
VIDEO BASED HUMAN ACTIVITY RECOGNITION
USING WAVELET TRANSFORM AND HIDDEN
CONDITIONAL RANDOM FIELDS (HCRF)
Muhammad Hameed Siddiqi
1
, La The Vinh
1
and Adil Mehmood Khan
2
1
Ubiquitous Computing Lab, Dept. of Computer Engineering, Kyung Hee University, Suwon, Rep. of Korea
2
Division of Information and Computer Engineering, Ajou University, Suwon, Rep. of Korea
Keywords: Activity Recognition, Wavelet Transform, HCRF, Video Surveillance.
Abstract: In this research, we proposed testing and validating the accuracy of employing wavelet transform and
Hidden Conditional Random Field (HRCF) for video based activity recognition. For feature extraction,
Symlet wavelet was tested and decomposed up to 4 levels, and some of the highest coefficients were
extracted from each level of decomposition. These coefficients were based on the average frequency of each
video frame and the time difference between each frame. Finally, a novel HRCF model was applied for
recognition. The proposed method was tested on a database of ten activities, where the data were collected
from nine different people, and compared with one of the existing techniques. The overall recognition rate,
using the symlet wavelet family (Symlet 4), was 93% that showed an improvement of 13% in performance.
1 INTRODUCTION
Aim of a video-based activity recognition (VAR)
system is to automatically recognize a human
activity using a sequence of images (video frames).
A large number of such systems have been
developed in the past, such as (Aggarwal, 1999,
Cedras, 1995, Gavrila, 1999, Moeslund, 2006,
Turaga, 2008, and Yilmaz, 2006, Siddiqi, 2010).
Feature extraction is an important step in any
VAR system. A well-known technique employed for
this includes (Uddin, 2008, and 2010). They used
Principal Component Analysis (PCA) and
Independent Component Analysis (ICA). PCA
yields uncorrelated components, especially if the
data are a merged of non-Gaussian components then
PCA fails to extract components having non-
Gaussian distribution (Buciu, 2009). ICA, though
better than PCA, is slow to train, especially in the
case of high dimensional data. Also, ICA is very
weak in managing the inputs.
For recognition, conventional learning methods,
such as Hidden Markove Model (HMM), Support
Vector Machine (SVM), Gaussian Mixture Model
(GMM), Artificial Neural Network (ANN), etc have
been mostly employed. Among these, HMM is the
most commonly used method (Uddin 2008, 2010).
Despite its wide use, it still has some serious
deficiencies, such as difficulty to represent multiple
interacting activities (Gu, 2009), incapability of
capturing long-range or transitive dependencies, and
requiring intense training (Kim, 2010).
Our objective was to develop a new feature
extraction algorithm and to remove the limitations of
the HMM by using a novel hidden condition random
field model. Our feature vector is built by extracting
the highest wavelet coefficients on the basis of each
frame’s frequency and the time difference between
each frame for each activity. At the recognition
stage, the hidden condition random field model is
used for acivity recognition.
2 MATERIALS AND METHODS
The aim of this section is to explain the proposed
feature extraction and recognition technique.
2.1 Feature Extraction
In this stage, we used the decomposition process
applied using Wavelet Transform (WT), for which
the video frames were in greyscale. The reason for
converting from RGB to gray scale was to improve
the efficiency of the proposed algorithm. The
wavelet decomposition could be interpreted as
401
Hameed Siddiqi M., The Vinh L. and Mehmood Khan A..
VIDEO BASED HUMAN ACTIVITY RECOGNITION USING WAVELET TRANSFORM AND HIDDEN CONDITIONAL RANDOM FIELDS (HCRF).
DOI: 10.5220/0003818704010404
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2012), pages 401-404
ISBN: 978-989-8565-03-7
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

signal decomposition in a set of independent
feature vector. Each vector consists of sub-vectors
like
2212223 2
0000 0
, , ,........,
D
DD D Dn
VVVV V
−− − −
=
(1)
where V represents the 2D feature vector. If we
have a 2D frame x it breaks up into orthogonal
sub images corresponding to different
visualization. The following equation shows one
level of decomposition.
X = A
1
+ D
1
(2)
where X indicates the decomposed image and A
1
and D
1
are called approximation and detail
coefficient vectors. If a video frame is
decomposed up to multiple levels, the (7) can then
be written as
X = A
j
+ D
j
+ D
j-1
+ D
j-2
+ …. + D
2
+ D
1
(3)
where j represents the level of decomposition, and
‘A’ and ‘D’ represent the approximation and detail
coefficients respectively. The detail coefficients
mostly consist of noise, so for feature extraction
only the approximation coefficients are used. In
the proposed algorithm, each frame is
decomposed up to four levels, i.e., the value of j =
4, because by exceeding the value of j = 4, the
image looses significant information, due to that
the informative coefficients cannot be detected
properly, which may cause misclassification. The
detail coefficients further consist of three sub-
coefficients, so the (3) can be written as
44321
X
A
DDDD
=++++
4
44 4
33 3
22 2
11 1
()()()
()()()
()()()
()()()
hvd
hvd
hvd
hvd
A
DDD
DDD
DDD
DDD
⎡⎤
=+ + + +
⎣⎦
⎡⎤
++ +
⎣⎦
⎡⎤
++ +
⎣⎦
⎡⎤
++
⎣⎦
(4)
Or simply the formula can be written as:
1
4
4
()()()
ii i
i
X
hvd
A
DDD
=
⎡⎤
=+ + +
⎣⎦
∑
(5)
where D
h
, D
v
and D
d
are known as horizontal,
vertical and diagonal coefficients respectively. It
means that all the coefficients are connected with
each other like a chain. Note that at each
decomposition step, approximation and detail
coefficient vectors are obtained by passing the
signal through a low-pass filter and high-pass
filter respectively.
After decomposition, the feature vector is created
by taking the average of all the frequencies of the
activity frames, and also using the time difference
between the activity frames. In a specified time
window and frequency band with wavelet transform,
the frequency is guesstimated. The signal (frame) is
analyzed by using the wavelet transform (Turunen,
2011):
()
.
1
,()
j
ij fe
i
i
tb
Cab yt dt
a
a
ψ
∞
∗
−∞
−
⎛⎞
=
⎜⎟
⎝⎠
∫
(6)
where ɑ
i
is the scale of the wavelet between lower
frequency and upper frequency bounds to get high
decision for frequency estimation, and b
i
is the
position of the wavelet from the start and end of the
time window with the spacing of signal sampling
period. Other parameters include: time t; the wavelet
function Ψ
f.e.
, which is used for frequency
estimation; and C(ɑ
i
, b
i
), which are the wavelet
coefficients with the specified scale and position
parameters. Finally, the scale is converted to the
mode frequency, f
m
:
..
..
()
().
afe
m
mfe
f
f
a
ψ
ψ
=
Δ
(7)
where f
a
(Ψ
f.e.
) is the average frequency of the
wavelet function, and ∆ is the signal sampling
period.
2.2 Recognition
To overcome the limitations of HMM and Gaussian
mixture HCRF model, we explicitly included a
mixture of Gaussian distributions in the feature
functions, thus our feature functions could be
described in the following forms
Pr
1
(,, ) ( )
ior
s
f
YSX s s s
δ
=
=∀
(8)
,1
1
(,, ) ( )( ) ,
T
Transation
ss t t
t
f
YSX s s s s ss
δδ
′
−
=
′′
=Σ = = ∀
(9)
()
,,,
11
(,, ) log , , ( )
TM
Observation Obs
ssmtsmsmt
tm
f
YSX N x s s
μδ
==
⎛⎞
=
ΣΣΓ Σ =
⎜⎟
⎝⎠
(10)
(
)
()
(
)
1
2
2
,
1
11
,, , , ,
2
2
,, exp( )( )
D
sm
sm sm sm sm sm
Nx x x
π
μμμ
−
Σ
′
Σ= − − Σ −
(11)
where M is the number of density function, D is the
dimension of the observation,
,
Obs
s
m
Γ
is the mixing
weight of the m
th
component with mean μ
s,m
and
covariance matrix ∑
s,m
. As we can see in (15), Г, μ,
and ∑ we can be updated during the training phase,
hence we can set
VISAPP 2012 - International Conference on Computer Vision Theory and Applications
402
,
1
Obs
sm
sΛ=∀
(12)
As a result, the conditional probability can be
rewritten as below
(
)
|;,,,pY X
μ
ΛΓ Σ
Pr Pr
(,, )
exp ( , , )
(,, )
( ; ,,,)
ior ior
ss
s
Transition Transition
ss ss
ss
S
Observation
s
s
fYSX
fYSX
fYSX
zX
μ
′′
′
⎛⎞
ΣΛ +
⎜⎟
⎜⎟
ΣΣΛ +
⎜⎟
⎜⎟
Σ
⎜⎟
⎝⎠
ΛΓ Σ
=
(13)
()
,
1
Pr
1
1
, , ......,
12
,,,
1
exp
log , ,
(;,,,)
Transition
ss
T
tt
ior
M
S
Obs
t
SSS S
t
sm t sm sm
ttt
m
Nx
zX
μ
μ
−
=
=
=
⎛⎞
⎛⎞
Λ+
⎜⎟
⎜⎟
ΣΛ+Σ
⎛⎞
⎜⎟
⎜⎟
ΣΓ Σ
⎜⎟
⎜⎟
⎜⎟
⎝⎠
⎝⎠
⎝⎠
ΛΓ Σ
=
(14)
(
)
|;,,,
(;,,,)
Score Y X
zX
μ
μ
Λ
ΓΣ
ΛΓ Σ
=
(15)
Based on (19) and (20), we can compute the
conditional probability by using the well-known
forward and backward algorithm as below
{}
()
1
1
12
Pr
,
, ,......,
1
,,,
1
() exp
log , ,
tt
ttt
ior
S
Transition
ss
T
SSS S S
M
Obs
t
sm t sm sm
m
s
Nx
τ
τ
α
μ
−
==
=
=
⎛⎞
Λ
⎜⎟
⎜⎛ ⎞⎟
Λ+
=Σ
⎜⎟
⎜⎟
+Σ
⎜⎟
⎛⎞
⎜⎟
ΣΓ Σ
⎜⎟
⎜⎟
⎜⎟
⎝⎠
⎝⎠
⎝⎠
(
)
1,,,
1
()exp log , ,
M
Transition Obs
s
ssmsmsm
sm
sNx
ττ
αμ
′
−
′
=
⎛
⎛
′
=Σ Λ ΣΓ Σ
⎜
⎜
⎝
⎝
(16)
{}
()
1
1
1
Pr
,
, ,......,
1
,,,
1
() exp
log , ,
tt
T
ttt
ior
S
Transition
ss
T
SSSS S
M
Obs
t
sm t sm sm
m
s
Nx
ττ
τ
β
μ
−
+
==
=
=
⎛⎞
Λ
⎜⎟
⎜⎛ ⎞⎟
Λ+
=Σ
⎜⎟
⎜⎟
+Σ
⎜⎟
⎛⎞
⎜⎟
ΣΓ Σ
⎜⎟
⎜⎟
⎜⎟
⎝⎠
⎝⎠
⎝⎠
()
1,,,
1
()exp log , ,
M
Transition Obs
ss sm sm sm
sm
sNx
ττ
βμ
′
+
′
=
⎛
⎛
⎞
′
=Σ Λ ΣΓ Σ
⎜
⎟
⎜
⎝
⎠
⎝
(17)
(
)
|;,,, ()
T
S
Score Y X s
μα
ΛΓ Σ =
∑
1
()
S
s
β
=
∑
(18)
In the training phase, our goal was to find the
parameters (Ʌ, Г, μ, and ∑) to maximize the
conditional probability of the training data.
3 RESULTS AND DISCUSSION
In order to evaluate the proposed algorithm, we used
a publicly available dataset (Gorelick, 2007),
containing ten activities. Each activity is performed
by nine different people. The frame size is 144 x
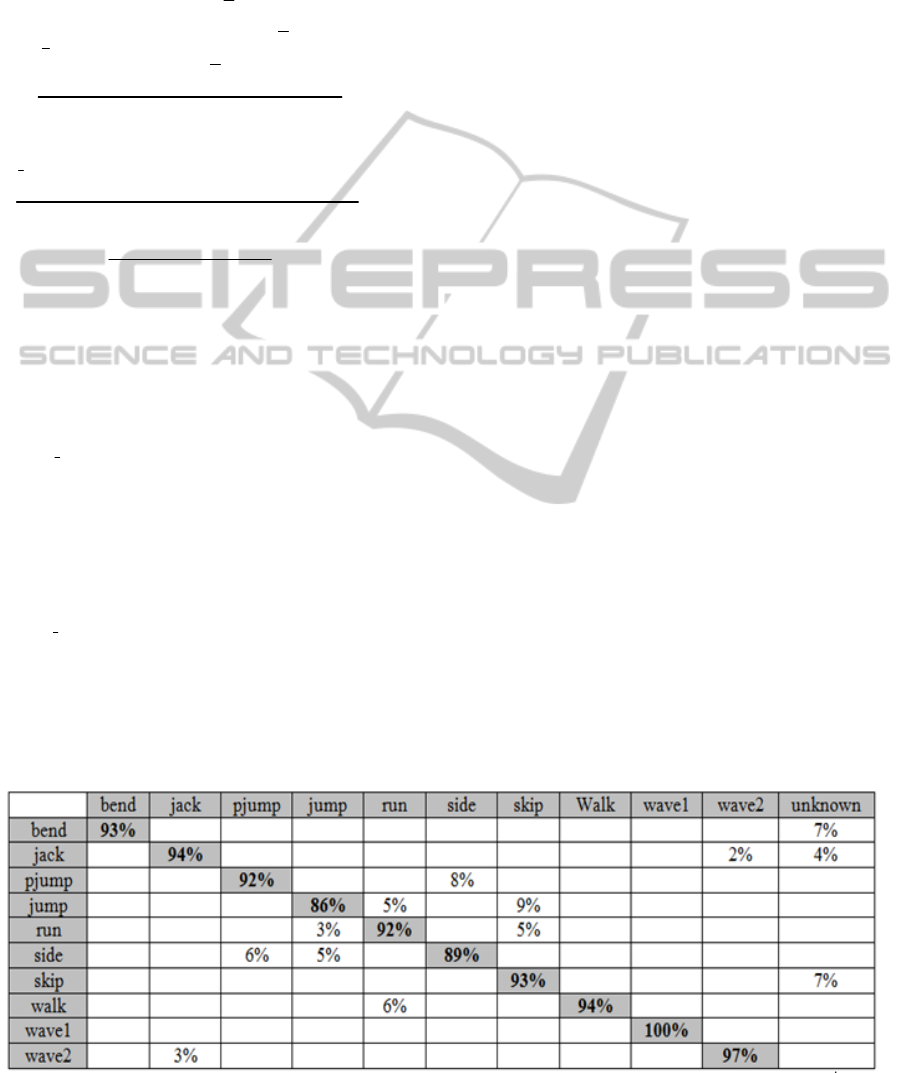
180. The confusion matrix, shown in Table 1, shows
the recognition rate of the proposed algorithm.
3.1 Comparison with Existing
Algorithm
The proposed method was compared with one of
the existing algorithms (Uddin, 2008), whose
results are shown in Table 2, in terms of accuracy.
The proposed algorithm improved the recognition
rate by about 13%. This improvement in accuracy
could be attributed to the use of symlet wavelet,
which is a compactly supported wavelet with the
least asymmetry and the highest number of
vanishing moments for a given support width, and
HCRF, which provides a better performance
because it solves the limitations of the Conditional
Random Fields (CRF) HMM.
Table 1: Recognition rates for the testing dataset obtained by the proposed algorithm model (blank cells represent 0%). The
average accuracy is 93.0 %.
VIDEO BASED HUMAN ACTIVITY RECOGNITION USING WAVELET TRANSFORM AND HIDDEN
CONDITIONAL RANDOM FIELDS (HCRF)
403
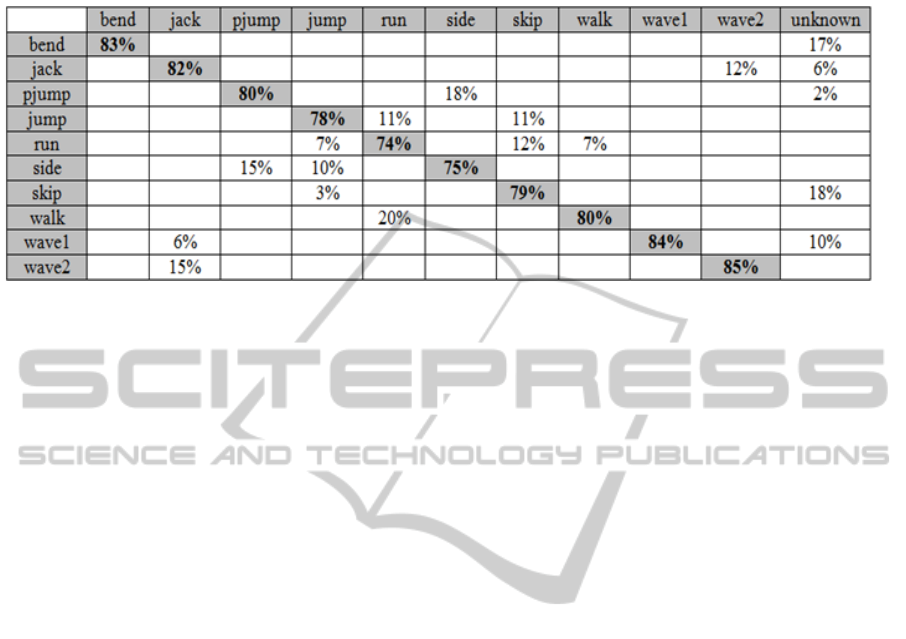
Table 2: Recognition rates for the testing dataset obtained by the existing algorithm (Uddin, 2008). The blank cells
represent 0%. The average accuracy is 80.0 %.
4 CONCLUSIONS
In this research, we proposed a VAR algorithm that
employs wavelet transform and HCRF model. The
proposed algorithm was tested on a publicly
available dataset. The recognition results were
compared with one of the existing techniques that
used PCA, ICA, and HMM. The overall recognition
rate using the symlet wavelet family (Symlet 4) was
93%. These results showed an improvement of 13%
in performance.
ACKNOWLEDGEMENTS
This work was supported by the new faculty
research fund of Ajou University.
REFERENCES
Aggarwal, J. K., Cai, Q., 1999. Human motion analysis: A
review. Comput. Vis. Image Und., vol. 73(3), pp. 428-
40.
Cedras, C., Shah, M., 1995. Motion-based recognition: A
survey. Image Vis. Comput., vol. 13(2), pp. 129-55.
Gavrila, D. M., 1999. The visual analysis of human
movement: a survey: Comput. Vis. Image Und., vol.
73(1), pp. 82-98.
Gorelick, L., Blank M., Shechtman E., Irani M., Basri R.,
2007. Actions as Space-Time Shapes. IEEE Trans.
PAMI., vol. 29(12), pp.2247-53.
Gu, T., Wu, Z., Tao, X., Pung, H. K., Lu, J., 2009.
epSICAR: An Emerging Patterns based approach to
sequential, interleaved and Concurrent Activity
Recognition. In Proc. of IEEE Intl. Conference on
Pervasive Computing and Communications.
Kim, T.-S., Uddin, M. Z., 2010. Silhouette-based Human
Activity Recognition Using Independent Component
Analysis, Linear Discriminant Analysis and Hidden
Markov Model. New Developments in Biomedical
Engineering, ISBN: 978-953-7619-57-2. Edited by:
Domenico Campolo. Published by InTech.
Moeslund, T. B., Hilton, A., Kruger, V., 2006. A survey of
advances in vision-based human motion capture and
analysis. Comput. Vis. Image Und., vol. 104(2), pp.
90-126.
Siddiqi, M. H., Fahim, M., Lee, S. Y., Lee, Y.-K, 2010.
Human Activity Recognition Based on Morphological
Dilation followed by Watershed Transformation
Method. Proc. of International Conference on
Electronics and Information Engineering (ICEIE), pp.
V2 433-V2 437.
Turaga, P., Chellappa, R., Subrahmanian, V. S., Udrea, O.,
2008. Machine Recognition of Human Activities: A
survey. IEEE Trans. Circuits and Systems for
VideoTechnology, vol. 18(11), pp. 1473-88.
Turunen, J, 2011. A Wavelet-based Method for Estimating
Damping in Power Systems. PhD. Thesis, Aalto
University, School of Electrical Engineering,
Department of Electrical Engineering Power
Transmission Systems.
Uddin, M. Z., Lee, J. J., Kim, T.-S, 2010. Independent
shape component-based human activity recognition
via Hidden Markov Model. Appl. Intell, vol. 33(2), pp.
193-206.
Uddin, M. Z., Lee, J. J., Kim, T.-S. 2008. Shape-Based
Human Activity Recognition Using Independent
Component Analysis and Hidden Markov Model.
Proc. of 2
1st
International Conference on Industrial,
Engineering, and other Applications of Applied
Intelligent Systems, pp.245-254.
Yilmaz, A., Javed, O., Shah, M., 2006. Object tracking: A
survey. ACM Comput. Surv., vol. 38(4).
VISAPP 2012 - International Conference on Computer Vision Theory and Applications
404
