
Combining Keypoint Clustering and Neural Background Subtraction for
Real-time Moving Object Detection by PTZ Cameras
Danilo Avola
1
, Marco Bernardi
2
, Luigi Cinque
2
, Gian Luca Foresti
1
and Cristiano Massaroni
2
1
Department of Mathematics, Computer Science, and Physics, Udine University, Via delle Scienze 208, 33100 Udine, Italy
2
Department of Computer Science, Sapienza University, Via Salaria 113, 00198 Rome, Italy
Keywords:
Foreground Detection, Keypoint Clustering, Neural Background Subtraction, Moving Objects, PTZ Cameras.
Abstract:
Detection of moving objects is a topic of great interest in computer vision. This task represents a prerequisite
for more complex duties, such as classification and re-identification. One of the main challenges regards the
management of dynamic factors, with particular reference to bootstrapping and illumination change issues.
The recent widespread of PTZ cameras has made these issues even more complex in terms of performance due
to their composite movements (i.e., pan, tilt, and zoom). This paper proposes a combined keypoint clustering
and neural background subtraction method for real-time moving object detection in video sequences acquired
by PTZ cameras. Initially, the method performs a spatio-temporal tracking of the sets of moving keypoints to
recognize the foreground areas and to establish the background. Subsequently, it adopts a neural background
subtraction to accomplish a foreground detection, in these areas, able to manage bootstrapping and gradual
illumination changes. Experimental results on two well-known public datasets and comparisons with different
key works of the current state-of-the-art demonstrate the remarkable results of the proposed method.
1 INTRODUCTION
Smart systems to automatically perform monitoring
tasks (e.g., person re-identification) is playing a more
and more important role. A main duty of these tasks
is the moving object detection, since it allows the seg-
mentation of the foreground moving elements, thus
facilitating the reconstruction of the background of a
video sequence. Anyway, the moving object detection
presents a wide range of challenges, which are well
reported in (Shaikh et al., 2014). These challenges
mainly regard the management of the following dy-
namic factors of the scene:
• bootstrapping: construction of the background
model is a complex task, especially when the ini-
tial frames of a video contain moving objects;
• illumination changes: gradual illumination
changes can affect the moving object detection,
especially in outdoor environments where the
natural light changes over time;
• camouflage: foreground moving elements must be
segmented from the scene, even if they have chro-
matic features similar to those of the background;
• shadows: shadows of the moving objects must be
considered in the construction of the background.
In the last decades, several solutions have been
proposed to face these issues (Bouwmans, 2014; So-
bral and Vacavant, 2014) and, recently, great atten-
tion has been given to moving object detection al-
gorithms based on artificial neural networks (ANNs)
(Maddalena and Petrosino, 2008; Maddalena and Pet-
rosino, 2014). ANNs present different advantages. In
particular, their ability in adapting and learning new
situations has played a key role in using these algo-
rithms instead of the traditional approaches in video
surveillance. In addition, these algorithms are prov-
ing to be very suitable for the management of those
dynamic aspects that are the focus of the present pa-
per, i.e., bootstrapping and illumination changes.
1.1 Foreground Detection by using PTZ
Cameras
Foreground detection by using PTZ cameras has a
rich literature. Initially, the frame-to-frame methods
were the first presented approaches. They consist in
identifying the overlapping regions between two con-
secutive frames and in analysing the pixel informa-
tion inside them. In (Kang et al., 2003), an adap-
tive background model is generated by consecutive
frames, and subsequently aligned by using of a geo-
638
Avola, D., Bernardi, M., Cinque, L., Foresti, G. and Massaroni, C.
Combining Keypoint Clustering and Neural Background Subtraction for Real-time Moving Object Detection by PTZ Cameras.
DOI: 10.5220/0006722506380645
In Proceedings of the 7th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2018), pages 638-645
ISBN: 978-989-758-276-9
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

metric transform. The work proposed in (Zhou et al.,
2013), instead, utilized a motion segmentation algo-
rithm, based on the methods reported in (Brox and
Malik, 2010; Ochs and T.Brox, 2011), to analyse the
point trajectories, to segment them into clusters, and
to turn these clusters into dense regions. Another
solution is shown in (Avola et al., 2017b), where a
spatio-temporal tracking of sets of keypoints is used
to distinguish the background from the foreground.
Subsequently, different attempts in improving the
existing methods led the developers in exploring the
frame-to-global approaches. An interesting work is
presented in (Xue et al., 2011), where the authors pro-
posed a panoramic Gaussian mixture model to cover
the camera field of view and to register each new
frame using a multi-layered correspondence ensem-
ble. Probabilistic methods were also used, as reported
by (Kwak et al., 2011; Elqursh and Elgammal, 2012),
which proposed solutions based on Bayesian filters.
Different approaches are those based on machine
learning techniques. In the work presented by (Fer-
one and Maddalena, 2014), moving object detection is
performed by an original extension of a neural-based
background subtraction approach. Lastly, in (Rafique
et al., 2014), an algorithm based on Restricted Boltz-
man Machine (RBM) to learn and to generate the
background model is reported.
1.2 Main Contribution
Unlike the existing works, this paper presents an algo-
rithm for real-time moving object detection (in video
sequences acquired by PTZ cameras) based on the
combination of keypoint clustering and neural back-
ground subtraction. The spatio-temporal tracking of
the keypoints is used to estimate the camera move-
ments and the scale variations (Avola et al., 2017b).
In particular, this step is utilized to identify the can-
didate areas of foreground and to manage the boot-
strapping problem. Subsequently, on these areas, an
ANN implemented by using self-organizing feature
maps (SOFMs) (Kohonen, 1982) is used to perform a
neural background subtraction and to handle the grad-
ual illumination changes. The main contribution of
the paper can be summarized as follows:
1. a robust bootstrapping management, in real-time,
by using an original keypoint clustering strategy;
2. a variation of the neural background subtraction
method proposed in (Maddalena and Petrosino,
2014) through which also the video sequences ac-
quired by PTZ cameras (and not only by static
cameras) can be managed;
3. an adaptive use of the neural background sub-
traction method proposed in (Maddalena and
Petrosino, 2014; Ferone and Maddalena, 2014)
through which only candidate areas of the image
(and not the whole image) can be analysed, thus
reducing both computational time and noise.
The rest of the paper is structured as follows. Sec-
tion 2 describes the proposed method. Section 3
presents two experimental sessions. In the first, the
Hopkins 155 dataset (Tron and Vidal., 2007) is used
to compare the accuracy of the proposed method with
key works of the current state-of-the-art. In the sec-
ond, the Airport MotionSeg dataset (Dragon et al.,
2013) is used to evaluate the performance of the pro-
posed method during zoom operations. Finally, Sec-
tion 4 concludes the paper.
2 LOGICAL ARCHITECTURE
As shown in Figure 1, the system architecture is di-
vided in different modules. The first module is the
Background Module Initialization, where a model of
the background composed by both a neural map and
a set of keypoints, and linked descriptors, is created.
The keypoints and descriptors are contained in two
sets called K
b
t
and D
b
t
, respectively, and where t is a
time instant. The self-organizing neural network cre-
ated in this step is organized as a 3D matrix, denoted
with β
t
. In the first iteration, the sets K
b
0
and D
b
0
are
extracted from f
0
, i.e., the first frame acquired by the
PTZ camera. The frames after f
0
are provided as in-
put to the Feature Matching module, which finds the
correspondences between K
b
t−1
and K
t
, where K
t
is
the set of keypoints extracted from the frame f
t
. The
correspondences are stored in a collection containing
all the matches, called Φ
t
. By using Φ
t
, the changes in
the scene, due to the PTZ camera movements, are es-
timated in the Camera Movements & Scale Changes
module. This module also analyses the displacement
of the keypoints inside the scene and identifies the set
of candidate keypoints that belongs to the foreground,
called K
F
t
. In Keypoint Clustering & Foreground Area
Detection module, the keypoints in K
F
t
are grouped in
clusters that indicate the areas of the foreground ele-
ments. These areas of pixel, called A
t
, are used to
perform the foreground segmentation in the Neural
Background Subtraction module. Moving objects are
represented by a set of blobs, called Mask
F
t
. At each
iteration, all components of the background model are
updated by the Background Model Updating module.
The updating of the weight vectors in β
t
is performed
according to the position of the pixels. If a pixel be-
longs to the foreground, its weight vector is not up-
dated. This last phase allows to obtain a robust model.
Combining Keypoint Clustering and Neural Background Subtraction for Real-time Moving Object Detection by PTZ Cameras
639
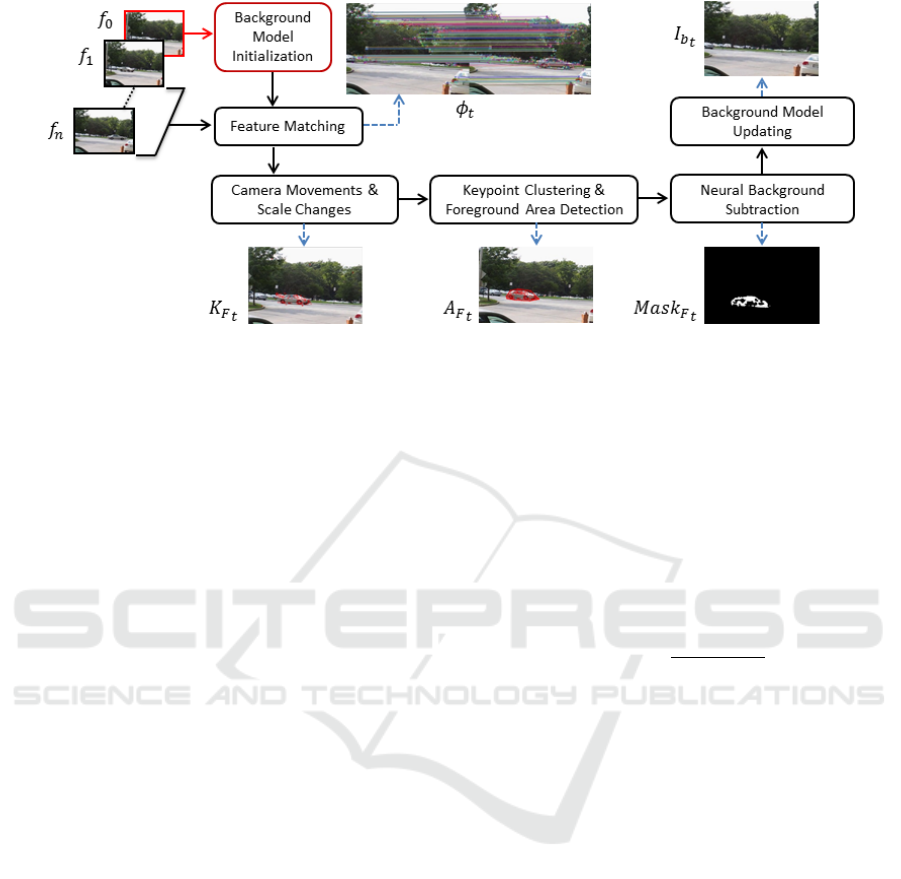
Figure 1: Logical architecture of the proposed system.
2.1 Background Model Initialization
Given a time instant t, the background model at the
previous iteration is composed by an RGB image,
called I
b
t−1
, the set of keypoints K
b
t−1
, the set of de-
scriptors D
b
t−1
, and a self-organising neural network,
called β
t−1
. The I
b
t−1
image represents an approxima-
tion, at time instant t − 1, of the scene containing only
the background elements (when t = 0, I
b
0
is equal to
f
0
). Notice that, f
0
can also contain foreground ele-
ments, in fact the use of the keypoint clustering (as
shown in Section 2.4) can manage the bootstrapping
problem even if the initial scene is populated by mov-
ing elements. In the proposed solution, β
t
is repre-
sented by a 3D matrix with N rows, P columns, and n
layers, whose number, i.e., n = 6, was chosen accord-
ing to empiric tests. Each layer L
i
, with 1 6 i 6 n,
contains, for each pixel x ∈ I
b
t
, L × N weight vec-
tors, called m
L
i
(x). The whole set of layers, L
i
, com-
poses the map β
t
. At time instant t = 0, the weights
of the vectors m
i
(x) in β
0
are initialized by using the
pixel brightness values of f
0
. Also the sets K
b
and
D
b
are extracted from f
0
by using the feature extrac-
tor A-KAZE (Alcantarilla et al., 2013), which is able
to compute and to describe the visual features with
faster performance with respect to other popular fea-
ture extractors, such as: SURF (Bay et al., 2008) or
ORB (Rublee et al., 2011).
2.2 Feature Matching
In this phase, inspired by the work proposed in (Avola
et al., 2017a), the features of the background model
are compared with those extracted from the current
frame. A set of keypoints, K
t
, with their descrip-
tors, D
t
, are extracted from f
t
. In this step, the fea-
tures of the background model are separated to those
that do not belong to it. The K-Nearest Neighbours
(KNN) approach (Bishop, 2011) was chosen to per-
form the match between the descriptors in K
b
t−1
and
those in K
t
. Considering that A-KAZE extracts de-
scriptors composed of binary values, the Hamming
distance was used. Like the work proposed in (Avola
et al., 2017b), for each k ∈ K
b
t−1
, the two best matches
between k and K
t
were found by using a KNN with
K = 2. Subsequently, the ratio between these two
matches is computed as follows:
ratio =
hDist(k, k
0
1
)
hDist(k, k
0
2
)
(1)
where, k
0
, k
00
∈ K
t
are the keypoints that have a match
with k. The Hamming distances from k are expressed
by hDist(k, k
0
1
) and hDist(k, k
0
2
), respectively. The
ratio in [0, 1] expresses the proximity of Hamming
distances between two different matches. If the ra-
tio value is high, the two distances are close. When
the ratio is over a threshold r (where r defines the
maximum closeness between the two distances), all
matches of k are discarded. A low value of r implies a
low presence of undesired matches. Based of several
empirical tests, we fixed the value of r to 0.60. All
valid best matches are inserted into the Φ
t
set, while
all the keypoints, in K
t
, without a valid match with
K
b
t−1
are inserted in a set called K
di f f
.
Unlike the work presented in (Avola et al., 2017b),
the proposed method performs a comparison between
the sets K
di f f
and K
F
t−1
, in addition to the only com-
parison between K
b
t−1
and K
t
. Notice that, this task
can be performed only when a foreground element is
identified in the frame f
t−1
. The set of these matches
are called Φ
d
. All keypoints in K
di f f
with a match
in Φ
d
t
are inserted in the K
F
t
set, the latter represents
the collection of the candidate foreground keypoints
inside the frame f
t
. This last step has been added to
ICPRAM 2018 - 7th International Conference on Pattern Recognition Applications and Methods
640

also identify the foreground elements that do not per-
form movements in a current frame.
2.3 Camera Movement and Scale
Change Estimation
The foreground keypoints, the camera movements,
and the scale changes are estimated by using the
matches inside Φ
t
. The first step is to distinguish the
background keypoints from the moving object key-
points, by using a 3x3 homography matrix, called H.
This matrix describes the relation between two con-
secutive frames and maps the coordinates of a point
x
1
in f
t−1
into the coordinates of a point x
2
in f
t
:
x
2
= Hx
1
(2)
In our case, H is used to map the coordinates of
the keypoints inside I
b
t−1
in the coordinates of the
keypoints inside f
t
. This task is performed by the
RANdom SAmple Consensus (RANSAC) algorithm
(Fischler and Bolles, 1981) by using the matches con-
tained in Φ
t
. The initial estimated homography, H, is
refined by using the Levenberg-Marquardt optimiza-
tion (Marquardt and Donald, 1963) that minimizes the
re-projection error. For each match (k, k
0
) ∈ Φ
t
, the
following condition must be verified:
z =
1 if
p
(k − k
0
)
2
−
p
(k − k
h
)
2
≥ τ
1
0 otherwise.
(3)
where, k
h
= Hk is the estimated position of k in f
t
,
and τ
1
is a tolerance on the difference between the
estimated distance by homography and the estimated
distance by Φ
t
. If z = 0, the keypoint k
0
is a back-
ground keypoint and it is inserted in K
b
t
. When τ
1
has
a low value, a large number of keypoints results static
and fitted in the background, on the other hand, in this
case a large number of false positives inside K
F
t
can
occur. Instead, if τ
1
has a high value, the estimation of
the keypoint movements is less restrictive, but a large
number of false negatives can occur. Based on empir-
ical tests, the value of τ
1
has been fixed to 2.0. On
the contrary, when k
0
is a foreground keypoint, it is
inserted in K
F
t
. When all the candidate keypoints in
K
b
t
are found, their matches in Φ
t
are used to compute
the affine transformation matrix between I
b
t−1
and f
t
,
thus computing the information required to estimate
the movements performed by the PTZ camera. Given
three pairs of matches (k
a
, k
b
), (k
c
, k
d
), and (k
e
, k
f
)
∈ Φ
t
with k
b
, k
d
, and k
f
∈ K
t
, the affine transforma-
tion matrix, A, can be calculated as follows:
A =
λ
x
0 t
x
0 λ
y
t
y
0 0 1
=
x
k
b
x
k
d
x
k
f
y
k
b
y
k
d
y
k
f
x
k
a
x
k
c
x
k
e
y
k
a
y
k
c
y
k
e
1 1 1
−1
(4)
where, t
x
and t
y
are the translations on the x and y
axes, respectively. While, λ
x
and λ
y
are the variation
scale on the same axes. Notice that, when a zoom is
performed, we obtain that λ
x
= λ
y
.
Subsequently, the weights in β
t−1
must be aligned
according to the new spatial position of its correlated
pixel. By using t
x
,t
y
and λ, the common portion of
the scene between f
t−1
and f
t
is estimated. This area
is expressed by a bounding box R
t−1
in f
t−1
and a
bounding box R
t
in f
t
. If t
x
6= 0 or t
y
6= 0, the weights
of the pixels in R
t−1
must be moved to the new region
R
t
, for each layer L
i
∈ β
t−1
. This alignment generates
a new self-organising map, called β
0
t
. If λ 6= 1, a zoom
operation occurs and an interpolation to update the
layers of β
t−1
is applied. For each layer L
i
∈ β
t−1
, the
weights of the pixels inside R
t−1
are interpolated in
R
t
of L
0
i
∈ β
0
t
. The pan, tilt, and zoom-out operations
generate new pixels in f
t
, which require an initializa-
tion of their weight vectors in β
0
t
. For each p 6∈ R
t
is
required an initialization, then ∀L
0
i
∈ β
0
t
, L
0
i
(p) = f
t
(p)
is obtained. When t
x
= t
y
= 0 and λ = 1, the alignment
of the weights in β
t−1
is not necessary.
2.4 Keypoint Clustering and
Foreground Detection
The areas that include the foreground elements in f
t
are obtained by using a clustering algorithm applied
on the keypoints contained in K
F
t
. The Density-Based
Spatial Clustering of Applications with Noise (DB-
SCAN) algorithm (Ester et al., 1996) is chosen for
the reason that it does not require to specify a-priory
the number of clusters, moreover it is suitable to man-
age the presence of noise. The DBSCAN algorithm
requires two parameters. The first, called τ
2
, is the ra-
dius used to search the neighbouring keypoints. The
second, called MinPts, is the minimum number of
neighbouring keypoints that are required to form a
single cluster. With a low value of τ
2
, small clusters
are obtained, but a certain amount of information can
be lost. On the contrary, with a high value of τ
2
, large
clusters are created, but a high level of noise can be
included. The result of this step consists of a set of
clusters, C
t
= (c
1
, c
2
, ..., c
m
). Each c
i
∈ C
t
is a portion
of f
t
and is associated to a set of pixels, called α
c
. The
entire collection of these areas α
c
, called A
t
, indicates
all the regions that contain foreground elements in f
t
.
2.5 Neural Background Subtraction
In this stage, the pixels inside the areas in A
t
are anal-
yses to find foreground elements. The background
subtraction process works as follows:
Combining Keypoint Clustering and Neural Background Subtraction for Real-time Moving Object Detection by PTZ Cameras
641

• For each pixel g 6∈ α, and ∀α ∈ A
t
, the value of
Mask
F
t
(g) (i.e., the value of the pixel g inside the
mask) is set to 0.
• For each pixel p ∈ α, and ∀α ∈ A
t
:
Mask
F
t
(p) =
(
1 if
|Ω
p
|
|H
p
|
≤ 0.5;
0 otherwise.
(5)
where, H
p
= p
0
: |p − p
0
| ≤ h, is a 2D spatial neigh-
bourhood of p (including p) with a radius of length h
(in the proposed method h = 2). Instead, Ω
p
is the set
of pixels in H
p
that satisfies the following condition:
Ω
p
= {p
0
∈ H
p
: d(β
0
t
(p
0
), f
t
(p
0
)) ≤ ε} (6)
where, d(β
0
t
(p
0
), f
t
(p
0
)) is the best match distance be-
tween the value of pixel p
0
in f
t
and the weights of
pixel p
0
inside β
0
t
. More details on this distance are
reported in Section 2.5.1. The threshold ε indicates
the maximum distance that a pixel p
0
can have with
its best match. If the best match distance is greater
than ε, then p
0
is defined as a foreground pixel. No-
tice that, high values of the threshold allow to suc-
cessfully process background pixels with significant
changes (in terms of speed). Anyway, these values
can made the method short-sighted in capturing slow
changes of the foreground scene. The Eq. 5 indicates
a measure of how many pixels in the neighbourhood
of p have correspondence with the model. The pixel p
can be considered a background pixel only if its value
is less than 0.5 (i.e, less than half of the pixels in its
neighbourhood does not belong to the foreground). In
general, the value of 0.5 can be considered a balanced
estimation for background and foreground elements.
2.5.1 Find Best Match
The best match of a pixel p with its model in β
0
t
is
computed as follows:
d(β
0
t
(p), f
t
(p)) = min
i=1,...,n
d(m
L
0
i
(p), f
t
(p)) (7)
where, d(•, •) is a metric based on the used color
space to construct the self-organising map. In the
proposed method, the Euclidean distance between the
value of pixel and its weight vector of the layer L
i
us-
ing the HSV colour model, is used. The metric can be
expressed as follows:
d(L
0
i
(p), f
t
(p)) = ||(v
1
s
1
cos(h
1
), v
1
s
1
sin(h
1
), v
1
)
−(v
2
s
2
cos(h
2
), v
2
s
2
sin(h
2
), v
2
)||
2
2
(8)
where, v
1
, s
1
and h
1
are the value, the saturation, and
the hue of the pixel p, respectively. Instead, v
2
, s
2
and
h
2
are the same values of the weights in m
L
0
i
(p).
2.5.2 Cast Shadow
With the aim to manage complex scenarios, the pro-
posed method inherits, from the current literature, a
remarkable approach to make better the background
subtraction stage, thus improving the whole algo-
rithm. Moving objects can generate shadows, which
require to be managed and included in the background
model. Based on the work reported in (Cucchiara
et al., 2003), the proposed method performs a detec-
tion of the cast shadow pixels, which are considered
as background and updated by the Eq. 9.
2.6 Background Model Updating
The reinforcement of the self-organising map is a nec-
essary step to recognize moving objects and to distin-
guish them from the changes of the background. Dur-
ing this task, the updating of a pixel weight influences
all the weights belonging to the same layer. So a new
updated self-organising map, called β
t
, for the frame
f
t
is obtained. Moreover, a new set of internal lay-
ers of β
t
, called L
∗
i
, for 1 ≤ i ≤ n, is computed. The
update relation is defined as follows:
m
L
∗
i
(p) = (1 − ϕ(p, p
0
))m
L
0
i
(p) + ϕ(p, p
0
) f
t
(p) ∀p
0
∈ N
p
(9)
where, p ∈ α (α ∈ A
t
) and N
p
= {p
0
∈ f
t
: |p − p
0
| <
w
2D
} is a 2D squared spatial neighbourhood of p that
includes p. The radius of N
p
is expressed by w
2D
(here fixed as: w
2D
= 1). Actually, ϕ(p, p
0
) is defined
as follows:
ϕ(p, p
0
) = γg(p − p
0
)(1 − Mask
F
t
) (10)
where, g(p − p
0
) is a 2D Gaussian low-pass filter
(Burt, 1981) and γ is the learning rate. A large
value of γ produces a fast learning step of the self-
organising map with respect to the changes of the
scene. In this work, after different empirical tests, γ
was set to 0.05. On the contrary, a small value of the
parameter reduces the false negatives since the map
learns less rapidly. For each pixel outside the areas in
the A
t
set, only the weight of every layer L
∗
i
in β
t
is
processed as follows:
m
L
∗
i
(p) =
(
f
t
(p) if i = n;
m
L
0
i+1
(p) otherwise.
(11)
In this way, the most recent frame information, in
the n
th
layer, is stored, while the older information
contained in the 0
th
layer is removed. The updating
of the weights of these pixels is fundamental to man-
age the bootstrapping problem. Even if, in the back-
ground initialization phase, foreground elements are
included, their location is identified by the clusters.
ICPRAM 2018 - 7th International Conference on Pattern Recognition Applications and Methods
642

(a) (b) (c) (d) (e) (f)
Figure 2: Examples of moving object detection and background updating. The video sequences from the column (a) up to the
column (e) belong to the Hopkins 155 dataset. The last sequence belongs to the Airport MotionSeg dataset. For each column
(from the top to the bottom), the first picture is the generic frame, the second is the keypoint clustering stage, the third is the
moving object mask, and the last is the background updating. From the first up to the last column the following video are
shown: tennis, people2, cars6, camel01, people1, and bus.
This means that each pixel outside the clusters be-
longs to the background. The proposed method can
estimate, since from the first frames, the moving ob-
jects without an initial estimation of the background.
The latter can be considered a concrete overcoming
of the current state-of-the-art.
3 EXPERIMENTAL RESULTS
This section reports the experimental results per-
formed on the Hopkins 155 dataset (Tron and Vidal.,
2007) and on the Airport MotionSeg dataset (Dragon
et al., 2013). The first was used to perform a compar-
ison, in terms of Precision (Prec), Recall (Rec), and
F1 − Measure (F1), with selected key works of the
current literature. The second was used to prove the
effectiveness of the proposed method during zoom-
in/zoom-out operations. Notice that, the latter task is
rather unusual since the majority of works in this ap-
plication field do not consider moving object detec-
tion along with zoom operations. Observe also that,
in the proposed experiments, the values of ε and γ was
set to 0.005 and 0.05, respectively, thanks to the pre-
liminary empirical tests performed on both datasets.
Conversely, the parameters τ
2
and MinPts, that de-
pend of several factors, including the image resolu-
tion and the keypoint distribution, and whose values
are reported in Table 1, were established on the basis
of the observations derived by the OPTICS algorithm
(Ankerst et al., 1999).
Table 1: Values of the τ
2
and MinPts parameters on the
basis of the OPTICS algorithm. The first five videos (from
the top) belong to the Hopkins 155 dataset, the last belongs
to the Airport MotionSeg dataset.
Video Resolution τ
2
MinPts
Camel01 680x540 60 6
Cars6 640x480 70 5
People1 640x480 60 5
People2 640x480 60 5
Tennis 530x380 60 5
Bus 1440x1080 80 3
3.1 Experimental Evaluation
In Figure 2, visual representations of the results ob-
tained by the proposed method during the different
stages of the architecture are reported. The first row
shows an example of source frame for each of the five
challenging video sequences, the second row presents
the related foreground keypoint clustering. The com-
puted clusters allow the method to reduce the noise in
the background subtraction stage, as depicted in the
third row. The clusters also limit the computational
Combining Keypoint Clustering and Neural Background Subtraction for Real-time Moving Object Detection by PTZ Cameras
643

Table 2: Comparison with key works of the current literature on the basis of the average of the Precision, Recall, and F1-
Measure metrics. The people1, people2, cars6, camel01, and tennis video sequences belong to the Hopkins 155 dataset. The
last video sequence, bus, belongs to the Airport MotionSeg dataset.
people1 people2 cars6 camel01 tennis bus
Prec Rec F1 Prec Rec F1 Prec Rec F1 Prec Rec F1 Prec Rec F1 Prec Rec F1
Proposed method 0.809 0.954 0.876 0.836 0.984 0.903 0.800 0.956 0.871 0.790 0.962 0.868 0.801 0.991 0.895 0.882 0.943 0.911
(Avola et al., 2017b) 0.765 0.917 0.840 N.A. N.A. N.A. 0.785 0.910 0.840 N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A
(Kwak et al., 2011) - with NBP 0.950 0.930 0.940 0.850 0.760 0.828 N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A
(Kwak et al., 2011) - without NBP 0.910 0.760 0.828 0.910 0.220 0.286 N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A
(Elqursh and Elgammal, 2012) - 1 0.940 0.850 0.893 0.840 0.990 0.909 N.A. N.A. N.A. N.A. N.A. N.A. 0.860 0.920 0.890 N.A. N.A. N.A
(Elqursh and Elgammal, 2012) - 2 0.970 0.880 0.923 0.850 0.970 0.906 N.A. N.A. N.A. N.A. N.A. N.A. 0.900 0.810 0.850 N.A. N.A. N.A
(Ferone and Maddalena, 2014) 0.958 0.923 0.940 0.931 0.971 0.950 0.866 0.964 0.913 N.A. N.A. N.A. N.A. N.A. N.A N.A. N.A. N.A.
(Brox and Malik, 2010) 0.890 0.775 0.829 N.A. N.A N.A 0.824 0.994 0.901 N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A
(Zhou et al., 2013) 0.936 0.933 0.934 0.925 0.965 0.945 0.837 0.984 0.905 N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A. N.A
(Sheikh et al., 2009) 0.780 0.630 0.697 0.730 0.830 0.777 N.A. N.A. N.A. N.A. N.A. N.A. 0.270 0.830 0.400 N.A. N.A. N.A
time required by the moving object detection stage
considering that only some portions of the frame f
t
are processed (and not the whole frame). The area
analysed by the method is slightly greater than the
area delimited by the clusters, this to be sure not to
miss parts of the foreground elements. Typically, the
method considers an area of the 20% bigger. We cho-
sen this value by empirical evaluations, which shown,
in the worst case, an amount of pixels outside the clus-
ters of about the 18%. Finally, the last row reports the
reconstruction of the background, I
b
t
, for each video.
The computational time required by the construction
of the clusters does not influence the performance of
the method since the number of keypoints that has to
be analysed is significantly lower than the number of
pixels that has to be processed without using the clus-
tering based approach.
The correctness of the moving object detection
algorithm was estimated by using three well-known
metrics: Precision (Prec), Recall (Rec), and F1 −
Measure (F1). The metrics were computed on
the bases of the pixels correctly assigned to the
background and foreground in relation to the given
ground-truth, more specifically:
Rec =
T P
T P + FN
(12)
Prec =
T P
T P + FP
(13)
F1 =
2(Rec)(Prec)
Rec + Prec
(14)
where, T P, FP, FN, and T N are the number of true
positive, false positive, false negative, and true neg-
ative, respectively, in terms of number of pixels in-
side and outside of the related portion of the image
(i.e., background or foreground). In Table 2 the re-
sults of the proposed solution are shown. We have
chosen to perform the experiments on those video se-
quences since they, almost all, are directly compara-
ble with selected key works of the current state-of-
the-art. The results show that, as regards the recall
values, the proposed method achieves good perfor-
mance, especially in the people1 and tennis video se-
quences, where it reaches the best results. In people2
and car6 video sequences, even if the method does not
obtain the higher values, the recall measure is very
close to the best works in the literature. Moreover,
in the tennis video sequence the obtained results, as
regards the recall and F1 metrics, exceed the exter-
minated key works. Notice that, high recall values
obtained by the proposed method highlight that it is
able to capture almost all the pixels that compose the
foreground objects. This last factor is very important
for the application of additional processing, such as
object classification and people re-identification.
No results were found in other works for the
camel01 video, anyway we have tested it because, in
our opinion, it is a very interesting sequence. In addi-
tion, we have observed that several works do not treat
zoom-in and zoom-out operations, make the com-
parison a very hard task. We have adopted a very
challenging video sequence of the Airport MotionSeg
dataset, i.e., bus, to test the proposed method during
these operations. The obtained results have been ex-
tremely satisfying with all the computed metrics. The
bus video sequence does not provide the ground-truth
of the foreground. To solve this gap, the likely fore-
ground pixels were computed by a semi-automatic
segmentation process. Summarizing, the method has
shown to work properly with different challenging
video sequences. The obtained results have pointed
out that the proposed strategy is highly practical and
consistent. Finally, the use of the keypoints allows the
method to be used in real-time application fields.
4 CONCLUSIONS
This paper presents a combined keypoint clustering
and neural background subtraction method for real-
time moving object detection in video sequences ac-
quired by PTZ cameras. The experimental results per-
formed on two well-known public datasets demon-
strate the effectiveness of the proposed approach com-
pared with selected key works of the current state-of-
ICPRAM 2018 - 7th International Conference on Pattern Recognition Applications and Methods
644

the-art. The reported solution shows different con-
tributions with respect to the current literature, in-
cluding the management of the bootstrapping and il-
lumination change issues, the real-time processing,
an original keypoint clustering strategy, and a novel
pipeline based on the neural background subtraction.
REFERENCES
Alcantarilla, P., Nuevo, J., and Bartoli, A. (2013). Fast
explicit diffusion for accelerated features in nonlin-
ear scale spaces. pages 1–12. British Machine Vision
Conference (BMVC).
Ankerst, M., Breunig, M. M., Kriegel, H.-P., and Sander, J.
(1999). Optics: Ordering points to identify the clus-
tering structure. SIGMOD Record, 28(2):49–60.
Avola, D., Bernardi, M., Cinque, L., Foresti, G. L., and
Massaroni, C. (2017a). Adaptive bootstrapping man-
agement by keypoint clustering for background ini-
tialization. Pattern Recognition Letters, 100:110–116.
Avola, D., Cinque, L., Foresti, G. L., Massaroni, C., and
Pannone, D. (2017b). A keypoint-based method for
background modeling and foreground detection using
a ptz camera. Pattern Recognition Letters, 96:96–105.
Bay, H., Ess, A., Tuytelaars, T., and Gool, L. V. (2008).
Speeded-up robust features (surf). Computer Vision
and Image Understanding, 110(3):346–359.
Bishop, C. M. (2011). Pattern Recognition and Ma-
chine Learning. Information Science and Statistics.
Springer.
Bouwmans, T. (2014). Traditional and recent approaches
in background modeling for foreground detection: An
overview. Computer Science Review, 11-12:31–66.
Brox, T. and Malik, J. (2010). Object segmentation by long
term analysis of point trajectories. pages 282–295.
European Conference on Computer Vision (ECCV).
Burt, P. J. (1981). Fast filter transform for image processing.
Computer Graphics and Image Processing, 16(1):20–
51.
Cucchiara, R., Grana, C., Piccardi, M., and Prati, A. (2003).
Detecting moving objects, ghosts and shadows in
video streams. IEEE Transactions on Pattern Anal-
ysis and Machine Intelligence, 25(10):1337–1342.
Dragon, R., Ostermann, J., and Gool, L. V. (2013). Robust
realtime motion-split-and-merge for motion segmen-
tation. pages 59–69. German Conference on Pattern
Recognition (GCPR).
Elqursh, A. and Elgammal, A. (2012). Online moving cam-
era background subtraction. pages 228–241. European
Conference on Computer Vision (ECCV).
Ester, M., Kriegel, H.-P., Sander, J., Xu, X., Simoudis,
E., Han, J., and Fayyad, U. (1996). A density-
based algorithm for discovering clusters in large spa-
tial databases with noise. pages 226–231. Proceedings
of the Second International Conference on Knowledge
Discovery and Data Mining (KDD).
Ferone, A. and Maddalena, L. (2014). Neural background
subtraction for pan-tilt-zoom cameras. IEEE Trans-
actions on Systems, Man, and Cybernetics: Systems,
44(5):571–579.
Fischler, M. A. and Bolles, R. C. (1981). Random sample
consensus: A paradigm for model fitting with appli-
cations to image analysis and automated cartography.
Communications of the ACM, 24(6):381–395.
Kang, S., Paik, J.-K., Koschan, A., Abidi, B. R., and Abidi,
M. A. (2003). Real-time video tracking using ptz cam-
eras. volume 5132, pages 103–111. International Con-
ference on Quality Control by Artificial Vision.
Kohonen, T. (1982). Self-organized formation of topolog-
ically correct feature maps. Biological Cybernetics,
43(1):59–69.
Kwak, S., Lim, T., Nam, W., Han, B., and Han, J. H. (2011).
Generalized background subtraction based on hybrid
inference by belief propagation and bayesian filtering.
pages 2174–2181. IEEE International Conference on
Computer Vision (ICCV).
Maddalena, L. and Petrosino, A. (2008). A self-organizing
approach to background subtraction for visual surveil-
lance applications. IEEE Transactions on Image Pro-
cessing, 17(7):1168–1177.
Maddalena, L. and Petrosino, A. (2014). The 3dsobs+ algo-
rithm for moving object detection. Computer Vision
and Image Understanding, 122:65–73.
Marquardt and Donald (1963). An algorithm for least-
squares estimation of nonlinear parameters. SIAM
Journal on Applied Mathematics, 11(2):431–441.
Ochs, P. and T.Brox (2011). Object segmentation in video:
a hierarchical variational approach for turning point
trajectories into dense regions. pages 1583–1590.
IEEE International Conference on Computer Vision
(ICCV).
Rafique, A., Sheri, A. M., and Jeon, M. (2014). Back-
ground scene modeling for ptz cameras using rbm.
pages 165–169. International Conference on Control,
Automation and Information Sciences (ICCAIS).
Rublee, E., Rabaud, V., Konolige, K., and Bradski, G.
(2011). Orb: An efficient alternative to sift or surf.
pages 2564–2571. IEEE International Conference on
Computer Vision (ICCV).
Shaikh, S. H., Saeed, K., and Chaki, N. (2014). Mov-
ing Object Detection Using Background Subtraction.
SpringerBriefs in Computer Science. Springer Inter-
national Publishing.
Sheikh, Y., Javed, O., and Kanade, T. (2009). Background
subtraction for freely moving cameras. pages 1219–
1225. IEEE International Conference on Computer
Vision (ICCV).
Sobral, A. and Vacavant, A. (2014). A comprehensive re-
view of background subtraction algorithms evaluated
with synthetic and real videos. Computer Vision and
Image Understanding, 122:4–21.
Tron, R. and Vidal., R. (2007). A benchmark for the com-
parison of 3-d motion segmentation algorithms. pages
1–8. IEEE International Conference on Computer Vi-
sion and Pattern Recognition (CVPR).
Xue, K., Ogunmakin, G., Liu, Y., Vela, P. A., and Wang,
Y. (2011). Ptz camera-based adaptive panoramic and
multi-layered background model. pages 2949–2952.
IEEE International Conference on Image Processing
(ICIP).
Zhou, X., Yang, C., and Yu, W. (2013). Moving object
detection by detecting contiguous outliers in the low-
rank representation. IEEE Transactions on Pattern
Analysis and Machine Intelligence, 35(3):597–610.
Combining Keypoint Clustering and Neural Background Subtraction for Real-time Moving Object Detection by PTZ Cameras
645
