
Dynamic Selection of Exemplar-SVMs for Watch-list Screening through
Domain Adaptation
Saman Bashbaghi
1
, Eric Granger
1
, Robert Sabourin
1
and Guillaume-Alexandre Bilodeau
2
1
Laboratoire d’Imagerie de Vision et d’Intelligence Artificielle,
École de Technologie Supérieure, Université du Québec, Montréal, Canada
2
LITIV Lab, Polytechnique Montréal, Montréal, Canada
bashbaghi@livia.etsmtl.ca, {eric.granger, robert.sabourin}@etsmtl.ca, gabilodeau@polymtl.ca
Keywords:
Face Recognition, Video Surveillance, Multi-classifier System, Single Sample Per Person, Random Subspace
Method, Domain Adaptation, Dynamic Classifier Selection.
Abstract:
Still-to-video face recognition (FR) plays an important role in video surveillance, allowing to recognize indi-
viduals of interest over a network of video cameras. Watch-list screening is a challenging video surveillance
application, because faces captured during enrollment (with still camera) may differ significantly from those
captured during operations (with surveillance cameras) under uncontrolled capture conditions (with variations
in, e.g., pose, scale, illumination, occlusion, and blur). Moreover, the facial models used for matching are
typically designed a priori with a limited number of reference stills. In this paper, a multi-classifier system
is proposed that exploits domain adaptation and multiple representations of face captures. An individual-
specific ensemble of exemplar-SVM (e-SVM) classifiers is designed to model the single reference still of each
target individual, where different random subspaces, patches, and face descriptors are employed to generate
a diverse pool of classifiers. To improve robustness of face models, e-SVMs are trained using the limited
number of labeled faces in reference stills from the enrollment domain, and an abundance of unlabeled faces
in calibration videos from the operational domain. Given the availability of a single reference target still, a
specialized distance-based criteria is proposed based on properties of e-SVMs for dynamic selection of the
most competent classifiers per probe face. The proposed approach has been compared to reference systems
for still-to-video FR on videos from the COX-S2V dataset. Results indicate that ensemble of e-SVMs desig-
ned using calibration videos for domain adaptation and dynamic ensemble selection yields a high level of FR
accuracy and computational efficiency.
1 INTRODUCTION
In decision support systems for video surveillance,
face recognition (FR) is increasingly employed to
enhance security in public places, such as airports,
subways, etc. FR systems are needed to accurately
detect the presence of individuals of interest enrolled
to the system over a network of surveillance came-
ras (De la Torre Gomerra et al., 2015), (Pagano et al.,
2014). In still-to-video FR, face models generated ba-
sed on face stills are matched against faces captured
in videos under uncontrolled conditions. Thus, face
models are composed of one or very few facial regi-
ons of interest (ROIs) isolated in reference face stills
for template matching, or a neural and statistical clas-
sifier, where the parameters are estimated using refe-
rence ROIs (De-la Torre Gomerra et al., 2015).
Watch-list screening is among the most challen-
ging application in video surveillance. Face mo-
dels are typically designed a priori during enrollment
using a single reference still (high-quality mugshot
or ID photo) under controlled conditions (Bashbaghi
et al., 2014). A key issue in still-to-video FR is that
the appearance of ROIs captured with still camera dif-
fers significantly from ROIs captured with video ca-
meras due to various nuisance factors, e.g., changes
in illumination, pose, blur, and occlusion, and camera
inter-operability (Barr et al., 2012). The single sam-
ple per person (SSPP) problem found in these systems
has been addressed by different techniques, such as
using multiple face representations, synthetic genera-
tion of virtual faces, and incorporating auxiliary sets
to enlarge the design data (Bashbaghi et al., 2014),
(Mokhayeri et al., 2015), (Yang et al., 2013).
Still-to-video FR systems can be viewed as a dom-
ain adaptation (DA) problem, where the distribution
738
Bashbaghi, S., Granger, E., Sabourin, R. and Bilodeau, G-A.
Dynamic Selection of Exemplar-SVMs for Watch-list Screening through Domain Adaptation.
DOI: 10.5220/0006256507380745
In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2017), pages 738-745
ISBN: 978-989-758-222-6
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

of facial ROIs captured from reference stills in the
enrollment domain (ED) are different from those vi-
deo ROIs captured from multiple surveillance came-
ras, where each one represents a non-stationary opera-
tional domain (OD) (Shekhar et al., 2013). Since any
distributional change (either domain shift or concept
drift) can degrade performance, DA methods may
be deployed to design accurate classification systems
that will perform well on the OD given knowledge
obtained from the ED (Patel et al., 2015).
State-of-the-art systems for FR in video surveil-
lance are typically designed with individual-specific
face detectors (one or 2-class classifiers) that can be
easily added, removed, and specialized over time (Pa-
gano et al., 2014), (Bashbaghi et al., 2014). Using
an ensemble of classifiers per individual with static
selection and fusion of diversified set of base clas-
sifiers has been shown to enhance the robustness of
still-to-video FR (Bashbaghi et al., 2015). Further-
more, dynamic selection (DS) can be also exploited to
select the most suitable classifiers for an input video
ROI. DS can be considered as an effective approach
in ensemble-based systems, when the training data is
limited and imbalanced (Britto et al., 2014). To that
end, base classifiers can be selected according to their
level of competence to classify under specific capture
conditions and individual behaviors within an opera-
tional environment (Shekhar et al., 2013).
In this paper, a robust dynamic individual-specific
ensemble-based system is proposed for still-to-video
FR. Multiple feature subspaces corresponding to dif-
ferent face patches and descriptors are employed to
generate a diverse pool of classifiers, and to improve
robustness against different perturbation factors fre-
quently observed in real-world surveillance environ-
ments. During enrollment, an individual-specific en-
semble of e-SVM classifiers is designed for each tar-
get individual based on the ED data (the limited num-
ber of labeled faces in reference stills) and OD data
(an abundance of unlabeled faces captured in calibra-
tion videos). Thus, an unsupervised DA method is
employed to train e-SVMs in the ED, where unlabe-
led lower-quality videos of unknown persons are con-
sidered to transfer the knowledge of the OD. Three
different training schemes are proposed using a sin-
gle labeled target still along with non-target still ROIs
from the cohort, as well as, unlabeled non-target vi-
deo ROIs captured with surveillance camera.
During operations, a novel distance-based crite-
ria is proposed for DS based on the properties of e-
SVMs in order to effectively adapt to the changing
uncontrolled capture conditions. Thus, the DS appro-
ach performs in the feature space to select the most
competent e-SVMs for a given probe ROI based on
the distance between support vectors of e-SVMs and a
target still for each individual of interest. The perfor-
mance of the proposed system is compared to state-
of-the-art systems using the videos from COX-S2V
dataset (Huang et al., 2015).
2 SYSTEMS FOR
STILL-TO-VIDEO FR
Still-to-video FR systems attempt to accurately match
the faces captured from video surveillance cameras
against the corresponding facial models of the indi-
viduals of interest registered to the system. Due to
generation of discriminative facial models, the SSPP
problem has been addressed using techniques to pro-
vide multiple face representations (Bashbaghi et al.,
2014), (Kamgar-Parsi et al., 2011). For instance, face
synthesizing through morphology is used in (Kamgar-
Parsi et al., 2011), where a specialized neural net-
work is trained for each individual. Multiple face
representations (employing patch configurations and
different face descriptors) exploited in an ensemble-
based system have shown to significantly improve the
overall performance of a basic still-to-video FR at the
cost of either several template matchers or multiple
classifiers (Bashbaghi et al., 2014), (Bashbaghi et al.,
2015). As a specialized classification technique con-
sidering the SSPP problem, e-SVM classifier is adap-
ted using non-target video ROIs (Bashbaghi et al.,
2016), (Malisiewicz et al., 2011).
Spatio-temporal recognition can be also exploited
to enhance the robustness, where decisions are produ-
ced through a tracker to regroup ROIs of a same per-
son into trajectories (Dewan et al., 2016). Recently,
sparse representation based classification (SRC) met-
hods are adopted to increase robustness to intra-class
variation using a generic auxiliary training set, such
as sparse variation dictionary learning (SVDL) (Yang
et al., 2013). Similarly, an extended sparse represen-
tation approach through domain adaptation (ESRC-
DA) (Nourbakhsh et al., 2016) has been proposed
for still-to-video FR incorporating matrix factoriza-
tion and dictionary learning. According to the avai-
lability of labeled data in the OD, unsupervised DA
has been proposed, where it does not consider labeled
data in the OD as observed in watch-list screening ap-
plications (Qiu et al., 2014). Two unsupervised DA
approaches are relevant for still-to-video FR based
on the knowledge transferred between the enrollment
and operational domains (Patel et al., 2015), (Pan and
Yang, 2010). Instance transfer methods attempt to ex-
ploit parts of the ED data for learning in the OD. In
contrast, feature representation transfer methods ex-
Dynamic Selection of Exemplar-SVMs for Watch-list Screening through Domain Adaptation
739
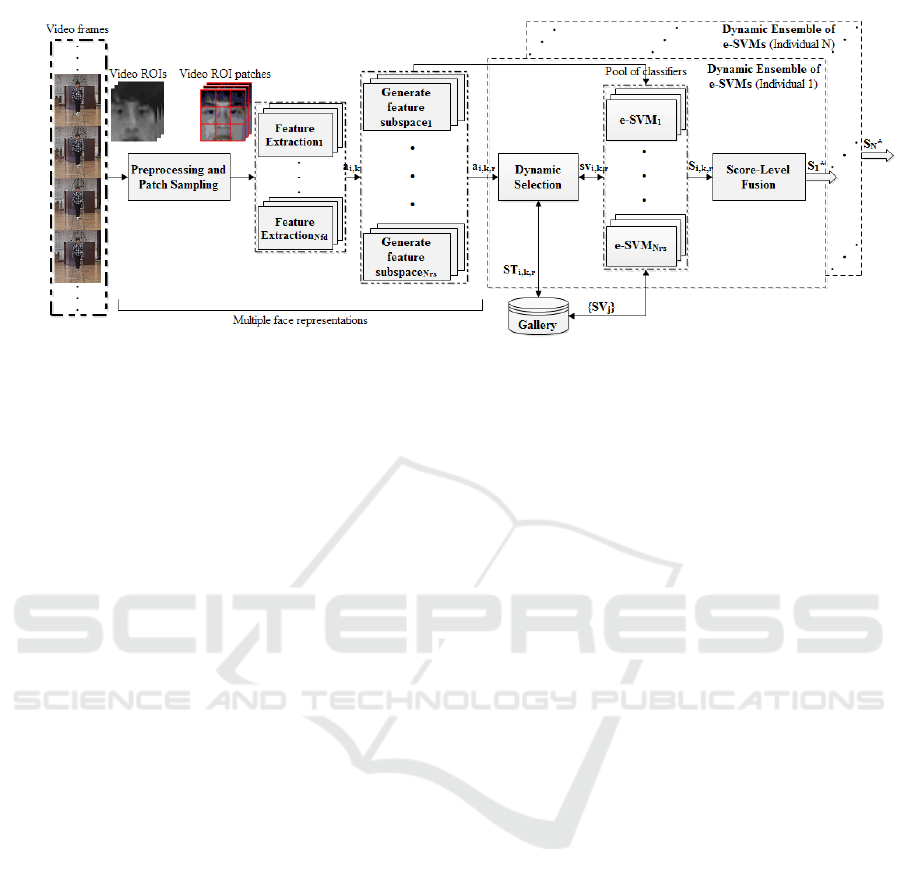
Figure 1: Block diagram of the proposed still-to-video FR system using dynamic ensemble of e-SVMs per target individual.
ploit OD data to find a latent feature space that redu-
ces the distribution differences between the ED and
the OD (Pan and Yang, 2010).
3 ENSEMBLES OF
EXEMPLAR-SVMS THROUGH
DOMAIN ADAPTATION
The block diagram of the proposed system is shown
in Figure 1. During enrollment, a single reference still
of a target individual is employed to train an ensem-
ble of e-SVMs using faces captured in OD and mul-
tiple face representations to generate diverse pools of
e-SVM classifiers. During operations, the most com-
petent classifiers are selected dynamically for a probe
ROI using a new selection criteria according to chan-
ges in capture conditions of the OD and combined.
3.1 Enrollment Phase
During enrollment of a target individual, a diverse
pool of e-SVM classifiers is constructed for each tar-
get individual enrolled to the system. In particular,
several representations generated from the labeled tar-
get still ROI through using different patches, descrip-
tors, and random subspaces. These representations of
the target still ROI are used along with the correspon-
ding unlabeled video ROIs of non-target individuals
to train e-SVMs. Thus, a pool of N
p
· N
f d
· N
rs
e-
SVMs are trained for each individual of interest and
stored in the gallery, where N
p
is the number of pat-
ches, N
f d
and N
rs
are the number of descriptors and
random subspaces, respectively.
To generate multiple face representations, random
feature subspaces are extracted from patches isolated
uniformly without overlapping in each ROI, where
patches are represented using several complementary
face descriptors, such as LPQ and HOG descriptors
(Ahonen et al., 2008), (Deniz et al., 2011). For ex-
ample, LPQ extract texture features of the face ima-
ges from frequency domain through Fourier transform
and has shown high robustness to motion blur. HOG
extract edges using different angles and orientations,
where it is more robust to pose and scale changes, as
well as, rotation and translation. Random sampling
of features extracted from each local patch can pro-
vide diversity among classifiers, due to different fe-
ature distributions, and exploits information on local
structure of faces for FR under changes in pose, illu-
mination, and occlusions.
Different training schemes as illustrated in Fi-
gure 2 are considered using either the labeled target
still ROIs from the cohort or unlabeled non-target vi-
deo ROIs captured from the calibration videos. To
that end, an unsupervised DA approach is considered,
where labeled still reference ROIs from the cohort and
unlabeled video ROIs captured from the operational
environment are employed to train e-SVM classifiers.
In the first training scheme (Figure 2 (a)), labeled tar-
get still ROIs versus non-target still ROIs from the co-
hort are employed to train e-SVMs without exploiting
unlabeled video ROIs from the OD for DA. The se-
cond scheme (Figure 2 (b)) relies on several unlabeled
non-target video ROIs from all calibration videos (or
background model), while in the third scheme (Figure
2 (c)), unlabeled video ROIs captured from each spe-
cific camera are exploited in conjunction with a tar-
get still ROI in order to design camera-specific pools
of classifiers. Thus, an individual-specific pool of
e-SVM classifiers trained with video ROIs of speci-
fic camera is employed to recognize individuals from
ROIs captured with the corresponding camera.
ICPRAM 2017 - 6th International Conference on Pattern Recognition Applications and Methods
740

(a) Training scheme 1
(b) Training scheme 2
(c) Training scheme 3
Figure 2: Illustration of different training schemes for DA
with an e-SVM classifier.
To train a classifier under imbalanced data distri-
butions (a single reference labeled still from the ED
versus several unlabeled non-target videos from the
OD), specialized linear SVM classifiers called e-SVM
are adapted (Bashbaghi et al., 2016) for each scheme.
Let a be the labeled target ROI pattern, x and U are
non-target ROI patterns (either labeled still ROIs for
scheme 1 or unlabeled video ROIs for schemes 2 and
3) and their number, respectively. The e-SVM is for-
mulated as follows:
min
w,b
w
2
+C
1
max(0, 1 −
w
T
a + b
+
C
2
∑
x∈U
max
0, 1 −
w
T
x + b
,
(1)
where C
1
and C
2
parameters control the weight of re-
gularization terms, w is the weight vector, and b is the
bias term. To deal with the imbalanced training data
in such a situation and avoid the learning model to
bias toward the majority class (unlabeled non-target
videos), the regularization term (C
1
) of the minority
class (a single labeled target reference still) is assig-
ned greater than the regularization term (C
2
) of nega-
tive samples.
3.2 Operational Phase
During operations, people appear before surveillance
cameras (see Figure 1), while each individual-specific
ensemble attempts to recognize these faces as an indi-
vidual of interest. Each frame is segmented to extract
facial ROI(s) and then multiple face representations
are generated for classification. Then, every ROI is
projected into multiple feature subspaces correspon-
ding to classifiers, and those that meet competence
criteria are dynamically selected. A given probe ROI
is fed to an ensemble of e-SVMs defined through DS.
Score-level fusion is adopted to combine the scores
of e-SVM classifiers selected from the pool. The ope-
rational phase of the proposed system is described in
Algorithm 1.
Algorithm 1: Operational phase with DS.
1: Input: Pool of e-SVM classifiers C
j
for individual of interest j,
the set of support vectors
SV
j
per C
j
2: Output: Scores of dynamic ensembles based on a subset of the
most competent classifiers C
∗
j
3: for each probe ROI t do
4: Divide testing ROI t into patches after preprocessing
5: for each patch i = 1...N
p
do
6: for each face descriptor k = 1...N
f d
do
7: a
i,k
← Extract features f
k
from patch p
i
8: for each subspaces r = 1...Nrs do
9: a
i,k,r
← sample subspaces s
r
from a
i,k
10: C
∗
j
←
{
/
0
}
11: for each classifier c
l
in C
j
do
12: if d
a
i,k,r
, ST
i,k,r
≤ d
a
i,k,r
, sv
i,k,r
then
13: C
∗
j
← c
l
∪C
∗
j
14: end if
15: end for
16: end for
17: end for
18: end for
19: if C
∗
j
is empty then
20: S
∗
j
← Use mean scores of C
j
to classify t
21: else
22: S
∗
j
← Use mean scores of C
∗
j
to classify t
23: end if
24: end for
As formalized in Algorithm 1, each given probe
ROI t is first divided into patches p
i
. Feature ex-
traction technique f
k
is applied on each patch p
i
to
Dynamic Selection of Exemplar-SVMs for Watch-list Screening through Domain Adaptation
741

form a ROI pattern a
i,k
. These patterns are projected
into the N
rs
feature subspaces s
r
generated for training
e-SVM classifiers and then a
i,k,r
is projected into the
feature space of the support vectors
SV
j
of classi-
fiers C
j
and the reference still ST
i,k,r
of the target indi-
vidual j. Finally, those classifiers c
l
in C
j
that satisfy
the levels of competence criteria (line 12) are selected
to constitute C
∗
j
in order to classify the testing sample
t, where sv
i,k,r
∈
SV
j
is the closest support vector
to ST
i,k,r
. Subsequently, the scores of selected clas-
sifiers S
i,k,r
are combined using score-level fusion to
provide final score S
∗
j
. However, fusion of all clas-
sifiers in C
j
is exploited to classify t when none of
classifiers fulfill the competence criteria. The calibra-
ted score of e-SVM for the given probe ROI t and the
regression parameters (α
a
,β
a
) is computed as follows
(Malisiewicz et al., 2011):
f (x|w, α
a
, β
a
) =
1
1 + e
−α
a
(
w
T
a
−β
a
)
(2)
When a probe ROI is captured, a new DS method
is exploited based on e-SVM properties to provide a
strong discrimination among probe ROIs. It allows
the system to select the subset of classifiers that are
the most suitable for the given capture conditions of
a given probe ROI. In order to select the most com-
petent classifiers, the proposed internal competence
criteria relies on the: (1) distance from the non-target
support vectors ROIs, d (a
i,k,r
, sv
i,k,r
), and (2) close-
ness to the target still ROI pattern, d (a
i,k,r
, ST
i,k,r
).
The key idea is to select the e-SVM classifiers that
locate the given probe ROI close to the target sup-
port vector, yet far from non-target support vectors.
If the distance between the probe and the target still
is lower than the distance from support vectors, then
those classifiers are dynamically selected as a suitable
subset for classifying the probe ROIs.
Classifiers with support vectors that are far from
the ROI probes can be also desired candidates, be-
cause they may classify them correctly. Distance from
non-target support vectors can be defined by conside-
ring the closest support vector to the target still ROI
in the proposed DS approach (see Figure 3). All the
non-target support vectors were sorted a priori based
on their distance to the target still (the target support
vector) in an offline processing. Then, the closest sup-
port vector to the target still is used to compare with
the input probe ROIs.
In contrast to the common DS techniques that use
local neighborhood accuracy for measuring the level
of competence (Britto et al., 2014), it is not man-
datory in the proposed DS approach to define neig-
hborhood with a set of validation data, using methods
like k-NN. Thus, the proposed criteria exploits the
local e-SVM properties, and accounts for the SSPP
Figure 3: Illustration of the proposed dynamic classifier se-
lection approach in a 2D feature space.
constraints, where it is efficient in terms of complex-
ity (number of computations to define neighborhood).
However, different distance metrics, such as Eucli-
dean can be employed to measure the distances bet-
ween the probe ROI and either a target still ROI pat-
tern or non-target support vectors.
4 EXPERIMENTAL RESULTS
4.1 Methodology for Validation
In this paper, two aspects of the proposed system
are assessed experimentally using a real-world vi-
deo surveillance data. First, different e-SVM training
schemes are compared for the proposed individual-
specific ensembles. Second, the impact of applying
DS is analyzed on the performance. Experiments in
this paper are shown at transaction-level to perform
face classification
1
.
A challenging still-to-video dataset called COX-
S2V
2
(Huang et al., 2015) is employed to evaluate
performance of the proposed and baseline systems.
This dataset consists of 1000 subjects, where each
subject has a high-quality still image captured un-
der controlled condition, and four lower-quality facial
trajectories captured under uncontrolled conditions
using two different off-the-shelf camcorders. Each
trajectory has 25 faces (16x20 and 48x60 resoluti-
ons), where ROIs taken from these videos encounter
changes in illumination, expression, scale, viewpoint,
1
In still-to-video FR system, operational ROI would be
regrouped into trajectories for spatio-temporal recognition
2
http://vipl.ict.ac.cn/resources/datasets/cox-face-
dataset/COX-S2V
ICPRAM 2017 - 6th International Conference on Pattern Recognition Applications and Methods
742

and blur. An example of a still ROI belonging to one
subject and corresponding video ROIs is shown in Fi-
gure 4.
Figure 4: Example of the reference still ROI for enrollment
of subject ID #1 and some corresponding ROIs extracted
from videos from the 4 OD of the COX-S2V dataset.
In experiments, the high-quality stills for N
wl
= 20
individuals of interest are randomly chosen to popu-
late the watch-list due to assessment of the proposed
DS system, as well as, N
wl
= 10 for evaluation of dif-
ferent training schemes. Videos of 100 unlabeled per-
sons from the OD considered as calibration videos are
employed during the enrollment for DA. In addition,
videos of 100 other unknown people along with vi-
deos of the watch-list individuals are merged for tes-
ting during the operational phase. Therefore, one tar-
get individual at a time and all of the unknown per-
sons within the test videos participate in each testing
iteration. In order to achieve statistically significant
results, the experiments are replicated 5 times consi-
dering different individuals of interest.
The reference still and video ROIs are converted
to grayscale and scaled to a common size of 48x48
pixels due to computational efficiency (Huang et al.,
2015). Histogram equalization is then utilized to en-
hance contrast, as well as, to eliminate the effect of il-
lumination changes. Afterwards, each ROI is divided
into N
p
= 9 uniform non-overlapping patch configu-
rations of 16x16 pixels as in (Bashbaghi et al., 2016),
(Chen et al., 2015). Libsvm library (Chang and Lin,
2011) is used in order to train e-SVMs differently,
where the same regularization parameters C
1
= 1 and
C
2
= 0.01 are considered for all exemplars based on
the imbalance ratio (Bashbaghi et al., 2016). Random
subspace sampling with replacement is also employed
to randomly generate several subspaces N
rs
= 20 from
the original feature space. Ensemble of template ma-
tchers (TMs) and e-SVMs using multiple face repre-
sentations (Bashbaghi et al., 2014), (Bashbaghi et al.,
2016), ESRC-DA (Nourbakhsh et al., 2016), specia-
lized kNN adapted for video surveillance (VSkNN)
(Pagano et al., 2014), and SVDL (Yang et al., 2013)
are considered as the baseline and state-of-the-art FR
systems to validate the proposed system.
Receiver operating characteristic (ROC) curve is
adopted to evaluate performance of the proposed sy-
stem at transaction-level. Thus, area under ROC
curve (AUC) as a global scalar metric of the detection
performance is considered, where it may be inter-
preted as the probability of classification. Another
relevant curve that can estimate the system perfor-
mance under imbalanced data situation is precision-
recall (PR), where TPR can be associated as recall
and precision (P) is computed as follows: P =
TP
TP+FP
.
System performance are provided using average par-
tial AUC (pAUC) and area under PR (AUPR) along
with standard errors. It is worth noting that, the AUPR
could be more desirable to represent the global accu-
racy of the system in skewed imbalanced data condi-
tions.
4.2 Results and Discussion
The average transaction-level performance of diffe-
rent training schemes with considering N
wl
= 10 in-
dividuals of interest based on DA are presented in
the Table 1 over each video of COX-S2V. Results in
Table 1 indicate that the training schemes 1 is gre-
atly outperformed by schemes 2 and 3, where calibra-
tion videos from OD are employed for DA to train e-
SVMs. However, schemes 2 performs better than the
camera-specific training scheme (scheme 3) in terms
of both accuracy and computational complexity. In
the scheme 2, videos from all of the cameras (global
knowledge of the surveillance environment) are em-
ployed to generate an e-SVM pool, while 4 camera-
specific e-SVM pools are generated for the scheme 3
using videos of each specific camera (partial know-
ledge of the surveillance environment). For instance,
only the classifiers within the pool of camera #1 that
are trained using videos captured form camera #1 are
employed to classify the probe ROI captured using
camera #1 during operations.
Since the capture conditions and camera charac-
teristics are different in COX-S2V dataset, it leads to
a significant impact on the system performance. For
example, the performance of the proposed system for
video3 is lower than other videos. The differences
between pAUC(20%) and the corresponding AUPR
observed in Table 1 reveal the severely imbalanced
operational data, where a large number of e-SVMs
can correctly classify the non-target ROIs but some
of them can classify the target ROIs correctly. The-
refore, the FPR values are very low in all cases and
consequently, the pAUC(20%) values obtained from
Dynamic Selection of Exemplar-SVMs for Watch-list Screening through Domain Adaptation
743

Table 1: Average pAUC(20%) and AUPR performance of different training schemes and the proposed system with or without
DS (N
wl
= 10 for experiments on training schemes and N
wl
= 20 for DS) at transaction-level over COX-S2V videos.
Systems
Video1 Video2 Video3 Video4
pAUC(20%) AUPR pAUC(20%) AUPR pAUC(20%) AUPR pAUC(20%) AUPR
Training Scheme 1 77.62±4.18 57.28±5.08 92.31±1.93 72.90±4.44 69.16±4.32 40.10±5.25 84.63±5.33 58.13±2.89
Training Scheme 2 100±0.00 94.23±0.22 99.99±0.00 94.06±0.36 99.95±0.04 94.21±0.33 99.99±0.00 94.17±0.22
Training Scheme 3 99.99±0.00 94.13±0.26 99.79±0.13 93.66±0.54 98.27±0.76 89.07±1.98 89.78±0.15 92.68±1.35
Proposed system w.o. DS 100±0.00 94.70±0.19 99.83±0.06 92.49±0.73 95.32±0.87 81.18±1.21 97.04±0.95 84.90±2.01
Proposed system w. DS 100±0.00 93.37±0.29 99.96±0.01 92.51±0.41 97.68±0.47 82.50±1.44 98.40±0.44 85.23±1.69
ROC curves are always higher than AUPR values.
Performance of the proposed system either with
DS or without DS with N
wl
= 20 are also presented in
Table 1 using the second training scheme. As shown
in Table 1, applying the proposed DS approach can
improve the performance instead of combining all of
the classifiers within the pool. It implies that dyna-
mically integrating a subset of competent classifiers
leads to a higher level of accuracy over different cap-
ture conditions. Since only two distances (distance
from the probe to the target still ROI and distance to
the closest non-target support vector) are measured in
the DS approach, it is efficient and does not signifi-
cantly increase the computational burden.
The proposed system with DS approach is compa-
red with the state-of-the-art and baseline FR systems
in Table 2. It can be seen from Table 2 that the propo-
sed system significantly outperforms ESRC-DA, en-
semble of TMs, SVDL, and VSkNN, especially re-
garding to AUPR values. System using VSkNN and
SVDL provide a lower level of performance, mostly
because of the considerable differences between the
appearance of the target face stills and video faces, as
well as, the level of data imbalance of target ROIs ver-
sus non-target ROIs observed during operations. It is
worth noting that both VSkNN and SVDL are more
suitable for close-set FR problems, such as face iden-
tification, where each probe face should be assigned
to one of the target still in the gallery. However, spar-
sity concentration index was used as a threshold to
reject the probes not appearing in the over-complete
dictionaries in SVDL and ESRC-DA. The results ob-
served from Table 2 suggest that the proposed system
with DS approach can also achieve a higher or compa-
rable level of performance to (Bashbaghi et al., 2016)
with a significant decrease of computational complex-
ity.
Table 2 also presents the complexity in terms of
the number of dot products required during operations
to process a probe ROI. Computational complexity of
the proposed system is mainly affected by the feature
extraction, classification, dynamic classifier selection,
and fusion for a given probe ROI. In this regard, e-
SVM classification is performed with a linear SVM
kernel function using a dot product. The complex-
ity to process a probe ROI is O(N
d
· N
sv
) (Chang and
Lin, 2011), where N
d
and N
sv
are the dimensionality
of the face descriptors and the number of support vec-
tors, respectively. Thus, the worst case of complex-
ity to process an input ROI can be computed as the
product of N
p
·N
f d
·N
rs
·N
sv
·N
d
according to dot pro-
ducts per e-SVM classifier. For example, the propo-
sed system with DS needs 9·2·20·18·71 dot products
for fusion in the worst case, where all of the clas-
sifiers are dynamically selected, and 9 · 2 · 20 · 2 · 71
for performing dynamic selection. Noted that the
proposed system in this paper employs two different
light-weight face descriptors, whereas ensemble of
e-SVMs (Bashbaghi et al., 2016) utilizes four diffe-
rent face descriptors along with applying PCA with
the complexity of O
N
3
d
for feature ranking and se-
lection. Meanwhile, ensemble of TMs and VSkNN
employ Euclidean distance with O
N
2
d
to calculate
the similarity among templates. The complexity of
ESRC-DA is calculated with O
N
2
d
.k
, where k is the
number of atoms.
5 CONCLUSION
This paper presents a system specialized for watch-
list screening applications that exploits dynamic se-
lection of classifier ensembles trained through multi-
ple face representations and DA. Multiple face repre-
sentation (different random subspaces, patches, and
descriptors) are employed to design the individual-
specific ensemble of e-SVMs per target individual,
to provide diversity among classifiers, and to over-
come the existing nuisance factors in surveillance en-
vironments. Unsupervised DA allows to generate di-
verse pools of e-SVM, where video ROIs of non-
target individuals are exploited. Different training
schemes were considered using unlabeled non-target
video ROIs, and training global e-SVMs on calibra-
tion videos from all network cameras performs most
efficiently. In addition, a new distance-based criteria
of competence is proposed for DS during operations
to dynamically select the best subset of classifiers per
input probe. Distances of a given probe to the target
still and the closest support vector are considered as
ICPRAM 2017 - 6th International Conference on Pattern Recognition Applications and Methods
744

Table 2: Average transaction-level performance of the proposed and state-of-the-art FR systems on videos of the COX-S2V.
FR Systems pAUC(20%) AUPR Complexity (number of dot products)
VSkNN (Pagano et al., 2014) 56.80±4.02 26.68±3.58 671,744
SVDL (Yang et al., 2013) 69.93±5.67 44.09±6.29 810,000
Ensemble of TMs (Bashbaghi et al., 2014) 84.00±0.86 73.36±9.82 1,387,200
ESRC-DA (Nourbakhsh et al., 2016) 99.00±0.13 63.21±4.56 432,224,100
Ensemble of e-SVMs (Bashbaghi et al., 2016) 99.02±0.15 88.03±0.85 2,327,552
Proposed system w. DS 99.02±0.23 88.40±0.96 504,720
the competence criteria. Simulation results obtained
using videos of the COX-S2V dataset confirm that the
proposed system is computationally efficient and out-
performs the state-of-the-art systems even when the
data is limited and imbalanced.
ACKNOWLEDGMENT
This work was supported by the Fonds de Recherche
du Québec - Nature et Technologies.
REFERENCES
Ahonen, T., Rahtu, E., Ojansivu, V., and Heikkila, J. (2008).
Recognition of blurred faces using local phase quanti-
zation. In ICPR, pages 1–4.
Barr, J. R., Bowyer, K. W., Flynn, P. J., and Biswas, S.
(2012). Face recognition from video: A review. IJ-
PRAI, 26(05).
Bashbaghi, S., Granger, E., Sabourin, R., and Bilodeau, G.-
A. (2014). Watch-list screening using ensembles ba-
sed on multiple face representations. In ICPR, pages
4489–4494.
Bashbaghi, S., Granger, E., Sabourin, R., and Bilodeau, G.-
A. (2015). Ensembles of exemplar-svms for video
face recognition from a single sample per person. In
AVSS, pages 1–6.
Bashbaghi, S., Granger, E., Sabourin, R., and Bilodeau, G.-
A. (2016). Robust watch-list screening using dynamic
ensembles of svms based on multiple face representa-
tions. Machine Vision and Applications.
Britto, A. S., Sabourin, R., and Oliveira, L. E. (2014). Dyn-
amic selection of classifiers - a comprehensive review.
Pattern Recognition, 47(11):3665 – 3680.
Chang, C.-C. and Lin, C.-J. (2011). Libsvm: A library for
support vector machines. ACM TIST, 2(3):1–27.
Chen, C., Dantcheva, A., and Ross, A. (2015). An ensem-
ble of patch-based subspaces for makeup-robust face
recognition. Information Fusion, pages 1–13.
De la Torre Gomerra, M., Granger, E., Radtke, P. V., Sa-
bourin, R., and Gorodnichy, D. O. (2015). Partially-
supervised learning from facial trajectories for face re-
cognition in video surveillance. Information Fusion,
24:31–53.
De-la Torre Gomerra, M., Granger, E., Sabourin, R., and
Gorodnichy, D. O. (2015). Adaptive skew-sensitive
ensembles for face recognition in video surveillance.
Pattern Recognition, 48(11):3385 – 3406.
Deniz, O., Bueno, G., Salido, J., and la Torre, F. D. (2011).
Face recognition using histograms of oriented gra-
dients. Pattern Recognition Letters, 32(12):1598 –
1603.
Dewan, M. A. A., Granger, E., Marcialis, G.-L., Sabourin,
R., and Roli, F. (2016). Adaptive appearance model
tracking for still-to-video face recognition. Pattern
Recognition, 49:129 – 151.
Huang, Z., Shan, S., Wang, R., Zhang, H., Lao, S., Kuerban,
A., and Chen, X. (2015). A benchmark and compara-
tive study of video-based face recognition on cox face
database. IP, IEEE Trans on, 24(12):5967–5981.
Kamgar-Parsi, B., Lawson, W., and Kamgar-Parsi, B.
(2011). Toward development of a face recognition sy-
stem for watchlist surveillance. IEEE Trans on PAMI,
33(10):1925–1937.
Malisiewicz, T., Gupta, A., and Efros, A. (2011). Ensemble
of exemplar-svms for object detection and beyond. In
ICCV, pages 89–96.
Mokhayeri, F., Granger, E., and Bilodeau, G.-A. (2015).
Synthetic face generation under various operational
conditions in video surveillance. In ICIP, pages 4052–
4056.
Nourbakhsh, F., Granger, E., and Fumera, G. (2016). An
extended sparse classification framework for domain
adaptation in video surveillance. In ACCV, Workshop
on Human Identification for Surveillance.
Pagano, C., Granger, E., Sabourin, R., Marcialis, G., and
Roli, F. (2014). Adaptive ensembles for face recogni-
tion in changing video surveillance environments. In-
formation Sciences, 286:75–101.
Pan, S. J. and Yang, Q. (2010). A survey on transfer lear-
ning. KDE, IEEE Trans on, 22(10):1345–1359.
Patel, V., Gopalan, R., Li, R., and Chellappa, R. (2015). Vi-
sual domain adaptation: A survey of recent advances.
IEEE Signal Processing Magazine, 32(3):53–69.
Qiu, Q., Ni, J., and Chellappa, R. (2014). Dictionary-based
domain adaptation for the re-identification of faces. In
Person Re-Identification, Advances in Computer Vi-
sion and Pattern Recognition, pages 269–285.
Shekhar, S., Patel, V., Nguyen, H., and Chellappa, R.
(2013). Generalized domain-adaptive dictionaries. In
CVPR, pages 361–368.
Yang, M., Van Gool, L., and Zhang, L. (2013). Sparse va-
riation dictionary learning for face recognition with
a single training sample per person. In ICCV, pages
689–696.
Dynamic Selection of Exemplar-SVMs for Watch-list Screening through Domain Adaptation
745
