
Managing Distributed Queries under Personalized Anonymity
Constraints
Axel Michel
1,2
, Benjamin Nguyen
1,2
and Philippe Pucheral
2
1
SDS Team at LIFO, INSA-CVL, Boulevard Lahitolle, Bourges, France
2
Petrus team, Inria Saclay & UVSQ, Versailles, France
Keywords:
Data Privacy and Security, Big Data, Distributed Query Processing, Secure Hardware.
Abstract:
The benefit of performing Big data computations over individual’s microdata is manifold, in the medical,
energy or transportation fields to cite only a few, and this interest is growing with the emergence of smart
disclosure initiatives around the world. However, these computations often expose microdata to privacy leak-
ages, explaining the reluctance of individuals to participate in studies despite the privacy guarantees promised
by statistical institutes. This paper proposes a novel approach to push personalized privacy guarantees in the
processing of database queries so that individuals can disclose different amounts of information (i.e. data at dif-
ferent levels of accuracy) depending on their own perception of the risk. Moreover, we propose a decentralized
computing infrastructure based on secure hardware enforcing these personalized privacy guarantees all along
the query execution process. A performance analysis conducted on a real platform shows the effectiveness of
the approach.
1 INTRODUCTION
In many scientific fields, ranging from medicine to so-
ciology, computing statistics on (often personal) pri-
vate and sensitive information is central to the disci-
pline’s methodology. With the advent of the Web, and
the massive databases that compose it, statistics and
machine learning have become “data science”: their
goal is to turn large volumes of information linked
to a specific individual, called microdata, into knowl-
edge. Big Data computation over microdata is of ob-
vious use to the community: medical data is used to
improve the knowledge of diseases, and find cures:
energy consumption is monitored in smart grids to op-
timize energy production and resources management.
In these applications, real knowledge emerges from
the analysis of aggregated microdata, not from the mi-
crodata itself
1
.
Smart disclosure initiatives, pushed by legislators
(e.g. EU General Data Protection Regulation (Eu-
ropean Union, 2016)) and industry-led consortiums
(e.g. blue button and green button in the US
2
, Midata
3
1
We thus do not consider applications such as targeted ad-
vertising, who seek to characterize the users at individual
level.
2
https://www.healthit.gov/patients-families/your-health-da
ta; https://www.healthit.gov/patients-families/
3
https://www.gov.uk/government/news/the-midata-vision-
in the UK, MesInfos
4
in France), hold the promise of
a deluge of microdata of great interest for analysts. In-
deed, smart disclosure enables individuals to retrieve
their personal data from companies or administrations
that collected them. Current regulations carefully re-
strict the uses of this data to protect individual’s pri-
vacy. However, once the data is anonymized, its pro-
cessing is far less restricted. This is good news, since
in most cases, these operations (i.e. global database
queries) can provide results of tunable quality when
run on anonymized data.
Unfortunately, the way microdata is anonymized
and processed today is far from being satisfactory.
Let us consider how a national statistical study is
managed, e.g. computing the average salary per ge-
ographic region. Such a study is usually divided into
3 phases: (1) the statistical institute (assumed to be
a trusted third party) broadcasts a query to collect
raw microdata along with anonymity guarantees (i.e.,
a privacy parameter like k in the k−anonymity or ε
in the differential privacy sanitization models) to all
users ; (2) each user consenting to participate trans-
mits her microdata to the institute ; (3) the institute
computes the aggregate query, while respecting the
of-consumer-empowermenthttps://www.gov.uk/governme
nt/news/
4
http://mesinfos.fing.org/http://mesinfos.fing.org/
Michel, A., Nguyen, B. and Pucheral, P.
Managing Distributed Queries under Personalized Anonymity Constraints.
DOI: 10.5220/0006477001070117
In Proceedings of the 6th International Conference on Data Science, Technology and Applications (DATA 2017), pages 107-117
ISBN: 978-989-758-255-4
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
107

announced anonymity constraint.
This approach has two important drawbacks:
1. The anonymity guarantee is defined by the querier
(i.e. the statistical institute), and applies uniformly
to all participants. If the querier decides to pro-
vide little privacy protection (e.g. a small k in the
k−anonymity model), it is likely that many users
will not want to participate in the query. On the
contrary, if the querier decides to provide a high
level of privacy protection, many users will be
willing to participate, but the quality of the results
will drop. Indeed, higher privacy protection is al-
ways obtained to the detriment of the quality and
then utility of the sanitized data.
2. The querier is assumed to be trusted. Although
this could be a realistic assumption in the case
of a national statistics institute, this means it is
impossible to outsource the computation of the
query. Moreover, microdata centralization exacer-
bates the risk of privacy leakage due to piracy (Ya-
hoo and Apple recent hack attacks are emblematic
of the weakness of cyber defenses
5
), scrutiniza-
tion and opaque business practices. This erodes
individuals trust in central servers, thereby reduc-
ing the proportion of citizen consenting to partic-
ipate in such studies, some of them unfortunately
of great societal interest.
The objective of this paper is to tackle these
two issues by reestablishing user’s empowerment,
a principle called by all recent legislations protect-
ing the management of personal data (European
Union, 2016). Roughly speaking, user’s empower-
ment means that the individual must keep the con-
trol of her data and of its disclosure in any situation.
More precisely, this paper makes the following con-
tributions:
• proposing a query paradigm incorporating person-
alized privacy guarantees, so that each user can
trade her participation in the query for a privacy
protection matching her personal perception of
the risk,
• providing a secure decentralized computing
framework guaranteeing that the individual keeps
her data in her hands and that the query issuer
never gets cleartext raw microdata and sees only
a sanitized aggregated query result matching all
personalized privacy guarantees,
• conducting a performance evaluation on a real
5
Yahoo ’state’ hackers stole data from 500 million
users - BBC News. www.bbc.co.uk/news/world-us-
canada-37447016www.bbc.co.uk/news/world-us-canada-
37447016
dataset demonstrating the effectiveness and scal-
ability of the approach.
The rest of the paper is organized as follows. Sec-
tion 2 presents related works and background ma-
terials allowing the precisely state the problem ad-
dressed. Section 3 details the core of our contribu-
tion. Section 4 shows that the overhead incurred by
our algorithm, compared to a traditional query pro-
cessing technique, remains largely tractable. Finally,
Section 5 concludes.
2 STATE OF THE ART AND
PROBLEM STATEMENT
2.1 Related Works on
Privacy-preserving Data Publishing
Anonymization has been a hot topic in data publi-
cation since the 1960’s for all statistical institutions
wanting to publish aggregate data. The objective of
most of these data publishing techniques is to provide
security against an attacker who is going to mount
deanonymization attacks, which will link some sen-
sitive information (such as their salary or medical di-
agnosis) to a specific individual. Particular attention
was drawn to the problem by Sweeney, the introduc-
tion of the k-anonymity model (Sweeney, 2002) that
we consider in this paper. k-anonymity is a partition
based approach to anonymization, meaning that the
original dataset, composed of individual’s microdata,
is partitionned, through generalization or suppression
of values, into groups who have similar values which
will then be used for grouping.
The partition-based approach splits the attributes
of the dataset in two categories: a quasi-identifier and
some sensitive data. A quasi-identifier (denoted QID)
is a set of attributes for which some records may ex-
hibit a combination of unique values in the dataset,
and consequently be identifying for the correspond-
ing individuals (e.g., ZipCode, BirthDate, Gender).
The sensitive part (denoted SD) encompasses the at-
tribute(s) whose association with individuals must be
made ambiguous (e.g., Disease).
Partition-based approaches essentially apply a
controlled degradation to the association between in-
dividuals (represented in the dataset by their quasi-
identifier(s)) and their sensitive attribute(s). The ini-
tial dataset is deterministically partitioned into groups
of records (classes), where quasi-identifier and sen-
sitive values satisfy a chosen partition-based privacy
model. The original k-Anonymity model (Sweeney,
DATA 2017 - 6th International Conference on Data Science, Technology and Applications
108
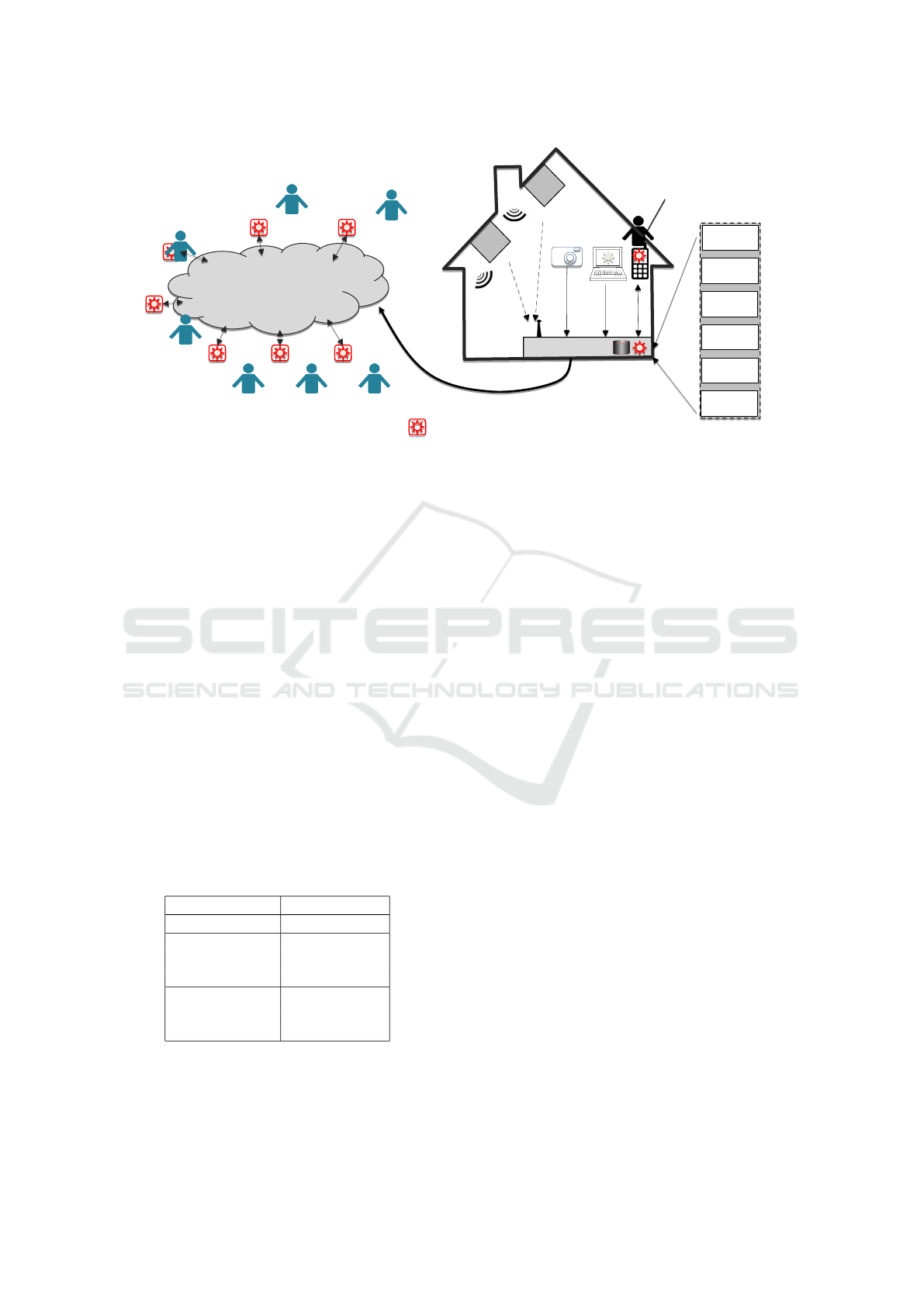
Power
provider
Super-
market
Car insurer
A
P
h
o
t
o
s
M
y
F
i
l
e
s
S
y
n
c
.
Fixed Trusted Cell
Heat
sensor
Power
meter
F E
D
H
G
I
Employer
Hospital
School
C
SSI
Trusted Data Server
MobileTrusted Cell
Figure 1: Trusted Cells reference architecture.
2002) requires each class to contain at least k in-
distinguishable records, thus each sensitive data will
be associated with at least k records. Many other
models have been introduced since 2006, such as
`-Diversity (Machanavajjhala et al., 2006) or t-
Closeness (Li et al., 2010). Each model further con-
strain the distribution of sensitive data within each
class, tackling different adversarial assumptions. For
example, the `-Diversity principle requires that the set
of sensitive data associated to each equivalence class
be linked to ` different sensitive values. t-closeness
requires each class to have a similar distribution of
sensitive values. To illustrate this, table 1 shows
a 3-anonymous and 2-diverse version of a dataset.
This means, for each tuple, at least two others have
the same quasi-identifier (i.e. 3-anonymity) and for
each group of tuples with the same quasi-identifier,
there are at least two distinct sensitive values (i.e. 2-
diversity). It is important to note that the higher the k
and `, the better the privacy protection, but the lower
the precision (or quality) of the query.
Table 1: 3−anonymous and 2−diverse table.
Quasi-identifier Sensitive
ZIP Age Condition
112** > 25 Cancer
112** > 25 Cancer
112** > 25 Heart Disease
1125* * Heart Disease
1125* * Viral Infection
1125* * Cancer
A different concept is differential privacy, intro-
duced by Dwork in (Dwork, 2006). Differential pri-
vacy is more adapted to interactive query answering.
It’s advantage is to provide formal guarantees regard-
less of the knowledge of the adversary. However, dif-
ferential privacy limits the type of computation which
can be made on the data. Moreover, fixing the privacy
parameter ε is a cumbersome and not intuitive task,
out of reach of lambda individuals.
Another approach is to make an agreement be-
tween the user and the querier. Te concept of sticky
policies presented by Trablesi, Neven, Ragget et
al. (Trabelsi et al., 2011) consists to make a policy
about authorization (i.e. what the querier can do) and
obligation(i.e. what he querier must do) which will
stick to the user data.
2.2 Reference Computing Architecture
Concurrently with smart disclosure initiatives, the
Personal Information Management System (PIMS)
paradigm has been conceptualized (Abiteboul et al.,
2015), and emerges in the commercial sphere (e.g.
Cozy Cloud, OwnCloud, SeaFile). PIMS holds the
promise of a Privacy-by-Design storage and comput-
ing platform where each individual can gather her
complete digital environment in one place and share
it with applications and other users under her con-
trol. The Trusted Cells architecture presented in (An-
ciaux et al., 2013), and pictured in Figure 1, precisely
answers the PIMS requirements by preventing data
leaks during computations on personal data. Hence,
we consider Trusted Cells as a reference computing
architecture in this paper.
Trusted Cells is a decentralized architecture by
nature managing computations on microdata through
the collaboration of two parties. The first party is
a (potentially large) set of personal Trusted Data
Servers (TDSs) allowing each individual to manage
her data with tangible elements of trust. Indeed, TDSs
Managing Distributed Queries under Personalized Anonymity Constraints
109

incorporate tamper resistant hardware (e.g. smartcard,
secure chip, secure USB token) securing the data and
code against attackers and users’ misusages. Despite
the diversity of existing tamper-resistant devices, a
TDS can be abstracted by (1) a Trusted Execution En-
vironment and (2) a (potentially untrusted but cryp-
tographically protected) mass storage area where the
personal data resides. The important assumption is
that the TDS code is executed by the secure device
hosting it and then cannot be tampered, even by the
TDS holder herself.
By construction, secure hardware exhibit limited
storage and computing resources and TDSs inherit
these restrictions. Moreover, they are not necessarily
always connected since their owners can disconnect
them at will. A second party, called hereafter Sup-
porting Server Infrastructure (SSI), is thus required
to manage the communications between TDSs, run
the distributed query protocol and store the interme-
diate results produced by this protocol. Because SSI
is implemented on regular server(s), e.g. in the Cloud,
it exhibits the same low level of trustworthiness.
The resulting computing architecture is said asym-
metric in the sense that it is composed of a very large
number of low power, weakly connected but highly
secure TDSs and of a powerful, highly available but
untrusted SSI.
2.3 Reference Query Processing
Protocol
By avoiding delegating the storage of personal data
to untrusted cloud providers, Trusted Cells is key to
achieve user empowerment. Each individual keeps
her data in her hands and can control its disclo-
sure. However, the decentralized nature of the Trusted
Cells architecture must not hinder global computa-
tions and queries, impeding the development of ser-
vices of great interest for the community. SQL/AA
(SQL Asymmetric Architecture) is a protocol to exe-
cute standard SQL queries on the Trusted Cells archi-
tecture (To et al., 2014; To et al., 2016). It has been
precisely designed to tackle this issue, that is execut-
ing global queries on a set of TDSs without recentral-
izing microdata and without leaking any information.
The protocol, illustrated by the Figure 2, works as
follows. Once an SQL query is issued by a querier
(e.g. a statistic institute), it is computed in three
phases: first the collection phase where the querier
broadcasts the query to all TDSs, TDSs decide to par-
ticipate or not in the computation (they send dummy
tuples in that case to hide their denial of participa-
tion), evaluate the WHERE clause and each TDS returns
its own encrypted data to the SSI. Second, the aggre-
gation phase, where SSI forms partitions of encrypted
tuples, sends them back to TDSs and each TDS par-
ticipating to this phase decrypts the input partition,
removes dummy tuples and computes the aggregation
function (e.g. AVG, COUNT). Finally the filtering phase,
where TDSs produce the final result by filtering out
the HAVING clause and send the result to the querier.
Note that the TDSs participating to each phase can be
different. Indeed, TDSs contributing to the collection
phase act as data producers while TDSs participating
to the aggregation and filtering phases act as trusted
computing nodes. The tamper resistance of TDSs is
the key in this protocol since a given TDS belonging
to individual i
1
is likely to decrypt and aggregate tu-
ples issued by TDSs of other individuals i
2
, . .., i
n
.
Finally, note that the aggregation phase is recursive
and runs until all tuples belonging to a same group
have been actually aggregated. We refer the interested
reader to (To et al., 2014; To et al., 2016) for a more
detailed presentation of the SQL/AA protocol.
2.4 Problem Statement
In order to protect the privacy of users, queries must
respect a certain degree of anonymity. Our primary
objective is to push personalized privacy guarantees
in the processing of regular statistical queries so that
individuals can disclose different amount of informa-
tion (i.e., data at different level of accuracy) depend-
ing on their own perception of the risk. To the best of
our knowledge, no existing work has addressed this
issue. For the sake of simplicity, we consider SQL as
the reference language to express statistical/aggregate
queries because of its widespread usage. Similarly,
we consider personalized privacy guarantees derived
from the k-anonymity and `-diversity models because
(1) they are the most used in practice, (2) they are rec-
ommended by the European Union (European Union,
2014) and (3) they can be easily understood by in-
dividuals
6
. The next step in our research agenda is
to extend our approach to other query languages and
privacy guarantees but this ambitious goal exceeds the
scope and expectation of this paper
Hence, the problem addressed in this paper is to
propose a (SQL) query paradigm incorporating per-
sonalized (k-anonymity and `-diversity) privacy guar-
antees and enforcing these individual guarantees all
along the query processing without any possible leak-
age.
6
The EU Article 29 Working Group mention these char-
acteristics as strong incentives to make these models ef-
fectively used in practice or tested by several european
countries (e.g., the Netherlands and French statistical in-
stitutes).
DATA 2017 - 6th International Conference on Data Science, Technology and Applications
110
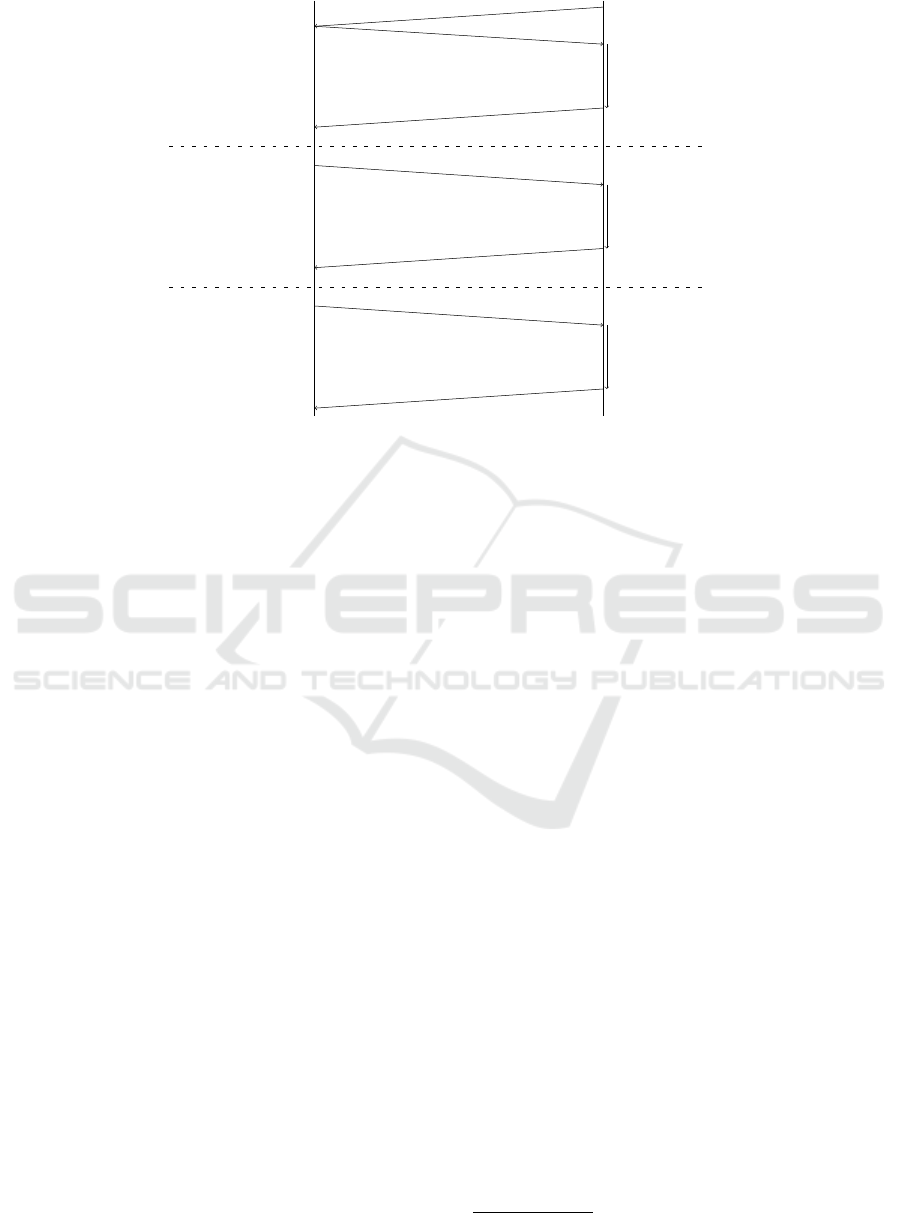
SSI TDSs
connect
send Q
decrypt Q
check AC
compute WHERE
encrypt tuple t
`.append(t)
send t
P
i
= `.partition(i)
send P
i
decrypt P
i
remove dummies
compute aggregations
encrypt partition P
agg
i
`
0
.append(P
agg
i
)
send P
agg
i
P
j
= `
0
.partition(j)
send P
j
decrypt P
j
remove dummies
compute HAVING
finalize result res
i
result.append(res
i
)
send res
i
Collection phaseAggregation phaseFiltering phase
Figure 2: SQL/AA Protocol.
3 PERSONALIZED ANONYMITY
GUARANTEES IN SQL
3.1 Modeling Anonymisation using SQL
We make the assumption that each individual owns
a local database hosted in her personal TDS and that
these local databases conform to a common schema
which can be easily queried in SQL. For exam-
ple, power meter data (resp., GPS traces, healthcare
records, etc) can be stored in one (or several) table(s)
whose schema is defined by the national distribution
company (resp., an insurance company consortium,
the Ministry of Health, etc). Based on this assump-
tion, the querier (i.e., the statistical institute) can issue
regular SQL queries as shown by the Figure 3.
SELECT <Aggregate function(s)>
FROM <Table(s)>
WHERE <condition(s)>
GROUP BY <grouping attribute(s)>
HAVING <grouping condition(s)>
Figure 3: Regular SQL query form.
For the sake of simplicity, we do not consider
joins between data stored in different TDSs but inter-
nal joins which can be executed locally by each TDS
are supported. We refer to (To et al., 2014; To et al.,
2016) for a deeper discussion on this aspect which is
not central to our work in this paper.
Anonymity Guarantees: are defined by the
querier, and correspond to the k and ` values that will
be achieved by the end of the process, for each group
produced. They correspond to the commitment of
the querier towards any query participant. Different
k and ` values can be associated to different granular-
ity of grouping. In the example pictured in Figure 4,
the querier commits to provide k ≥ 5 and ` ≥ 3 at a
(City,Street) grouping granularity and k ≥ 10 and
` ≥ 3 at a (City) grouping granularity.
Anonymity Constraints: are defined by the
users, and correspond to the values they are willing
to accept in order to participate in the query. Back to
the example of Figure 4, Alice’s privacy policy stip-
ulates a minimal anonymization of k ≥ 5 and ` ≥ 3
when attribute Salary is queried.
According to the anonymity guarantees and con-
straints, the query computing protocol is as follows.
The querier broadcasts to all potential participants the
query to be computed along with metadata encod-
ing the associated anonymity guarantees. The TDS
of each participant compares this guarantees with the
individual’s anonymity constraints. This principle
shares some similarities with P3P
7
with the match-
ing between anonymity guarantees and constraints se-
curely performed by the TDS. If the guarantees ex-
ceed the individual’s constraints, the TDS participates
to the query by providing real data at the finest group-
ing granularity. Otherwise, if the TDS finds a group-
ing granularity with anonymity guarantees matching
her constraints, it will participate, but by providing a
degraded version of the data, to that coarser level of
granularity (looking at Figure 4, answering the group
7
https://www.w3.org/P3P/https://www.w3.org/P3P/
Managing Distributed Queries under Personalized Anonymity Constraints
111

Querier
1
Q
1
=
SELECT city, street
AVG(salary)
GROUP BY city, street
Q
1
.metadata
group by city, street:
anonymity: 5
diversity: 3
group by city:
anonymity: 10
diversity: 3
TDS Alice
policies:
aggregation on salary :
anonymity: 5
diversity: 2
TDS Bob
policies:
aggregation on salary :
anonymity: 6
diversity: 3
TDS Charlie
policies:
aggregation on salary :
anonymity: 5
diversity: 4
SSI
queries list:
Q
1
, . . .
connect
connect
connect
Q
1
Q
1
Q
1
(salary
Alice
,
city
Alice
,
street
Alice
)
D_FLAG=0
(salary
Bob
,
city
Bob
)
D_FLAG=0
(dummy_salary,
dummy_city,
dummy_street)
D_FLAG=1
Q
1
Figure 4: Example of collection phase with anonymity constraints.
by city, street clause is not acceptable for Bob,
but answering just with city is). Finally, if no match
can be found, the TDS produces fake data (called
dummy tuples in the protocol) to hide its denial of par-
ticipation. Fake data is required to avoid the querier
from inferring information about the individual’s pri-
vacy policy or about her membership to the WHERE
clause of the query.
Figure 4 illustrates this behavior. By comparing
the querier anonymity guarantees with their respec-
tive constraints, the TDSs of Alice, Bob and Charlie
respectively participate with fine granularity values
(Alice), with coarse granularity values (Bob), with
dummy tuples (Charlie).
The working group ODRL
8
is looking at some
issues similar to the expression of privacy policies.
However, this paper is not discussing about how users
can express their privacy policy in a standard way.
3.2 The
k
i
SQL/AA Protocol
We now describe our new protocol, that we call
k
i
SQL/AA to show that it takes into account many
different k values of the i different individuals.
k
i
SQL/AA is an extension of the SQL/AA proto-
col (To et al., 2014; To et al., 2016) where the enforce-
ment of the anonymity guarantees have been pushed
in the collection, aggregation and filtering phases.
Collection Phase: After TDSs download the
query, they compare the anonymity guarantees an-
nounced by the querier with their own anonymity
8
https://www.w3.org/community/odrl/https://www.w3.org/
community/odrl/
constraints. As discussed above (see Section 3.1)
TDSs send real data at the finest grouping granularity
compliant with their anonymity constraints or send a
dummy tuple if no anonymity constraint can be satis-
fied.
Aggregation Phase: To ensure that the
anonymization guarantees can be verified at
the filtering phase, clauses COUNT(*) and
COUNT(DISTINCT A) are computed in addition
to the aggregation asked by the querier. COUNT(*)
will be used to check that the k−anonymity guarantee
is met while COUNT(DISTINCT A) will be used
to check the `−diversity guarantee on attribute (or
group of attributes) A on which the aggregate function
applies (e.g. salary in our example)
9
. If tuples with
varying grouping granularity enter this phase, they
are aggregated separately, i.e. one group per grouping
granularity.
Filtering Phase: Besides HAVING predicates
which can be formulated by the querier, the HAVING
clause is used to check the anonymity guaran-
tees. Typically, k−anonymity sums up to check
COUNT(*)≥ k while `−diversity is checked by
COUNT(DISTINCT A)≥ `. If these guarantees are not
met for some tuples, they are not immediately dis-
carded. Instead, the protocol tries to merge them with
a group of coarser granularity encompassing them.
Let us consider the example of Table 2(a). The tuple
(Bourges, Bv.Lahitolle, 1600) is merged with
the tuple (Bourges, ******, 1400) to form the tu-
9
Since this clause is an holistic function, we can compute
it while the aggregation phase by adding naively each dis-
tinct value under a list or using a cardinality estimation
algorithm such as HyperLogLog (Flajolet et al., 2007).
DATA 2017 - 6th International Conference on Data Science, Technology and Applications
112

Table 2: Filtering phase.
(a) Example of a post aggregation phase result
city street AVG(salary) COUNT(*)
COUNT
(DISTINCT salary)
Le Chesnay Dom. Voluceau 1500 6 4
Le Chesnay ****** 1700 9 6
Bourges Bv. Lahitolle 1600 3 3
Bourges ****** 1400 11 7
(b) Privacy guarantees of
the query
Attributes k `
city, street 5 3
city 10 3
(c) Data sent to the querier
city street AVG(salary)
Le Chesnay Dom. Voluceau 1500
Bourges ****** 1442.86
ple (Bourges, ******, 1442.86). Merges stop
when all guarantees are met. If, despite merges, the
guarantees cannot be met, the corresponding tuples
are removed form the result. Hence, the querier will
receive every piece of data which satisfies the guar-
anties, and only these ones, as shown on Table 2(c).
How to Generalize: To reach the same k and `
values on the groups, the grouping attributes can be
generalized in different orders, impacting the qual-
ity of the result for the querier. For instance, if the
GroupBy clause involves two attributes Address and
Age, would it be better to generalize the tuples on
Address (e.g. replacing <City,Street> by <City>)
or on Age (replacing exact values by intervals) ? It
would be valuable for the querier to give “hints” to
the TDSs on how to generalize the data, by indi-
cating which attributes to generalize, and what pri-
vacy guarantees will be enforced after each gener-
alization. In the following example, we consider
the UCI Adult dataset (Lichman, 2013), we define
a GroupBy query GB on attributes Age, Workclass,
Education, Marital_status, Occupation, Race,
Gender, Native_Country and we compute the av-
erage fnlwgt operation OP=AVG(fnlwgt). MD repre-
sents the metadata attached to the query. Each meta-
data indicates which k and ` can be guaranteed after a
given generalization operation. Depending on the at-
tribute type, generalizing an attribute may correspond
to climbing up in a generalization hierarchy (for cat-
egorical attributes such as Workclass or Race) or re-
placing a value by an interval of greater width (for
numeric values such as Age or Education). The
del operation means that the attribute is simply re-
moved. The ordering of the metadata in MD translates
the querier requirements.
GB= Age, Workclass, Education, Marital_status,
Ocupation, Race, Gender, Native_Country;
OP= AVG(fnlwgt);
MD= : k=5 l=3,
age->20: k=6 l=3,
workclass->up: k=8 l=4,
education->5: k=9 l=4,
marital_status->up: k=9 l=4,
occupation->up: k=10 l=4,
race->up: k=11 l=5,
gender->del: k=14 l=6,
native country->del:k=15 l=7,
age->40: k=17 l=8;
Figure 5:
k
i
SQL/AA query example.
4 EXPERIMENTAL EVALUATION
We have implemented the
k
i
SQL/AA protocol on
equivalent open-source hardware used in (To et al.,
2014; To et al., 2016). The goal of this experimental
section is to show that there is very little overhead
when taking into account personalized anonymity
constraints compared to the performance measured by
the original implementation of To et al.. Our imple-
mentation is tested using the classical adult dataset of
UCI-ML (Lichman, 2013)
4.1 Implementation of
k
i
SQL/AA
Protocol
The implementation of
k
i
SQL/AA builds upon the
secure aggregation protocol of SQL/AA (To et al.,
2014; To et al., 2016), recalled in Section 2.3. The
secure aggregation is based on non-deterministic en-
cryption as AES-CBC to encrypt tuples. Each TDS
encrypts its data with the same secret key but with a
different initialization vector such that two tuples with
the same value have two different encrypted values.
The protection ensures the SSI cannot infer personal
informations by the distribution of same encrypted
Managing Distributed Queries under Personalized Anonymity Constraints
113

values. To make sure that aggregations are entirely
computed, the SSI uses a divide and conquer parti-
tioning to make the TDS compute partial aggregations
on partitions of data. Then the SSI merges partial ag-
gregations to compute the last aggregation. The ag-
gregation phase is illustrated by the Figure 6.
Final Aggregation
Agg(P
1,2
)
Agg(P
1
)
Agg(P
2
)
Agg(P
3,4
)
Agg(P
3
)
Agg(P
4
)
Figure 6: Aggregation phase with four partitions.
In
k
i
SQL/AA, the aggregation phase has been kept
unchanged from the SQL/AA system since our con-
tribution is on the collection phase and the filtering
phase. The algorithm implementing the collection
phase of
k
i
SQL/AA is given below (see Algorithm 1).
As in most works related to data anonymization, we
make the simplifying assumption that each individual
is represented by a single tuple. Hence, the algorithm
always return a single tuple. This tuple is a dummy if
the privacy constraints or the WHERE clause cannot be
satisfied.
Algorithm 1: Collection Phase.
procedure COLLECTION_PHASE(Query Q)
t ← getTuple(Q)
p ← getConstraints(Q)
g ← getGuarantees(Q)
i ← 0
if veri f yW here(t, Q) then
while g
i
< p do
if not canGeneralize(t) then
t ← makeDummy(Q)
else
t ← nextGeneralization(t)
i ← i + 1
end if
end while
else
t ← makeDummy(Q)
end if
return Encrypt(t)
end procedure
The filtering phase algorithm is given by Algo-
rithm 2.
First, the algorithm sorts tuples of the aggre-
gation phase by generalization level, making mul-
tiple sets of tuples of same generalization level.
The function verifyHaving checks if COUNT(*) and
COUNT(Disctinct) match the anonymization guar-
Algorithm 2: Filtering Phase.
procedure FILTERING_PHASE(Query Q, Tuples-
Set T)
sortByGeneralizationLevel(T )
g ← getGuarantees(Q)
for i f rom 0 to MaxGeneralizationLevel(Q) do
for t ∈ T
i
do
t ← decrypt(t)
if veri f yHaving(t,Q) then
result.addTuple(t)
else if canGeneralize(t) then
t ← nextGeneralization(t)
T
i+1
.addTuple(t)
end if
end for
end for
return result
end procedure
antees expected at this generalization level. If so,
the tuple is added to the result. Otherwise, it is fur-
ther generalized and merged with the set of higher
generalization level. At the end, every tuple which
cannot reach the adequate privacy constraints, despite
achieving maximum generalization is not included in
the result.
4.2 Experiments Platform
SD card
Bluetooth
Fingerprint
reader
Smartcard
(data manag
t
)
(secrets)
(data)
MCU
USB
Figure 7: TDS characteristics.
The performance of the
k
i
SQL/AA protocol pre-
sented above has been measured on the tamper re-
sistant open-source hardware platform shown in Fig-
ure 7. The TDS hardware platform consists of a
32-bit ARM Cortex-M4 microcontroller with a max-
imum frequency of 168MHz, 1MB of internal NOR
flash memory and 196kb of RAM, itself connected
to a µSD card containing all the personal data in
an encrypted form and to a secure element (open
smartcard) containing cryptographic secrets and al-
gorithms. The TDS can communicate either through
DATA 2017 - 6th International Conference on Data Science, Technology and Applications
114
USB (our case in this study) or Bluetooth. Finally,
the TDS embeds a relational DBMS engine, named
PlugDB
10
, running in the microcontroller. PlugDB
is capable to execute SQL statement over the local
personal data stored in the TDS. In our context, it is
mainly used to implement the WHERE clause during
the Collection phase of
k
i
SQL/AA.
Our performance tests use the Adult dataset
from the UCI machine learning repository (Lich-
man, 2013). This dataset is an extraction from the
American census bureau database. We modified the
dataset the same way of (Iyengar, 2002; Bayardo
and Agrawal, 2005). We kept eight attributes to per-
form the GoupBy clause, namely age, workclass,
education, marital status, occupation, race,
native country and gender. Since our work is
based on GROUP BY queries, we also kept the
fnlwgt (i.e. final weight) attribute to perform an AVG
on it. The final weight is a computed attribute giv-
ing similar value for people with similar demographic
characteristics. We also removed each tuple with a
missing value. At the end we kept 30162 tuples. At-
tributes age and education are treated as numeric
values and others as categorical values. Since TDS
have limited resources, categorical value are repre-
sented by a bit vector. For instance, the categorical
attribute workclass is represented by a 8 bits value
and its generalization process is performed by taking
the upper node on the generalization tree given in Fig-
ure 8. The native country attribute is the largest and
requires 49 bits to be represented.
Private
0x80
Self-emp-not-inc
0x40
Self-emp-inc
0x20
Federal-gov
0x10
Locale-gov
0x08
State-gov
0x04
Without-pay
0x02
Never-worked
0x01
Gov-emp
0x1c
Self-emp
0x60
without-pay
0x03
Emp
0xfc
*
0xff
Figure 8: Generalization tree of workclass attribute.
4.3 Performance measurements
k
i
SQL/AA being an extension of SQL/AA protocol,
this section focuses on the evaluation of the overhead
incurred by the introduction of anonymisation guar-
antees in the query protocol. Then, it sums up to a di-
rect comparison between
k
i
SQL/AA and the genuine
SQL/AA. To make the performance evaluation more
complete, we first recall from (To et al., 2016) the
comparison between SQL/AA itself and other state of
the art methods to securely compute aggregate SQL
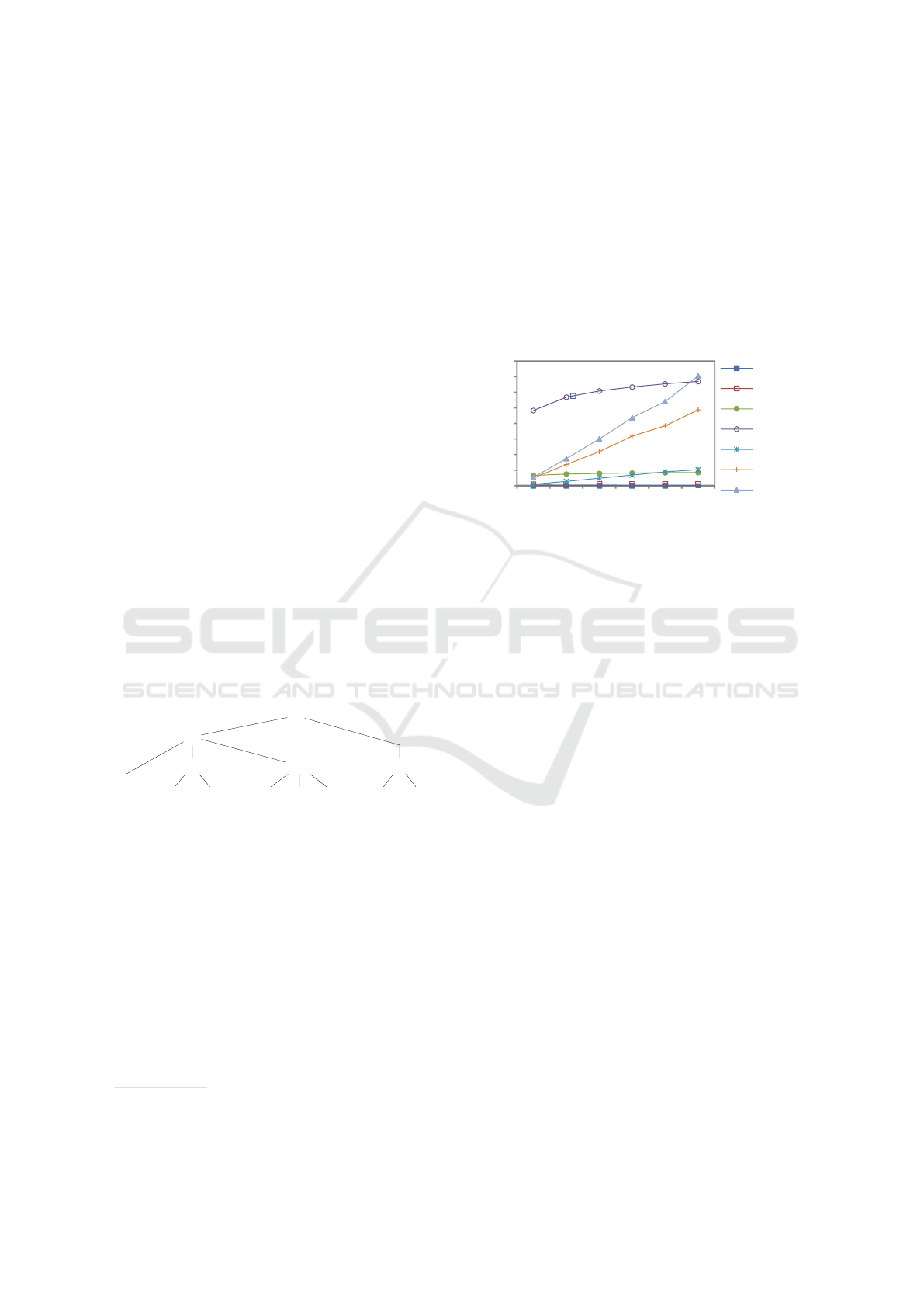
queries. This comparison is pictured in Figure 9.
The Paillier curve shows the performance to compute
10
https://project.inria.fr/plugdb/en/https://project.inria.fr/
plugdb/en/
aggregation in a secure centralized server using ho-
momorphic encryption, presented in (Ge and Zdonik,
2007). The DES curve uses also a centralized server
and a DES encryption scheme (data are decrypted at
computation time). Finally, SC curves correspond to
the SQL/AA computation with various numbers of
groups G (i.e. defined by GroupBy clause). This fig-
ure shows the strength of the massively parallel cal-
culation of TDSs when G is small and its limits when
G is really too big. We compare next the overhead
introduced by our contribution to SQL/AA.
0
5
10
15
20
25
30
35
40
5
15
25
35
45
55
TQ (second)
Nt (millions)
SC (G=1)
SC (G=100)
SC (G=1000)
SC (G=10000)
Plaintext
Paillier
DES
Figure 9: Performance measurements of SQL/AA and state
of the art.
Categorical vs. numeric values. We ran a query
with one hundred generalization levels, using first cat-
egorical, then numerical values. Execution time was
exactly the same, demonstrating that the cost of gen-
eralizing categorical or numerical values is indiffer-
ent.
Collection and Filtering Phases. Figures 10 and 11
show the overhead introduced by our approach, re-
spectively on the collection and filtering phases. The
time corresponds to processing every possible gener-
alization of the query presented in Figure 5, which
generates the maximal overhead (i.e., worst case) for
our approach. The SQL/AA bar corresponds to the ex-
ecution cost of the SQL/AA protocol inside the TDS,
the data transfer bar corresponds to the total time
spent sending the query and retrieving the tuple (ap-
proximately 200 bytes at an experimentally measured
data transfer rate of 7.9Mbits/sec), the TDS platform
bar corresponds to the internal cost of communicating
between the infrastructure and the TDS (data trans-
fer excluded), and the Privacy bar corresponds to the
overhead introduced by the kiSQL/AA approach. All
times are indicated in milliseconds. Values are aver-
aged over the whole dataset (i.e. 30K tuples).
Collection Phase Analysis. The overhead of the
collection phase resides in deciding how to generalize
the tuple in order to comply with the local privacy re-
quirements, and the global query privacy constraints.
Figure 10 shows that our protocol introduces a 0.25ms
overhead for a total average execution time of 3.5ms,
thus under 10% which we consider is a very reason-
Managing Distributed Queries under Personalized Anonymity Constraints
115
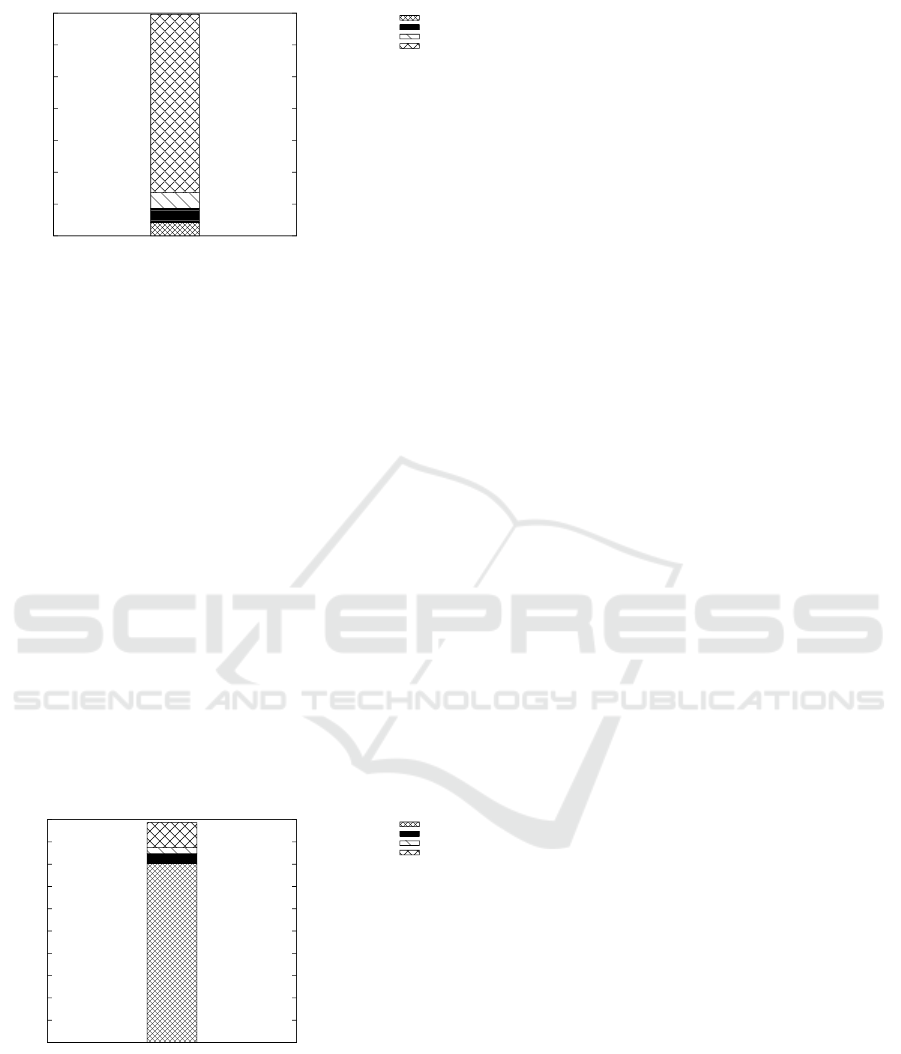
0
0.5
1
1.5
2
2.5
3
3.5
Time (ms)
data transfert
SQL/AA
Privacy
TDS platform
Figure 10: Collection Phase Execution Time Breakdown.
able cost.
Filtering Phases Analysis. Figure 11 shows break-
down of the filtering phase execution time. The filter-
ing phase takes places once the TDSs have computed
all the aggregations and generalizations. The limited
resources of the TDSs are bypassed by the SQL/AA
system with the help of the (distributed) aggregation
phase. Since every group is represented by one tu-
ple, the TDS which computes the filtering phase re-
ceives a reduced amount of tuples (called G). To et
al. have shown that the SQL/AA protocol converges
if it is possible for a given TDS to compute G groups
during the aggregation phase. As this is the number
of tuples that will be processed during the filtering
phase, we know that if G is under the threshold to
allow its computation via the distributed agregation
phase, then it will be possible to compute the filter-
ing phase with our improved protocol. Once again,
measurements show that the overhead introduced by
k
i
SQL/AA is of only 4% compared to the overall cost
of this phase : the overhead introduced is of 0.42ms
compared to a total cost of 9.8ms.
0
1
2
3
4
5
6
7
8
9
10
Time (ms)
data transfert
SQL/AA
Privacy
TDS platform
Figure 11: Filtering Phase Execution Time Breakdown.
5 CONCLUSION
In this paper, we presented a novel approach to de-
fine and enforce personalized anonymity constraints
on SQL GROUP BY queries. To the best of our
knowledge, this is the first approach targeting this is-
sue. To this end, we extended the SQL/AA protocol
and implemented our solution on secure hardware to-
kens (TDS). Our experiments show that our approach
is clearly useable, with an overhead of a few percent
on a total execution time compared with the genuine
SQL/AA protocol.
Our current work involves investigating the qual-
ity of the anonymization produced, in presence of
different anonymization constraints for each individ-
ual. We firmly believe that introducing personalized
anonymity constraints in database queries and provid-
ing a secure decentralized query processing frame-
work to execute them gives substance to the user’s
empowerment principle called today by all legisla-
tions regulating the use of personal data.
REFERENCES
Abiteboul, S., André, B., and Kaplan, D. (2015). Managing
your digital life. Commun. ACM, 58(5):32–35.
Anciaux, N., Bonnet, P., Bouganim, L., Nguyen, B., Popa,
I. S., and Pucheral, P. (2013). Trusted cells: A sea
change for personal data services. In CIDR 2013,
Sixth Biennial Conference on Innovative Data Systems
Research, Asilomar, CA, USA, January 6-9, 2013, On-
line Proceedings.
Bayardo, R. J. and Agrawal, R. (2005). Data privacy
through optimal k-anonymization. In Proceedings
of the 21st International Conference on Data Engi-
neering, ICDE ’05, pages 217–228, Washington, DC,
USA. IEEE Computer Society.
Dwork, C. (2006). Differential privacy. In Proceeding
of the 39th International Colloquium on Automata,
Languages and Programming, volume 4052 of Lec-
ture Notes in Computer Science, pages 1–12. Springer
Berlin / Heidelberg.
European Union (2014). ARTICLE 29 Data Protection
Working Party: Opinion 05/2014 on Anonymisation
Techniques.
European Union (2016). Regulation (EU) 2016/679 of the
European Parliament and of the Council of 27 April
2016 on the protection of natural persons with re-
gard to the processing of personal data and on the
free movement of such data, and repealing Directive
95/46/EC (General Data Protection Regulation). Offi-
cial Journal of the European Union, L119/59.
Flajolet, P., Fusy, r., Gandouet, O., and Meunier, F. (2007).
Hyperloglog: The analysis of a near-optimal cardinal-
ity estimation algorithm. In Proceedings of the 2007
International conference on Analysis of Algorithms
(AOFA’07).
Ge, T. and Zdonik, S. (2007). Answering aggregation
queries in a secure system model. In Proceedings
of the 33rd International Conference on Very Large
Data Bases, VLDB ’07, pages 519–530. VLDB En-
dowment.
DATA 2017 - 6th International Conference on Data Science, Technology and Applications
116

Iyengar, V. S. (2002). Transforming data to satisfy pri-
vacy constraints. In Proceedings of the Eighth
ACM SIGKDD International Conference on Knowl-
edge Discovery and Data Mining, KDD ’02, pages
279–288, New York, NY, USA. ACM.
Li, N., Li, T., and Venkatasubramanian, S. (2010). Close-
ness: A new privacy measure for data publishing.
IEEE Trans. Knowl. Data Eng., 22(7):943–956.
Lichman, M. (2013). UCI machine learning repository.
Machanavajjhala, A., Gehrke, J., Kifer, D., and Venkita-
subramaniam, M. (2006). l-diversity: Privacy beyond
k-anonymity. In Proceedings of the 22nd Interna-
tional Conference on Data Engineering, ICDE 2006,
3-8 April 2006, Atlanta, GA, USA, page 24.
Sweeney, L. (2002). k-anonymity: A model for protecting
privacy. International Journal of Uncertainty, Fuzzi-
ness and Knowledge-Based Systems, 10(5):557–570.
To, Q., Nguyen, B., and Pucheral, P. (2014). SQL/AA: ex-
ecuting SQL on an asymmetric architecture. PVLDB,
7(13):1625–1628.
To, Q.-C., Nguyen, B., and Pucheral, P. (2016). Private and
scalable execution of sql aggregates on a secure de-
centralized architecture. ACM Trans. Database Syst.,
41(3):16:1–16:43.
Trabelsi, S., Neven, G., Raggett, D., Ardagna, C., and et al.
(2011). Report on design and implementation. Tech-
nical report, PrimeLife Deliverable.
Managing Distributed Queries under Personalized Anonymity Constraints
117
