
Face Class Modeling based on Local Appearance for Recognition
Mokhtar Taffar
1
and Serge Miguet
2
1
Computer Sc. Dpt., University of Jijel, BP 98, Ouled Aissa, 18000, Jijel, Algeria
2
LIRIS, Universit
´
e de Lyon, UMR CNRS 5205, 5 av. Pierre Mend
`
es-France, 69676, Bron, France
mokhtar.taffar@gmail.com, serge.miguet@univ-lyon2.fr
Keywords:
Invariant Descriptors, Local Binary Patterns, Features Matching, Probabilistic Matching, Model Learning,
Appearance Modeling, Object Class Recognition, Facial Detection.
Abstract:
This work proposes a new formulation of the objects modeling combining geometry and appearance. The
object local appearance location is referenced with respect to an invariant which is a geometric landmark. The
appearance (shape and texture) is a combination of Harris-Laplace descriptor and local binary pattern (LBP),
all is described by the invariant local appearance model (ILAM). We applied the model to describe and learn
facial appearances and to recognize them. Given the extracted visual traits from a test image, ILAM model is
performed to predict the most similar features to the facial appearance, first, by estimating the highest facial
probability, then in terms of LBP Histogram-based measure. Finally, by a geometric computing the invariant
allows to locate appearance in the image. We evaluate the model by testing it on different images databases.
The experiments show that the model results in high accuracy of detection and provides an acceptable tolerance
to the appearance variability.
1 INTRODUCTION
The facial image analysis remains an active domain of
study (Agarwal et al., 2004; Fei-Fe et al., 2003) due
to the difficulty to model and learn a wide range of
intra-class appearance variability characterizing the
face objects. The face detection is a subjacent prob-
lem to recognition where detect face can be consid-
ered as a two-class recognition problem in which a
pattern is classified as being a face or non-facial ap-
pearance.
Thus, developing systems for facial detection has
mainly two challenges: facial appearance modeling
and probabilistic classifier design. The aim of facial
modeling is to choice a set of the most discriminative
local features extracted from face images and to con-
struct a model, across these instances of facial fea-
tures. The model should represent a large range of
facial appearance by minimizing the intra-class vari-
ations and maximizing the extra-class ones. Obvi-
ously, if inadequate facial features are adopted, even
the most performant classifiers will fail to accomplish
the given recognition task of facial appearance (Hadid
et al., 2004). Therefore, it is important to derive lo-
cal features which should verify some properties like:
prompt and easy extraction from images for an ef-
ficient processing, coding in a small size descriptor
vector (low dimensionality of appearance space) to
avoid a high computational cost of classifier, and a
best classes discrimination with tolerance to within-
class variations. But, it is not obvious to find features
which simultaneously meet all these criteria because
of the large variability in appearances due to different
factors such as scale, face pose, facial expressions,
lighting conditions, etc.
The basic LBP (local binary patterns) (Ojala et al.,
2002) features have been performed very well in var-
ious applications, including texture classification and
segmentation, image retrieval and surface inspection.
By this work, we adapted a discriminative feature
space which will be suitable to use for facial appear-
ance recognition. The proposed approach based on
the local descriptions consists of extracting a set of
independent facial regions using Harris-Laplace de-
tector. For each region, LBP feature histogram (rep-
resenting texture contents within region) is computed
and combined with the Harris-Laplace descriptor to
build descriptor code of the region. That is this code
that allows features matching and objects recognition
in scene.
We present an invariant model based on local
appearance, denoted ILAM, which is useful to de-
tect/recognize faces in images. The learned model is
based on similarity of appearances to recognize the
128
Taffar, M. and Miguet, S.
Face Class Modeling based on Local Appearance for Recognition.
DOI: 10.5220/0006185201280137
In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2017), pages 128-137
ISBN: 978-989-758-222-6
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

facial patches, then it become possible to predict their
presence on new image. The ILAM model is defined
across instances of a face; it is a geometric referen-
tial that links features over appearance changes. We
boosted our LBP representation by a convenient prob-
abilistic formulation to learn appearance variations.
By this manner, the model captures well the multi-
modal nature of facial appearances in the cases of il-
lumination and viewpoint changes. With new features
a classifier is trained to capture the facial appearance
of any viewpoint (frontal, profile, ...) in cluttered im-
ages. The facial LBP-appearance approach proposed
here is suitable for any resolution images and has a
short feature vector necessary for fast processing.
Experimentation proves that the ILAM learned
and boosted leads to accurate face localization even
when the appearance variation and intra-class vari-
ability occur (i.e., beard, ethnicity, etc.). The devel-
oped appearance algorithm is simple and has accept-
able cost. Experiments with detecting low-resolution
faces from images are also carried out to demonstrate
that the same facial modeling can be reliable and effi-
ciently used for such tasks.
In the following, a summary is given on works re-
lated to object class appearance modeling and recog-
nition based on local descriptors. Section 3 provides
a presentation of the new objects appearance descrip-
tion based on local traits useful for both learning pro-
cess described in section 4 and facial detection pro-
cess presented in section 5. We give, in section 6,
some experimental results obtained on facial appear-
ance recognition. Finally, at section 7, a conclusion
finishes this paper.
2 RELATED WORKS
Due to difficulties to capture the large appearance
variability of objects through the local features, de-
spite the invariance of the last ones to different vari-
ations such as illumination, viewpoint, partial occlu-
sion, etc., many models (Fergus et al., 2003; Toews
and Arbel, 2006; Taffar and Benmohammed, 2011;
Lindeberg, 1998) and features (Lowe, 2004; Miko-
lajczyk and Schmid, 2004; Kadir and Brady, 2001;
Ojala et al., 2002) have been proposed and applied to
facial appearance analysis. For instance in face de-
tecting, the normalized pixel values (Heisele et al.,
2000; Yang et al., 2002) and Haar-like features (Vi-
ola and Jones, 2001) are the most considered ones.
Heisele et al. (Heisele et al., 2000) reported that nor-
malized pixel values perform better than the gradi-
ent and wavelet features. Viola and Jones (Viola and
Jones, 2001) used Haar-like features to form integral
image characteristics and boosted them by AdaBoost
algorithm for fast learning, this results an efficient
face detection system.
Some features, such as those using PCA (Turk and
Pentland, 1991) and LDA (Etemad and Chellappa,
1997) subspaces in face recognition, have also been
considered. Such features are simple to compute, but
their discriminative power is limited (Phillips et al.,
2000). To overcome the main limitation of the PCA
representation, Local Feature Analysis (LFA) is de-
veloped in (Penev and Atick, 1996). A good re-
sults have been obtained with Gabor wavelet features
used in the elastic bunch graph matching algorithm
(EBGM) (Wiskott et al., 1997). Unfortunately, the al-
gorithm performs a complex analysis to extract a large
set of Gabor wavelet coefficients. In (Ahonen et al.,
2004), authors have obtained good performances in
face recognition using an LPB-based method in which
the face image was divided into many small non-
overlapping blocks, but the representation cannot be
used for small-sized face images common in many
face detection and recognition problems. In (Taffar
et al., 2012) the authors present a model which com-
bines SIFT (Lowe, 2004) local features and a face
invariant used as a geometric landmark. The model
have a detection performance highly invariant to face
viewpoints.
In (Hadid and Pietikinen, 2004), authors intro-
duced a representation which consists of dividing the
face image into several (e.g. 49) non-overlapping
blocks from which the local binary pattern histograms
are computed (using the LBP
u2
8,2
operator) and con-
catenating them into a single histogram. In such a
representation, the texture of facial regions is encoded
by the LBP while the shape of the face is recovered by
the concatenation of different local histograms. How-
ever, this representation is more adequate for larger
sized images (such as the FERET images) and leads
to a relatively long feature vector typically contain-
ing thousands of elements. Therefore, to overcome
this effect, they proposed in (Hadid et al., 2004) a
new facial representation which is efficient for low-
resolution images.
The emerging paradigm tries to model the objects
as a collection of parts (Pope and Lowe, 2000; Fer-
gus et al., 2003; Bart et al., 2004). Many contribu-
tions (Nanni et al., 2012; D
´
eniz et al., 2011; Yu et al.,
2013) used a combination of features from local re-
gions looking for growth the performance of the de-
tectors and recognition systems. However, the diffi-
culty lies in learning the parameters for the model be-
cause we do not want to explore a huge space to know
which parts are best for recognition. We overcome
this problem by designing a convenient appearance
Face Class Modeling based on Local Appearance for Recognition
129

representation. The approach adopted learns simulta-
neously the facial LBP-appearance, its geometry and
co-occurrence of features. The preselected facial fea-
tures, through an histogram-based matching using a
linear measure, are used in a probabilistic matching
to predict facial appearance and to localize and rec-
ognize it with accuracy even in the presence of view-
point changes and a rich multimodal appearance (i.e.,
expression, race, glasses).
3 LOCAL FACIAL APPEARANCE
FORMULATION
In several LBP approaches of the literature, the repre-
sentation of the whole face by dividing the face image
(either or not by overlapping blocks) is effective and
appropriate whether for images of high or low resolu-
tions, but never for both. In addition, a LBP descrip-
tion computed over the whole face image encodes
only the occurrences of the micro-patterns without
any indication about their locations with respect to
faces on images. The new appearance representation
described here tries to overcome these limits. It will
be suitable to deal with facial images of any sizes and
where faces can be anywhere on image.
During learning, we compute a facial LBP-feature
at each keypoint detected on face by using a scale
and affine invariant detector, such Extended Harris-
Laplacian detector (Mikolajczyk and Schmid, 2004).
A scale and an affine invariant interest point detec-
tor combines the Harris detector with the Laplacian-
based scale selection. The Harris-Laplace detector is
then extended to deal with significant affine transfor-
mations.
In affine scale-space the second moment matrix µ,
at a given point x, is defined by:
µ(x, Σ
I
, Σ
D
) =
det(Σ
D
)g(Σ
I
) ∗ ((∇
L
)(x, Σ
D
)(∇
L
)(x, Σ
D
)
T
)
(1)
where Σ
I
and Σ
D
are the covariance matrices which
determine the integration and differentiation Gaussian
kernels.
These interest keypoints have invariant properties
and are reputed to be tolerant to affine transforms, in-
plane changes of scale and rotation. Each keypoint
location corresponds to a central pixel of LBP region.
By this manner, a geometric information enriches the
structure of the local facial appearance with respect
to an invariant. The keypoints detected on face are
located anywhere in the image and computed on the
16 ×16 neighborhood. In this way, they can be at dif-
ferent locations, nearest or farest, from each other. In
Figure 1: Local representation of facial appearance: in ad-
dition to Extended Harris-Laplacian descriptor, a 15 × 15
facial region around the keypoint is described by a concate-
nation of a set of local (LBP
4,1
and LBP
8,2
operators) LBP
histograms.
other terms, the LBP-blocks can be overlapped or not,
as shown in Fig. 1. Thus, the representation which
consists of dividing the face image into several over-
lapping blocks or not, and from which the local bi-
nary pattern histograms are computed then concate-
nated into a single histogram has been abandoned.
The proposed facial LBP-appearance representa-
tion consists to define two kinds of blocks (over-
lapping and non overlapping ones) around each de-
tected keypoint from which the local binary pattern
histograms are computed (using two LBP operators:
LBP
u2
8,2
and LBP
4,1
) then concatenated into a single
(two dimension) histogram. In such a representation,
the texture of facial regions is encoded by the LBP
while their shape is recovered by the concatenation
of different local histograms. Therefore, we will pro-
pose here a general facial modeling which is not only
efficient for low-resolution images, but also more ad-
equate for larger sized images (such as FERET im-
ages). A strong point of this approach is that it re-
quires no pretreatment of the face images (such stan-
dardization, background suppression, face mask ex-
traction, etc.) and no geometric constraints (such as
size of face and its location in image), so it is inde-
pendent of the nature and size of the used image.
The first step uses the overlapping regions which
are scrutinized by 8-neighborhood LBP operator
(LBP
8,2
), where the overlapping size is set to 2 pix-
els, this allows to avoid statistical unreliability due
to long histograms computed over small regions. At
each keypoint, in total 36 regions can be used to gen-
erate LBP code and construct histograms. The second
process uses the non-overlapping blocks exploited by
4-neighborhood LBP operator (LBP
4,1
) where the cor-
responding histogram is sampled in the same way as
the LBP
8,2
operator. In total 25 regions are used to
generate LBP code and construct histograms. Thus,
each face is modeled by a set of local features. A lo-
cal facial characteristic is defined by two LBP codes
and concatenated histograms.
ICPRAM 2017 - 6th International Conference on Pattern Recognition Applications and Methods
130

Figure 2: Facial invariant, represented by a red arrow on
nose, is a geometric landmark for the local representation
of facial appearance represented by yellow squares on face.
The double-headed arrow describes affine transformation of
the appearance region f
i
to face invariant inv.
Finally, in the learning model, each local facial ap-
pearance is described by an Extended Harris-Laplace
descriptor enhanced by a global LBP histogram com-
puted over a 15 × 15 facial region around the key-
point by a concatenation of a set of local (LBP
4,1
and
LBP
8,2
operators) LBP histograms. In addition, we
assigned to each facial feature f
i
the geometric pa-
rameters which correspond to in-plan transformations
of the facial region with respect to (wrt) the land-
mark located on the nose and schematized as an ar-
row, it represents the face invariant (FI), denoted inv,
as shown in Fig. 2. By this manner, during detection
process, from the learning model, it will be possible
to deduce the presence of a new facial region from
all LBP histograms computed over a combination of
detected features that strongly match to some model
traits belonging to different learning images. This ap-
proach is also very useful for recognition. Thus, the
face invariant inv in the test image could be easily pre-
dicted and localized from the geometric parameters
(e.g., position, scale, and orientation) of a detected fa-
cial region (which has similar facial appearance in the
model) with respect to invariant in the learning model.
In our experiments, we considered 15 × 15 as the
minimal standard resolution region around a detected
keypoint and we derived the facial LBP-appearance
representation as follows:
At first, we divide a 15 × 15 facial image region
around the keypoint into 36 overlapping regions of
5 × 5 pixels (overlapping size=2 pixels). From each
region, we compute a 256-bin histogram using the
LBP
8,2
operator which is sampled into 16-bin his-
togram with a sampling step of 16. Then, we concate-
nate the results into a single 576-bin histogram. In the
second step, we divide the same 15 × 15 face region
around the same keypoint into 25 non-overlapping
blocks of 3 ×3 pixels. From each region, we compute
a 16-bin histogram using the LBP
4,1
operator and con-
catenate the results into a single 400-bin histogram.
Additionally, we apply LBP
u2
8,1
to the whole 15 × 15
facial region and derive a 59-bin histogram which is
added to the 976 bins previously computed. Thus, we
obtain a (59 + 976 = 1, 035)-bin histogram as a lo-
cal face representation at the detected point of interest
(see Fig. 1). Finally, a face is defined by a set of inde-
pendent local representation of facial appearance who
is none other than a set of Extended Harris-Laplace
descriptor and 1035-bin histogram. Thus, each facial
feature, denoted f
i
= { f
p
i
, f
g
i
, f
a
i
}, has three parame-
ters: presence f
p
i
, geometric f
g
i
, and appearance f
a
i
.
The model is based on the assumptions which are
the presence parameter f
p
i
follows a discrete bino-
mial distribution in the presence space and the appear-
ance parameter f
a
i
= (D
EHL
f
i
, LBP
f
i
) modeled by Ex-
tended Harris-Laplacian descriptor (denoted D
EHL
f
i
)
and LBP
f
i
representation of feature f
i
follows a nor-
mal distribution with mean µ
a
and covariance
∑
a
in
the appearance space. The geometric parameter f
g
i
of
the feature when with him is determined with respect
to face invariant inv in the image.
4 LEARNING PROCESS
Given a set of N visual traits { f
i
} extracted from
the training image, the model learns to detect if each
f
a
i
whether or not a facial appearance. In probabil-
ity term, from a set of facial appearance { f
a
i
} of the
subwindows extracted from the training image, the
model quantifies the likelihood term of each f
a
i
=
(D
EHL
f
i
, LBP
f
i
) feature which can be expressed as
p( f
p=1
i
| f
a
i
) =
p( f
p=1
i
)p( f
a
i
| f
p=1
i
)
p( f
a
i
)
(2)
where p is the binary presence parameter of fa-
cial appearance, e.g., p = 0 for non face or back-
ground sample. LBP
f
i
is the LBP facial representation
of the training sample f
i
extracted around Extended
Harris-Laplace keypoint described by D
EHL
f
i
appear-
ance, D
EHL
f
i
and LBP
f
i
parts of f
a
i
are statistically in-
dependents. Thus, it is important to accomplish the
learning model under the following assumptions:
• f
g
i
and f
a
i
are statistically independent given pres-
ence f
p
i
.
• D
EHL
f
i
and LBP
f
i
are geometrically independents.
• f
g
i
parameter is related to the geometry of D
EHL
f
i
appearance parameter of f
i
.
Depending on whether f
i
is a positive or nega-
tive sample (face or non-face), the model exhibits the
Face Class Modeling based on Local Appearance for Recognition
131

quantity of the probability ratio R( f
a
i
) =
p( f
p=1
i
| f
a
i
)
p( f
p=0
i
| f
a
i
)
,
e.g., f
i
is face if R( f
a
i
) > 1.
5 RECOGNITION PROCESS
In facial appearance recognition, given a set of visual
observations { f
i
} extracted from test image, each f
i
is
defined by its appearance values f
a
i
= (D
EHL
f
i
, LBP
f
i
)
and geometric values f
g
i
= { f
g:(x,y)
i
, f
g:σ
i
, f
g:θ
i
} of the
extracted image feature f
i
. Thus, the learning model
attempts to confirm if each f
i
is or not a facial appear-
ance ( f
a
i
, f
p=1
i
). The classifier decides on the facial
appearance of the subwindow according to the likeli-
hood value of the following expression:
p( f
a
i
| f
p=1
i
) =
p( f
a
i
)p( f
p=1
i
| f
a
i
)
p( f
p=1
i
)
(3)
where p( f
a
i
| f
p=1
i
) is a posterior value to affirm the
facial appearance of the feature, p( f
a
i
) is a prior over
facial appearance in the learning model, p( f
p=1
i
| f
a
i
)
is the likelihood value of feature presence f
i
given its
facial appearance, and p( f
p=1
i
) is the evidence that
the feature is facial in the learning model.
Thus, it is interesting to perform facial appear-
ance recognition using the learning model under the
assumptions that are:
• D
EHL
f
i
and LBP
f
i
are geometrically independents
given f
g
i
.
• f
g
i
parameter is defined by geometric parameters
of D
EHL
f
i
descriptor in the image.
• D
EHL
f
i
and LBP
f
i
are appearance independents
given facial appearance f
a
i
.
• f
p
i
presence parameter depends on presence of the
local facial appearance f
a
i
in the image.
From these hypothesis, given an appearance D
EHL
f
i
detected in the test image, it becomes easier to deduce
multiple shapes and patterns of the facial appearance
given by a combination of D
EHL
f
j
and LBP
f
k
parts of
different traits in the learning model, where f
j
and f
k
are the model traits, and D
EHL
f
i
is the appearance part
that matches to D
EHL
f
j
in the model.
In addition, before to perform the EM classifier,
a set of similarity measures is applied over the LBP-
histograms (three different histograms-based metrics:
Histogram Intersection, Log-Likelihood Statistic, Chi
Square Statistic) in order to confirm the facial pres-
ence detections and remove the false ones. The
threshold values are fixed empirically for each dis-
tance. For a given detected window, we count the
number of recognitions by matching the histograms
within a neighborhood of 15 × 15 pixels (each de-
tected window is geometrically localized by its cen-
tral trait). The detections are removed if no matching
occurs at this region. Otherwise, we keep them, the
regions for which the matching occurs have a high
outcome of EM classification. The LBP traits ex-
tracted from new image are expected as facial fea-
tures under different lightning and viewpoints varia-
tions. The idea is to find a cluster of features that
have appearance agreement with a face. This set of
data observations { f
p=1
i
} is formed by estimating ap-
pearance distance d( f
a
i
, f
a
j
| f
b
j
) result of a true face or
background relatively to an appearance threshold Γ
a
.
For each feature f
i
, when appearance matching
occurs, the facial appearance probability of f
i
, de-
noted p( f
i
| f
p=1
i
, f
a
j
), can be computed, where p is
the presence parameter, e.g., p=0 for background or
face appearance absence. Features with facial appear-
ance are retained and they are reputed to belong to
face, e.g., p( f
i
| f
p=1
i
, f
a
j
) > p( f
i
| f
p=0
i
, f
a
k
), where f
j
and f
k
are the features of best probabilistic matching
with f
i
in facial and background spaces respectively.
Moreover, we calculated the number of model fea-
tures v
p=1
i
(resp. v
p=0
i
) that have voted for image fea-
ture f
i
as facial (resp. background). Thus, this appear-
ance probabilistic classification of f
i
allows deciding
one by one if the image features have facial appear-
ance or not.
Furthermore, once all the facial features are
known in the test image, a hierarchical clustering
based on the geometrical classification algorithm is
performed. This makes it possible to group them ac-
cording to their geometrical positions in the image.
Using a geometric clustering threshold Γ
c
, the algo-
rithm provides one or more clusters of facial features.
This allows to generate one invariant inv for each
cluster. Each inv localizes a possible facial presence.
Thus, a multiple facial appearance can be recognized
in image. This procedure tries to confirm the appear-
ance statistical dispersion on test image with respect
to the appearance in the learning model.
6 EXPERIMENTATION
6.1 Data and Experimental
Considerations
Because we assume that our appearance-based de-
tection scheme captures very well the variability of
ICPRAM 2017 - 6th International Conference on Pattern Recognition Applications and Methods
132

Figure 3: Examples of face images from CMU-Profiles
database (CMU-Database, 2009) where faces present pose
changes.
facial appearances, a low supervised learning with
a training set of some hundreds images is suffi-
cient to build the facial model. For this purpose,
we collected a set of 300 face images belonging to
a part of FERET (FERET-Database, 2009), CMU-
profile (CMU-Database, 2009), PIE (PIE-Database,
2009), and AT&T (AT&T-Database, 1994) databases.
Then, we increase the number of f
i
= { f
p
i
, f
g
i
=
( f
g:(x,y)
i
, f
g:σ
i
, f
g:θ
i
), f
a
i
= (D
EHL
f
i
, LBP
f
i
)} features in
the learning model by adding a negative samples
{ f
p=0
i
} from some natural images from the net to ob-
tain a set of 960 face and non-face appearances. Addi-
tionally, to enable the system to also detect faces from
any viewpoint (in-plane rotation), we used a train-
ing set of face images of the CMU-Profile database.
Fig. 3 shows the examples of face images and the dif-
ferent rotated face samples. Overall, we obtained a
training set of 360 faces. The faces are divided into
three categories of views: frontal, view angle 20
◦
-70
◦
,
and profile.
To collect more consistent and reliable (face and
nonface) appearances (patterns and shapes), we used
the boostrap strategy in five iterations [15]. First,
we randomly extracted 200 appearances from a set
of MIT-CMU Profile database which contain faces
and 100 appearances from a set of natural images
which do not contain faces. Then, at each iteration we
trained the system, run the face detector, and collected
all those face (resp. nonface) appearances that were
wrongly classified as nonfaces (resp. faces) and used
them for training. Overall, we obtained 1080 + 132
facial appearances as positive training examples and
60 + 47 nonface as negative training examples. The
learning model involved 1, 319 features (1, 212 facial
features and 107 negatives); they are chosen well,
deemed to be informative with respect to (wrt) invari-
ant, and not redundant.
Some parameters have been experimentally fixed
by testing their impact on accurate localization of the
face invariant. The appearance threshold Γ
a
is em-
pirically set at different values for the corresponding
histogram distances, this allows to preselect only fea-
tures with coherent facial appearance.
To check the geometric agreement of predicted in-
variants and a symmetric consistency of facial fea-
tures, the value of threshold Γ
g
is set on 3-parameters
that correspond to position, scale and rotation. The
position parameter of threshold Γ
g:(x,y)
is a pixel dis-
tance that must be less than inverse of invariant scale.
The scale parameter of threshold Γ
g:σ
is limited to a
ratio of 5% in scale with respect to the scale varia-
tion in image, and orientation threshold Γ
g:θ
enables
10 degrees of tolerance.
A clustering threshold Γ
c
allows aggregating the
geometry of predicted invariants for accurate localiza-
tion of the best cluster of invariants. An invariant is
clustered if its minimal distance to any invariant (ei-
ther clustered or not) is less than Γ
c
relative to the
mean of scales.
6.2 Facial Recognition from Viewpoint
The performance of ILAM model is evaluated for
different values of appearance threshold Γ
a
and for
different histogram distances. Figure 4 plots the re-
sult of experiments which allow us to set the best Γ
a
value for each distance. For intersection and likeli-
hood metrics the best detection rates (resp. 83.27%
and 79.6%) are obtained for the values 0.4 and 0.9
of Γ
a
respectively but less than for Chi Square dis-
tance. For Γ
a
= 0.6, ILAM model gives a good preci-
sion result and the Chi Square distance is clearly best.
The face detection grows quickly to reach the rate of
92.4% since the chosen threshold Γ
a
is cut as a preci-
sion factor to predict the facial appearance presence.
The Precision-Recall curves (PRC) in figure 5
drawn the performance comparison of ILAM model
for different distances of similarity on the same pro-
tocol. It depicts that histogram distance of Chi Square
provides an accuracy quality to the model than the
Log-likelihood Statistic similarity. The Chi Squared
distance is slightly better than the Histogram Inter-
section metric and no need to impose geometric or
appearance constraints on faces in cluttered image be-
fore detection.
From the collected training sets, we extracted the
proposed facial representations (as described in sec-
tion 5). Then, we used these features as inputs to the
classifier and trained the face detector. Thus, the sys-
tem is run on several images from different sources
in order to prove its acceptable performance of facial
appearance recognition. Fig. 6 shows some detection
examples. It can be seen that not only most of the
upright frontal faces are detected but also the faces
which present viewpoint changes and an appearance
variability. For instance, Fig. 6.A shows perfect de-
tections. In Fig. 6.D no face is missed and one face
is detected by the system even when the severe occlu-
Face Class Modeling based on Local Appearance for Recognition
133
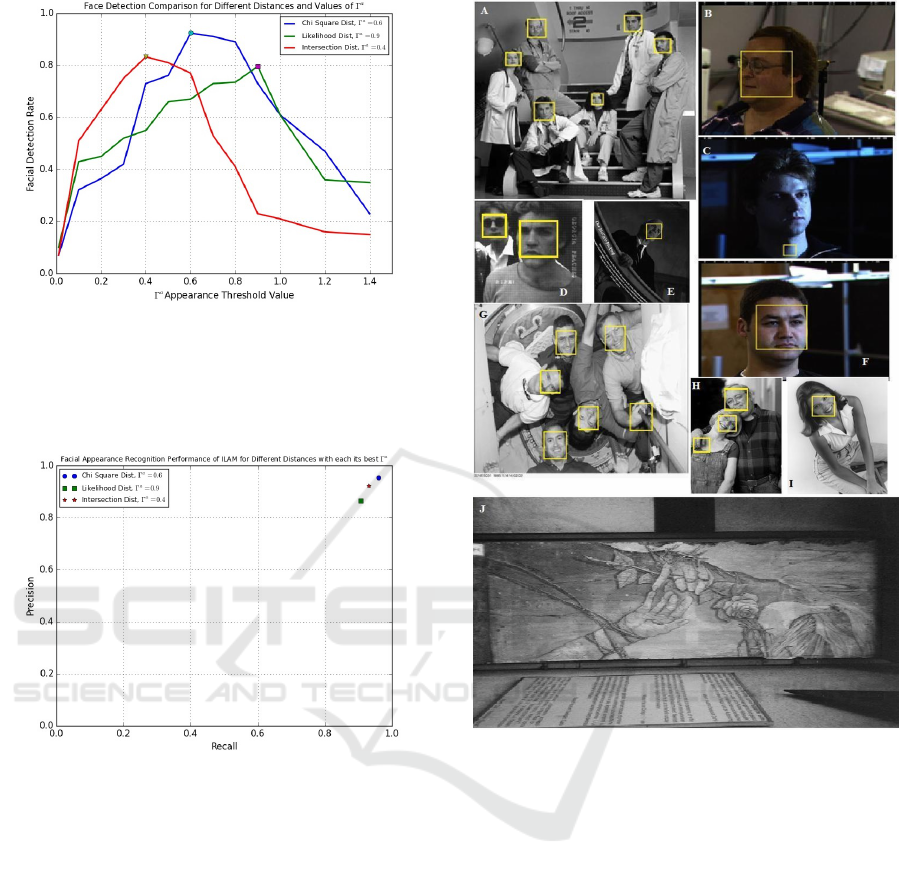
Figure 4: The evaluation results of facial appearance detec-
tion for different values of Γ
a
, on the protocol of 300 face
images from the CMU-Profile database (CMU-Database,
2009), allows to set the best Γ
a
value for each distance. The
results illustrate the rate of 92.4% of ILAM model to infer
faces which present viewpoint changes.
Figure 5: PRC curves of facial appearance model, on the
protocol of 180 face images from the ORL database (AT&T-
Database, 1994) for a face localization task, illustrates the
rate of 95.6% of ILAM model to infer faces in images for
threshold appearance Γ
a
= 0.6, since Chi Squared distance
is proved the best in this context.
sion occurs. A similar case is shown in Fig. 6.G in
which the face is not missed despite a large in-plane
rotation.
Since the system is trained to detect faces at any
degree of in-plane rotation, from the face view to the
profile view (i.e., up to ±90
◦
), it succeeded to find the
strongly rotated faces in Fig. 6.G, 6.H and Fig. 6.I,
and failed to detect slightly rotated ones (as those in
Fig. 6.C) due to the large appearance variability. A
false negative is shown in Fig. 6.J while a false posi-
tive is shown in Fig. 6.C, 6.G and 6.H but their num-
bers in the statistics detector are very low. Notice
that this false positive is expected since the face is
pose-angled from the range angle of 45
◦
± 5 wors-
ened when the facial appearance variability is dras-
Figure 6: Facial appearance recognition examples in several
images from different databases. The images A, D, E, G, H
and I are from the subset of MIT-CMU tests. They belong to
the 120 images considered for comparison. The images B,
C and F are from PIE database. We notice the excellent de-
tections of upright faces in A, D, F and G; detections under
slight in-plane rotation in G and H; even with glass occlu-
sion a right detection in D, missed face and false detection
in C because of high appearance variability, detected faces
correctly in E, G, H and I even with a large in-plane rota-
tion; no missing face in B caused by a profile view of face;
and false detections in G and H due to similarity to facial
appearance.
tic and the detector performs well for the profil view.
These examples summarize the main aspects of our
detection system using images from different sources.
The detected faces are marked by a rectangle encom-
passing or covering one or several facial regions each
characterized by the detected facial LBP-appearance,
as shown in Figure 7.
In order to report quantitative results and com-
pare them against those of the state-of-the-art algo-
rithms, we considered the test images from the MIT-
ICPRAM 2017 - 6th International Conference on Pattern Recognition Applications and Methods
134
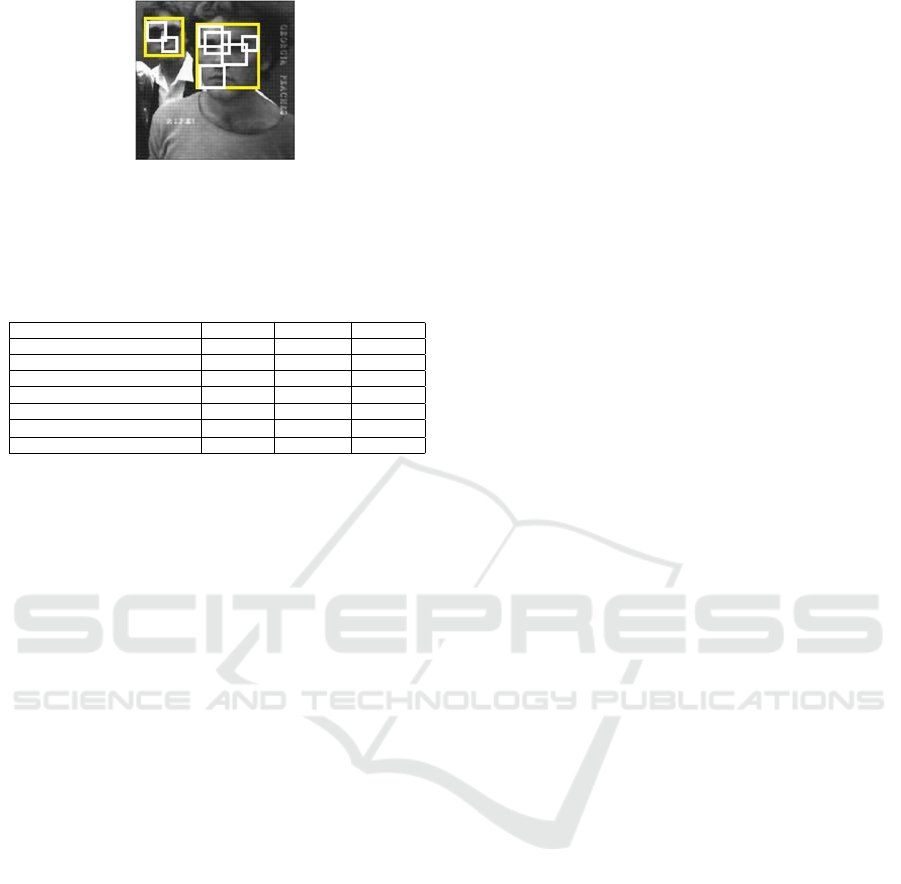
Figure 7: The yellow englobing rectangles of detected faces
include one or several facial LBP-appearance regions repre-
sented by white rectangles.
Table 1: Comparative performance of ILAM facial detector
based LBP-appearance representation with some detectors
on 80 images containing 227 faces.
Method Face Det. False Det. Det. rates
BDF Method 221 1 97.4%
Schneiderman-Kanade(1.0, 1.0) 218 41 96.0%
Normalized Pixel features 213 6 93.8%
LBP feature LBP
u2
8,1
(59 bins) 47 184 20.7%
LBP feature LBP
4,1
(144 bins) 211 9 92.9%
LBP
4,1
+LBP
u2
8,1
trait(203 bins) 222 13 97.8%
ILAM based f
i
trait 225 3 99.1%
CMU sets (CMU-Database, 2009) that are used prin-
cipally with the Bayesian Discriminating Features
(BDF) method (Liu, 2003), Schneiderman-Kanade
approach (Schneiderman and Kanade, 1998), Nor-
malized Pixel features (Heisele et al., 2000), and LBP
representation as in (Hadid et al., 2004). There are 80
images containing 227 faces. Some of these images
are shown in Fig. 6.(A, D, E, G, H, and I).
Table 1 presents the performance of our facial
appearance recognition system and those of other
approaches like: BDF (Liu, 2003), Schneiderman-
Kanade (Schneiderman and Kanade, 1998), and LBP-
feature used in (Hadid et al., 2004). We can see (from
the 1st, 2nd, 5th and 6th rows of Table 1) that our ap-
proach has a performance slightly higher to the com-
parative approaches. The proposed ILAM detector
using LBP-based approach (where LBP features are
extracted around Extended Harris-Laplace keypoint)
succeeded in detecting 225 faces with few false posi-
tives caused by the similar appearance of the detected
objects to faces. Some missing faces are mainly due
to severe facial appearance variability added to a large
in-plane rotation (as shown an example in Fig. 6.C)
and sometimes to occlusion. We notice that ILAM
system has an high performance, moreover, it is more
general and not only dedicated to frontal faces but
also to faces in different poses and even when occlu-
sion occurs.
Additionally, if the detected faces are to be fed to a
recognition step, then, no raison to tolerate some false
detections even if it is likely that these images will be
rejected (therefore they will not be accepted as those
of an individual). In such a context even if our face
detector performs slightly better as it succeeded in de-
tecting 225 faces among 227 (the system detected the
tilted faces in Fig. 6.G despite the large in-plane rota-
tion) it tolerates only 3 false detections. The 8th row
of Table 1 presents this performance.
Analyzing the ILAM representations and inves-
tigating the usefulness of dividing the facial images
into regions around detected keypoints, we noticed
that calculating the LBP traits from these regions
yielded a good result (see the 8th row in Table 1).
This is expected since such a representation encodes
only the occurrences of the micro-patterns without
any indication about their locations. Combining both
representations further enhances the detection perfor-
mance. However, computing the LBP traits only from
the whole images (59 bins) yields a low detection rate
of 20.7% (see 5th row in Table 1).
In order to further investigate the discriminative
power of facial appearance of ILAM model, we used
a similar face detector combined with an EM classifier
and using different features as inputs, then compared
the results to those obtained using the proposed f
i
traits. We trained the system using the same training
samples as described in Section 6.1 and we perform
the tests on 238 images containing 300 faces from
the subset of CMU-Profile (CMU-Database, 2009),
CMU-PIE (PIE-Database, 2009), and AT&T (AT&T-
Database, 1994).
We chose, for experimental purpose, the HoG
(histograms of oriented gradients) features (D
´
eniz
et al., 2011), LBP/LTP representation (Nanni et al.,
2012), and ones based on patch-based SIFT-LBP in-
tegration (Yu et al., 2013) as inputs, even if, it has
been shown in (Nanni et al., 2012) that such texture
descriptors (LBP/LTP patterns and local phase quan-
tization) for describing region and a bag-of-features
approach for describing object performs comparably
well to HoG and SIFT-LBP based ones when using a
SVM classifier.
Table 2 (5th row) shows the performance of ILAM
model based on LBP
4,1
+ LBP
8,2
+ LBP
u2
8,1
traits com-
puted over the local region. Although the results are
quite good as 294 faces among 300 were detected,
still the proposed approach using the f
i
visual fea-
tures, where f
a
i
= (D
EHL
f
i
, LBP
f
i
) is the facial appear-
ance part of f
i
, computed over regions around key-
points
• performed better (comparison between the 5th
row and 6th row in Table 2);
• used a combination of well know features which
results on simple descriptor and histogram vectors
and thus more faster to compute over the little re-
gions;
Face Class Modeling based on Local Appearance for Recognition
135

Table 2: Comparative performance of ILAM modeling
combined with an EM classifier to different features used
as inputs.
Method Face Det. False Det. Det. rates
HOG features 293 8 97.6%
LBP/LTP representation 294 6 98.1%
Patch-based SIFT-LBP 296 6 98.6%
LBP
4,1
+ LBP
8,2
+ LBP
u2
8,1
trait 294 9 98.0%
f
i
= { f
p
i
, f
g
i
, f
a
i
} trait 298 5 99.3%
• did not need to impose anyone constraint like his-
togram equalization; and
• principally needs a simple EM classifier to esti-
mates the latent data, than using a series of SVM
classifiers (Hadid et al., 2004; Vapnik, 1998).
7 CONCLUSION
The appearance representation of face class presented
in this paper offers robust properties such as tolerance
to geometric transforms and illumination changes. It
captures well the viewpoints variations and especially
intra-class variability. It has a geometric localiza-
tion sufficiently accurate and its magnitude remains
roughly constant with respect to size of object in im-
age. The ILAM model based on combination of lo-
cal appearance of Extended Harris-Laplace descriptor
and texture of LBP feature provides a low degree of
supervision. The experimentation reveals that the fa-
cial formulation is useful and has high capability to
classify new face instances, of course this representa-
tion can be applied to another object class.
REFERENCES
Agarwal, S., Awan, A., and Roth, D. (2004). Learning to
detect objects in images via a sparse, part-based rep-
resentation. In PAMI, 26(11), pp. 1475–1490.
Ahonen, T., Hadid, A., and Pietikinen, M. (2004). Face
recognition with local binary patterns. In Proc. of the
8th ECCV Conference.
AT&T-Database (1994). At&t: The database of faces. In
Cambridge University, http://www.cl.cam.ac.uk/.
Bart, E., Byvatov, E., and Ullman, S. (2004). View-invariant
recognition using corresponding object fragments. In
ECCV, pp 152-165.
CMU-Database (2009). Cmu face group and face detection
project, frontal and profile face images databases. In
http://vasc.ri.cmu.edu/idb/html/face/.
D
´
eniz, O., Bueno, G., Salido, J., and la Torre, F. D. (2011).
Face recognition using histograms of oriented gradi-
ents. In Pattern Recognition Letters, vol.32, pp:1598-
1603.
Etemad, K. and Chellappa, R. (1997). Discriminant analysis
for recognition of human face images. In Journal of
the Optical Society of America, vol.14, pp:1724-1733.
Fei-Fe, L., Fergus, R., and Perona, P. (2003). A bayesian
approach to unsupervised one-shot learning of object
categories. In ICCV, Nice, France, pp. 1134–1141.
FERET-Database (2009). Color feret face database. In
www.itl.nist.gov/iad/humanid/colorferet.
Fergus, R., Perona, P., and Zisserman, A. (2003). Ob-
ject class recognition by unsupervised scale-invariant
learning. In CVPR, Madison, Wisconsin, pp. 264–271.
Hadid, A. and Pietikinen, M. (2004). Selecting models
from videos for appearance-based face recognition. In
Proc. of the 17th International Conference on Pattern
Recognition (ICPR).
Hadid, A., Pietikinen, M., and Ahonen, T. (2004). A dis-
criminative feature space for detecting and recogniz-
ing faces. In CVPR Proceedings, Vol. 2, pp. 797–804.
Heisele, B., Poggio, T., and Pontil, M. (2000). Face detec-
tion in still gray images. In Technical Report 1687,
Center for Biological and Computational Learning,
MIT.
Kadir, T. and Brady, M. (2001). Saliency, scale and image
description. In IJCV, 45(2), pp. 83–105.
Lindeberg, T. (1998). Feature detection with automatic
scale selection. In International Journal of Computer
Vision, vol. 30(2), pp. 79-116.
Liu, C. (2003). A bayesian discriminating features method
for face detection. In IEEE Trans. on PAMI, vol. 25,
pp:725-740.
Lowe, D. (2004). Distinctive image features from scale-
invariant keypoints. In IJCV, 60(2), pp. 91–110.
Mikolajczyk, K. and Schmid, C. (2004). Scale and affine in-
variant interest point detectors. In IJCV, 60(1), pp. 63-
86.
Nanni, L., Brahnam, S., and Lumini, A. (2012). Random
interest regions for object recognition based on texture
descriptors and bag of features. In Expert Systems with
Applications, Elsevier Journal, vol.39, pp:973-977.
Ojala, T., Pietikinen, M., and Menp, T. (2002). Multires-
olution gray-scale and rotation invariant texture clas-
sification with local binary patterns. In IEEE Trans-
actions on Pattern Analysis and Machine Intelligence
(PAMI), vol.24, pp:971-987.
Penev, P. and Atick, J. (1996). Local feature analysis: a gen-
eral statistical theory for object representation. In Net-
work: Computation in Neural Systems, vol.7, pp:477-
500.
Phillips, P., Moon, H., Rizvi, S. A., and Rauss, P. J. (2000).
The feret evaluation methodology for face recognition
algorithms. In IEEE Trans. on PAMI, vol.22, pp:1090-
1104.
PIE-Database (2009). Cmu pose, illumination, and ex-
pression (pie) database. In http:/www.ri.cmu.edu/
projects/project 418.html.
Pope, A. and Lowe, D. (2000). Probabilistic models of ap-
pearance for 3-d object recognition. In IJCV, 40(2),
pp. 149–167.
ICPRAM 2017 - 6th International Conference on Pattern Recognition Applications and Methods
136

Schneiderman, H. and Kanade, T. (1998). Probabilistic
modeling of local appearance and spatial relationships
for object recognition. In CVPR Proceedings, pages
45-51.
Taffar, M. and Benmohammed, M. (2011). Generic face in-
variant model for face detection. In Proc. IP&C Con-
ference Springer, pp 39-45.
Taffar, M., Miguet, S., and Benmohammed, M. (2012).
Viewpoint invariant face detection. In Networked Dig-
ital Technologies, Communications in Computer and
Information Science, Springer Verlag, pp:390-402.
Toews, M. and Arbel, T. (2006). Detection over viewpoint
via the object class invariant. In Proc. Int’l Conf. Pat-
tern Recognition, vol. 1, pp. 765-768.
Turk, M. and Pentland, A. (1991). Eigenfaces for recog-
nition. In Journal of Cognitive Neuroscience, vol. 3,
pp:71-86.
Vapnik, V. (1998). Statistical learning theory. In Wiley Edi-
tion, New York.
Viola, P. and Jones, M. (2001). Rapid object detection using
a boosted cascade of simple features. In Proc. Com-
puter Vision and Pattern Recognition (CVPR), pages
511-518. Springer.
Wiskott, L., Fellous, J.-M., Kuiger, N., and der Malsburg,
C. V. (1997). Face recognition by elastic bunch graph
matching. In IEEE Transactions on PAMI, vol.19,
pp:775-779.
Yang, M.-H., Kriegman, D. J., and Ahuja, N. (2002). De-
tecting faces in images: A survey. In IEEE Trans. on
PAMI, vol.24, pp:34-58.
Yu, J., Qin, Z., Wan, T., and Zhang, X. (2013). Feature in-
tegration analysis of bag-of-features model for image
retrieval. In Neurocomputing, vol.120, pp:355-364.
Face Class Modeling based on Local Appearance for Recognition
137
