
LOW LATENCY RECOGNITION AND REPRODUCTION OF
NATURAL GESTURE TRAJECTORIES
Ulf Großekath
¨
ofer
1
, Amir Sadeghipour
1
, Thomas Lingner
2
,
Peter Meinicke
2
, Thomas Hermann
1
and Stefan Kopp
1
1
Center of Excellence Cognitive Interaction Technology (CITEC), Bielefeld University, Bielefeld, Germany
2
Department of Bioinformatics, Institute of Microbiology and Genetics, Georg-August-University, G
¨
ottingen, Germany
Keywords:
Ordered means models, Time series prototyping, Time series reproduction.
Abstract:
In human-machine interaction scenarios, low latency recognition and reproduction is crucial for successful
communication. For reproduction of general gesture classes it is important to realize a representation that is
insensitive with respect to the variation of performer specific speed development along gesture trajectories.
Here, we present an approach to learning of speed-invariant gesture models that provide fast recognition and
convenient reproduction of gesture trajectories. We evaluate our gesture model with a data set comprising
520 examples for 48 gesture classes. The results indicate that the model is able to learn gestures from few
observations with high accuracy.
1 INTRODUCTION
In human-human interaction we find that gestures be-
tween communicating people are tightly interweaved
and thereby successfully support and structure inter-
action. Obviously, the interactands make sense of
their observations incrementally and can foresee the
continuation and/or intervene and react themselves
gesturally without significant delay. Such processing
scheme seems to be a crucial prerequisite for success-
ful communication, and gives rise to the question how
we can implement or optimize similar low-latency re-
sponses with machine learning approaches – partic-
ularly in case of the continuous multivariate observa-
tions that occur in body gestural communication. This
application becomes furthermore relevant as we wit-
ness a dramatic evolution in sensing technology over
the past years, starting with high-end time-of-flight
cameras in general and continued with low-cost sys-
tems such as the Microsoft Kinect
TM
, which promise
to make gestural communication available as standard
interface.
Gestures can be understood and represented as
multivariate state trajectories of joint/end effector
state over time, and their correct recognition and in-
terpretation are most relevant for multimodal dia-
logue systems. However, in addition to recognition, it
would also be most useful if the system could also re-
produce (or imitate) gestures, using one and the same
model. Particularly imitation is a behavior pattern ob-
served frequently in human-human interaction. Be-
yond communicative functions, gesture reproduction
is also needed if machines are to learn motion pat-
terns from example, thus allowing to command future
robots or agents by just showing an interaction. In
such a context, an abstraction of temporal variation of
gesture execution enables a speed-invariant modeling
and reproduction, and assures a most flexible applica-
bility.
A common approach for the analysis of gesture
trajectories are hidden Markov models (HMMs) (Ra-
biner, 1989). HMMs provide good representation
properties for time series data and reach excellent re-
sults in various applications (Rabiner, 1989; Garrett
et al., 2003; Kellokumpu et al., 2005). In case of
gesture data, HMMs can not only represent gesture
classes but can also be used to generate new ges-
tures (Kuli
´
c et al., 2008; Kwon and Park, 2008; Wil-
son and Bobick, 1999). Furthermore, HMMs have
also been applied to imitation learning of body move-
ments (Calinon et al., 2010; Inamura et al., 2003;
Amit and Mataric, 2002). However, the training of
HMMs usually requires a large number of examples
which complicates their application in gesture learn-
ing. In particular, for estimation of transition proba-
bilities many observations are necessary. In general,
supervised learning techniques, such as support vec-
tor machines, can successfully be used with a much
154
Großekathöfer U., Sadeghipour A., Lingner T., Meinicke P., Hermann T. and Kopp S. (2012).
LOW LATENCY RECOGNITION AND REPRODUCTION OF NATURAL GESTURE TRAJECTORIES.
In Proceedings of the 1st International Conference on Pattern Recognition Applications and Methods, pages 154-161
DOI: 10.5220/0003770901540161
Copyright
c
SciTePress

smaller number of examples but they do not provide
a model for reproduction of gestures. Furthermore, a
rejection class or criterion would be difficult to realize
with a merely discriminative learning approach.
We approach the problem of learning prototype
representations from few data examples in the con-
text of learning gestures, i.e., expressive wrist move-
ments executed in free space. We collected a data set
that contains 3-dimensional trajectories of the right
hand wrist for 48 gesture classes. For data anal-
ysis, we used a simplified, speed invariant genera-
tive model whose parameters are interpretable in data
space. Its model architecture is similar to the archi-
tecture known from HMMs, but does not include any
transition probabilities. We conduct experiments re-
garding prototype and generalization properties for
gesture trajectories when only few examples are avail-
able.
2 SETUP AND DATA
Our setup is optimized towards imitation learn-
ing during human-agent interaction. It com-
prises a time-of-flight camera, a marker-free track-
ing software and a humanoid virtual agent called
Vince (see Figure 1). The time-of-flight camera
(a SwissRanger
TM
SR4000
1
) captures the scene in 3d
at a frequency of ≈ 30 fps. The scene data are used by
the software iisu
TM
2.0
2
to map a human skeleton on
the present user in the scene. We extract the relevant
information of the skeleton, such as the user’s height,
spatial positions of the wrists and the center of mass
to compute the normalized 3d positions of the wrists
with respect to the user’s body size. Within a body-
correspondence-solver submodule, the wrists’ posi-
tions are transformed (rotated and scaled) from the
coordinate system of the camera to egocentric space
of the virtual agent which stays face-to-face to the
human demonstrator. In the current study we focus
on the right wrist and record these data as time series
for each performed gesture. During data acquisition,
Vince imitates the subject’s right hand movements in
real time. In this way, the demonstrator receives vi-
sual feedback on how Vince would perform those ges-
tures. It is worth noting that the ambiguous position
of the elbow at each time step is not captured but com-
puted with the aid of inverse kinematic (Tolani et al.,
2000).
Overall, 520 examples from 48 different gesture
classes were captured in the format of 3d wrist move-
1
http://www.mesa-imaging.ch
2
http://www.softkinetic.net
ment trajectories with time stamps. Each trajec-
tory starts from and ends at the rest position of the
right hand, whereas the gestures were demonstrated
at different velocities and require an average execu-
tion of 4.75 seconds. The performed gestures ranged
from conventional communicative gestures (“wav-
ing”, “come here” and “calm down”) over iconic ges-
tures (“circle”, “spiky”, “square”, “surface” and “tri-
angle”) to deictic gestures (“pointing” to left, right
and upward). These gestures have been performed
as 48 different classes, each with respect to some of
the following variant features: size (e.g. small and
big circle), performing space (e.g. drawing a circle at
the right side or in front of oneself), direction (clock-
wise or counter-clockwise), orientation (horizontal or
vertical), repetition (repeating some subparts of the
movement, such as drawing a circle once or twice, or
swinging the hand for several times during waving).
The complete data set is available as supplementary
material
3
.
Here, we use a simplified gesture model to pro-
vide robust recognition and learning from few ex-
amples. The essential simplification arises from a
speed invariant representation of gesture trajectories,
since the meaning and intention of most gestures are
independent of the temporal variation of execution
speed. Moreover, the fluctuation of speed might lead
to an over-detailed representation which lacks suffi-
cient generalization.
3 ORDERED MEANS MODELS
In order to learn speed invariant prototype representa-
tions, we use a specialized generative model which
we refer to as an ordered means model (OMM).
OMMs have been successfully applied to classifica-
tion of time series data before (W
¨
ohler et al., 2010;
Grosshauser et al., 2010). Similar to HMMs, OMMs
are generative state space models that emit a sequence
of observation vectors O = [o
1
, . . . , o
T
] out of K hid-
den states. As a distinguishing feature, OMMs do not
include any transition probabilities between states.
This leads to a simplified model architecture that in-
trinsically provides a speed invariant representation of
time series such as the gestures trajectories analyzed
in this study.
3.1 Model Architecture
In OMMs, the network of model states follows a left-
to-right topology, i.e. OMMs only allow transitions to
3
http://www.techfak.uni-bielefeld.de/ags/ami/publica-
tions/GSLMHK2012-LLR/
LOW LATENCY RECOGNITION AND REPRODUCTION OF NATURAL GESTURE TRAJECTORIES
155
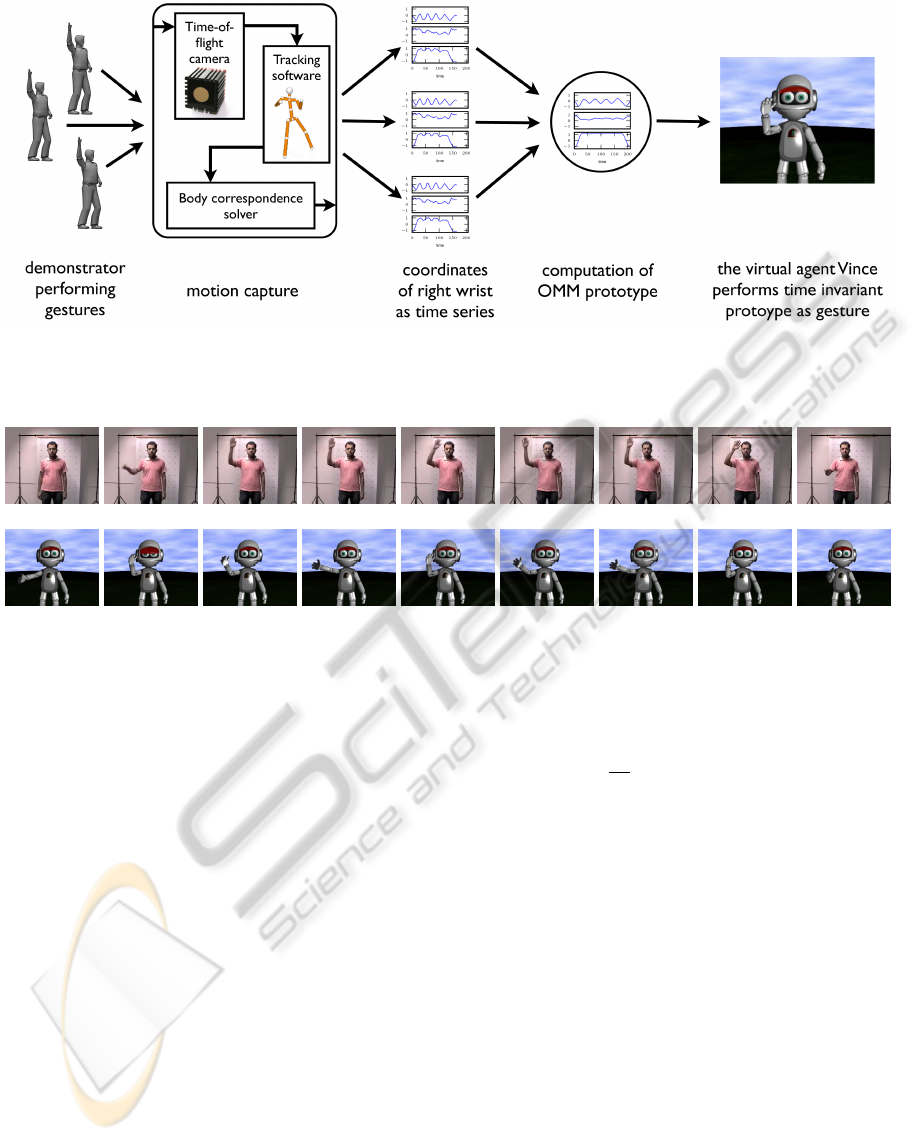
Figure 1: In our setup, demonstrated right hand gestures are captured and preprocessed within the motion capture module
and the resulting 3d trajectories are stored as time series. OMM prototypes are computed from different demonstrations and
performed by the virtual agent Vince, as the result of the prototype learning process.
Figure 2: This figure shows screenshots from the gesture videos. The first row shows video screenshots of a human demon-
strator during data acquisition. In the second row Vince, a virtual agent, performs the corresponding OMM prototype. The
gesture in these videos is from class ”waving head 2.5 swings”.
states with equal or higher indices as compared to the
current state. The emissions of each state k are mod-
eled as probability distributions b
k
(·) and are assumed
to be Gaussian with b
k
(o
t
) = N (o
t
;µ
k
, σ). The stan-
dard deviation parameter σ is identical for all states
and is used as a global hyperparameter.
With regard to the above model architecture, an
OMM Ω is completely defined by an ordered se-
quence of reference vectors Ω = [µ
1
, . . . , µ
K
], i.e. the
expectation values of the emission distributions b
k
(·).
3.2 Length Distribution
To provide a fully defined generative model, OMMs
require the definition of an explicit length distribu-
tion P(T ) either by domain knowledge or by estima-
tion from the observed lengths in the training data.
This, however, may not be possible due to missing
knowledge or non-representative lengths of the ob-
servations. To circumvent the definition and estima-
tion of a length model we assume a flat distribution
in terms of an improper prior with equally probable
lengths.
For a given length T, we define each valid
path q
T
= q
1
. . . q
T
through the model to be equally
likely:
P(q
T
|Ω) =
1
M
T
· P(T ) if q
1
≤ q
2
≤ .. ≤ q
T
,
0 else
(1)
where M
T
is the number of valid paths for a time se-
ries of length T through a K-state model:
M
T
= |{q
T
: q
1
≤ q
2
≤ ··· ≤ q
T
}| (2)
=
K + T − 1
T
. (3)
Since all paths are equally likely, there is no equiva-
lent realization in terms of transition probabilities in
HMMs.
3.3 State Duration Probabilities
The absence of state transition probabilities leads
to modified state duration probabilities in OMMs.
The state duration probabilities of HMMs depend on
the transition probabilities and are geometrically dis-
tributed. In OMMs, the probability P
k
(τ) to stay τ
time steps in state k depends on the sequence length
ICPRAM 2012 - International Conference on Pattern Recognition Applications and Methods
156

T and the number of model states K. Considering
the combinatorics of the path generation process (see
Eq. 1 and Eq. 2), the duration probability distributions
of OMMs follow
P
k
(τ) =
T +K−2−τ
K−2
T +K−1
K−1
. (4)
Note that for OMMs the state duration probabilities
depend on T , the length of the analyzed time series
examples and, therefore, varies for times series of dif-
ferent length. This is also the reason why there exists
no equivalent realization of such an modeling in terms
of transition probabilities in HMMs.
3.4 Parameter Estimation
In order to estimate particular model parameters
[µ
1
, . . . , µ
K
] by a set of observations O = {O
1
, .., O
N
}
we maximize the log-likelihood
L =
N
∑
i=1
ln p(O
i
|Ω) (5)
with respect to the mean vectors µ
k
.
To solve this optimization problem, we use an it-
erative expectation maximization algorithm (Demp-
ster et al., 1977), similar to the well-known Baum-
Welch algorithm from HMMs (Rabiner, 1989). First,
we compute the so-called responsibilities
r
i,k,t
=
p(O
i
, q
t
= k|Ω)
p(O
i
|Ω)
(E-step) (6)
and then re-estimates the model parameters according
to
µ
k
=
N
∑
i=1
T
∑
t=1
r
i,k,t
· o
i,t
N
∑
i=1
T
∑
t=1
r
i,k,t
(M-step). (7)
These steps are repeated until convergence.
3.5 Efficient Computation of
Production Likelihoods and
Responsibilities
To compute the production likelihoods p(O
i
|Ω) and
the responsibilities (Eq. 6) in a computationally ef-
ficient way, we use a dynamic programming solution
that is similar to the forward-backward algorithm (Ra-
biner, 1989) known from HMMs, but only omit tran-
sition probabilities.
We define the forward variable according to
α
i,k,t
∝ p(o
i,1
. . . o
i,t
|q
t
≤ k, Ω). (8)
Since α
i,k,t
depends only on the variable of the previ-
ous state k − 1 and of the previous point in time t −1,
this yields a fast dynamic programming solution:
α
i,k,t
= α
i,k,t−1
· b
k
(o
i,t
) + α
i,k−1,t
(9)
that is initialized with α
i,k,0
= 1, and α
i,0,t
= 0. Simi-
larly, we compute the backward variable
β
i,k,t
= β
i,k,t+1
· b
k
(o
i,t
) + β
i,k+1,t
(10)
∝ p(o
i,t
..o
i,t
|q
t
≥ k, Ω). (11)
by means of recursion, initialized with β
i,k,T +1
= 1
and β
i,K+1,t
= 0.
The production likelihood then is
p(O
i
|Ω) = α
i,K,T
= β
i,1,1
(12)
and the responsibilities can be computed by
r
i,k,t
=
α
i,k,t−1
· b
k
(o
i,t
) · β
i,k,t+1
α
i,K,T
. (13)
3.6 Classification
To use OMMs for classification, i.e. to assign an
unseen gesture trajectory to one of J classes, J
class-specific models Ω are first estimated from the
data. Assuming equal prior probabilities, an un-
known gesture O then is assigned to the class associ-
ated with the model that yields the highest production
likelihood p(O|Ω
j
) of all models.
To extend the proposed system to classification in
a continuous gesture trajectories stream, some exten-
sions would be necessary, e.g. detection of beginning
of gestures, a rejection scheme in case a user does not
perform a gesture, etc. A common approach is to par-
tition the data stream via a sliding window and reject
gestures by thresholds on the posteriori probabilities.
3.7 Prototype Property
An OMM Ω is completely represented by an ordered
sequence of reference vectors Ω = [µ
1
, . . . , µ
K
], which
correspond to the expectation values of the emission
distributions b
k
(·). Since the expectation values are
elements of the same data space as the observed data
examples, the series of reference vectors is fully in-
terpretable as a time series prototype in data space.
4 EXPERIMENTS
In order to evaluate OMMs for learning of speed-
invariant gesture prototypes from few data, we de-
signed an experimental setup to investigate the fol-
lowing research questions:
LOW LATENCY RECOGNITION AND REPRODUCTION OF NATURAL GESTURE TRAJECTORIES
157
X
−1.0
−0.5
0.0
0.5
1.0
Y
−1.0
−0.5
0.0
0.5
1.0
Z
−1.0
−0.5
0.0
0.5
1.0
X
−1.0
−0.5
0.0
0.5
1.0
Y
−1.0
−0.5
0.0
0.5
1.0
Z
−1.0
−0.5
0.0
0.5
1.0
X
−1.0
−0.5
0.0
0.5
1.0
Y
−1.0
−0.5
0.0
0.5
1.0
Z
−1.0
−0.5
0.0
0.5
1.0
X
−1.0
−0.5
0.0
0.5
1.0
Y
−1.0
−0.5
0.0
0.5
1.0
Z
−1.0
−0.5
0.0
0.5
1.0
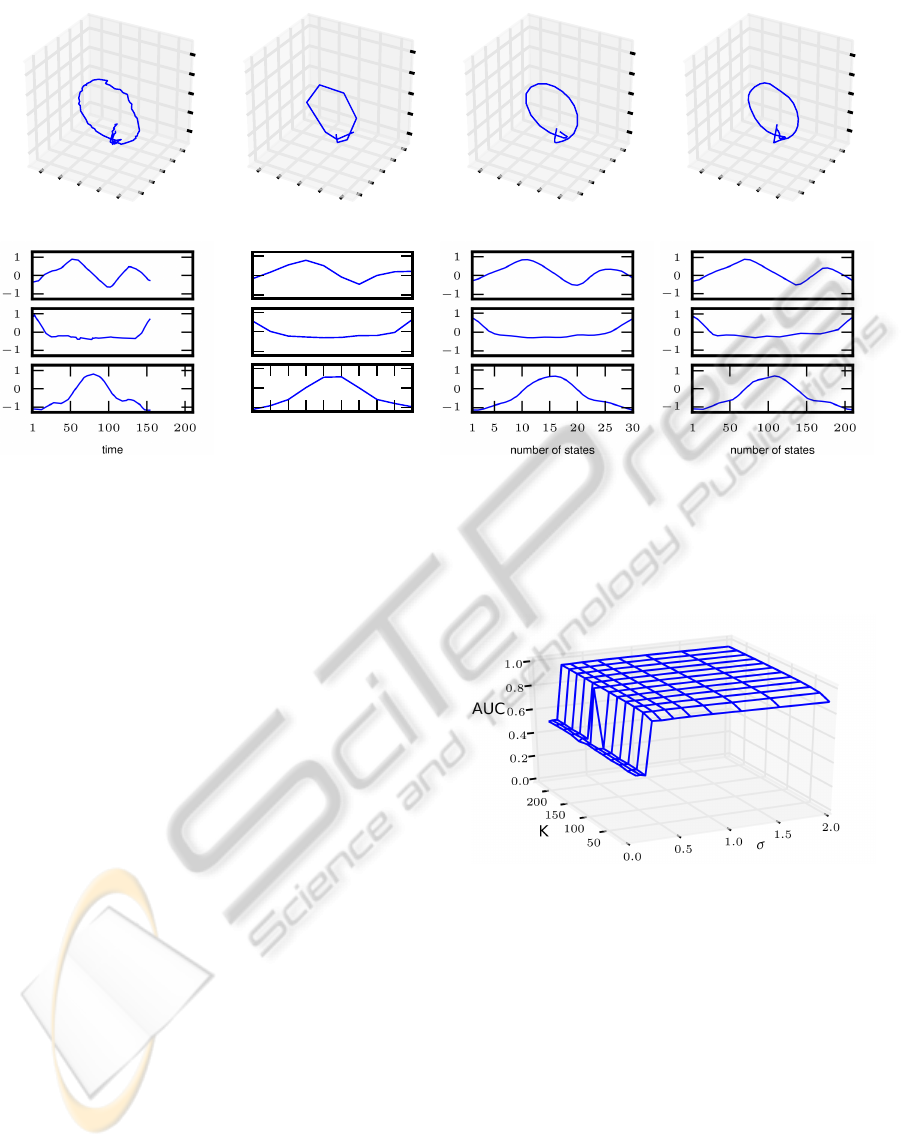
(a) example gestures
trajectory
−1
0
1
X
−1
0
1
Y
1 2 3 4 5 6 7 8 9 10
number of states
−1
0
1
Z
(b) K = 10 (c) K = 30 (d) K = 210
Figure 3: This figure shows plots of a gesture trajectory together with corresponding OMM prototypes trained with different
values for the number of model states K, as 3-dimensional plots (first row) and as x-, y-, z-location coordinates varying in
time (second row). In column one, a randomly selected gesture from class “circle, big, front, clockwise, vertical, one time” is
plotted, columns two to four show the corresponding OMM prototypes with 10, 30, and 210 model states.
1. Do the learned OMM parameters provide an in-
terpretable prototype for a set of gestures?
2. How do these prototypes perform in terms of gen-
eralization accuracy, even if only few training data
are available?
3. What influence does the number of model states
in OMMs have on the classification accuracy and
the computational demands?
To address the first question, we trained an OMM for
each gesture class and examined the resulting model
parameters. Subsequently, we let the virtual agent
Vince execute the trained prototypes and captured
these executions on video (cf. supplementary mate-
rial).
In order to address the second question, we com-
pared OMM classifiers to a standard classification
technique in terms of classification accuracy and run-
ning times on artificially reduced training data sets.
For comparison, we chose nearest neighbor classi-
fiers based on a dynamic time warping (Chiba and
Sakoe, 1978) distance function (NN
DTW
). We eval-
uated both classifiers with subsets from the training
data set, whereby the amount of training data per class
ranged from one to seven examples. Additionally, we
conducted classification experiments with all avail-
able training data. To obtain the final error rate, we
Figure 4: Dependency between the number of OMM states
K, the emission distribution parameter σ and the area-
under-curve rate in leave-one-out evaluation on the training
data set.
applied the resulting classifiers to the dedicated test
data set.
We evaluated the influence of the number of
model states K in a similar way. We trained classi-
fiers with a reduced number of model states K and
number of training examples and tested their general-
ization capabilities with the complete test data set.
For all experiments, we partitioned the data set
into a training set (369 example gestures) and a test
set (the remaining 151 examples). All data was nor-
malized to zero mean and unit variance according to
the training data. We identified optimal OMM hy-
ICPRAM 2012 - International Conference on Pattern Recognition Applications and Methods
158
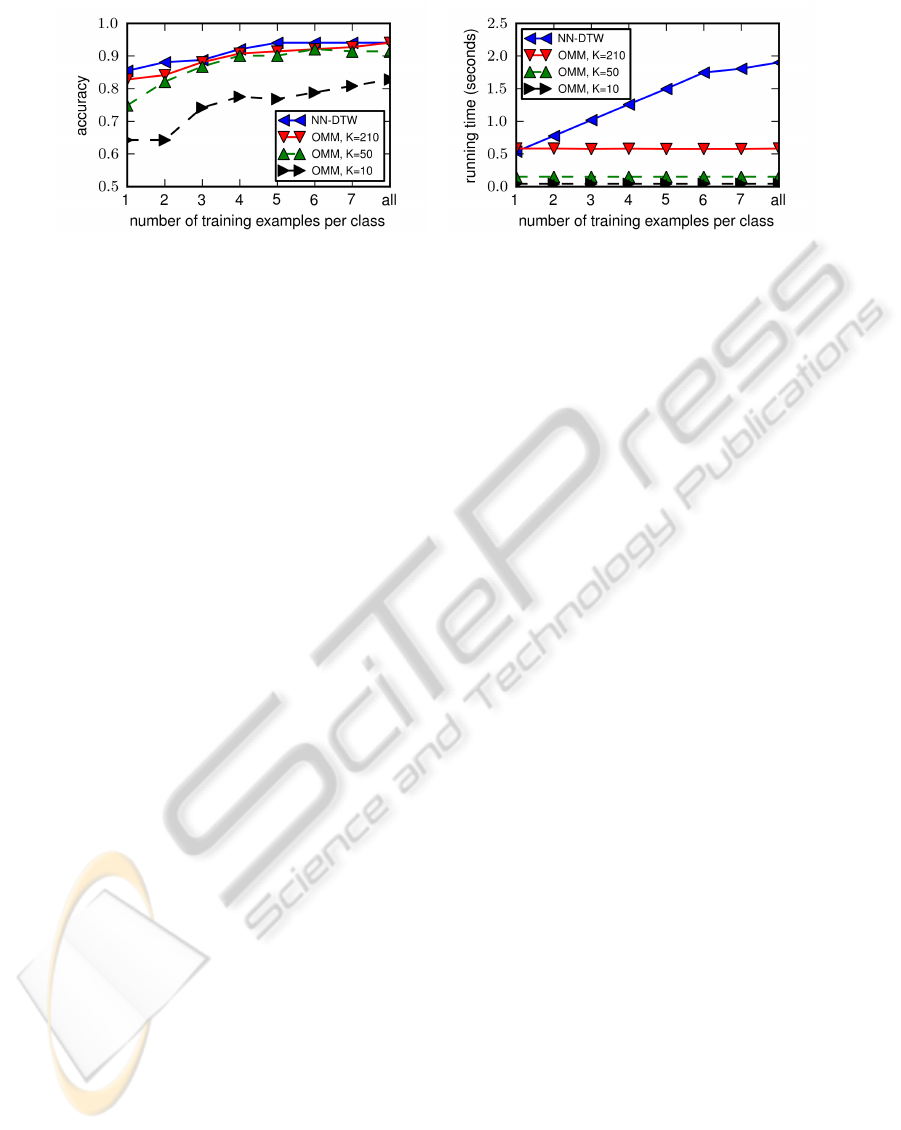
(a) Classification accuracy of test data set. (b) Average running time for classification of one unseen gesture.
Figure 5: This figure shows the accuracy (Fig. (a)) and average running times (Fig. (b)) for single trial classification of unseen
gestures for NN
DTW
and OMM classifier depending on the number of training examples per class. For OMM classifier,
different values for the number of model states K ∈ {10, 50, 210} are plotted.
perparameters K and σ by means of leave-one-out
cross validation on the training data set. As the cri-
terion for hyperparameter optimization, we chose the
area under the receiver operating curve (AUC). We
trained a model with the training data of one class
(except the one left out). We then used the left out
gesture as a positive and the gesture data from the re-
maining classes as negative examples for AUC analy-
sis. We chose eleven equidistant values for the num-
ber of OMM states K ∈ {10, 30, . . . , 230}, the set
of values for the standard deviation parameter was
σ ∈ {2 · 0.75
y
|y = 1, . . . , 10}. We initialized the iter-
ative model estimation scheme of OMMs with ran-
domized deterministic assignments, i.e. a randomly
selected combination of model states for each train-
ing example, of all training data to the model states.
The resulting random paths are forced to follow the
restrictions induced by the left-to-right model topol-
ogy.
We measured the running time in terms of the sin-
gle core CPU time on an Intel Xeon CPU with 2.5
GHz. The OMM and NN
DTW
algorithms used in
this study were implemented in the Python program-
ming language. Time-critical parts such as the dy-
namic programming code were realized using the C
programming language. We provide an OMM Python
package as well as the complete OMM source code
for download as supplementary material.
5 RESULTS AND DISCUSSION
Figure 3 shows graphical representations of a ran-
domly selected gesture from class “circle, big, front,
clockwise, vertical, one time” together with plots of
corresponding OMM prototypes with different val-
ues for the number of model states K. The first
row shows the data as 3-dimensional plots and the
second row shows the same data as location coordi-
nates developing over time. For the prototypes, we
chose three different values for the number of states
K ∈ {10, 30, 210}. As standard deviation parameter,
we chose σ = 0.84375, the value that reached the
highest AUC value of ≈ 0.95 in leave-one-out vali-
dation.
The plots indicate a clear correspondence between
an underlying gesture class and the learned OMM pa-
rameters, and it is obvious that OMMs are able to ex-
tract prototype representations of the gestures. Even
a prototype with K = 10 model states reveals a tra-
jectory that is similar to the genuine circle gesture.
For K = 30 the plot of the prototype fully represents
a circle gesture that, in comparison to a model with
K = 210 states, only differs in length.
To underline the abstraction capacity, we executed
all gesture prototypes with our virtual agent Vince. In
the supplementary material, we attached a video that
contains example gestures from all 48 gesture classes,
and recordings of the virtual agent performing the re-
lated gesture prototypes. Additionally, figure 2 shows
screenshots of these video recordings. The first row
shows video screenshots from a human demonstra-
tor performing a gestures during data acquisition, the
screenshots in the second row show how the virtual
agent Vince is executing the learned OMM parame-
ters from the matching class. In this video the demon-
strator and Vince are performing the gesture “waving
head 2.5 swings”.
In general, both results—the examination of the
learned prototype as well as the videos of Vince who
executes these prototype gestures—indicate that the
speed-invariant architecture of OMMs is able to de-
duce essential gesture features from a set of example
trajectories. However, some videos (e.g. all “come”
and “surface” prototypes) suggest that using only a
limited body model, i.e. the right hand wrist, might
not be adequate to fully reproduce a gesture. E.g.,
LOW LATENCY RECOGNITION AND REPRODUCTION OF NATURAL GESTURE TRAJECTORIES
159

Vince’s performance of the “come” prototype lacks
the orientation of his hand palm. Even though the
plain hand wrist trajectory matches the subject’s hand
wrist trajectory, the incorrectly oriented palm might
make it difficult for a human user to identify the in-
tended gesture. Presumably, a more detailed body
model, as e.g. in (Bergmann and Kopp, 2009), would
improve the prototype representation. In contrast,
other gesture classes are sufficiently represented only
by hand wrist trajectories, e.g., Vinces performances
of all waving related classes are easy to comprehend.
Figure 4 illustrates the dependency between the
hyperparameters (K, σ) and the leave-one-out ac-
curacy in terms of AUC rates. This figure clearly
demonstrate that the accuracy remains stable and is
almost independent of the number of states K and the
value of emission distribution parameter σ. Only for
values of σ < 0.2 or K = 10 the AUC accuracy sub-
stantially decreases.
Figure 5(a) shows the performance results of our
evaluation in terms of classification accuracy on the
test set depending on the number of training exam-
ples per class for different classifiers. These in-
clude OMMs with a high number of states according
to maximum classification accuracy (K = 210) and
OMMs with a reduced number of states (K = 10, 50).
In general, all classifiers are able to recognize un-
seen gesture trajectories with high accuracy, although
OMM classifier with 10 model states reach substan-
tially lower accuracy. Using all training examples,
NN
DTW
as well OMMs classify gestures with high ac-
curacy of ≈ 0.94, although the performance for OMM
classifiers with only K = 10 is noticeably lower. The
plot also shows that a reduction of the number of
training examples does not substantially reduce the
classification accuracy. Only for OMMs with a low
number of states, a degradation can be observed be-
low three examples.
The slightly higher recognition performance of
NN
DTW
classifiers comes at the cost of substantially
increased computational demands. In the scenario
with all available training data, OMMs classifiers pro-
vide an average speed-up factor of at least ≈ 3. For
decreasing number of models states the speed-up fac-
tor increases once more. OMM classifier with K = 50
respond in ≈ 0.14 seconds, with K = 10 OMM clas-
sify an unseen gesture in 0.04 seconds. In comparison
to the average classification times of NN
DTW
this is an
acceleration between 3 and 44 times. This allows low-
latency recognition of gesture performances which is
a requirement for interaction with humans.
6 CONCLUSIONS
We applied ordered means models (OMMs) to recog-
nize and reproduce natural gesture trajectories. The
results from our classification experiment show that
OMMs are able to learn gestures from multivariate
times series even if only few observations are avail-
able. Furthermore, our run time measurements indi-
cate, that OMMs are well suited for low latency ges-
ture recognition. Even though more complex mod-
els and methods might further increase the recogni-
tion performance, in particular in human computer
interaction scenarios the response time is crucial.
Here, OMMs are able to provide a suitable trade-
off between accuracy and computational demands.
We showed that OMMs with few model states can
still reach competitive accuracy indices while consid-
erably decreasing computational demands to ensure
low latency capability. The combination of abstract-
ing and reproducing prototypical gesture trajectories,
the achievable response times, and the high recogni-
tion accuracy even for small training data sets makes
OMMs an ideal method for human computer interac-
tion.
In our ongoing research we focus on the auto-
matic optimization of classification in online use on
continuous interaction streams. Additionally, we are
working on a porting the gesture tracking system
to Microsofts Kinect
TM
. To further improve dis-
crimination performance in supervised setups, future
work in this context will include the use of Fisher
kernels (Jaakkola et al., 1999), which are straight-
forward to derive from OMMs.
ACKNOWLEDGEMENTS
This work is supported by the German Research
Foundation (DFG) in the Center of Excellence for
Cognitive Interaction Technology (CITEC). Thomas
Lingner has been funded by the PostDoc program of
the German Academic Exchange Service (DAAD).
REFERENCES
Amit, R. and Mataric, M. (2002). Learning movement se-
quences from demonstration. In ICDL ’02: Proceed-
ings of the 2nd International Conference on Develop-
ment and Learning, pages 203–208, Cambridge, Mas-
sachusetts. MIT Press.
Bergmann, K. and Kopp, S. (2009). Gnetic – using bayesian
decision networks for iconic gesture generation. In
Proceedings of the 9th Conference on Intelligent Vir-
tual Agents, pages 76–89. Springer.
ICPRAM 2012 - International Conference on Pattern Recognition Applications and Methods
160

Calinon, S., D’halluin, F., Sauser, E., Caldwell, D., and Bil-
lard, A. (2010). Learning and reproduction of gestures
by imitation. Robotics Automation Magazine, IEEE,
17(2):44 –54.
Chiba, S. and Sakoe, H. (1978). Dynamic programming
algorithm optimization for spoken word recognition.
IEEE Transactions on Acoustics, Speech and Signal
Processing, 26(1):43.
Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977).
Maximum likelihood from incomplete data via the em
algorithm. Journal of the Royal Statistical Society, Se-
ries B, 39(1):1–38.
Garrett, D., Peterson, D., Anderson, C., and Thaut, M.
(2003). Comparison of linear, nonlinear, and fea-
ture selection methods for EEG signal classification.
Neural Systems and Rehabilitation Engineering, IEEE
Transactions on, 11(2):141–144.
Grosshauser, T., Großekath
¨
ofer, U., and Hermann, T.
(2010). New sensors and pattern recognition tech-
niques for string instruments. In International Con-
ference on New Interfaces for Musical Expression,
NIME2010, Sydney, Australia.
Inamura, T., Toshima, I., and Nakamura, Y. (2003). Ac-
quiring motion elements for bidirectional computation
of motion recognition and generation. In Siciliano,
B. and Dario, P., editors, Experimental Robotics VIII,
volume 5, pages 372–381. Springer-Verlag.
Jaakkola, T., Diekhaus, M., and Haussler, D. (1999). Us-
ing the fisher kernel method to detect remote protein
homologies. Proceedings of the Seventh International
Conference on Intelligent Systems for Molecular Biol-
ogy, pages 149–158.
Kellokumpu, V., Pietik
¨
ainen, M., and Heikkil
¨
a, J. (2005).
Human activity recognition using sequences of pos-
tures. In Proceedings of the IAPR Conference on Ma-
chine Vision Applications (MVA 2005), Tsukuba Sci-
ence City, Japan, pages 570–573. Citeseer.
Kuli
´
c, D., Takano, W., and Nakamura, Y. (2008). Incre-
mental learning, clustering and hierarchy formation
of whole body motion patterns using adaptive hidden
markov chains. The International Journal of Robotics
Research, 27(7):761.
Kwon, J. and Park, F. (2008). Natural movement genera-
tion using hidden markov models and principal com-
ponents. Systems, Man, and Cybernetics, Part B: Cy-
bernetics, IEEE Transactions on, 38(5):1184–1194.
Rabiner, L. (1989). A tutorial on hidden markov models
and selected applications in speech recognition. Pro-
ceedings of the IEEE, 77(2):257–286.
Tolani, D., Goswami, A., and Badler, N. (2000). Real-
time inverse kinematics techniques for anthropomor-
phic limbs. Graphical models, 62(5):353–388.
Wilson, A. and Bobick, A. (1999). Parametric hidden
markov models for gesture recognition. Pattern Anal-
ysis and Machine Intelligence, IEEE Transactions on,
21(9):884–900.
W
¨
ohler, N.-C., Großekath
¨
ofer, U., Dierker, A., Hanheide,
M., Kopp, S., and Hermann, T. (2010). A calibration-
free head gesture recognition system with online capa-
bility. In International Conference on Pattern Recog-
nition, pages 3814–3817, Istanbul, Turkey. IEEE
Computer Society, IEEE Computer Society.
LOW LATENCY RECOGNITION AND REPRODUCTION OF NATURAL GESTURE TRAJECTORIES
161
