
From a Logical Approach to Internal States of Hash Functions
How SAT Problem Can Help to Understand SHA-⋆ and MD⋆
Florian Legendre
1
, Gilles Dequen
2
and Micha¨el Krajecki
1
1
UFR Sciences, University of Reims Champagne-Ardennes, Moulin de la Housse, Reims, France
2
MIS, University of Picardie Jules Verne, Amiens, France
Keywords:
Hash Functions, Logical Cryptanalysis, MD5, SHA-1, Satisfiability.
Abstract:
This paper deals with logical cryptanalysis of hash functions. They are commonly used to check data integrity
and to authenticate protocols. These functions compute, from an any-length message, a fixed-length bit string,
usually named digest. This work defines an experimental framework, that allows, thanks to the propositional
formalism, to study cryptosystems at the bit level through corresponding instances of the SAT problem. Thus,
we show that some internal words of popular hashing functions MD⋆ and SHA-⋆ are not as random as expected
and provide some convincing elements to explain this phenomenon by the use of round constants. Because
this presents several weaknesses, we show how to detect and exploit these ones through an application based
on logical cryptanalysis. As a result we show equivalences, and quasi-equivalences between digits and explain
how we inverse reduced-step versions of MD5 and SHA-1.
1 INTRODUCTION
In the last years, the proliferation of digital systems
has placed cryptology at the heart of our communi-
cations. Within this context, studies about crypto-
graphic functions are a keystone to preserve the sus-
tainability of our systems. More specifically, the field
of Cryptanalysis consists in finding weaknesses that
will facilitate the retrieval of any secret information.
Several general cryptanalysis approaches have been
proposed over the years such as differential (Biham
and Shamir, 1990) or linear (Matsui and Yamagishi,
1992) ones. This paper deals with cryptographic hash
functionsthat are centralelementsof moderncryptog-
raphy. A hash function can be defined as a determin-
istic process that generates a fixed-length bit string,
usually named digest, from any-length bit string also
named the message. It is commonly used to check
integrity of files or communications. Moreover, it
usually participate to authentication protocols. One
of their main characteristic is to diffuse and confuse
an input message in a very fast way. Within this
framework, the internal 32-bit words of a hashing pro-
cess need to look as random as possible. So that
making this possible, the compression function of-
ten use round constants, derived from physical con-
stants (Knuth, 1997). In (Legendre et al., 2012), we
encoded the MD5 hash function in a DIMACS format
in order to tackle the preimage thanks to SAT solv-
ing. In this paper we focus on our SAT modeling in
order to examine the structural behavior of the inter-
nal words of the process by two different ways. The
first one is via an automatic logical reasoning that al-
low to deduce equivalencies and some special rela-
tions between variables. The second one is by us-
ing the formula to generate statistical informations
so that estimating a generic behavior of the process.
From this, we then deduce classical and conditional
probabilities that shed a light on unexpected struc-
tural informations. Indeed we show that just using
round constants leads to belie the idea of a total ran-
domness of the hashing process and can give some
information that could help an attacker. From this, we
present equivalences, quasi-equivalences and quasi-
implications that could be used in other cryptanalytic
approach. This paper is organized as follows: In sec-
tion 2, we give an overview of hash functions more
focused on those that use the Merkle-Damg
˚
ard con-
struction. We also recall some notations and objects
related to the SAT problem and its solving rules. The
section 3 deals with our probabilistic approach and
give details about specific cases where probabilities
aren’t uniforms. In section 4, we show how to use
these special weaknesses in a practical framework and
particularly by using SAT solvers and logical reason-
ing. Finally we conclude and open perspectives.
435
Legendre F., Dequen G. and Krajecki M..
From a Logical Approach to Internal States of Hash Functions - How SAT Problem Can Help to Understand SHA-* and MD*.
DOI: 10.5220/0004534104350443
In Proceedings of the 10th International Conference on Security and Cryptography (SECRYPT-2013), pages 435-443
ISBN: 978-989-8565-73-0
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

2 BACKGROUND AND
PRELIMINARIES
2.1 About Cryptographic Hash
Functions
A cryptographic hash function can be defined as a
deterministic algorithm that maps an any-length bit
string (also named the message) to a fixed-length bit
string, usually named digest or hash
. Among the
uses of such a function we can notice for instance
the integrity check of files or communications or dig-
ital signature. It can also contribute to ensure au-
thentication protocols with Message Authentication
Codes (MACs) which are a mean that two users with
a shared secret key can authenticate between each
other
. To make these functions secure, they required
to be theoretically or computationally collision and
(second) preimage resistant.
2.2 Notations
In this paper, we mainly focus on the popular MD⋆
and SHA-⋆ hash functions that are built following
the Merkle-Damg
˚
ard construction (Merkle, 1989;
Damg˚ard, 1989). Each of these functions uses inter-
nal 32-bit words that are described with the following
notations. Let be the process at step i. We denote each
word as:
• Q
i
is the internalstate obtained at the endofa step.
• f
i
is a non-linear function. It can be named {F, G,
H, I}, depending on the step considered.
• S
i
is a sum resulting of a 4 operands addition. This
represents the main operation of a round.
• Within the propositional context, an addition of 4
operands could generate 2 levels of carry. fC
i
is
the first level. sC
i
is the second level of carry.
• tC
i
is the first (and unique) level carry resulting of
a 2 operands addition
• Cst
i
is a round constant
Note also:
• W[ j] is the j
th
bit of a 32-bit word, j ∈ {0, ...31}
• M
k
is the k
th
32-bit word from the input message,
k ∈ {0, ...15}
2.3 About MD5
MD5 was designed in 1991 by Ron Rivest as an evo-
lution of MD4, strengthening its security by adding
some improvements. The operating principle of this
function consists in the repetition of 64 steps, defined
with three sub-steps as follows:
a) Q
i
← Q
i−4
+ f(Q
i−1
, Q
i−2
, Q
i−3
) + M
k
+Cst
i
b) Q
i
← Q
i
≪ s
n
c) Q
i
← Q
i
+ Q
i−1
where :
• i is the current step, ∈ { 1, ..., 64 }
• Q
−3
, Q
−2
, Q
−1
, Q
0
are the Initial Values (I.V.).
• ≪ s
n
the circular shifting to the left(rotating) by
n bits position, depends on i.
• f
i
∈ { F, G, H, I }, where:
F(X,Y,Z) = (X ∧ Y) ∨ (
X ∧ Z)
G(X,Y,Z) = F(Z,X,Y)
H(X,Y,Z) = X ⊕ Y ⊕ Z
I(X,Y,Z) = Y ⊕ (X ∨
Z)
2.4 About SHA-1
SHA-1 was designed in 1995 by the NSA as an im-
proved version of SHA-0 in order to prevent some
weaknesses. The operating principle is the same as
the MD⋆ family and consists in a hashing process
where five states of 32-bit words are initialized and
then modified at each of the 80 steps. A step can be
defined with the following sub-steps:
a) Q
i
← (Q
i−1
≪ 5)
b) Q
i
← Q
i
+ f(Q
i−2
, (Q
i−3
≪ 30),Q
i−4
)
c) Q
i
← Q
i−5
+W[i] +Cst
i
where :
• i is the current step, ∈ { 0, 1, ..., 79 }.
• Q
i−1
, Q
i−2
, Q
i−3
, Q
i−4
, Q
i−5
are the I.V
• Cst
i
is defined among four predefined constants.
• ≪ r, the circular shifting to the left(rotating) by
r bits position.
• f
i
∈ { F, G, H, I }, where:
F(X,Y,Z) = (X ∧ Y) ∨ (
X ∧ Z)
G(X,Y,Z) = X ⊕ Y ⊕ Z
H(X,Y,Z) = (X ∧ Y) ∨ (X ∧ Z) ∨ (Y ∧ Z)
I(X,Y,Z) = G(X,Y,Z)
• W[i] is the i
th
word of 32 bits. These words are
built from the input message, as follows:
– if i < 16
W[i] is the i
th
32-bit word from the message
– if 16 ≤ i ≤ 79
W[i] ← (W[i− 3] ⊕ W[i − 8] ⊕ W[i− 14]
⊕ W[i− 16]) ≪ 1
SECRYPT2013-InternationalConferenceonSecurityandCryptography
436

Note SHA-1 differs from SHA-0 by the shifting of
W[i]. Finally, note in the following of this paper, 1
round for a MD⋆ (resp. SHA-⋆) function corresponds
to 16 (resp. 20) steps.
2.5 Notation about SAT Solving
Since our approach is based on the logical cryptanaly-
sis principles, this work is closely related to SAT solv-
ing techniques. The boolean SATisfiablilty problem
(short for SAT) is a well-known NP-Complete prob-
lem (Biere et al., 2009; Cook, 1971). Its interest has
grown significantly these past few years because of its
simplicity and its ability to express a wide set of var-
ious problems. Moreover, the last progresses about
solving techniques have led SAT to be a great and
competitive approach to tackle a wide range of indus-
trial and academic problems. Among them, logical
cryptanalysis is a very recent use of SAT formalism
and already have produced some new results.SAT is
of determining if a boolean expression F has at least
one assignment of truth value (also named an inter-
pretation) {TRUE, FALSE} to its variable so that it
is TRUE. In this paper, F is considered as a CNF-
formula(ConjunctiveNormal Form) which can be de-
fined as a set of clauses (interpreted as a conjunction)
where a clause is a set (interpreted as a disjunction) of
literals.
More precisely, let V = { v
1
, ..., v
n
} be a set
of n boolean variables. A signed boolean variable
is named a literal. We denote, v
i
and
v
i
the posi-
tive and negative literals referring to the variable v
i
respectively. The literal v
i
(resp.
v
i
) is TRUE (also
said satisfied) if the corresponding variable v
i
is as-
signed to TRUE (resp. FALSE). Literals are com-
monly associated with logical AND and OR operators
respectively denoted ∧ and ∨.
As mentioned above,
a clause is a disjunction of literals, that is for in-
stance v
1
∨
v
2
∨ v
3
∨ v
4
. Hence, a clause is sat-
isfied if at least one of its literals is satisfied. As a SAT
formula F is considered under CNF, it is satisfied if
all its clauses are satisfied. Finally, if its exists an as-
signment of V on {TRUE, FALSE} such as to make
the formula F TRUE, F is said SAT and UNSAT oth-
erwise.
2.6 Our Approach
The cryptanalysis of a hash function can be
done
thanks to an algebraic approach. Generally, two ways
are helpful to improve efficiently the solving method:
Gr¨obner basis (Faug`ere and Joux, 2003; Bettale et al.,
2012) and SAT solvers (Bard et al., 2007; Mironov and
Zhang, 2006). Among these, the best way to study the
function with a bitwise reasoning, i.e.in F
2
, seems to
be the one using a SAT formalism because SAT tools
propose an easy way to examine the problem mod-
eled in its finest granularity. In our knowledge,
no
work exists
about how analyzing and measuring the
security of hash function thanks to this approach. In
(De et al., 2007) and then in our previous work (Leg-
endre et al., 2012), the method used consists in en-
code the MD5 hash function
under its corresponding
CNF expression so that practically tackling the (sec-
ond)
preimage. In these works, some hash functions
are represented with a bitwise reasoning only by us-
ing boolean equations. Thus, the whole process is
described with the tiniest
modelling, then simplified
thanks to logical simplifications and finally inverted
reduced-step versions thanks to a
generic SAT solver.
In this paper, we
choose to reuse our SAT represen-
tation of MD⋆ and SHA-⋆ with aim to identify some
practical weaknesses that will allow future works on
collision and (second) preimage inversion.
In prac-
tice, we consider the CNF as a tool to examine the
structural behavior of the internal words of the pro-
cess by two different ways.
First, we searched to
outline the fact there are some special relations be-
tween variables as implications or equivalences.
This
can be done thanks to
an automatic logical reasoning.
Second, we use the CNF to estimate, thanks to statis-
tics and
within a genericframework, how behaveeach
variable (correlated to each digit of the Hashing Pro-
cess) in relation to
all others. From this, we deduced
classical and conditional probabilities. As a result,
we presented equivalences, quasi-equivalences and
quasi-implications that could be used in any cryptan-
alytic approach. In this sense, we finally talked about
logical cryptanalysis and presented a practical inver-
sion of a 23 steps SHA-1’s process.
3 LOGICAL REASONING
In (Legendre et al., 2012) we showed that using logi-
cal simplifications applied on a SAT formula describ-
ing a process of hashing
helps to tackle the second
preimage of MD5 up to 28 steps which is still, in our
knowledge, the best
practical inversion. Since this ap-
pears to be a promising way to break more steps, we
enriched the
original simplification process. In the
following, we describe logical simplifications we pro-
cess to learn information that could be helpful within
a reduced-step inversion of MD5 or SHA-1
.
3.1 Detection of Equivalences
The existence of a logical equivalency, from a point
FromaLogicalApproachtoInternalStatesofHashFunctions-HowSATProblemCanHelptoUnderstandSHA-*and
MD*
437

of view of a valid process of hashing, means that
at least two digits (it could be more) are linked by
their respective value in every model. Practically
and informally, this can be seen as a digit that has
always the same (or opposite) value as another one.
If such a case occurs, both digits represent the same
information and only one of them should be con-
sidered into the process. Such a relation is denoted
with the operator : ⇔. As an example, consider the
CNF formula F having the following clauses, the
detection of equivalencies can be computed as
:
c
1
= (a ∨
b) c
2
= (a∨ f)
c
3
= (b∨ c) c
4
= (c∨ d)
c
5
= (f ∨
g) c
6
= (g∨ h)
c
7
= (a∨ d ∨ e) c
8
= (a∨ h∨ e)
• If a is set to FALSE then you can directly deduce
that b, c, d and e must be set to FALSE, unless
to falsify F , thanks to the clauses c
1
, c
3
, c
4
and
c
7
respectively. Hence, we notice that a equals
to FALSE implies e equals to FALSE. We denote
this implication
a ⇒ e. The corresponding CNF
expression is
e∨ a. As a remark, this clause also
represents the implication e ⇒ a.
• In the same way, if a is set to TRUE then you can
imply that f, g, h are set to FALSE and e to TRUE
respectively.
• Consequently, since e ⇒ a and a ⇒ e, this means
that whatever could be the solution, a and e have
the same value. This is denoted a ⇔ e. There-
fore, you can substitute every e inthe formulaby a
(and vice versa). From this, may result a cascade
of new simplifications. For instance, proceeding
that substitution in F leads c
7
and c
8
to become
obsolete, a∨
a being tautological and so useless.
From a
pplying this type of treatments on our SAT
formulas results several equivalences. Some of them
are trivial.
In spite of this, others are not so. In the
following, we mention some examples.
• A Trivial Case:
F
1
[29] ⇔ Q
1
[29]. This equivalence is quite easy
to detect because F
1
= (Q
1
∧ Q
0
) ∨ (
Q
1
∧ Q
−1
)
and Q
0
and Q
−1
are I.V. and hence are constant.
This means that if Q
0
[i]
differs from Q
−1
[i] (i ∈
{0. . . 31}), then F
1
depends exclusively on Q
1
.
There is a relation of equivalence which appears
between F
1
and Q
1
which appears once on four
on average.
• Non Trivial Case:
This is the most interesting case. It seldom oc-
curs
within a general framework, but it gives a
pertinent information to cryptanalysts. We name
special case a non-trivial case which occurs in a
specific formula. For instance, if we apply our
treatment
on a CNF describing a preimage attack
of MD5, we exhibit equivalences that are not re-
lated
to the entire MD5 process but to the specific
instance. Thanks to that, if we consider a preim-
age attack on the 29 first steps of MD5 where the
reduced-step digest is set to 0, we then deduce
M
8
[2] ⇔
Q
24
[2], where M
8
is the 9
th
bloc of the
input message M.
• Direct Implication:
If two implications of the form a ⇒ b and a ⇒ b
occur then for all value of a, b equals to TRUE.
Consequently, b must not be set to FALSE unless
to falsify F . As an illustration, we deduce that
sC
39
[0] must be set to FALSE on our reduced-step
preimage attack of MD5.
3.2 Static Look-ahead and More
We apply a classic local treatment in SAT solv-
ing named Look-Ahead (Li and Anbulagan, 1997)
which consists in foreseeing the effects of choosing a
branching variable to evaluate one of its values. From
this evaluation,
it can infer an assignment or some in-
formations among equivalences (see section 3), fixed
literals and new binary clauses
. Hereafter, some de-
tails.
• Fixed literals:
i)
if a ⇒ false then a must be set to TRUE
• New binary clauses:
ii) if a ⇒ b then the clause (
a ∨ b) can be added
to F . This will be same if (a ∧ b)) ⇒ false
occurs.
iii) if a ⇒ (x
1
∧ x
2
∧ . . . ∧ x
n
) and
a ⇒ (y
1
∧
y
2
∧ . . . ∧ y
m
) then clauses (x
i
∨ y
j
), ∀(1 ≤ i ≤
n) and (1 ≤ j ≤ m) can be added to F .
• Subsuming Look-Ahead
By enhancing the principle of look-ahead, you
check multiple implications in order to produce
subsuming clause.
Let be C a clause of the
form: x
1
∨ x
2
∨ . . . ∨ x
i
∨ . . . ∨ x
k
.
iv) if
x
1
∧ x
2
∧ . . . ∧ x
i
⇒ false then C should be
replace by the clause (is subsumed by) x
1
∨x
2
∨
. . . ∨ x
i
in F .
v) if (x
1
∧
x
2
∧ . . . ∧ x
i
) ⇒ false then C is sub-
sumed by x
2
∨ . . . ∨ x
i
4 SPECIFIC PROBABILITIES
In this section, we define an experimental framework
SECRYPT2013-InternationalConferenceonSecurityandCryptography
438
that allows to study at the bit-level the behavior of a
hashing process. This framework uses a SAT formula
modeling a cryptosystem that has been previously de-
fined in (Legendre et al., 2012).
4.1 From a SAT Formula to get Statistics
The SAT formula F can be used as a tool. The assign-
ment of variables corresponding to the input message
leads the SAT engine to fix all the unassigned vari-
ables of F thanks to a linear and deterministic pro-
cess named unit propagation. This corresponds to the
hashing process and the complete assignment A of
variables of F is a solution. Actually, A gives useful
information on how a variable is set but also how two
variables are set in pairs (and more). This last remark
is interesting. Thus, memorizing each pair of vari-
ables allows us to appreciate the behavior of a vari-
able with respect to another. For instance, let v and w
be two boolean variables. From A, looking at v and w
at the same time lets to know which of the following
subsets of S appears:
{v = false∧ w = false} ; {v = false∧ w = true}
{v = true ∧ w = false} ; {v = true∧ w = true}
respectively denoted (v∧ w), (v∧ w), (v ∧ w), (v∧ w).
We establish a protocol to compute statistics from a
SAT formula F :
i) Create a random input message
ii) Assign this message and infers from F . It gener-
ates A.
iii) From A, for each pairs of variables,
memorize the
subset which appears in S
iv)
goto i) (This loop should be iterated n times)
v) Group and overlay all the subsets and divide by n.
From this, we obtain the probability to be 1 for each
couple of variables (v,w), denoted p(v∧ w).
4.2 Preliminary Remarks
The probability of a variable v to be 1 in a general
framework is determined by p(v) = p(v∧ v). More-
over, the conditional probability of a variable v given
w is determined by:
p(v|w) =
p(v∧ w)
p(w)
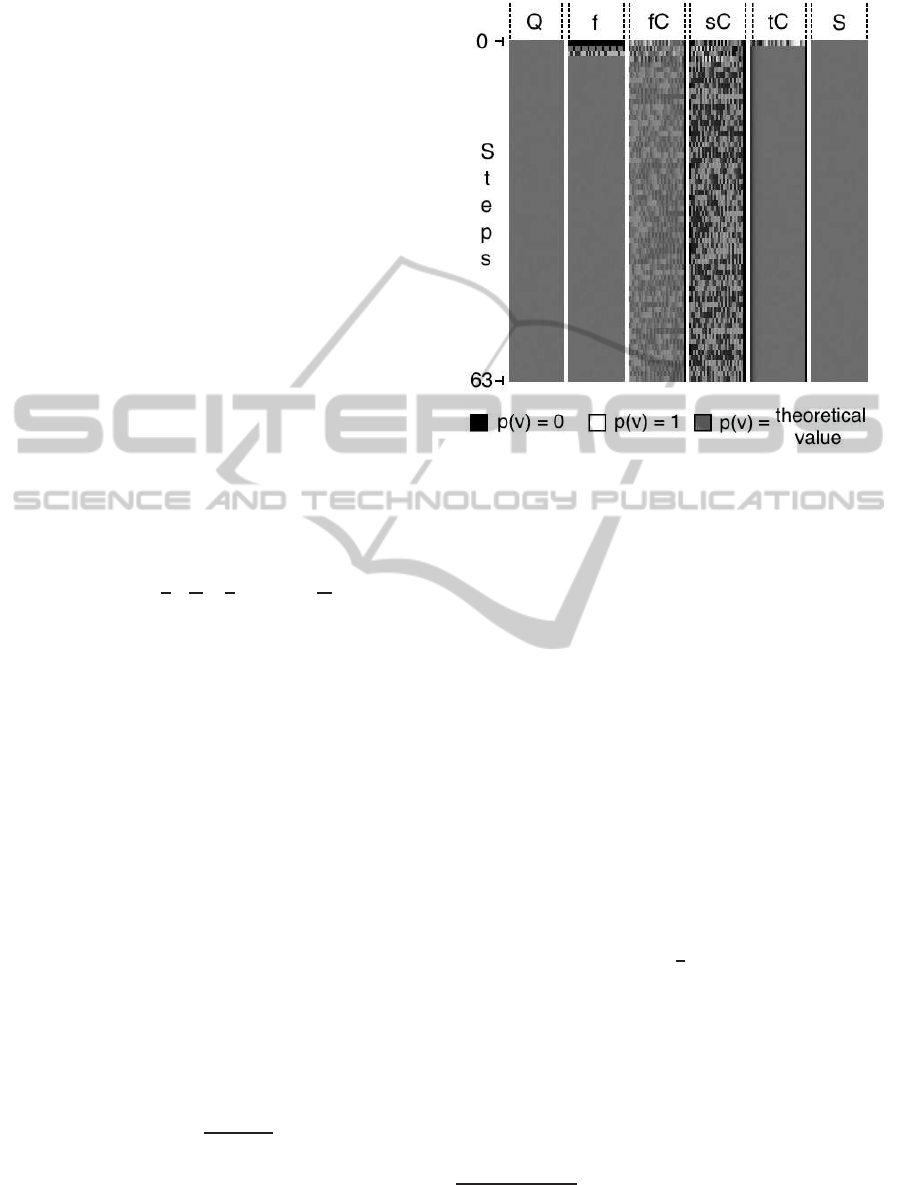
4.3 General Behavior of MD5
In one hand, we computed for each variable the theo-
Figure 1: Probability of a variable from the MD5 process,
to be 1, from step 0 to 63, sorted by type of 32-bit word on
big endian.
retical probabilities we should have in a general pro-
cess. In an other hand, we use our SAT formula rep-
resenting the MD5 hash function in order to com-
pute classical and conditional probabilities. Then, we
compared these two type of probabilities.
Within this
way, we drew a PGM
1
image representing this com-
parison, vertically sort by step and horizontally sort
by type of words (see fig 1). The used notation is the
one defined in 2.2. If the pixel is black, the probabil-
ity derived from the SAT formula differs by the theo-
retical probability by tending to 0, and if the pixel is
white, the probability differs by tending to 1. Conse-
quently, the more the pixel is white or black, the more
the practical probability is far from the theory.
In the columnsrepresentingthe internalstates (Q),
the non-linear functions (f), the carries of the two
operands addition (tC) and the four operands sum (S),
the gray is uniform and corresponds to the theoreti-
cal probability which is ≃
1
2
. This means, the words
are totally random for each bit, as expected. How-
ever, this is not the case for the columns representing
the carries of the four operands addition (fC and sC).
Hereafter, some details and explanations.
4.3.1 About Carries
The theoretical probabilities to be 1 for the first carry
2
turns around 0.58. Focus on step 17, we get for in-
1
Portable GrayMap file format
2
Except the five first least significant bit where the prob-
abilities are slightly higher.
FromaLogicalApproachtoInternalStatesofHashFunctions-HowSATProblemCanHelptoUnderstandSHA-*and
MD*
439
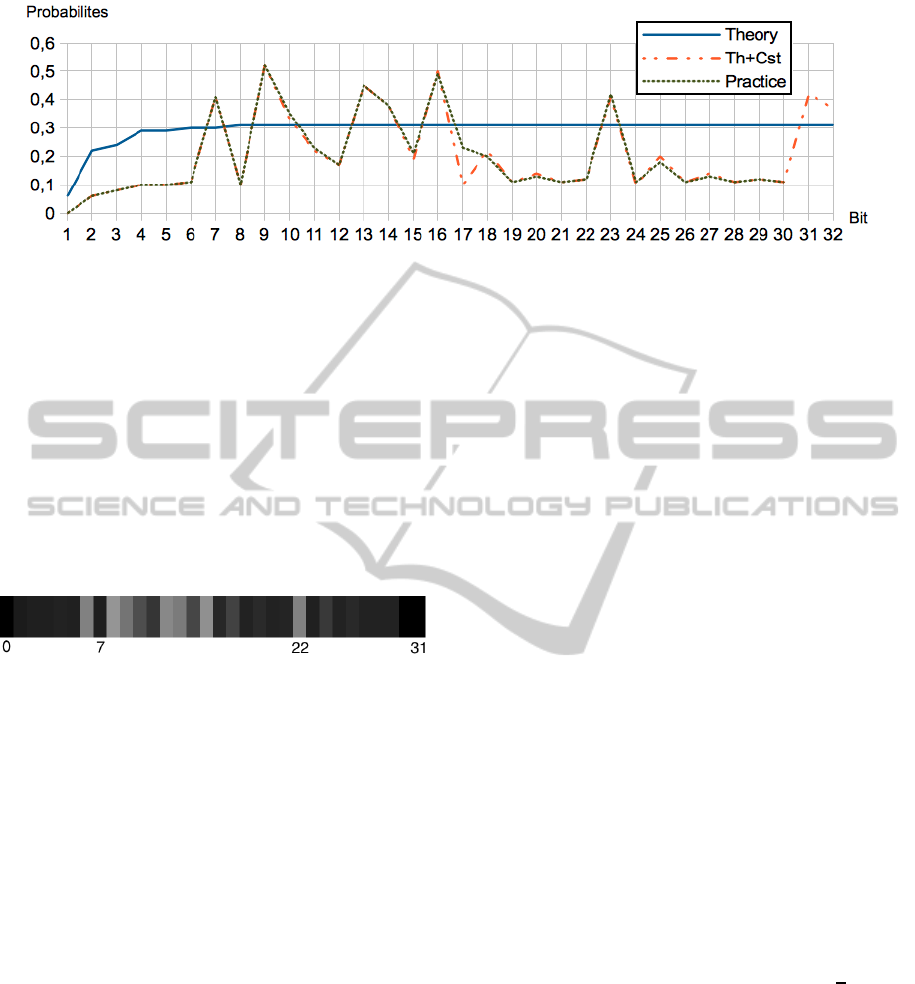
Figure 2: Comparison between theoretical probabilities with (Th+Cst) and without (Theory) a fixed round constant, and com-
puted probabilities in our benchmark (Practice). Here we can observe that the curve representing the theory by considering a
constant and the curve extracted from our statistical database are grouped. This means, they have the same behavior, which
differs from the theory.
stance p(fC
17
[5]) = 0.67 and p(fC
17
[23]) = 0.49. The
gap with the theory is approximately 15%. However,
the gaps are widening even more so if we look at the
second carries.
The figure 3 is a zoom in the second carries, step 17.
We can observe two things: probabilities are not uni-
forms (because there are several gray tones) and some
go far away of the theoretical probability by tending
to 0, for instance the bit 7, and others to 1, for instance
the bit 22.
Figure 3: Second carries step 17, on big endian.
Our explanation is this phenomena is due to round
constants. Our idea is the fixing of a round constant
consists in assigning an operand in the general struc-
ture of the addition and has for consequence to create
a new structure totally defined by the round constant.
To
confirm this point, we computed theoretical prob-
abilities of the variables which are involved in
this
addition by considering one operand fixed. Contin-
uing with the step 17, we concretely fix an operand to
the value
0xc040b340
and observe how the structure
behaves. The result is unequivocal: the experience
confirms the practice because the observed probabil-
ities in practice are very closed to the ones observed
when we fixed a round constant (see fig 2 to com-
pare probabilities). This means, in our point of view,
round constants weaken the hashing process because
several probabilities become very far from their the-
oretical
values. This implies that the MD5 process is
not entirely random.
As an illustration, the bit 7, step
17 has a probability of 0.10 instead of 0.31 in theory
and the bit 22 has a probability of 0.41.
4.4 Gather Probabilistic and Judicious
Information from MD5
Once we built this statistical database, we can apply
some specific treatments to detect factual relations as
for instance fixed variables and equivalences but also
probabilistic relations as quasi-fixed variables, quasi-
implications or quasi-equivalences.
4.4.1 Factual Relations
We can identify statistics which represent a fixed vari-
able just by extracting probabilities such as p(v) = 0
or p(v) = 1. For instance, in the MD5 process, the vari-
able corresponding to sC
1
[26] is always assigned to 0.
It’s also possible to detect equivalences. Let be v and
w two boolean variables. We have:
1) if p(v) = p(v∧ w), then v ⇒ w
In others words, if p(w|v) = 1, then v ⇒ w
2) if p(v|w) = p(w|v) = 1, then v ⇔ w
4.4.2 Probabilistic Relations
Let be t a threshold such as t ≤ p(v) < 1. We call
quasi-fixed variable a variable such as whatever the
instance, the variable has a probability p(v) to be 1
higher than t. This means, the variable v (resp
v) is set
to 1 (resp 0) in (p(v)*100) % of cases. We call quasi-
implication a relation between two variables such as:
p(w|v) ≥ t and note this relation v ; w
Finally, we call quasi-equivalence a relation between
two variables such as:
p(w|v) ≥ t, p(v|w) ≥ t and note this relation v < w
In this paper, we also talked about quasi-relation
to mentioned a probabilistic relation.
SECRYPT2013-InternationalConferenceonSecurityandCryptography
440
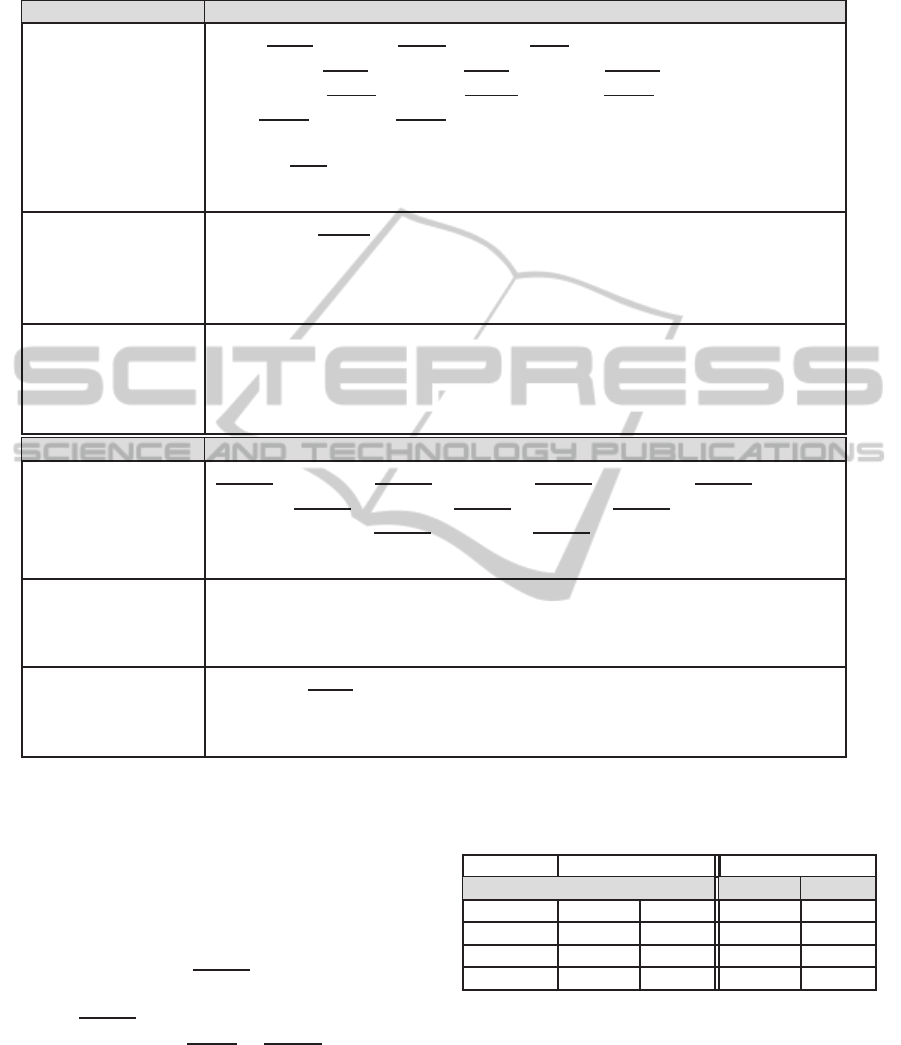
Table 1: Some of Equivalences, Quasi-Equivalences and Quasi-implications detected from the MD5 and the SHA-1 processes
with a threshold t = 0.99. The used notation is the one presented in 2.2. Moreover Hx and cHx are variables about the hash.
Relation From MD5
Equivalences tC
0
[0] ⇔ Q
1
[0] , S
0
[25] ⇔ Q
1
[0] , S
0
[0] ⇔ fC
0
[0] , M
0
[0] ⇔ fC
0
[0]
Hb[0] ⇔ cHb[0] , Ha[0] ⇔ cHa[0] , cHd[1] ⇔ Hd[1]
Q
62
[1] ⇔ Hd[1] , cHc[1] ⇔ Hc[1] , Q
63
[1] ⇔ Hc[1]
Q
64
[0] ⇔ Hb[0] , Q
61
[0] ⇔ Ha[0] , Hd[0] ⇔ Q
62
[0] , Hc[0] ⇔ Q
63
[0]
f
1
[ j] ⇔ Q
1
[ j] for j ∈ { 0, 8, 9, 13,18, 22, 24, 25, 26, 29, 30 }
f
1
[ j] ⇔ Q
1
[ j] for j ∈ { 1, 2, 4, 5,6, 10, 12, 14, 17, 20, 21, 28 }
Quasi-Equivalences Q
1
[21] < M
0
[14] , Q
61
[8] < Ha[8] , Q
61
[8] < cHa[8]
Ha[8] < Q
61
[8] , Ha[8] < cHa[8] , cHa[8] < Q
61
[8] , M
0
[14] < f
1
[21]
cHa[8] < Ha[8] , f
1
[21] < M
0
[14] , M
0
[14] < Q
1
[21]
Quasi-Implications M
0
[14] ; Q
1
[21] , Q
1
[21] ; M
0
[14] , Ha[8] ; Q
16
[8] , Hb[28] ; cHb[30]
Q
61
[8] ; Ha[8] , cHa[8] ; Q
61
[8] , Q
64
[28] ; cHb[30] , cHa[8] ; Q
61
[8]
Q
61
[8] ; Ha[8] , Ha[8] ; Q
61
[8] , cHa[8] ; Ha[8] , Ha[8] ; cHa[8]
Relation From SHA-1
Equivalences sC
0
[28] ⇔ fC
0
[28] , sC
0
[27] ⇔ fC
0
[27] , sC
0
[25] ⇔ fC
0
[25] , sC
0
[24] ⇔ sC
0
[17]
sC
0
[21] ⇔ fC
0
[21] , sC
0
[20] ⇔ fC
0
[20] , sC
0
[19] ⇔ fC
0
[19]
sC
0
[15] ⇔ fC
0
[15] , sC
0
[12] ⇔ fC
0
[12]
Quasi-Equivalences sC
0
[28] < sC
0
[17] , sC
0
[27] < fC
0
[28] , sC
0
[24] < cHc[7] , sC
0
[24] < fC
0
[28]
sC
0
[17] < cHc[7] , sC
0
[17] < fC
0
[28] , fC
1
[16] < sC
1
[16] , sC
1
[16] < fC
1
[16]
Quasi-Implications M
0
[8] ; sC
1
[14] , M
1
[13] ; sC
1
[14] , M
1
[10] ; sC
1
[14]
M
2
[25] ; sC
2
[27] , M
3
[27] ; sC
3
[27]
4.4.3 Application to MD5 and SHA-1
In this part, we just focus on the detection of proba-
bilistic relations, because detecting factual relations is
already done by the logical preprocessing (section 3).
In practice, we applied a specific treatment which
extract all the specific probabilities that correspond
to logical simplifications. For instance, by defining
t = 0.99, we found p(
M
0
[14] | f
2
[21]) = 0.9969
from the MD5 process. This means we have
f
2
[21] ; M
0
[14] and this can be added to the for-
mula by the new clause (
f
2
[21] ∨ M
0
[14]).
We concretely illustrate our experimentations
about MD5 and SHA-1 by giving a portion of differ-
ent relations we detected in the table 1. We can ob-
serve for instance a lot of relations in the first steps
facilitating the prediction of the behavior of the vari-
Table 2: Detection of quasi-fixed variables (q-Fixed) and
quasi-equivalences (q-Equi) in the MD5 and SHA-1 pro-
cesses according to a threshold.
MD5 SHA-1
Treshold q-Fixed q-Equi q-Fixed q-Equi
0.995 2 10 1 8
0.99 5 29 5 44
0.985 9 79 8 88
0.98 12 105 13 169
ables. Furthermore,we have relations between carries
but also others involving states, the input message or
non-linear functions. In our knowledge, this is the
only approach where computed probabilities are con-
cretely put together in order to emerge new relations
that could be exploit in practice. To put the stress on
the interest of our experimentations, we referenced in
the table 2 the number of quasi-fixed variables and
quasi-equivalences found from the MD5 and SHA-1
FromaLogicalApproachtoInternalStatesofHashFunctions-HowSATProblemCanHelptoUnderstandSHA-*and
MD*
441

hashing processes, according to a threshold t. We can
see that more the threshold is low, more we get infor-
mation about special relations between variables.
5 EXPORT WEAKNESSES IN A
PRACTICAL FRAMEWORK
Logical cryptanalysis (Massacci and Marraro, 2000;
Mironov and Zhang,2006) offersa perfect framework
to exploit concrete weaknesses. Generally, it consists
in tackle a crypto-system thanks to a two phases pro-
cess where in a first part the problem is defined un-
der a SAT formalism and in a second part it is solved
thanks to the use of SAT solvers. In this manner,
weaknesses can be used to help to reduce the practical
complexity of a preimage problem during the boolean
encoding or directly during the solving phase.
5.1 Reduction of the Practical
Complexity
As we find fixed and quasi-fixed variables, we can
reduce the practical complexity of a problem by as-
signing these variables. Indeed, for instance if a vari-
able v is fixed to 1 then all the clauses which contains
the corresponding positive literal v are SAT and all the
clauses which contains the correspondingnegativelit-
eral v are reduced. Moreover, as we find equivalences
and quasi-equivalences, we can replace a variable by
an other. This can provoke many simplifications as
for instance the ones presented in this paper in 3.
Concretely, we alternatively preprocessed our SAT
formulas and injected information uprooted from our
detection method. In this way, we reduced the SHA-
1 and MD5 formulas according to the statistics in ta-
ble 3. The formulas’s sizes are directly affected by the
number of variables (Nb Var), the number of literals
(Nb Lit) and the number of clauses (Nb Cl) used to
represent the problem. In addition, we also counted
the number of binary clauses (Bin cl) in the formu-
las since these clauses are very interesting to increase
the efficiency of SAT solving
3
. In this manner, we can
observe that applying our treatments (pp) allows to
decrease the sizes of our SAT formulas and enrich the
practical complexity of their SAT solving thanks to an
importing of binary clauses for both SHA-1 and MD5.
5.2 Improve Heuristic in SAT Solvers
A good way to solve algebraic systems, especially
3
Solving a SAT problem is polynomial if it is composed
only of binary clauses.
Table 3: Reduction of the SAT formulas sizes for MD5 and
SHA-1 with an enrichment of information.
MD5
Nb Var Nb Lit Nb Cl Bin cl
Before pp 12749 ≈1.23M 224653 381
After pp 12677 ≈ 0.98M 206807 2252
SHA-1
Nb Var Nb Lit Nb Cl Bin cl
Before pp 12771 ≈ 2.21M 375195 908
After pp 12732 ≈ 2.18M 374541 1454
boolean systems is the use of complete SAT solvers.
These ones are mainly based on the DPLL (Davis
et al., 1962) or the CDCL (Zhang et al., 2001) algo-
rithms which consist in a systematic enumeration of
truth assignments thanks to a binary search-tree
4
At
each node, their is a policy choice made to decide the
next variable to be assign.
Our probabilities can be a good mean to improve
the splitting choice policy of a dedicated SAT solver.
In practice, the heuristic branching compute with a
very precise evaluation the new node of the binary
tree, but this choice is often difficult. In these cases,
probabilities can help to enrich the evaluation, in par-
ticular when a variable has a very high probabil-
ity to be 0 or 1.
5.3 Tackle the Preimage of Hash
Functions
In order to tackle the preimage of a hash function,
we can instantiate the variables corresponding to a
chosen hash in a CNF representing a reduced-step
process of the function. Then, thanks to the logical
simplifications presented in this paper, both factual
and probabilistic (section 3), the formula is then
preprocessed to decrease its practical complexity. Fi-
nally we apply a SAT engine to search for a solution.
If the formula is solved, necessarily all the variables
are assigned, even those from the input message.
In practice, our best result in tackling the preimage
of MD5 is about 1 round and 12 steps. About
SHA-0 and SHA-1 we inverted 1 round 3 steps. The
formula for SHA-1 is composed of 75,974 clauses
and 3,321 variables. In our knowledge, this is not
the best practical result about the inversion of SHA-
⋆ (Canni`ere and Rechberger, 2008)(Christian, 2010).
Nevertheless, our work has an original approach and
is hopeful to conclude in better results. Hereafter, an
instance of a SHA-1 hash and its corresponding input,
obtained at the end of the hash function and not by
the compression function.
4
The reader should refer to (Biere et al., 2009)
SECRYPT2013-InternationalConferenceonSecurityandCryptography
442

1 round 3 steps on SHA-1 (23 steps)
Fixed Hash:
0x00000000 0x00000000 0x00000000 0x00000000
Input found:
0x35691c1a 0xead7eb26 0xcac76b0e 0x00000000
0x51e43c45 0xaa8bc12a 0xdb8fa47c 0x00000000
0x637c1517 0x80abea2e 0x9339f44e 0x00000000
0x6367caee 0xbc8920ec 0x1084c8d7 0x45075a9e
6 CONCLUSIONS
In this paper
5
, we propose a based logical approach
to bring out some cryptographic weaknesses in hash
functions. Indeed, we noticed that model the function
in a binary field (F
2
), allows to point out several vari-
ables which have not a random behavior, as expected
in a hashing process. In this context, certain internal
words, especially carries, are weak and the function
may be tackled by these partially open doors to get
new information.
We confirmed this point through an experimentation
where we foundequivalences, quasi-equivalencesand
quasi-implication by two different ways: an auto-
matic logical reasoning and a probabilistic approach.
Thanks to the first technique, we show factual rela-
tions that could be used in a general case. More-
over, the probabilistic method allow to outline an
overview of quasi-relation. This attests that the vari-
ables are strongly correlated and their relations can
be exploited to gather new information. As a re-
sult, we presented a set of equivalences and quasi-
equivalences and explain why they exist through an
observation of the influence of round constants. Fi-
nally, we talked about logical cryptanalysis by im-
porting these weaknesses in SAT formulas. In this
sense, we show how to improve an heuristic in SAT
solvers and show practical preimage attacks against
SHA-1.
In our knowledge, this is the only approach where
logical and probabilistic deductions highlights weak-
nesses in hash functions. Moreover, our method is
generic and so we can also export our method on
others cryptographic schemes and underline bitwise
weaknesses that could be exploited. Interestingly, im-
proving heuristic in SAT solvers seems to be a very
hopeful way to improve practical preimage attacks as,
nowadays, it does not exist any dedicated solver to
logical cryptanalysis.
5
This work is supported by the Direction G´en´erale de
l’Armement : http://www.defense.gouv.fr/dga
REFERENCES
Bard, G. V., Courtois, N. T., and Jefferson., C. (2007). Ef-
ficient methods for conversion and solution of sparse
systems of low-degree multivariate polynomials over
gf(2) via sat-solvers. Cryptology ePrint Archive, Re-
port 2007/024.
Bettale, L., Faug`ere, J.-C., and Perret, L. (2012). Solving
polynomial systems over finite fields: improved anal-
ysis of the hybrid approach. In ISSAC, pages 67–74.
Biere, A., Heule, M. J. H., Maaren, H. V., and Walsh, T.,
editors (2009). Handbook of Satisfiability, volume
185 of Frontiers in Artificial Intelligence and Appli-
cations. IOS Press.
Biham, E. and Shamir, A. (1990). Differential cryptanalysis
of des-like cryptosystems. In CRYPTO, pages 2–21.
Canni`ere, C. D. and Rechberger, C. (2008). Preimages for
reduced sha-0 and sha-1. In CRYPTO, pages 179–202.
Christian, R. (2010). Second-preimage analysis of reduced
sha-1. In Proceedings of the Australasian conference
on Information security and privacy, pages 104–116.
Cook, S. A. (1971). The Complexity of Theorem Proving
Procedures. In 3
rd
ACM Symp. on Theory of Comput-
ing, Ohio, pages 151–158.
Damg˚ard, I. (1989). A design principle for hash functions.
In CRYPTO, pages 416–427.
Davis, M., Logemann, G., and Loveland, D. (1962). A Ma-
chine Program for Theorem-Proving. Journal Associ-
ation for Computing Machine, (5):394–397.
De, D., Kumarasubramanian, A., and Venkatesan, R.
(2007). Inversion attacks on secure hash functions us-
ing satsolvers. In SAT, pages 377–382.
Faug`ere, J.-C. and Joux, A.(2003). Algebraic Cryptanalysis
of Hidden Field Equation (HFE) Cryptosystems Using
Gr¨obner Bases. In Advances in Cryptology - CRYPTO
2003, volume 2729, pages 44–60.
Knuth, D. E. (1997). The art of computer program-
ming, volume 2 (3rd ed.): seminumerical algorithms.
Addison-Wesley Longman Publishing Co., Inc.
Legendre, F., Dequen, G., and Krajecki, M. (2012). Invert-
ing thanks to sat solving - an application on reduced-
step md*. In SECRYPT, pages 339–344.
Li, C.-M. and Anbulagan (1997). Heuristics based on unit
propagation for satisfiability problems. In the Fif-
teenth International Joint Conference on Artificial In-
telligence (IJCAI97), Nagoya (JAPAN), page 366371.
Massacci, F. and Marraro, L. (2000). Logical cryptanalysis
as a sat problem. J.Autom.Reasoning, pages 165–203.
Matsui, M. and Yamagishi, A. (1992). A new method
for known plaintext attack of feal cipher. In EURO-
CRYPT, pages 81–91.
Merkle, R. (1989). One way hash functions and des. In
CRYPTO, pages 428–446.
Mironov, I. and Zhang, L. (2006). Applications of sat
solvers to cryptanalysis of hash functions. In SAT,
pages 102–115.
Zhang, L., Madigan, C., Moskewicz, M., and Malik, S.
(2001). Efficient conflict driven learning in a boolean
satisfiability solver. In ICCAD.
FromaLogicalApproachtoInternalStatesofHashFunctions-HowSATProblemCanHelptoUnderstandSHA-*and
MD*
443
