
Improved Greedy Nonrandomness Detectors for Stream Ciphers
Linus Karlsson, Martin Hell and Paul Stankovski
Department of Electrical and Information Technology, Lund University, P.O. Box 118, 221 00, Lund, Sweden
{linus.karlsson, martin.hell, paul.stankovski}@eit.lth.se
Keywords:
Maximum Degree Monomial, Distinguisher, Nonrandomness Detector, Grain-128a, Grain-128.
Abstract:
We consider the problem of designing distinguishers and nonrandomness detectors for stream ciphers using
the maximum degree monomial test. We construct an improved algorithm to determine the subset of key and
IV-bits used in the test. The algorithm is generic, and can be applied to any stream cipher. In addition to this,
the algorithm is highly tweakable, and can be adapted depending on the desired computational complexity.
We test the algorithm on the stream ciphers Grain-128a and Grain-128, and achieve significantly better results
compared to an earlier greedy approach.
1 INTRODUCTION
Modern stream ciphers take as input a secret key and
a public IV. These values are typically loaded into the
state as part of the initialization. Before generating
keystream, the key and IV are mixed such that each
state bit depends on a large number of key and IV
bits. This is accomplished using a set of initialization
rounds. During the initialization, the cipher does not
produce any output. These initialization rounds are
used to prevent attacks in which an attacker can use
knowledge of the IV in order to deduce information
about the keystream.
When designing a stream cipher, care must be
taken when choosing the number of initialization
rounds. Too many, and the cipher will have poor ini-
tialization performance, too few and an attacker may
be able to perform an attack, e.g., a chosen-IV attack.
A part of the field of cryptanalysis concerns the
construction of distinguishers and nonrandomness de-
tectors. The goal of both devices is to determine if the
input comes from a cipher, or is just random data. For
a good cipher, such a device should not be possible to
construct, since the output from a cipher should ap-
pear random.
The difference between distinguishers and non-
randomness detectors is the amount of control the at-
tacker has. In a distinguisher, the key is fixed and un-
known to the attacker, thus only the IV bits are avail-
able to modify. In a nonrandomness detector, both
key and IV bits are modifiable by the attacker.
Previous work such as (Englund et al., 2007) has
considered the design of distinguishers and nonran-
domness detectors by using a test called the Maxi-
mum Degree Monomial (MDM) test. This test looks
at statistical properties of a cipher, and tries to find
weaknesses.
The MDM test requires choosing a suitable sub-
set of the cipher’s IV bits. The choice of this subset
is crucial, and a greedy algorithm for finding a good
subset was proposed in (Stankovski, 2010).
We build upon the previous work and propose
an improved, generalized, algorithm which outper-
forms the greedy algorithm in finding suitable sub-
sets. We also implement and test our algorithm and
present new results on the stream ciphers Grain-128
and Grain-128a.
The paper is organized as follows. Section 2
presents the necessary background, while Section 3
describes our improved algorithm. In Section 4 the
results are presented, followed by a discussion of re-
lated work in Section 5. Section 6 concludes the pa-
per.
2 BACKGROUND
The maximum degree monomial test was presented
in (Englund et al., 2007) and described a clean way to
detect nonrandomness by looking at the cipher output.
Considering an arbitrary stream cipher, we can
consider it as a black box with two inputs, and one
output. The input is the key K and the initialization
vector (IV) V respectively. We consider the concate-
nation of the key K and the IV V as a boolean space
B of dimension b = |K| + |V |.
We are interested in finding out whether or not the
Karlsson, L., Hell, M. and Stankovski, P.
Improved Greedy Nonrandomness Detectors for Stream Ciphers.
DOI: 10.5220/0006268202250232
In Proceedings of the 3rd International Conference on Information Systems Security and Privacy (ICISSP 2017), pages 225-232
ISBN: 978-989-758-209-7
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
225

maximum degree monomial exists in the ANF of the
boolean function of the first keystream bit. According
to the Reed-Muller transform, the coefficient of the
maximum degree monomial can be found simply by
XORing all the entries in the truth table of a boolean
function as
M
x∈{0,1}
b
z
0
(x)
where z
0
(x) is the first output bit of the stream cipher
initialized with the values in x. Thus we generate all
possible values for the input set, and for each value
perform an initialization of the cipher to get the first
keystream bit.
An interesting use case for this test is in analyz-
ing the required amount of initialization rounds of a
stream cipher. Typically, a stream cipher designer has
to choose a suitable count of these rounds: too few,
and we may have attacks on the cipher, too many, and
the performance hit will be large.
The idea above can be extended such that we
consider a modified version of the cipher, where we
also look at the cipher output during its initialization
rounds (normally this output is suppressed). Assum-
ing a cipher with l initialization rounds, we denote the
ith initialization round output function as f
i
(x), thus
giving us a vector
f
1
(x), f
2
(x), . . . , f
l
(x).
Thus, instead of only looking at the ANF and find-
ing the maximum degree of a single function (z
0
be-
fore), we now look at l different boolean functions,
and for each of the functions, we find the coefficient
of the maximum degree monomial. We call this se-
quence of coefficients the maximum degree monomial
signature, or MDM signature, following the terminol-
ogy in (Stankovski, 2010).
The keystream produced by an ideal stream cipher
should be indistinguishable from a random stream of
bits to an observer. This means that if we look at each
output bit function f
i
(x), it should appear to be a ran-
dom function f
i
: B → {0, 1}. Consequentially, for
a random function, we expect the maximum degree
monomial to exist with probability
1
2
. Therefore, we
expect the coefficients 0 and 1 to appear with equal
probability, and we expect to see a random-looking
MDM signature for an ideal cipher.
However, if the input space B is large, clearly the
construction of a MDM signature will result in too
many initialization of the cipher to be practically us-
able. Therefore, we can only consider a subset S of
the input space B. The remaining part, B \ S, is set
to some constant value, typically either all zero or all
one.
2.1 Finding the Subset S
Choosing different subsets S will give different MDM
signatures. For example, looking at the stream cipher
Grain-128a (Ågren et al., 2011) and the subset S con-
sisting of key bit 23, and IV bits 47, 53, 58, 64, we
get the following MDM signature:
000. . . 000
| {z }
187 zeros
111. . .
Clearly, the start of this MDM signature, with its
187 consequent zeros, does not appear to be random.
However, after the initial 187 zeros, the sequence start
to appear more random-like. We can interpret the re-
sult above as that it is not enough with 187 initializa-
tion rounds. However, Grain-128a has 256 rounds in
total, and thus we state that we find nonrandomness
in 187 out of 256 initialization rounds. We note that
we get a nonrandomness result, since we include both
key and IV bit in the input subset S.
It should now be clear that we wish to maximize
the number of zeros we can find, with the ultimate
goal being to find a nonrandomness in all initializa-
tion rounds, thus spilling over to the actual keystream
of an unmodified cipher.
The subset S plays a crucial role here. Its composi-
tion affects the resulting MDM signature to a great ex-
tent. Consider the two examples for Grain-128a found
in Table 1.
Table 1: The number of initial zeros in the MDM signature
for two different subsets S for Grain-128a.
K IV rounds out of 256
{} {1, 2, 3, 4, 5} 107
{23} {47, 53, 58, 64} 187
As we see, the choice of the input set S is signif-
icant. In the above case, where |S| = 5, i.e. we have
chosen five key and/or IV bits, the second row is actu-
ally the optimal result. However, calculating the opti-
mal result is infeasible as S grows to a larger set. For
Grain-128a, which has 96 IV bits and 128 key bits,
we will have to test
224
|S|
combinations.
2.2 Greedy Approach
In (Stankovski, 2010) the author proposed a greedy
algorithm to find such a subset. The suggested ap-
proach can concisely be described with the following
steps:
1. Find an optimal starting bitset of a small size (pos-
sibly also zero, making this step optional)
ICISSP 2017 - 3rd International Conference on Information Systems Security and Privacy
226

2 , 16
8 , 43
32 , 69
.
.
.
. . . k
i−1
α
i−1
2 , 16 , 86
2 , 16 , 55
.
.
.
k
i
n
i
8 , 43 , 54
8 , 43 , 27
.
.
.
k
i
n
i
32 , 69 , 5
32 , 69 , 8
.
.
.
k
i
n
i
8 , 43 , 54
2 , 16 , 86
8 , 43 , 27
.
.
.
. . . k
i−1
α
i−1
k
i
α
i
merge, sort, reduce
Figure 1: One step of our improved algorithm.
2. Add the n bits which together produce the highest
number of zero rounds to the current bitset.
3. Repeat step 2 until a bitset of the wanted size m is
found.
Consider an example where we start with the opti-
mal bitset described earlier. A few steps of the greedy
algorithm, with n = 1, would then look like this:
i
0
: K = {23} IV = {47, 53, 58, 64}
i
1
: K = {23} IV = {47, 53, 58, 64, 12}
i
2
: K = {23, 72} IV = {47, 53, 58, 64, 12}
i
3
: K = {23, 72, 31} IV = {47, 53, 58, 64, 12}
i
4
: K = {23, 72, 31, 107} IV = {47, 53, 58, 64, 12}
As we can see, the algorithm will, for each itera-
tion, add the best bit, i.e. the one that gives the largest
amount of zeros in the MDM signature.
The issue with this greedy algorithm is the same
as for greedy algorithms in general—they may fail to
find the global optimum, and instead get stuck in local
optima.
3 IMPROVED ALGORITHM
We build upon the greedy algorithm presented in Sec-
tion 2.2, but instead present a more general solution
which can achieve better results.
One efficiency problem with a purely greedy al-
gorithm is the risk that it gets stuck in a local opti-
mum. This optimum may or may not be close to the
global optimum. Our core idea is to extend the naïve
greedy algorithm by examining more possible paths.
Instead of only looking at the single best candidate in
each step, we store and explore several different can-
didates. The idea is that the second best candidate in
one step may very well be the better one at the next
stage of the algorithm.
Examining more possible bit sets will, of course,
increase the computational complexity of the algo-
rithm. However, the computational complexity can
be calculated, and we can derive an expression for the
total computational complexity, which can be used to
estimate the time required.
Our algorithm is described in Algorithm 1 and Al-
gorithm 2. The algorithm is parametrized by three
different parameter vectors: α, k, and n. A graphical
presentation of one iteration of the algorithm is given
in Figure 1, which serve as the basis for the descrip-
tion of the algorithm below:
1. Consider a set of candidates from a previous iter-
ation, or from an optimal starting set.
2. For each candidate in the list, we add the k
i
best
n
i
new bits and store them in a new list. Note that
we now have one such new list for each candidate
in the original list.
3. Merge all lists, sorting by the number of zero
rounds. This gives a list of .. . k
i−1
α
i−1
k
i
items.
4. Finally, reduce the size of this list with the factor
α
i
(0 < α
i
≤ 1.0), limiting the size of the com-
bined list to . . . k
i−1
α
i−1
k
i
α
i
items.
5. Repeat from step 1 until a bitset of the wanted size
has been found.
We note that the previous greedy algorithm from
Section 2.2 corresponds to specific values of these
parameter vectors, namely α = [1.0, 1.0, . . .]), k =
Improved Greedy Nonrandomness Detectors for Stream Ciphers
227

[1, 1, . . .], and n = [n, n, . . .]. Thus our improved al-
gorithm is a generalization of the previous algorithm.
Algorithm 1: SlightlyGreedy.
Input: key K, IV V, bit space B, maximum bit-
set size m, vector k, vector n, vector α
Output: bitset S of size m.
S
0
= {
/
0}
/* The set S
0
contains a single empty bitset */
for (each i ∈ {0, . . . , m − 1}) {
for (each c ∈ S
i
) {
L
c
= FindBest(K,V, B, c, k
i
, n
i
);
}
S
i+1
= concatenate(all L
c
from above);
sort S
i+1
;
reduce # of elements in S
i+1
by a factor α
i
;
}
return S
m
;
Algorithm 2: FindBest.
Input: key K, IV V , bit space B, current bitset
c, number of best bitsets to retain k, bits to add n
Output: k bitsets each of size |c| + n.
/* let
S
k
denote the set of all k-combinations of
a set S. */
S =
/
0;
for (each n-tuple {b
1
, . . . , b
n
} ∈
B\c
n
) {
z = number of initial zeros using bit set
c ∪ {b
1
, . . . , b
n
};
if (z is among the k highest values) {
add c ∪ {b
1
, . . . , b
n
} to S;
reduce S to k elements by removing
element with lowest z;
}
}
return S;
3.1 Computational Cost
The computational cost C depends on the input pa-
rameter vectors according to the following function,
where c is the number of iterations required (c = |k| =
|n| = |α|), b is the bit space size b = |B|.
C(b, c, k, n, α) =
c−1
∑
i=0
"
2
∑
i
j=0
n
j
b −
∑
i−1
j=0
n
j
n
i
i−1
∏
j=0
k
j
α
j
#
(1)
The formula can be derived using combinatorics.
In the formula, the power of two is related to the
size of the bitset—a large bitset requires more cal-
culations. The binomial coefficient is the number of
possible bitsets we can form given the current itera-
tion’s n
i
. Finally, the final product is needed because
we reduce the number of candidates in each iteration
using the factors in α. Clearly, in practice, the actual
running time is also dependent on other factors, such
as the cipher we are running the algorithm on.
Note that for the naïve greedy algorithm, where
we have a constant n, and k and α are both all ones,
we get the following simplified expression for the
complexity:
C(b, c, n) =
c−1
∑
i=0
2
n(i+1)
b − n · i
n
(2)
4 RESULTS
Finding the correct vectors k, n, and α is crucial to
achieving good performance of our algorithm. While
the original greedy approach only had one degree of
freedom (the constant n), our generalized algorithm
has many more. We have performed a significant
amount of simulations to present results on how the
choice of parameters affect the final result. The tests
have been performed mainly on the cipher Grain-
128a, but also on Grain-128 (Hell et al., 2006). The
exact parameters used for each result presented below
are available in the Appendix.
4.1 Tuning the Greediness
We start by varying k and α. We keep an identical
amount of candidates in each iteration, but vary k and
α. Recall that k
i
govern how many new candidates
we generate from a previous iteration’s bitset. A high
k
i
and low α
i
means that we may end up with several
candidates that have the same “stem”, i.e. they have
the same origin list. If we lower k
i
and instead in-
crease α
i
we will get a greater mix of different stems,
while still maintaining the same amount of candidates
for the iteration—in a sense we lower the greediness
of the algorithm. Thus, we want to test some different
tradeoffs between the two parameters. In the results
below, we name the different test cases as a percent-
age value of the total amount of candidates for each
round. As an example, if the total number of candi-
dates in a given round is 1000, we could select a k
i
of 200, and a corresponding α
i
of 0.005, which gives
us 1000 candidates for the next round as well. We
call this particular case 20 %-k since k
i
is 20 % of the
candidates for the round.
ICISSP 2017 - 3rd International Conference on Information Systems Security and Privacy
228

We have tried several combinations of k and α
as can be seen in the plot in Figure 2. We also in-
clude the greedy algorithm as a reference. Note that
the greedy algorithm will due to its simplistic nature
have a lower computational complexity since it only
keeps one candidate in each iteration. To be able to
compare the results based on computational complex-
ity, we have plotted the graph based on logarithmic
complexity rather than bit set size. The complexity
is calculated using Equation 1, and we then take the
(natural) logarithm of the this value, so that we can
produce a reasonably scaled plot. This graph can be
seen in Figure 3. The maximum rounds for each case
is also available in Table 2.
From the results we note that a too low k seems to
lower the efficiency of the algorithm. The reason for
this is probably that the too low k forces the algorithm
to choose candidates from lists with lower amounts
of rounds, which are then not useful in the following
iterations.
Table 2: Results when varying k and α.
Test case Maximum rounds
Greedy 187
20 %-k 203
0.5 %-k 198
0.2 %-k 192
min-k %-k 190
4.2 Varying the Number of Bits Added
in Each Iteration
We have also tried modifying n in a number of differ-
ent combinations. The rationale behind this is that we
expect that a higher n will yield better results, since
that also reduces the risk to get stuck in a local op-
tima. However, having a large, constant, n throughout
all iteration as in (Stankovski, 2010) means that the
later iterations will be very computationally demand-
ing. Therefore, we test three different variants where
the n-vector contains decreasing values of n
i
. As a
base line, we present the naive greedy approach with
a constant n of 1, 2, and 3 respectively.
We note that the computational complexity will
vary significantly depending on the choice of the vec-
tor n. We first plot the graph with the x-axis as the bit
set size, as can be seen i Figure 4. We can also look at
the graph plotted with the computational complexity,
calculated as in Equation 1. This allows us to com-
pare the results achieved for a specific computational
complexity. This is done in Figure 5. The maximum
rounds for each case are also available in Table 3.
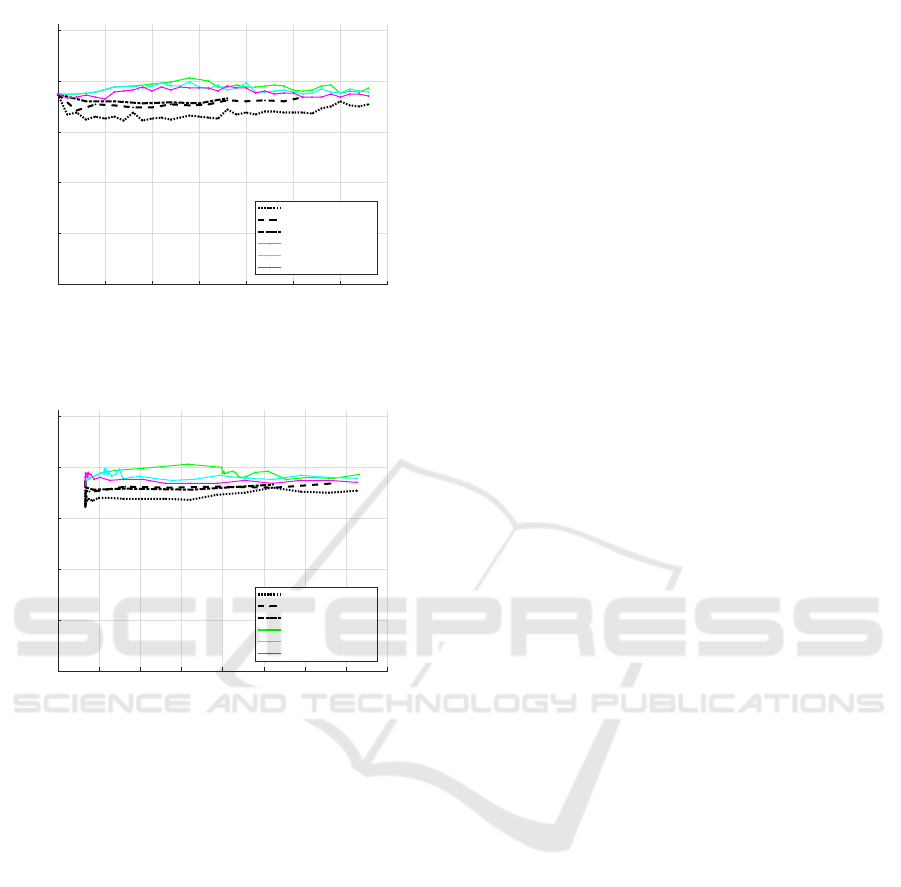
5 10 15 20 25 30 35 40
bit set size
0
50
100
150
200
250
rounds
Start with optimal bit set of size 5, then 1-bit add, different k
greedy
improved (20%-k)
0.5%-k
0.2%-k
min-k
Figure 2: Varying k and α, with n
i
= 1. Thick dotted black
line is the greedy baseline.
25 26 27 28 29 30 31 32 33
log(complexity)
0
50
100
150
200
250
rounds
Start with optimal bit set of size 5, then 1-bit add, different k
greedy
improved (20%-k)
0.5%-k
0.2%-k
min-k
Figure 3: Varying k and α, with n
i
= 1. Thick dotted black
line is the greedy baseline. The x-axis scaled according to
logarithmic computational complexity.
From the results we note that regardless of our
choice of n, our algorithm outperforms the greedy
variants. We also see that a higher n
i
in the initial
iterations seem to lead to better results which remain
as the algorithm proceeds towards larger bitsets.
Table 3: Results when varying n.
Test case Maximum rounds
Greedy 1-bit 187
Greedy 2-bit 187
Greedy 3-bit 187
2-2-2-2-2-2-2-2-1-. . . 203
2-2-2-2-1-. . . 199
1-. . . 195
Improved Greedy Nonrandomness Detectors for Stream Ciphers
229
5 10 15 20 25 30 35 40
bit set size
0
50
100
150
200
250
rounds
Start with optimal bit set of size 5, different n
greedy 1-add
greedy 2-add
greedy 3-add
2-2-2-2-2-2-2-2-1-...
2-2-2-2-1-...
1-...
Figure 4: Varying n. Thick black lines are the greedy base-
lines for n equal to 1, 2, and 3.
25 26 27 28 29 30 31 32 33
log(complexity)
0
50
100
150
200
250
rounds
Start with optimal bit set of size 5, different n
greedy 1-add
greedy 2-add
greedy 3-add
2-2-2-2-2-2-2-2-1-...
2-2-2-2-1-...
1-...
Figure 5: Varying n. Thick black lines are the greedy base-
lines for n equal to 1, 2, and 3. The x-axis scaled according
to logarithmic computational complexity.
4.3 Results on Grain-128
In addition to the results above on Grain-128a,
we also tested our algorithm on Grain-128. In
(Stankovski, 2010), a full-round (256 out of 256 ini-
tialization rounds) result was presented using a bit-set
of size 40, using only IV-bits, with an optimal starting
bitset of size 6. This was found using a constant n = 2.
In our generalized algorithm, this corresponds to a pa-
rameter set of α = [1.0, 1.0, 1.0, . . .]), k = [1, 1, 1, . . .],
and n = [6, 2, 2, . . .].
We construct a new set of parameters utilizing our
improved algorithm. We utilize the possibility to keep
multiple candidates in each step, especially in the be-
ginning where we still have small bitsets. We find a
smaller bitset, of size 25, which still gives us a full-
round result of 256 out of 256 initialization rounds.
Using the complexity formula in Equation 1, we can
compare the computational complexity between the
two results, and find that our improved algorithm has
a complexity which is a factor about 2
12
lower than
the earlier result, while still finding an equal amount
of zeros in the MDM signature.
5 RELATED WORK
In (Saarinen, 2006) the author discussed the d-
Monomial test, and how it can be applied in chosen-
IV attacks against stream ciphers. In contrast to our
work, Saarinen considers monomials of various de-
grees (up to degree d, therefore the name d-Monomial
test). Another difference is the choice of bit set, where
Saarinen only considers n-consecutive bits either in
the beginning or in the end of the IV, rather than
choosing freely from all parts of the IV.
In (Englund et al., 2007) the Maximum Degree
Monomial (MDM) test was introduced. Instead of
looking at different degrees of monomials, the MDM
test only focus on the maximum degree. The rationale
behind this is that the maximum degree monomial is
likely to occur only if all IV bits have been properly
mixed. In addition, the existence of the maximum de-
gree monomial is easy to find. The coefficient of the
monomial can be found by simply XORing all entries
in the truth table.
In the previously mentioned work, a subset of the
IV space was used in the tests. In (Stankovski, 2010),
a greedy heuristic to find these bitsets was discussed.
The algorithm started with an optimal bitset of a small
size, and then added n bits in each step in a greedy
fashion. In addition, both IV and key bits were sug-
gested for getting distinguisher and nonrandomness
results, respectively.
In (Liu et al., 2015), the authors concentrate on
small cubes, and instead look at unions of these cubes.
Another difference is that they look at sub-maximal
degree monomial tests.
Also partly based on Stankovski’s work is the
work in (Sarkar et al., 2016), where the authors pro-
pose two new, alternative heuristics. In the first, called
“maximum last zero”, the authors not only maximize
the initial sequence of zeros, but also ensure that the
position of the current iteration in the MDM signa-
ture is a zero as well. In their second heuristic, called
“maximum frequency of zero”, they instead look at
the total amount of zeros in the MDM signature. Their
heuristics are only applied to Trivium (De Cannière,
2006) and Trivia-SC (Chakraborti et al., 2015). Sim-
ilar to this paper, they also mention the use of a non-
constant n, i.e. a n-vector, although the authors do
not discuss the reasons for this choice.
In (Vielhaber, 2007) an attack called AIDA
on Trivium (with half the amount of initialization
ICISSP 2017 - 3rd International Conference on Information Systems Security and Privacy
230

rounds) was presented. Related to this attack are the
cube attacks (Dinur and Shamir, 2009), and especially
the dynamic cube attacks (Dinur and Shamir, 2011)
which was used to attack Grain-128.
Attacks on the newer Grain-128a has been dis-
cussed in some recent papers as well. In (Banik et al.,
2013) the authors present a related-key key attack re-
quiring > 2
32
related keys, and > 2
64
chosen IVs,
while in (Sarkar et al., 2015) the authors present a
differential fault attack against all the three ciphers in
the Grain-family.
6 CONCLUSIONS
In this paper we have discussed the use of the max-
imum degree monomial test to analyze the required
amount of initialization rounds of stream ciphers. We
have proposed a new algorithm to find a suitable sub-
set of key and IV-bits used in the MDM test. Our al-
gorithm has its root in a greedy approach, but by gen-
eralizing, we have designed an algorithm less suscep-
tible to local optima. The algorithm is very flexible,
and the parameters can be tuned based on the desired
computational complexity. Testing our algorithm on
the cipher Grain-128a, with different parameters, we
achieve new significantly better results compared to
the previous greedy algorithm.
ACKNOWLEDGMENTS
The computations were performed on resources pro-
vided by the Swedish National Infrastructure for
Computing (SNIC) at Lunarc.
REFERENCES
Ågren, M., Hell, M., Johansson, T., and Meier, W. (2011).
Grain-128a: a new version of Grain-128 with optional
authentication. International Journal of Wireless and
Mobile Computing, 5(1):48–59.
Banik, S., Maitra, S., Sarkar, S., and Meltem Sönmez, T.
(2013). A chosen IV related key attack on Grain-
128a. In Information Security and Privacy: 18th Aus-
tralasian Conference, ACISP 2013, Brisbane, Aus-
tralia, July 1-3, 2013. Proceedings, pages 13–26.
Springer.
Chakraborti, A., Chattopadhyay, A., Hassan, M., and
Nandi, M. (2015). Trivia: A fast and secure authenti-
cated encryption scheme. In Cryptographic Hardware
and Embedded Systems – CHES 2015: 17th Interna-
tional Workshop, Saint-Malo, France, September 13-
16, 2015, Proceedings, pages 330–353. Springer.
De Cannière, C. (2006). Trivium: A stream cipher construc-
tion inspired by block cipher design principles. In In-
formation Security: 9th International Conference, ISC
2006, Samos Island, Greece, August 30 - September 2,
2006. Proceedings, pages 171–186. Springer.
Dinur, I. and Shamir, A. (2009). Cube attacks on tweak-
able black box polynomials. In Advances in Cryptol-
ogy - EUROCRYPT 2009: 28th Annual International
Conference on the Theory and Applications of Crypto-
graphic Techniques, Cologne, Germany, April 26-30,
2009. Proceedings, pages 278–299. Springer.
Dinur, I. and Shamir, A. (2011). Breaking Grain-128
with dynamic cube attacks. In Fast Software Encryp-
tion: 18th International Workshop, FSE 2011, Lyn-
gby, Denmark, February 13-16, 2011, Revised Se-
lected Papers, pages 167–187. Springer.
Englund, H., Johansson, T., and Sönmez Turan, M. (2007).
A framework for chosen IV statistical analysis of
stream ciphers. In Progress in Cryptology – IN-
DOCRYPT 2007: 8th International Conference on
Cryptology in India, Chennai, India, December 9-13,
2007. Proceedings, pages 268–281. Springer.
Hell, M., Johansson, T., Maximov, A., and Meier, W.
(2006). A stream cipher proposal: Grain-128. In 2006
IEEE International Symposium on Information The-
ory, pages 1614–1618.
Liu, M., Lin, D., and Wang, W. (2015). Searching cubes for
testing boolean functions and its application to Triv-
ium. In 2015 IEEE International Symposium on In-
formation Theory (ISIT), pages 496–500.
Saarinen, M.-J. O. (2006). Chosen-IV statistical at-
tacks on eSTREAM stream ciphers. http://
www.ecrypt.eu.org/stream/papersdir/2006/013.pdf.
Sarkar, S., Banik, S., and Maitra, S. (2015). Differen-
tial fault attack against Grain family with very few
faults and minimal assumptions. IEEE Transactions
on Computers, 64(6):1647–1657.
Sarkar, S., Maitra, S., and Baksi, A. (2016). Observing bi-
ases in the state: case studies with Trivium and Trivia-
SC. Designs, Codes and Cryptography.
Stankovski, P. (2010). Greedy distinguishers and nonran-
domness detectors. In INDOCRYPT 2010, pages 210–
226. Springer.
Vielhaber, M. (2007). Breaking ONE.FIVIUM
by AIDA an algebraic IV differential attack.
Cryptology ePrint Archive, Report 2007/413.
http://eprint.iacr.org/2007/413.
APPENDIX
This appendix contains the exact vectors used for the
different results discussed in Section 4. The vectors
used for the results for varying k and α are given in
Table 4. In the same fashion, the vectors used for the
results for varying n are presented in Table 5. Finally,
the vectors for the results on Grain-128 are given in
Table 6.
Improved Greedy Nonrandomness Detectors for Stream Ciphers
231

Table 4: Varying k and α.
Greedy
k { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
n { 5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
α { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
Improved (20 %-k)
k { 1000, 200, 200, 200, 200, 200, 200, 200, 200, 200, 200, 200, 100, 60, 60, 20, 20, 20, 20, 20, 20, 12, 6, 3, 2, 2, 2, 2, 2, 1, 1, 1, 1 }
n { 5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
α { 1.0, 0.005, 0.005, 0.005, 0.005, 0.005, 0.005, 0.005, 0.005, 0.005, 0.005, 0.005, 0.005, 0.01,
1
60
,
1
60
, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05,
1
12
,
2
15
,
0.375, 0.5, 0.5, 0.5, 0.5,
2
9
, 1.0, 0.5, 1.0 }
0.5 %-k
k { 1000, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 3, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
n { 5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
α { 1.0, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2,
1
6
, 0.3, 0.5,
1
3
, 1.0, 1.0, 1.0, 1.0, 1.0, 0.6, 0.5, 0.4, 0.75, 1.0, 1.0, 1.0, 1.0,
2
9
, 1.0, 0.5, 1.0 }
0.2 %-k
k { 1000, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
n { 5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
α { 1.0, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.6, 1.0,
1
3
, 1.0, 1.0, 1.0, 1.0, 1.0, 0.6, 0.5, 0.4, 0.75, 1.0, 1.0, 1.0, 1.0,
2
9
, 1.0, 0.5, 1.0 }
min-k
k { 1000, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
n { 5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
α { 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.5, 0.6, 1.0,
1
3
, 1.0, 1.0, 1.0, 1.0, 1.0, 0.6, 0.5, 0.4, 0.75, 1.0, 1.0, 1.0, 1.0,
2
9
, 1.0, 0.5, 1.0 }
Table 5: Varying n.
Greedy 1-add
k { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
n { 5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
α { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
Greedy 2-add
k { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
n { 5, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2 }
α { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
Greedy 3-add
k { 1, 1, 1, 1, 1, 1, 1 }
n { 5, 3, 3, 3, 3, 3, 3 }
α { 1, 1, 1, 1, 1, 1, 1 }
2-2-2-2-2-2-2-2-1-...
k { 1000, 200, 200, 200, 200, 150, 50, 50, 50, 30, 15, 6, 5, 5, 5, 5, 5, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
n { 5, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
α { 1.0, 0.005, 0.005, 0.0005, 0.005,
1
150
, 0.02, 0.01, 0.02, 0.02,
1
15
,
1
15
, 0.15, 0.2, 0.2,
4
45
, 0.1, 0.5, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 }
2-2-2-2-1-...
k { 1000, 200, 200, 200, 200, 150, 50, 50, 50, 30, 15, 6, 5, 5, 5, 5, 5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
n { 5, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
α { 1.0, 0.005, 0.005, 0.0005, 0.005,
1
150
, 0.02, 0.01, 0.02, 0.02,
1
15
,
1
15
, 0.15, 0.2, 0.2,
4
45
, 0.1, 0.5, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0,
1.0 }
1-...
k { 1000, 200, 200, 200, 200, 150, 50, 50, 50, 30, 15, 6, 5, 5, 5, 5, 5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
n { 5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
α { 1.0, 0.005, 0.005, 0.0005, 0.005,
1
150
, 0.02, 0.01, 0.02, 0.02,
1
15
,
1
15
, 0.15, 0.2, 0.2,
4
45
, 0.1, 0.5, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0,
1.0, 1.0, 1.0, 1.0, 1.0 }
Table 6: Results on Grain-128.
Greedy 1-add
k { 1000, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 80, 60, 60, 20, 20, 20, 20, 20 }
n { 6, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
α { 1.0, 0.0125, 0.0125, 0.0125, 0.0125, 0.0125, 0.0125, 0.0125, 0.0125, 0.0125, 0.0125, 0.0125, 0.00625, 0.01,
1
60
,
1
60
, 0.05, 0.05, 0.05, 0.05 }
ICISSP 2017 - 3rd International Conference on Information Systems Security and Privacy
232
