
A Tracking Approach for Text Line Segmentation in Handwritten
Documents
Insaf Setitra, Zineb Hadjadj and Abdelkrim Meziane
Research Center on Scientific and Technical Information, CERIST, Algiers, Algeria
{isetitra, zhadjadj, ameziane}@cerist.dz
Keywords:
Tracking, Connected Components, Angle Minimization, Segmentation, Line, Handwritten, Prediction.
Abstract:
Tracking of objects in videos consists of giving a label to the same object moving in different frames. This
labelling is performed by predicting position of the object given its set of features observed in previous frames.
In this work, we apply the same rationale by considering each connected component in the manuscript as a
moving object and to track it so that to minimize the distance and angle of of the connected component to
its nearest neighbour. The approach was applied to images of ICDAR 2013 handwritten segmentation contest
and proved to be robust against text orientation, size and writing script.
1 INTRODUCTION
Text line segmentation is considered a non-trivial task
to solve the field of handwritten document recog-
nition (Stamatopoulos et al., 2013). By and large,
many challenges can occur when segmenting hand-
written document images such as skew in text lines
and adjacency of text lines. To solve some of the
text line segmentation challenges, literature count a
variety of text line segmentation techniques. Li et al.
(Li et al., 2008) proposed an approach for handwrit-
ten text line segmentation using level sets. Goto and
Aso (Goto and Aso, 1999) proposed a local linearity
based method to detect text lines in English and Chi-
nese documents. In the method proposed by Hones
and Litcher (H
¨
ones and Lichter, 1994), text lines are
generated by expanding the line anchors of the doc-
ument image. The previously cited methods cannot
handle variable sized text, which is the main draw-
back.
Roy et al. (Roy et al., 2012) proposed text line
extraction using foreground and background infor-
mations. Louloudis et al. (Louloudis et al., 2007)
used a block-Based Hough Transform for text line
extraction. In the method proposed by Loo and Tan
(Loo and Tan, 2002) the irregular pyramids are used
for text line segmentation. Recently, Bukhari et al.
(Bukhari et al., 2008) proposed a line segmentation
approach for camera-based warped documents using
active contour models. Gatos et al. (Gatos et al.,
2007) proposed an algorithm based on text line and
word detection for warped documents. Bai et al. (Bai,
2008) used a traditional perceptual grouping-based al-
gorithm for extracting curved lines. Pal and Roy (Pal
and Roy, 2004) proposed a head-line based technique
for multi-oriented (printed in several orientations) and
curved text lines extraction from Indian documents.
In other work, Pal et al. (Pal et al., 2003) developed
a system for English multi-oriented text line extrac-
tion estimating the equation of the text line from the
character information.
Although cited approaches ware competitive, they
still lack universality and the problem of text lines
especially in curved document remains open. This
paper describes a new approach inspired of tracking
works to detect lines in handwritten document im-
ages.
Basically, tracking is the process of following ob-
jects through an image sequence (Mitiche and Ag-
garwal, 2014). The earliest methods were focussed
on following the trajectory of a few feature points
through the sequence. Examples include Kalman fil-
ter (Bar-Shalom, 1987) (Broida and Chellappa, 1986)
(Boykov and Huttenlocher, 2000) and are applied in
areas such as in (Li et al., 2010) and (Zheng et al.,
2012).
In our approach, each cluster of connected pixels
(which can be a word or a part of a word) is consid-
ered as a moving object and it seeks for its best match
which satisfies a trajectory angle. Position of the clus-
ter (defined as a connected component in the remain-
ing of the paper) is predicted using prevision position
and angle between previous and current observation
must be minimized in order to have a best match of
Setitra, I., Hadjadj, Z. and Meziane, A.
A Tracking Approach for Text Line Segmentation in Handwritten Documents.
DOI: 10.5220/0006199001930198
In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2017), pages 193-198
ISBN: 978-989-758-222-6
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
193

the current cluster. Clusters are tracked and matched
pair to pair until the end of the document and lines
are result of that matching. We benefit from tracking
rationale where we predict position of clusters accord-
ing to their history, and avoid tracking issues since we
do not count on any feature of the cluster which is ob-
vious since clusters (words or parts of words in the
handwritten document image) need not necessarily to
be similar in shape or be a weak deformation of their
best matches.
We explain more deeply our approach in section 2.
We give a preliminary set of tests and criticize them
in section 3 and conclude in section 4.
2 OUR APPROACH
Input of our algorithm are binary manuscript images,
the first step is then not to segment images, but in-
stead, extract directly connected components that will
be tracked over the manuscript image. Connected
components are in our case sets of pixels that have
a 4 connectivity link. We also remove small regions
of connected components since they can false our line
segmentation. Examples of such regions include dots
(dark pink dots in figure 1.). As a result of this first
step, we have a set of connected components each rep-
resented by row and column indices of the connected
component center (yellow dots in figure 1.). In or-
der to group each set of connected components into a
line, we first perform a binary matching of each pair
of connected components so that each pair is in the
same line. Connected components are assumed to be
in the same line if they are spatially close to each other
and if the angle they produce with their origin is be-
low a certain threshold.
More specifically, Let X = {x
1
, x
2
, ...x
n
} be a set
of connected component centers s.t. x
i
=
x
i
1
x
i
2
is a
2−dimensional vector representing index of line and
index of column of center x
i
.
Let also D(x
k
, x
i
) be the Euclidean distance between
x
k
and x
i
where i ranges from 1 to n and k is an random
value chosen from 1 to n. D(x
k
, x
i
) is computed as
follows:
D(x
k
, x
i
) =
q
(x
k
1
− x
i
1
)
2
+ (x
1
2
− x
i
2
)
2
(1)
By sorting D(x
k
, x
i
) and taking the first N points
which satisfy this sorting, we will have a subset of X
with N elements each representing a connected com-
ponents the closest to x
k
.
Le Y = y
1
, y
2
, ..., y
N
be the set of N closest con-
nected components to x
k
. Geometrically, this set can
Figure 1: Example of connected component analysis for
line segmentation. Red region: connected component to
be matched. Gray circle: region of interest which is the set
of connected components nearest to connected component
to be matched (red region) centred at it. The region of in-
terest include small connected components to be removed
(pink regions) and connected component to be considered
for comparisons and matching (blue regions). Black regions
are connected components far from the connected compo-
nent to be matched (red region) and are not considered for
comparisons and matching. Yellow dots are centres of con-
nected components. Note that centres of connected com-
ponents are put only for visualization and are not effective
centres returned by our implementation.
be seen as a polygon centered at x
k
and having at most
N − 1 vertices; number of vertices can be less than
N − 1 because some vertices can be aligned. From
the set Y , we would like to get the best match of x
k
to
one of y
i
, i.e. we would like to know if x
k
and y
i
are
aligned and how close they are. We do this by com-
puting the inner angle between x
k
, y
i
and the origin
x
0
.
If x
k
is the first element of X , then, x
0
has coordi-
nates x
0
1
and x
0
2
= x
k
2
+1. This means that x
0
is aligned
to x
k
and y
i∗
(the best match to x
k
) must minimize the
inner angle with the horizon. We choose x
0
aligned to
x
k
because, for the first element, we suppose that the
writing in the manuscript is horizontal. We treat the
case where the writing takes another direction (say up
to the right or down to the right) by taking the his-
tory of Y later on. We explain more specifically how
we compute and minimize the angle between x
k
and
y
i
as follow. We keep the same notation as previously
and use (without justification) some basic notions of
geometry.
The inner angle between x
k
, x
0
and y
i
centered at
x
k
can be derived as follows.
First, the vector between x
k
and x
0
is computed
using:
−−→
x
0
x
k
= x
0
− x
k
(2)
−−→
x
0
x
k
=
x
0
1
x
0
2
−
x
k
1
x
k
2
(3)
ICPRAM 2017 - 6th International Conference on Pattern Recognition Applications and Methods
194
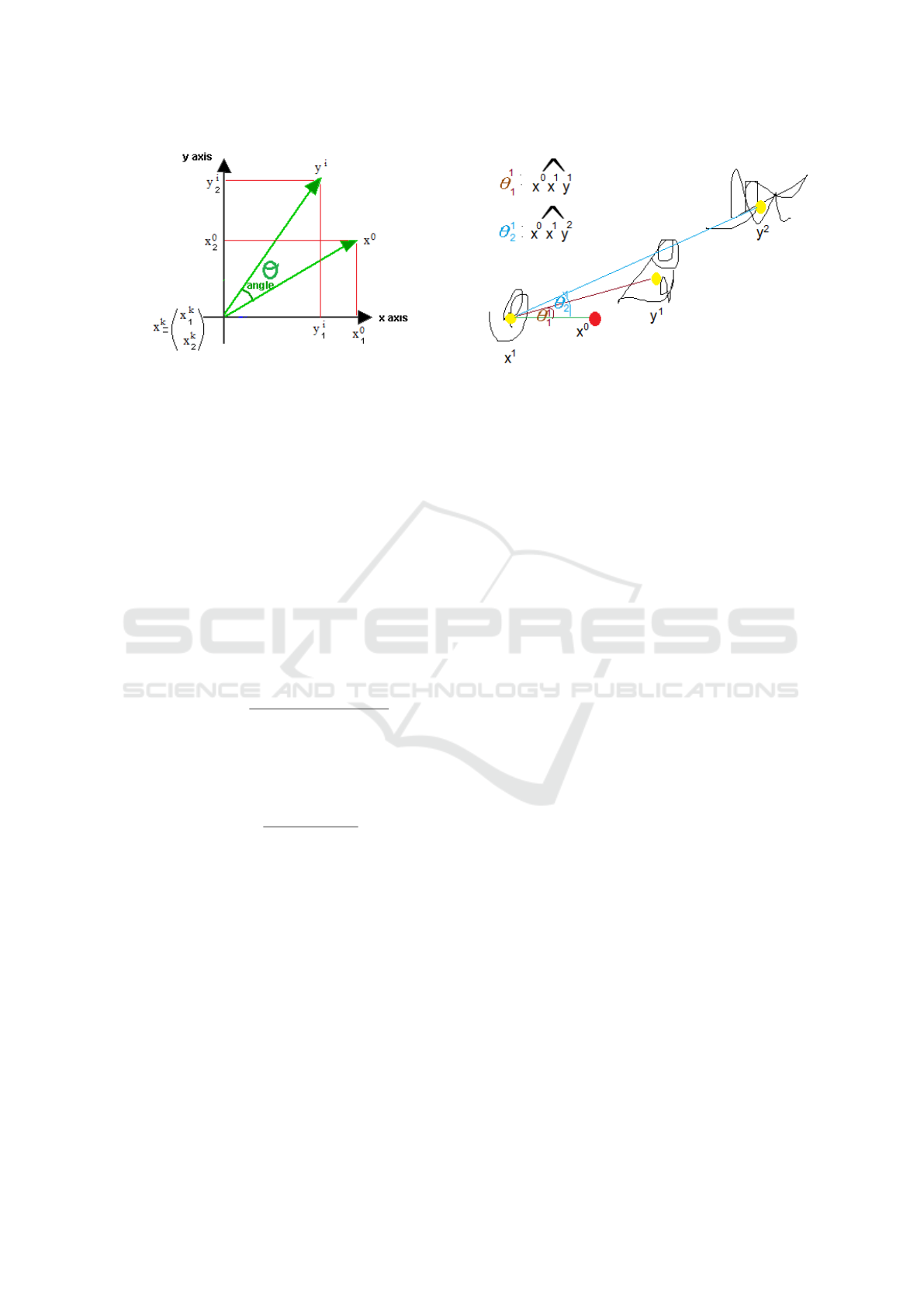
Figure 2: Example of
\
x
0
x
k
y
i
computation; the inner angle
between x
0
, x
k
and y
i
centred at x
k
.
Then, the vector between x
k
and y
i
is computed using:
−→
x
k
y
i
= x
k
− y
i
(4)
−→
x
k
y
i
=
x
k
1
x
k
2
−
y
i
1
y
i
2
(5)
The dot product of
−−→
x
0
x
k
and
−→
x
k
y
i
is given by
−−→
x
0
x
k
.
−→
x
k
y
i
=k
−−→
x
0
x
k
kk
−→
x
k
y
i
k cosθ (6)
where
\
x
0
x
k
y
i
is the inner angle between x
0
x
k
y
i
cenered
at x
k
and k
−−→
x
0
x
k
k is length of the vector
−−→
x
0
x
k
and is
computed as:
k
−−→
x
0
x
k
k=
q
(x
0
1
− x
k
1
)
2
+ (x
0
2
− x
k
2
)
2
(7)
k
−→
x
k
y
i
k is computed the same way.
From equation 6, we can have the angle θ as follows:
θ = arcos
−−→
x
0
x
k
.
−→
x
k
y
i
k
−−→
x
0
x
k
kk
−→
x
k
y
i
k
(8)
Figure 2 shows a general case of computation of
angle between two the three points (
\
x
0
x
k
y
i
). In the
case of the figure, x
0
is not the horizontal axis but
instead an arbitrary point in the space.
Once angles between x
k
and all y
i
computed, the
next step is to choose the best match of x
k
to one of y
that minimizes the angle computed previously as fol-
lows: While x
k
and x
0
are fixed for the point x
k
, the
only variable is y
i
. Let then θ in equation 8 be equal
to f (y
i
). Minimization of the angle (θ = f (y
i
)) is then
subject to y
i
and is performed as follows:
argmin
y
i
∈Y
f (y
i
) := {y
∗
ky
∗
∈ Y ∧∀y
i
∈ Y : f (y
∗
) ≤ f (y
i
)}
(9)
Figure 3: Example of angle minimization when x
k
is the
first connected component center in X. Black regions are
connected components and yellow regions are centres of
each connected component.
Figure 3 shows and example of this minimization. In
the figure y
1
was chosen as the best match to x
1
since
θ
1
1
(the angle
\
x
0
x
1
y
1
) was smaller than θ
1
2
(the angle
\
x
0
x
1
y
2
).
In a more general case, we choose y
∗
that min-
imizes the angle between the origin x
0
and current
point to match x
k
. A further refinement is done where
if the angle constituted by x
k
and y
∗
with the origin
is higher than a certain threshold ε
θ
, the matching is
rejected. Note that, this threshold is initialized to +∞.
We update this ε
θ
after we accept the first match.
Once the first match of x
k
to y
∗
is chosen, update
of ε
θ
is necessary. ε
θ
in this step will be the angle
\
x
0
x
k
y
∗
). Update of threshold is necessary because
if we accept the minimum angle without threshold-
ing, then we can match a connected component in
the end of the line to a connected component of an-
other line. Thresholding allows stopping tracking of
the connected component especially when the line in
the manuscript ends.
At this point, the matching will result in a
3−dimensional vector where first dimension is x
k
,
second is y
∗
and third dimension is
\
x
0
x
k
y
∗
.
When x
k
is not the first point to be matched, then,
to get the history of x
k
we look at the first previous
neighbour of x
k
which is x
k−1
.
The process starting from the choice of k in x
k
to
the angle minimization step is repeated to all points in
X.
For remaining points in X, one obvious obser-
vation is that, remaining points will have a history,
i.e. at least one previous point in X has already been
matched. This is crucial to know the writing style in
the manuscript. For example, if the writing in the
manuscript was from going from up to down of the
page, then, the origin x
0
will not be the horizontal line,
A Tracking Approach for Text Line Segmentation in Handwritten Documents
195
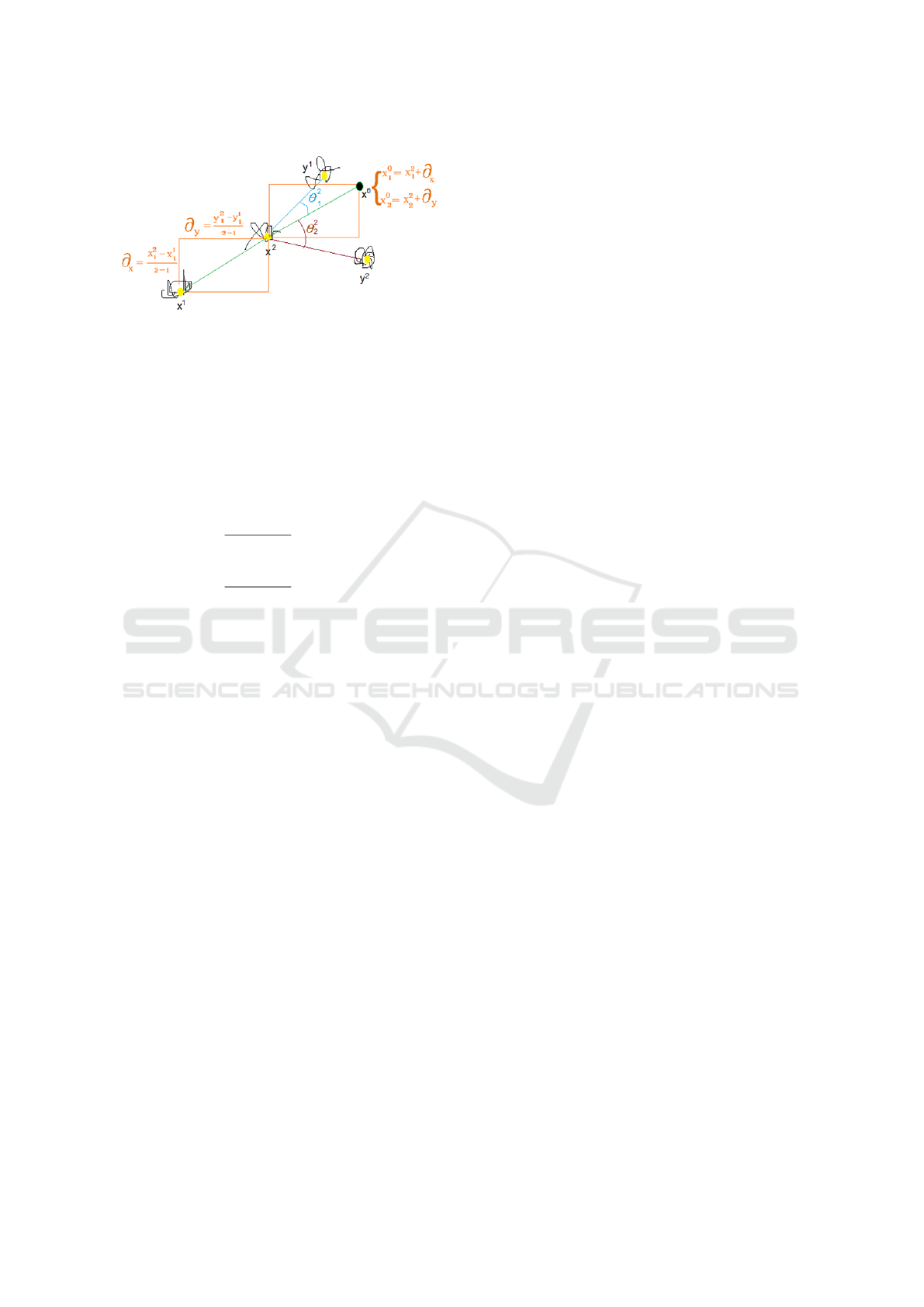
Figure 4: Example of angle minimization when x
k
is not
the first connected component center in X (angles have his-
tory). Black regions are connected components and yellow
regions are centres of each connected component. The best
match of x
1
is given to y
1
.
but will instead, will be calculated as follows:
Let x
k
be the point to be matched and x
k
−1 be the first
previous neighbour of x
k
. To compute the hostory of
writing i.e. the previous angle, we need to compute x
0
coordinate. coordinates of x
0
as computed as follows:
∂x =
x
k
1
− x
k−1
1
k − (k − 1)
= x
k
1
− x
k−1
1
(10)
∂y =
y
k
1
− y
k−1
1
k − (k − 1)
= y
k
1
− y
k−1
1
(11)
where ∂x and ∂x are displacement from x
k−1
to x
k
in
the horizontal axis and vertical axis respectively.
x
0
coordinates can then be computed as follows:
(
x
0
1
= x
k
1
+ ∂x
x
0
2
= x
k
2
+ ∂y
(12)
where x
0
1
and x
0
2
are the row and column indices of x
0
respectively.
This computation is important since we would like
to keep history of writing which is based in the pre-
vious matching. This follows the principle of dif-
ferent types of tracking especially the Kalman filter
[ref] which keeps history of previous observations.
Note that our approach is different from tracking ap-
proaches as we do not keep a whole history but only
the previous observation of angle which is most simi-
lar to Hidden Markov models approaches.
Once x
0
coordinates computed, the same process
is repeated to get the best match of x
k
. Figure 4 shows
an example of x
0
computation and getting the best
match according to the angle history. In the figure,
the best match would be given to y
1
instead of y
2
al-
though the angle between x
1
, y
1
and the x − axis is
bigger than the one between x
1
, y
2
and the x − axis,
but since the matching follows same pattern as previ-
ous matching, the best match is given to y
1
.
3 EXPERIMENTAL RESULTS
We tested our approach on images of ICDAR 2013
Handwriting Segmentation Contest, (Stamatopoulos
et al., 2013). The dataset consists of 150 document
images written in English and Greek as well as 50
images written in Bangla along with the associated
ground truth for training and 50 images written in En-
glish, 50 images written in Greek and 50 images writ-
ten in Bangla for test (Stamatopoulos et al., 2013).
The dataset is challenging in that the skew angle be-
tween text lines and within the same line is different.
We implemented our approach in matlab 2010
and we choose in our approach the angle threshold
ε
θ
= 0.2
o
, number of neighbours of the connected
component to track as N = 20 and minimum size of
the connected components as 200 pixels.
In the experimental phase, we draw a blue line
between each pair of centres of matched connected
components found in section 2. When lines are cu-
mulated, they show clearly direction of motion of
words (connected components that we matched pre-
viously). Although visual observation can prove ro-
bustness of the approach, quantitative analysis is nec-
essary to validate the approach and extend it to other
datasets. We did not include the quantitative analysis
in this work because our approach links only pairs of
lines. If we apply the software proposed in the contest
as described in section II and III of (Stamatopoulos
et al., 2013) and in (con, ) we would have a low accu-
racy. This is because each pair of connected compo-
nents would be considered as a line. In order to solve
this issue we propose two solutions: either to cluster
blue lines (between matched connected components)
so that each cluster constitute a line in the handwrit-
ten document, or to track, among all pairs, the first
connected component so that to have a complete tra-
jectory of it in the line. We leave this improvement
to a future work while we present here only the main
steps of the approach and a preliminary result.
Figure 5 shows examples of application of our ap-
proach to images of the contest. Although images are
in different orientations, our approach can still de-
tect lines in the handwritten documents. However,
two main drawbacks can be observed in the approach;
first, several connected components were ignored in
the processing, those components are the one smaller
than the threshold size defined as 200 pixels previ-
ously. The second drawback can be observed in the
two last handwritten lines of figure 5.(b). In the figure,
we can observe some blue lines from the two hand-
written lines merged. Since some components have
their centres further from center of the word they be-
long to, and due to their previous observation, they
ICPRAM 2017 - 6th International Conference on Pattern Recognition Applications and Methods
196

(a)
(b)
(c)
(d)
Figure 5: Result of our approach on images of ICDAR 2013
Handwriting Segmentation Contest. (a) result of process-
ing image 202.tif, (b) result of processing image 337.tif,(c)
result of processing image 342.tif,(d) result of processing
image 343.tif.
are matched wrongly. One possible solution can be
to enhance resolution of the original image so that
each line keeps its own connected components close
to each other.
4 CONCLUSION
In this work, we presented a new approach for hand-
written text line segmentation inspired of various
tracking approaches. The aim of the approach is to
track each pair of connected components in the hand-
written document which satisfy angle minimization.
The approach is suitable when when connected com-
ponents in the handwritten document are close to each
other independently of the skew and line orientation.
However, the approach can fail when connected com-
ponents from different lines are close. Inthis case,
they are merged to same line since the most avail-
able information used in our approach is the center
of the connected component. The approach gave ac-
ceptable visual results but need to be enhanced with a
complete tracking so that a quantitative analysis can
be performed. The approach being innovative can be
enhanced and open a new way of detecting lines in
handwritten documents using word tracking.
ACKNOWLEDGEMENT
Authors would like to thank program chairs of the
International Document Image Processing Summer
school (IDIPS 2015) (IDI, ) for their introduction to
the ICDAR 2013 Handwriting Segmentation Contest
during the summer school and for their pertinent ex-
planations and remarks.
REFERENCES
http://users.iit.demokritos.gr/∼nstam/
ICDAR2013HandSegmCont.
http://samosweb.aegean.gr/idips2015/.
Bai, N. N. (2008). Extracting curved text lines using
the chain composition and the expanded grouping
method.
Bar-Shalom, Y. (1987). Tracking and Data Association.
Academic Press Professional, Inc., San Diego, CA,
USA.
Boykov, Y. and Huttenlocher, D. P. (2000). Adaptive
bayesian recognition in tracking rigid objects. In
Computer Vision and Pattern Recognition, 2000. Pro-
ceedings. IEEE Conference on, volume 2, pages 697–
704 vol.2.
A Tracking Approach for Text Line Segmentation in Handwritten Documents
197

Broida, T. J. and Chellappa, R. (1986). Estimation of object
motion parameters from noisy images. IEEE Trans-
actions on Pattern Analysis and Machine Intelligence,
PAMI-8(1):90–99.
Bukhari, S. S., Shafait, F., and Breuel, T. M. (2008). Seg-
mentation of curled textlines using active contours.
In Document Analysis Systems, 2008. DAS ’08. The
Eighth IAPR International Workshop on, pages 270–
277.
Gatos, B., Pratikakis, I., and Ntirogiannis, K. (2007). Seg-
mentation based recovery of arbitrarily warped docu-
ment images. In Ninth International Conference on
Document Analysis and Recognition (ICDAR 2007),
volume 2, pages 989–993.
Goto, H. and Aso, H. (1999). Extracting curved text
lines using local linearity of the text line. Interna-
tional Journal on Document Analysis and Recogni-
tion, 2(2):111–119.
H
¨
ones, F. and Lichter, J. (1994). Layout extraction of mixed
mode documents. Machine Vision and Applications,
7(4):237–246.
Li, X., Wang, K., Wang, W., and Li, Y. (2010). A multiple
object tracking method using kalman filter. In Infor-
mation and Automation (ICIA), 2010 IEEE Interna-
tional Conference on, pages 1862–1866.
Li, Y., Zheng, Y., Doermann, D., Jaeger, S., and Li, Y.
(2008). Script-independent text line segmentation
in freestyle handwritten documents. IEEE Transac-
tions on Pattern Analysis and Machine Intelligence,
30(8):1313–1329.
Loo, P. K. and Tan, C. L. (2002). Document Analysis
Systems V: 5th International Workshop, DAS 2002
Princeton, NJ, USA, August 19–21, 2002 Proceedings,
chapter Word and Sentence Extraction Using Irregular
Pyramid, pages 307–318. Springer Berlin Heidelberg,
Berlin, Heidelberg.
Louloudis, G., Gatos, B., and Halatsis, C. (2007). Text line
detection in unconstrained handwritten documents us-
ing a block-based hough transform approach. In Pro-
ceedings of the Ninth International Conference on
Document Analysis and Recognition - Volume 02, IC-
DAR ’07, pages 599–603, Washington, DC, USA.
IEEE Computer Society.
Mitiche, A. and Aggarwal, J. (2014). Computer Vision
Analysis of Image Motion by Variational Methodsn.
Springer International Publishing.
Pal, U. and Roy, P. P. (2004). Multioriented and curved
text lines extraction from indian documents. IEEE
Transactions on Systems, Man, and Cybernetics, Part
B (Cybernetics), 34(4):1676–1684.
Pal, U., Sinha, S., and Chaudhuri, B. B. (2003). Image
Analysis: 13th Scandinavian Conference, SCIA 2003
Halmstad, Sweden, June 29 – July 2, 2003 Proceed-
ings, chapter Multi-oriented English Text Line Iden-
tification, pages 1146–1153. Springer Berlin Heidel-
berg, Berlin, Heidelberg.
Roy, P. P., Pal, U., and Llad
´
os, J. (2012). Text line extraction
in graphical documents using background and fore-
ground information. International Journal on Docu-
ment Analysis and Recognition (IJDAR), 15(3):227–
241.
Stamatopoulos, N., Gatos, B., Louloudis, G., Pal, U., and
Alaei, A. (2013). Icdar 2013 handwriting segmenta-
tion contest. In 2013 12th International Conference
on Document Analysis and Recognition, pages 1402–
1406.
Zheng, B., Xu, X., Dai, Y., and Lu, Y. (2012). Ob-
ject tracking algorithm based on combination of dy-
namic template matching and kalman filter. In In-
telligent Human-Machine Systems and Cybernetics
(IHMSC), 2012 4th International Conference on, vol-
ume 2, pages 136–139.
ICPRAM 2017 - 6th International Conference on Pattern Recognition Applications and Methods
198
