
Consistent Optical Flow Maps for
Full and Micro Facial Expression Recognition
Benjamin Allaert, Ioan Marius Bilasco and Chabane Djeraba
Univ. Lille, CNRS, Centrale Lille, UMR 9189 - CRIStAL -
Centre de Recherche en Informatique Signal et Automatique de Lille, F-59000 Lille, France
benjamin.allaert@ed.univ-lille1.fr, {marius.bilasco, chabane.djeraba}@univ-lille1.fr
Keywords:
Facial expression, Micro-expression, Optical Flow.
Abstract:
A wide variety of face models have been used in the recognition of full or micro facial expressions in image se-
quences. However, the existing methods only address one family of expression at a time, as micro-expressions
are quite different from full-expressions in terms of facial movement amplitude and/or texture changes. In this
paper we address the detection of micro and full-expression with a common facial model characterizing facial
movements by means of consistent Optical Flow estimation. Optical Flow extracted from the face is generally
noisy and without specific processing it can hardly cope with expression recognition requirements especially
for micro-expressions. Direction and magnitude statistical profiles are jointly analyzed in order to filter out
noise and obtain and feed consistent Optical Flows in a face motion model framework. Experiments on CK+
and CASME2 facial expression databases for full and micro expression recognition show the benefits brought
by the proposed approach in the filed of facial expression recognition.
1 INTRODUCTION
Automatic facial expression analysis has attracted
great interest over the past decade in various domains.
Facial expression recognition has been widely studied
in computer vision. Recent methodologies for static
expression recognition have been proposed and ob-
tain good results for acted expression. However, in
order to cope with the natural context challenges like
face occlusions, non-frontal poses, expression inten-
sity and amplitude variations must be addressed.
Challenges like illumination variation, face occlu-
sions, non-frontal poses have been addressed in fields
other then expression recognition. Several research
results were also published on this topic primarily
based on face alignment. Although the methodology
is more mature, it is far from being fully robust. This
topic attracts still many researches and discussions.
In the following we focus on challenges brought
by supporting a wide range of facial movement am-
plitudes when producing a full or micro expression.
In case of full expression the underlying facial move-
ment and the induced texture deformation can be
clearly differentiated from the noise that can appear
when analyzing the face properties. However, as the
amplitudes are much smaller in micro-expressions at-
tention must be paid to small changes encoding.
Automatic micro-expression recognition algo-
rithms have recently received growing attention in the
literature (Yan et al., 2014; Liu et al., 2015; Wang
et al., 2014a; Wang et al., 2014b). Micro-expressions
are quite different from full-expression recognition.
They are characterized by rapid facial movements
having low intensity. Micro-expressions typically in-
volve a fragment of the facial region. Therefore,
previous work that were suitable for full-expression
recognition may not work well for micro-expressions.
In other words, it seems difficult to find a common
methodology for analyzing full and micro expression
in an accurate manner.
Dynamic texture is an extension of texture char-
acterization to the temporal domain. Description and
recognition of dynamic textures in facial expression
recognition have attracted growing attention because
of their unknown spatial and temporal extent. Impres-
sive results have recently been achieved in dynamic
texture synthesis using the framework based on a sys-
tem identification theory which estimates the parame-
ters of a stable dynamic model (Wang et al., 2014a;
Wang et al., 2014b). However, the recognition of
dynamic texture is a challenging problem compared
with the static case (P
´
eteri and Chetverikov, 2005).
Indeed, for real videos the stationary dynamic tex-
tures must be well-segmented in space and time and it
Allaert B., Bilasco I. and Djeraba C.
Consistent Optical Flow Maps for Full and Micro Facial Expression Recognition.
DOI: 10.5220/0006127402350242
In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2017), pages 235-242
ISBN: 978-989-758-226-4
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
235

is difficult to define a metric in the space of dynamic
models.
In facial expression recognition, Optical Flow
methods are popular as Optical Flow estimation is
a natural way to characterize the local dynamics of
a temporal texture (Fortun et al., 2015). The use of
Optical Flow reduces dynamic texture analysis to the
analysis of a sequence of instantaneous motion pat-
terns viewed as static textures. Optical Flow are re-
cently used to analyze full-expression (Liao et al.,
2013; Su et al., 2007; Lee and Chellappa, 2014) and
micro-expression (Liu et al., 2015). Good perfor-
mances were obtain in both cases. However, the us-
age of the Optical Flow is still questioned because
the accuracy drops in the presence of motion disconti-
nuities, large displacements or illumination changes.
Recent Optical Flow algorithms (Revaud et al., 2015;
Chen and Koltun, 2016; Bailer et al., 2015) evolved to
better deal with noise and motion discontinuities em-
ploying complex filtering requiring high computation
time. Still, these algorithms were designed for generic
Optical Flow computations and are not adapted to fa-
cial morphology and physical constraints.
In this paper, we investigate the effectiveness of
using a facial dedicated filtered dense Optical Flow
in order to recognize the full-expressions (anger, fear,
disgust, happiness, sadness, and surprise) and micro-
expressions (positive, negative, surprise) in near-
frontal-view recordings. In section 2, we discuss ex-
isting work related to static approaches for full and
micro expression recognition. In section 3, we present
our approach for extracting the coherent movement
on the face in different locations from dense Optical
Flow method. We filter the noise considering the fa-
cial movement hypothesis (local coherency and prop-
agation). Next, we explore the characterization of the
coherent Optical Flow into a facial model formula-
tion in section 4. Experimental results are discussed
in section 5. Finally, the conclusion and future per-
spectives are given in section 6.
2 RELATED WORK
Most of the 2D-feature-based methods are suitable for
the analysis of near frontal facial expressions in pres-
ence of limited head motions and intense expressions.
In order to provide the reader with an overview of ap-
proaches challenging these limitations, we present the
recent facial alignment method and how the approach
of facial expression recognition is adapted to the dif-
ferent intensity of expression.
The face is usually detected and aligned in order
to reduce variations in scale, rotation, and position.
Alignment based on eyes is the most popular strat-
egy since eyes are the most reliable facial compo-
nents to be detected and suffer little changes in pres-
ence of expressions. Assuming the face region is well
aligned, histogram-like features are often computed
from equal-sized facial grids. However, apparent mis-
alignment can be observed and it is primarily caused
by variations in face pose and facial deformation, as
well as the diversity in human face geometry. Re-
cent studies use the facial landmarks to define a facial
region that increase robustness to facial deformation
during expression. Jiang et al. (Jiang et al., 2014) de-
fine a mesh over the whole face with an Active Shape
Model (ASM), and extract features from each of the
regions enclosed by the mesh. Han et al. (Han et al.,
2014) use an Active Apparent Model (AAM) to trans-
form a facial grid and improve feature extraction for
recognizing facial Action Units (AUs).
Thanks to recent databases (Yan et al., 2014;
Li et al., 2013), the demand for computer vision
techniques to improve the performance of micro-
expression recognition is increasing. Recent works
usually used spatiotemporal local binary pattern
(LBP) for micro-expression analysis (Wang et al.,
2014b; Wang et al., 2014a; Yan et al., 2014). Huang
et al. (Huang et al., 2016b) proposed spatiotempo-
ral completed local binary pattern (STCLQP) and ob-
tained promising performances with regard to sim-
ilar state-of-the-art methods. The reason may be
that STCLQP provides more useful information for
micro-expression recognition, as STCLQP extracts
jointly information characterizing magnitudes and
orientations. Recently, Liu et al. (Liu et al.,
2015) built a feature for micro-expression recognition
based on a robust Optical Flow method and extract a
Main Directional Mean Optical-flow (MDMO). They
showed that the magnitude is more discriminant than
the direction when working with micro-expression
and they achieve better performance than spatiotem-
poral LBP approach.
Some approaches employ dense Optical Flow for
full expression recognition and perform well in sev-
eral databases. Su et al. (Su et al., 2007) propose to
uniformly distribute 84 feature points over the three
automatically located rectangles instead of extracting
precise facial features (eyebrows, eyes, mouth). They
select the facial regions which contribute more to-
wards the discrimination of expressions. Lee et al.
(Lee and Chellappa, 2014) design sparse localized fa-
cial motion dictionaries from dense motion flow data
of facial expression image sequences. The proposed
localized dictionaries are effective for local facial mo-
tion description as well as global facial motion anal-
ysis. Liao et al. (Liao et al., 2013) improve the exist-
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
236

ing feature extraction result by learning expression-
specific spatial weighting masks. The learned spatial
weighted masks correspond to the human attention to
discriminate between expressive faces, and determine
the importance of facial regions. The weighted masks
can significantly increase the performance of facial
expressions recognition and intensity estimation on
several databases.
Inspired by the success of simple dense Optical
Flow approach, we explore magnitude and direction
constraints in order to extract the relevant movement
on the face. Considering the smoothing of motion of
recent Optical Flow approach, a simple Optical Flow
combined with magnitude constraint seems adequate
for reducing the noise induced by lighting changes
and small head motions. In the next section, we pro-
pose a filtering Optical Flow method based on consis-
tent local motion propagation to keep only the perti-
nent motion during facial expression.
3 FACIAL RELATED FILTERING
The facial characteristics (skin smoothness, skin re-
flect and elasticity) involves dealing with the incon-
sistency and the noise induced by motion discontinu-
ities, as well as, illumination changes while extracting
directly the Optical Flow on the face.
Instead of explicitly computing the global Opti-
cal Flow field, the Optical Flow constraint equation is
used in a specific facial area defined in relation with
the facial action coding system in order to keep only
the pertinent motion of the face. The pertinent motion
is defined as the Optical Flow extracted from regions
where the intensity of moving pixels reflects natural
facial movements characteristics. We consider a nat-
ural facial movement to be uniform during motion if
it is characterized by continuity over neighboring pix-
els, as well as, by continuous diminution of its in-
tensity over neighboring regions. The filtering oper-
ation of Optical Flow is divided into several stages
and they are illustrated in Figure 1. The Farneb
¨
ack
algorithm (Farneb
¨
ack, 2003) is used to compute fast
dense Optical Flow (A). It is not the most accurate
algorithm but it ensures that motion is not disaggre-
gated by smoothing and the computation time is low.
Based on the Farneb
¨
ack flow field, we determine the
consistent facial motion from the facial regions hav-
ing high probability of movement (RHPM) (B). Each
RHPM analyze their neighbors behavior in order to
estimate the propagation of the motion on the whole
face (C). The filtered Optical Flow field is computed
from the coherent motion in each RHPM (D).
Next, we present in detail our approach for ex-
Figure 1: All stages of the proposed method.
tracting the coherent movement in different locations
on the face from dense Optical Flow method by filter-
ing the noise on the basis of the facial movement hy-
pothesis assuming local coherency and propagation.
3.1 RHPM Local Coherency
In order to cope with the noise and to filter the Optical
Flow information, we start by analyzing the direction
distribution within each local region in order to keep
only the reliable flow. The proposed method is illus-
trated in Figure 2.
Figure 2: The process of consistent local motion character-
ization in RHPM.
Consistent Optical Flow Maps for Full and Micro Facial Expression Recognition
237

Each region with a high probability of movement
contains local Optical Flow information for each pixel
: a direction and a magnitude. Each RHPM is defined
by a center ε(x,y) called epicenter and a local propa-
gation value λ which define the size of the area under
investigation around the epicenter.
In order to measure the consistency of the Optical
Flow in terms of directions, we analyze the direction
distribution into the RHPM for several layers of mag-
nitude (Figure 2-A). We assume that the motion on
the face spread progressively due to the skin elastic-
ity. Furthermore, we have constructed 5 normalized
histograms (M = (M
1
,M
2
,..., M
5
)) that represent the
direction distribution over 36 bins (of 10
◦
each) for
different magnitudes ranges. The magnitude ranges
vary according to the characteristics of the data to be
processed. We have kept only 5 magnitudes, since
they are sufficient to reflect the consistency of move-
ment in facial motion.
Afterwards, the intersection of direction for each
pair of consecutive magnitudes is computed to esti-
mate motion overlap between two consecutive mag-
nitudes (Figure 2-B). We build a feature ρ, which
represent the intersection between two magnitude his-
tograms by
ρ
k
i
=
(
1, if M
k
i
> 0 and M
k
i+1
> 0.
0, otherwise.
(1)
where i = 1,2,...,5 is the index of magnitudes and k is
the number of bins. The vector ρ is composed only
of 0 (no match is found relevant to the bin k) and 1
(histograms have a common occurrence into the bin
k). To cope with the discretization problems where
close angles can be spread over different bins, we ex-
tend the direction distribution limits by one bin. If no
direction is found for all feature vector ρ, the RHPM
is considered as being locally incoherent. After ex-
tracting the occurrences feature vector ρ for each pair
of magnitudes, the union of all ρ vectors provide the
main directions.
The number of occurrences for each direction
within Ψ range is from 0 (low intensity) to 4 (high in-
tensity) and characterize the importance of each direc-
tion (Figure 2-C). If no common directions between
the four feature vector ρ are found, the RHPM is con-
sidered as being locally incoherent.
Despite the fact that a RHPM is considered as co-
herent, the filtering of local motion has not yet been
completed. Indeed, if we consider a natural facial
movement to be uniform during motion then the lo-
cal facial motion should spread to other region neigh-
bors. The analysis of the movement propagation in
the RHPM neighborhood is explained further.
3.2 RHPM Neighborhood Propagation
Facial muscles action ensures that a local motion
spreads to neighboring regions until motion exhaus-
tion. Motion is subject to changes that could affect
direction and magnitude in any location. However,
intensity of moving facial region tends to remain con-
stant during facial expression. Therefore, a perti-
nent motion computed in a RHPM appears, eventu-
ally with a lower or upper intensity, in at least one
neighboring region.
Facial motion analysis consists in estimating the
motion propagation in the direct neighborhood of the
specific RHPM. We propose a method to find the local
facial motions that best discriminate expressions and
corresponds to the regional importance of the expres-
sive faces. The propagation analysis is illustrated in
Figure 3. Next, we explain the process steps : how to
locate RHPM Neighboring regions (Figure 3-1); how
to calculate the consistency between two regions (Fig-
ure 3-2) and how to estimate the global consistent mo-
tion around the RHPM (Figure 3-3).
When an RHPM is locally coherent, we must ver-
ify that the motion has expanded into a neighboring
RHPM. The propagation motion analysis is illustrated
in Figure 3-1. The neighboring RHPM regions (rep-
resented by the other square) are regions with a high
probability of propagation (RHPP). It is expected to
measure a consistent motion between a region and its
neighborhood. Eight RHPP are generated around the
RHPM. All these regions are at a distance ∆ from
the RHPM epicenter. The bigger distance between
two epicenter, the less coherence the overlapping area
may exhibit. λ is the size of the area under investiga-
tion around the epicenter. Finally, β characterize the
number of direct propagation from the epicenter that
is carried out by the propagation analysis.
Each RHPP is analyzed in order to evaluate the
local coherency of the initial RHPM as illustrated in
Figure 3-2. As an outcome of the process, each lo-
cally consistent RHPP is characterized by a direc-
tional vector Ψ containing 36 bins (10° wide) of dif-
ferent magnitudes. Here the magnitudes correspond
to the number of occurrences of a given orientation at
different movement intensity scales (M
1
to M
5
). The
RHPM is considered to be consistent with its RHPP
if a confidence rating ω exceeds a fixed percentage
threshold θ. ω is computed as follow :
ω = 1 −
k
∑
k=1
min(Ψ
0
k
,Ψ
1
k
). (2)
where ω correspond to the intersection between two
neighboring region directional vector Ψ
0
and Ψ
1
and
k = 1,2,...,36 is the index of the bin. Next, recur-
sively, for each inter-coherent RHPP we conduct the
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
238
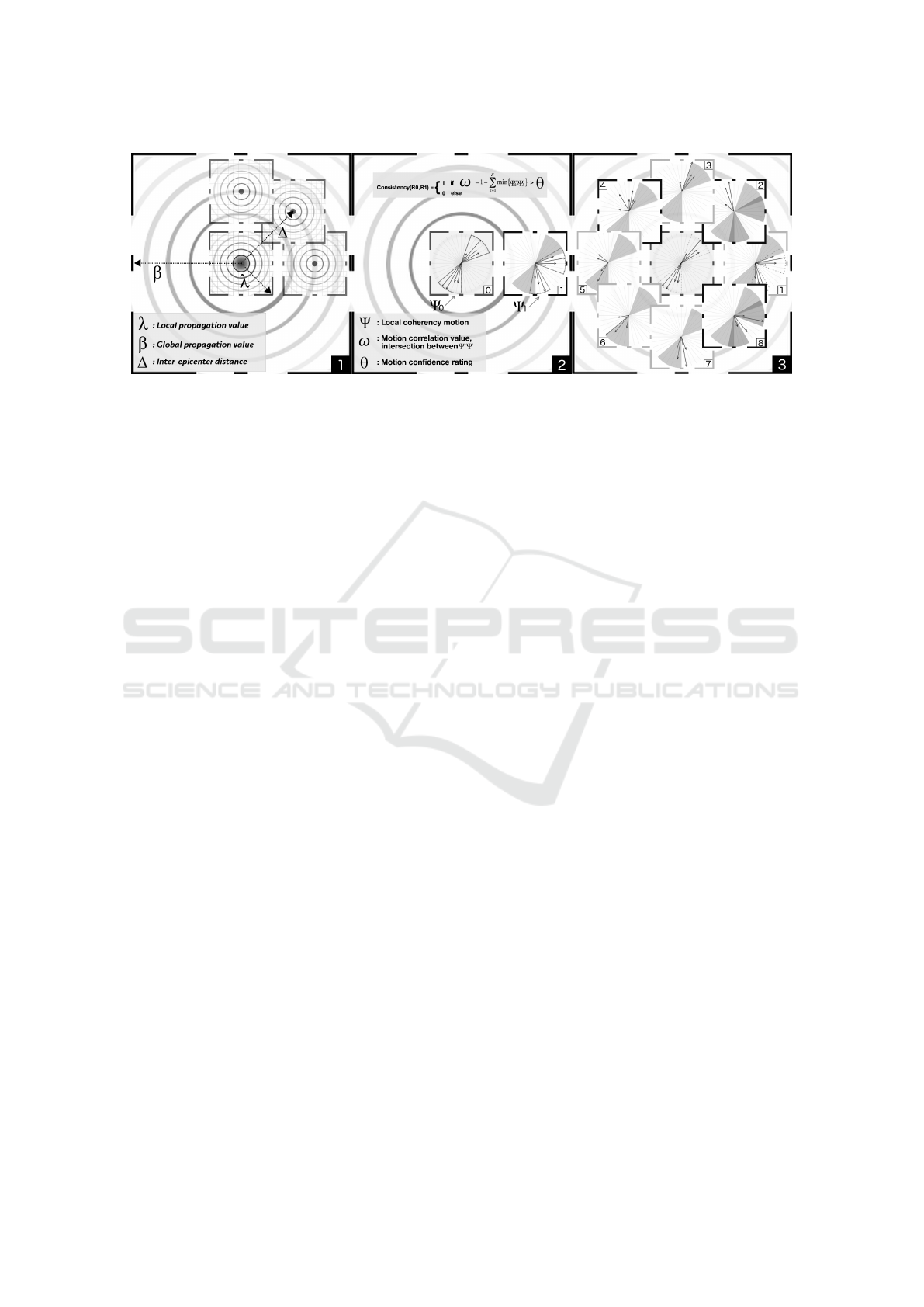
Figure 3: Estimate the motion propagation in the direct neighborhood of the specific RHPM (the central square).
same inter-region coherency measurements as long as
at least one nearly created RHPP is inter-region co-
herent with neighbor the previous one. The recursive
process ends when the value β is reached.
The motion propagation after one iteration is
given in Figure 3-3. RHPP are represented with bold
borders if the motion is coherent with the RHPM.
Otherwise, RHPP are represented with light borders.
When the motion between two neighbors region is
considered as coherent, a binary coherency map is
updated in order to keep track of the evaluation pro-
cedure and avoid cycles. However, local region that
are marked as non inter-region coherent, may be re-
evaluated as coherent with an other RHPP in subse-
quent propagation. This is especially true in presence
of skin wrinkles or furrows because motion disconti-
nuities appears.
Finally, each distribution vector (Ψ) correspond-
ing to the RHPPs that have direct or indirect connec-
tions to the original RHPM (e.g. at least once motion
is consistent between 2 neighbor regions) characterize
the global region motion. If the motion propagation
between all neighbors is inconsistent, the propagation
motion is no more explored and that means that there
are no more pertinent motions into the region. The
global region motion is extracted by applying the fol-
lowing formula
η =
n
∑
i=1
Ψ
i
. (3)
Where n is the number of consistent regions (the
RHPM and all consistent RHPR). η is a histogram
over 36 bins, which contains, for each bin the sum of
each intensity of coherent RHPP. The maximum value
for each bin correspond to the number of consistent
regions n multiplied by the high intensity of motion in
Ψ, that is 4. Therefore, at this stage of the process, we
are able to calculate the coherent propagation motion
defined by an oriented histogram η from a specific lo-
cation.
In the next, we study the impact of RHPM loca-
tion on the face. More specifically, we show that the
intensity of expression (full or micro) plays a key role
in the positioning of RHPM and, in the same time, it
impacts the way to extract the consistent motion on
the face.
4 EXPRESSION RECOGNITION
We use the facial landmarks to define a facial region
that increase facial deformation robustness during ex-
pression. Similarly to Jiang et al. (Jiang et al., 2014),
the facial landmarks are used to define a mesh over
the whole face, and a feature vector can be extracted
from each of the regions enclosed by the mesh. To
extract these facial meshes from face images, the fa-
cial landmarks are located with the method proposed
by Kazemi et al. (Kazemi and Sullivan, 2014). Next,
landmark positions and the geometrical statistics of
the face are used to compute a new set of points that
allow to define a mesh over the whole face (fore-
head, cheek). Finally, the best discriminant landmarks
points are selected from original landmarks corre-
sponding to the active face regions and specific points
are computed in order to set out the mesh boundaries.
The partitioning of facial regions of interest (ROIs) is
illustrated in the Figure 4. The partitioning of these
ROIs is based on the facial motion observed in the
previous consistency maps extracted from both full
and micro-expressions. The locations of these ROIs
are uniquely determined by the landmarks points. For
example, the position of the feature point f
Q
is the av-
erage of positions of two feature points, f10 and f55.
The distance between the eyebrows and the forehead
feature points ( f
A
, f
B
,..., f
F
) correspond to the size of
the nose Distance
f 27, f 33
/4 which makes it possible to
maintain the same distance for optimal adaptation to
the size of the face.
Consistent Optical Flow Maps for Full and Micro Facial Expression Recognition
239

Figure 4: The partitioning of facial regions of interest.
The facial motion mask is computed from these
25 ROIs. The method used to build the feature vec-
tor from the facial motion mask is illustrated in the
Figure 5. In each frame f
i
, we consider the filtered
Optical Flow inside each ROI R
k
i
, where i is the index
of frames and k = 1,2,...,25 is the index of ROIs. In-
side each R
k
i
, a histogram (η) is computed as defined
in equation 3 from the Optical Flow filtered consider-
ing the ROI as initial RHPM. Overtime, for each ROI,
the histograms are summed as defined in equation 4,
which correspond to local facial motion of the entire
sequence of facial motion.
ζ(R
k
) =
n
∑
i=1
η
k
i
(R
k
i
). (4)
Finally, all histograms ζ are concatenated into one-
row vector, which is considered as the feature vector
for the full and micro expression ζ = (ζ
1
,ζ
2
,...,ζ
n
).
An example is illustrated in the Figure 5, where all
histograms corresponding to the R
1
i
and R
22
i
with i ∈
[1,n] are summed as defined in equation 4 in ζ
1
and
ζ
22
respectively then added to ζ.
Figure 5: Method for building the feature vector from the
facial motion mask.
The features vector size is equal to the number of
ROI multiplied by the number of bins, making a total
of 900 features values.
5 EVALUATION
In this section, we evaluate the performance of our
proposed method on two datasets : (the extended
Cohn-Kanade database (Lucey et al., 2010) and
CASME2 (Yan et al., 2014). We discuss the choice
of optimal parameters for the databases and show
that only the magnitude intervals must be adapted
to accommodate the specificities of intensity of fa-
cial expression. Finally, we compare our performance
against major state-of-the-art approaches.
5.1 Full-expression
CK+ contains 410 facial expression sequences from
100 participants coming from different ethnicities and
genders. In these image sequences, the expression
starts from a neutral status and ends in the apex status.
The number of samples for the following expressions,
i.e. anger, sadness, happiness, surprise, fear and dis-
gust are 42, 82, 100, 80, 64 and 45, respectively.
In the experiments, we use LIBSVM (Chang and
Lin, 2011) with the Radial Basis Function kernel and
the 10 fold cross-validation protocol. This protocol is
used by several approaches working on CK+ as it fits
better to the size and the structure of the data set. Each
expression is classified into one of the six classes :
anger, fear, disgust, happiness, sadness, and surprise.
The following experimental results are obtained
using λ = 15, β = 3, ∆ = 10. Initially, we consid-
ered the following magnitude intervals in every re-
gion: M1(x)|x ∈ [1,10], M2(x )|x ∈ [2, 10], M3(x)|x ∈
[3,10], M4(x)|x ∈ [4,10], M5(x)|x ∈ [5,10]. Each in-
terval stops at a maximum of 10, where 10 corre-
sponds to the mean of the max of coherent magnitude
estimated from all sequences. The overlap of inter-
vals allow to ensure consistency in each histogram.
Small movements around the mouth corners and be-
tween the eyes were not always detected and we in-
cluded the magnitude M
0
and delete the magnitude
M
5
to retain only 5 intervals of magnitudes for the
corresponding regions R
3
,R
19
,R
22
.
Table 1 compares the performance of the proposed
method with the recent state-of-the-art Optical Flow
methods on CK+. The performance of the our system
is comparable with the other systems as it achieved
an average recognition rate of 93.17% with alignment
based on eyes and coherent Optical Flow. Neverthe-
less, the highest recognition rate is obtained using fea-
tures from the filtered coherent facial motion com-
bined with geometric features.
Our method reported comparable recognition per-
formance with the most competitive Optical Flow ap-
proaches. Although we report the best accuracy re-
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
240

Table 1: Performance Comparison of Different State-of-
the-Art Optical Flow Approaches on CK+ Database. The
bold means our proposed methods.
Method Measure Seq. Exp. Acc(%)
(Liao et al., 2013) LOSO 442 6 92,5%
(Su et al., 2007) train/test 415 5 93,27%
(Lee and Chellappa, 2014) 4-fold ndef 7 86,7%
Coherent Flow + RHPM 10-fold 410 6 93.17%
Coherent Flow + RHPM + Geom. 10-fold 410 6 95.34%
sults for 6-class expressions, Su et al. (Su et al., 2007)
achieve higher scores, but they only use 5 classes
(Neutral, Happy, Surprise, Sad, Anger). Considering
the variations observed in the number of sequences
and expression types recognized by the various meth-
ods it is difficult to clearly identify the best one. For
our experiments we used the original CK+ collection
as introduced in (Lucey et al., 2010) and we brought
no modification neither to the videos nor the annota-
tions.
We have shown that our approach obtains good
performances in CK+, where the expressions are
acted and there is little or no disruptions (head mo-
tion, lightning variation). Next, we present the perfor-
mance of our method to recognize micro-expressions.
5.2 Micro-expression
The CASME2 database contains 246 spontaneous
micro-expressions from 26 subjects, categorized into
five classes: happiness (32 samples), disgust (63 sam-
ples), surprise (25 samples), repression (27 samples)
and Others (99 samples).
In the experiments, we use leave-one-subject-out
(LOSO) cross validation protocol because it is more
strict than leave-one-out (LOO) cross validation and
matches better the structure of the data (different
number of videos par subject). In this protocol, the
samples from one subject are used for testing, the rest
for training. We use the LIBSVM (Chang and Lin,
2011) with the Radial Basis Function and the grid
search method, where the optimal parameter is pro-
vided using ten-fold cross validation.
Table 2 shows a comparison to some other ap-
proaches for micro-expression using the recognition
rates given in each paper. It should be noted that
the results are not directly comparable due to differ-
ent experimental setups (number of expression classes
and number of sequences), but they still give an
indication of the discriminating power of each ap-
proach. Our method outperforms the other meth-
ods in almost all cases. The best results are ob-
tained using the same mask and parameters as for full-
expression recognition (λ = 15, β = 3, ∆ = 10) except
for the division of magnitudes defined here as follows
: M1(x)|x ∈ [0.1,5], M2(x)|x ∈ [0.2,5], M3(x)|x ∈
[0.3,5], M4(x)|x ∈ [0.4,5], M5(x)|x ∈ [0.5,5]. The
geometric information was not considered here, as
the landmarks locations are mostly stables through-
out the sequence. It should be noted that the Optical
Flow is not calculated from two consecutive frame but
on two frame intervals. Indeed, the time lapses be-
tween two frame in CASME2 is so small (recorded
with high-speed camera (at 200 fps)) and combined
with the low expression intensity it is difficult not
make a distinction between the noise and the true fa-
cial motion. No magnitude consistency can be found
in local region with our method when consecutive
frames are processed. Hence, we are considering the
entire sequence, but this is frequent in the literature
as other authors summarize videos in fewer frames
(Wang et al., 2014b; Huang et al., 2016a; Huang et al.,
2016b).
Table 2: Performance comparison with the state-of-the-art
methods on CASME2 database. Results in bold correspond
to our method.
Method Measure Class Acc(%)
Baseline (Yan et al., 2014) LOO 5 63.41%
LBP-SIP (Wang et al., 2014b) LOO 5 67.21%
LSDF (Wang et al., 2014a) LOO 5 65.44%
MDMO (Liu et al., 2015) LOSO 4 67.37%
STLBP-IIP (Huang et al., 2016a) LOSO 5 62.75%
DiSTLBP-IPP (Huang et al., 2016a) LOSO 5 64.78%
Coherent Flow + RHPM LOSO 5 65.35%
If the recognition process is re-evaluated on a four
classes basis (Happy, Disgust, Surprise, Repression),
the performance is improved by 11.57%, which cor-
responds to an accuracy of 76.92%. This proves that
the Other class does not stand out clearly from oth-
ers. In (Liu et al., 2015), the repression and the other
sequences are combined in a single class, which re-
duces the chances of falsely classification of Happi-
ness to Repression class. This new organization re-
ported a gain of 1.02% with our method. Moreover,
(Liu et al., 2015) reported on removing 11 samples
in the recognition process due to mis-estimates of the
facial features in the first frame of the video.
The results obtained on the original CASME2 and
the reorganized variants show the good performances
for micro-expressions recognition. Our method out-
performs the other state-of-the-art methods in al-
most all cases. These results were obtained by em-
ploying the same method used for recognizing full-
expressions, except for, smaller magnitude intervals
that were considered in order to fit better to low mag-
nitudes in micro-expressions.
Consistent Optical Flow Maps for Full and Micro Facial Expression Recognition
241

6 CONCLUSIONS
In the paper, we have shown that the coherent move-
ment extracted from dense Optical Flow method by
considering the facial movement hypothesis achieves
state-of-the-art performance on both facial full-
expression and micro-expression databases. The
magnitude and direction constraints are estimated in
order to reduce the noise induced by lighting changes
and small head motions over time. The proposed ap-
proach adapts well on both full-expressions (CK+)
and micro-expressions (CASME2). The only adjust-
ment concerning the magnitude intervals is actually
related to the nature of expression. The other param-
eters common to both experiences have been selected
empirically and deserve specific attention in future
experiments.
Our current approach is used only in near-frontal-
view recordings where the presence of occlusions,
fast head motion and lightning variation is practi-
cally zero. The next step consist in adapting our
method to the domain of spontaneous facial expres-
sion recognition. To address this situation, a normal-
ization method will be necessarily used. However, it
must be kept in mind that any change made in the
facial picture has important side-effects on the Op-
tical Flow. Despite the wealth of research already
conducted, no method is capable of dealing with all
issues at a time. We believe that the normalization
approaches based on facial components or shape are
not adapted to Optical Flow as facial deformation will
impact Optical Flow computation by inducing motion
distortion. So rather than considering the normaliza-
tion in the field of facial components, efforts should
instead be focused on the Optical Flow domain.
ACKNOWLEDGEMENTS
This research has been partially supported by the FUI
project MAGNUM 2.
REFERENCES
Bailer, C., Taetz, B., and Stricker, D. (2015). Flow fields:
Dense correspondence fields for highly accurate large
displacement optical flow estimation. In ICCV.
Chang, C.-C. and Lin, C.-J. (2011). Libsvm: a library for
support vector machines. ACM TIST.
Chen, Q. and Koltun, V. (2016). Full flow: Optical flow
estimation by global optimization over regular grids.
CVPR.
Farneb
¨
ack, G. (2003). Two-frame motion estimation based
on polynomial expansion. In SCIA. Springer.
Fortun, D., Bouthemy, P., and Kervrann, C. (2015). Optical
flow modeling and computation: a survey. Computer
Vision and Image Understanding.
Han, S., Meng, Z., Liu, P., and Tong, Y. (2014). Facial grid
transformation: A novel face registration approach for
improving facial action unit recognition. In ICIP.
Huang, X., Wang, S., Liu, X., Zhao, G., Feng, X.,
and Pietikainen, M. (2016a). Spontaneous fa-
cial micro-expression recognition using discrimina-
tive spatiotemporal local binary pattern with an im-
proved integral projection. CVPR.
Huang, X., Zhao, G., Hong, X., Zheng, W., and Pietik
¨
ainen,
M. (2016b). Spontaneous facial micro-expression
analysis using spatiotemporal completed local quan-
tized patterns. Neurocomputing.
Jiang, B., Martinez, B., Valstar, M. F., and Pantic, M.
(2014). Decision level fusion of domain specific re-
gions for facial action recognition. In ICPR.
Kazemi, V. and Sullivan, J. (2014). One millisecond face
alignment with an ensemble of regression trees. In
CVPR.
Lee, C.-S. and Chellappa, R. (2014). Sparse localized fa-
cial motion dictionary learning for facial expression
recognition. In ICASSP.
Li, X., Pfister, T., Huang, X., Zhao, G., and Pietik
¨
ainen,
M. (2013). A spontaneous micro-expression database:
Inducement, collection and baseline. In FG.
Liao, C.-T., Chuang, H.-J., Duan, C.-H., and Lai, S.-H.
(2013). Learning spatial weighting for facial expres-
sion analysis via constrained quadratic programming.
Pattern Recognition.
Liu, Y.-J., Zhang, J.-K., Yan, W.-J., Wang, S.-J., Zhao, G.,
and Fu, X. (2015). A main directional mean optical
flow feature for spontaneous micro-expression recog-
nition. Affective Computing.
Lucey, P., Cohn, J. F., Kanade, T., Saragih, J., Ambadar, Z.,
and Matthews, I. (2010). The extended cohn-kanade
dataset (ck+): A complete dataset for action unit and
emotion-specified expression. In CVPR Workshops.
P
´
eteri, R. and Chetverikov, D. (2005). Dynamic texture
recognition using normal flow and texture regularity.
In IbPRIA.
Revaud, J., Weinzaepfel, P., Harchaoui, Z., and Schmid, C.
(2015). Epicflow: Edge-preserving interpolation of
correspondences for optical flow. In CVPR.
Su, M.-C., Hsieh, Y., and Huang, D.-Y. (2007). A simple
approach to facial expression recognition. In WSEAS.
Wang, S.-J., Yan, W.-J., Zhao, G., Fu, X., and Zhou, C.-G.
(2014a). Micro-expression recognition using robust
principal component analysis and local spatiotempo-
ral directional features. In ECCV Workshop.
Wang, Y., See, J., Phan, R. C.-W., and Oh, Y.-H. (2014b).
Lbp with six intersection points: Reducing redundant
information in lbp-top for micro-expression recogni-
tion. In ACCV.
Yan, W.-J., Li, X., Wang, S.-J., Zhao, G., Liu, Y.-J., Chen,
Y.-H., and Fu, X. (2014). Casme ii: An improved
spontaneous micro-expression database and the base-
line evaluation. PloS one.
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
242
