
AECID: A Self-learning Anomaly Detection Approach based on
Light-weight Log Parser Models
Markus Wurzenberger, Florian Skopik, Giuseppe Settanni and Roman Fiedler
AIT Austrian Instritute of Technology, Center for Digital Safety and Security, Vienna, Austria
Keywords:
Anomaly Detection, Intrusion Detection System, Machine Learning, Log Analysis.
Abstract:
In recent years, new forms of cyber attacks with an unprecedented sophistication level have emerged. Addi-
tionally, systems have grown to a size and complexity so that their mode of operation is barely understandable
any more, especially for chronically understaffed security teams. The combination of ever increasing exploita-
tion of zero day vulnerabilities, malware auto-generated from tool kits with varying signatures, and the still
problematic lack of user awareness is alarming. As a consequence signature-based intrusion detection systems,
which look for signatures of known malware or malicious behavior studied in labs, do not seem fit for future
challenges. New, flexibly adaptable forms of intrusion detection systems (IDS), which require just minimal
maintenance and human intervention, and rather learn themselves what is considered normal in an infrastruc-
ture, are a promising means to tackle today’s serious security situation. This paper introduces ÆCID, a new
anomaly-based IDS approach, that incorporates many features motivated by recent research results, including
the automatic classification of events in a network, their correlation, evaluation, and interpretation up to a
dynamically-configurable alerting system. Eventually, we foresee ÆCID to be a smart sensor for established
SIEM solutions. Parts of ÆCID are open source and already included in Debian Linux and Ubuntu. This
paper provides vital information on its basic design, deployment scenarios and application cases to support the
research community as well as early adopters of the software package.
1 INTRODUCTION
In 1980, James Anderson was one of the first re-
searchers who indicated the need of intrusion de-
tection systems (IDS), contradicting the common
assumption of software developers and administra-
tors, that their computer systems were running in
‘friendly’, i.e. secure, environments (James P. Ander-
son, 1980). Recent reports (Verizon, 2016) (Syman-
tec, 2016) show that while companies started to invest
large amounts of resources into cyber security already
years ago, many basic security issues unfortunately
remain. On the one side, the increasing interconnec-
tion of previously isolated infrastructures, and the cre-
ation of systems of systems as well as the emergence
of the Internet of Things (IoT) (Atzori et al., 2010)
tremendously increases the attack surface. On the
other side of the scale, the awareness in non-security
company is still rather low – most successful attacks
today still use phishing, skimming and baiting (Ver-
izon, 2016) and exploit human negligence to obtain
unauthorized access to a company’s ICT network.
A wide variety of security solutions have been
proposed in recent years to cope with this challeng-
ing situation. While some of them were able to re-
lax the situation at least partially, research on intru-
sion detection systems seems – due to rapidly chang-
ing technologies and system design paradigms – to
be a never-ending story. Signature-based approaches
(Mitchell and Chen, 2014), i.e., black-listing meth-
ods, are still the de-facto standard applied today for
some good reasons: they are essentially easy to con-
figure, can be centrally managed, i.e., do not need
much customization for specific networks, yield a ro-
bust and reliable detection for known attacks and pro-
vide low false positive rates. While these are all great
benefits for the application in today’s enterprise envi-
ronments, there are, nevertheless, solid arguments to
watch out for more sophisticated anomaly-based de-
tection mechanisms (Liao et al., 2013), which should
be applied additionally to black-listing approaches for
the reasons explained as follows.
• The exploitation of new zero-day vulnerabilities
are hardly detectable by blacklisting-approaches.
Simply, there are no signatures to describe the in-
dicators of an unknown exploit.
386
Wurzenberger, M., Skopik, F., Settanni, G. and Fiedler, R.
AECID: A Self-learning Anomaly Detection Approach based on Light-weight Log Parser Models.
DOI: 10.5220/0006643003860397
In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018), pages 386-397
ISBN: 978-989-758-282-0
Copyright © 2018 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

• Attackers can easily circumvent the detection of
Malware, once indicators are widely distributed.
Simply re-compiling a Malware with small mod-
ifications will change hash sums, names, IP ad-
dresses of command and control servers and the
like – in the worst case, rendering all these data
which is used to describe indicators useless.
• Eventually, many sophisticated attacks use social
engineering as an initial intrusion vector. Here
no technical vulnerabilities are exploited, hence,
no indicators on a blacklist can appropriately de-
scribe malicious behavior.
Especially the latter requires smart anomaly detec-
tion approaches to reliably discover deviations from
a desired system’s behavior as a consequence of an
unusual utilization through an illegitimate user. This
is the usual case when an adversary manages to steal
user credentials and is using these actually legitimate
credentials to illegitimately access a system. How-
ever, an attacker will eventually utilize the system dif-
ferently from the legitimate user, to reach his target,
for instance running scans, searching shared directo-
ries and trying to extend his influence to surround-
ing systems at either unusual speed, at unusual times,
taking unusual routes in the network, issuing actions
with unusual frequency, causing unusual data trans-
fers at unusual bandwidth. This causes a series of
events within an infrastructure which are picked up
by anomaly-based approaches and used to trigger off
alerts.
Certainly, even black-listing approaches can cover
some of these cases. For instance, log-in attempts
outside business hours is a standard case, which ev-
ery well-configured IDS can detect. The point here
is, that with just using black-listing the security per-
sonnel must think of a wide variety of potential at-
tack cases ahead and how they manifest in the net-
work, i.e., which kind of events they would trigger.
This is not only a cumbersome never-ending task, but
also extremely error-prone. Eventually, there will al-
ways be ways to exploit a system of which the de-
signers and operators did not think in advance. In
contrast to that, the application of white-listing ap-
proaches seems intriguing here: one needs to describe
the ‘normal and desired system behavior’ (this means
to ‘white list’ what is known good) and everything
that differs from this description is potentially classi-
fied as hostile.
The effort is comparatively lower, which demon-
strates impressively the advantage of an anomaly-
based approach. However, while this seems quite at-
tractive, the advantages come with a price. Often,
high false positive rates, complex behavior models,
potentially error-prone learning phases and the like
are just some of the drawbacks to consider. Deploy-
ing, configuring and effectively operating an anomaly
detection system is a highly non-trivial task.
Substantial effort has been invested to apply
anomaly detection on network traffic in real-time
(Liao et al., 2013). With these methods, irregularities
of data flows can be effectively spotted by investigat-
ing network packets and their meta data, such as flows
between previously decoupled systems or changes in
the interaction patterns and behavior. However, many
argue that in the future a reliable detection of anoma-
lies will only be feasible on the host. The wide adop-
tion of numerous tunneling technologies, end-to-end
encryption, virtualization/containerization, and soft-
ware defined networks makes it hard – if not impos-
sible – to track the real system behavior by inspect-
ing network traffic only. More sophisticated, but also
more complex is the detection of anomalies based on
actual system events. These system events are often
captured in system log files and are just waiting to be
harnessed by more modern anomaly detection tech-
niques.
In this paper, we have a close look on the applica-
bility of anomaly detection approaches in IDS which
specifically exploit semantically rich log data. In par-
ticular the contribution of this paper is threefold:
• we discuss the design principles of a modern scal-
able anomaly detection system to be applied in
large-scale distributed systems;
• we outline the ÆCID approach, which is an ac-
tual implementation based on the aforementioned
design principles;
• we demonstrate the successful application of the
ÆCID approach specifically in non-enterprise IT
environments, such as Industry 4.0 and cyber-
physical systems.
The remainder of the paper is organized as fol-
lows. Section 2 outlines important background and
related work. Section 3 discusses important con-
cepts for modern anomaly detection approaches ap-
plied in IDS systems, specifically, the distribution of
the parsing and un-supervised classification process
over numerous nodes and continuous synchronization
among them. In Section 4 the implementation of the
most important features of the ÆCID system is de-
scribed, followed by its mode of operation in Section
5. Then, Section 6 highlights typical application cases
of ÆCID and demonstrates where such a system is
superior over a standard signature-based solution. Fi-
nally, Section 7 concludes the paper.
AECID: A Self-learning Anomaly Detection Approach based on Light-weight Log Parser Models
387

2 BACKGROUND AND RELATED
WORK
Like other security tools, IDS aim to achieve a higher
level of security in ICT networks. Their primary
goal is to timely and rapidly detect invaders, so that
it is possible to react quickly and reduce the caused
damage. In opposite to Intrusion Prevention Sys-
tems (IPS) that are able to actively defend a network
against an attack, IDS are passive security mech-
anisms, which allow to detect attacks without en-
abling any countermeasure automatically (Whitman
and Mattord, 2012), but informing administrators of
the discovered intrusion through notification proce-
dures.
(Sabahi and Movaghar, 2008; Liao et al., 2013;
Garc
´
ıa-Teodoro et al., 2009) survey various methods
applicable for intrusion detection. IDS can roughly
be categorized as host-based IDS (HIDS), network-
based IDS (NIDS) and hybrid or cross-layer IDS
(Vacca, 2013). Similarly to simple security solutions
such as anti-viruses, HIDS are installed on every sys-
tem (host) of the network that needs to be monitored.
While HIDS deliver specific high-level information
about an attack and allow comprehensive monitor-
ing of a single host, they can be potentially disabled
by, for example, a Denial of Service (DoS) attack,
because if a system is once compromised also the
HIDS is. NIDS monitor and analyze the network traf-
fic crossing the network internal to an organization.
For monitoring a network with an NIDS, one single
sensor-node can be sufficient and the functionality of
this sensor is not effected if one system of the network
is compromised. A major drawback of NIDS is that
if the network is overloaded, a complete monitoring
cannot be guaranteed, because some network pack-
ets may be dropped to avoid congestion. Cross-layer
and hybrid IDS merge different methods. Hybrid IDS
usually provide a management framework that com-
bines HIDS and NIDS to reduce their drawbacks and
benefit from their advantages. Cross-layer IDS aim to
maximize the available information while minimiz-
ing the false alarm rate. To achieve this, various data
sources, such as log data and network traffic data, are
used for intrusion detection.
There exist generally three detection methods ap-
plied in IDS: signature-based detection (SD), stateful
protocol analysis (SPA), and anomaly-based detection
(AD) (Liao et al., 2013). SD and SPA can only de-
tect previously known attack patterns using signatures
and rules that describe malicious events and thus are
also called black-listing approaches (Whitman and
Mattord, 2012) (Scarfone and Mell, 2007). AD ap-
proaches are more flexible and able to detect novel
and previously unknown attacks. They establish a
baseline of normal system behavior and therefore are
also called white-listing approaches (Garc
´
ıa-Teodoro
et al., 2009).
The rapidly changing cyber threat landscape de-
mand for flexible and self-adaptive IDS approaches.
One solution are self-learning AD based approaches
that automatically learn and continuously adapt the
normal system behavior; this serves as ground truth
to detect anomalies that expose attacks and especially
invaders. Generally, there are three ways to realize
self-learning AD (Goldstein and Uchida, 2016): su-
pervised, semi-supervised, and unsupervised. Unsu-
pervised methods do not require any labeled data and
are able to learn distinguishing normal from malicious
system behavior during the training phase. Semi-
supervised methods are applied when the training set
only contains anomaly-free data; they are also known
as ‘one-class’ classification. Supervised methods re-
quire a fully labeled training set containing both nor-
mal and malicious data. These three methods do
not necessitate active human intervention during the
learning process. While unsupervised self-learning is
entirely independent from human influence, for the
other two methods the user has to ensure that the train-
ing data is anomaly free and correctly labeled. Con-
sequently, the previously described methods can be
categorized as unsupported self-learning approaches.
3 MOTIVATION AND
CHALLENGES
This section discusses the motivation behind the intro-
duction of the novel anomaly detection approach pre-
sented in this paper, and summarizes the challenges
this approach aims to address. This work builds on
our prior research on the topic, published in ((Fried-
berg et al., 2015)), and enhances the approach therein
presented by extending its features and improving its
flexibility.
Existing anomaly detection approaches that ana-
lyze computer log data are mostly designed for foren-
sic analysis. However, these techniques can comple-
ment on-line Intrusion Detection System (IDS) and
timely detect sophisticated attacks, such as advanced
persistent threats (APT), and eventually mitigate their
impact (Friedberg et al., 2015). Furthermore, con-
trarily to available state-of-the-art IDS, which mostly
process network traffic data, a paradigm shift towards
textual log data should be considered. In fact, the cur-
rent trend shows an increasing adoption of end-to-end
encryption in network communications, to secure crit-
ical information in transit. Hence, only clear text meta
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
388

information is available for the investigation, if only
network traffic is inspected. Thus, alternative data
sources need to be leveraged to effectively perform
anomaly detection. To the best of our knowledge, no
online IDS is available, which processes log data to
perform anomaly detection.
Anomaly-based IDS normally implement white-
listing mechanisms; they are also called behavior
based approaches because they compare computer
network’s or system’s activities against a model that
characterizes the normal behavior. This reference is
considered to be “anomaly-free” and is also known as
ground-truth. Today’s rapidly changing cyber threat
landscape accounts for flexible and self-adaptive IDS
approaches. Thus, to build a system behavior model
semi-supervised self-learning methods can be ap-
plied, whose main strength is the capability to detect
unknown attacks without requiring attack signatures.
Leveraging self-learning and white-listing meth-
ods it is possible to implement anomaly detection sys-
tems that are independent from semantical interpre-
tation of the processed log data, and from the syn-
tax of the data. Since the system behavior model
can be built automatically, the only requirement is
that the syntax of the log lines does not change over
time, as this would be considered as a deviation from
the normal system behavior and therefore marked as
anomaly. This is feasible because log data, contrar-
ily to free text, follows a predefined structure. Nor-
mally, a log message comprises static chunks, i.e.,
constant strings that occur often in the log sequence
(e.g., prepositions, commands, protocol names), and
variable chunks occurring less frequently (e.g., IP ad-
dresses, host names, TCP port numbers). Moreover,
the order in which different parts occur in a log line is
deterministic and does not vary.
Another benefit of self-learning and white-listing
approaches utilized for anomaly detection is their in-
trinsic flexibility. They can be applied to process logs
produced by legacy systems and by appliance with
small market shares (like those largely employed in
cyber physical systems (CPS)). Such systems often
lack of vendor support and suffer from poor docu-
mentation. Usually neither security solution providers
supply signatures for monitoring these systems, nor
vendors make patches available to keep the systems
up-to-date. Furthermore, modern networks, such as
the Internet of Things (IoT), comprise many devices
that are often not powerful enough to allocate the
large amounts of resources required to run anomaly
detection tools. Thus, light-weight anomaly detec-
tion mechanisms that can operate consuming a min-
imal amount of memory and CPU are necessary. One
way to meet this requirement is to foresee a decentral-
ized architecture. Different light-weight processing
instances can be distributed across the infrastructure,
while a central control instance, running on a pow-
erful machine, executes resource intensive operations
(such as machine-learning functions) and allows an
administrator to control the distributed light-weighted
instances.
3.1 Detectable Anomalies
In order for an anomaly detection method to be con-
sidered effective, different types of anomalies have to
be recognizable by using it, with a certain level of
confidence. In the following we list the main cate-
gories of anomalies a modern anomaly detection tool
should be capable to reveal.
The simplest type of anomaly is represented by
anomalous single events. On the one hand, these
can be so-called outliers representing rarely occur-
ring events, which appear so seldom that are not part
of the normal system behavior model. On the other
hand, these anomalies can be violations of prohibited
parameter values; for example, a client access exe-
cuted through a user agent normally not utilized in a
network, therefore not white-listed. In case of black-
listing approaches, user agents that are not allowed
need to be added (one-by-one) to the blacklist, and
hence imply a high risk of incompleteness.
Anomalous event parameters are point anomalies
such as IP addresses, port numbers or software ver-
sions that are not white-listed and therefore are not
part of the normal system behavior. This type of
anomalies includes, for example, events that occur
outside of business hours, or are triggered by accounts
of employees who are on vacation.
Anomalous single event frequencies are events
usually considered normal, which occur with an
anomalous frequency. For example, in case of data
theft, an anomalously high number of database ac-
cesses from a single client would be recorded in the
log data, triggering an anomaly.
Anomalous event sequences are anomalies reveal-
able by observing the dependency between related
events. Such dependency can be formalized by defin-
ing correlation rules. A correlation rule describes a
series of events that have to occur in an ordered se-
quence, within a given time-window, to be considered
non anomalous. To detect more complex anomalous
processes, which may involve different systems on
a network, multiple log lines need to be examined.
After a particular log line type (recording a condi-
tioning event) is observed, another specific log line
(recording the expected implied event) has to occur
within a predefined time slot. Otherwise, an anomaly
AECID: A Self-learning Anomaly Detection Approach based on Light-weight Log Parser Models
389
is raised. Additionally, such correlation rules should
be definable so that once a given (conditioning) event
occurred, the algorithm checks if in a predefined time
window previous to such event, another specific (im-
plied) event has occurred. Correlation rules allow, for
example, the detection of access chain violations, e.g.,
in course of an SQL-injection.
4 THE ÆCID APPROACH
This section introduces ÆCID, a novel anomaly de-
tection approach we propose to address the chal-
lenges outlined in the previous section. We illustrate
here the system architecture and we describe the two
main components ÆCID consists of: the AMiner and
ÆCID Central.
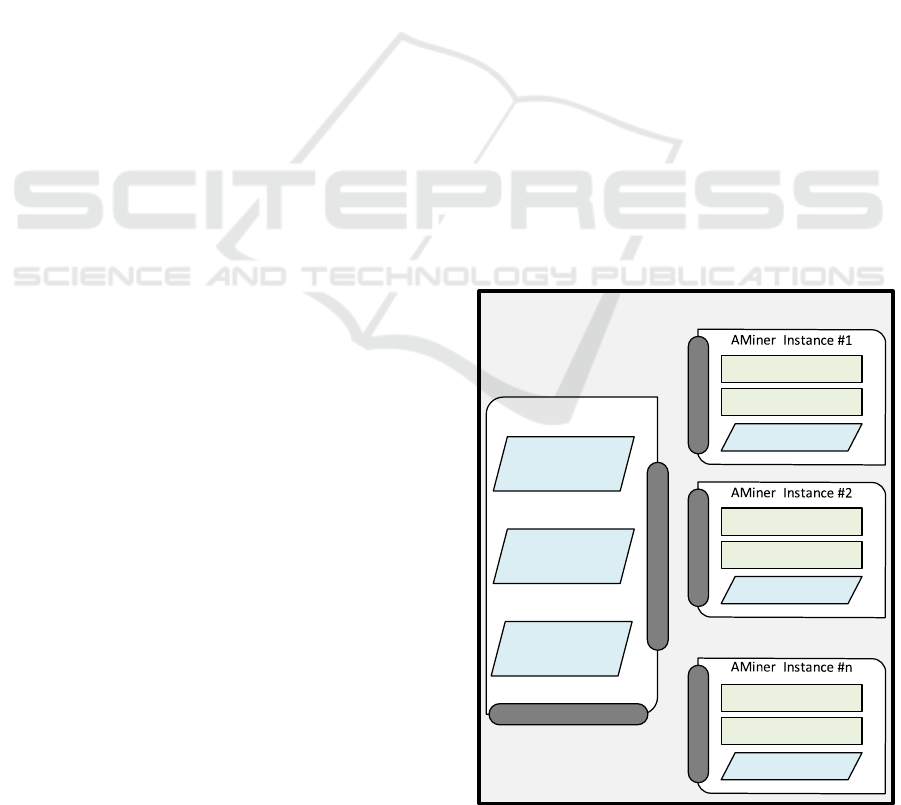
Figure 1 depicts the system architecture of ÆCID.
ÆCID is designed to allow the deployment in
highly distributed environments; in fact, due to its
lightweight implementation, an AMiner instance can
be installed, as vantage point, on any relevant node of
the network; ÆCID Central is the component respon-
sible of controlling and coordinating all the deployed
AMiner instances.
The AMiner operates similarly to an HIDS sensor.
It has to be installed on every host and network node
that needs be monitored, or – if possible – on a cen-
tralized logging storage which collects the log data
generated by the monitored nodes. Each AMiner in-
stance interprets the log messages acquired from the
node it is deployed on, following a specific model,
called parser model, generated ad-hoc to represent the
different events being logged on that particular node.
A tailored rule set identifies the events that are con-
sidered legitimate on that system; an AMiner instance
checks every parsed log line against this rule set and
reports any mismatch. Furthermore, each AMiner in-
stance comprises a report generator that produces a
detailed record of parsed and unparsed lines, alerts
and triggered alarms. The reports can be sent either
via the AECID Central Interface to the AECID Cen-
tral, or through additional interfaces (e.g., via e-mail)
to system administrators. The parser model in combi-
nation with the rule set, characterize the normal sys-
tem behavior, i.e., describe the type, structure, and
content of log lines representing events allowed to oc-
cur on the monitored system. Every log message vio-
lating this behavioral model represents an anomaly.
While the AMiner performs lightweight opera-
tions such as parsing log messages and comparing
them against a set of existing rules, ÆCID Central
provides more advanced features, and therefore re-
quires more computational resources than a single
AMiner instance. One of the main functions executed
by ÆCID Central is to learn the normal system behav-
ior of every monitored system, and consequently con-
figure the AMiner instance, running on that system,
to detect any logged abnormal activity. To do this,
ÆCID Central analyzes the logs received from each
AMiner instance, generates a tailored parser model
(Parser Model Generator function) and a specific set
of rules (Rule Generator function), and sends them
to the AMiner instance, which adopts them to exam-
ine future log messages. ÆCID Central provides the
different AMiner instances with self-learned parser
models and rule sets, and adapts them, when the net-
work infrastructure and/or the user behavior change.
Hence, ÆCID Central needs to control and configure
all the deployed AMiner instances; these operations
are performed through the AMiner Interface. More-
over, a Control Interface allows a system administra-
tor to communicate with ÆCID Central, adjust its set-
tings, and setup the deployed AMiner instances. Ad-
ditionally ÆCID Central leverages a Correlation En-
gine that allows to analyze and associate events ob-
served by different AMiner instances, with the pur-
pose of white-listing events generated by complex
processes involving diverse network nodes. ÆCID
Central also provides a Web-based GUI, to explore
and review statistics as well as information on trig-
gered alerts and alarms. If the log data collected
within a network infrastructure includes records of
communication events between network devices (e.g.,
ÆCID
ÆCID Central IF
Parser Model
Rule Set
Report Generator
...
ÆCID CENTRAL
Control Interface
AMiners IF
Parser Model
Generator
Rule
Generator
Correlation
Engine
ÆCID Central IF
Parser Model
Rule Set
Report Generator
ÆCID Central IF
Parser Model
Rule Set
Report Generator
Figure 1: ÆCID architecture.
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
390

“ntpd[“
PID [INT]
“]: “
“ntpd exiting on signal “
“Listen and drop on “
“Listening on routing
socket on fd # “
“Listen normally on “
“proto: precision = “
“peers refreshed“
“ntp_io: estimated max descriptors: 1024, initial socket boundary: 16“
“new interface(s) found: waking up resolver“
SIGNAL [INT]
FD [INT]
“ “
INTERFACE [IF]
“ “
ADDRESS [IPv6]
“ UDP 123“
ADDRESS [IPv4]
“ UDP 123“
FD [INT]
“ for interface updates“
“:123“
FD [INT]
“ “
INTERFACE [IF]
“ “
ADDRESS [IPv6]
“ UDP 123“
ADDRESS [IPv4]
“ UDP 123“
“:123“
PREC [DDM]
“ usec“
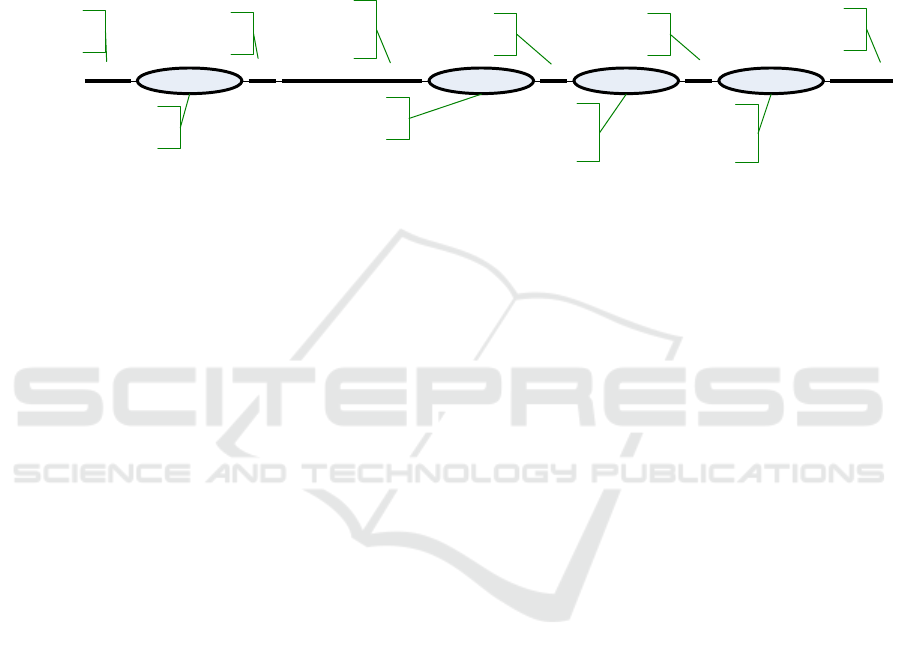
Figure 2: The graph describes the parser model for ntpd (Network Time Protocol) service logs. String under quotes are fixed
elements or elements of a list. Oval entities symbolize model elements that allow variable values (an example of a parsed
log-line is provided in Figure 3).
packets’ headers observed via tcpdump), ÆCID can
operate as NIDS, and therefore be utilized as hybrid
IDS.
4.1 AMiner
The AMiner is the peripheral component of the ÆCID
system, which executes lightweight operations on log
data collected from the system it is deployed on.
The current AMiner implementation – available open
source
1
– is compatible with Python 2.6-2.7 and has
been tested on CentoOS 6.7 and Ubuntu Xenial 16.04.
In the lightest available configuration, AMiner re-
quires only 32 MB of memory to perform simple log
line filtering. If stricter memory requirements are in
place, the AMiner can run on a separate (more power-
ful) machine, and listen to the log stream coming from
the monitored device. This makes it possible to pro-
cess logs produced by devices with low computational
power, legacy systems, and devices whose hardware
does not meet the AMiner’s installation requirements.
The following sections illustrate in detail how the
AMiner parses the captured log messages and how it
identifies whether the logged event is to be considered
legit or it indicates an anomaly.
4.1.1 Parser Model
The AMiner interprets every incoming log message
according to a specific parser model, which charac-
terizes the events observed on the device or network
component it monitors. The parser model represents
a path entropy model that efficiently describes the
white-listed, i.e. permitted, log lines. It describes the
log model of the monitored system as a graph, specifi-
cally an ordered tree (see Figure 2). The goal of using
1
https://git.launchpad.net/logdata-anomaly-miner/
the parser model is to filter out as much redundant in-
formation as possible before a detailed analysis of the
log line is performed. The parser model allows to ef-
ficiently extract all the information contained in a log
line, while retaining only a minimum amount of data.
Thus, every branch of the graph includes fixed seg-
ments, which represent constant strings always occur-
ring in the same position of the log line, and variable
segments, which represent strings that differ from line
to line.
Log messages produced by different services have
generally different syntaxes; for this reason, a parser
model can only describe the set of possible log mes-
sages produced by one single service. This implies
that an AMiner instance will adopt a distinct parser
model for each different service running on the sys-
tem that it monitors.
There exist several components, named
ModelElements, a parser can consist of. The
most frequently used are
2
:
• AnyByteDataModelElement: Match anything till
the end of a log-atom.
• DateTimeModelElement: Simple datetime pars-
ing using python datetime module.
• DecimalIntegerValueModelElement: Parsing
integer values.
• FirstMatchModelElement: Branch the model
taking the first branch matching the remaining
log-atom data.
• FixedDataModelElement: Match a fixed (con-
stant) string.
• IpAddressDataModelElement: Match an IPv4
address.
2
A more exhaustive list of model elements
can be found in the AMiner documentation at:
https://git.launchpad.net/logdata-anomaly-miner/tree/
source/root/usr/share/doc/aminer/ParsingModel.txt
AECID: A Self-learning Anomaly Detection Approach based on Light-weight Log Parser Models
391
Listing 1: Example log data of an ntpd service.
0: J u n 14 1 6:1 7 :12 g hive - ldap ntpd [16 7 21] : List e n and drop on 0 v4w i ld c a rd 0.0. 0 . 0 UDP 1 23
1: J u n 14 1 6:1 7 :12 g hive - ldap ntpd [16 7 21] : List e n and drop on 1 v6w i ld c a rd : : U DP 1 2 3
2: J u n 14 1 6:1 7 :12 g hive - ldap ntpd [16 7 21] : List e n no r m all y on 2 lo 1 2 7.0 . 0.1 UDP 1 23
3: J u n 14 1 6:1 7 :12 g hive - ldap ntpd [16 7 21] : List e n no r m all y on 3 e t h 0 13 4 .7 4 . 77 . 21 UDP 123
4: J u n 14 1 6:1 7 :12 g hive - ldap ntpd [16 7 21] : List e n no r m all y on 4 e t h 1 10 . 1 0. 0 . 57 UDP 123
5: J u n 14 1 6:1 7 :12 g hive - ldap ntpd [16 7 21] : List e n no r m all y on 5 e t h 1 fe 8 0 :: 5 6 52: ff : fe5a : f 8 9 f UDP 123
6: J u n 14 1 6:1 7 :12 g hive - ldap ntpd [16 7 21] : List e n no r m all y on 6 e t h 0 fe 8 0 :: 5 6 52: ff : fe01 :1 aee UDP 123
7: J u n 14 1 6:1 7 :12 g hive - ldap ntpd [16 7 21] : List e n no r m all y on 7 lo ::1 UDP 1 23
8: J u n 14 1 6:1 7 :12 g hive - ldap ntpd [16 7 21] : peers re fr e s hed
9: J u n 14 1 6:1 7 :12 g hive - ldap ntpd [16 7 21] : Li s t en i n g on r o uti n g soc k e t on fd #24 for in t er f a ce up dat e s
“ntpd[“
16721
“]: “ “Listen normally on “
3
“ “
eth0
“ “
134.74.77.21
“ UDP 123“
PID
Decimal Integer Model
File Descirptor
Decimal Integer Model
IP
First Match Model
IP Address Model
String 2
Fixed Data Model
Service Name
Fixed Data Model
String 1
Fixed Data Model
Message
First Match Model
Fixed Data Model
Interface Name
Variable Byte Model
(0..9a..z.)
String 3
Fixed Data Model
Port
Fixed Word List Model
Figure 3: Example of log line parsing (cf. List 1 line number 3 and Figure 2).
• SequenceModelElement: Match all the sub-
elements exactly in the given order.
• FixedWordlistDataModelElement: Match one
of the fixed strings from a list.
• VariableByteDataModelElement: Match vari-
able length data encoded within a given alphabet.
When the AMiner parses a log line, it usually ap-
plies a preamble model to parse the beginning of the
line; for example, in case of a syslog message, the
preamble corresponds to the timestamp and the host
name. Afterwards, a FirstMatchModelElement de-
cides which service the log line reports about, and
applies the corresponding parsing model. For a bet-
ter understanding of the parser, Figure 2 shows the
graph of the parser model for the log lines of an
ntpd service (see List 1). Figure 3 illustrates how
the line number 3 in List 1 is parsed. The figure
shows how the different elements of the log line are
mapped to the nodes of the graph that represents the
parser of the ntpd service. For example, at each
fork of the graph a FirstMatchModelElement is
applied to find the correct branch, before the next
part of the line can be parsed. The oval entities
mark variable segments of the log line; these have
to follow specific rules, e.g., a PID parsed by the
DecimalIntegerValueModelElement must consist
only of digits between 0 and 9. Non-oval entities
mark fixed segments of the parsed log line that must
always occur for a log line to match the same branch
of the parser model.
4.1.2 Detecting Anomalies
There are two ways for the AMiner to reveal anoma-
lies within the log messages: i) by observing devi-
ations of the log lines from the parser model, ii) by
identifying log lines which do not follow certain pre-
defined rules.
Thanks to the acquired knowledge on the nor-
mal system behavior, formalized through the corre-
sponding parser model, the most advantageous way
to reveal anomalies is to detect significant deviations
of the logged events from the normal system behav-
ior model. Usually, an information system operates
only in a contained number of system states. Those
states, which occur while the system runs normally,
i.e. when the system is not in maintenance or recov-
ery mode, define the model for the normal system be-
havior. Given that log data records occurring system
events, a log message that does not match any avail-
able path in the parser model graph is to be consid-
ered anomalous, because it represents an unexpected
system event. Thus, the AMiner considers a log line
non-anomalous only if it matches one entire path of
the parser model graph. Hence, every deviation from
the graph’s paths indicates an anomalous event. The
anomaly can be caused either by a technical failure,
by maintenance activities, or by an unused system
function that has been activated by an attack. The
AMiner white-lists all paths described by the graph
defined by the parser model, and raises an alert every
time a log line cannot be fully parsed.
Another way to detect anomalies is by defining
white-listing rules, which are formulated in order to
allow only specific system events. The AMiner ex-
tracts all paths occurring in a log line and the as-
sociated parsed values as shown in List 2. White-
listing rules can be defined by simply allowing only
specific values for a certain log line element, or spe-
cific combination of different values. For example,
in /model/services/ntpd/msg/ipv4/ip, it is pos-
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
392

Listing 2: Output of the parser shown in Figure 2 applied to
log line 3 from List 1.
Ju n 1 4 16 : 17: 1 2 ghiv e - ldap ntpd [16 7 2 1]: Liste n
nor m all y on 3 e t h 0 13 4 . 74 . 77 . 21 UDP 123
/ mod e l / sy s log / t i m e : ‘ J u n 14 1 6 : 1 7 :1 2 ’
/ mod e l / sy s log / h o s t : ‘ ghive - ldap ’
/ mod e l / se rvi c es / n t p d / sn a m e : ‘ ntpd [ ’
/ mod e l / se rvi c es / n t p d / pid : ‘1672 1 ’
/ mod e l / se rvi c es / n t p d / s1 : ‘]: ’
/ mod e l / se rvi c es / n t p d / msg / text : ‘ List e n no r m all y
on ’
/ mod e l / se rvi c es / n t p d / msg / d e sc r ipt o r : ‘3 ’
/ mod e l / se rvi c es / n t p d / msg / s2 : ‘ ’
/ mod e l / se rvi c es / n t p d / msg / if : ‘eth0 ’
/ mod e l / se rvi c es / n t p d / msg / s3 : ‘ ’
/ mod e l / se rvi c es / n t p d / msg / ipv4 / ip : ‘134 . 7 4 . 7 7 .2 1 ’
/ mod e l / se rvi c es / n t p d / msg / ipv4 / p o r t /: ‘ U D P 123 ’
sible to white-list only a certain list of IP addresses
which are allowed to occur. If a non-white-listed IP
address is detected, an alert or an alarm can be raised,
and consequently an e-mail message can automati-
cally be sent to system administrators to notify them
of the anomaly. The same concept can be applied for
a combination of values; for example to allow that
specific user names only appear together with certain
IP or MAC addresses. A rule can also be configured
as a black-listing rule, to filter out known unwanted
events, whose impact is considered dangerous. Fi-
nally, it is possible to formulate rules in a way to per-
mit a range or a list of values.
Signature based IDS normally analyze log lines
individually, however, malicious network behavior
often manifests in an sequence of multiple log lines.
Only by correlating such a sequence of events the
anomaly can become apparent. For this reason, the
AMiner can be configured to detect anomalies based
on statistics. For example, a specific event which nor-
mally occurs 5 to 7 times per hour, will trigger an
alert if it suddenly occurs 10 times in one hour. In
this case, the AMiner will detect changes in the dis-
tribution of path occurrences. For example, assuming
that the occurrence of a path follows a normal distri-
bution over a predefined time interval, a fluctuation
of the mean and of the standard deviation will indi-
cate an anomaly. This demonstrates that the AMiner
is able to detect not only anomalous single events, but
also anomalous event frequencies.
Once an anomaly is detected, the AMiner can be
configured to handle alerts and alarms. Reports can be
sent via e-mail, periodically at a specified frequency,
or every time a certain number of alerts is reached, or
immediately as soon as an alarm is triggered to timely
inform an administrator.
4.2 ÆCID Central
ÆCID Central is the intelligent component of ÆCID.
It includes the parser generator, the rule generator,
and a correlation engine, which allows to correlate
events observed by different AMiner instances. The
AMiner Interface enables the exchange of data be-
tween ÆCID Central and the different AMiner in-
stances deployed in the network, while a Control In-
terface allows administrators to configure the whole
system as well as to visualize analysis results.
4.2.1 Control Interface
The control interface allows system administrators to
communicate with ÆCID Central and, through the
AMiner Interface, to orchestrate the different AMiner
instances deployed in the network. This means that
the administrator can change the settings of every
AMiner instance, including the parser model they
adopt, the set of rules that they check, as well as the
data sources that they parse (i.e., their input data).
Furthermore, ÆCID Central is equipped with a graph-
ical interface visualizing analytical statistics (includ-
ing for example the number of occurrences of a cer-
tain type of log line), along with information on de-
tected anomalies and triggered alerts and alarms.
4.2.2 Parser Model Generator
The parser model generation is one of the self-
learning functions provided by ÆCID. Via the con-
trol interface the system administrator can activate the
parser model generator separately for each AMiner
instance controlled by ÆCID Central. This is done
when a new AMiner instance is deployed, new hard-
ware or software components are added to the net-
work, or a high number of false alerts occur, caused
by deviations from the current parser model.
When the parser model generator is activated the
respective AMiner instance reports every unparsed
line to ÆCID Central. The lines are then analyzed to
derive a new parser model, or to adapt an existing one.
First, the parser model generator collects a certain
number of lines; afterwards, it applies either a word-
based clustering, similar to SLCT (Vaarandi, 2003),
or a character-based clustering, similar to (Wurzen-
berger et al., 2017), to group the log lines and detect
static and variable parts of the log lines. Based on
the obtained alignments that describe the derived log
line clusters, and considering the information about
the log line segments occurring as variable parts, the
graph describing the log line model can be built. Once
the parser reaches a certain stability level, i.e. when
the process is repeated for a new set of obtained log
AECID: A Self-learning Anomaly Detection Approach based on Light-weight Log Parser Models
393

1
Client Firewall Web Server Database Server
2 3
4
56
Figure 4: The figure shows the log-in process to an online shop: (1) the client tries to log into an online shop on a web server,
(2) a connection through the firewall occurs, (3) the Web server checks credentials through a database query, (4) the database
query returns some result, (5) a response through the firewall: access acceptance or denial, (6) client receives the response.
lines, and the parser does not need to be adapted any-
more, ÆCID Central terminates the parser model gen-
eration process. Finally, the generated parser is for-
warded to the respective AMiner instance, and the
AMiner starts filtering out unknown log lines and gen-
erating alerts.
The parser model generator is also invoked to
adapt an existing log line model. New paths can be
added to the graph describing a parser model, lists
such as FixedWordlistDataModelElements
can be adapted, or alphabets such as
VariableByteDataModelElements can be up-
dated.
4.2.3 Rule Generator
Another self-learning function provided by ÆCID is
the rule generation. Similarly to the parser model
generator, the rule generator can be activated for a
specific AMiner instance via the control interface.
Once enabled, the selected AMiner instance will for-
ward the parsed lines to the rule generator running on
ÆCID Central. Based on the parsed values the rule
generator creates candidates for rules. It defines lists
or intervals of values that are allowed to occur in a
specific path, or it defines rules enforcing that values
of different paths are only allowed to occur in spe-
cific combinations, e.g., specific usernames are only
allowed to occur in combination with specific IP or
MAC addresses.
Once the rule generator defines a rule candidate,
the candidate has to be verified. One way to accom-
plish this is to run a binomial test as shown in (Fried-
berg et al., 2015), to evaluate if a tested rule candidate
is stable or not. Once a rule candidate is verified and
therefore considered stable, the rule generator pushes
it to the AMiner, which includes it into its rule set.
4.2.4 Correlation Engine
The correlation engine implemented in ÆCID Central
allows to detect network-wide anomalies by correlat-
ing events observed by different AMiner instances.
This makes it possible to detect deviations within
complex processes that involve different services, and
therefore produce log messages on components mon-
itored by different AMiner instances. Consider the
example depicted in Fig. 4; it shows the normal ac-
cess chain of the log-in procedure to a Web-shop.
If a user logs into the Web-shop, certain log lines
will be produced in a specific order by the firewall,
the Web-server, the database server and the Web-
server again, including specific values for the paths
of the parser. ÆCID is able to identify such event se-
quences, and to generate corresponding models. This
allows ÆCID to automatically derive relevant corre-
lation rules and verify through them if the system
behavior is aligned with the generated model. All
AMiner instances monitoring the services involved in
the process will, in fact, forward to ÆCID Central
the log events for which the correlation rule is being
evaluated (even if they are not individually considered
anomalous). ÆCID Central will then analyze the se-
quence of events collected from the different AMiner
instances and verify their alignment to the model. If
the illustrative access chain mentioned above is vio-
lated, because the database is accessed without a pre-
vious access to the Web-server (this could be due to an
SQL-Injection), ÆCID Central will identify an incon-
sistency and therefore trigger an alarm. This is an ex-
ample that demonstrate how ÆCID does not only de-
tect anomalies that manifest in deviations of the nor-
mal system behavior of a single device, but also com-
plex anomalies that can only be detected when analyz-
ing events occurring in diverse nodes of the network.
It is important to notice that the correlation rules can
also be applied to a single AMiner instance to analyze
complex processes running on one single node.
5 SYSTEM DEPLOYMENT AND
OPERATION
This section illustrates the different topologies in
which ÆCID can be deployed within a network, and
presents the phases of its operational work-flow.
The simplest way to deploy ÆCID is by employ-
ing only one AMiner instance installed on a single
node. This setup allows to exclusively monitor events
produced and logged by that single component. Al-
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
394
ÆCID CENTRAL
AMiner Instance #1
Updates
(Parser Models
Rule Set
)
Unparsed Log
lines
+
Report
Alerts & Alarms
ÆCID CENTRAL
AMiner Instance #1
Parser Models
+
Rule Set
Unparsed Log
lines
ÆCID CENTRAL
AMiner Instance #1
Unparsed Log
lines
Step 1 Step 2
Step 3
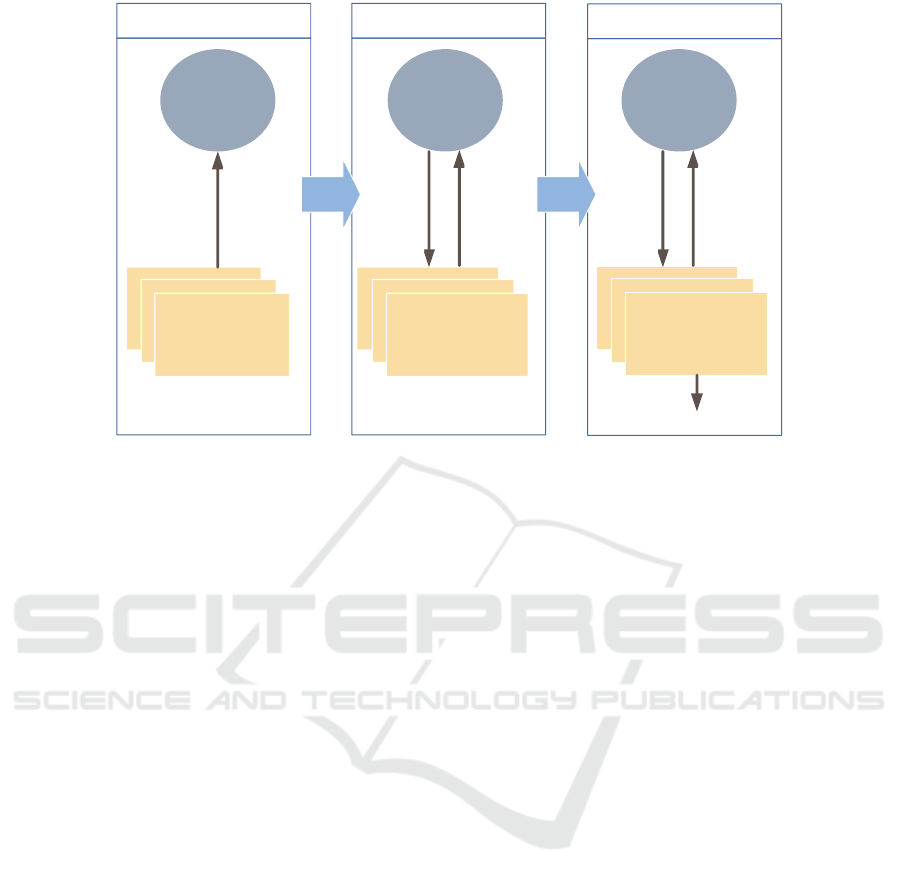
Figure 5: ÆCID Initialization Process.
ternatively, if a log collection mechanism is in place
on the node, which acquires log messages from other
remote nodes in the network (
`
a la Syslog server), the
AMiner can work in a centralized fashion, and an-
alyze events occurring on distributed systems. The
drawback of this configuration is that the parser mod-
els, as well as the set of rules utilized by the AMiner
for the detection of anomalies, are statically defined
and need to be manually configured. The lack of
an intelligent component (ÆCID central) implies, in
fact, that the administrators have to: i) define the
parser model describing the structure of the events
being logged by the monitored node, and ii) have a
thorough understanding of every event (occurring on
every monitored node) that is to be consider legiti-
mate, and instantiate a corresponding set of withe-
listing rules. This solution is applicable in case of
small-scale systems, whose computational power is
not sufficient to run ÆCID central, which perform
highly recurrent operations, and are therefore simple
to characterize manually.
If the infrastructure to be monitored comprises
a large number of distributed nodes, with little re-
sources and small computational power at their dis-
posal, ÆCID can be deployed following a star topol-
ogy. In this setup, an AMiner instance is installed on
every distributed node, while a more powerful node
hosts ÆCID Central. Every AMiner is connected to
ÆCID Central and exchanges with it information re-
garding parsed lines and discovered anomalies.
Figure 5 illustrates the three stages required to
initialize the ÆCID system when deployed in this
topology. When the AMiner instances are installed
for the first time on the nodes, they are not able to
parse any of the log lines generated on the node, be-
cause no parser model is defined yet; thus, they for-
ward every unparsed line to ÆCID Central, which
learns the structure of the log messages received from
each node and automatically builds a dedicated parser
model for each service generating logs on each node.
Along with the parser models, ÆCID Central builds
the behavioral model of the services running on ev-
ery connected node, and generates a corresponding
set of white-listing rules per node, which describe the
model, i.e., the normal behavior.
In the second step, ÆCID Central forwards the
derived parser models and rule-sets to the respective
AMiner instances; now the AMiner instances can fol-
low the received parser models, analyze the incom-
ing log messages and identify any suspicious event
by checking the adherence to the obtained rules.
The third step represents the fully operational sys-
tem; the AMiner instances continue sending any un-
parsed log line to ÆCID Central for further inspec-
tion, and receive from ÆCID Central updates on the
enabled parser models and set of rules. If correlation
rules are defined, ÆCID Central (through its corre-
lation engine) analyzes the relevant log messages in-
teracting with the involved AMiner instances, as de-
scribed in the previous section.
Whenever an anomaly is revealed, the AMiner in-
stance generates a notification report and, if neces-
sary, sends it by email to a pre-configured list of re-
cipients. Alerts and alarms are also reported to ÆCID
Central, where they can be aggregated and visualized.
Finally, in case sufficient resources and computa-
AECID: A Self-learning Anomaly Detection Approach based on Light-weight Log Parser Models
395

tional power are available on a single node, ÆCID
can be deployed in its full-fledged setup on a stand-
alone machine. In this scenario, ÆCID Central and
the AMiner instance operate on the same node. The
advantage of this topology, compared to the first one,
lies in the fact that the administrators do not need to
manually determine the parser models nor to define
the set of rules, because ÆCID Central automatically
generates them following the three-step approach de-
scribed above and depicted in Figure 5.
6 APPLICATION SCENARIOS
The multi-layer light-weight detection approach pre-
sented in this paper introduces a number of benefits
that make its adoption attractive for a series of appli-
cation scenarios. This section explores some of the
most promising use cases, in which the employment
of ÆCID, stand-alone or in conjunction with other se-
curity solutions, would be highly advantageous.
As extensively illustrated in the previous sections,
ÆCID can be adopted to analyze events logged by
systems running on different layers of the OSI model.
If applied on network traffic information, ÆCID can
identify and keep track of the communications estab-
lished between different systems in the network, and
perform a network interaction graph analysis. Ob-
serving which network nodes interact with each-other
at which frequency, would allow ÆCID to build a
“communication-behavior” model, and to promptly
identify any divergence from such a model, which
could indicate internal or external malicious attempts
to access network systems.
Similarly, ÆCID could be employed to analyze
events recorded on the application layer, particularly
when users authenticate on the numerous services de-
ployed in an enterprise network. Authentication inter-
action graph analysis can be performed using ÆCID,
to monitor which users authenticate on which services
with which frequency. The “authentication-behavior”
model established by ÆCID in this scenario would
allow to reveal any unusual authentication attempt,
pinpointing potential intrusions, illegitimate access to
critical resources, or erroneous authentication.
Moreover, ÆCID could serve as additional secu-
rity layer, besides signature-based and other black-
listing solutions, such as firewalls. In this setup
ÆCID would improve the overall detection capabil-
ity by allowing the identification of previously un-
known threats, and the verification of suspicious trig-
gered alerts. The false positive rate (FPR) as well as
the number of false negatives (FN) would decrease
effectively and a higher level of security would be
achieved. The alarms triggered by ÆCID could then
be fed into a Security Information and Event Man-
agement (SIEM) system, which would correlate them
with the events generated by other sensors.
A further promising application area is CPS. CPS
of the future will be the backbone of Industry 4.0, and
will operate following a self-adaptation paradigm,
which foresees that the components of a system are
capable of configuring, protecting and healing them-
selves when certain internal and/or external condi-
tions demand to (Musil et al., 2017). The process of
self-adaptation follows four principal phases: moni-
tor, analysis, plan, execute. Critical events, observed
in the systems (in the monitor phase) and opportunely
examined (in the analysis phase), would trigger spe-
cific changes in the system configuration (through the
execute phase), which would follow suitable adapta-
tion policies (evaluated in the plan phase). In the con-
text of ICT security this approach could allow CPS
being targeted by security threats to timely identify
the indicators of an attack and swiftly react to contain
its effects, reducing its impact. In this scenario, em-
ploying ÆCID in the monitoring and analysis phase,
would be an asset. Thanks to their light-weight na-
ture, AMiner instances could be installed on numer-
ous low-power components deployed across the CPS,
which would not be able to run any traditional IDS.
By recording system events they would allow to have
an accurate and comprehensive overview of the se-
curity situation of the entire CPS in real-time. The
anomalies identified by ÆCID Central would then be
evaluated and, in line with predefined security poli-
cies, trigger configuration changes in the monitored
CPS, that would contain the effect of the detected
threat.
Finally, the system behavior model built by ÆCID
Central, makes it possible for ÆCID to identify criti-
cal security events previously unseen, which may po-
tentially indicate the occurrence of a zero-day attack.
Integrating ÆCID with a threat intelligence (TI) man-
agement system would allow security operation cen-
ters to greatly improve their incident handling capa-
bility. Indicators of compromise (IoC), obtained by
inspecting the anomalies revealed by ÆCID, could in
fact be combined and correlated with the intelligence
gathered from multiple data sources by TI manage-
ment solutions (such as the tool proposed in (Settanni
et al., 2017)). This correlation is fundamental to in-
terpret the IoCs, confirm the occurrence of an attack,
and identify possible mitigation strategies. Addition-
ally, this integrated framework would allow to dynam-
ically reconfigure any deployed monitoring system in
order to center their focus towards those critical as-
sets vulnerable to the discovered threat. Eventually,
ICISSP 2018 - 4th International Conference on Information Systems Security and Privacy
396

this solution would also support the definition of at-
tack signatures, which would be used to update any
black-listing security solutions deployed in the infras-
tructure, and guarantee a higher level of protection.
7 CONCLUSION AND OUTLOOK
New light-weight forms of IDS, capable of auto-
matically comprehending and dynamically adapt to
the behavior of large-scale distributed systems, are
a promising means to tackle today’s advanced secu-
rity threats. In this paper, we discussed the design
principles a modern anomaly detection system should
follow to be effective. Furthermore, we introduced
the ÆCID approach, a light-weight detection mech-
anism based on self-learning log parser models. We
presented ÆCID’s system architecture, and we out-
lined the advantages this approach provides in terms
of detection effectiveness, deployment flexibility, and
applicability. Several use case scenarios demonstrate
how ÆCID would greatly improve the security pos-
ture of modern organization, allowing them to achieve
a higher degree of protection against advanced cyber
threats.
Parts of ÆCID are open source and are already
included in Debian Linux and Ubuntu; future work
includes the implementation of the system in opera-
tional controlled environment, its validation in differ-
ent complex application scenarios, and the evaluation
of its performance on large-scale distributed systems.
ACKNOWLEDGEMENTS
This work was partly funded by the FFG project syn-
ERGY (855457), European research project SemI40
(ECSEL joint undertaking nr. 692466) and carried
out in course of a PhD thesis at the Vienna Univer-
sity of Technology funded by the FFG project BAESE
(852301).
REFERENCES
Atzori, L., Iera, A., and Morabito, G. (2010). The internet
of things: A survey. Computer networks, 54(15).
Friedberg, I., Skopik, F., Settanni, G., and Fiedler, R.
(2015). Combating advanced persistent threats: From
network event correlation to incident detection. Com-
puters & Security, 48:35–57.
Garc
´
ıa-Teodoro, P., D
´
ıaz-Verdejo, J., Maci
´
a-Fern
´
andez, G.,
and V
´
azquez, E. (2009). Anomaly-based network
intrusion detection: Techniques, systems and chal-
lenges. Computers & Security, 28(1-2):18–28.
Goldstein, M. and Uchida, S. (2016). A Comparative Evalu-
ation of Unsupervised Anomaly Detection Algorithms
for Multivariate Data. PloS one, 11(4):e0152173.
James P. Anderson (1980). Computer security threat moni-
toring and surveillance. Technical Report 17, James P.
Anderson Company, Fort Washington, Pennsylvania.
Liao, H.-J., Richard Lin, C.-H., Lin, Y.-C., and Tung, K.-Y.
(2013). Intrusion detection system: A comprehensive
review. Journal of Network and Computer Applica-
tions, 36(1):16–24.
Mitchell, R. and Chen, I.-R. (2014). A survey of intrusion
detection techniques for cyber-physical systems. ACM
Computing Surveys (CSUR), 46(4):55.
Musil, A., Musil, J., Weyns, D., Bures, T., Muccini, H.,
and Sharaf, M. (2017). Patterns for self-adaptation
in cyber-physical systems. In Multi-Disciplinary
Engineering for Cyber-Physical Production Systems,
pages 331–368. Springer.
Sabahi, F. and Movaghar, A. (2008). Intrusion Detection:
A Survey. pages 23–26. IEEE.
Scarfone, K. and Mell, P. (2007). Guide to intrusion de-
tection and prevention systems (idps). NIST special
publication, 800(2007):94.
Settanni, G., Shovgenya, Y., Skopik, F., Graf, R., Wurzen-
berger, M., and Fiedler, R. (2017). Acquiring cyber
threat intelligence through security information corre-
lation. In Cybernetics (CYBCONF), 2017 3rd IEEE
International Conference on, pages 1–7. IEEE.
Symantec (2016). ISTR Internet Security Threat Report.
Technical Report 21, Symantec Corporation.
Vaarandi, R. (2003). A data clustering algorithm for mining
patterns from event logs. In IP Operations & Man-
agement, 2003.(IPOM 2003). 3rd IEEE Workshop on,
pages 119–126. IEEE.
Vacca, J. R. (2013). Managing information security. Else-
vier.
Verizon (2016). 2016 Data Breach Investigations Report.
Technical report, Verizon.
Whitman, M. E. and Mattord, H. J. (2012). Principles of
information security. Course Technology, Cengage
Learning, Stamford, Conn., 4. ed., international ed
edition. OCLC: 930764051.
Wurzenberger, M., Skopik, F., Landauer, M., Greitbauer, P.,
Fiedler, R., and Kastner, W. (2017). Incremental clus-
tering for semi-supervised anomaly detection applied
on log data. In Proceedings of the 12th International
Conference on Availability, Reliability and Security,
page 31. ACM.
AECID: A Self-learning Anomaly Detection Approach based on Light-weight Log Parser Models
397
