
Towards a Query Translation Disambiguation Approach using Possibility
Theory
Oussama Ben Khiroun
1,2
, Bilel Elayeb
1,3
and Narj
`
es Bellamine Ben Saoud
1
1
RIADI Research Laboratory, ENSI, Manouba University, 2010, Manouba, Tunisia
2
National Engineering School of Sousse, ENISO, Sousse University, 4023, Sousse, Tunisia
3
Emirates College of Technology, P.O. Box: 41009, Abu Dhabi, United Arab Emirates
Keywords:
Cross-Language Information Retrieval, Possibility Theory, Parallel Corpus, Co-occurrence Graph, Query
Translation Disambiguation, Query Expansion.
Abstract:
We propose in this paper a combined method for Cross-Language Information Retrieval (CLIR) using statisti-
cal and lexical resources. On the one hand, we extracted a bilingual French to English dictionary from aligned
texts of the Europarl collection. On the other hand, we built a co-occurrence graph structure and used the
BabelNet lexical network to process the disambiguation of translation candidates for ambiguous words. We
compared our new possibilistic approach with circuit-based one and studied the impact of query expansion by
adopting the pseudo-relevance feedback (PRF) technique. Our experiments are performed using the standard
CLEF-2003 collection. The results show the positive impact of PRF on the query translation process. Besides,
the possibilistic approach using the co-occurrence graph outperforms the overall circuit-based runs.
1 INTRODUCTION
Cross-Language Information Retrieval (CLIR) deals
with retrieving and ranking a set of documents writ-
ten in a language different from the language of the
user’s query. It is an active sub-domain of the Infor-
mation Retrieval (IR) which is centered on the search
for documents starting from a need for information by
the IR system user. Indeed, CLIR tries to overcome
the language barrier between user requests and doc-
uments (Nie, 2010). In fact, in real life, a user sub-
mitting a query in French could also be interested in
documents in English, German, Arabic, etc.
In order to solve the problem of linguistic hetero-
geneity, the intuitive solution consists in translating
the query and/or the documents before performing the
search. We distinguish three general approaches for
translation that can be used in the design of a CLIR
system (Zhou et al., 2012) depending on translating
the query to match the representation of the document
or translate the document to match the query or trans-
late both of the query and the document to a third lan-
guage called pivot.
The first method is the most widespread in CLIR
researches since the length of the query is usually
short which makes its translation faster and easier.
However, the reduced length of the query may gener-
ate ambiguity effect due to a limited contextual infor-
mation for the translation phase. Therefore, the sec-
ond method of document translation retains the the-
oretical advantage of having more contextual infor-
mation to determine the correct translation. However,
given the volume of the documents, this translation
becomes rather slow. This will require translating the
documents into all possible languages.
The paper is organized as follows: We review in
Section 2 previous related works about cross-lingual
disambiguation. In Section 3, we present the model
architecture that we used to perform translations dis-
ambiguation task. Section 4 details our new proposed
possibilistic approach for query disambiguation. Ex-
perimental results and their discussion are provided in
Section 5. Finally, Section 6 concludes this paper by
evaluating our work and proposing some directions
for future research.
2 RELATED WORK
The main approaches for query translation could be
resumed in using a Machine Translation (MT) system
or using a bilingual token-to-token resource (such as
bilingual dictionaries) or relying on corpus analysis.
606
Khiroun, O., Elayeb, B. and Saoud, N.
Towards a Query Translation Disambiguation Approach using Possibility Theory.
DOI: 10.5220/0006654706060613
In Proceedings of the 10th International Conference on Agents and Artificial Intelligence (ICAART 2018) - Volume 2, pages 606-613
ISBN: 978-989-758-275-2
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Many barriers still challenge the development of
CLIR systems such as the coverage of dictionaries,
the unavailability of parallel corpora in some lan-
guages and common linguistic specificity like poly-
semy, agglutination and named entity recognition.
Parallel corpora are considered a common source
of knowledge to perform the disambiguation task in
multilingual context. By sharing hidden meaning
that can be useful for extracting linguistic knowledge,
these corpora are good resources not only for per-
forming Cross-Lingual Word Sense Disambiguation
(CLWSD), but also for Natural Language Processing
(NLP) tasks (Resnik, 2004).
2.1 Graph-based Approaches for
CLWSD
In general, many techniques have been addressed
for solving CLWSD. As observed by (Duque et al.,
2015), graph-based systems are one of the most suc-
cessful approaches in the systems that participated in
the 2010 and 2013 SemEval competitions. Some of
these algorithms, have been widely used in the lit-
erature (Mihalcea, 2005; Navigli and Lapata, 2010;
Agirre et al., 2014).
(V
´
eronis, 2004) presented the HyperLex algo-
rithm which is a corpus-based approach by build-
ing a co-occurrence graph for all pairs of words co-
occurring in the context of the target word. This kind
of graph have the properties of small world graphs.
Hence, the graph possesses highly connected compo-
nents (or hubs) that identify the main word uses (or
senses) of the target word, and so can be used to per-
form WSD task.
Agirre et al. present in (Agirre et al., 2006) a
comparative study between the Hyperlex algorithm of
V
´
eronis with an adapted algorithm of PageRank (Brin
and Page, 1998) for WSD. Thus, they explored the
use of two graph algorithms for corpus-based dis-
ambiguation of nominal senses. The performance of
PageRank was nearly the same as that of HyperLex,
with the advantage of PageRank of using less opti-
mization parameters.
(Silberer and Ponzetto, 2010) was inspired by the
works of (V
´
eronis, 2004) and (Agirre et al., 2006).
In fact, they presented in their work a graph-based
system to perform CLWSD by using a co-occurrence
graph built from multilingual parallel corpora and
the application of previously developed graph algo-
rithms for monolingual WSD. Afterwards, the Mini-
mum Spanning Tree (MST) is extracted from the final
graph to perform WSD.
(Duque et al., 2015) presented an approach which
comprises the automatic generation of bilingual dic-
tionaries and the construction of a co-occurrence
graph to select the most suitable translations from
the dictionary. The proposed algorithms are based
on (i) sub-graphs (or communities) containing clus-
ters of words with related meanings, (ii) distances
between nodes representing words, and (iii) the rel-
ative importance of each node in the whole graph.
Using the SemEval-2010 and SemEval-2013 datasets
to evaluate their system, they proved the validity of
the unsupervised graph-based technique, which uses
the whole document as a coherent piece of informa-
tion, while other works consider windows of a spe-
cific size for building the context and calculating the
co-occurrences.
2.2 Combining Lexical and Statistical
Resources for CLIR
Since there are a diversity of query translation tech-
niques, the idea of combining these techniques was
studied in recent works in order to examine if one
approach is complementary to an other (Nie, 2010;
Azarbonyad et al., 2013; Schamoni et al., 2014).
For example, (Herbert et al., 2011) introduced in
a CLIR model by using Wikipedia to map concepts in
one language to their equivalents in another language.
This mapping is ensured thanks to the redirection
and cross-language links in multilingual Wikipedia
versions. In this work, the authors showed that the
Wikipedia translations can improve the performance
of statistical machine translation based CLIR systems.
In fact, queries are translated with Google Trans-
late online service and extended with new transla-
tions. These translations are obtained by mapping
noun phrases in the query to concepts in the target
language using Wikipedia.
(T
¨
ure and Boschee, 2014) have introduced a new
method for building a single combination recipe for
each query. They formulated this idea as a set of
binary classification problems. The results show
that trained classifiers can be used to produce query-
specific combination weights effectively.
(Kim et al., 2015) explored how combining lex-
ical and statistical translation resources can improve
CLIR. Indeed, they used both Wikipedia and a ma-
chine readable dictionary (MRD) as lexical transla-
tion knowledge. Moreover, they explored parallel cor-
pora to extract statistically the translation candidates.
Kim et al. have proved that using the three transla-
tion evidences together (ie. a MRD, a parallel cor-
pus and Wikipedia knowledge) can yield better results
from any one source alone. Kim et al. proposed an
approach to post-translation query expansion using a
random walk over the Wikipedia concept link graph.
Towards a Query Translation Disambiguation Approach using Possibility Theory
607

This approach yields further improvements over al-
ternative techniques when evaluated on the NTCIR-5
English–Korean test collection.
A previous work of Elayeb et al. (Elayeb et al.,
2017) try to adjust dictionary based query translation
approaches since these approaches suffer from trans-
lation ambiguity and a word-by-word query transla-
tion is not always accurate. In this work, the au-
thors proposed a probability-to-possibility transfor-
mation as a mean to introduce further tolerance in
query translation process. The reported experiments
on the CLEF-2003 test collection showed that the
performance of the probability-to-possibility transfor-
mation based approach is better than the probabilis-
tic one and some state-of-the-art CLIR tools. The
work of Elayeb et al. was extended in (Ben Romd-
hane et al., 2017) to a discriminative possibilistic
query translation disambiguation approach using both
a bilingual dictionary and the Europarl parallel cor-
pus. The main goal is to overcome some draw-
backs of the dictionary-based techniques. When eval-
uated with the CLEF-2003 test collection, the dis-
criminative possibilistic approach outperformed both
the probabilistic and the probability-to-possibility
transformation-based approaches, especially for short
queries.
3 MODEL ARCHITECTURE FOR
DISAMBIGUATING QUERY
TRANSLATIONS
In this section, we propose the model architecture
to design and implement a new approach for disam-
biguating query translations in CLIR. We present in
Figure 1 the different resources and steps of this task
as follows:
Starting from an initial query written in French
(which presents the source language), a set of transla-
tions candidates in English language is reached from a
specific built dictionary. The process of building this
dictionary is described in sub-section 3.1.
Afterwards, the disambiguation module processes
ambiguous words, which have more than one possible
translation candidate. In this step, two main resources
are used to choose only the most relevant translation
(see details in sub-section 3.2).
A pseudo relevance feedback is applied at the end
of the process by extracting the most significant terms
from the top first returned documents and the whole
process may be iterated.
Co-occurrence graph
resource from Europarl
English documents
Index of
documents
Dictionary of
translations
Expanded
query
Search
Pseudo relevance
feedback
Documents
results
Resources for disambiguating
query translations
Disambiguated
translated query
Matching
User
Europarl
parallel corpus
Disambiguating query
translations
Find English
translations
Query in
French
PRF
A set of
possible
translations
Resources for extracting
words translations
BabelNet
Figure 1: Overview of the disambiguation process for query
translations.
3.1 Extracting Translation Candidates
To select the translation candidates for the query
terms, we build a bilingual dictionary from the align-
ment of texts in French with the corresponding En-
glish texts in Europarl collection. This collection in-
cludes parallel texts in more than 11 languages which
are extracted from the proceedings of the European
Parliament (Koehn, 2005). Europarl was designed
initially for the statistical machine translation (SMT).
Nevertheless, it is used in other applications such as
NLP and WSD.
Afterwards, to ensure the alignment of the paral-
lel texts in Europarl at the word level, we used the
GIZA++ statistical machine translation toolkit
1
. This
tool is a statistical aligner that is able to extract one-
to-many translations (Och and Ney, 2003).
The final extracted couples of word in both source
and target languages are structured in CSV format.
This format may help in making the dictionary an
easy human readable resource. Nevertheless, the built
resource lacks of coverage. Actually, we exploited a
limited set of 717 French words enclosed in CLEF-
2003 standard collection’s queries (or topics). The fi-
nal number of English translation candidates is 2324.
1
http://www.statmt.org/moses/giza/GIZA++.html
ICAART 2018 - 10th International Conference on Agents and Artificial Intelligence
608

Thus, extracting a limited subset of translations may
lead to an Out Of Vocabulary (OOV) problem in case
of using this resource for other more general purpose.
3.2 Disambiguating Query Translations
In order to proceed in disambiguation task of the pro-
posed translation candidates after extraction step, we
used two different types of resources: a statistical and
a lexical resource. On the one hand, we extracted
a co-occurrence graph from Europarl English docu-
ments. Each word is related with other words of the
same sentence, based on the assumption that if two
terms co-occur then they tend to be semantically re-
lated (Cao et al., 2005). Hence, we consider the sen-
tence as the context window.
On the other hand, we used BabelNet, which is
considered as a rich lexical resource by the integra-
tion of lexicographic and encyclopedic knowledge
from WordNet and Wikipedia (Navigli and Ponzetto,
2012). BabelNet is a multilingual knowledge re-
source, in that it provides a semantic network where
related concepts are connected within a graph struc-
ture. Given these distinguishing features, BabelNet is
a powerful resource for performing knowledge-based
lexical disambiguation in a multilingual setting. Ba-
belNet groups words into sets of synonyms called
synsets (this name is inspired from WordNet termi-
nology (Miller et al., 1990)). All words composing a
given Babel synset are semantically related.
4 A POSSIBILISTIC APPROACH
FOR DISAMBIGUATING
QUERY TRANSLATIONS
We based our approach on the possibilistic theory in-
troduced by Zadeh (Zadeh, 1978) and developed by
several authors (Dubois and Prade, 2011).
Consider we have a query written in source lan-
guage Q
(src)
= {T
(src)
1
,T
(src)
2
,...,T
(src)
n
} where n rep-
resents the number of words in the query. Each term
T
(src)
i
in the query may have one to many translation
candidates in a chosen target language.
Let’s note by Φ(T
(src)
i
) = {T
(trg)
i j
, j ∈ [1..m]} the
set of the m possible translation candidates, for a term
T
(src)
i
, that are extracted from the built bilingual dic-
tionary (refer to sub-section 3.1).
We call vector of context, relative to a term T
(src)
i
,
the union of sets of translation candidates for terms
T
(src)
k
6= T
(src)
i
formalized as follows:
VC
i
= {
[
Φ(T
(src)
k
), k 6= i and k ∈ [1..m]} (1)
We designate by semantic vector, relative to
a translation candidate T
(trg)
i j
, the set of extracted
terms from the co-occurrence graph or the assembled
synsets from BabelNet as described previously in sub-
section 3.2. Hence, we note the semantic vector as
follows:
V S
i j
=< s
(trg)
i j1
, s
(trg)
i j2
,..., s
(trg)
i jk
> (2)
The relevance of a semantic vector, presented by
V S
i j
, to the vector of context of the query, is deter-
mined by extending the possibilistic matching model
proposed in (Ben Khiroun et al., 2012) by using a
double measure of relevance as follows:
The possible relevance allows ignoring irrelevant
translations to a given query. The necessary relevance
reinforces the need to include relevant translation can-
didates in the final translation of the query.
The possibility measure Π(V S
i j
|VC
i
) is propor-
tional to:
Π(V S
i j
|VC
i
) = Π(w
1
|V S
i j
) × ... × Π(w
p
|V S
i j
)
= n f t
1i j
× . .. × n f t
pi j
(3)
• With: n f t
ki j
= t f
ki j
/max(t f
ki j
) represents the nor-
malized frequency of the translation term w
k
∈
VC
i
in the semantic vector V S
i j
relative to the
translation term candidate T
(trg)
i j
;
• And t f
ki j
=
occurrences number o f w
k
inV S
i j
number o f termsinV S
i j
.
The necessity to restore a relevant translation candi-
date T
(trg)
i j
for a context of translation terms, noted by
N(V S
i j
|VC
i
), is calculated as the following:
N(V S
i j
|VC
i
) = 1 − Π(¬V S
i j
|VC
i
) (4)
At the same way, Π(¬V S
i j
|VC
i
) is proportional
to:
Π(¬V S
i j
|VC
i
) = (1 − φ
1
(T
(trg)
i j
)) × ... × (1 − φ
p
(T
(trg)
i j
))
(5)
Where:
φ
k
(T
(trg)
i j
) = Log
10
(
nCT
i
nT
ik
) × n f t
ki j
(6)
• With: nCT
i
: Number of translation candidates for
the term T
(src)
i
of the initial query;
• And nT
ik
: Number of translation candidates con-
taining the term w
k
∈ VC
i
.
We define the degree of possibilistic relevance (DPR)
of each translation candidate (T
(trg)
i j
) giving a context
of translation terms (VC
i
) by the following formula:
DPR(V S
i j
|VC
i
) = Π(V S
i j
|VC
i
) + N(V S
i j
|VC
i
) (7)
The preferred translations are those having a high
score of DPR.
Towards a Query Translation Disambiguation Approach using Possibility Theory
609

We resume in Algorithm 1 the different steps of
our proposed possibilistic approach.
Algorithm 1: The possibilistic algorithm for query
translation disambiguation.
input : Q
(src)
query in source language
output: Q
(trg)
translated query in target
language
1 foreach term T
(src)
i
∈ Q
(src)
do
2 build vector of context VC
i
3 foreach translation candidate
T
(trg)
i j
∈ Φ(T
(src)
i
) do
4 extract semantic vector V S
i j
from a
resource
5 compute possibilistic score of V S
i j
in
relation with VC
i
6 end
7 add best translation candidate to Q
(trg)
8 end
5 EXPERIMENTAL RESULTS
AND COMPARATIVE STUDY
In this section, we evaluate and compare the contribu-
tion of the possibilistic approach by using lexical and
statistical translation resources. We used the CLEF-
2003 as standard test collection. This collection pro-
vides necessary tools for the evaluation of information
retrieval systems for mono- and multilingual tasks. It
includes a set of documents, a set of queries and the
list of relevant documents for each query (Braschler
and Peters, 2004). The documents, that form CLEF-
2003, are written in 9 European languages (including
English and French) and are collected from the same
periods and have comparable contents.
To perform the experimentation, we used the Ter-
rier platform for information retrieval. All experi-
ments are carried out using the OKAPI BM25 weight-
ing model for matching between queries and docu-
ments (Ounis et al., 2007).
5.1 Evaluating the Query Translation
Approach
We compare in Figure 2 our proposed approach
for disambiguating query translations based on two
knowledge resources. The series, labeled with “Cooc-
currence” and “Babelnet”, refer respectively to the
co-occurrence built graph scenario and to synsets ex-
tracted from BabelNet.
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0 ,8 0, 9 1
Precision
Recall
Baseline
MT
Babelnet
Cooccurrence
Figure 2: Recall-Precision curve comparing different runs.
The “baseline” series represent the precision
of the original English version of queries pro-
posed in CLEF-2003 test collection. We intro-
duced also the results of translations using the
Google Translate Machine Translation (MT) tool
(https://translate.google.com).
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
Precision
Recall
Baseline+PRF
MT+PRF
Babelnet+PRF
Cooccurrence+PRF
Figure 3: Recall-Precision curve comparing different runs
by applying pseudo-relevance feedback (PRF).
The pseudo-relevance feedback (PRF) technique
exploits the top k most relevant retrieved documents
in order to expand the proposed query. Therefore, a
set of candidate terms from these documents is added
using often variants of Rocchio algorithm (Rocchio,
1971). Hence, we present, in Figure 3, the impact
of applying PRF with previous runs scenarios. We
used the Bo1 (Bose-Einstein 1) PRF algorithm imple-
mented in the Terrier IR platform by applying the de-
fault settings as follows: the number of terms to ex-
pand a query is set to 10 and the number of top-ranked
documents from which these terms are extracted is
limited to three documents.
Table 1 details precision values @5, @10,
@15. . . and @1000 top documents of all runs by ap-
plying the PRF query expansion. Results show that
using co-occurrence as a disambiguating resource by
applying the possibilistic approach outperform other
resources at first top documents. However, the perfor-
mance of MT is better at last ranked documents.
To refine our study about the co-occurrence
based approach in comparison with the BabelNet
ICAART 2018 - 10th International Conference on Agents and Artificial Intelligence
610
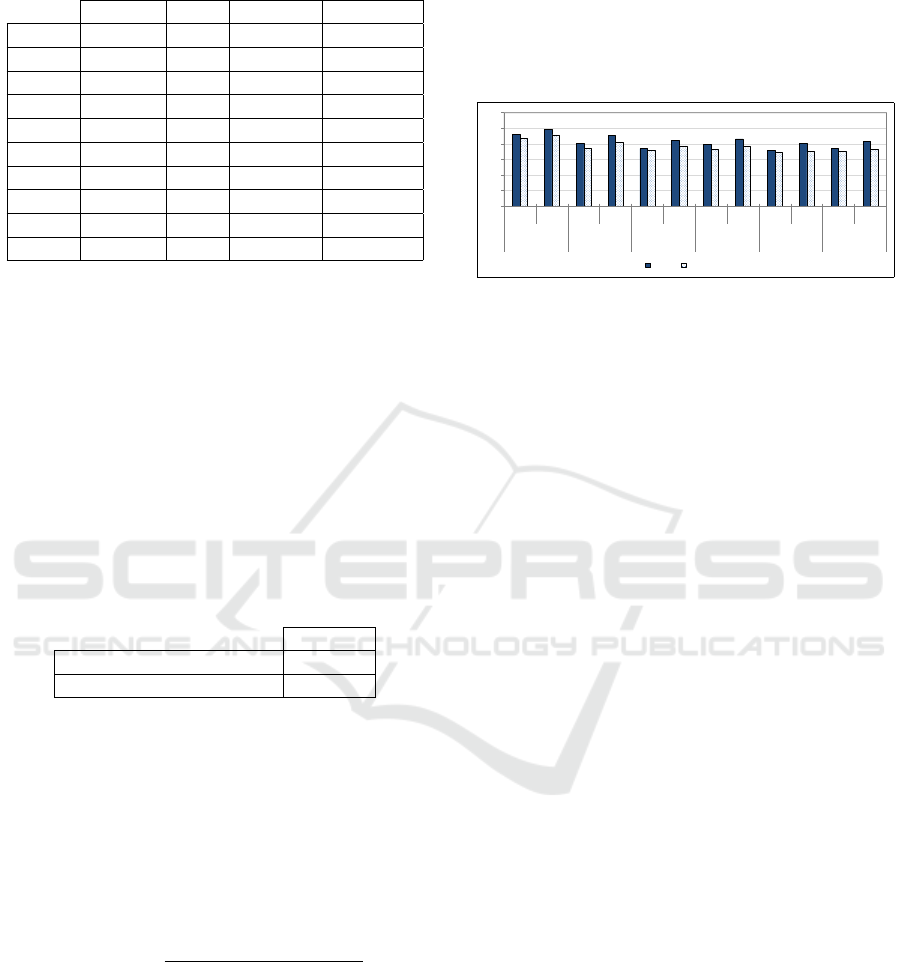
Table 1: Precision values for different runs by applying
pseudo relevance feedback.
Baseline MT BabelNet Co-occurr.
P@5 0,4148 0,3741 0,3741 0,3815
P@10 0,3333 0,3259 0,3037 0,3352
P@15 0,2975 0,2864 0,2691 0,3012
P@20 0,2741 0,2657 0,2398 0,2759
P@30 0,2309 0,2259 0,2049 0,2364
P@50 0,1785 0,1789 0,1596 0,1848
P@100 0,118 0,1185 0,1056 0,1174
P@200 0,0705 0,0694 0,065 0,0683
P@500 0,0334 0,0315 0,0304 0,0313
P@1000 0,0175 0,0164 0,0162 0,0163
and the machine translation approaches, we use the
Wilcoxon matched-pairs signed-ranks test as proposed
by (Dem
ˇ
sar, 2006). The given values (p value) are
computed by comparing the precision values pairs of
the co-occurrence based resource approach to each
from the other machine translation and BabelNet
based approaches.
As given in Table 2, the p value results prove
that the improvement of the co-occurrence approach,
compared to both the MT (p value = 0.010301 < 0.05)
and to the BabelNet (p value = 0.003509 < 0.05), is
statistically significant (Biau et al., 2010).
Table 2: The p value results for the Wilcoxon matched-pairs
signed-ranks test for precision values.
p value
Co-occurrence vs. MT 0.010301
Co-occurrence vs. BabelNet 0.003509
In order to have a comparison study of the pos-
sibilistic model, we conducted more detailed experi-
ments by using the circuit-based approach measure.
This approach was studied previously in monolingual
WSD by (Elayeb et al., 2015).
In our current work, we apply this model for dis-
ambiguating query translations terms by computing
semantic similarity of a given term t
i
and a translation
candidate t
j
according to the following formula:
sim(t
i
,t
j
) =
#circuits(t
i
,t
j
)
MAX(#circuitsin graph)
(8)
• Where: #circuits(t
i
,t
j
): represents the number
of circuits starting from the node t
i
and passing
through the node t
j
in the graph (i.e. t
i
→ ... →
t
j
→ ... → t
i
);
• And: MAX(#circuitsin graph): represents the
maximum number of circuits in the graph.
Aiming to optimize the search of circuits in the graph
structure, we extracted a limited collection of Ba-
belNet’s synsets included in the translation candi-
dates. This subset covers only the dictionary of
translations entries that corresponds to CLEF-2003
queries. Besides, we considered the maximum length
of circuit taken into account about 4 edges as studied
in (Elayeb, 2009).
0
0,1
0,2
0,3
0,4
0,5
0,6
simple PRF simple PRF simple PRF simple PRF simple PRF simple PRF
Baseline MT Babelnet
(possibilistic)
Cooccurrence
(possibilistic)
Babelnet
(circuit-based)
Cooccurrence
(circuit-based)
MAP R-précision
Figure 4: MAP and R-precision results for possibilistic
and circuit-based approaches by applying pseudo relevance
feedback (scenario “PRF”) and without applying it (sce-
nario “simple”).
Figure 4 shows the values of the MAP and R-
precision common measures in the evaluation of IR
systems. The MAP value represents the mean aver-
age precision of the query topics and the R-precision
defines the precision at rank R; where R is the total
number of relevant documents (Baccini et al., 2012)
As a general first observation, we notice that the
co-occurrence methods still outperform with little en-
hancement the BabelNet based runs. However, all
runs are under baseline and MT performance when
considering the MAP an R-precision metrics.
Results show an advance for possibilistic runs
when compared to the circuit-based approaches. In-
deed, computing the DPR score comprises two mea-
sures: the possible relevance allows rejecting irrel-
evant translations, whereas the necessary relevance
makes it possible to reinforce the translations not
eliminated by the possibility. The performance of
possibilistic models versus probabilistic ones was
also observed in other applications such as query
expansion (Elayeb et al., 2011) and monolingual
WSD (Elayeb et al., 2015).
6 CONCLUSION
This work presents and compares possibilistic and
circuit-based approaches using statistical and lexical
resources. The two resources are built by modeling
co-occurrence graph and extracting BabelNet synsets
relations to form graph data structures. Our proposed
approach aim to design a general process for CLWSD.
On the one hand, the proposed possibilistic ap-
proach outperformed the circuit-based one. On the
other hand, using co-occurrence graphs have resulted
Towards a Query Translation Disambiguation Approach using Possibility Theory
611

to slightly better performance compared to exploiting
extracted sub-networks from BabelNet. Furthermore,
applying pseudo-relevance feedback technique con-
tributed in the enhancement of different runs, which
joins previous works (Paskalis and Khodra, 2011;
Ben Khiroun et al., 2014; Elayeb et al., 2014).
As future perspectives of the current work, we
propose to resolve the out of vocabulary problem due
to the nature of bilingual dictionary extraction pro-
cess that is proposed in this paper. In fact, knowl-
edge based query translation approaches that rely on
aligned corpora are dependent to the size and the type
of analyzed texts. This could be a great challenge
face to the lack of parallel resources for some lan-
guages like Arabic as presented in (Elayeb and Boun-
has, 2016). Another potentially interesting direction
for future work would be to study the impact of ap-
plying query expansion before and after the transla-
tion process (known also by pre- and post-translation
query expansion). Moreover, we can study the con-
tribution of query expansion techniques, other than
pseudo-relevance feedback, such as knowledge based
ones that rely on machine readable dictionaries or by
exploiting ontological semantic relations for example.
ACKNOWLEDGEMENTS
We are grateful to the Evaluations and Language re-
sources Distribution Agency (ELDA) which kindly
provided us the CLEF-2003 collection.
REFERENCES
Agirre, E., L
´
opez de Lacalle, O., and Soroa, A. (2014). Ran-
dom Walks for Knowledge-based Word Sense Disam-
biguation. Comput. Linguist., 40(1):57–84.
Agirre, E., Mart
´
ınez, D., de Lacalle, O. L., and Soroa, A.
(2006). Two Graph-based Algorithms for State-of-
the-art WSD. In Proceedings of the 2006 Conference
on Empirical Methods in Natural Language Process-
ing, EMNLP ’06, pages 585–593, Stroudsburg, PA,
USA. Association for Computational Linguistics.
Azarbonyad, H., Shakery, A., and Faili, H. (2013). Ex-
ploiting Multiple Translation Resources for English-
Persian Cross Language Information Retrieval. In In-
formation Access Evaluation. Multilinguality, Multi-
modality, and Visualization, Lecture Notes in Com-
puter Science, pages 93–99. Springer, Berlin, Heidel-
berg.
Baccini, A., D
´
ejean, S., Lafage, L., and Mothe, J. (2012).
How many performance measures to evaluate infor-
mation retrieval systems? Knowledge and Informa-
tion Systems, 30(3):693–713.
Ben Khiroun, O., Elayeb, B., Bounhas, I., Evrard, F., and
Bellamine-BenSaoud, N. (2012). A Possibilistic Ap-
proach for Automatic Word Sense Disambiguation. In
Proceedings of the 24th Conference on Computational
Linguistics and Speech Processing (ROCLING), pages
261–275, Taiwan.
Ben Khiroun, O., Elayeb, B., Bounhas, I., Evrard, F., and
Bellamine-BenSaoud, N. (2014). Improving query
expansion by automatic query disambiguation in in-
telligent information retrieval. In The 6th Interna-
tional Conference on Agents and Artificial Intelli-
gence (ICAART 2014), pages 153–160, Angers, Loire
Valley, France.
Ben Romdhane, W., Elayeb, B., and Bellamine Ben Saoud,
N. (2017). A Discriminative Possibilistic Approach
for Query Translation Disambiguation. In Natu-
ral Language Processing and Information Systems,
Lecture Notes in Computer Science, pages 366–379.
Springer, Cham.
Biau, D. J., Jolles, B. M., and Porcher, R. (2010). P value
and the theory of hypothesis testing: an explanation
for new researchers. Clinical Orthopaedics and Re-
lated Research, 468(3):885–892.
Braschler, M. and Peters, C. (2004). CLEF 2003 Methodol-
ogy and Metrics. In Peters, C., Gonzalo, J., Braschler,
M., and Kluck, M., editors, Comparative Evaluation
of Multilingual Information Access Systems, number
3237 in Lecture Notes in Computer Science, pages 7–
20. Springer Berlin Heidelberg.
Brin, S. and Page, L. (1998). The Anatomy of a Large-
scale Hypertextual Web Search Engine. In Proceed-
ings of the Seventh International Conference on World
Wide Web 7, WWW7, pages 107–117, Amsterdam,
The Netherlands, The Netherlands. Elsevier Science
Publishers B. V.
Cao, G., Nie, J.-Y., and Bai, J. (2005). Integrating Word
Relationships into Language Models. In Proceedings
of the 28th Annual International ACM SIGIR Con-
ference on Research and Development in Information
Retrieval, SIGIR ’05, pages 298–305, New York, NY,
USA. ACM.
Dem
ˇ
sar, J. (2006). Statistical Comparisons of Classifiers
over Multiple Data Sets. J. Mach. Learn. Res., 7:1–
30.
Dubois, D. and Prade, H. (2011). Possibility theory and its
application: Where do we stand. Mathware and Soft
Computing, 18(1):18–31.
Duque, A., Araujo, L., and Martinez-Romo, J. (2015). CO-
graph: A new graph-based technique for cross-lingual
word sense disambiguation. Natural Language Engi-
neering, 21(5):743–772.
Elayeb, B. (2009). SARIPOD: Syst
`
eme multi-Agent de
Recherche Intelligente POssibiliste des Documents
Web. PhD thesis, Institut National Polytechnique de
Toulouse, France & Ecole Nationale des Sciences de
l’Informatique, Universit
´
e de la Manouba, Tunisie.
Elayeb, B., Ben Romdhane, W., and Bellamine Ben Saoud,
N. (2017). Towards a new possibilistic query trans-
lation tool for cross-language information retrieval.
Multimedia Tools and Applications, pages 1–43.
ICAART 2018 - 10th International Conference on Agents and Artificial Intelligence
612

Elayeb, B. and Bounhas, I. (2016). Arabic Cross-Language
Information Retrieval: A Review. ACM Trans. Asian
Low-Resour. Lang. Inf. Process., 15(3):1–44.
Elayeb, B., Bounhas, I., Ben Khiroun, O., Evrard, F.,
and Bellamine Ben Saoud, N. (2015). A Compara-
tive Study Between Possibilistic and Probabilistic Ap-
proaches for Monolingual Word Sense Disambigua-
tion. Knowl. Inf. Syst., 44(1):91–126.
Elayeb, B., Bounhas, I., Ben Khiroun, O., Evrard, F., and
Bellamine-BenSaoud, N. (2011). Towards a possi-
bilistic information retrieval system using semantic
query expansion:. International Journal of Intelligent
Information Technologies, 7(4):1–25.
Elayeb, B., Bounhas, I., Khiroun, O. B., and Saoud, N. B. B.
(2014). Combining Semantic Query Disambiguation
and Expansion to Improve Intelligent Information Re-
trieval. In Duval, B., Herik, J. v. d., Loiseau, S., and
Filipe, J., editors, Agents and Artificial Intelligence,
number 8946 in Lecture Notes in Computer Science,
pages 280–295. Springer International Publishing.
Herbert, B., Szarvas, G., and Gurevych, I. (2011). Combin-
ing Query Translation Techniques to Improve Cross-
language Information Retrieval. In Proceedings of the
33rd European Conference on Advances in Informa-
tion Retrieval, ECIR’11, pages 712–715, Berlin, Hei-
delberg. Springer-Verlag.
Kim, S., Ko, Y., and Oard, D. W. (2015). Combining lexical
and statistical translation evidence for cross-language
information retrieval. Journal of the Association for
Information Science and Technology, 66(1):23–39.
Koehn, P. (2005). Europarl: A Parallel Corpus for Statistical
Machine Translation. In Proceedings of the 10th Ma-
chine Translation Summit, pages 79–86, Phuket, Thai-
land. AAMT.
Mihalcea, R. (2005). Unsupervised Large-vocabulary Word
Sense Disambiguation with Graph-based Algorithms
for Sequence Data Labeling. In Proceedings of
the Conference on Human Language Technology and
Empirical Methods in Natural Language Processing,
HLT ’05, pages 411–418, Stroudsburg, PA, USA. As-
sociation for Computational Linguistics.
Miller, G. A., Beckwith, R., Fellbaum, C., Gross, D., and
Miller, K. J. (1990). Introduction to WordNet: An
On-line Lexical Database. International Journal of
Lexicography, 3(4):235–244.
Navigli, R. and Lapata, M. (2010). An Experimental Study
of Graph Connectivity for Unsupervised Word Sense
Disambiguation. IEEE Trans. Pattern Anal. Mach. In-
tell., 32(4):678–692.
Navigli, R. and Ponzetto, S. P. (2012). BabelNet: The Au-
tomatic Construction, Evaluation and Application of a
Wide-coverage Multilingual Semantic Network. Artif.
Intell., 193:217–250.
Nie, J.-Y. (2010). Cross-language Information Retrieval.
Morgan & Claypool Publishers.
Och, F. J. and Ney, H. (2003). A Systematic Comparison of
Various Statistical Alignment Models. Comput. Lin-
guist., 29(1):19–51.
Ounis, I., Lioma, C., Macdonald, C., and Plachouras, V.
(2007). Research directions in terrier: a search engine
for advanced retrieval on the web. CEPIS Upgrade
Journal, 8(1).
Paskalis, F. and Khodra, M. (2011). Word sense disam-
biguation in information retrieval using query expan-
sion. In 2011 International Conference on Electrical
Engineering and Informatics (ICEEI), pages 1–6.
Resnik, P. (2004). Exploiting Hidden Meanings: Using
Bilingual Text for Monolingual Annotation. In Com-
putational Linguistics and Intelligent Text Processing,
Lecture Notes in Computer Science, pages 283–299.
Springer, Berlin, Heidelberg.
Rocchio, J. (1971). Relevance Feedback in Information
Retrieval. In The SMART Retrieval System, pages
313–323. Prentice-Hall, Englewood Cliffs, New Jer-
sey, USA.
Schamoni, S., Hieber, F., Sokolov, A., and Riezler, S.
(2014). Learning Translational and Knowledge-based
Similarities from Relevance Rankings for Cross-
Language Retrieval. In Proceedings of the 52nd An-
nual Meeting of the Association for Computational
Linguistics, ACL 2014, volume 2, pages 488–494,
Baltimore, MD, USA.
Silberer, C. and Ponzetto, S. P. (2010). UHD: Cross-Lingual
Word Sense Disambiguation Using Multilingual Co-
Occurrence Graphs. In Erk, K. and Strapparava, C.,
editors, Proceedings of the 5th International Work-
shop on Semantic Evaluation, SemEval@ACL 2010,
Uppsala University, Uppsala, Sweden, July 15-16,
2010, pages 134–137. The Association for Computer
Linguistics.
T
¨
ure, F. and Boschee, E. (2014). Learning to Translate:
A Query-Specific Combination Approach for Cross-
Lingual Information Retrieval. In Moschitti, A., Pang,
B., and Daelemans, W., editors, Proceedings of the
2014 Conference on Empirical Methods in Natural
Language Processing, EMNLP 2014, pages 589–599.
ACL.
V
´
eronis, J. (2004). HyperLex: lexical cartography for in-
formation retrieval. Computer Speech & Language,
18(3):223–252.
Zadeh, L. (1978). Fuzzy sets as a basis for a theory of pos-
sibility. Fuzzy Sets and Systems, 1(1):3–28.
Zhou, D., Truran, M., Brailsford, T., Wade, V., and Ash-
man, H. (2012). Translation techniques in cross-
language information retrieval. ACM Comput. Surv.,
45(1):1:1–1:44.
Towards a Query Translation Disambiguation Approach using Possibility Theory
613
