achieved rule generation by analyzing the
historical traces with their ad-hoc learning
algorithms. They produced partial rules, combined
them into one rule that gives necessary conditions to
alert a critical phenomena. They used the dataset
including time stamped information about the
positions and the status of buses in the city of Dublin
(Margara et al., 2014). Their solution on producing
rules in order to detect a composite event from
timely logs is quite inspiring, but on most problems
answering a question like “is there a fire or not?” is
not enough, the RE mechanism should give a more
detailed output set. For a similar problem, Sannino
et al. proposed a mobile system for Obstructive
Sleep Apnea (OSA) event detection and they tested
their approach on an apnea-ECG database ((Penzel
et al., 2000). They used a new RE mechanism called
DEREx based on Differential Evolution. DEREx
generates and selects desired individuals in a
population, and then rules are encoded from the
selected individuals (Sannino et al., n.d.) (De Falco,
2013)
Rule generation was also utilized on the problem
of prediction of promoters in the DNA sequences by
Karli. He proposed a new method called Inductive
Rule Extraction Method (IREM), which takes
attribute-value pairs as classes and selects the best
pairs to use in extraction of the rules. Cost function
that was used in selection, mainly depends on class-
based entropies. Method was tested on the E. Cole
promoter gene arrays of DNA, which were collected
from the UCI MLR (Bache and Lichman, 2013)
((Karl, 2014). In a close topic, for gene expression
profiling Chen et al. tried RE from trained SVM
with multiple kernels (Chen et al., 2007). They used
RuleGenerationforScenariobasedDecisionSupportSystemonPublicFinanceDomain
75

ALL-AML leukemia dataset (Golub et al., 1999) and
colon tumor dataset (Alon et al., 1999)
As an example of rule induction, Y. Qian et al.
introduced a method from decision tables based on
converse approximation (CA). In their study
basically, CA is used to give the definition of the
upper and lower approximations of a target concept
under a granulation order. They explained and gave
the usage of their algorithm on two simple custom
data sets (Qian et al., 2008).
5 METHODOLOGY
As expressed below, the final output of this work is
an ontology based DSS with scenario-based future
predicting capability. In the general view of the
planned tasks, the list isas follows: analyzing the
resources that belong to the pilot organization,
determining the parameters related with the fields of
prediction and determining the resources, which will
be used to assign values of those parameters. The
mentioned determinations are being made together
with the domain experts in the research team. As the
data set, we chose EU-funded research projects
completed after 2010 on CORDIS and the EU as the
organization. Now, we are working on the policy
documents of the EU such as EUROPE 2020
strategy, definitions of the programmes, scope of the
subjects and other project related data published in
The EU Open Data Portal and CORDIS project
database. Later on, a conventional RBS will be
created. However, since we do not have a method
that will automatically feed the RBS with rules and
facts yet, we will manually produce rules and facts
from the resources and make the RBS capable of
giving reasonably accurate answers for the past data
on manually generated test cases. On the next
phase, we will develop the dynamic rule extraction
mechanism for making predictions on the
inexperienced scenarios. As mentioned before, we
will develop a learners system for dynamic rule
generation. According to determined decision
parameters and deductions on obtaining these
parameters, necessary learner types and their
working principles (such as ordering, weights, and
necessary computations) will be specified. When all
the system specifications are ready, creation of the
learners, the derivation of feature vectors, training,
testing and optimization phases will be conducted.
After the learners system is established, the
complete DSS (with whole knowledge base) will be
tested on the scenarios that were prepared at the
beginning of the study and then necessary
optimizations will take place.
To make the whole “ontology based decision
support system” work, finally, we will combine the
ontology based knowledge extraction system and the
scenario based DSS to constitute the system that can
enrich its knowledge base from both structured and
unstructured data. The key point on the combining
method is the query results should be data sets,
which can be easily processed by training
algorithms. As mentioned before, this will make
other researches possible on the extracted
knowledge.
Remaining of this part gives the phases of the
study in detail.
5.1 Building the Ontology
This part of the study is mostly completed; the
others are in progress or waiting status. In this phase,
firstly to gain domain expertise we have discussed
key terms in budgeting, accounting and necessary
related topics in public finance with domain experts
on regular meetings. After defining relations,
making simplifications and grouping were done and
finally sub ontologies and relations between sub
ontologies were determined. (Since this study is not
about ontology development, details will not be
given.)
5.2 Determining the Properties of the
Knowledge Base
In this phase high-level policy papers, budgets of
past years, reports as programme budget realizations
are being inspected. By the inspection, necessary
decision parameters, intermediate parameters, key
performance indicators (KPI), key goal indicators
(KGI) and similar important information for
defining the facts and the rules will be specified. A
sample analysis on the relations of the pilot domain
can be seen in Figure 3. The process includes
revealing the relations and effects between these
concepts and defining the resources containing that
information. For this purpose, together with the
domain experts, we are making analysis on the query
and report needs of decision makers. The domain
experts will evaluate the success rate of the studies
in this phase. In addition, all the tests in next phases
will check and update these outputs.
By the way, domain experts in our team have public
finance experience; however, it would be better if
we could work with EU officers during the project.
IC3K2014-DoctoralConsortium
76
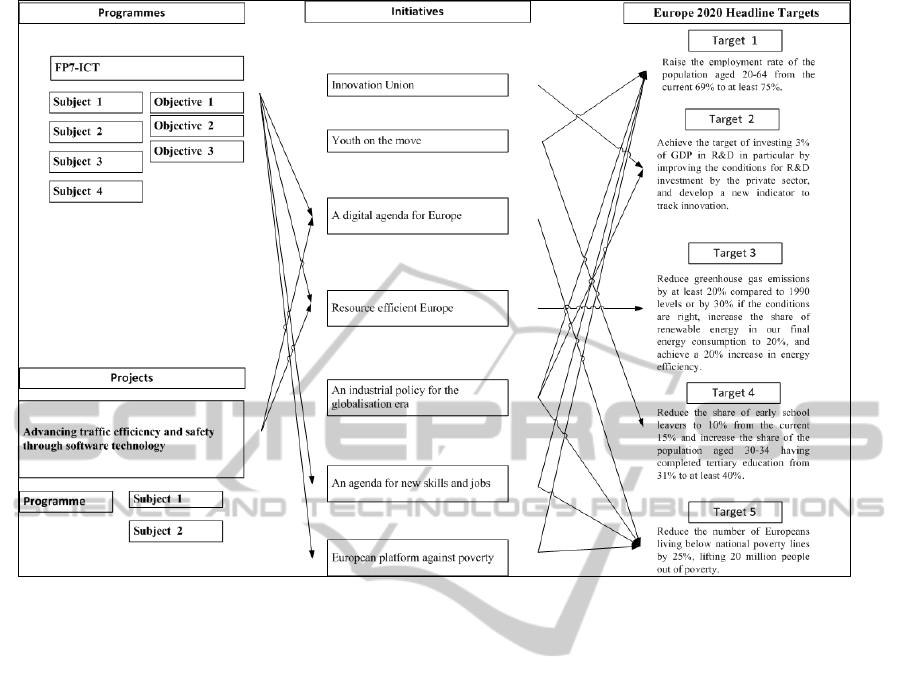
Figure 3: A sample analysis on relations between projects and organizational targets.
5.3 Developing Static Rules Base
In this phase, a custom system development life
cycle for RBS development will be defined and it
will be repeated in the next phases. According to
properties defined in the previous phase, we will
manually formulate facts and rules, and we will
introduce them to the RBS. Then we will make
verification and validation tests on the RBS with an
enriched knowledge base. We aim the following
gains by the tests:
resolving the issues as ambiguities in the
information resource
resolving the knowledge base errors and
anomalies in the definitions of the facts and
the rules
resolving the errors in the inference engine
determining the situations that may result in
misconception when using the system, and
resolving these by the activities like providing
ease-of-use, making input validation, checking
the system messages
To measure the success rate of these outputs we
will apply methods in following two categories.
5.3.1 Static Methods
Inspection of rules and facts by the domain
experts manually
Automatic syntax checks
Automatic logical anomaly checks like
integrity and rule pair checks
5.3.2 Dynamic Methods
Running the test cases obtained from past data
Running the test cases designed by domain
experts, organization personnel (if possible)
and researchers
Running the randomly generated test cases
obeying some semantic constraints, if the
above test cases are not found sufficient
5.4 Developing Dynamic Rule
Extraction Mechanism
The dynamic rule generation mechanism is the part
of the system that will make rule simulation, answer
the questions that cannot be answered by static rules
and predict the future states of the decision
parameters. To develop this mechanism according to
RuleGenerationforScenariobasedDecisionSupportSystemonPublicFinanceDomain
77

determined decision parameters and deductions on
obtaining these parameters, necessary learner types
and their working principles will be determined. By
the analysis on the data sets, features for different
learner types will be chosen and then the training,
testing, optimization activities will follow. In
addition, we will develop an external application for
domain experts for training the system by asking
what-if type questions and saving the answers to the
system. We plan to run all the test cases that we run
on the static rules base.
6 EXPECTED OUTCOME
The expected outcome of the project is an ontology
based DSS which has two big modules: ontology
based KES and scenario based DSS. Second one is
the expected outcome of this thesis. As given in
Figure 1, the system starts with processing
structured/unstructured data and transforming them
to knowledge, which is suitable for feeding
knowledge base of the DSS. It is planned to send
queries to the KES and get a data set about a topic.
This approach is chosen because the result as a data
set is standard and can be used for other researches
as well. KES also has a knowledge base that should
not be confused with the knowledge base of the
DSS.
We plan to implement the DSS by a RBS with
both static and dynamic rules. By a dynamic rules
base, we mean a rule generation system (RGS). Two
basic innovations are aimed by the proposed Rule
Generation System (RGS). Firstly, it is a novel
approach on generating rules for many related but
different topics, so the architecture is able to give
comprehensible reasoning about composite events
and it gives a design template for similar research.
Second innovation is producing rules for answering
the what-if type questions like if-then type ones.
In this paragraph, let us tell why we need the
dynamic rules. To make the system initialization for
the chosen topic, firstly previous experiences and
answers of domain experts for some (present or
produced) cases should be stored to the system
knowledge base. After this process, the RBS should
be able to use its power on making inferences about
the present situation and make reasoning. However,
gathered as described below, a static knowledge
base will not be sufficient to explain the results of
scenarios that have not been observed before, we
mean here static knowledge base will not be
sufficient on “explaining answers of what-if type
questions”. To overcome this, we propose a RBS
with both static and dynamic rules. The basic view
of the system is in Figure. 4. The system has basic
features of a RBS (Hayes-Roth, 1985) plus dynamic
rule base.
What is expected from this RGS is giving the
rule that defines the result, suggestion or the action
related to a particular if case. The difference of the
dynamic rule base’s answer from a conventional
RBS’s answer is that it may be the result of a
computation, generalization or another process by
the system module, which is responsible for a
particular topic. We plan to realize this system by
different the constructs as ANNs, SVMs and other
rule generation methods, as seen in Figure 6. A
necessary amount of learners will be deployed and
they will be in suitable type for the related dataset.
After training the whole system with data set from
the KES, it will be possible to generate rules and
resolve inexperienced situations by the help of its
internal learner capabilities such as generalization.
The proposed system seen in Figure 6 has a
modular structure where modules can produce
independent results. It must be noted that any
module has its own data set and they do not feed
each other. The data sets are gathered by different
query results from the KES. The arrows on the
figure mean; on execution, the rule selector will go
in the direction or in the opposite direction of the
arrows. Non-technically saying when an answer is
waiting to be given, the system will consider
the related topics; it may be for the results or for the
causes. When all the rules about different topics are
generated, they will be collected in the RBS’s
knowledge base. The mentioned search for related
topics of an event will be achieved by the RBS, here
we figure them separately in order to show that they
will be generated separately.
Another notification that should be given is about
the purpose of the learners as ANNs and SVMs on
what-if type questions. They have the strength to
give an output vector when you provide the input
vector, where these vectors are meaningful
representations in our problem domain. From this,
we may conclude that they can answer what-if type
questions. Right, they can answer desired question
but they cannot always explain their answer. Surely,
we do not admit this on various real world problems.
Instead, they will be used for RE, and what-if
questions will be answered by the rules that learners
generated. When using the rule sets but not the
learners themselves, one should feel disturbed about
losing learners’ capabilities such as learning and
generalization, since the rules are extracted from
learner not from the data set. Researches as (Martens
IC3K2014-DoctoralConsortium
78
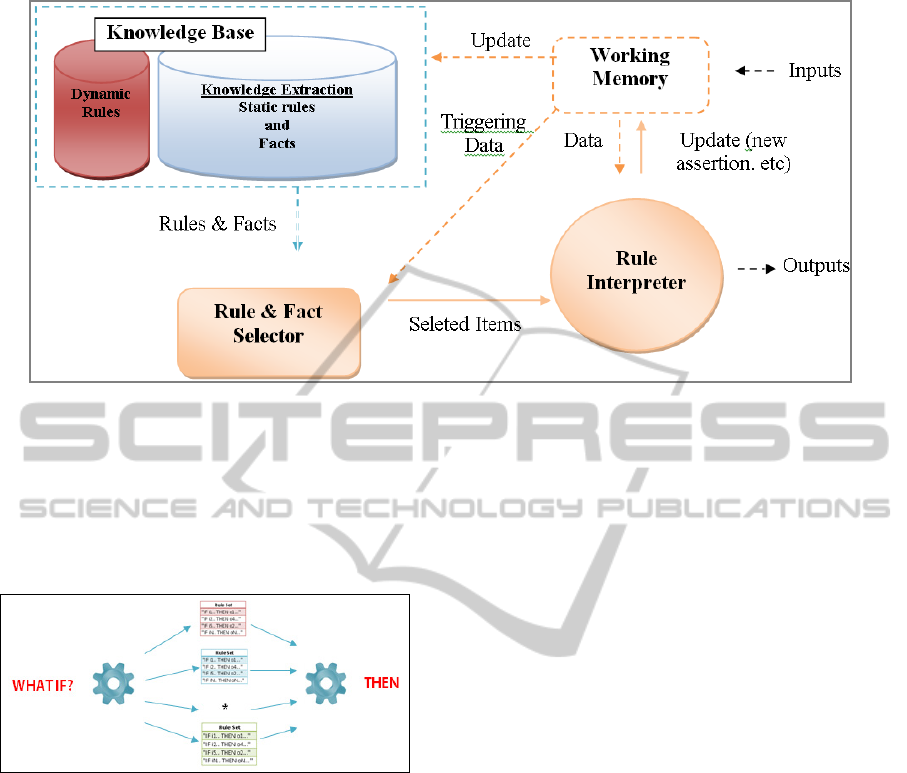
Figure 4: DSS with Dynamic Rule Set.
(Martens et al., 2009) show that the learners have
better accuracy than the accuracy of the rule set they
generated. Even so, in this study, we sacrifice
accuracy in a small rate not to lose
comprehensibility. We pictured the mentioned
scenario in Figure 5.
Figure 5: System answering what-if type questions.
REFERENCES
Alon, Uri, Barkai, Naama, Notterman, Daniel A, Gish,
Kurt, Ybarra, Suzanne, Mack, Daniel, and Levine,
Arnold J. 1999. Broad patterns of gene expression
revealed by clustering analysis of tumor and normal
colon tissues probed by oligonucleotide arrays.
Proceedings of the National Academy of Sciences,
96(12), 6745–6750.
Andrews, Robert, Diederich, Joachim, and Tickle, Alan B.
1995. Survey and critique of techniques for extracting
rules from trained artificial neural networks.
Knowledge-based systems, 8(6), 373–389.
Augasta, M Gethsiyal, and Kathirvalavakumar, T. 2012.
Rule extraction from neural networks—A comparative
study. Pages 404–408 of: Pattern Recognition,
Informatics and Medical Engineering (PRIME), 2012
International Conference on. IEEE.
Bache, K., and Lichman, M. 2013. UCI Machine Learning
Repository.
Barakat, Nahla, and Bradley, Andrew P. 2010. Rule
extraction from support vector machines: a review.
Neurocomputing, 74(1), 178–190.
Barakat, Nahla, and Diederich, Joachim. 2006. Eclectic
Rule-Extraction from Support Vector Machines.
International Journal of Computational Intelligence,
2(1).
Box, George EP, and Jenkins, Gwilym M. 1976. Time
series analysis, control, and forecasting.
Browne, Antony. 1997. Neural network analysis,
architectures and applications. CRC Press.
Buchanan, B.G., and Duda, R.O. 1983. Principles of rule-
based expert systems. Advances in Computers, 22,
163–216.
Chen, Zhenyu, Li, Jianping, and Wei, Liwei. 2007. A
multiple kernel support vector machine scheme for
feature selection and rule extraction from gene
expression data of cancer tissue. Artificial Intelligence
in Medicine, 41(2), 161–175.
De Falco, Ivanoe. 2013. Differential Evolution for
automatic rule extraction from medical databases.
Applied Soft Computing, 13(2), 1265–1283.
Dhar, Vasant, and Stein, Roger. 1996. Intelligent decision
support methods: the science of knowledge work.
Etchells, Terence A, and Lisboa, Paulo JG. 2006.
Orthogonal search-based rule extraction (OSRE) for
trained neural networks: a practical and efficient
approach. Neural Networks, IEEE Transactions on,
17(2), 374–384.
Finlay, Paul N. 1989. Introducing decision support
systems. NCC Blackwell.
Gestel, Tony Van, Baesens, Bart, Suykens, Johan AK,
Van den Poel, Dirk, Baestaens, Dirk-Emma, and
Willekens, Marleen. 2006. Bayesian kernel based
classification for financial distress detection. European
journal of operational research, 172(3), 979–1003.
RuleGenerationforScenariobasedDecisionSupportSystemonPublicFinanceDomain
79
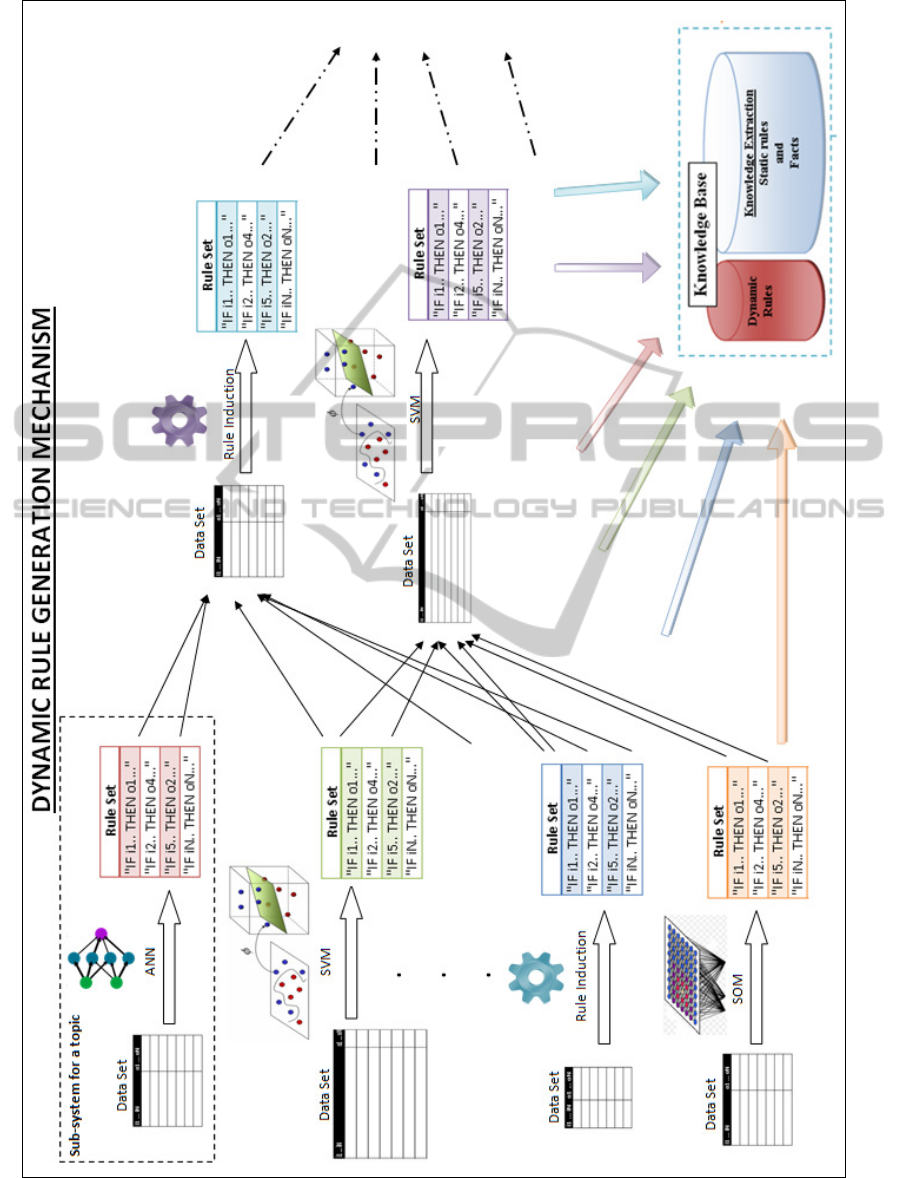
Figure 6: Rule Generation System.
IC3K2014-DoctoralConsortium
80

Golub, Todd R, Slonim, Donna K, Tamayo, Pablo, Huard,
Christine, Gaasenbeek, Michelle, Mesirov, Jill P,
Coller, Hilary, Loh, Mignon L, Downing, James R,
Caligiuri, Mark A, et al. 1999. Molecular
classification of cancer: class discovery and class
prediction by gene expression monitoring. science,
286(5439), 531–537.
Han, Jiawei, Kamber, Micheline, and Pei, Jian. 2006. Data
mining: concepts and techniques. Morgan kaufmann.
Hayes-Roth, F. 1985. Rule-based systems. Communica-
tions of the ACM, 28(9), 921–932.
Hettich, S., and Bay, S. D. 1999. The UCI KDD Archive
(http://kdd.ics.uci.edu).
Jacobsson, Henrik. 2005. Rule Extraction from Recurrent
Neural Networks: ATaxonomy and Review. Neural
Computation, 17(6), 1223–1263.
Kahramanli, Humar, and Allahverdi, Novruz. 2009. Rule
extraction from trained adaptive neural networks using
artificial immune systems. Expert Systems with
Applications, 36(2), 1513–1522.
Karl, G. 2014. Promoter prediction using IREM (inductive
rule extraction method).
Khan, Javed, Wei, Jun S, Ringner, Markus, Saal, Lao H,
Ladanyi, Marc, Westermann, Frank, Berthold, Frank,
Schwab, Manfred, Antonescu, Cristina R, Peterson,
Carsten, et al. 2001. Classification and diagnostic
prediction of cancers using gene expression profiling
and artificial neural networks. Nature medicine, 7(6),
673–679.
Kuttiyil, A.S. 2004. Survey of rule extraction methods.
Leng, Gang, McGinnity, Thomas Martin, and Prasad,
Girijesh. 2005. An approach for on-line extraction of
fuzzy rules using a self-organising fuzzy neural
network. Fuzzy sets and systems, 150(2), 211–243.
Li, Ai, and Chen, Guo. 2014. A new approach for rule
extraction of expert system based on SVM.
Measurement, 47, 715–723.
Malone, James, McGarry, Kenneth, Wermter, Stefan, and
Bowerman, Chris. 2006. Data mining using rule
extraction from Kohonen self-organising maps. Neural
Computing and Applications, 15(1), 9–17.
Margara, Alessandro, Cugola, Gianpaolo, and
Tamburrelli, Giordano. 2014. Learning From the Past:
Automated Rule Generation for Complex Event
Processing.
Martens, David, Baesens, Bart, Van Gestel, Tony, and
Vanthienen, Jan. 2007. Comprehensible credit scoring
models using rule extraction from support vector
machines. European journal of operational research,
183(3), 1466–1476.
Martens, David, Baesens, BB, and Van Gestel, Tony.
2009. Decompositional rule extraction from support
vector machines by active learning. Knowledge and
Data Engineering, IEEE Transactions on, 21(2), 178–
191.
Min, Jae H, and Lee, Young-Chan. 2005. Bankruptcy
prediction using support vector machine with optimal
choice of kernel function parameters. Expert systems
with applications, 28(4), 603–614.
Mitra, Sushmita, and Hayashi, Yoichi. 2000. Neuro-fuzzy
rule generation: survey in soft computing framework.
Neural Networks, IEEE Transactions on, 11(3), 748–
768.
Penzel, T, Moody, GB, Mark, RG, Goldberger, AL, and
Peter, JH. 2000. The apnea-ECG database. Pages 255–
258 of: Computers in Cardiology 2000. IEEE.
Power, Daniel J, and Sharda, Ramesh. 2009. Decision
support systems. Springer handbook of automation,
1539–1548.
Qian, Yuhua, Liang, Jiye, and Dang, Chuangyin. 2008.
Converse approximation and rule extraction from
decision tables in rough set theory. Computers and
Mathematics with Applications, 55(8), 1754–1765.
Quintana, D., Luque, C., and Isasi, P. 2005. Evolutionary
rule-based system for IPO underpricing prediction.
Pages 983–989 of: Proceedings of the 2005
conference on Genetic and evolutionary computation.
ACM.
Ripley, Brian D, Whittle, P, Kay, J, Hand, DJ, Tarassenko,
L, Brown, PJ, Titterington, DM, Taylor, C, Gilks, WR,
Critchey, F, et al., 1994. Neural Networks And
Related Methods For Classification. Discussion.
Reply. Journal of the Royal Statistical Society. Series
B. Methodological, 56(3), 409–456.
Sahoo, R.K., Oliner, A.J., Rish, I., Gupta, M., Moreira,
J.E., Ma, S., Vilalta, R., and Sivasubramaniam, A.
2003. Critical event prediction for proactive
management in large-scale computer clusters. Pages
426–435 of: Proceedings of the ninth ACM SIGKDD
international conference on Knowledge discovery and
data mining. ACM.
Sannino, Giovanna, De Falco, Ivanoe, and De Pietro,
Giuseppe. An automatic rule extraction-based
approach to support OSA events detection in an
mHealth system.
Sethi, Kamal Kumar, Mishra, Durgesh Kumar, and
Mishra, Bharat. 2012. Extended Taxonomy of Rule
Extraction Techniques and Assessment of KDRuleEx.
International Journal of Computer Applications, 50.
Setiono, Rudy, and Liu, Huan. 1997. NeuroLinear: From
neural networks to oblique decision rules.
Neurocomputing, 17(1), 1–24.
Setiono, Rudy, Baesens, Bart, and Mues, Christophe.
2008. Recursive neural network rule extraction for
data with mixed attributes. Neural Networks, IEEE
Transactions on, 19(2), 299–307.
Shumway, R.H., and Stoffer, D.S. 2000. Time series
analysis and its applications. Springer Verlag.
Taha, Ismail, and Ghosh, Joydeep. 1996. Three techniques
for extracting rules from feedforward networks.
Intelligent Engineering Systems Through Artificial
Neural Networks, 6, 23–28.
Thrun, Sebastian B, Bala, Jerzy W, Bloedorn, Eric,
Bratko, Ivan, Cestnik, Bojan, Cheng, John, De Jong,
Kenneth A, Dzeroski, Saso, Fisher, Douglas H,
Fahlman, Scott E, et al.
1991. The monk’s problems:
A performance comparison of different learning
algorithms.
RuleGenerationforScenariobasedDecisionSupportSystemonPublicFinanceDomain
81

Towell, Geoffrey G, and Shavlik, Jude W. 1993.
Extracting refined rules from knowledge-based neural
networks. Machine learning, 13(1), 71–101.
Triantaphyllou, Evangelos, and Felici, Giovanni. 2006.
Data mining and knowledge discovery approaches
based on rule induction techniques. Vol. 6. Springer.
Tsukimoto, Hiroshi. 2000. Extracting rules from trained
neural networks. Neural Networks, IEEE Transactions
on, 11(2), 377–389.
Turban, Efraim. 1990. Decision support and expert
systems: management support systems. Prentice Hall
PTR.
IC3K2014-DoctoralConsortium
82
