
A FRAMEWORK FOR QOS-AWARE EXECUTION OF
WORKFLOWS OVER THE CLOUD
Moreno Marzolla
1
and Raffaela Mirandola
2
1
Universit`a di Bologna, Dipartimento di Scienze dell’Informazione, Mura A. Zamboni 7, I-40127 Bologna, Italy
2
Politecnico di Milano, Dipartimento di Elettronica e Informazione, Piazza Leonardo da Vinci, I-20133 Milano, Italy
Keywords:
Cloud Computing, Workflow Engine, Self-management, SLA Management.
Abstract:
The Cloud Computing paradigm is providing system architects with a new powerful tool for building scalable
applications. Clouds allow allocation of resources on a ”pay-as-you-go” model, so that additional resources
can be requested during peak loads and released after that. In this paper we describe SAVER (qoS-Aware
workflows oVER the Cloud), a QoS-aware algorithm for executing workflows involving Web Services hosted
in a Cloud environment. SAVER allows execution of arbitrary workflows subject to response time constraints.
SAVER uses a simple Queueing Network (QN) model to identify the optimal resource allocation; specifically,
the QN model is used to identify bottlenecks, and predict the system performance as Cloud resources are
allocated or released. Our approach has been validated through numerical simulations, whose results are
reported in this paper.
1 INTRODUCTION
The emerging Cloud computing paradigm is rapidly
gaining consensus as an alternative to traditional IT
systems. Informally, Cloud computing allows com-
puting resources to be seen as a utility, available on
demand. Cloud services can be grouped into three
categories (Zhang et al., 2010): Infrastructure as a
Service (IaaS), providing low-level resources such
as Virtual Machines (VMs); Platform as a Service
(PaaS), providing software development frameworks;
and Software as a Service (SaaS), providing whole
applications. The Cloud provider has the responsibil-
ity to manage the resources it offers so that the user re-
quirements and the desired Quality of Service (QoS)
are satisfied.
In this paper we present SAVER (qoS-Aware
workflows oVER the Cloud), a workflow engine pro-
vided as a SaaS. The engine allows different types
of workflows to be executed over a set of Web Ser-
vices (WSs). In our scenario, users negotiate QoS re-
quirements with the service provider; specifically, for
each type c of workflow, the user may request that the
average execution time of the whole workflow should
not exceed a threshold R
+
c
. Once the QoS require-
ments have been negotiated, the user can submit any
number of workflows of the different types. Both the
submission rate and the time spent by the workflows
on each WS can fluctuate over time.
SAVER uses an underlying IaaS Cloud to provide
computational power on demand. The Cloud hosts
multiple instances of each WS, over which the work-
load can be balanced. If a WS is heavily used, SAVER
will increase the number of instances by requesting
new resources from the Cloud. System reconfigura-
tions are triggered periodically, when instances are
added or removed where necessary.
SAVER uses a open, multiclass Queueing Net-
work (QN) model to predict the response time of
a given Cloud resource allocation. The parameters
which are needed to evaluate the QN model are ob-
tained by passively monitoring the running system.
The performance model is used within a greedy strat-
egy which identifies an approximate solution to the
optimization problem minimizing the number of WS
instances while respecting the Service Level Agree-
ment (SLA).
The remainder of this paper is organized as fol-
lows. In Section 2 we give a precise formulation
of the problem we are addressing. In Section 3 we
describe the Queueing Network performance model
of the Cloud-based workflow engine. SAVER will
be fully described in Section 4, including the high-
level architecture and the details of the reconfigura-
tion algorithms. The effectiveness of SAVER have
been evaluated using simulation experiments, whose
216
Marzolla M. and Mirandola R..
A FRAMEWORK FOR QOS-AWARE EXECUTION OF WORKFLOWS OVER THE CLOUD.
DOI: 10.5220/0003898702160221
In Proceedings of the 2nd International Conference on Cloud Computing and Services Science (CLOSER-2012), pages 216-221
ISBN: 978-989-8565-05-1
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)
results will be discussed in Section 5. In Section 6 we
review the scientific literature and compare SAVER
with related works. Finally, conclusions and future
works are presented in Section 7.
2 PROBLEM FORMULATION
SAVER is a workflow engine that receives workflows
from external clients, and executes them over a set
of K WS 1,...,K. At any given time t, there can be
C(t) different workflow types (or classes); for each
class c = 1,... ,C(t), clients define a maximum al-
lowed completion time R
+
c
. The number of workflow
classes C(t) does not need to be known in advance;
furthermore, it is possible to add or remove classes at
any time.
We denote with λ
c
(t) the average arrival rate of
class c workflows at time t. Since all WSs are shared
between the workflows, the completion time depends
both on arrival rates λ(t) =
λ
1
(t),.. . ,λ
C(t)
(t)
, and
on the utilization of each WS.
To satisfy the response time constraints, the sys-
tem must adapt to cope with workload fluctuations.
To do so, SAVER relies on a IaaS Cloud which main-
tains multiple instances of each WS. We denote with
N
k
the number of instances of WS k; a system con-
figuration N(t) = (N
1
(t),.. . ,N
K
(t)) is an integer vec-
tor representing the number of allocated instances of
each WS. When the workload intensity increases,
additional instances are created to eliminate the bot-
tlenecks; when the workload decreases, surplus in-
stances are shut down and released.
The goal of SAVER is to minimize the total num-
ber of WS instances while maintaining the mean ex-
ecution time of type c workflows below the threshold
R
+
c
, c = 1,...,C(t). Formally, we want to solve the
following optimization problem:
minimize f (N(t)) =
K
∑
k=1
N
k
(t) (1)
subject to R
c
(N(t)) ≤ R
+
c
for all c = 1,.. . ,C(t)
N
i
(t) ∈ {1,2,3, ...}
where R
c
(N(t)) is the mean execution time of type c
workflows when the system configuration is N(t).
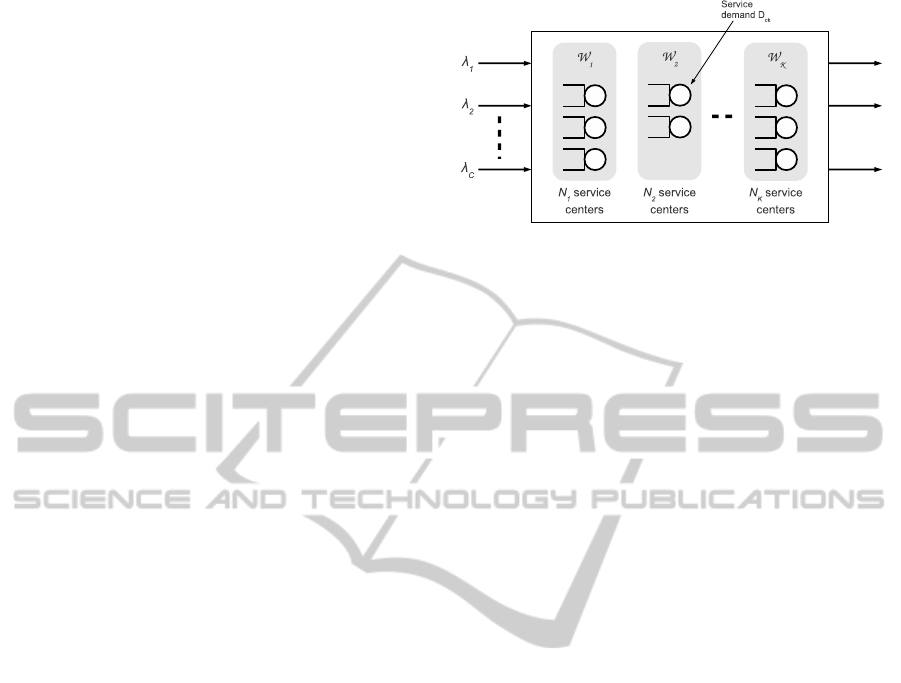
3 PERFORMANCE MODEL
In this section we describe the QN performance
model which is used to plan a system reconfigura-
tion. We model the system using the open, multi-
class QN model (Lazowska et al., 1984) shown in
Figure 1: Performance model based on an open, multiclass
Queueing Network.
Fig. 1. Each server represents a single WS instance;
thus, WS k is represented by N
k
queueing centers, for
each k = 1, ...,K. N
k
can change over time, as re-
sources are added or removed from the system.
In our QN model there are C different classes of
requests: each request represents a workflow, thus
workflow types are directly mapped to QN request
classes. In order to simplify the analysis of the model,
we assume that the inter-arrival time of class c re-
quests is exponentially distributed with arrival rate λ
c
.
The interaction of a type c workflow with WS k is
modeled as a visit of a class c request to one of the N
k
queueing centers representing WS k. We denote with
R
ck
(N) the total time (residence time) spent by type c
workflows on one of the N
k
instances of WS k for a
given configuration N. The residence time is the sum
of two terms: the service demand D
ck
(N) (average
time spent by a WS instance executing the request)
and queueing delay (time spent by a request in the
waiting queue).
The utilization U
k
(N) of an instance of WS k is
the fraction of time the instance is busy processing re-
quests. If the workload is evenly balanced, then both
the residence time R
ck
(N) and the utilization U
k
(N)
are almost the same for all N
k
instances.
4 SAVER ARCHITECTURE
SAVER is a reactive system based on the Monitor-
Analyze-Plan-Execute (MAPE) control loop shown
in Fig. 2. During the Monitor step, SAVER collects
operational parameters by observing the running sys-
tem. The parameters are evaluate during the Analyze
step; if the system needs to be reconfigured (e.g., be-
cause the observed response time of class c work-
flows exceeds the threshold R
+
c
, for some c), a new
configuration is identified in the Plan step. We use
the QN model described in Section 3 to evaluate dif-
ferent configurations and identify an optimal server
allocation such that all QoS constraints are satisfied.
AFRAMEWORKFORQOS-AWAREEXECUTIONOFWORKFLOWSOVERTHECLOUD
217

Figure 2: SAVER Control Loop.
U
k
(N) =
C
∑
c=1
λ
c
D
ck
(N) (2)
R
ck
(N) =
D
ck
(N)
1−U
k
(N)
(3)
R
c
(N) =
K
∑
k=1
N
k
R
ck
(N) (4)
Figure 3: Equations for the QN model of Fig. 1.
Finally, during the Execute step, the new configura-
tion is applied to the system: WS instances are cre-
ated or destroyed as needed by leveraging the IaaS
Cloud. Unlike other reactive systems, SAVER can
plan complex reconfigurations, involving multiple ad-
ditions/removals of resources, in a single step.
4.1 Monitoring System Parameters
The QN model is used to estimate the execution time
of workflow types for different system configurations.
To analyze the QN it is necessary to know two param-
eters: (i) the current arrival rate of type c workflows,
λ
c
, and (ii) the mean service demand D
ck
(M) of type
c workflows on an instance of WS k, for the current
configuration M.
The parameters above can be computed by moni-
toring the system over a time interval of suitable du-
ration T. The arrival rates λ
c
can be estimated by
counting the number A
c
or arrivals of type c work-
flows which are submitted over the observation pe-
riod; then λ
c
can be defined as λ
c
= A
c
/T.
Measuring the service demands D
ck
(M) is more
difficult because they must not include the time spent
by a request waiting to start service. If the WSs
do not provide detailed timing information (e.g., via
their execution logs), it is possible to estimate D
ck
(M)
from the measured residence time R
ck
(M) and uti-
lization U
k
(M). We use the equations shown in Fig-
ure 3, which hold for the open multiclass QN model
in Fig. 1. These equations describe known properties
of open QN models (see (Lazowska et al., 1984) for
details).
The residence time is the total time spent by a type
c workflowwith one instance of WS k, includingwait-
ing time and service time. The workflow engine can
measure R
ck
(M) as the time elapsed from the instant
a type c workflow sends a request to one of the N
k
instances of WS k, to the time the request is com-
pleted. The utilization U
k
(M) of an instance of WS
k can be obtained by the Cloud service dashboard (or
measured on the computing nodes themselves). Us-
ing (3) the service demands can be expressed as
D
ck
(M) = R
ck
(M)(1−U
k
(M)) (5)
Let M be the current system configuration; let us
assume that, under configuration M, the observed ar-
rival rates are λ = (λ
1
,... ,λ
C
) and service demands
are D
ck
(M). Then, for an arbitrary configuration N,
we can combine Equations (3) and (4) to get:
R
c
(N) =
K
∑
k=1
N
k
D
ck
(N)
1−U
k
(N)
(6)
The current total class c service demand on all
instances of WS k is M
k
D
ck
(M), hence we can ex-
press service demands and utilizations of individual
instances for an arbitrary configuration N as:
D
ck
(N) =
M
k
N
k
D
ck
(M) (7)
U
k
(N) =
M
k
N
k
U
k
(M) (8)
Thus, we can rewrite (6) as
R
c
(N) =
K
∑
k=1
D
ck
(M)M
k
N
k
N
k
−U
k
(M)M
k
(9)
which allows us to estimate the response time R
c
(N)
of class c workflows for any configuration N, given
information collected by the monitor for the current
configuration M.
4.2 Finding a New Configuration
In order to find an approximate solution to the opti-
mization problem (1), SAVER starts from the current
configuration M, which may violate some response
time constraints, and executes Algorithm 1. After col-
lecting device utilizations, response times and arrival
rates, SAVER estimates the service demands D
ck
us-
ing Eq. (5).
Then, SAVER identifies a new configuration N ≻
M
1
by calling the function ACQUIRE() (Algorithm 2).
The new configuration N is computed by greedily
adding new instances to bottleneck WSs. The QN
model is used to estimate response times as instances
are added: no actual resources are instantiated from
1
N ≻ M iff N
k
≥ M
k
for all k = 1,..., K, the inequality
being strict for at least one value of k
CLOSER2012-2ndInternationalConferenceonCloudComputingandServicesScience
218

Algorithm 1: The SAVER Algorithm.
Require: R
+
c
: Maximum response time of type c work-
flows
1: Let M be the initial configuration
2: loop
3: Monitor R
ck
(M), U
k
(M), λ
c
4: for all c := 1,...,C; k := 1,...,K do
5: Compute D
ck
(M) using Eq. (5)
6: N := Acquire(M,λ,D(M),U(M))
7: for all c := 1,...,C; k := 1,...,K do
8: Compute D
ck
(N) and U
k
(N) using Eq. (7) and (8)
9: N
′
:= Release(N,λ,D(N),U(N))
10: Apply the new configuration N
′
to the system
11: M := N
′
{Set N
′
as the current configuration M}
Algorithm 2: Acquire(N,λ,D(N),U(N)) → N
′
.
Require: N System configuration
Require: λ Current arrival rates of workflows
Require: D(N) Service demands at configuration N
Require: U(N) Utilizations at configuration N
Ensure: N New system configuration
1: while
R
c
(N) > R
+
c
for any c
do
2: b := argmax
c
R
c
(N) − R
+
c
R
+
c
c = 1,...,C
3: j := argmax
k
{ R
b
(N) − R
b
(N+ 1
k
) | k = 1,..., K}
4: N := N+ 1
j
5: Return N
the Cloud service at this time.
The configuration N returned by the function AC-
QUIRE() does not violate any constraint, but might
contain too many WS instances. Thus, SAVER in-
vokes the function RELEASE() (Algorithm 3) which
computes another configuration N
′
≺ N by remov-
ing redundant instances, ensuring that no constraint
is violated. To call procedure RELEASE() we need
to estimate the service demands D
ck
(N) and utiliza-
tions U
k
(N) with configuration N. These can be eas-
ily computed from the measured values for the current
configuration M.
After both steps above, N
′
becomes the new cur-
rent configuration: WS instances are created or termi-
nated where necessary by acquiring or releasing hosts
from the Cloud infrastructure. See (Marzolla and Mi-
randola, 2011) for further details.
5 NUMERICAL RESULTS
We performed a set of numerical simulation experi-
ments to assess the effectiveness of SAVER. We con-
sider all combinations of C ∈ {10,15, 20} workflow
types and K ∈ {20,40, 60} Web Services. Service de-
mands D
ck
have been randomly generated, in such a
Algorithm 3: Release(N,λ,D(N),U(N)) → N
′
.
Require: N System configuration
Require: λ Current arrival rates of workflows
Require: D(N) Service demands at configuration N
Require: U(N) Utilizations at configuration N
Ensure: N
′
New system configuration
1: for all k := 1,...,K do
2: Nmin
k
:= N
k
∑
C
c=1
λ
c
D
ck
(N)
3: S := {k | N
k
> Nmin
k
}
4: while (S 6=
/
0) do
5: d := argmin
c
R
+
c
− R
c
(N)
R
+
c
c = 1,. . . ,C
6: j := argmin
k
R
c
(N− 1
k
) − R
+
c
k ∈ S
7: if
R
c
(N− 1
j
) > R
+
c
for any c
then
8: S := S\ { j} {No instance of WS j can be
removed}
9: else
10: N := N− 1
j
11: if
N
j
= Nmin
j
then
12: S := S\ { j}
13: Return N
way that class c workflows have service demands
which are uniformly distributed in [0,c/C]. Thus,
class 1 workflows have lowest average service de-
mands, while type C workflows have highest de-
mands. The system has been simulated for T = 200
discrete steps t = 1,.. . ,T. Arrival rates λ(t) at step
t have been generated according to a fractal model,
starting from a randomly perturbed sinusoidal pattern
to mimic periodic fluctuations; each workflow type
has a different period.
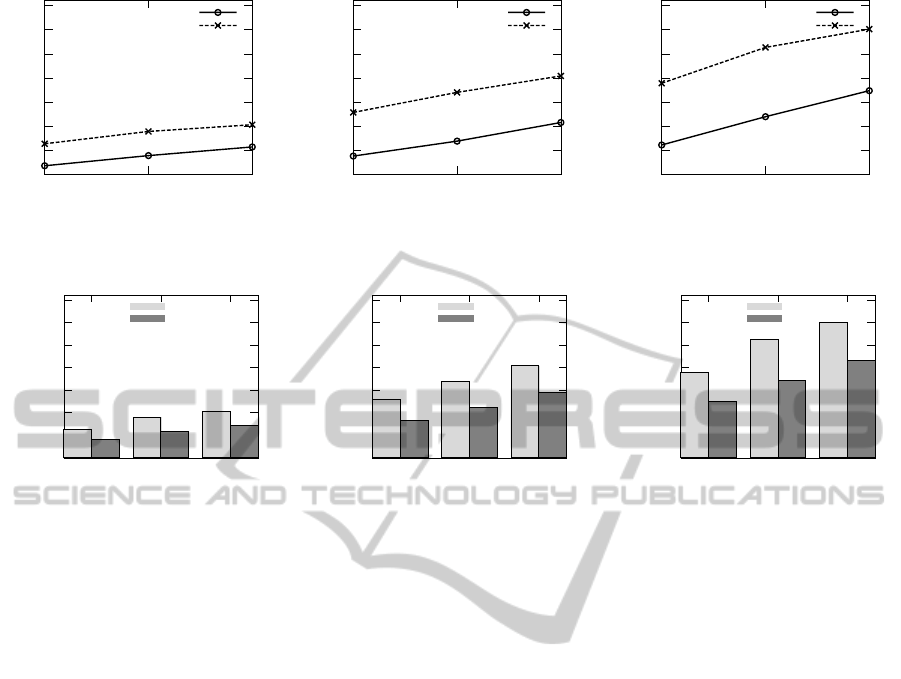
The minimum and the maximum number of re-
sources allocated by SAVER during the simulation run
are illustrated in Figure 4. Figure 5 shows the to-
tal number of WS instances allocated over the whole
simulation run by SAVER (labeled Dynamic) with the
number of instances statically allocated by overpro-
visioning for the worst-case scenario (labeled Static).
The results show that SAVER allocates between 64%–
72% of the instances required by the worst-case sce-
nario. As previously observed, if the IaaS provider
charges a fixed price for each instance allocated at
each simulation step, then SAVER allows a consistent
reduction of the total cost, while still maintaining the
negotiated SLA.
6 RELATED WORKS
Several research contributions have previously ad-
dressed the issue of optimizing the resource alloca-
tion in cluster-based service centers; some of them
AFRAMEWORKFORQOS-AWAREEXECUTIONOFWORKFLOWSOVERTHECLOUD
219
0
100
200
300
400
500
600
700
10 15 20
Number of WS instances
Number of workflow types (C)
Min. WS instances
Max. WS instances
(a) K = 20
0
100
200
300
400
500
600
700
10 15 20
Number of WS instances
Number of workflow types (C)
Min. WS instances
Max. WS instances
(b) K = 40
0
100
200
300
400
500
600
700
10 15 20
Number of WS instances
Number of workflow types (C)
Min. WS instances
Max. WS instances
(c) K = 60
Figure 4: Minimum and maximum number of WS instances allocated during the simulation runs.
0
20000
40000
60000
80000
100000
120000
140000
10 15 20
Number of WS instances
Number of workflow types (C)
Static
Dynamic
(a) K = 20
0
20000
40000
60000
80000
100000
120000
140000
10 15 20
Number of WS instances
Number of workflow types (C)
Static
Dynamic
(b) K = 40
0
20000
40000
60000
80000
100000
120000
140000
10 15 20
Number of WS instances
Number of workflow types (C)
Static
Dynamic
(c) K = 60
Figure 5: Total number of WS instances allocated during the whole simulation runs (lower is better).
use control theory-based feedback loops (Litoiu et al.,
2010; Kalyvianaki et al., 2009), machine learning
techniques (Kephart et al., 2007; Calinescu, 2009),
or utility-based optimization techniques (Urgaonkar
et al., 2007; Zhu et al., 2009). When moving to virtu-
alized environments the resource allocation problem
becomes more complex because of the introduction
of virtual resources (Zhu et al., 2009). Several ap-
proaches have been proposed for QoS and resource
management at run-time (Li et al., 2009; Litoiu et al.,
2010; Ferretti et al., 2010; Jung et al., 2010; Huber
et al., 2011; Yazir et al., 2010).
(Li et al., 2009) describes a method for achieving
optimization in Clouds by using performance models
all along the development and operation of the appli-
cations running in the Cloud. The proposed optimiza-
tion aims at maximizing profits by guaranteeing the
QoS agreed in the SLAs taking into account a large
variety of workloads. A layered Cloud architecture
taking into account different stakeholders is presented
in (Litoiu et al., 2010). The architecture supports
self-management based on adaptive feedback control
loops, present at each layer, and on a coordination ac-
tivity between the different loops. Mistral (Jung et al.,
2010) is a resource managing frameworkwith a multi-
level resource allocation algorithm considering real-
location actions based mainly on adding, removing
and/or migrating virtual machines, and shutdown or
restart of hosts. This approach is based on the usage
of Layered Queuing Network (LQN) performance
model. It tries to maximize the overall utility taking
into account several aspects like power consumption,
performance and transient costs in its reconfiguration
process. In (Huber et al., 2011) the authors present an
approach to self-adaptive resource allocation in vir-
tualized environments based on online architecture-
level performance models. The online performance
prediction allow estimation of the effects of changes
in user workloads and of possible reconfiguration ac-
tions. Yazir et al. (Yazir et al., 2010) introduces
a distributed approach for dynamic autonomous re-
source managementin computing Clouds, performing
resource configuration using through Multiple Crite-
ria Decision Analysis.
With respect to these works, SAVER lies in the re-
search line fostering the usage of models at runtime to
drive the QoS-based system adaptation. SAVER uses
an efficient modeling technique that can then be used
at runtime without undermining the system behavior
and its overall performance.
Ferretti et al. (Ferretti et al., 2010) describe a
middleware architecture enabling a SLA-driven dy-
namic configuration, management and optimization
of Cloud resources and services. The approach is
purely reactive and considers a single-tier application,
while SAVER works for an arbitrary number of WSs
and uses a performance model to plan complex recon-
figurations in a single step.
CLOSER2012-2ndInternationalConferenceonCloudComputingandServicesScience
220

Finally, Canfora et al. (Canfora et al., 2005)
describe a QoS-aware service discovery and late-
binding mechanism which is able to automatically
adapt to changes of QoS attributes in order to meet
the SLA. The binding is done at run-time, and de-
pends on the values of QoS attributes which are mon-
itored by the system. It should be observed that in
SAVER we consider a different scenario, in which
each WS has just one implementation which how-
ever can be instantiated multiple times. The goal of
SAVER is to satisfy a specific QoS requirement (mean
execution time of workflows below a given threshold)
with the minimum number of instances.
7 CONCLUSIONS
In this paper we presented SAVER, a QoS-aware al-
gorithm for executing workflows involving Web Ser-
vices hosted in a Cloud environment. SAVER se-
lectively allocates and deallocates Cloud resources
to guarantee that the response time of each class of
workflows is kept below a negotiated threshold. This
is achieved though the use of a QN performance
model which drives a greedy optimization strategy.
Simulation experiments show that SAVER can ef-
fectively react to workload fluctuations by acquir-
ing/releasing resources as needed.
Currently, we are working on the extension of
SAVER, exploring the use of forecasting techniques
as a mean to trigger resource allocation and deallo-
cation proactively. More work is also being carried
out to assess the SAVER effectiveness through a more
comprehensive set of real experiments.
REFERENCES
Calinescu, R. (2009). Resource-definition policies for au-
tonomic computing. In Proc. Fifth Int. Conf. on Au-
tonomic and Autonomous Systems, pages 111–116,
Washington, DC, USA. IEEE Computer Society.
Canfora, G., Di Penta, M., Esposito, R., and Villani, M. L.
(2005). Qos-aware replanning of composite web ser-
vices. In Proceedings of the IEEE International Con-
ference on Web Services, ICWS ’05, pages 121–129,
Washington, DC, USA. IEEE Computer Society.
Ferretti, S., Ghini, V., Panzieri, F., Pellegrini, M., and Tur-
rini, E. (2010). Qos-aware clouds. In Proceedings of
the 2010 IEEE 3rd International Conference on Cloud
Computing, CLOUD ’10, pages 321–328. IEEE Com-
puter Society.
Huber, N., Brosig, F., and Kounev, S. (2011). Model-based
self-adaptive resource allocation in virtualized envi-
ronments. In SEAMS ’11, pages 90–99, New York,
NY, USA. ACM.
Jung, G., Hiltunen, M. A., Joshi, K. R., Schlichting, R. D.,
and Pu, C. (2010). Mistral: Dynamically managing
power, performance, and adaptation cost in cloud in-
frastructures. In ICDCS, pages 62–73. IEEE Com-
puter Society.
Kalyvianaki, E., Charalambous, T., and Hand, S. (2009).
Self-adaptive and self-configured cpu resource provi-
sioning for virtualized servers using kalman filters. In
ICAC’09, pages 117–126. ACM.
Kephart, J. O., Chan, H., Das, R., Levine, D. W., Tesauro,
G., III, F. L. R., and Lefurgy, C. (2007). Coordinat-
ing multiple autonomic managers to achieve specified
power-performance tradeoffs. In ICAC’07, page 24.
IEEE Computer Society.
Lazowska, E. D., Zahorjan, J., Graham, G. S., and Sev-
cik, K. C. (1984). Quantitative System Performance:
Computer System Analysis Using Queueing Network
Models. Prentice Hall.
Li, J., Chinneck, J., Woodside, M., Litoiu, M., and Iszlai, G.
(2009). Performance model driven qos guarantees and
optimization in clouds. In CLOUD ’09, pages 15–22,
Washington, DC, USA. IEEE Computer Society.
Litoiu, M., Woodside, M., Wong, J., Ng, J., and Iszlai, G.
(2010). A business driven cloud optimization archi-
tecture. In Proc. of the 2010 ACM Symp. on Applied
Computing, SAC ’10, pages 380–385. ACM.
Marzolla, M. and Mirandola, R. (2011). A Framework for
QoS-aware Execution of Workflows over the Cloud.
arXiv preprint abs/1104.5392.
Urgaonkar, B., Pacifici, G., Shenoy, P., Spreitzer, M., and
Tantawi, A. (2007). Analytic modeling of multitier
internet applications. ACM Trans. Web, 1.
Yazir, Y. O., Matthews, C., Farahbod, R., Neville, S., Gui-
touni, A., Ganti, S., and Coady, Y. (2010). Dynamic
resource allocation in computing clouds using dis-
tributedmultiple criteria decision analysis. In CLOUD
’10, pages 91–98. IEEE Computer Society.
Zhang, Q., Cheng, L., and Boutaba, R. (2010). Cloud com-
puting: state-of-the-art and research challenges. J. of
Internet Services and Applications, 1:7–18.
Zhu, X., Young, D., Watson, B. J., Wang, Z., Rolia, J., Sing-
hal, S., McKee, B., Hyser, C., Gmach, D., Gardner,
R., Christian, T., and Cherkasova, L. (2009). 1000
islands: an integrated approach to resource manage-
ment for virtualized data centers. Cluster Computing,
12(1):45–57.
AFRAMEWORKFORQOS-AWAREEXECUTIONOFWORKFLOWSOVERTHECLOUD
221
