
Change Rule Execution Scheduling in Incremental Roundtrip
Engineering Chain: From Model-to-Code and Back
Van Cam Pham, Ansgar Radermacher, S
´
ebastien G
´
erard and Florian Noyrit
CEA, LIST, Laboratory of Model Driven Engineering for Embedded Systems, P.C. 174, Gif-sur-Yvette, 91191, France
Keywords:
Code Generation, Change Rules, Incremental, Model Transformation, Model Driven Engineering, EMF-
IncQuery, AST.
Abstract:
Model driven engineering allows many stakeholders to contribute their expertise to the system description.
This practice enables agility but implies consistency maintenance issues between different system models.
Incremental model transformations (IMT) are used to synchronize different artifacts contributed by the stake-
holders. IMTs detect changes on the source model and execute change rules to propagate updates to the target
model. However, the execution of change rules is not straightforward. A rule is only correctly executed if
its precondition is satisfied at execution time. The precondition checks the availability of certain source and
target elements involved in the rule. If a rule is executed when the precondition is false, either the execution
is blocked or stopped. Therefore, the produced target model becomes incorrect. This paper presents two ap-
proaches to the scheduling of change rule execution in incremental model transformations. These approaches
are also applied to the case of model and code synchronization and implemented in a tool named IncRoundtrip
that transforms and generates code for distributed systems. We also compare the runtime execution perfor-
mance of different incremental approaches with batch transformation and evaluate their correctness.
1 INTRODUCTION
The use of Model Driven Engineering (MDE) has in-
creased in industries to gain quality and productivity
(Mussbacher et al., 2014). In MDE, the process of de-
veloping a system most often relies on chaining trans-
formations from source models at high level abstrac-
tion to target models and finally to code. Those two
techniques are identified as model to model (M2M)
and model to code (M2C) transformations. However,
the development of complex system hardly follows a
purely linear development process. Indeed, in modern
developments many stakeholders contribute their ex-
pertise to the system description in an iterative way.
This practice enables agility but implies consistency
maintenance issues. In order to solve maintenance
issues, incremental model transformations (IMT) are
proposed.
IMTs consist of three phases: source model
change detection, impact analysis, and change prop-
agation (Kusel et al., 2013). The first phase detects
which elements are added-to, modified-in or deleted-
from the source model. The impact analysis maps
these changes to change rules and the last phase exe-
cutes the change rules to update the target model.
Changes are often captured by mechanisms of the
modeling environment in transactions. In case many
changes are detected, many associated change rules
need to be executed to produce a correct target model.
However, change rules cannot simply be executed in
the same order as the associated modifications. The
execution of a rule usually uses not only changed
elements in the source model but also certain other
source and target elements. In on-demand transfor-
mation mode, the changed source elements and cer-
tain other source elements used by a rule are avail-
able in the source model but in runtime mode, the
source elements involved in the rule execution may
not appear at the change time and added later by other
model manipulations. Moreover, the target elements
involved in the execution of a rule might be missing
at the change time. If a rule is executed at the time the
involved elements have not appeared yet in the source
or the target model, either the execution is blocked or
stopped, thus the produced target model is not cor-
rect. In that way, a wrong change rule execution or-
der even leads the violation of correctness and con-
sistency of transformations. Therefore, the transfor-
mation engine must determine which rule to be fired
first.
Pham, V., Radermacher, A., Gérard, S. and Noyrit, F.
Change Rule Execution Scheduling in Incremental Roundtrip Engineering Chain: From Model-to-Code and Back.
DOI: 10.5220/0005687702250232
In Proceedings of the 4th International Conference on Model-Driven Engineering and Software Development (MODELSWARD 2016), pages 225-232
ISBN: 978-989-758-168-7
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
225
This paper presents two approaches named target-
independence and target-dependence, respectively,
dedicated to the scheduling of change rule execution
in incremental model transformations. In these ap-
proaches, we specify that a rule is successfully exe-
cuted if all its required elements are available. These
required elements can be in the source or target mod-
els. These elements play the role of a precondition
of a change rule. The precondition is explicitly ex-
pressed in change rules. Once the precondition is pro-
vided, it is verified at runtime before firing the associ-
ated rule. These approaches are put in practice by im-
plementing a tool named IncRoundTrip that supports
incremental JAVA round-trip engineering and deploy-
ment from UML models. We compare the runtime ex-
ecution performances of the round-trip chain between
the two approaches and a batch transformation.
The remainder of the paper is structured as fol-
lows: Section 2 shows a motivating example. Section
3 presents works related to incremental model trans-
formation. Section 4 and 5 focus on our approaches
and round-trip engineering from models to code, re-
spectively. Section 6 tests the approaches by means
of a proof of concept implementation of a tool named
IncRoundtrip. We conclude and plan future works in
Section 7.
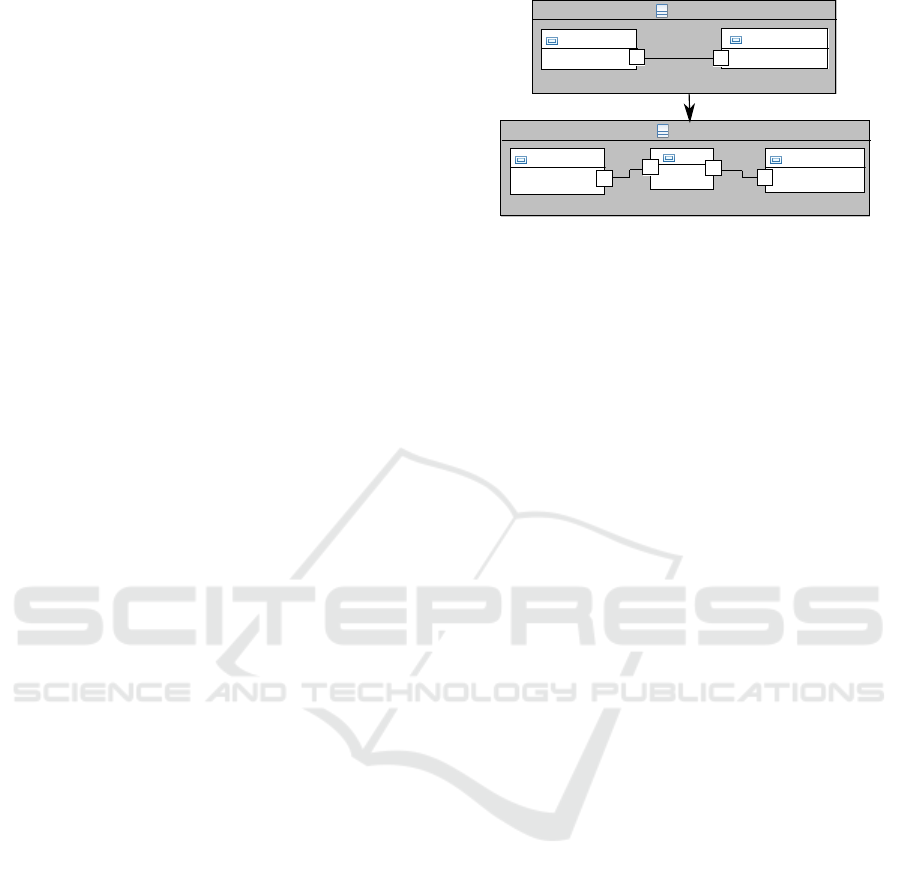
2 MOTIVATING EXAMPLE
Our motivating example transforms a UML connec-
tor into an interaction component (Radermacher et al.,
2009). This M2M transformation exists in the de-
ployment tool Qompass Designer (Qompass, 2015),
but is currently not implemented in an incremental
way. As in Figure 1, the transformation consists of
two rules of copying classes and properties from a
UML source model and reifying UML connector to
an interaction component, respectively. In a batch
transformation, the transformation engine orderly vis-
its System, client, server and eventually connector to
transform them to the target model.
In runtime incremental mode, the model evolution
process adds System, client, server and connector to
the source model. To propagate these changes, the
copying rule and the reification rule are executed three
times and one, respectively. There are many order-
ing options to execute these rules. If the transforma-
tion engine chooses copying System first, then client,
server, and finally reifying the connector, the target
model is correctly produced.
If the reification rule is fired first instead, the run-
time execution of the rule will not find the proper-
ties client and server in the target model. The engine
System
client: Client
clientPort: ICompute
server: Server
serverPort: ICompute
System
client: Client
clientPort: ICompute
server: Server
serverPort: ICompute
ic: IC
M2M
Figure 1: Transformation example from a UML Connector
into an interaction component.
therefore either stops or blocks the execution of the
rule. Thus the interaction component ic and the new
connectors are not created in the target model. In this
way, the resulting target model is not the same as that
of the batch transformation.
Optionally, the transformation engine can execute
change rules in the same order as the original mod-
ifications. In this example, if System, client, server
and connector are orderly added to the source model,
the transformation engine copies the class and the two
parts before reifying the connector to produce the cor-
rect model. However, if the connector is added by
model manipulations before the two parts are added,
the reification rule is fired before. Therefore, the reifi-
cation rule is not finished since the parts in the target
model involved in the execution are missing. This or-
der creates an incorrect target model.
3 RELATED WORK
This section presents different approaches related to
incremental model synchronizations and round-trip
engineering of models and code.
Triple graph grammar (TGG) (Kindler and Wag-
ner, 2007)(Giese and Wagner, 2006)(Hermann et al.,
2013) originates from graph theories. A graph trans-
formation rule consists of two sides: a left- and a
right-hand side. TGG performs local manipulations
on graph models by finding a match of its left hand
side graph pattern in the model and replacing it with
the right hand side graph. TGG can be used for bi-
directional transformations (Lauder et al., 2012) but
TGG assumes that relationships between source and
target model elements are bijective. Specifically, in
our case, a connector is transformed in two different
mappings.
QVT-R (OMG, 2008) standardized by OMG sup-
ports pre-conditions to schedule transformation rules.
However, up to now, there is no implementation that
supports full features of QVT-R.
MODELSWARD 2016 - 4th International Conference on Model-Driven Engineering and Software Development
226

Change driven model transformation (Bergmann
et al., 2011) is the approach that we base on. Dif-
ferently from other approaches, this approach consid-
ers changes as first-classes and part of transforma-
tion rules. In order to capture changes on a source
model, uncontrolled model changes caught by mech-
anisms of the modeling environment in transactions
are observed and evaluated. An incremental pattern
matching technique is used in the evaluation to de-
tect changes and send notifications to an event-driven
mechanism. The latter then maps changes to change
rules to propagate updates to the target model. Our
approach focuses on the change detection and impact
analysis phases which are parts of the model and code
synchronization mechanism. Moreover, we support
a batch transformation for the first time (the target
model does not exist yet) since batch transformations
are faster than IMTs in deriving the non-existing tar-
get model. Further modifications of the source model
are transformed by IMTs. Traceability links created
by the batch transformation are interrogated and used
by IMTs.
Round-trip engineering of models and code is sup-
ported by several tools and approaches. RTET in
(Nagowah et al., 2013) generates a working version of
a tiered application with a JSP presentation, EJB man-
ager classes with functions in JAVA, with an appro-
priate database model and Model/View/Control Web
application. AndroMDA (AndroMDA, 2015) is a
code generation framework that follows the Model
Driven Architecture (MDA) paradigm. AndroMDA
can generate deployable Java EE applications from a
UML model using Hibernate, EJB, Spring and Structs
frameworks. However, AndroMDA does not support
reverse engineering. ArgoUML (Tigris, 2015) is an
open source modeling tool that supports code gen-
eration and reverse engineering for skeleton code of
C++ and JAVA. However, ArgoUML does not pro-
vide a round-trip engineering for C++/JAVA. Reverse
engineering approaches in (Tonella, 2005) and (Xin
and Xiaojie, 2007) do not provide the co-evolution
between source code and models.
Our IncRoundTrip implementation is an open
source tool. IncRoundTrip offers not only a (partially)
incremental round-trip generation of JAVA and C++
from UML but also instant incremental model syn-
chronization.
4 INCREMENTAL MODEL
TRANSFORMATION
This section describes our incremental model syn-
chronization that is a part of the round-trip engineer-
ing chain. Our incremental synchronization of mod-
els consists of forward and backward transformations.
As in the introduction section, an IMT consists of
three phases: change detection, impact analysis and
change propagation. Change detection is executed
by a mechanism that listens to and receives elemen-
tary notifications from source models. Changes on
the source model are usually not related to the tar-
get model but the changed elements are linked to
the associated target elements in the impact analysis
phase to check the availability of required elements
and order the change rule execution. We refer this ap-
proach as target-independence since the changes on
the source model are detected without considering the
target model. The second one as target-dependence
considers the traceability links between the changed
elements of the source model and the associated ele-
ments in the target model.
4.1 Target-independence
For the first approach, as in Figure 2, a mecha-
nism as a query engine interrogates only the source
model separately from the target model. When the
source model changes, the mechanism receives these
changes and recognizes change pattern matches. The
query engine then sends a list of pattern matches to
the Analyzer which then maps these matches to cor-
responding change rules. A precondition is passed
along with a change rule in a form similar to ”when”
of QVT-R. It, as previously mentioned, consists of
one or several existing model elements required by its
corresponding change rule and is examined by the An-
alyzer. The Analyzer chooses one rule to analyze its
precondition. It retrieves target elements transformed
from source ones. If one of these target elements is
not available in the target model, the rule is sequen-
tially dependent on another rule and must be fired af-
ter the other rule. The Analyzer then puts the rule in
a queue and continues with other rules. If all required
elements of the rule are available, the rule is fired by
the Rule Executor. When the execution of a rule is
finished, the Analyzer reads a rule from the queue to
iterate the process. Algorithm 1 shows how the Ana-
lyzer works.
Algorithm 1 shows that the availability of all re-
quired elements must be verified before firing a rule.
However, the verification of the availability of re-
quired elements does not need to be done before the
activation of rules. Indeed, the verification can be
placed in rule execution. Therefore, a rule can be
executed immediately after an associated change is
detected. When the execution of the rule needs to
retrieve a target element by a retrieving function, it
Change Rule Execution Scheduling in Incremental Roundtrip Engineering Chain: From Model-to-Code and Back
227

Figure 2: Target-independent change detection.
checks the availability of that element. If the element
is available, it continues. Otherwise, either the rule
is put into the queue or the execution waits in the re-
trieving function and the execution is resumed when
the missing element is created in the target model.
To do this, we define the retrieving function that ma-
nipulates traceability links between source and target
model elements created in rule execution to get asso-
ciated target elements from source elements. The re-
trieving function returns target elements or waits until
these target elements are available. However, this op-
tion may create temporary inconsistencies in the pro-
duced model.
Algorithm 1: Change rule ordering by checking precondi-
tions.
Precondition: Change rules (CRs) and their precon-
ditions
1: function ACTIVATE RULES(CRs)
2: RulesQueue ← getAllRules(CRs);
3: while RulesQueue.notEmpty do
4: r ← dequeue(RulesQueue)
5: isReady ← areRequiredsAvailable(r)
6: if isReady then
7: execute(r )
8: else
9: enqueue(RulesQueue, r)
10: end if
11: end while
12: end function
In the previous example, the precondition of the
copy rule is that the container of the copied element
is mapped. Therefore, the container is put into the
list of required elements in the precondition. The
query engine gets a notification for each element
(System, client, server and connector) added to the
source model. Listing 1 (elements in blue are meta-
model elements of UML) shows the query rule writ-
ten in EMF-IncQuery (Ujhelyi et al., 2015) to rec-
ognize matches (the pattern matching is supported
by several approaches as in (Fan et al., 2013) and
(Bergmann et al., 2012)). A class, an attribute of
a class or a connector of a class Class(element) are
detected as added by Class.ownedAttribute(
clz, ele-
ment), and Class.ownedConnector( clz, element) re-
spectively. These matches are sent to the Analyzer
pa t t e r n add ed E l e m e n t ( ele ) {
Clas s ( e l e ) ;
} or {
Clas s . o w n e d A t t r i b u t e ( _clz , el e ) ;
} or {
Clas s . o w n e d C o n n e c t o r ( _clz , el e ) ;
}
Listing 1: EMF-IncQuery with the target-independent
approach.
as events. If the copying rule corresponding to the
added System is chosen first by the Analyzer, the lat-
ter checks that the execution of this rule does not in-
volve other elements since System is the root element
of the source model and does not have a container.
The Analyzer therefore fires the rule by transferring
the rule to the Rule Executor. The Analyzer then
checks other rules. However, if the reifying rule is
chosen before the copying rule, the Analyzer does not
find the required elements System, client and server.
This rule is added to the queue to be processed af-
ter these required elements are created. Similarly, the
Analyzer then checks other rules and finds the copy-
ing rule for System. As a result, client and server
are copied to the target model. The reifying rule is
then executed with the availability of all required el-
ements. Consequently, the produced target model be-
comes correct in any way of choosing rules to be an-
alyzed.
4.2 Target-dependence
The target-dependent approach is based on the fol-
lowing principle: a change is only detected if all of
its required elements are available and the execution
of a rule directly triggers other rules. Required ele-
ments are verified in the change detection phase in-
stead of the impact analysis phase. These required el-
ements are expressed as constraints of patterns writ-
ten in query languages such as EMF-IncQuery. To
do it, the query engine must be able to interrogate
both of the source and target models. As in Figure
3, this approach uses a traceability model between
the source and target models. The traceability model
refers to one or more source and target models and
has explicit traces that refer to elements of the source
and target models. The traceability metamodel is ex-
pressed in Figure 4. The source, traceability and tar-
get model are considered as one model. The query
engine queries not only the source model but also
the target and the traceability models. The princi-
ple of detecting changes is somewhat similar to that
of Triple Graph Grammar. An element is detected as
added to a source model if it is found in the source
model but not in the traceability model. An element
MODELSWARD 2016 - 4th International Conference on Model-Driven Engineering and Software Development
228
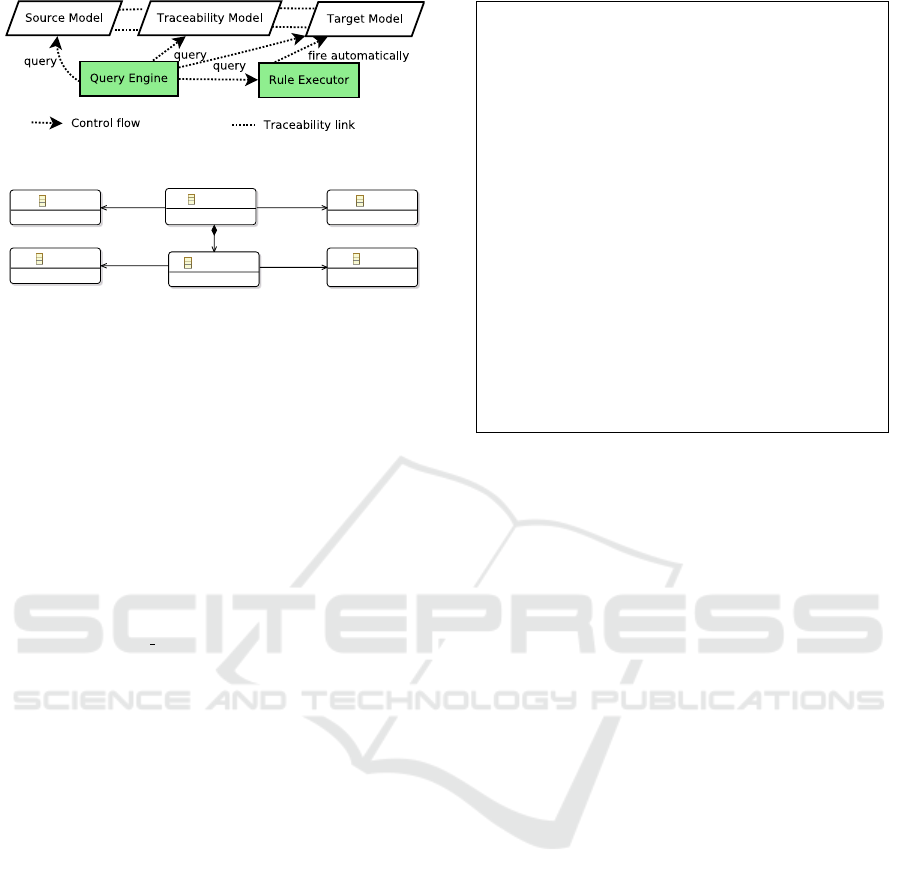
Figure 3: Target-dependent change detection.
TraceRoot
TraceElement
Model
Model
Element
Element
[0..*] modelTraces
[0..*] srcModel
[0..*] tgtModel
[0..*] tgtElements
[0..*] srcElements
Figure 4: Traceability metamodel.
is considered as removed from the source model if ei-
ther it is found in the traceability model but not in the
source model or there are target elements in the trace-
ability model but no corresponding source elements.
When the source model changes, the pattern matcher
of the query engine utilizes these links to collect all
required elements of the rule. The rules are hence
executed without referencing or checking any condi-
tions.
In the previous example, several query rules are
written as in Listing 2. ”neg” is a negative applica-
tion condition in graph pattern matching. neg find
traceElement(ele, tgt) queries the traceability model
to detect that the element ele is not mapped or trans-
formed to the target model yet. When the four ele-
ments from the example are added, only System is
detected as added since the list of required elements
of the rule is empty (System is the root element). Af-
ter the execution of copying System is finished, client
and server are detected as added since the container
System of these parts as the precondition of the copy-
ing rules corresponding to these elements is available
in the target model. These rules can be simultane-
ously executed. The finishing of copying the three
previous elements prompts the query engine to detect
the added connector. The Rule Executor fires then the
reifying rule to finish the propagation.
4.3 Discussion
The target-independent approach has the advantage of
simplicity and is useful for in-place transformations,
since the source model is (trivially) always up to date
and therefore required elements are always available.
Nevertheless, it implicitly wastes time in the impact
analysis within the Analyzer since many iterations of
verifying required elements for every rule are needed
before the activation of rules. These iterations even
increase the execution time if many change rules need
pa t t e r n tra ce E l e m e n t ( src , tgt ) {
Tr a ce R o o t . mo d e l Tr a c e s ( _root , tr ) ;
Tr a c e E l e m e n t . sr c E l e m en t s ( tr , src ) ;
Tr a c e E l e m e n t . tg t E l e m en t s ( tr , tgt ) ;
}
pa t t e r n un m a p p e d E l e m e n t ( ele ) {
Clas s ( el e me n t ) ;
neg f i n d tra c e E l e m e nt ( ele , _tgt ) ;
} or {
Clas s . o w n e d A t t r i b u t e ( clz , ele ) ;
find t ra ce E l e m e n t ( clz , _ t gt C lz ) ;
neg f i n d tra c e E l e m e nt ( ele , _tgt ) ;
} or {
Clas s . o w n e d C o n n e c t o r ( ele ) ;
find t ra ce E l e m e n t ( clz , _ t gt C lz ) ;
neg f i n d tra c e E l e m e nt ( ele , _tgt ) ;
Clas s . o w n e d A t t r i b u t e [0] ( clz , cli ) ;
Clas s . o w n e d A t t r i b u t e [1] ( clz , srv ) ;
find t ra ce E l e m e n t ( cli , _ ) ;
find t ra ce E l e m e n t ( srv , _ ) ;
}
Listing 2: EMF-IncQuery with the target-dependent
approach.
to be fired (see Section 6 for the execution time com-
parison).
To improve execution time of the target-
independent approach, the Analyzer can set a prior-
ity for each rule. A higher value would be assigned
to the priority of the copying rule than that of the
reifying rule. The engine can activate the rule with
the highest priority without multiple iterations and the
performance would be better. However, the priority
assigning approach is not feasible since the priority
settings of rules are manually written by transforma-
tion writers. Moreover, in the example above, System
and its attributes are transformed by three instances
of the same rule (the copying rule). If the Analyzer
chooses an instance associated with one of the at-
tributes to transform first, the execution of the rule
instance would not find System in the target model.
To resolve this, a dynamic priority scheduling that
checks all rules to execute is necessary. In fact, this
dynamic scheduling is similar to the above target-
independence approach that checks all required ele-
ments of a rule to be executed.
In the target-dependent approach, two indepen-
dent rules with required elements can be detected and
executed in parallel mode. The impact analysis and
firing of rules are effortless but the pattern match-
ing is more complicated. The matcher does not only
evaluate the source model (as the target-independent
approach does) but also the target and traceability
model.
By comparing the two approaches, there is a trade-
off between the change detection and impact analysis.
Change Rule Execution Scheduling in Incremental Roundtrip Engineering Chain: From Model-to-Code and Back
229
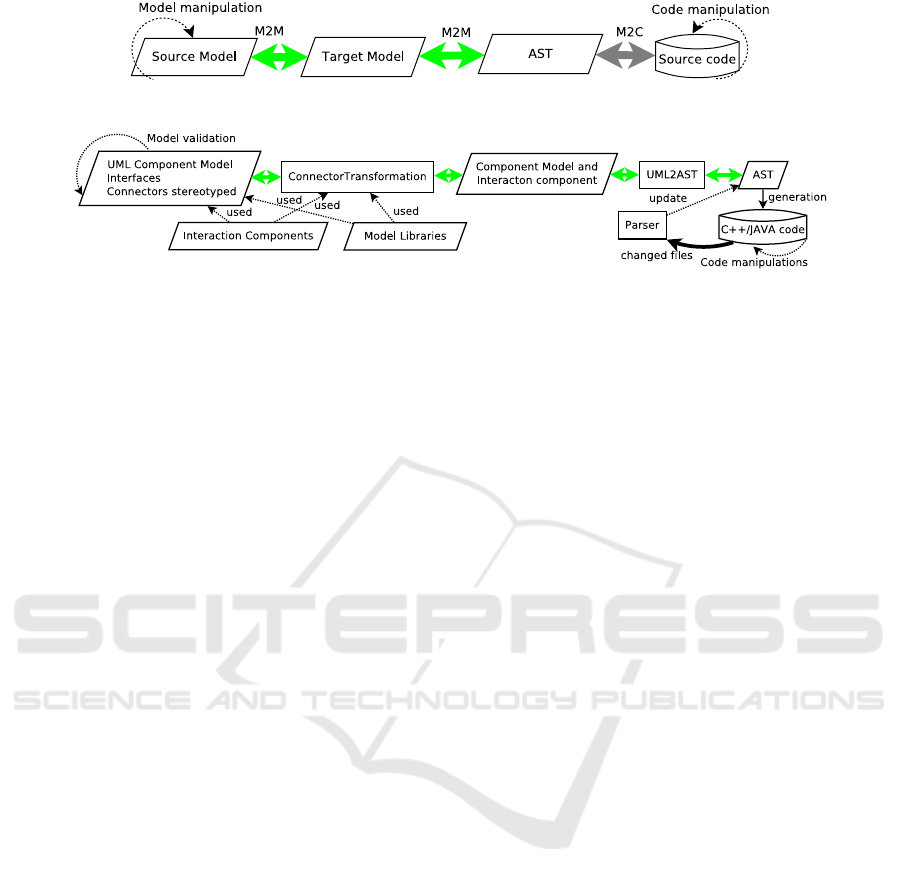
Figure 5: Incremental round-trip engineering chain with ASTs.
Figure 6: Model transformation chain in Qompass Designer.
If a smart pattern matching technique (such as EMF-
IncQuery in the Eclipse Modeling Framework) is sup-
ported by the development environment, the target-
dependent would be the choice. Contrarily, the target-
independent would be more suitable for tools with
poor graph techniques support. In the implementa-
tion, we compare the runtime execution performance
of both approaches.
5 TARGET MODELS AND CODE
SYNCHRONIZATION
This section presents a synchronization of code and
target models derived from the above transformations.
In order to reuse the transformation techniques dis-
cussed above, the models should be transformed into
an intermediate representation that reflects code. We
transform the models into an Abstract Syntax Tree
(AST). Code is generated from the AST by an unpars-
ing process. The synchronization from code to ASTs
is a parsing process supported by many development
environments. By this way, model synchronization
from target models to AST is needed (as shown in
Figure 5). Using an intermediate representation as
ASTs increases the modularity of the chain.
In the model evolution process, the incremental
transformation updates the corresponding AST nodes
from the changed model elements. The updated AST
nodes are used to deduce changed compilation units
that define a set of modeling elements used for mod-
eling source files. The code generator then uses tem-
plates, which define the generation of AST compila-
tion units to code, to re-generate the files associated
with the changed compilation units. In fact, the num-
ber of compilation units deduced from the updated
AST nodes might be high, as shown in the renam-
ing case below. In order to reduce it, we categorize
different cases in which a compilation unit should be
re-generated to its corresponding source file as fol-
lowings:
• If a model element is added, only its containing file
on the code level is generated; if one is updated,
two cases are distinguished: renaming and chang-
ing the element content.
• If an element is renamed, its corresponding com-
pilation unit and all other compilation units that
refer to (or use) it need to be re-generated since
references in code are name-based.
• If the content of an element has changed, only re-
generate its compilation unit; if one is deleted,
delete its compilation units and re-generate the
compilation units that refer to this element.
In fact, if a compilation unit refers to a deleted
element, it will require changes since re-generation
will not help resolve code errors (i.e., an attribute of
a class typed with a deleted class). Thus, developers
need to explicitly make changes to fix core errors ei-
ther on the model level (re-type the attribute or delete
the attribute) or the code level.
In the backward direction of the round-trip, when
a code file is changed by developer operations such
as adding or renaming classes, functions/methods or
attributes, the file is parsed into an AST by an update
of existing ASTs. By updating ASTs, the backward
incremental transformation automatically propagates
changes from code to the target models and eventu-
ally to the source models. We implemented both of
the IMT approaches as presented above to propagate
changes from code to models in the backward direc-
tion.
6 PROOF OF CONCEPT
As previously mentioned, Qompass Designer cur-
rently executes the connector transformation among
other transformations in a batch mode. Qompass De-
signer also supports the deployment and generation
MODELSWARD 2016 - 4th International Conference on Model-Driven Engineering and Software Development
230
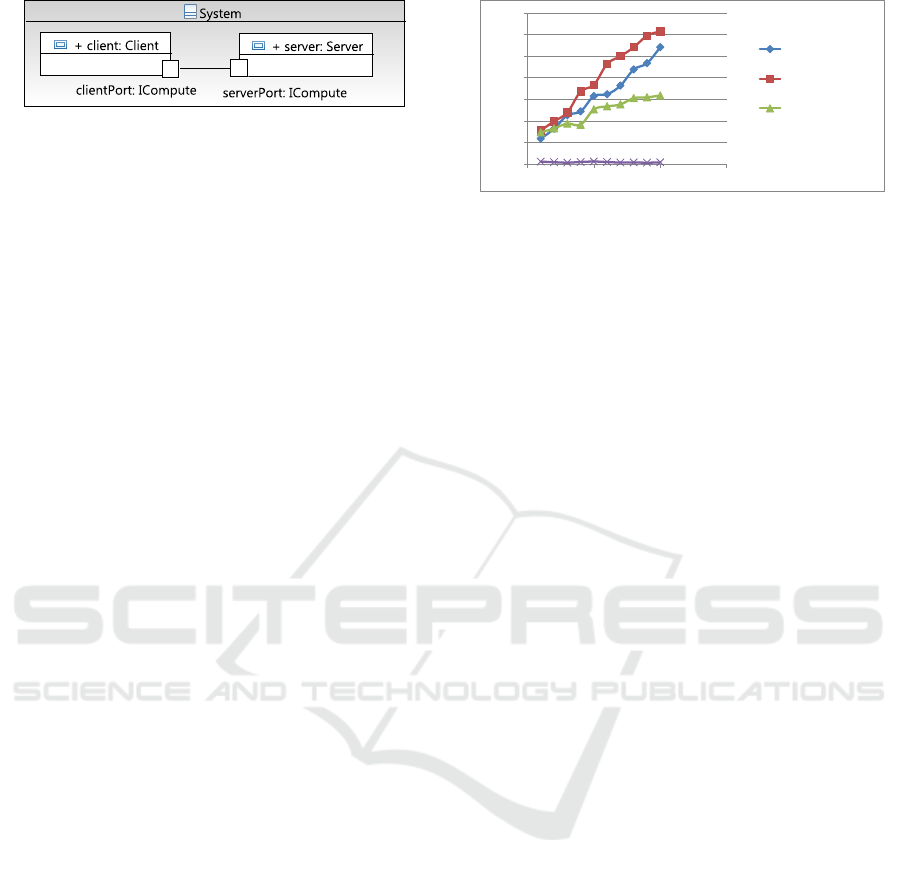
Figure 7: Application model for evaluation.
of C++ code for embedded distributed systems from
UML models. In order to do so, it needs the informa-
tion about which interaction components (IC) should
be used and this information is provided by a stereo-
type from the Flex-eware compoment model FCM
(Jan et al., 2012). To put our incremental approaches
in pratice, we implement a tool named IncRoundTrip
based on the existing batch transformation in Qom-
pass Designer. The tool transforms a source UML
model that contains FCM connectors to a target model
containing ICs. The target model is then transformed
into ASTs and eventually JAVA code. The implemen-
tation of an incremental C++ generator is in progress.
The incremental chain is shown in Figure 6. To de-
tect changes, we utilize the incremental graph pattern
matching language EMF-IncQuery.
A UML component model firstly consists of com-
ponents, interfaces, connectors and stereotypes ap-
plied to components used in the ConnectorTransfor-
mation phase. The component model can also im-
port other UML model libraries that contain different
data types or ICs (in model libraries as well). The se-
mantics of model libraries is similar to source code
libraries in traditional software development. There-
fore, ICs that are used in the transformation can be
defined in other model libraries independently from
the application model. The ConnectorTransformation
principally transforms UML connectors into ICs. The
transformation is not trivial since ICs are adapted to
the types used by a connection (types of connected
ports). The details of the ConnectorTransformation
are shown in (Radermacher et al., 2009) but are not in
the scope of this paper. After transformation, code is
generated from components to object-oriented code.
The synchronization of ASTs and code is independent
from model transformations.
In order to test the IMTs in practice, we imple-
mented a batch transformation and the incremental
approaches, executed them and compared the result-
ing models and code in all cases. The resulting mod-
els and code are the same. We also evaluated the per-
formance of these implementations. We executed the
chain on models with the number of nodes ranging
from 2 to 20 nodes and the number of connectors with
different interfaces from 1 to 10. A small application
model is shown in Figure 7. We transform ICs for
distributed applications that use socket connections
0
10000
20000
30000
40000
50000
60000
70000
0 5 10 15
Target-
dependence
Target-
independence
Batch
Number of connectors
ms
Figure 8: Performance comparison between the incremental
transformation approaches and batch transformation.
to communicate. The number of generated classes
ranges from 8 to 71. The performance comparison
of the two approaches and the batch transformation is
shown in Figure 8. As noted in the above sections, the
target-dependent approach runs faster than the target-
independent one. Moreover, the batch transformation
outperforms the two others for the first time since the
batch does not need to detect and analyze the impact
of changes on the target model. The communication
between components is established by the connector
that connects through ports typing interfaces. After
the first transformation, we add 5 UML classes (each
one has 5 operations and 5 attributes), the transforma-
tion time in the target-dependent approach dramati-
cally decreases as the Incremental line in Figure 8.
The time for processing (transforming to the target
model and eventually code) these 5 classes is 1s.
7 CONCLUSION
In the paper, we discussed two approaches of change
rules scheduling in incremental model transforma-
tions. One approach iterates to check the availability
of required elements of rules and the other one uses
triggers and query languages. In the later, a change
is only detected if its required elements are available.
We applied the approaches to a specific round-trip en-
gineering model transformation and code generation
tool named IncRoundtrip in model- and component-
based development. In the implementation, we detect
changes by the incrementality of the EMF-IncQuery
query language. We compared the runtime execu-
tion performance of both approaches and the batch
transformation. The target-dependent approach out-
performs the other one.
Models and code are synchronized in both direc-
tions. We used ASTs as intermediate models to reuse
model transformation techniques. We synchronized
the models and ASTs. The synchronization of ASTs
and code are executed by the help of parsers.
Change Rule Execution Scheduling in Incremental Roundtrip Engineering Chain: From Model-to-Code and Back
231

For the moment, the model synchronization is
done by two uni-directional transformations that are
difficult to maintain and the synchronization from
code to models is not fully implemented. For fu-
ture works, we will apply the scheduling algorithms to
the definition of a transformation language. Queries
written in this language are then generated to EMF-
IncQuery and Xtend code to provide fully automati-
cally runtime incremental model synchronization. We
will also complete the round-trip chain for C++ and
JAVA.
ACKNOWLEDGEMENTS
The work presented in this paper is supported by
the European project SafeAdapt, grant agreement No.
608945, see http://www.SafeAdapt.eu. The project
deals with adaptive system with additional safety and
real time constraints. The adaptation and safety as-
pects are stored in different models in order to achieve
a separation of concerns. These models need to be
synchronized.
REFERENCES
AndroMDA (2015). http://www.andromda.org/ [Online;
accessed 01-Sept-2015].
Bergmann, G., Rth, I., Szab, T., Torrini, P., and Varr, D.
(2012). Incremental pattern matching for the efficient
computation of transitive closure. Lecture Notes in
Computer Science, 7562 LNCS:386400.
Bergmann, G., Rth, I., Varr, G., and Varr, D. (2011).
Change-driven model transformations, volume 11.
Fan, W., Wang, X., and Wu, Y. (2013). Incremental graph
pattern matching, volume 38.
Giese, H. and Wagner, R. (2006). Incremental Model
Synchronization with Triple Graph Grammars, page
543557.
Hermann, F., Ehrig, H., Orejas, F., Czarnecki, K., Diskin,
Z., Xiong, Y., Gottmann, S., and Engel, T. (2013).
Model synchronization based on triple graph gram-
mars: correctness, completeness and invertibility.
Software and Systems Modeling, page 129.
Jan, M., Jouvray, C., Kordon, F., Kung, A., Lalande, J.,
Loiret, F., Navas, J., Pautet, L., Pulou, J., Raderma-
cher, A., and Seinturier, L. (2012). Flex-eWare: A
flexible model driven solution for designing and im-
plementing embedded distributed systems. Software -
Practice and Experience, 42:1467–1494.
Kindler, E. and Wagner, R. (2007). Triple graph grammars:
Concepts, extensions, implementations, and applica-
tion scenarios. Techn. Ber. tr-ri-07-284, University of.
Kusel, A., Etzlstorfer, J., and Kapsammer, E. (2013). A sur-
vey on incremental model transformation approaches.
ME 2013 Models and Evolution Workshop, at MOD-
ELS’13.
Lauder, M., Anjorin, A., Varr, G., and Sch, A. (2012). Ef-
ficient model synchronization with precedence triple
graph grammars.
Mussbacher, G., Amyot, D., Breu, R., Bruel, J.-m., Cheng,
B. H. C., Collet, P., Combemale, B., France, R. B.,
Heldal, R., Hill, J., Kienzle, J., and Sch
¨
ottle, M.
(2014). The Relevance of Model-Driven Engineering
Thirty Years from Now. ACM/IEEE 17th MODELS,
pages 183–200.
Nagowah, L., Goolfee, Z., and Bergue, C. (2013). RTET -
A round trip engineering tool. In ICoICT 2013, pages
381–387.
OMG (2008). Meta Object Facility (MOF) 2.0 Query / View
/ Transformation Specification.
Qompass (2015). https://wiki.eclipse.org/Papyrus Qompass.
[Online; accessed 01-Sept-2015].
Radermacher, A., Cuccuru, A., Gerard, S., and Ter-
rier, F. (2009). Generating execution infrastructures
for component-oriented specifications with a model
driven toolchain: A case study for marte’s gcm and
real-time annotations. SIGPLAN Not., 45(2):127–136.
Tigris (2015). Tigris. http://argouml.tigris.org/. [Online;
accessed 01-Sept-2015].
Tonella, P. (2005). Reverse engineering of object oriented
code. Proceedings. 27th International Conference on
Software Engineering, 2005. ICSE 2005.
Ujhelyi, Z., Bergmann, G., Heged
¨
us, A., Horv
´
ath, A., Izs
´
o,
B., R
´
ath, I., Szatm
´
ari, Z., and Varr
´
o, D. (2015). EMF-
IncQuery: An integrated development environment
for live model queries. Science of Computer Program-
ming, 98(2015):80–99.
Xin, W. and Xiaojie, Y. (2007). Towards an AST-based ap-
proach to reverse engineering. In Canadian Confer-
ence on Electrical and Computer Engineering, pages
422–425.
MODELSWARD 2016 - 4th International Conference on Model-Driven Engineering and Software Development
232
