
EMBEDDED FEATURE SELECTION FOR SPAM AND PHISHING
FILTERING USING SUPPORT VECTOR MACHINES
Sebasti
´
an Maldonado
1
and Gast
´
on L’Huillier
2
1
Faculty of Engineering and Applied Sciences, Universidad de los Andes
Av. San Carlos de Apoquindo 2200, Las Condes, Santiago, Chile
2
Groupon, Inc., Palo Alto, CA, U.S.A.
Keywords:
Spam and phishing filtering, Support vector machines, Feature selection, Embedded methods.
Abstract:
Today, the Internet is full of harmful and wasteful elements, such as phishing and spam messages, which must
be properly classified before reaching end-users. This issue has attracted the pattern recognition community’s
attention and motivated to determine which strategies achieve best classification results. Several methods use
as many features as content-based properties the data set have, which leads to a high dimensional classification
problem. In this context, this paper presents a feature selection approach that simultaneously determines a non-
linear classification function with minimal error and minimizes the number of features by penalizing their use
in the dual formulation of binary Support Vector Machines (SVM). The method optimizes the width of an
anisotropic RBF Kernel via successive gradient descent steps, eliminating features that have low relevance
for the model. Experiments with two real-world Spam and Phishing data sets demonstrate that our approach
accomplishes the best performance compared to well-known feature selection methods using consistently a
small number of features.
1 INTRODUCTION
One particular domain for which machine learn-
ing has been considered a key component is cyber-
security. Specifically, for the correct identification of
the large number of spam messages, web spam, and
spam servers which inundate Internet resources every
day. It is likely that spam messages will continue to
be one of the most wasteful, dangerous and infectious
elements on the Web as new campaigns are occasion-
ally instigated by spam senders (Taylor et al., 2007).
Identifying malicious emails such as spam or
phishing can be considered as a task of binary clas-
sification where the goal is to discriminate between
the two classes of “desired” and “undesired” emails.
Support Vector Machine (Vapnik, 1998) is an effec-
tive classification method and provides several advan-
tages such as absence of local minima, adequate gen-
eralization to new objects, and representation that de-
pends on few parameters. Furthermore, this method
has proved to be very effective for spam classifica-
tion (Tang et al., 2008) and Phishing (L’Huillier et al.,
2010). However, this approach does not determine the
importance of the features used by a classifier (Mal-
donado and Weber, 2009). In this paper we present a
feature selection approach for binary classification us-
ing SVM, showing its potential for spam and phishing
classification.
This paper is organized as follows. In Section 2
we briefly introduce spam and phishing classification.
Recent developments for feature selection using SVM
are reviewed in Section 3. Section 4 presents the pro-
posed feature selection method based on SVM. Ex-
perimental results using real-world data sets are given
in Section 5. A summary of this paper can be found
in Section 6, where we provide its main conclusions
and address future developments.
2 SPAM AND PHISHING
CLASSIFICATION
Among all counter-measures used against spam and
phishing, there are two main alternatives (Bergholz
et al., 2010): content-based classification on the one
hand and blacklisting and white-listing on the other.
In the following, the main approaches for these alter-
natives are briefly reviewed.
445
Maldonado S. and L’Huillier G. (2012).
EMBEDDED FEATURE SELECTION FOR SPAM AND PHISHING FILTERING USING SUPPORT VECTOR MACHINES.
In Proceedings of the 1st International Conference on Pattern Recognition Applications and Methods, pages 445-450
DOI: 10.5220/0003782004450450
Copyright
c
SciTePress

2.1 Content-based Classification
Spam filtering is a classical problem in machine learn-
ing, and many filtering techniques have been de-
scribed (Goodman et al., 2007). However, in terms of
content-based classification, phishing differs in many
aspects from the spam case. While most of spam
emails are intended to spread information about prod-
ucts and web sites, in phishing, the interaction be-
tween a message and the receiver is more complex.
End users are usually involved in a third step of in-
teraction, such as following malicious links, filling
deceptive forms, or replying with useful information
which are relevant for the fraud message to succeed.
Previous works on content-based filtering of de-
ceptive spam or phishing emails have focused on the
extraction of a large number of features used in pop-
ular machine learning techniques for its classification
(Bergholz et al., 2010).
2.2 Network-based Classification
Real Time Blacklists (RBLs) have been considered as
an efficient alternative to filtering spam messages, just
by considering server-side features for spam sender
detection. These services can be queried over the Do-
main Name System (DNS) protocol, which provides
a powerful tool for email servers to decide whether or
not to accept messages from a given host (Tang et al.,
2008). These approaches are based on features ex-
tracted from network properties and not from content-
based characteristics, hence the dimensionality of the
classification problem is considerably low and the
features’ properties are different than in content-based
approaches. For this reason, these approaches were
not considered in this paper.
3 EMBEDDED FEATURE
SELECTION FOR SVMS
There are different strategies for embedded feature se-
lection. First, feature selection can be seen as an op-
timization problem. For example, the methods pre-
sented in (Neumann et al., 2005) add an extra term
that penalizes the cardinality of the selected feature
subset to the standard cost function of SVM. By op-
timizing this modified cost function features are se-
lected simultaneously to model construction. Another
embedded approach is the Feature Selection Con-
caVe (FSV) (Bradley and Mangasarian, 1998), based
on the minimization of the “zero norm” :
k
w
k
0
=
|
{
i : w
i
6= 0
}
|. Note that
k
·
k
0
is not a norm be-
cause the triangle inequality does not hold (Bradley
and Mangasarian, 1998), unlike l
p
-norms with p > 0.
Since the l
0
-“norm” is non-smooth, it was approxi-
mated by a concave function:
k
w
k
0
≈ e
T
(e −exp(−β|w|) (1)
with an approximation parameter β ∈ R
+
and e =
(1, . . . ,1)
T
. The problem is finally solved by using an
iterative method called Successive Linearization Al-
gorithm (SLA) for FSV (Bradley and Mangasarian,
1998). (Weston et al., 2003) proposed an alternative
approach for zero-“norm” minimization (l
0
-SVM) by
iteratively scaling the variables, multiplying them by
the absolute value of the weight vector w. An impor-
tant drawback of these methods is that they are limited
to linear classification functions (Guyon et al., 2006).
Several embedded approaches consider backward
feature elimination in order to establish a ranking
of features, using SVM-based contribution measures
to evaluate their relevance. One popular method is
known as Recursive Feature Elimination (SVM-RFE)
(Guyon et al., 2009). The goal of this approach is to
find a subset of size r among n variables (r < n) which
maximizes the classifier’s performance. The feature
to be removed in each iteration is the one whose re-
moval minimizes the variation of W
2
(α):
W
2
(α) =
m
∑
i,s=1
α
i
α
s
y
i
y
s
K(x
i
,x
s
) (2)
The scalar W
2
(α) is a measure of the model’s pre-
dictive ability and is inversely proportional to the mar-
gin. Features are eliminated applying the following
procedure:
1. Given a solution α, for each feature p calculate:
W
2
(−p)
(α) =
m
∑
i,s=1
α
i
α
s
y
i
y
s
K(x
(−p)
i
,x
(−p)
s
) (3)
where x
(−p)
i
represents the training object i with
feature p removed.
2. Eliminate the feature with smallest value of
|W
2
(α) −W
2
(−p)
(α)|.
Another ranking method that allows kernel func-
tions was proposed in (Rakotomamonjy, 2003), which
considers a leave-one-out error bound for SVM,
the radius margin bound (Vapnik, 1998) LOO ≤
4R
2
||w||
2
, where R denotes the radius of the small-
est sphere that contains the training data. This bound
is also used in (Weston et al., 2001) through the scal-
ing factors strategy. Feature selection is performed by
scaling the input parameters by a vector σ ∈ [0, 1]
n
.
ICPRAM 2012 - International Conference on Pattern Recognition Applications and Methods
446

Large values of σ
j
indicate more useful features. The
problem consists in choosing the best kernel of the
form:
K
σ
(x
i
, x
s
) ≡ K(σ ∗ x
i
, σ ∗ x
s
) (4)
where ∗ is the component-wise multiplication opera-
tor. The method presented by (Weston et al., 2001)
considers the gradient descent algorithm for updating
σ. (Canu and Grandvalet, 2002) propose to limit the
use of the attributes by constraining the scaling fac-
tors using a parameter σ
0
, which controls the norm of
σ.
4 THE PROPOSED METHOD FOR
EMBEDDED FEATURE
SELECTION
An embedded method for feature selection using
SVMs is proposed in this section. The main idea is
to penalize the use of features in the dual formulation
of SVMs using a gradient descent approximation for
Kernel optimization and feature elimination. The pro-
posed method attempts to find the best suitable RBF-
type Kernel function for each problem with a minimal
dimension by combining the parameters of general-
ization (using the 2-norm), goodness of fit, and fea-
ture selection (using a 0-“norm” approximation).
For this approach we use the anisotropic Gaussian
Kernel:
K(x
i
, x
s
, σ) = exp
−
||σ ∗ x
i
− σ ∗ x
s
||
2
2
(5)
where ∗ denotes the component-wise vector product
operator, defined as a*b = (a
1
b
1
, . . . , a
n
b
n
).
The proposed approach (Kernel-Penalized SVM)
incorporates feature selection in the dual formulation
of SVMs. The formulation includes a penalization
function f (σ) based on the 0-“norm” approximation
(1) described in Section 3 and modifying the Gaus-
sian Kernel using an (anisotropic) width vector σ as a
decision variable. The feature penalization should be
negative since the dual SVM is a maximization prob-
lem. The following embedded formulation of SVMs
for feature selection is proposed:
Max
α, σ
m
∑
i=1
α
i
−
1
2
m
∑
i,s=1
α
i
α
s
y
i
y
s
K(x
i
, x
s
, σ)−C
2
f (σ)
(6)
subject to
m
∑
i=1
α
i
y
i
= 0
0 ≤ α
i
≤ C i ∈ {1, . . . , m}.
σ
j
≥ 0 j ∈ {1, . . . , n}.
Notice that the values of σ are always consid-
ered to be positive, in contrast to the weight vector
w in formulation (1), since it is desirable that the
kernel widths be positive values (Maldonado et al.,
2011). Considering the “zero norm” approximation
described in (1),
k
σ
k
0
≈ e
T
(e − exp(−β|σ|), and
since |σ
j
| = σ
j
∀ j, it is not necessary to use the 1-
norm in the approximation.
The following feature penalization function is pro-
posed, where the approximation parameter β is also
considered. In (Bradley and Mangasarian, 1998), the
authors suggest setting β to 5:
f (σ) = e
T
(e − exp(−βσ) =
n
∑
j=1
[1 − exp (−βσ
j
)]
(7)
Since the formulation (6) is non-convex, we de-
velop an iterative algorithm for its approximation.
A 2-step methodology is proposed: first we solve
the traditional dual formulation of SVM for a fixed
anisotropic kernel width σ:
Max
α
m
∑
i=1
α
i
−
1
2
m
∑
i,s=1
α
i
α
s
y
i
y
s
K(x
i
, x
s
, σ) (8)
subject to
m
∑
i=1
α
i
y
i
= 0
0 ≤ α
i
≤ C i ∈ {1, . . . , m}.
In the second step the algorithm solves, for a given
solution α, the following non-linear formulation:
Min
σ
F(σ) =
m
∑
i,s=1
α
i
α
s
y
i
y
s
K(x
i
, x
s
, σ) +C
2
f (σ)
(9)
subject to
σ
j
≥ 0 j ∈ {1, . . . , n}.
The goal of formulation (9) is to find a sparse so-
lution, making zero as many components of σ as pos-
sible. We propose an iterative algorithm that updates
the anisotropic kernel variable σ, using the gradient of
the objective function, and eliminates the features that
are close to zero (below a given threshold ε). The al-
gorithm solves successive gradient descent steps until
one particular scaling factor σ
j
drops below a thresh-
old ε, starting with one initial solution σ
0
. When this
happens, attribute j is eliminated by setting σ
j
= 0.
EMBEDDED FEATURE SELECTION FOR SPAM AND PHISHING FILTERING USING SUPPORT VECTOR
MACHINES
447

Algorithm 1: Kernel Width Updating and Feature Elimina-
tion.
1. Start with σ = σ
0
;
2. flag=true; flag2=true;
3. while(flag==true) do
4. train SVM (formulation (8));
5. t = 0;
6. while(flag2==true) do
7. σ
t+1
= σ
t
− γ∆F(σ
t
);
8. if (||σ
t+1
− σ
t
||
1
< ε
0
) then
9. flag2==false, flag==false;
10. else
11. if (∃ j | σ
t+1
j
> 0 ∧ σ
t+1
j
< ε, ∀ j) then
12. for all (σ
t+1
j
< ε) do σ
t+1
j
= 0;
13. flag2==false;
14. end if
15. end if
16. t = t + 1;
17. end while;
18. end while;
Then the algorithm returns to formulation (8) until
convergence. It is also possible that several variables
become zero in one iteration. The algorithm Kernel
Width Updating and Feature Elimination follows:
In the seventh line the algorithm adjusts the Kernel
variables by using the gradient descent procedure, in-
corporating a gradient parameter γ. In this step the al-
gorithm computes the gradient of the objective func-
tion in formulation (9) for a given solution of SVMs
α, obtained by training an SVM classifier using for-
mulation (8). For a given feature j, the gradient of
formulation (9) is:
∆
j
F(ν) = C
2
βexp (−βσ
j
) (10)
+
m
∑
i,s=1
σ
j
(x
i, j
− x
s, j
)
2
α
i
α
s
y
i
y
s
K(x
i
, x
s
, σ)
Lines 8 and 9 of the algorithm represent the stop-
ping criterion, which is reached when σ
t+1
≈ σ
t
.
Lines 11 to 14 of the algorithm represent the feature
elimination step. When a Kernel variable σ
j
in itera-
tion t + 1 is below a threshold ε, this feature is con-
sidered as irrelevant and eliminated by setting σ
j
= 0.
This variable will not be included in subsequent iter-
ations of the algorithm.
5 RESULTS FOR SPAM AND
PHISHING DATA SETS
We applied the proposed approach for feature selec-
tion to two data sets. We consider the following pro-
cedure for model comparison: First, model selec-
tion is performed before feature selection, obtaining
the kernel parameters d, ρ and penalty parameter C.
The best combination is selected via 10-fold cross-
validation. For the methods RFE-SVM, FSV-SVM
and Fisher Filtering a ranking is first obtained with the
training data, and model performance is then obtained
using 10-fold cross-validation for specific numbers
of attributes, depending on the size of the data set,
considering the hyper-parameters obtained during the
model selection procedure. For KP-SVM, instead,
the algorithm runs using initial hyper-parameters and
automatically obtains the desired number of features
and the Kernel shape when convergence is reached
we compute also the average cross-validation per-
formance in intermediate steps for comparison pur-
poses. The parameters for KP-SVM were selected
previously according to the following values:
• Parameter C
2
represents the penalty for the feature
usage and is strongly related to C, the original reg-
ularization parameter. C
2
is considered the most
important parameter for KP-SVM, since classifi-
cation results change significantly varying its val-
ues. We try the following values, monitoring both
classification accuracy and feature usage:
C
2
= {0, 0.5C,C, 2C}
• The initial (isotropic) kernel width σ
0
, the thresh-
old ε and the gradient parameter γ are considered
less influential in the final solution, according to
our empirical results. We set σ
0
=
1
ρ
2
· e, where ρ
is the isotropic kernel width obtained in a previous
step for model selection considering all features,
and e is a vector of ones of the size of the number
of current features in the solution; ε =
1
100ρ
2
and
γ = 0.1ε||∆F(σ
0
)||, where ||∆F(σ
0
)|| represents
the Euclidean norm of the first computed gradient
vector. This combination of parameters guaran-
tees both a sufficiently small ε that avoids the re-
moval of relevant features and an adequate update
of the kernel variables, controlled by the magni-
tude of the components of ∆F(σ). This parameter
avoids a strong fluctuation of the kernel variables
and negative widths, especially at the first itera-
tions of the algorithm.
ICPRAM 2012 - International Conference on Pattern Recognition Applications and Methods
448
5.1 Description of Data Sets
In this subsection we briefly describe the different
data sets mentioned above.
Spambase Data Set (Spam). The Spambase Data
set from the UCI data repository (Asuncion and
Newman, 2007) presents 57 features and 4,601 in-
stances (2,788 emails labeled as spam and 1,813 ham
1
emails). The data set was created by Mark Hopkins,
Erik Reeber, George Forman and Jaap Suermondt
from the Hewlett Packard Labs.
Most of the features indicate whether a particu-
lar word or character was frequently occurring in the
email. The data set presents 48 continuous attributes
representing the percentage of words in the email that
match a particular word, 6 continuous attributes repre-
senting the percentage of characters in the email that
match a particular character, the average length of un-
interrupted sequences of capital letters, the length of
the longest uninterrupted sequences of capital letters
and the total number of capital letters in the email.
The predictive variables were scaled between 0 and 1.
Phishing Data Set (Phishing). The phishing cor-
pus used to test the proposed methodology, was an
English language phishing email corpus built using
Jose Nazario’s phishing corpus
2
and the SPAMAS-
SASSIN ham collection. The phishing corpus consists
of 4,450 emails manually retrieved from November
27, 2004 to August 7, 2007.
The ham corpus was built using the Spamas-
sassin collection, from the Apache SPAMASSASSIN
Project
3
, based on a collection of 6,951 ham email
messages. Both phishing and ham messages are avail-
able in UNIX mbox format. All features were extracted
according to (L’Huillier et al., 2010).
5.2 Results using Kernel-penalized
Feature Selection
First we compare the results of the best model found
using the described model selection procedure for the
three different kernel functions: linear, polynomial,
and Gaussian kernel. The following set of values for
the parameters (penalty parameter C, degree of the
polynomial function d and Gaussian Kernel width σ)
were used (Maldonado and Weber, 2009):
C = {0.1, 0.5, 1, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100,
1
“Ham” is the name used to describe regular messages
that are neither spam nor phishing.
2
Available at http://bit.ly/jnazariophishing [Online: ac-
cesses November 02, 2011].
3
Available at http://spamassassin.apache.org/publiccorp
us/ [Online: accessed November 02, 2011].
200, 300, 400, 500, 1000}
d = {2, 3, 4, 5, 6, 7, 8, 9}
ρ = {0.1, 0.5, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 100}.
Best cross-validation results were achieved for
both data sets using the Gaussian Kernel. Then we
compared the classification performance of the differ-
ent ranking criteria for feature selection by plotting
the mean test accuracy for an increasing number of
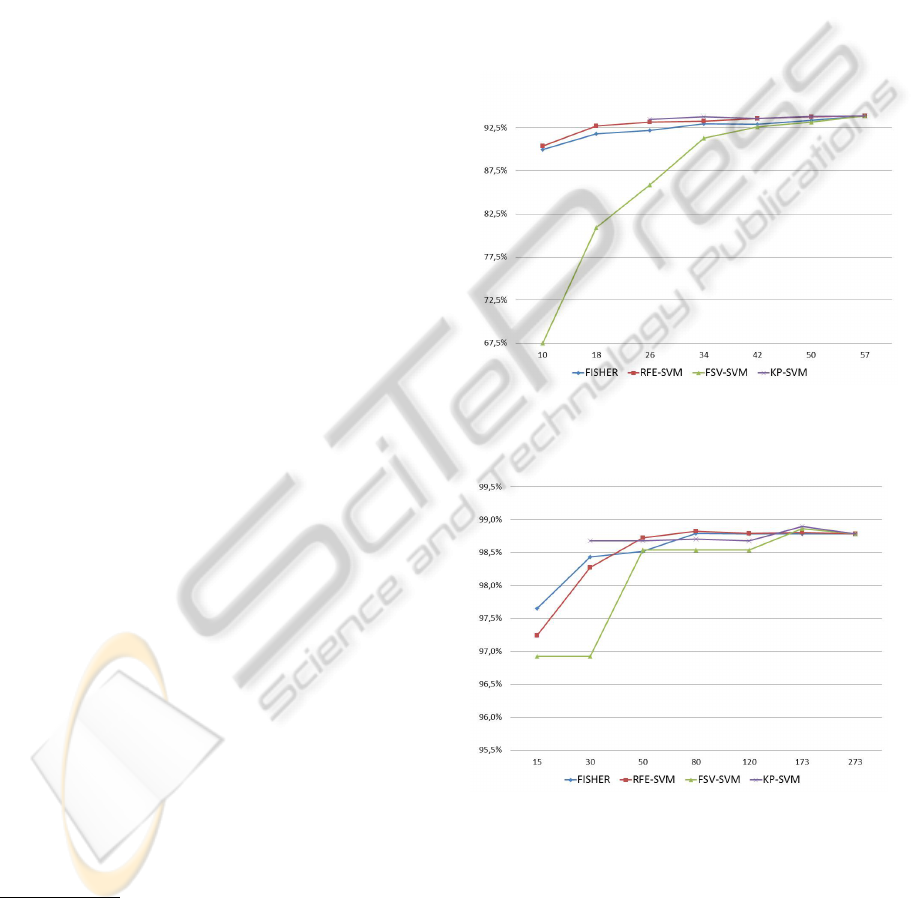
ranked features used for learning. Figures 1 and 2
show the results for each data set respectively. The
proposed KP-SVM approach provides only the infor-
mation until the stopping criterion is reached.
Figure 1: Mean of test accuracy for Spam vs. the number
of ranked variables used for training.
Figure 2: Mean of test accuracy for Phishing vs. the number
of ranked variables used for training.
These experiments underline that the proposed ap-
proach, KP-SVM, outperforms other feature selec-
tion methods in terms of classification performance
for a small number of features in both data sets used.
Another important remark is that best classification
performance is achieved for KP-SVM considering
C
2
= C for the Spam data set and C
2
= 0.5C for the
EMBEDDED FEATURE SELECTION FOR SPAM AND PHISHING FILTERING USING SUPPORT VECTOR
MACHINES
449

Phishing data set. For both data sets the use of fea-
ture penalization outperforms the model obtained us-
ing C
2
= 0, which can be considered a variant of the
ARD model presented in (Chapelle et al., 2002). This
fact proves the importance of feature selection in rel-
atively high dimensional data sets, such as the ones
presented in this work.
6 CONCLUSIONS
In this work we present an embedded approach for
feature selection using SVM applied to phishing and
spam classification. A comparison with other feature
selection methods shows its advantages:
• It outperforms other techniques in terms of classi-
fication accuracy.
• It is not necessary to set a priori the number of
features to be selected, unlike other feature se-
lection approaches. The algorithm determines the
optimal feature number according to the regular-
ization parameter C
2
.
• It can be used with other kernel functions, such as
linear and polynomial kernels.
Even if several parameters have to be tuned, the
computational effort can be reduced since the search
for a feature subset can be obtained automatically, re-
ducing computational time by avoiding a validation
step on finding an adequate number of features.
Future work has to be done in various directions.
First, we consider the extension to highly imbalanced
data sets, a very relevant topic in phishing and spam
classification, and in pattern recognition in general.
Furthermore, the current scenario for spam and phish-
ing classification suggests the extension of the pro-
posed embedded feature selection technique to very
large databases as an important research opportunity.
ACKNOWLEDGEMENTS
Support from the Chilean “Instituto Sistemas Com-
plejos de Ingenier
´
ıa” (ICM: P-05-004-F) is greatly ac-
knowledged.
REFERENCES
Asuncion, A. and Newman, D. (2007). UCI machine learn-
ing repository.
Bergholz, A., Beer, J. D., Glahn, S., Moens, M.-F., Paass,
G., and Strobel, S. (2010). New filtering approaches
for phishing email. Journal of Computer Security,
18(1):7–35.
Bradley, P. and Mangasarian, O. (1998). Feature selec-
tion v
´
ıa concave minimization and support vector ma-
chines. In Int. Conference on Machine Learning,
pages 82–90.
Canu, S. and Grandvalet, Y. (2002). Adaptive scaling for
feature selection in SVMs. Advances in Neural Infor-
mation Processing Systems, 15:553–560.
Chapelle, O., Vapnik, V., Bousquet, O., and Mukherjee,
S. (2002). Choosing multiple parameters for support
vector machines. Machine Learning, 46:131–159.
Goodman, J., Cormack, G. V., and Heckerman, D. (2007).
Spam and the ongoing battle for the inbox. Commun.
ACM, 50(2):24–33.
Guyon, I., Gunn, S., Nikravesh, M., and Zadeh, L. A.
(2006). Feature extraction, foundations and applica-
tions. Springer, Berlin.
Guyon, I., Saffari, A., Dror, G., and Cawley, G. (2009).
Model selection: Beyond the bayesian frequentist di-
vide. Journal of Machine Learning research, 11:61–
87.
L’Huillier, G., Hevia, A., Weber, R., and Rios, S. (2010).
Latent semantic analysis and keyword extraction for
phishing classification. In ISI’10: Proceedings of the
IEEE International Conference on Intelligence and
Security Informatics, pages 129–131, Vancouver, BC,
Canada. IEEE.
Maldonado, S. and Weber, R. (2009). A wrapper method
for feature selection using support vector machines.
Information Sciences, 179:2208–2217.
Maldonado, S., Weber, R., and Basak, J. (2011). Kernel-
penalized SVM for feature selection. Information Sci-
ences, 181(1):115–128.
Neumann, J., Schn
¨
orr, C., and Steidl, G. (2005). Combined
svm-based feature selection and classification. Ma-
chine Learning, 61:129–150.
Rakotomamonjy, A. (2003). Variable selection using SVM-
based criteria. Journal of Machine Learning research,
3:1357–1370.
Tang, Y., Krasser, S., Alperovitch, D., and Judge, P. (2008).
Spam sender detection with classification modeling on
highly imbalanced mail server behavior data. In Pro-
ceedings of the International Conference on Artificial
Intelligence and Pattern Recognition, AIPR’08, pages
174–180. ISRST.
Taylor, B., Fingal, D., and Aberdeen, D. (2007). The war
against spam: A report from the front line. In In NIPS
2007 Workshop on Machine Learning in Adversarial
Environments for Computer Security.
Vapnik, V. (1998). Statistical Learning Theory. John Wiley
and Sons.
Weston, J., Elisseeff, A., Sch
¨
olkopf, B., and Tipping, M.
(2003). The use of zero-norm with linear models and
kernel methods. Journal of Machine Learning re-
search, 3:1439–1461.
Weston, J., Mukherjee, S., Chapelle, O., Ponntil, M., Pog-
gio, T., and Vapnik, V. (2001). Feature selection for
SVMs. In Advances in Neural Information Processing
Systems 13, volume 13.
ICPRAM 2012 - International Conference on Pattern Recognition Applications and Methods
450
