
A Study on Cooperative Action Selection Considering Unfairness in
Decentralized Multiagent Reinforcement Learning
Toshihiro Matsui and Hiroshi Matsuo
Nagoya Institute of Technology, Gokisyo-cho, Showa-ku, Nagoya, Aichi, 466-8555, Japan
Keywords:
Multiagent System, Reinforcement Learning, Distri buted Constraint Optimization, Unfairness, Leximin.
Abstract:
Reinforcement learning has been studied for cooperative learning and optimization methods in multiagent sys-
tems. In several frameworks of multiagent reinforcement learning, the system’s whole problem is decomposed
into l ocal problems for agents. To choose an appropriate cooperative action, the agents perform an optimiza-
tion method that can be performed in a distributed manner. While the conventional goal of the learning is the
maximization of the total rewards among agents, in practical resource al location problems, unfairness among
agents is critical. In several recent studies of decentralized optimization methods, unfairness was conside-
red a criterion. We address an action selection method based on leximin cri teria, w hich reduces the unfairness
among agents, in decentralized reinforcement learning. We experimentally evaluated the eff ects and influences
of the proposed approach on classes of sensor network problems.
1 INTRODUCTION
Reinforcement learning has been studied as coopera-
tive learning and optimization methods in multiagent
systems (Hu and Wellman, 2003; Zhang and Lesser,
2011; Nguyen et al., 2014). In several frameworks of
multiagent reinfor c ement learn ing, the system’s en-
tire problem is decomposed into local problems fo r
agents. To choose an appropriate cooperative action,
the agents perform an o ptimization method that can
be perform ed in a distributed manner.
A class of networked distributed POMDPs was
defined for a sensor network domain (Zhang and Les-
ser, 2011), and in the reinforceme nt lea rning for such
problems, the joint actions of agents are selected
using the max-sum algo rithm (Farinelli et al., 2008),
which is a solution method for distributed constraint
optimization problems (DCOPs).
Similarly, Markovian dynamic DCOPs and their
solution method were proposed (Nguyen et al., 2014 ),
where distributed RVI Q -learning and R-learning al-
gorithms employed DPOP (Petcu and Faltings, 2005 ),
which is a lso a solution method of DCOPs, to select
the jo int actions of agents.
While the learning’s c onventional goal is the ma x-
imization of total rewa rds among agents, in practi-
cal resource allocation problem s, unfairness among
agents is crucial. In several recent studies of decen-
tralized optimization methods including D COPs, un-
fairness is deemed an important criterion (Netzer and
Meisels, 2013a; N e tz er an d Meisels, 2013b).
As a criterion of unfairness, leximin has been stu-
died (Moulin, 1988; Bouveret and Lemaˆıtre, 2 009).
The leximin defines the relationship between two vec-
tors in multi-objective optimization problems. Max-
imization on the leximin improves unfairness among
objectives. Extended classes of DCOPs applying lex-
imin criterio n and solution methods have been propo-
sed (Ma tsui et al., 20 14; Matsui et al., 2015).
In this study, we address an action selection met-
hod based on leximin cr iteria, which reduces the un-
fairness among agents, in decentralized reinforcement
learning. We experimentally evaluated the effects and
influences of the proposed approach on classes of sen-
sor network problems.
The remainder of this paper is organized as fol-
lows. The next section sh ows the background of our
study including reinforcement le arning with a dis-
tributed setting and criteria for the cooperative acti-
ons of agents. Section 3 describes a class of sen-
sor network problems for our motivatin g domain.
Our proposed approach is sh own in Section 4 . In
Section 5, o ur proposed methods are experimentally
evaluated. Related works and discussions are ad-
dressed in Section 6, and the study is concluded in
Section 7.
88
Matsui T. and Matsuo H.
A Study on Cooperative Action Selection Considering Unfairness in Decentralized Multiagent Reinforcement Learning.
DOI: 10.5220/0006203800880095
In Proceedings of the 9th International Conference on Agents and Artificial Intelligence (ICAART 2017), pages 88-95
ISBN: 978-989-758-219-6
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2 BACKGROUND
2.1 Reinforcement Learning with
Distributed Setting
Several types of reinforc ement learning have been ap-
plied to multiagent systems to optimize cooperative
policies among age nts. In several recent studies, mul-
tiagent reinforcem ent learning is modeled and solved
using a distributed manner (Zhang and Lesser, 2011;
Nguyen et al., 2014). Basically, these approaches re-
semble standard settings, while the lea rning tables are
distributed a mong agents. The optimal joint action is
determined u sin g a distributed optimiz a tion method.
Here we address a standard Q-learning as a base
of su c h a distributed version. The problem of Q-
learning consists of a set of states S, a set of actions
A, a function tab le of Q-values Q, r eward function R,
and an update rule:
Q
t+1
(s
t
, a
t
) = (1 − α)Q
t
+ α(r + γmax
a
Q
t
(s
t+1
, a)). (1)
s
t
∈ S and a
t
∈ A denote a joint state and a joint action
among agents at time step t. r is the reward that is
received from reward function R in an environme nt
when agents perform joint a ction a
t
at joint state s
t
.
The learning is adjusted by learning rate α and dis-
count rate γ. In each time step t, agents sense current
joint state s
t
and cho ose joint action a
t
from A. Af-
ter the agents perform action a
t
, they sen se next state
s
t+1
and obtain reward r from the environment. Ba-
sed on the reward and the next state, agents update
the Q-values for s
t
and a
t
. In this computation, op-
timal joint action a at joint state s
t+1
is chosen and
the corre sponding Q-value is propagated with the dis-
count ra te . The above processing is repeated until the
agents learn the environment’s informatio n.
To choose the next joint action at joint state s
t
,
several heuristics are employed based o n th e trade-
off between exploration and exploitation. With ε-
greedy heuristic, agents perform random walk with
probability ε and op timal joint action a
∗
such that
a
∗
= argmax
a
Q
t
(s
t
, a) with probability 1 − ε.
In a distributed setting, each agent i has a part of
states S
i
and actions A
i
, where ∪
i
S
i
= S and ∪
i
A
i
= A.
Note that, for i 6= j, S
i
∩ S
j
and A
i
∩ A
j
can be non-
empty sets. Local problems are related by this over-
lap. Each agent i has a function table of Q-values Q
i
for S
i
and A
i
. Also, partial reward function R
i
is de-
fined for S
i
and A
i
. An advantage of this setting is
that huge global jo int states a nd actions are approxi-
mated as sets of local joint states and actions. H owe-
ver, cooper a tion is necessary to cho ose an approp riate
global joint action, while each agent i updates Q
i
in-
dependently.
2.2 Cooperation based on Distributed
Constraint Optimization
To choose an appropriate global joint action, an op-
timization method that resembles distributed p roblem
solving is necessary. In the ca se of a ε-greedy he u-
ristic, age nts p e rform random walk or choose the glo-
bally optimal action. The latter case is represented as
a distributed constraint optimization problem (Modi
et al., 2005; Petcu and Faltings, 2005; Farinelli et al.,
2008; Zivan, 2008), which is a fu ndamental problem
in multiagent cooperation .
A distributed constraint optimization problem
(DCOP) is define d by (A , X, D, F). Here A is a
set of agents, X is a set of variables, D is a set of
domains of variables, and F is a set of objective
functions. The variables and functions are distri-
buted to the agents in A . Variable x
n
∈ X ta-
kes its values from its domain D
n
∈ D. Function
f
m
∈ F defines the utility values on several var ia bles.
X
m
⊂ X defines the set of variables in the scope of
f
m
. F
n
⊂ F defines a set of functions, where x
n
is
in their scope. f
m
is defined as f
m
(x
m0
, ·· · , x
mk
) :
D
m0
× ··· × D
mk
→ R, w here {x
m0
, ·· · , x
mk
} = X
m
.
f
m
(x
m0
, ·· · , x
mk
) is also denoted by f
m
(X
m
). Aggre-
gation F(X) of all the objective functions is defined
as F(X) =
∑
m s.t. f
m
∈F,X
m
⊆X
f
m
(X
m
). The goal is to
find a globally optimal assign ment that maximizes the
value of F(X).
Consider the pro blem for optimal joint action a
∗
such that a
∗
= argmax
a
Q
t
(s
t
, a). In distributed set-
tings, since the Q-values a re approx imated with local
Q-values, each agent i has Q
i,t
at time step t. Here
variable x
n
of a DCOP is defined for A
n
⊂ A
i
and D
n
correspo nds to A
n
. Note that agent i’s A
i
(and S
i
) can
overlap with different agent j’s A
j
(and S
j
). In this
case, partial set A
n
= A
i
∩ A
j
is sha red by both agents
and defined as domain D
n
of variable x
n
. On the ot-
her hand, function f
m
is defined for Q
i,t
. Namely,
f
m
(X
m
) = Q
i,t
(s
i,t
, a
i
), where s
i,t
is a vector of con-
stant values. While X
m
correspo nds to A
i
, X
m
overlaps
with the scopes of the functions in other age nts.
Since this problem resembles the computation of
max
a
Q
t
(s
t+1
, a) in Eq. (1), the same solution meth od
can be applied to both computations of a join t action
and learning.
Each agent locally knows the information of its
own variables and the related fun c tions in the initial
state. An optimization method in a distributed man-
ner computes the globally optimal solution. Several
solution methods have b een proposed f or DCOPs.
Here we employ a dynamic programming method that
computes the exact optimal solution.
A Study on Cooperative Action Selection Considering Unfairness in Decentralized Multiagent Reinforcement Learning
89

2.3 Optimization Criteria
In conventional multiagent reinf orcement learning,
the goal of the problem is to optimize the global sum
of the rewards. On the other hand, different studies
address the individuality of each age nt, such as the
Nash equilibrium (Hu and Wellman, 2003).
In several recent DCOP studies, fairness among
agents was addre ssed (Netzer and M e isels, 2013a;
Netzer and Meisels, 2013b; Matsui et al., 2014; Mat-
sui et al., 2015). Since the solution methods for such
classes of problems a re d esigned as distributed algo-
rithms, the pro blem of joint actions can be replaced
by problems based on fairness. In particular, optimi-
zation with th e leximin criterion (Moulin, 1988 ; Bou-
veret and Lemaˆıtre, 2009; Matsui et al., 2014; Matsu i
et al., 2015) shown below improves fairness among
agents. Here we refer the definitions in (Matsui et al.,
2015).
To address multiple o bjectives for agents, ob-
jective vectors are defined. Each value of an objective
vector corresponds to a utility value for an agent. Ob-
jective vector v is defined as [v
0
, ·· · , v
K
], wh ere v
j
is
an objective value. Vector F(X ) of objective functi-
ons is defined as [F
0
(X
0
), ··· , F
K
(X
K
)], where X
j
is
the subset of X on which F
j
is defined. F
j
(X
j
) is an
objective fun c tion for objective j. For assignment X ,
vector F(X ) of the functions returns a n objective vec-
tor [v
0
, ·· · , v
K
]. Here v
j
= F
j
(X
j
). In addition, the
objective vector is sorted to employ leximin. Based
on objective vector v, in a sorted objective vector, all
the values of v are sorted in ascending or der.
Based on the sorted objective vectors, the lexi-
min is defined as follows. Let v and v
′
denote the
vectors of identical length K + 1. Let [v
0
, ·· · , v
K
]
and [v
′
0
, ·· · , v
′
K
] denote the sorted vectors of v and v
′
.
Also, let ≺
leximin
denote the relation of the leximin
ordering. v ≺
leximin
v
′
if and only if ∃t, ∀t
′
< t, v
t
′
=
v
′
t
′
∧ v
t
< v
′
t
.
The maximization on leximin redu c es the unfair-
ness among the utility values among the agents by im-
proving the worst case utilities. Also, this criterion
chooses a Pareto optima l objective vector.
In several re source alloc ation problems, reducing
unfairness among age nts is an important criterion,
while such joint actions may not be compatible with
conventional reinforcement learning.
3 MOTIVATING DOMAIN
Considering several related works (Zhang and Les-
ser, 2011; Nguyen et al. , 2014), we define an example
problem motivated by sensor ne tworks, as shown in
1
32
x
1
f
3
x
3
x
2
f
1
f
2
Sensor Variable
Function
Area/Agent
1
2
3
Targets
Figure 1: Sensor network problem.
Fig. 1. The system consists of sensors, areas, and tar-
gets. Each sensor adjoins a few areas, and each are a
adjoins a few sensors. Here we assume for simplicity
that an area is related to two sensors, e a ch of which
can be simultaneously allocate d to one of the adjoi-
ning are as.
While a target stays in one of the areas, multip le
targets can be in the same area. The sensing event
is active and detected by targets. A target randomly
moves to one of th e other neighborhood areas of sen-
sors adjoining the current staying area when sensors
are alloc ated to the residing area. We only consider
whether an area is occupied by at least one target.
When an area is oc cupied by targets and allocated
with sensors, a r eward is given that corresponds to
the combination of allocated sensors. However, if an
empty area is a llocated by sensors, a small negative
reward is given. The goal of the problem is to improve
the global reward aggregated for all the areas.
This system is represented as a problem of multia-
gent r e inforcem ent lea rning. To represent cooperative
action, agent i corresponds to area i. In actual settings,
such an agent will be operated by a sensor node that
adjoins the a rea. States S
i
of agent i correspond to the
states of sensors adjoining area i. Ea ch pair of sta-
tes (s
a
k
, s
o
k
) ∈ S
i
is defined by the states o f sensor k.
s
a
k
represents the area to which sensor k is allocated.
s
o
k
represents whether sensor k detects that an area is
occupied b y the targets. Similarly, actions A
i
are ba-
sed on the areas to which the sensors are allocated.
Each action a
k
∈ A
i
represents the area to which sen-
sor k is allocated. Q
i
is defined for S
i
and A
i
. The
values of reward function R
i
are defined for area i, as
shown above.
The DCOP for a joint action at time step t is re-
presented as follows. Variable x
k
is defined for a
k
of
sensor k. Function f
i
(X
i
) is d efined for Q
i,t
(s
i,t
, a),
where x
k
∈ X
i
correspo nds to a
k
∈ A
i
.
In the example shown in Fig. 1, the sensor network
consists of three sensor s and three ar eas. The agent
of area 1 has states S
1
, actions A
1
, and Q-values Q
1
.
Since the states and actions are related to sensors 1
and 2, the local problem p artially overlaps with those
of other agents. In a DCOP, a variable corresponds to
the actions of a sensor, and a function corresponds to
a part of a table of Q-values.
ICAART 2017 - 9th International Conference on Agents and Artificial Intelligence
90

4 COOPERATIVE ACTION
CONSIDERING UNFAIRNESS
4.1 Applying Leximin Optimization
In this study, we apply a leximin operator for action
selection based on the unfairness among agents. In
a sensor network, when an occupied area is observed
by multiple sensors, a h igher reward is given for mo re
informa tion. On the other hand, such a concentra tion
decreases the number of observed areas. Namely, se-
veral occupied are as can b e ignored even if sma ller
rewards are given.
Since the global sum of utilities amon g agents
does not consider individual utilities, other criteria are
required in this situation. A comparison of unfairness
based on leximin is expected to handle th is case. On
the other hand, this action selec tion might be incom-
patible with the original reinforc e ment learning. A s
the first study, we experimentally evaluate the effect
and influence of such action selection.
For multiple ob jective problems, each objective
for agent i of area i corresponds to function f
i
. The-
refore, a sorted objec tive vector consists of the values
of f
i
for all agents, but the conventional case em ploys
the value’s to tal summation.
4.2 Solution Method
To so lve the DCOPs for action selection, we employ
a dynamic programming approach that can be per-
formed in a distributed manner (Matsui and Ma tsu o,
2014; Matsui et al., 20 15). Since the solution met-
hod’s basic framework is the same fo r both criteria,
we first briefly sketch the solution method for the
summation. A DCOP is represen te d as a factor graph,
which is a bipartite graph that consists of variable no-
des, function nodes, a nd edges. For the factor graph , a
pseudo- tree, which is a tree-like graph structure defi-
ning the (partial) order of nodes, is generate d (Fig. 2).
Here we assume that the root node is one of variable
nodes. If the topo logy of the original sensor network
is static, a single pseudo-tree can be reused for each
problem solving. The problem is decomposed based
on pseudo-trees. As a result, each node has a partial
problem consisting of the subtree rooted at the node.
The partial problem of the subtree is only related to its
higher nodes with cu t edges between the subtree and
higher nodes. The variables that corresp ond to the cut
edges are called separators.
Based on the se relations, eac h node performs part
of the dynamic programming th at consists of two pha -
ses. The first phase is performed in a bottom-up man-
ner. Each node aggregates function tables from its
x
1
f
3
x
3
x
2
f
1
f
2
Variable
Function
f
4
x
4
x
1
f
1
x
2
f
2
x
3
f
3
f
4
x
4
x
1
x
1
, x
2
x
1
, x
2
x
1
, x
3
x
1
, x
3
x
3
x
4
(1) DCOP (2) Pseudo Tree
Separator
Figure 2: Solution method.
child nodes, if they exist, and genera te s a function ta-
ble by adding the function values for each assignment
to the related variables. In addition, a fun c tion node
also aggregates its function with the function table
and maximizes the aggregated function table for non-
separator variables. As a result, a smaller function
table for just the separators is generated and sent to
the parent no de.
The second phase is performed in a top-down
manner. In the root (variable) node, the optimal as-
signment for the variable is determined from the ag-
gregated function table. Then the root agent sends
its optimal assignment to its child nodes. The child
nodes determine the optimal a ssignment to the rela-
ted non-separator variables, if necessary, and propa-
gate the optimal assignment, including those of hig-
her nodes, to its child node. The computational and
space complexity of the solution method is exponen-
tial with the number of sep a rators for each partial pro-
blem. However, we prefer the exact solution method
to choose one optimal solutio n.
By replacing the objective values and th e addi-
tion/maxim ization operator s to the sorted objective
vectors and extended operators, the solution method
solves the maximization problem on leximin crite-
rion. The addition operator is replaced by a co uple
of concatenate and resorting operators for objective
vectors. The maximization is based on leximin. Since
we use real va lues as Q-values, the opportunities for
tiebreaks in leximin comparisons will be less th an the
case of integer values. However, the leximin operator
continues to work.
4.3 Selection of Action in Learning
Equations
Since action selection based on leximin criterion is
different from the original one, it ma y be incompa-
tible with reinfor cement learning. In p articular, the
selection of an optimal joint action in Eq. (1) might
A Study on Cooperative Action Selection Considering Unfairness in Decentralized Multiagent Reinforcement Learning
91

Sensor
Area/Agent
(1) grid
(2) tree
Figure 3: Topologies of problems.
be corrup ted, but the actual action selection can be
considered an exploration strategy.
To remove such influence from the learning equa-
tion, discount rate γ can be set to zero. Another ap-
proach is to employ the original optimization criterion
for the learning equation. I n this case, how the exp lo-
ration strategy b ased on leximin affects the original
method w ill be evaluated.
5 EVALUATION
5.1 Problem Settings
We experime ntally evaluated the effects and the in-
fluences of our proposed approach and evaluated the
following topologies of senso r network pro blems.
• grid: We placed sensors at the grid vertices and
the areas at the edges (Fig. 3 (1)). Since this to-
pology easily increases the number of separators,
we limit the size to 3 × 3 sensors.
• tree: A small tree is designed based on the capa-
city of the sensor resources. Similar to the grids,
sensors and areas are place d at the tree’s verti-
ces and edges. When two sensors are allocated to
an a rea in the center of this network, at least one
sensor c an be alloca ted to all of the other areas
((Fig. 3 (2)).
• tree-like: In addition to a randomly generated
tree, a few edges/areas are contained to compose
cycles.
To reduce the size of the state and action spaces, we
limited the problems so that an are a adjoins two sen-
sors. The number of targets was set to the number
of areas based on the average occ upancy ratio for the
areas.
We set the rewards f or the areas as follows.
• 0-2: When an occupied are a is sensed by one sen-
sor, no reward is given, and in the case of two sen-
sors a reward of 2 is given.
• 1-2: When an occupied area is sensed by one and
two sensors, rewards of 1 and 2 are given.
50
100
150
200
250
0 5000 10000
global rewards
steps
sum
leximin
Figure 4: Global reward (grid, 0-2, γ = 0).
Table 1: Global reward and allocated sensors to occupied
areas in last quarter steps (grid, 0-2, γ = 0).
alg. rwd. num. of rwd. num. of alc. sns. rate. of
≤0 2 0 1 2 occ.
sum 10722 24636 5364 5997 2332 5364 0.46
leximin 9006 25494 4506 6546 2918 4506 0.47
• 2-2 0-2: The areas are categorized into two types.
In most occupied areas, when one is sensed by
one or two sensors, a reward of 2 is given. On the
other hand, in one area, th e reward is defined as
0-2.
• 2-2 1-2: Similar to 2-2 0-2, the areas are catego-
rized, and the reward is defined as 1-2 in one area.
When a no n-occupied area is sensed, a small negative
reward −1.0
−3
is given.
We compared the following solution methods f or
action selection.
• sum: the summation is employed for both actual
actions and learning.
• leximin: the leximin is employed for both action
selections.
• lxmsum: the leximin and the summation are used
for the actual actions and the learning.
In a ddition, we compa red cases where discount ra te γ
is 0 and 0.5. The probab ility ε of random walk and
learning rate α were set to 0.2 and 0.2. These p ara-
meters are chosen based on preliminary experiments
so that several typical cases ar e shown. We performed
ten trials for the same problem. Each trial consisted of
10000 steps of joint actions. The r e sults were avera-
ged for the trials.
5.2 Results
First we evaluated the case of grid with a set of reward
0-2. He re discount rate γ was set to zero. Fig. 4 shows
ICAART 2017 - 9th International Conference on Agents and Artificial Intelligence
92
50
100
150
200
250
0 5000 10000
global rewards
steps
sum lxmsum leximin
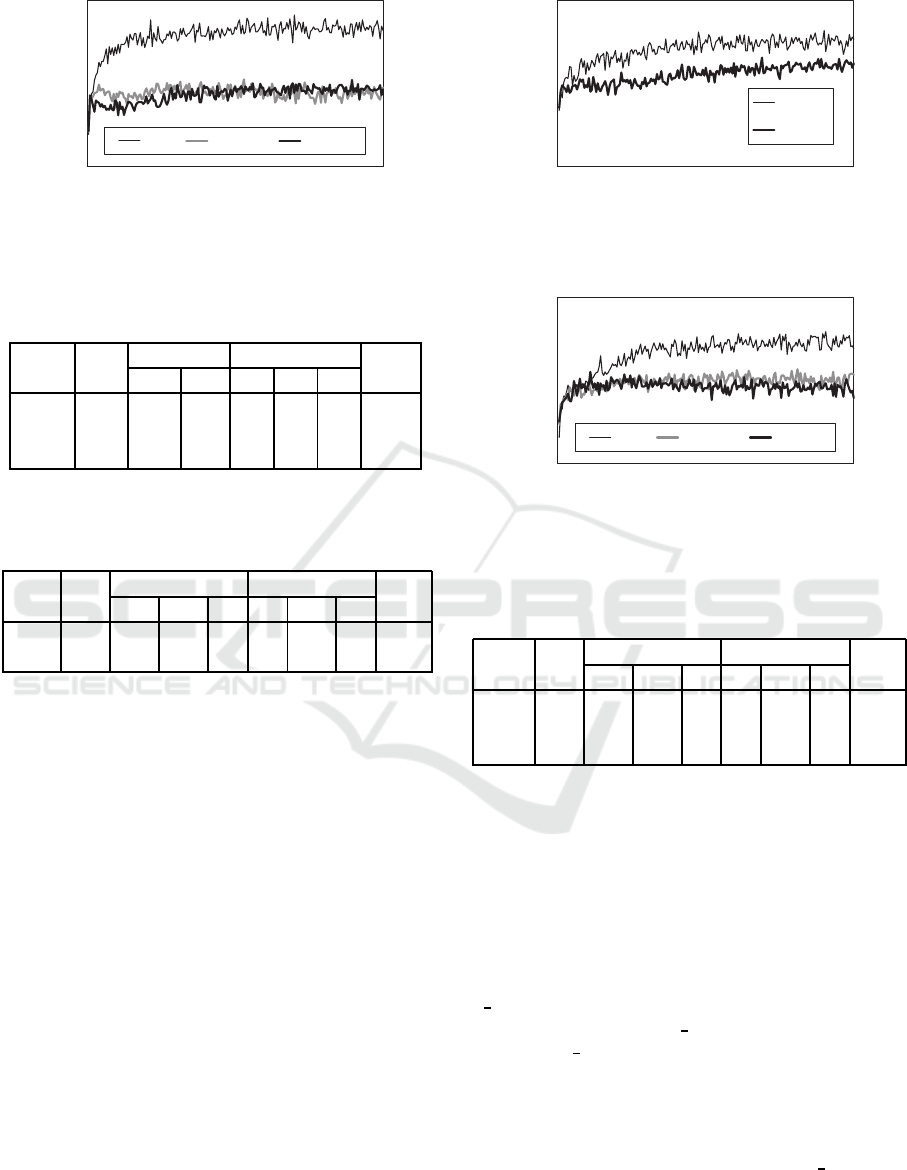
Figure 5: Global reward (grid, 0-2, γ = 0.5).
Table 2: Global reward and allocated sensors to occupied
areas in last quarter steps (grid, 0-2, γ = 0.5).
alg. rwd. num. of rwd. num. of alc. sns. rate. of
≤0 2 0 1 2 occ.
sum 10830 24582 5418 6209 2255 5418 0.47
lxmsum 6880 26556 3444 7101 2976 3444 0.47
leximin 7163 26415 3585 7027 4494 3585 0.50
Table 3: Global reward and allocated sensors to occupied
areas in last quarter steps (grid, 1-2, γ = 0).
alg. rwd. num. of rwd. num. of alc. sns. rate. of
≤0 1 2 0 1 2 occ.
sum 15270 17976 8773 3251 4863 8773 3251 0.56
leximin 14261 16205 13322 474 3696 13322 474 0.58
the global reward among the agents for 50 steps. Ta-
ble 1 shows the summation of the global rewards in
the last 2500 steps (rwd.), the histograms of the re-
wards (num. of rwd.), the histograms of the number of
allocated sensors to the o ccupied a reas (num. of alc.
sns.), and the occupancy ratio for all the ar e as (rate. of
occ.). Since this problem contains only single types of
rewards, conventional summation well works. In ad-
dition, a few areas can be c overed by two sensors, but
rewards are given only for two allocated sensors. In
such c a ses, a leximin strategy is less effective.
Next we evaluated the same problem with γ = 0.5 .
Fig. 5 and Table 2 show the results. The result also
contains the case of lxmsum. In this case, the reward
of leximin decreased less tha n the case of γ = 0. This
reveals that action selection based on leximin in lear-
ning did not improve the result. Also, lxmsum, which
employed conventional summation for learning, was
not effective in average.
The next case is grid with 1-2. In this p roblem,
sensors can cover most areas earning at least a reward
of 1. Fig. 6, Table 3, Fig. 7, and Tab le 4 show the re-
sults. leximin improved the coverage of the areas by
200
220
240
260
280
300
320
340
0 5000 10000
global rewards
steps
sum
leximin
Figure 6: Global reward (grid, 1-2, γ = 0).
200
250
300
350
0 5000 10000
global rewards
steps
sum lxmsum leximin
Figure 7: Global reward (grid, 1-2, γ = 0.5).
Table 4: Global reward and allocated sensors to occupied
areas in last quarter steps (grid, 1-2, γ = 0.5).
alg. rwd. num. of rwd. num. of alc. sns. rate. of
≤0 1 2 0 1 2 occ.
sum 15454 18513 7516 3972 5206 7516 3972 0.56
lxmsum 13787 17899 10408 1693 4861 10408 1693 0.56
leximin 13401 17699 11192 1108 4688 11192 1108 0.56
decreasing the global rewards. In this case, lxmsum
was slightly closer to sum than leximin. From this
result, action selection based on leximin is relatively
effective in simple cases, where the rewards are ea-
sily decreased to improve the worst case agen ts. For
this kind of settings, similar re sults we re obtained in
several other topologies including tree-like.
As a different setting, we evaluated tree with 2-
2
0-2. In this problem, an area in the center of the net-
work obtains rewards of 0
2, while other ar eas obtain
rewards of 2 2. Table 5 shows that leximin improved
the coverage of the areas. In addition, the total reward
of the ar ea in the center improved. On the other hand,
for γ = 0.5, the leximin result is worse than sum, as
shown in Table 6.
Similarly, we evaluated tree with 2-2
1-2. Ta-
bles 7 and 8 show the results. In this case, the num ber
of reward 1 increa sed, although we expected that the
total r eward of the area in the ce nter would improve.
A Study on Cooperative Action Selection Considering Unfairness in Decentralized Multiagent Reinforcement Learning
93
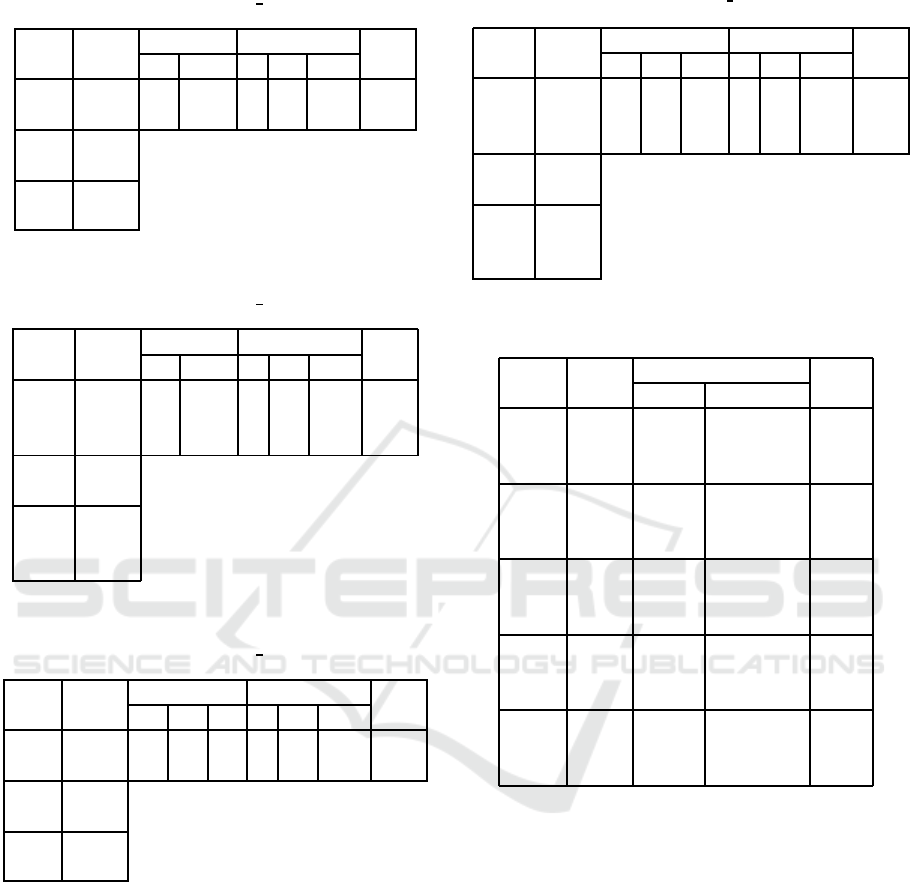
Table 5: Global reward and allocated sensors to occupied
areas in last quarter steps (tree, 2-2
0-2, γ = 0).
alg. rwd. num. of rwd. num. of alc. sns. rate. of
≤0 2 0 1 2 occ.
sum 20288 7353 10147 447 8148 2246 0.62
leximin 21176 6909 10591 268 8561 2204 0.61
alg. rwd. of
cnt. area
sum 2951
leximin 3454
Table 6: Global reward and allocated sensors to occupied
areas in last quarter steps (tree, 2-2
0-2, γ = 0.5).
alg. rwd. num. of rwd. num. of alc. sns. rate. of
≤0 2 0 1 2 occ.
sum 20889 7052 10448 320 8477 2214 0.63
lxmsum 19953 7520 9980 490 8121 2203 0.61
leximin 20076 7459 10041 469 8128 2231 0.62
alg. rwd. of
cnt. area
sum 3220
lxmsum 2671
leximin 2764
Table 7: Global reward and allocated sensors to occupied
areas in last quarter steps (tree, 2-2
1-2, γ = 0).
alg. rwd. num. of rwd. num. of alc. sns. rate. of
≤0 1 2 0 1 2 occ.
sum 20052 7084 774 9642 420 8356 2060 0.62
leximin 20148 6648 1550 9303 237 9098 1754 0.63
alg. rwd. of
cnt. area
sum 2707
leximin 2318
Instead, the coverage of the are a s improved b y decre-
asing the rewards of the center area. The result reveals
that simple action selection based on leximin does no t
easily adapt to relatively c omplex cases.
Table 9 shows the computational cost of the so-
lution method. Here the maximum degree of sen-
sors in tree-like was limited to three. Five instan-
ces we re also averaged for each setting of tree-like.
For grid, a pseudo tree was generated using a zig-
zag order from the left-top variable, while a maxi-
mum degree heuristic was employed f or other graphs.
The experiments were performed on a single compu-
ter with Core i7-3930K CPU @ 3.20GHz, 16GB me-
Table 8: Global reward and allocated sensors to occupied
areas in last quarter steps (tree, 2-2
1-2, γ = 0.5).
alg. rwd. num. of rwd. num. of alc. sns. rate. of
≤0 1 2 0 1 2 occ.
sum 20863 6754 623 10123 293 8661 2085 0.63
lxmsum 20317 6751 1174 9575 279 8864 1885 0.63
leximin 20338 6752 1151 9597 278 8836 1912 0.63
alg. rwd. of
cnt. area
sum 3126
lxmsum 2610
leximin 2616
Table 9: Computational cost.
prb. alg. max. sz. of separator comp.
variables combinations time [s]
grid sum 4 72 7.37
lxmsum 4 72 10.59
leximin 4 72 13.77
tree sum 1 4 0.56
lxmsum 1 4 0.67
leximin 1 4 0.77
tree-like sum 4 103 8.83
15 sns. lxmsum 4 103 13.28
20 areas leximin 4 103 18.01
tree-like sum 4 92 9.58
20 sns. lxmsum 4 92 15.15
25 areas leximin 4 92 20.63
tree-like sum 3 23 8.62
50 sns. lxmsum 3 23 13.80
55 areas leximin 3 23 19.47
mory, Linux 2.6.32 and g ++ 4.4.7. Note that our cur-
rent experimental impleme ntation can be improved.
The bottleneck of th e solu tion methods is the optimi-
zation method for action selection. Since the time and
space complexity o f dynamic progr amming exponen-
tially increases w ith the number of separators, large
and dense problems will need relaxations.
6 RELATED WORKS AND
DISCUSSIONS
This study was motivated by several previous studies
that addressed sensor network domains (Zhang and
Lesser, 2011; Ngu yen et al., 2014). Since those stu-
dies employed dedicated problems, we designed a re-
ICAART 2017 - 9th International Conference on Agents and Artificial Intelligence
94

lative simple one. Our setting of learning methods
relatively depend s on the random walk of ε-greedy
heuristics because of the activities of targets. In ad-
dition, we set a number of ta rgets so that almost half
of the areas are occupied, since unfairness depends on
resource capacities. Investigations of different classes
of problems will be future works.
Several studies such a s Nash-Q learning (Hu an d
Wellman, 2003) have addressed the individuality of
agents. While such studies mainly foc us on selfish
agents, we are interested in co operative a ctions by
considerin g u nfairness. As a first study, we addressed
the effects and influence of action selection based on
leximin that can be applied in a dec e ntralized man ner.
On the other hand, the results reveal the necessity
of dedicate d learning rules; in simple cases our pro-
posed approach has some effects. Since unfairness
depends on the values in Q-tables, more discussion s
for the case of leximin are necessary. In particular,
some normalization methods, for different progre sses
of leaning in individual agents, are possibly important
for the case of fairness.
We employed an exact solution method to select
joint ac tions. However, for large and c omplex pro-
blems, approximation methods are necessary, since
the time and space complexity of the exact method ex-
ponen tially incr eases with the nu mber of separators.
Such approximation is a lso considered as a ch allen-
ging problem.
7 CONCLUSIONS
We addressed action selection b ased on unfairness
among agents in a decentralized reinfo rcement lear-
ning framework and experimentally investigated the
effect and the influen ce of leximin criterion in action
selection. Even thoug h the proposed approach ef-
fectively worked in relatively simple settings, our re-
sults uncovered several exploration and learning is-
sues. Our future works will analyze the rela tionship
between the proposed cooperative action and learning
rules and applications to other problem domains. Im-
provement of learning rules to man a ge informatio n
of unfairness, and scalable solution methods for joint
action selection will also be im portant challenges.
ACKNOWLEDGEMENTS
This work was supported in par t by JSPS KA K ENHI
Grant Number JP16K00301.
REFERENCES
Bouveret, S. and Lemaˆıtre, M. (2009). Computing leximin-
optimal solutions in constraint networks. Artificial In-
telligence, 173(2):343–364.
Farinelli, A., Rogers, A., Petcu, A., and Jennings, N. R.
(2008). Decentralised coordination of low-power em-
bedded devices using the max-sum algorithm. In 7th
International Joint Conference on Autonomous Agents
and Multiagent Systems, pages 639–646.
Hu, J. and Wel lman, M. P. (2003). Nash q-learning for
general-sum stochastic games. J. Mach. Learn. Res.,
4:1039–1069.
Matsui, T. and Matsuo, H. (2014). Complete dist r ibuted
search algorithm for cyclic factor graphs. In 6th In-
ternational Conference on Agents and Artificial Intel-
ligence, pages 184–192.
Matsui, T., Silaghi, M., Hirayama, K., Yokoo, M., and Mat-
suo, H. (2014). Leximin multi ple objective optimiza-
tion for preferences of agents. In 17th International
Conference on Principles and Practice of Multi-Agent
Systems, pages 423–438.
Matsui, T., Silaghi, M., Okimoto, T., Hirayama, K., Yokoo,
M., and Matsuo, H. (2015). Leximin asymmetric mul-
tiple objective DCOP on factor graph. In Principles
and Practice of Multi-Agent Systems - 18th Internati-
onal Conference, pages 134–151.
Modi, P. J., Shen, W., Tambe, M., and Yokoo, M. (2005).
Adopt: Asynchronous distributed constraint optimi-
zation with quality guarantees. Artificial Intelligence,
161(1-2):149–180.
Moulin, H. (1988). Axioms of Cooperative Decision Ma-
king. Cambridge : Cambridge University Press.
Netzer, A. and Meisels, A. (2013a). Distributed Envy Mi-
nimization for Resource Allocation. In 5th Internati-
onal Conference on Agents and Artificial Intelligence,
volume 1, pages 15–24.
Netzer, A. and Meisels, A. (2013b). Distributed Local Se-
arch for Minimizing Envy. I n 2013 IEEE/WIC/ACM
International Conference on Intelligent Agent Techno-
logy, pages 53–58.
Nguyen, D. T., Yeoh, W., Lau, H. C., Zilberstein, S., and
Zhang, C. (2014). Decentralized multi-agent r einfor-
cement l earning in average-reward dynamic dcops. In
28th AAAI Conference on Artificial Intelligence, pages
1447–1455.
Petcu, A. and Faltings, B. (2005). A scalable method for
multiagent constraint optimization. In 19th Internati-
onal Joint Conference on Artificial Intelligence, pages
266–271.
Zhang, C. and Lesser, V. (2011). Coordinated multi-
agent reinforcement learning in networked distributed
pomdps. In 25th AAAI Conference on Artificial Intel-
ligence, pages 764–770.
Zivan, R. (2008). Anytime local search for distri buted con-
straint optimization. In Twenty-Third AAAI Confe-
rence on Artificial Intelligence, pages 393–398.
A Study on Cooperative Action Selection Considering Unfairness in Decentralized Multiagent Reinforcement Learning
95
