
POTENTIAL FIELD BASED INTEGRATED EXPLORATION FOR
MULTI-ROBOT TEAMS
Miguel Juli´a, Arturo Gil, Luis Pay´a and
´
Oscar Reinoso
Miguel Hern´andez University, System Engineering Department
Avda. Universidad s/n. Edif. Torreblanca, 03202 Elche-Alicante, Spain
Keywords:
Integrated Exploration, SPLAM, Potential Fields, Cooperative Mobile Robotics.
Abstract:
In this paper we present an approach for multi-robot cooperative exploration based on the potential field
generated by several basic behaviours. When an unknown environment is explored the uncertainty in the
localization normally grows, this fact may cause the failure of the Simultaneous Localization and Mapping
(SLAM) algorithm, and thus constructing an useless and inaccurate map. The exploration algorithm described
here considers the current knowledge of the environment, the location of the robots and the uncertainty in their
positions in order to return to previously explored areas when it is needed. These actions definitely help the
SLAM algorithm to build a precise map. Several simulations are presented that demonstrate the validity of the
approach.
1 INTRODUCTION
In the last years, a large number of applications have
emerged that require the utilization of cooperative
mobile robots. Most of these applications require the
robot team to be able to explore unknown environ-
ments autonomously. Employing multiple robots in-
stead of a single robot in exploration is an advantage
because the exploration time could be reduced (Cao
et al., 1995).
Simultaneous Localization and Mapping (SLAM)
techniques are generally used to explore an unknown
environment. They allow to build a map that de-
scribes the environment while simultaneously using
that map to localize the robots. However, the result
obtained by the SLAM algorithm strongly depends
on the trajectories performed by the robots (Stachniss
et al., 2005). When the robots travelthroughunknown
environments, the uncertainty over their position in-
creases and the construction of the map becomes dif-
ficult. Returning to previously explored areas or clos-
ing loops reduces the uncertainty over the pose of the
robots and improves the SLAM process.
Typical exploration algorithms do not take local-
ization uncertainty into account and direct the ex-
ploration in order to minimize the distance traveled
while maximizing the information gained. However,
the solution presented here explores the environment
efficiently and also considers the requisites of the
SLAM algorithm. Our algorithm considers return-
ing to previously explored places when the uncer-
tainty becomes too large. This idea has been previ-
ously exploited by other authors and is commonly de-
noted as Integrated Exploration or SPLAM (Simulta-
neous Planning Localization And Mapping). A solu-
tion to the SPLAM problem enables a mobile robot to
acquire data from sensors by autonomously moving
through its environment while at the same time build-
ing a map. The main contribution of this paper is a
new technique for Integrated Exploration for multi-
robot teams.
The remainder of the paper is structured as fol-
lows. Section 2 discusses related work and Section
3 presents the behaviour based exploration algorithm.
In Section 4 we explain the active localization state.
Next, Section 5 presents simulation results to test the
functionality of the method proposed. Finally, the
main conclusions and future work are presented.
2 RELATED WORK
Exploration techniques work basically using the fron-
tier concept introduced by (Yamauchi, 1997). He di-
vided the map into a regular grid of cells where to rep-
resent the occupation probability. At the beginning of
the exploration all the cells are unknown, so they are
308
Juliá M., Gil A., Payá L. and Reinoso Ó. (2008).
POTENTIAL FIELD BASED INTEGRATED EXPLORATION FOR MULTI-ROBOT TEAMS.
In Proceedings of the Fifth International Conference on Informatics in Control, Automation and Robotics, pages 308-314
DOI: 10.5220/0001508903080314
Copyright
c
SciTePress

initialized with an occupation probability of 0.5. This
value is updated with the information of the sensors
of the robots during the exploration. Relying on the
occupation probability for each cell, the cells are la-
beled as free, occupied or unknown. Frontier cells are
free cells that lie next to an unknown cell.
A group of explorationmethods employ path plan-
ning techniques in order to direct the robots to the
frontier cells (Simmons et al., 2000; Burgard et al.,
2005; Zlot et al., 2002). They differ in the coordina-
tion strategies used to assign a frontier to each robot:
the robots can go to the nearest frontier (Yamauchi,
1997) or they can follow a cost-utility model to make
their assignments. Normally, the cost is the length of
the path to a frontier cell, whereas utility could be un-
derstood in different ways: (Simmons et al., 2000)
consider the utility as the expected visible area be-
hind the frontier. (Burgard et al., 2005) consider in
the utility function the proximity of frontiers assigned
to other robots. (Zlot et al., 2002) suggest using a
market economy where the robots negotiate their as-
signments.
Another group of exploration techniques makes
use of potential field methods (Arkin and Diaz, 2002).
Potential field based exploring methods take into ac-
count a set of behaviours to generate a resultant po-
tential field. The most common behaviours in explo-
ration are attraction to frontiers and repulsion from
obstacles and other robots. This leads to the avoid-
ance of other robots and collisions and also improves
the exploration by dispersing the robots. As stated by
many authors, the main drawback of this technique is
the occurrence of local minima in the potential field,
which may trap the robot and block the exploration
process. A common solution to this problem is to plan
a path to a frontier cell in order to get the robot out
from the local minimum (Lau, 2003).
A few authors used integrated exploration in the
last years (Feder et al., 1999; Bourgoult et al., 2002;
Makarenko et al., 2002; Sim et al., 2004; Stachniss
et al., 2005). (Feder et al., 1999) decide the next
movement for robots by optimizing the information
gain of the environment and minimizing the uncer-
tainty in the localization of the robot. (Bourgoult
et al., 2002) and (Makarenko et al., 2002) use a simi-
lar idea including the uncertainty in the localization as
part of the utility function in the assignment of desti-
nations to robots. These 3 techniques are based on the
estimation of landmarks and they try to prevent that
the uncertainty in the pose of the robots grows, by
means of keeping always well estimated landmarks
in the field of view. (Sim et al., 2004) recover the
certainty over the pose of the robots during the explo-
ration using a parametric curve trajectory and includ-
ing returning to explored zones when the uncertainty
in the pose of the robot is too high. (Stachniss et al.,
2005) reduce the uncertainty by actively closing loops
with previously explored areas. They create a topo-
logical map of the environment and look for oppor-
tunities for closing loops in it. As we can see, there
are two main approaches to the problem of localiza-
tion during the exploration: to take the uncertainty
in the pose of the robots into account when choosing
the movements for the robots or to explore and re-
turn later to previously explored zones when the un-
certainty is large.
In this paper, a potential field based SPLAM tech-
nique is described. It is based on the potential field
generated by several basic behaviours designed to
rapidly explore the environment. It also considers re-
turning to previously explored zones when needed.
3 BEHAVIOUR-BASED
EXPLORATION ALGORITHM
In typical environments we can find a set of highly
distinctive elements that can be easily extracted with
the sensors of a robot. These elements are typi-
cally called landmarks. In our application, we as-
sume that the robots are able to detect a set of distinc-
tive 3D visual landmarks and they are able to obtain
relative measurements to them using stereo cameras.
These landmarks can be extracted as interest points
found in the images of the environment (Mozos et al.,
2007). The robot team is able to build a map with
a vision-based technique consisting on a particle fil-
ter approach to the SLAM problem, known as Fast-
SLAM (Gil et al., 2007).
Landmark based maps do not represent the free or
occupied areas in the environment. This is the rea-
son why we make use of a grid map to represent free
and occupied cells detected using the information of
the sonar. In addition, all the cells have a numerical
value associated that indicates their degree of explo-
ration, which is increased each time it falls into the
field of view of the robot, until it reaches a limit value
when the cell is considered to be fully explored. A
cell with an exploration degree of zero is considered
unexplored. We define the frontier cells as explored
cells that lie next to an unexplored cell that do not
belong to an obstacle.
Our approach to the problem of multi-robot explo-
ration consists of five basic behaviours whose com-
position results in the trajectory of each robot in the
environment:
Go to unexplored Areas: Each cell attracts each
robot with a force that depends on the degree of ex-
POTENTIAL FIELD BASED INTEGRATED EXPLORATION FOR MULTI-ROBOT TEAMS
309

Table 1: Forces defined for each behavior.
Go to unexplored areas:
~
F
1
k
=
1
M
∑
M
i=1
ν−e
i
ν
~s
i
−~p
k
r
3
i,k
Go to frontier:
~
F
2
k
=
1
M
F
∑
M
F
i=1
~s
i
−~p
k
r
3
i,k
Avoid other robots:
~
F
3
k
=
1
X
∑
X
j=1
−
~p
j
−~p
k
r
3
j,k
Avoid obstacle:
~
F
4
k
=
1
M
O
∑
M
O
i=1
−
~s
i
−~p
k
r
3
i,k
Improve imprecise landmarks:
~
F
5
k
=
1
n
t
∑
n
t
l=1
σ
l
~q
l
−~p
k
r
3
l,k
M: Number of cells in the map.
M
F
: Number of frontier cells.
M
O
: Number of obstacle cells in the range.
X: Number of robots.
n
t
: Current number of imprecise landmarks.
e
i
: Exploration level of cell i.
ν: Maximum exploration level.
σ
l
: Landmark position measure uncertainty.
~s
i
: Position vector of the i-th cell.
~p
j
: Position vector of the j-th robot.
~p
k
: Position vector of the k-th robot.
~q
l
: Position vector of the l-th landmark
r
i,k
: Distance from i-th cell to robot k.
r
j,k
: Distance from robot j-th to robot k.
r
l,k
: Distance from l-th landmark to robot k.
ploration of the cell.
Go to Frontier: This behaviour attracts the robots
to frontier cells since these are the cells that give way
to areas of interest.
Avoid other Robots: This behaviour results in a
repulsive force between robots that normally allows
to spread the robots around the environment.
Avoid Obstacle: Each cell within a specific range
that is identified as belonging to an obstacle, applies
a repulsive effort over every robot. This range allows
to easily adjust the system.
Improve imprecise Landmarks: This behaviour
tries to improve the quality of the exploration of those
areas where some landmarks have been extracted but
whose accuracy is not high enough.
Table 1 shows how the forces are calculated for
each behaviour. This way, the resulting force of the
combination of those five behaviours on each robot
constitutes a vector that indicates the trajectory of the
robot to optimize the exploration process as follows:
~
F
A
k
= k
1
~
F
1
k
+ k
2
~
F
2
k
+ k
3
~
F
3
k
+ k
4
~
F
4
k
+ k
5
~
F
5
k
. (1)
−2 0 2 4 6 8 10 12 14 16
10
15
20
25
30
(m)
(m)
Go To Unexplored Areas
Go To Frontier
Avoid Obstacles
Avoid Other Robots
Go To Imprecise Landmarks
Current Heading
Resultant Force
Figure 1: Weighted outputs of the behaviours and resultant
force in an exploring situation. Also, the landmarks that
have been detected until that moment are shown.
The composition of the behaviours is carried out
taking into account a set of weights k
i
whose value is
deduced experimentally. Fig. 1 shows the bird’s eye
view of an exploring situation with three robots.
Potential field methods have a main disadvantage:
when exploring complex environments, a robot may
be trapped at local minima in the potential field and
may not move, thus stopping the exploration process.
To solve this problem, we assume that we are able to
detect the situation in which the robot is trapped at a
local minimum. In this case, a new state is triggered
that enables the robot to escape from the local mini-
mum by planning a path to the nearest frontier cell.
4 INTEGRATED EXPLORATION
As an unknown environment is explored the uncer-
tainty in the localization of the robot grows. When
the uncertainty over the pose of the robots is high,
it is difficult to generate a correct map, and thus the
exploration process is inefficient. If the error in the
localization is very high, some frontiers and obstacles
could be added to the grid map erroneously and some
zones could remain unexplored. The perceptions of
the robots in a given moment can be in conflict with
past perceptions or with perceptions of other robots
because of a deficient localization.
Figure 2 shows an example of an extremely de-
ficient exploration caused by a large error in the lo-
calization. It can be observed how the wrong loca-
tion of some obstacles obstructs the corridor and part
of the environment remain unexplored. The error in
the map of landmarks created is considerably high.
All the landmarks in the map should appear over the
walls but they are situated erroneously. These are the
reasons we introduce new techniques to improve the
localization.
The SLAM method we use in our experiments is
commonly known as FastSLAM (Gil et al., 2007). It
ICINCO 2008 - International Conference on Informatics in Control, Automation and Robotics
310
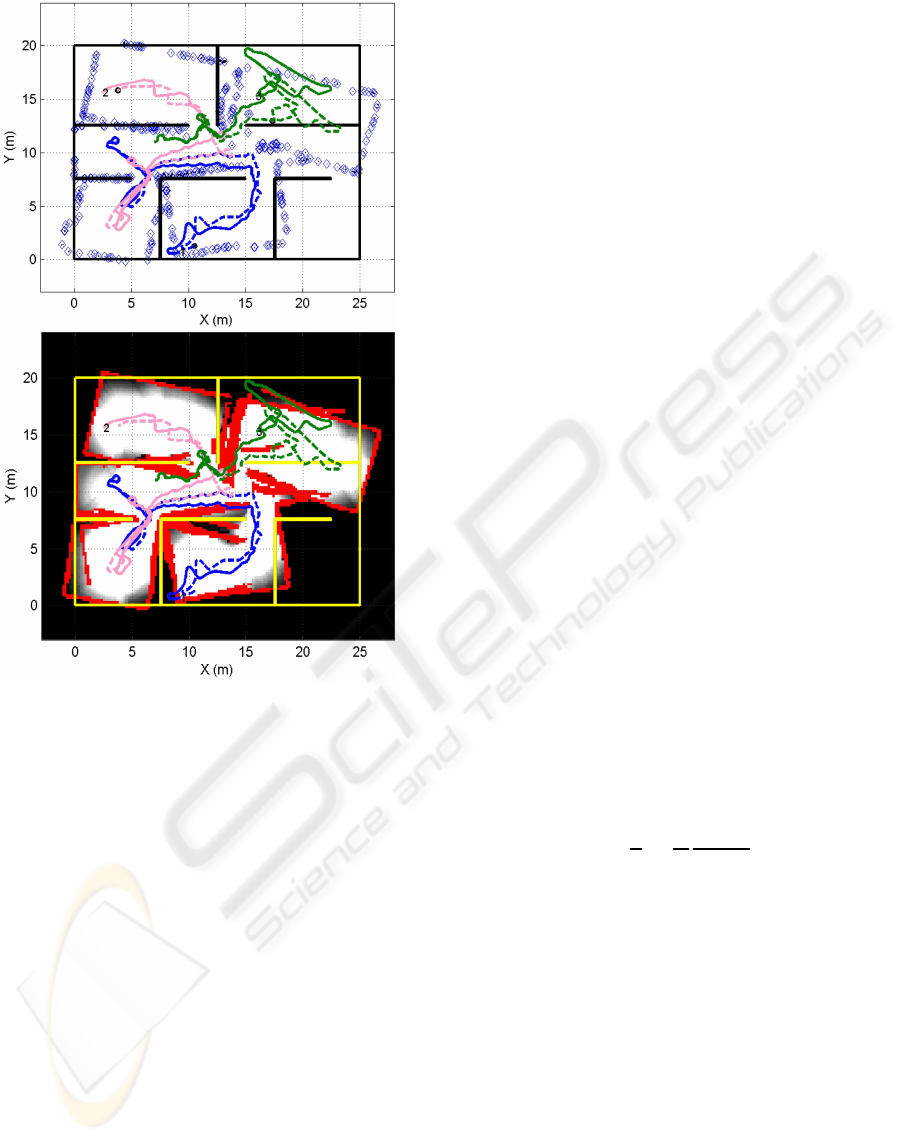
Figure 2: The upper figure shows the visual landmark map
created in an exploration with deficient localization. The
trajectories performed by the the robots are indicated in con-
tinuous lines and the estimated trajectories in discontinuous
lines. The landmarks detected are marked in their estimated
position. The bottom figure shows the grip map generated
for this situation. The grade of exploration is indicated in
gray levels and the obstacles detected in red color. Real ob-
stacle positions are marked in yellow.
consists of a particle filter, each particle having an es-
timation for the path of each robot and an estimation
of a set of landmarks conditioned to the path. We can
measure the uncertainty on the localization of a robot
by considering the dispersion for all the particles in
the position of the robot. When travelling through un-
known terrain, the dispersion of the particles usually
increases since each is well localized in his own local
map. Since we are using a finite number of particles
to represent the pose of the robots, this representa-
tion gets worse when the uncertainty is too high. In
this case we consider returning to previously explored
areas to reduce this uncertainty. This idea has been
employed by many authors (Feder et al., 1999; Bour-
goult et al., 2002; Makarenko et al., 2002; Sim et al.,
2004; Stachniss et al., 2005). Avoiding large periods
of time with a high dispersion is a good technique to
avoid the accumulation of error in the global localiza-
tion and an accurate map can be obtained. Thus, our
strategy is to return to positions with low dispersion
when the dispersion in the pose of the robot grows.
This solution produces a better estimation of the map
and the robot’s path.
We denote the model explained in Section 3 as the
Exploration State (StateA). Besides, we introduce an
Active Localization State (StateB). The Exploration
State allows exploring new areas of the map mean-
while the robots are well localized. The Active Local-
ization State intends to lead the robots to previously
explored areas when they have a relatively high uncer-
tainty associated, thus improving their localization.
The transition between both states is made according
to a hysteretic model with two transition thresholds
that are compared with the dispersion in the pose of
the robot.
In the Active Localization State, the control action
of the robot is the composition of Avoid Obstacle, al-
ready presented, and a new behaviour Go to Accurate
Landmarks. This new behavior aims at localizing the
robot returning to previously explored landmarks.
Go to Accurate Landmarks: This behaviour tries
to improve the estimation of the position of the robot,
driving it to landmarks whose position has a robust
estimation. Given a landmark, its position is calcu-
lated for each particle and a measure of its dispersion
ε
l
is calculated using the correspondent landmarks for
the different particles. The correspondence is done
considering an unique visual descriptor for each land-
mark. Each accurate landmark attracts the robot with
a force inversely proportional to the distance:
~
F
6
k
=
1
n
n
∑
l=1
1
ε
l
~q
l
−~p
k
r
2
l,k
. (2)
being n the current number of landmarks in the map,
~q
l
is the position of the l-th landmark, ~p
k
is the po-
sition of the robot k and r
l,k
is the euclidean distance
between both positions . Then the trajectory to follow
is pointed by the vector:
~
F
B
k
= k
4
~
F
4
k
+ k
6
~
F
6
k
, (3)
where the weights are deduced experimentally.
As stated before, the local minima in the poten-
tial field can block the exploration process. In these
cases, we plan a path to the nearest frontier cell. This
solution directs the robots to unknown areas and thus
is only a good solution in the State A. In StateB, local
minima are also likely to appear. In this case, we plan
a path to the last past position in the trajectory of the
robot where the dispersion is low.
POTENTIAL FIELD BASED INTEGRATED EXPLORATION FOR MULTI-ROBOT TEAMS
311
Dispersion > Th A
Local minimum detected
Dispersion < Th B
Target achieved
Local minimum detected
Dispersion > Th A
A
B
C
C’
Target achieved
Dispersion < Th B
(Path to Nearest Frontier)
(Path to low dispersion Pose)
Well Localized
Bad Localized
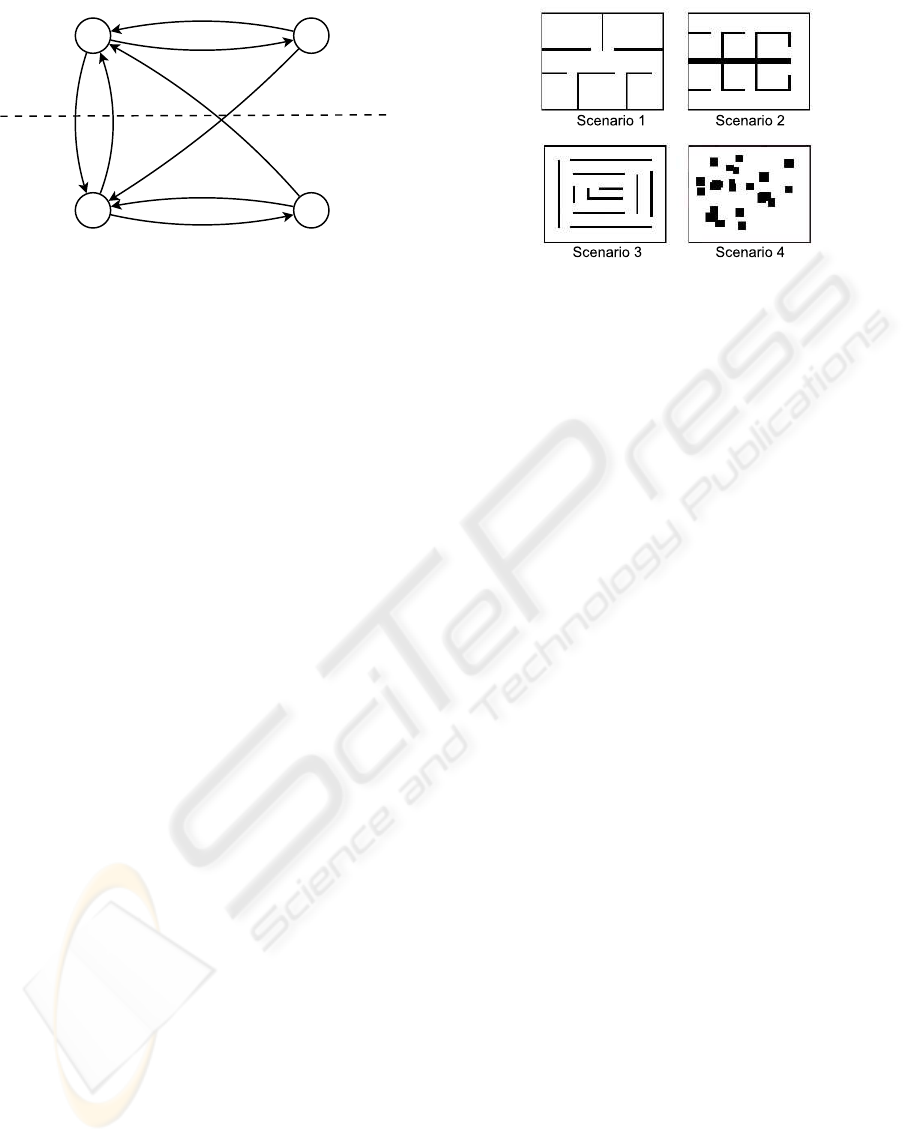
Figure 3: State transition diagram.
Figure 3 shows the state diagram for a robot. We
can distinguish two zones of operation: when the
robot is well localized and when it is not. When it is
well localized, it explores the environment by follow-
ing the State A combination of behaviors. If it finds a
local minimum during the exploration it plans a path
(State C) to the nearest frontier cell. When it arrives
to this cell it returns to the State A. If the dispersion on
the robot position in the particle filter is over a given
threshold the robot is considered to be bad localized
and it switches to the Active Localization State (B). If
it finds a local minimum being in this state, it plans
a path (C’) to a past position in the trajectory with
low dispersion. When the dispersion decreases below
a threshold the robot returns to the Exploration State
(A).
5 EXPERIMENTS AND RESULTS
In this section, we analyze simulation results of the
method proposed in this paper. The proposal is tested
in presence of uncertainty in the robots localization to
show the improvement in the quality of the maps gen-
erated and in the estimated path using the techniques
proposed to return to previously explored areas.
The scenarios chosen to test the method are shown
in Figure 4. Scenarios that represent hypothetical real
places like Scenario 1 or Scenario 2 were chosen at
the same time that other artificial scenarios as for ex-
ample Scenario 3 or a completely random scene as
Scenario 4.
The method proposed is tested with and with-
out considering the uncertainty in the position of the
robots. Besides, it is compared with a pure path plan-
ning approach where the robots always plan a path
to the nearest frontier cell. The mean error per robot
in the estimated trajectories, the exploration time, as
well as the error in the map of landmarks are ana-
lyzed.
The results of the simulation are shown in Figure
Figure 4: Scenarios.
5. On Scenario 1 and Scenario 4, the error on the
estimated path and in the map is smaller with the pro-
posed integrated exploration approach than when not
returning to previously explored zones. This two sce-
narios have large free spaces. When the robots travel
in these zones the measurement of the landmarks is
difficult as they are far away. This makes the dif-
ference between including the Go To Accurate Land-
marks behaviour or not. This large periods of time
with bad localization increases the global localization
error when not considering the dispersion to try to re-
localize the robot.
For Scenario 2 and Scenario 3 we do not observe
an improvement. Note that the global localization er-
ror depends on the form of trajectories and the ex-
ploration time that depend on the structure of the en-
vironments which is unknown. If the measurements
are good enough this other factors affects in a random
way and in average no difference is observed between
the methods.
The exploration time always increases because
this method does not always guide the robots to the
direction of the maximal information gain as it looks
also for the localization. As a conclusion, we think
that a method that only tries to minimize the explo-
ration time produces normally inaccurate maps use-
less for navigation. We consider that taking into ac-
count the requisites of SLAM while exploring the en-
vironment allows to obtain more precise maps.
6 CONCLUSIONS AND FUTURE
WORK
In this paper a method for multi-robot cooperative ex-
ploration has been presented. The method is based
on the computation of a set of behaviours designed
so that we simultaneously consider the necessity of
rapidly exploring the whole environment and the req-
uisite to build an accurate map. In this sense, the
ICINCO 2008 - International Conference on Informatics in Control, Automation and Robotics
312
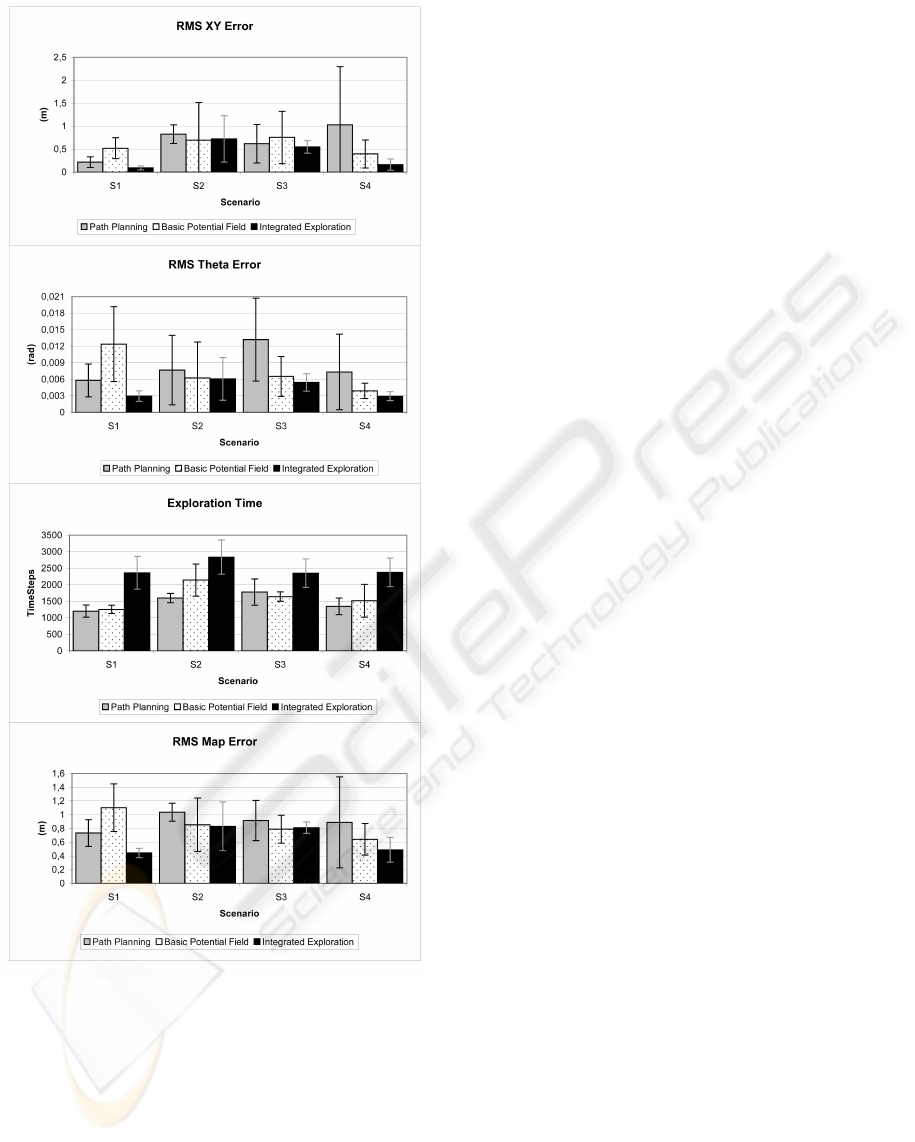
Figure 5: Results with uncertainty in localization: Path er-
ror on x,y and orientation (1st and 2nd graphs), exploration
time (3rd graph) and map error (4th graph).
method directs the robots to return to previously ex-
plored places when the uncertainty on the location
becomes significant, and this fact improves the qual-
ity of the resulting map. Several simulation results
demonstrate the validity of the approach. On scenar-
ios with large free space where there is a lack of good
measures of the landmarks the accuracy of the map
improves considerably.
As future works, we consider the extension of
the approach in dynamic environments, adding tech-
niques to learn automatically the multiple settings of
the system. New behaviors that avoid the dispersion
in the localization by trying to keep accurate land-
marks in the field of view will be added. Furthermore,
behaviors of attraction between robots will be incor-
porated in order to improve the localization since the
observation of one robot by other member in the team
may improve its localization. Semi-operated models
that integrate the commands expressed by a human
operator in the exploration task will also be studied,
where these commands would be taken as an advice.
ACKNOWLEDGEMENTS
This work has been supported by the Spanish Govern-
ment (Ministerio de Educaci´on y Ciencia). Project:
’Sistemas de percepci´on visual m´ovil y cooperativo
como soporte para la realizaci´on de tareas con redes
de robots’. Ref.: DPI2007-61197.
REFERENCES
Arkin, R. and Diaz, J. (2002). Line-of-sight constrained
exploration for reactive multiagent robotic teams. 7th
International Workshop on Advanced Motion Control,
AMC’02 , Maribor, Slovenia.
Bourgoult, F., Makarenko, A., Williams, S., Grocholsky,
B., and Durrant-Whyte, F. (2002). Information based
adaptive robotic exploration. In Proc. of the IEEE/RSJ
Int. Conf. on Intelligent Robots and Systems (IROS),
Lausanne, Switzerland.
Burgard, W., Moors, M., Stachniss, C., and Schneider, F.
(2005). Coordinated multi-robot exploration. IEEE
Transactions on Robotics, Vol. 21 No3 pp 376-386,
June.
Cao, Y., Fukunaga, A. S., Kahng, A. B., and Meng, F.
(1995). Cooperative mobile robotics: Antecedents
and directions. In IEEE/TSJ International Conference
on Intelligent Robots and Systems, Yokohama, Japan.
Feder, H., Leonard, J., and Smith, C. (1999). Adaptive mo-
bile robot navigation and mapping. Int. Journal of
Robotics Research, 18(7).
Gil, A., Reinoso, O., Pay´a, L., and Ballesta, M. (2007). In-
fluencia de los par´ametros de un filtro de part´ıculas en
la soluci´on al problema de slam. Accepted for publi-
cation in the IEEE Latin America.
Lau, H. (2003). Behavioural approach for multi-robot ex-
ploration. Australasian Conference on Robotics and
Automation (ACRA 2003), Brisbane, December.
Makarenko, A., Williams, S., Bourgoult, F., and Durrant-
Whyte, F. (2002). An experiment in integrated explo-
ration. In Proc. of the IEEE/RSJ Int. Conf. on Intelli-
POTENTIAL FIELD BASED INTEGRATED EXPLORATION FOR MULTI-ROBOT TEAMS
313

gent Robots and Systems (IROS), Lausanne, Switzer-
land.
Mozos, O. M., Gil, A., Ballesta, M., and Reinoso, O.
(2007). Interest point detectors for visual slam. Proc.
of the Conference of the Spanish Association for
Artificial Intelligence (CAEPIA), Salamanca, Spain,
November.
Sim, R., Dudek, G., and Roy, N. (2004). Online control
policy optimization for minimizing map uncertainty
during exploration. In Proc. of the IEEE Int. Conf. on
Robotics and Automation (ICRA), New Orleans, LA,
USA.
Simmons, R., Apfelbaum, D., Burgard, W., Fox, D., Moors,
M., Thrun, S., and Younes, H. (2000). Coordination
for multi-robot exploration and mapping. In Proceed-
ings of the AAAI National Conference on Artificial In-
telligence, Austin, TX.
Stachniss, C., Haehnel, D., Burgard, W., and Grisetti, G.
(2005). Actively closing loops in grid-based fastslam.
information. Advanced Robotics - The Int. Journal of
the Robotics Society of Japan (RSJ), Volume 19, num-
ber 10, pages 1059-1080.
Yamauchi, B. (1997). A frontier based approach for au-
tonomous exploration. IEEE International Sympo-
sium on Computational Intelligence in Robotics and
Automation, Monterey, CA, July 10-11.
Zlot, R., Stentz, A., Dias, M. B., and Thayer, S. (2002).
Multi-robot exploration controlled by a market econ-
omy. Proceedings of the IEEE International Confer-
ence on Robotics and Automation.
ICINCO 2008 - International Conference on Informatics in Control, Automation and Robotics
314
