
Geometrical and Visual Feature Quantization for 3D Face Recognition
Walid Hariri
1,2
, Hedi Tabia
1
, Nadir Farah
2
, David Declercq
1
and Abdallah Benouareth
2
1
ETIS/ENSEA, University of Cergy-Pontoise, CNRS, UMR 8051, Cergy-Pontoise, France
2
Labged Laboratory, Computer Science Department, Badji Mokhtar Annaba University, Annaba, Algeria
Keywords:
LBP, HoS, Bag-of-Features, Codebook, Depth Image, Term Vector.
Abstract:
In this paper, we present an efficient method for 3D face recognition based on vector quantization of both
geometrical and visual proprieties of the face. The method starts by describing each 3D face using a set of
orderless features, and use then the Bag-of-Features paradigm to construct the face signature. We analyze
the performance of three well-known classifiers: the Na
¨
ıve Bayes, the Multilayer perceptron and the Random
forests. The results reported on the FRGCv2 dataset show the effectiveness of our approach and prove that the
method is robust to facial expression.
1 INTRODUCTION
Face recognition has recently gained a blooming
attention and interest from the pattern recognition
community (Jafri and Arabnia, 2009). Many ap-
plications use facial recognition including security
oriented applications (access-control/verification sys-
tems, surveillance systems), computer entertainment
and customized computer-human interaction. Most
existing recognition methods are based on the 2D ap-
pearance of faces and discard their 3D shapes. This
leads to a poor discrimination power when dealing
with variation such as illumination, expressions, oc-
clusion or head poses. The availability of 3D scanners
and the rapid evolution in graphics hardware and soft-
ware, have greatly facilitated a shift from 2D to 3D
approaches. The advantage of the 3D representation
is in having more discriminant information regarding
the face’s shape which is less sensitive to variations.
Recent surveys of 3D face recognition advances can
be found in (Luo et al., 2015; Mishra et al., 2015).
3D face data can be also combined with 2D face
data to build multimodal approaches. Most efforts to
date in this area use relatively simplistic approaches
to fusing results obtained independently from the 3D
data and the 2D data. A multimodal recognition sys-
tem could perform better than any one of its individ-
ual components (Jyothi and Prabhakar, 2014; Bowyer
et al., 2006; Chang et al., 2005).
To describe the visual proprieties of both 2D and
3D face data, Local Binary Patterns (LBPs) (Ojala
et al., 2002) is a technique that has been widely ap-
plied for this purpose, especially in facial expression
recognition (Shan et al., 2009) and face recognition
(Ahonen et al., 2006; Huang et al., 2012). LBP
has a several advantages such as its high discrimina-
tive power, its tolerance against illumination changes
and its computational simplicity. A plenty of LBP
based face recognition methods have been proposed
in the literature (Huang et al., 2011b; Yang and Chen,
2013). Although, the various advantages of the LBP
descriptor, few drawbacks, such as the lose of the
global structure of the face, are still not handled. In
this paper, we propose a compact face representation
computed from two different modalities and aggre-
gated using the conventional Bag-of-Features (BoF).
The paradigm of BoF has successfully been applied in
several domains such as shape classification, object
detection and image retrieval (O’Hara and Draper,
2011). Here, we exploit both 3D and 2D face de-
scriptions to get a robust 3D face recognition system.
We firstly extract the Histogram of Shape index (HoS)
which represent the surface planarity of each face re-
gion according to the values of its Shape index (SI).
All shapes can be mapped into the interval: SI ∈ [0, 1],
where each value represents a different shape (saddle,
cup, dome, rut, ridge, etc.). Note that SI is mostly
used to extract histogram as shape descriptor because
it is independent of the scale variation. Next, once
we have extracted 2D depth image from each 3D face
mesh, we extract the LBP descriptor to describe the
face depth variation. Note that in our method, instead
of combining the extracted region histograms to get a
global descriptor, we use BoF representation instead
to get a global face description as orderless collections
of local features, after concatenation of their term vec-
tors. Finally, three different classifiers are applied to
assess the performance of our method.
Hariri W., Tabia H., Farah N., Declercq D. and Benouareth A.
Geometrical and Visual Feature Quantization for 3D Face Recognition.
DOI: 10.5220/0006101701870193
In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2017), pages 187-193
ISBN: 978-989-758-226-4
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
187
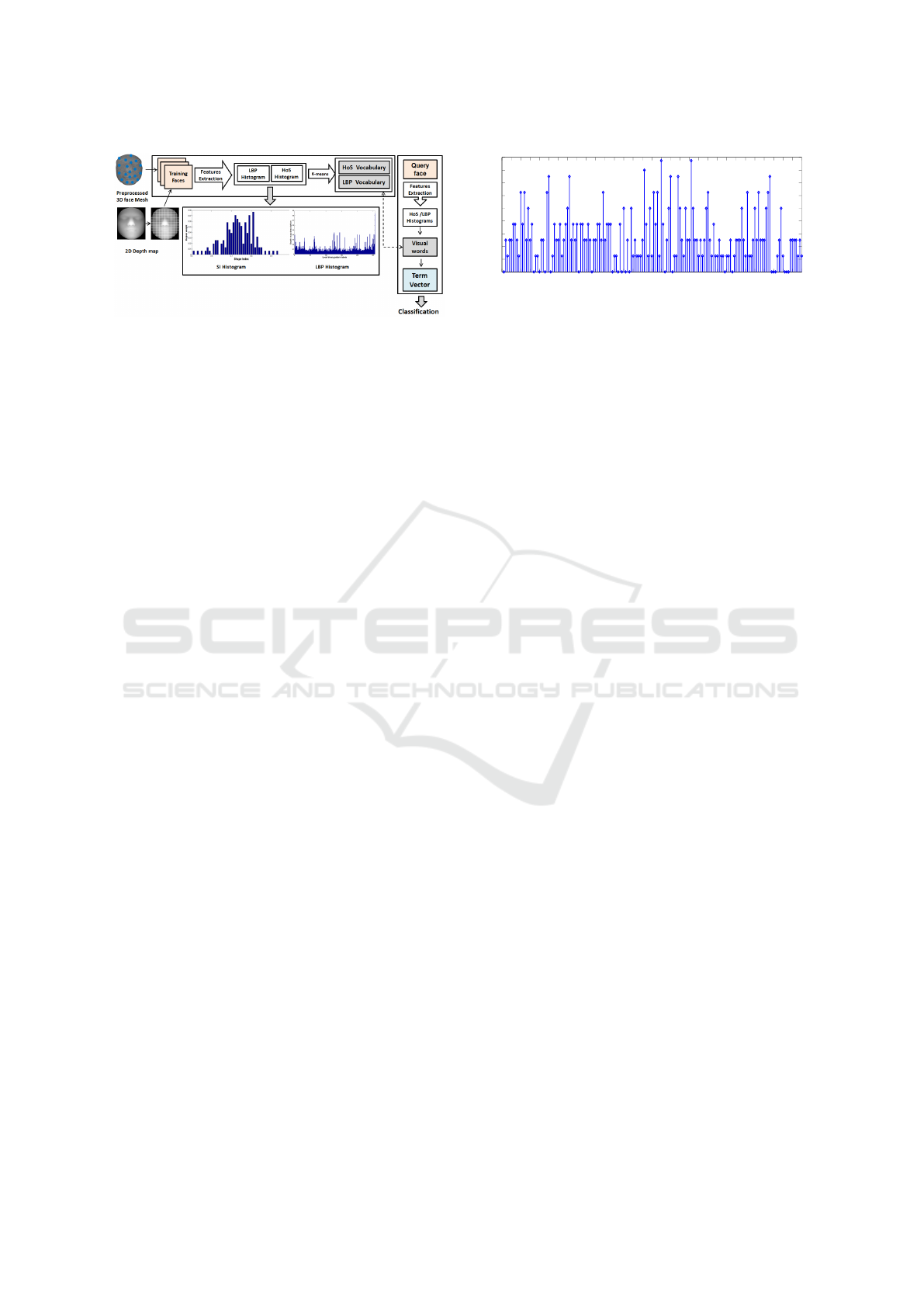
Figure 1: Overview of the proposed method.
The remainder of the paper is organized as fol-
lows, Section 2 presents the related works, the method
is described in Section 3. We detail the face descrip-
tion in Section 4. In Section 5, we present the used
classifiers. Experimental results and conclusion end
the paper.
2 RELATED WORKS
The conventional design of recognition systems goes
into two different steps; feature extraction and
face comparison. Several feature extraction meth-
ods have been proposed in the literature; signature
points (Chua et al., 2000), curves (Drira et al., 2013),
landmarks and curvatures (Creusot et al., 2013),
SIFT (Smeets et al., 2013), curvelet (Elaiwat et al.,
2014), covariance (Tabia et al., 2014; Tabia and Laga,
2015; Hariri et al., 2016a; Hariri et al., 2016b). For
face comparison, matching based technique such as
Iterative Closest Point (ICP) registration (Besl and
McKay, 1992) have been widely used. Machine learn-
ing based approaches have also been used for face
comparison (SVM (Lei et al., 2013), Neural net-
work (Sun et al., 2014; Ding and Tao, 2015), Ran-
dom forests (Fanelli et al., 2013), Adaboost (Xu et al.,
2009; Ballihi et al., 2012)). Most of these approaches
construct a set of statistical rules which are then used
to recognize unknown faces. Compared with match-
ing methods, machine learning based approaches pro-
vide efficient solutions to deal with big size galleries.
In this paper, we have applied a supervised learn-
ing approach based on three well-known classifiers;
the Na
¨
ıve Bayes, the Multilayer perceptron and the
Random forests.
3 METHOD
Figure 1 presents an overview of the proposed
method. After the acquisition step, the input face
surface is preprocessed to improve the quality of the
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100 105 110 115 120 125 130 135 140 145 150 155 160
0
0.005
0.01
0.015
0.02
0.025
0.03
0.035
0.04
0.045
Visual words
Occurrences
Figure 2: Global term vector from a query face. Items indi-
cate the occurrence of each visual word in the face.
input face which may contain some imperfections
as holes, spikes and includes some undesired parts
(clothes, neck, ears, hair, etc.) and so on. It consists of
applying successively a set of filters. First, a smooth-
ing filter is applied, which reduces spikes in the mesh
surface, followed by a cropping filter which cuts and
returns parts of the mesh inside an Euclidean sphere.
Next a filling holes filter is applied, which identifies
and fills holes in input meshes. Finally, to remove
spikes, we apply a median filter on 3D face vertices.
The filter starts by sorting the z coordinate within a
neighborhood, finding then the median, and finally re-
placing the original z coordinate with the value of the
median.
Once the 3D face mesh has been preprocessed, we
firstly extract N feature points using a uniform sam-
pling of the 3D face surface, the feature points are the
center of N patches from a paving of the face. Next,
from each 3D face, we extract the 2D depth image
where the gray value of each image pixel represents
the depth of the corresponding point on the 3D sur-
face. All 2D faces are normalized to 150 × 150 pix-
els. This 2D representation is widely used in 3D facial
analysis (Berretti et al., 2011; Huang et al., 2011a;
Vretos et al., 2011). As an example, Figure 3 illus-
trates 2D depth map images derived from 3D face
scans of the same subject. Then, we extract HoS and
LBP descriptors from the 3D face mesh and its cor-
responding 2D depth image, respectively. Once the
local descriptors have been extracted, we apply the
BoF paradigm to build a final compact signature.
Finally, to describe the whole face using BoF rep-
resentation, we build two different visual vocabular-
ies (C
Hos
, C
Lbp
) using k-means clustering. Note that
the number of visual words chosen for each vocabu-
lary may be different. In our implementation, we use
same size vocabularies (k
h
= k
l
, where k
h
is the num-
ber of words in C
Hos
and k
l
is the number of words
in C
Lbp
). A term vector is then computed as the oc-
currence of each visual word in the face, and a global
term vector of dimension k = k
h
+ k
l
is constructed.
It is obtained by serially concatenating both HoS and
LBP term vectors (see Figure 2).
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
188

4 FACE DESCRIPTION AND
FEATURES QUANTIZATION
In this section, we present the geometrical and visual
features of faces, as well as their quantization using
BoF paradigm.
4.1 Local Binary Pattern
LBP has originally been proposed by (Ojala et al.,
2002) for texture classification, and then extended
for various fields, including face recognition (Ahonen
et al., 2006; Yang and Chen, 2013) and face detection
(Sandbach et al., 2012). The LBP histogram com-
pares each center pixel with its neighbors, encoding
this relation into a binary word i.e. the ones whose in-
tensities exceed the center pixel’s are marked as (1),
otherwise as (0). This allows detection of patterns,
while being robust to contrast changes.
The 256-bin histogram of the labels computed
over an image can be used as a texture descriptor. In
this way we get a simple circular point features con-
sisting of only binary bits. Typically the feature ring
is unfolded as a row vector; and then with a binomial
weight assigned to each bit, the row vector is trans-
formed into decimal code for further use. Local prim-
itives which are codified by these bins include differ-
ent types of curved e.g. edges, spots, flat areas, etc.
Figure 4 shows some regions detected by the uniform
patterns of LBP.
Some LBP histogram-based methods change the
neighborhood of the LBP operator for improved per-
formance. By varying the value of radius, the LBP
of different resolutions is thus obtained. For example,
the operator LBP
4,1
uses 4 neighbors while LBP
16,2
considers the 16 neighbors on a circle of radius 2. In
the following, we refer to the neighborhood size by
p, where r is the circle radius that forms a circularly
symmetric neighbor set. d
lbp
is the LBP dimension
(number of bins) which is obtained by: d
lbp
= 2
p
.
In our method, we extract LBP histogram for each
face patch of 2D depth image, therefore, we compute
8-by-8 neighbors to get 256 bins histogram.
Figure 3: Facial depth images derived from 3D face scans.
4.2 Histogram of Shape Index
Shape index (SI) expresses different shape classes by
a single number ranging from 0 to 1, it can be esti-
Figure 4: Regions detected by the uniform patterns of LBP.
White circles represent ones and black circles zeros.
Figure 5: Nine shape types and their locations on the Shape
index scale.
mated by the following equation:
SI =
1
2
−
1
π
arctan
k
max
+ k
min
k
max
− k
min
(1)
Where k
max
and k
min
are the principal curvatures of
the surface. In our method, the values of SI are quan-
tized to 50 bins to get a histogram (HoS) of dimen-
sion: d
hos
= 50. It will be then normalized to form
a feature vector for each face region. Every distinct
surface shape corresponds to a unique value of SI, ex-
cept the planar shape. Points on a planar surface have
an indeterminate SI, since k
max
= k
min
= 0.
The SI captures eight basic shape types of a sur-
face which are based on the signs of Gaussian and
mean curvatures that was employed by (Besl, 2012).
Figure 5 presents these shapes according to their SI
value.
4.3 Bag of Features
The BoF representation aims to aggregate local de-
scriptors into a compact signature (Tabia et al., 2012;
Tabia et al., 2011). We first learn a codebook C =
(w
1
, w
2
, ..., w
k
) of k visual words (terms) obtained by
k-means clustering. Note that in our method, we have
two codebooks (C
Hos
, C
Lbp
) of dimension k
h
and k
l
respectively, where k = k
h
+k
l
is the dimension of the
global codebook C. The next step is to quantize local
descriptors of dimension d
hos
, d
lbp
into a set of vi-
sual words. Hence, it produces a k-dimensional vec-
tor, which is subsequently normalized.
To build a BoF of an image, the following steps
are required:
• Build Vocabulary: by clustering features from all
faces in a training set.
• Assign Terms: by assigning the features from each
face to the closest terms in the vocabulary.
• Generate Term Vector: obtained by counting the
frequency of each term in the face. In this pa-
per, we extract two term vectors; V
hos
and V
lbp
re-
spectively for HoS and LBP descriptors. These
Geometrical and Visual Feature Quantization for 3D Face Recognition
189

vectors are then grouped into one single vector
V =
V
hos
, V
lbp
.
5 CLASSIFIERS
In this section, we presents the three supervised clas-
sifiers used in our method, where each face is rep-
resented by a term vector. Note that we use gallery
faces as training set, where probe faces are used for
the test. In the following, we note V = [v1, . . . , v
k
] the
term vector of each face, where each v
i
refers to the
occurrence of the term i in the given face. k is the
number of attributes, and m is the number of classes.
• Na
¨
ıve Bayes classifier: are probabilistic classifiers
based on the Bayesian theorem (Lewis, 1998).
Given a face image to be classified to m possi-
ble outcomes of face subjects in the dataset. Each
face image is represented by a term vector V of
dimension k. The classifier assigns to this face
image the probability p(C
i
|v
1
, . . . , v
k
). The condi-
tional probability can be decomposed as:
p(C
i
|V ) =
p(C
i
) p(v|C
i
)
p(v)
. In practice, the nai
¨
ve con-
ditional independence assumptions assume that
each term occurrence v
i
in the face is condition-
ally independent of every other term occurrence
v
j
in the same face, for j 6= i, given the subject
identity C
i
.
• Random forest classifier: consisting of a collec-
tion of tree-structured classifiers developed by
(Breiman, 2001). In our experiments we used
Random Forest algorithm by considering 50 trees.
Classification of a new face from an input term
vector V is performed by putting it down each of
the trees (t
1
, . . . , t
10
) in the forest F. Each tree
t
i
gives a classification decision d
i
by voting for
the face subject class C
i
. According to the global
decision D = (d
1
, . . . , d
10
), the forest chooses the
classification d
j
having the most votes over all the
trees in the forest.
• Multilayer perceptron classifier: to classify a
probe face using its term vector V, it uses a set
of term occurrence as input values (v
i
) and associ-
ated weights (w
i
) and a sigmoid function (g) that
sums the weights and maps the results to an output
(y). Note that the number of hidden layers used in
our experiments is given by:
m+k
2
.
6 EXPERIMENTAL RESULTS
6.1 Experiments on FRGCv2 Dataset
FRGCv2 database (Phillips et al., 2005) is one of the
most comprehensive and popular datasets, contain-
ing 4007 3D face scans of 466 different persons, the
data were acquired using a minolta 910 laser scan-
ner that produces range images with a resolution of
640×480. The scans were acquired in a controlled
environment and exhibit large variations in facial ex-
pression and illumination conditions but limited pose
variations. The subjects are 57% male and 43% fe-
male, with the following age distribution : 65% 18-
22 years old, 18% 23-27and 17% 28 years or over.
The database contains annotation information, such
as gender and type of facial expression. This dataset
was firstly preprocessed as described in the Section 3.
In this experiment, we use neutral images from each
subject as galleries and the rest images are used as
probes.
First, we uniformly sample N = 200 feature points
from the preprocessed 3D face surface. The N fea-
ture points are the center of N patches. Next, for each
patch, we have extracted two histogram descriptors to
describe both geometrical and visual proprieties of the
face region; the HoS is of d
hos
= 50 dimension com-
puted on the 3D mesh as described in Section 4.2, and
the LBP
8,1
based descriptor (p = 8, r = 1), which is a
256-dimensional histogram computed as described in
Section 4.1.
To build the codebook from both descriptors, we
used k-means algorithm for descriptor clustering. We
denote C
hos
and C
lbp
the codebooks constructed from
respectively HoS and LBP descriptors. Both code-
book sizes are fixed to be k
h
= k
l
= 80 terms. Once
the codebooks are constructed, each face is then de-
scribed using two term vectors (V
hos
= [h
1
, h
2
..., h
k
h
],
V
lbp
= [l
1
, l
2
..., l
k
l
]) which represent the number of
times the each term appears in the face (Section 4.3).
The concatenated term vector V = [V
hos
, V
lbp
] used for
classification is of k dimension (k = k
h
+h
l
= 160). It
is subsequently normalized (see Figure 2).
Finally, to assess the classification performance
of our method on FRGCv2 dataset, we have applied
three different classifiers as presented in Section 5.
Note that in our experiment, we use neutral gallery
faces for the training, while the rest are used for the
test.
Table 1 presents the classification performance
of the BoF representation using HoS and LBP his-
tograms separately, and the performance of the con-
catenated signature. We can clearly see that the com-
bination of the BoF of the extracted HoS and LBP his-
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
190
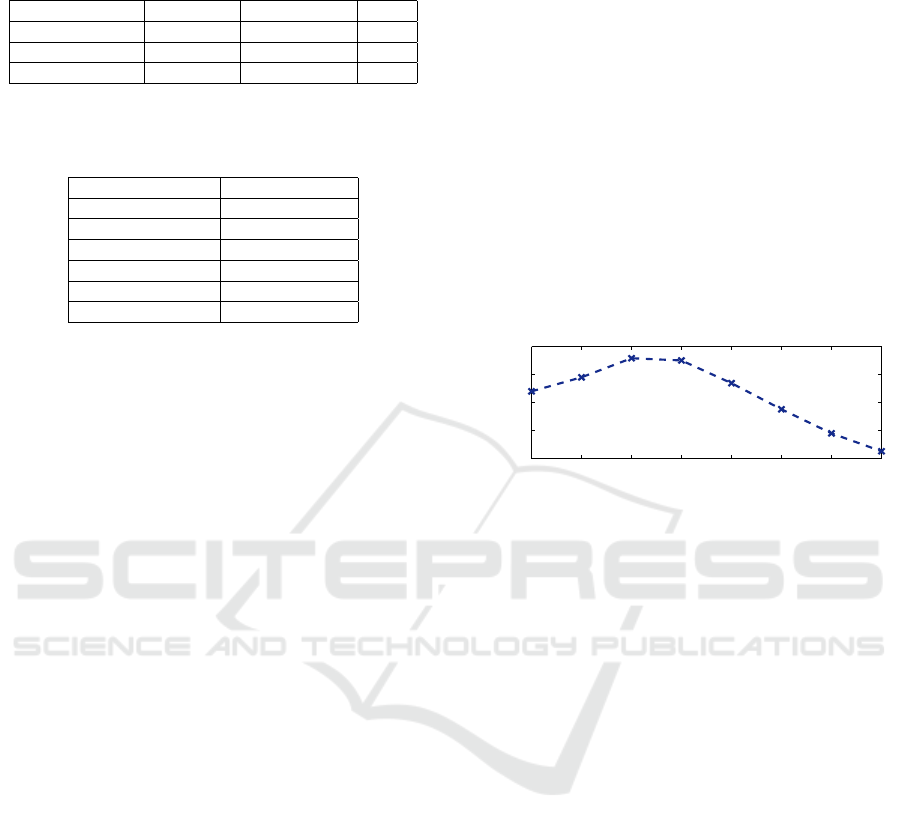
Table 1: Classification performance on FRGCv2 dataset us-
ing three different classifiers.
Method Na
¨
ıve Bayes Random forests MLP
Bag-of-HoS 91.2% 93.9% 96.1%
Bag-of-LBP 93.8% 94.8% 95.4%
Bag-of-(HoS+LBP) 95.4% 96.1% 97.9%
Table 2: Comparison with state-of-art methods on the
FRGCv2 dataset. The reported results are performed using
”Neutral versus All” identification protocol.
Method Neutral Versus. All
(Aly
¨
uz et al., 2010) 97.5%
(Elaiwat et al., 2014) 94.4%
(Drira et al., 2013) 97.0%
(Huang et al., 2012) 97.6%
(Faltemier et al., 2008) 97.2%
Our method 97.9%
tograms gives higher classification performance com-
pared to the separate use of term vectors from sin-
gle representation. This can be explained by the
fact that both descriptors are complementary and thus
their concatenation increases the classification perfor-
mance.
From Table 1, we can also see that BoF of LBP
representation performs better compared to the BoF
of HoS representation when using Random forests
and Na
¨
ıve Bayes classifiers. After combination, the
Multilayer perceptron classifier gives the highest clas-
sification rate (97.9%) due to its deep representation,
followed by Random forests and Na
¨
ıve Bayes respec-
tively. The high classification performance obtained
by Multilayer perceptron classifier is achieved thanks
to its high tolerance to noisy data, as well as its abil-
ity to classify patterns on which they have not been
trained. Note that the performance of our method can
further be improved by combining the three used clas-
sifiers using different combination approaches (e.g.
linear combination, majority vote, highest confidence
vote, etc.).
Table 2 presents a comparison of rank-1 recogni-
tion rate of our method to other state-of-art methods
using the same protocol. In this experiment, we eval-
uate ”Neutral versus All” identification experiment.
It can be observed that our method achieves the best
face identification performance among other state-
of-art methods with 97.9%. Particularly, (Elaiwat
et al., 2014) used curvelet local features and achieved
a rank-1 identification rate of 94.4%. (Drira et al.,
2013) used radial curves to represent the face sur-
faces, they achieved 97.0% rank-1 identification rate.
Furthermore, (Huang et al., 2012) used eLBP for 3D
facial representation and achieved 97.6% rank-1 iden-
tification rate. Besides, (Aly
¨
uz et al., 2010) utilized
curvature-based 3-D shape descriptors and achieved
97.5% rank-1 identification rate. Finally, (Faltemier
et al., 2008) achieved 97.2% rank-1 identification rate
using the matching of the best committee of local re-
gions. This comparison shows the efficiency of our
proposed method against expression variation.
6.2 Effect of Vocabulary Size
In this experiment, we analyzed how the classification
performance varies with respect to the visual vocab-
ulary size i.e. the number of visual words (k
h
, k
l
) in
each codebook. We set N = 200 the number of ex-
tracted HoS and LBP features, and vary the number
of visual words k
h
, k
l
of each codebook between 60
to 180. In our implementation, we use same values of
both k
h
and k
l
.
40 60 80 100 120 140 160 180
80
85
90
95
100
Number of terms
Classification rate
Figure 6: Effect of the codebook size on the classification
performance using Multilayer perceptron classifier.
Experimental results displayed in the Figure 6
shows that good results can be obtained even with a
relatively small number of visual words. The classifi-
cation rate remains stable when the number of terms
varies between 80 and 100, it starts to drop when
choosing values outside this interval, especially when
it exceeds 100 terms. Note that this performance de-
pends also on N (the number of the extracted feature
points from the face).
7 CONCLUSION
In this paper, we presented an efficient 3D face recog-
nition approach. We firstly extract the Histogram of
Shape index and Local binary pattern as region de-
scriptors from 3D mesh and 2D depth image respec-
tively. Next, we build two different visual vocabular-
ies using k-means clustering. A term vector is then
computed as the occurrence of each visual word in
the face, and a global term vector is constructed by
serially concatenating both HoS and LBP term vec-
tors. Our experiments on FRGCv2 dataset show that
the proposed method is robust against expression vari-
ation and gives challenging results compared to other
state-of-art methods.
Geometrical and Visual Feature Quantization for 3D Face Recognition
191

REFERENCES
Ahonen, T., Hadid, A., and Pietikainen, M. (2006). Face
description with local binary patterns: Application to
face recognition. Pattern Analysis and Machine Intel-
ligence, IEEE Transactions on, 28(12):2037–2041.
Aly
¨
uz, N., G
¨
okberk, B., and Akarun, L. (2010). Regional
registration for expression resistant 3-d face recogni-
tion. Information Forensics and Security, IEEE Trans-
actions on, 5(3):425–440.
Ballihi, L., Ben Amor, B., Daoudi, M., Srivastava, A., and
Aboutajdine, D. (2012). Boosting 3-d-geometric fea-
tures for efficient face recognition and gender classi-
fication. Information Forensics and Security, IEEE
Transactions on, 7(6):1766–1779.
Berretti, S., Amor, B. B., Daoudi, M., and Del Bimbo, A.
(2011). 3d facial expression recognition using sift de-
scriptors of automatically detected keypoints. The Vi-
sual Computer, 27(11):1021–1036.
Besl, P. J. (2012). Surfaces in range image understanding.
Springer Science & Business Media.
Besl, P. J. and McKay, N. D. (1992). Method for registration
of 3-d shapes. In Robotics-DL tentative, pages 586–
606. International Society for Optics and Photonics.
Bowyer, K. W., Chang, K., and Flynn, P. (2006). A survey
of approaches and challenges in 3d and multi-modal
3d+ 2d face recognition. Computer vision and image
understanding, 101(1):1–15.
Breiman, L. (2001). Random forests. Machine learning,
45(1):5–32.
Chang, K. I., Bowyer, K. W., and Flynn, P. J. (2005). An
evaluation of multimodal 2d+ 3d face biometrics. Pat-
tern Analysis and Machine Intelligence, IEEE Trans-
actions on, 27(4):619–624.
Chua, C.-S., Han, F., and Ho, Y.-K. (2000). 3d human face
recognition using point signature. In Automatic Face
and Gesture Recognition, 2000. Proceedings. Fourth
IEEE International Conference on, pages 233–238.
IEEE.
Creusot, C., Pears, N., and Austin, J. (2013). A machine-
learning approach to keypoint detection and land-
marking on 3d meshes. International journal of com-
puter vision, 102(1-3):146–179.
Ding, C. and Tao, D. (2015). Robust face recognition via
multimodal deep face representation. arXiv preprint
arXiv:1509.00244.
Drira, H., Ben Amor, B., Srivastava, A., Daoudi, M., and
Slama, R. (2013). 3d face recognition under expres-
sions, occlusions, and pose variations. Pattern Anal-
ysis and Machine Intelligence, IEEE Transactions on,
35(9):2270–2283.
Elaiwat, S., Bennamoun, M., Boussaid, F., and El-Sallam,
A. (2014). 3-d face recognition using curvelet local
features. Signal Processing Letters, IEEE, 21(2):172–
175.
Faltemier, T. C., Bowyer, K. W., and Flynn, P. J. (2008).
A region ensemble for 3-d face recognition. Infor-
mation Forensics and Security, IEEE Transactions on,
3(1):62–73.
Fanelli, G., Dantone, M., Gall, J., Fossati, A., and Van Gool,
L. (2013). Random forests for real time 3d face
analysis. International Journal of Computer Vision,
101(3):437–458.
Hariri, W., Tabia, H., Farah, N., Benouareth, A., and De-
clercq, D. (2016a). 3d face recognition using covari-
ance based descriptors. Pattern Recognition Letters,
78:1–7.
Hariri, W., Tabia, H., Farah, N., Declercq, D., and Be-
nouareth, A. (2016b). Hierarchical covariance de-
scription for 3d face matching and recognition under
expression variation. In 2016 International Confer-
ence on 3D Imaging (IC3D), pages 1–7. IEEE.
Huang, D., Ardabilian, M., Wang, Y., and Chen, L. (2011a).
A novel geometric facial representation based on
multi-scale extended local binary patterns. In Au-
tomatic Face & Gesture Recognition and Workshops
(FG 2011), 2011 IEEE International Conference on,
pages 1–7. IEEE.
Huang, D., Ardabilian, M., Wang, Y., and Chen, L. (2012).
3-d face recognition using elbp-based facial descrip-
tion and local feature hybrid matching. Informa-
tion Forensics and Security, IEEE Transactions on,
7(5):1551–1565.
Huang, D., Shan, C., Ardabilian, M., Wang, Y., and Chen,
L. (2011b). Local binary patterns and its application
to facial image analysis: a survey. Systems, Man, and
Cybernetics, Part C: Applications and Reviews, IEEE
Transactions on, 41(6):765–781.
Jafri, R. and Arabnia, H. R. (2009). A survey of face recog-
nition techniques. JIPS, 5(2):41–68.
Jyothi, K. and Prabhakar, C. (2014). Multi modal face
recognition using block based curvelet features. Inter-
national Journal of Computer Graphics & Animation,
4(2):21.
Lei, Y., Bennamoun, M., and El-Sallam, A. A. (2013). An
efficient 3d face recognition approach based on the fu-
sion of novel local low-level features. Pattern Recog-
nition, 46(1):24–37.
Lewis, D. D. (1998). Naive (bayes) at forty: The indepen-
dence assumption in information retrieval. In Machine
learning: ECML-98, pages 4–15. Springer.
Luo, J., Geng, S., Xiao, Z., and Xiu, C. (2015). A review
of recent advances in 3d face recognition. In Sixth
International Conference on Graphic and Image Pro-
cessing (ICGIP 2014), pages 944303–944303. Inter-
national Society for Optics and Photonics.
Mishra, B., Fernandes, S. L., Abhishek, K., Alva, A.,
Shetty, C., Ajila, C. V., Shetty, D., Rao, H., and Shetty,
P. (2015). Facial expression recognition using fea-
ture based techniques and model based techniques:
A survey. In Electronics and Communication Sys-
tems (ICECS), 2015 2nd International Conference on,
pages 589–594. IEEE.
O’Hara, S. and Draper, B. A. (2011). Introduction to the
bag of features paradigm for image classification and
retrieval. arXiv preprint arXiv:1101.3354.
Ojala, T., Pietik
¨
ainen, M., and M
¨
aenp
¨
a
¨
a, T. (2002). Mul-
tiresolution gray-scale and rotation invariant texture
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
192

classification with local binary patterns. Pattern Anal-
ysis and Machine Intelligence, IEEE Transactions on,
24(7):971–987.
Phillips, P. J., Flynn, P. J., Scruggs, T., Bowyer, K. W.,
Chang, J., Hoffman, K., Marques, J., Min, J., and
Worek, W. (2005). Overview of the face recogni-
tion grand challenge. In Computer vision and pattern
recognition, 2005. CVPR 2005. IEEE computer soci-
ety conference on, volume 1, pages 947–954. IEEE.
Sandbach, G., Zafeiriou, S., and Pantic, M. (2012). Local
normal binary patterns for 3d facial action unit detec-
tion. In Image Processing (ICIP), 2012 19th IEEE In-
ternational Conference on, pages 1813–1816. IEEE.
Shan, C., Gong, S., and McOwan, P. W. (2009). Facial
expression recognition based on local binary patterns:
A comprehensive study. Image and Vision Computing,
27(6):803–816.
Smeets, D., Keustermans, J., Vandermeulen, D., and
Suetens, P. (2013). meshsift: Local surface features
for 3d face recognition under expression variations
and partial data. Computer Vision and Image Under-
standing, 117(2):158–169.
Sun, Y., Wang, X., and Tang, X. (2014). Deep learning
face representation from predicting 10,000 classes. In
Computer Vision and Pattern Recognition (CVPR),
2014 IEEE Conference on, pages 1891–1898. IEEE.
Tabia, H., Daoudi, M., Colot, O., and Vandeborre, J.-P.
(2012). Three-dimensional object retrieval based on
vector quantization of invariant descriptors. Journal
of Electronic Imaging, 21(2):023011–1.
Tabia, H., Daoudi, M., Vandeborre, J.-P., and Colot, O.
(2011). A new 3d-matching method of nonrigid and
partially similar models using curve analysis. IEEE
Transactions on Pattern Analysis and Machine Intel-
ligence, 33(4):852–858.
Tabia, H. and Laga, H. (2015). Covariance-based descrip-
tors for efficient 3d shape matching, retrieval, and
classification. Multimedia, IEEE Transactions on,
17(9):1591–1603.
Tabia, H., Laga, H., Picard, D., and Gosselin, P.-H. (2014).
Covariance descriptors for 3d shape matching and
retrieval. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, pages
4185–4192.
Vretos, N., Nikolaidis, N., and Pitas, I. (2011). 3d facial ex-
pression recognition using zernike moments on depth
images. In Image Processing (ICIP), 2011 18th IEEE
International Conference on, pages 773–776. IEEE.
Xu, C., Li, S., Tan, T., and Quan, L. (2009). Automatic 3d
face recognition from depth and intensity gabor fea-
tures. Pattern Recognition, 42(9):1895–1905.
Yang, B. and Chen, S. (2013). A comparative study on local
binary pattern (lbp) based face recognition: Lbp his-
togram versus lbp image. Neurocomputing, 120:365–
379.
Geometrical and Visual Feature Quantization for 3D Face Recognition
193
