
Formal Concept Analysis Applied to
Professional Social Networks Analysis
Paula R. C. Silva
1
, S´ergio M. Dias
1,2
, Wladmir C. Brand˜ao
1
, Mark A. Song
1
and Luis E. Z´arate
1
1
Informatics Institute, Pontifical Catholic University of Minas Gerais, Belo Horizonte, Brazil
2
Federal Service of Data Processing, Belo Horizonte, Brazil
Keywords:
Formal Concept Analysis, Proper Implications, Social Networks.
Abstract:
From the recent proliferation of online social networks, a set of specific type of social network is attracting
more and more interest from people all around the world. It is professional social networks, where the users’
interest is oriented to business. The behavior analysis of this type of user can generate knowledge about
competences that people have been developed in their professional career. In this scenario, and considering
the available amount of information in professional social networks, it has been fundamental the adoption of
effective computational methods to analyze these networks. The formal concept analysis (FCA) has been a
effective technique to social network analysis (SNA), because it allows identify conceptual structures in data
sets, through conceptual lattice and implication rules. Particularly, a specific set of implications rules, know
as proper implications, can represent the minimum set of conditions to reach a specific goal. In this work,
we proposed a FCA-based approach to identify relations among professional competences through proper
implications. The experimental results, with professional profiles from LinkedIn and proper implications
extracted from PropIm algorithm, shows the minimum sets of skills that is necessary to reach job positions.
1 INTRODUCTION
In increasingly interconnected world, the social net-
works attend different people’s interests and address
the communication and information needs of several
user groups (Russell, 2013). In particular, there are
professional social networks focused on a specific
group of users interest is oriented to business. One of
the largest and most popular professional social net-
work is LinkedIn, which has more than 400 millions
users distributed in more than 200 countries and terri-
tories (LinkedIn, 2016).
LinkedIn users create professional profiles, they
available their professional skills, competences and
experience. Thus, LinkedIn provides a source of pro-
fessional information that can be exploited by enter-
prise managers in different ways, e.g., to find people
with appropriate competences to fulfill specific po-
sitions. In addition, the size and diversity of user-
generated content create an opportunity to identify
behavioral trends and user communities. In this sce-
nario, the formal concept analysis (FCA) presents it-
self as a mathematical theory that can be used for this
purpose.
FCA presents a mathematical formulation for data
analysis, which identify conceptual structures from a
data set (Ganter et al., 2005). It also presents an in-
teresting unified framework to identify dependencies
among data, by understanding and computing them in
a formal way (Codocedo et al., 2016). It is a branch
of lattice theory motivated by the need for a clear for-
malization of the notions of concept hierarchy.
There are two ways to extract and represent
knowledge from FCA: conceptual lattice and impli-
cation rules. In this work, we applied a particularly
type of implication rules, know as proper implica-
tions (Taouil and Bastide, 2001). We say that a propo-
sition P logically implies a proposition Q (P → Q), if
Q is true whenever P is true. The set of proper im-
plications have a minimal left-hand side and only one
item in right-hand side (Taouil and Bastide, 2001). It
has been used when the need is to find the minimum
conditionsto lead a goal. In this article, theproper im-
plications represent the set of minimum professional’s
skills (conditions) for achieve a job position (goal).
For example, the proper implication {statistic, ma-
chine learning, databases} → {data scientist} rep-
resent a minimum set of skills which are necessary to
be a data scientist.
Several authors have been applied FCA to address
Silva, P., Dias, S., Brandão, W., Song, M. and Zárate, L.
Formal Concept Analysis Applied to Professional Social Networks Analysis.
DOI: 10.5220/0006333401230134
In Proceedings of the 19th International Conference on Enterprise Information Systems (ICEIS 2017) - Volume 1, pages 123-134
ISBN: 978-989-758-247-9
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
123

research problems related to social networks analysis
(SNA). Note that, there are other methods to retrieve
knowledge from social networks. They are usually
based on graph theory, clustering and frequent item-
sets, which provide an approach to represent a social
network through a formal way. Additionally, there are
several FCA to SNA applications, such as ontology-
based technique (Kontopoulos et al., 2013), social
communities (Ali et al., 2014), network representa-
tion through concept lattice (Cuvelier and Aufaure,
2011), contextual pre-filtering process and identifying
user behavior through implication rules (Neto et al.,
2015a).
In this article, we proposed a FCA-based ap-
proach to identify professionalbehaviors through data
scraped from LinkedIn. First, we conceptually model
a LinkedIn user profile according to the model of
competences proposed by Durand (1998), because
this model has more acceptance in industry and
academia (Brand˜ao and Guimar˜aes, 2001). Second,
as an input data set, our approach needs an incidence
table (formal context) and a subset of proper implica-
tions are expected as an output. Lastly, a proper im-
plication represent careers trajectories, by minimum
professional’s skills (conditions) for achieve a posi-
tion (goal). These implications was extracted using
our proposed algorithm named PropIm. The PropIm
algorithm was proposed to extract proper implications
with support greater than zero, using a scalable ap-
proach.
The main contributions of this paper are: a profes-
sionals data set scraped from LinkedIn, a FCA-based
approach, and experiments set for apply FCA to pro-
fessional career analysis.
The structure of the article follows as: In Section
2, we present the preliminary definitions related to
FCA. In Section 3, we report related work that applied
FCA to social networks analysis. In Section 4, we
present our FCA-based approach to SNA. In Section
5, we report experiments and results. Finally, in Sec-
tion 6, we present the conclusions and future work.
2 FORMAL CONCEPT ANALYSIS
In this section, we introduce concepts related of
formal concept analysis (FCA) reported on litera-
ture (Ganter and Wille, 2012).
2.1 Formal Context
Formally, a formal context is a triple (G,M,I), where
G is a set of objects (rows), M is a set of attributes
(columns) and I are incidences. It is defined as
I ⊆ G × M. If an object g ∈ G and an attribute m ∈ M
have a relationship I, their representation is (g,m) ∈ I
or gIm, which could be read as “object g has attribute
m”. When an object has an attribute, the incidence is
identified and represented by “x”. In the formal con-
text shown in Table 1, rows are objects representing
users, and the columns are professional skills and po-
sitions.
Table 1: Example context of an user’s LinkedIn skills. The
attributes are: a: networks, b: mobile application, c: soft-
ware engineering, d: data bases, e: graphic processing, f:
computer architecture, g: operational systems.
a b c d e f g
17 x x x x x
18 x x
19 x x x
20 x x x x
21 x x x
22 x x
23 x x x x x
24 x x
Given a subset of objects A ⊆ G of formal context
(G,M,I), there is an attribute subset of M common
to all objects of A, even if empty. Likewise, given
a set B ⊆ M, there is an object subset that shares the
attributes of B, even if empty. These relationships are
defined by derivation operations:
A
′
:= {m ∈ M|gIm∀g ∈ A} (1)
B
′
:= {g ∈ G|gIm∀m ∈ B} (2)
A formal context (G, M, I) is a clarified context,
when ∀ g, h ∈ G, from g
′
= h
′
it always follows that
and, correspondingly m
′
= n
′
implies m = n ∀ m,n
∈ M. The clarification process consists in maintain-
ing one element (objects and attributes) from a set of
equal elements eliminating the others. In this process,
the number of objects and attributes can be reduced
while retaining lattice form (Ganter et al., 2005).
2.2 Formal Concept
From formal contexts we can obtain formal concepts,
defined as pairs (A,B), where A ⊆ G is called exten-
sion and B ⊆ M and is called intention, and they must
follow conditions A = B
′
and B = A
′
(equations 1 and
2)(Ganter et al., 2005).
Based on the formal context from Table 1, we can
obtain the formal concept ({18, 21, 24}, {software
engineering, data bases}), where elements of subset
B are {software engineering, data bases}, that, by
derivation (Equation 2), yield subset A = {18, 21,
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
124
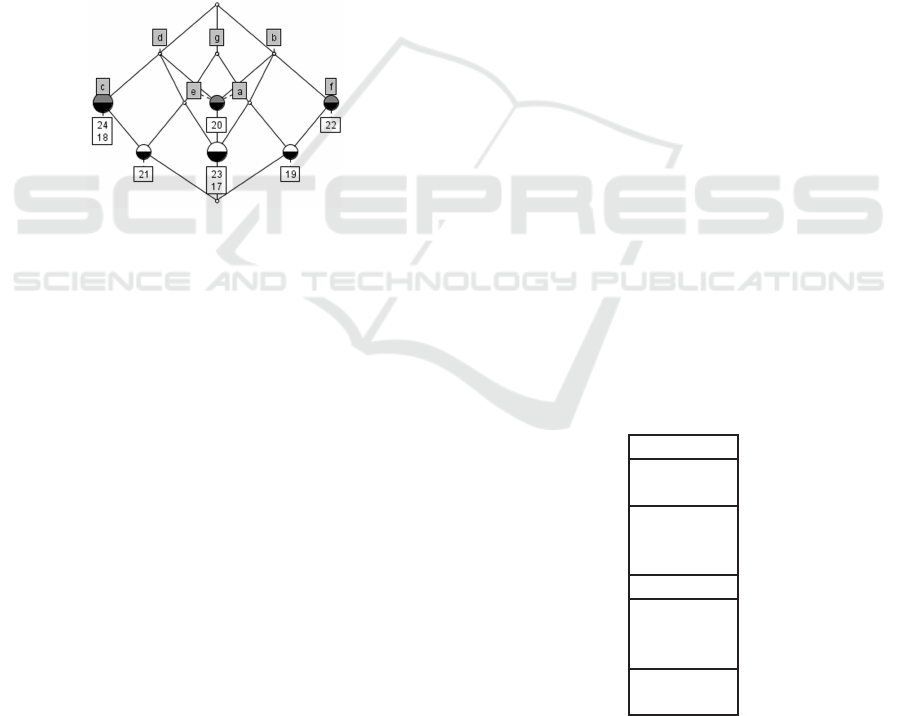
24}, representing the subset of users who have skills
in software engineering (c) and data bases (d).
It is important to note that a formal concept cor-
responds to any aspect of the problem domain, repre-
sented by objects and attributes, in which exists some
kind of comprehension and understanding.
2.3 Concept Lattice
With all formal concepts sorted hierarchically by or-
der of inclusion ⊆, we can build the concept lattice.
Sorting must be done, so that, the concept (A
1
,B
1
) is
considered less than or equal to (A
2
,B
2
) if and only
if, A
1
⊆ A
2
(equivalent to B
2
⊆ B
1
). In this case, the
concept (A
1
,B
1
) is called sub-concept and the con-
cept (A
2
,B
2
) super-concept. In Figure 1 is shown an
example of a concept lattice from the formal context
in Table 1.
Figure 1: Example of concept lattice.
2.4 Implication Rules
Given a formal context (G,M,I) or a concept lattice
B(G,M, I), these can be extracted exact rules or ap-
proximate rules (rules with statistical values, for ex-
ample, support and confidence) that express in a alter-
native way the underlying knowledge. The exact rules
can be classified in implication rules and functional
dependencies, while the approximation rules are di-
vided in classification rules and association rules. It
is particularly important in this work, to get the social
networks users’ behavior, consider exact rules. From
now these rules are going to called only implications.
Follows the definition of an implication (Ganter and
Wille, 2012):
Definition 2.1. Being a formal context whose at-
tributes set is M. An implication is an expression
P → Q, which P,Q ⊆ M.
An implication P → Q, extracted from a formal
context, or respective concept lattice, have to be such
that P
′
⊆ Q
′
. In other words: every object wich has
the attributes of P, it also have the attributes of Q.
Note that, if X is a set of attributes, then X respects
an implication P → Q iff P 6⊆ X or Q ⊆ X. An impli-
cation P → Q holds in a set {X
1
,... ,X
n
} ⊆ M iff each
X
i
respects P → Q; and P → Q is an implication of the
context (G,M,I) iff it holds in its set of object intents
(an object intent is the set of its attributes). An impli-
cation P → Q follows from a set of implications I , iff
for every set of attributes X if X respects I , then it
respects P → Q. A set of implications I is said to be
complete in (G, M, I) iff every implication of (G,M, I)
follows from I . A set of implications I is said to be
redundant iff it contains an implication P → Q that
follows from I \{P → Q}. Finally, an implication
P → Q is considered superfluous iff P∩ Q 6=
/
0.
In social networks will be convenientthat each im-
plication represent a minimum behavior. For this, we
will require that the complete set of implications I
of a formal context (G, M,I) have the following char-
acteristics, to be used as representative of the process:
• the right hand side of each implication is unitary:
if P → m ∈ I , then m ∈ M;
• superfluous implications are not allowed: if P →
m ∈ I , then m /∈ P;
• specializations are not allowed, i.e. left hand sides
are minimal: if P → m ∈ I , then there is not any
Q → m ∈ I such that Q ⊂ P.
A complete set of implications in (G, M,I) with such
properties is the so called set of proper implications
(Taouil and Bastide, 2001) or unary implication sys-
tem (UIS) (Bertet and Monjardet, 2010).
Definition 2.2. Let J be the complete closed set of
implications of a formal context (G,M,I). Then the
set of proper implications I for (G,M,I) is defined
as: {P → m ∈ J |P ⊆ M and m ∈ M \ P and ∀Z ⊂
P: Z → m /∈ J }.
Table 2: Proper implications extracted from formal context
in Table 1.
P → m
e
→ a
b,d
a
→ b
e
f
d,g → c
a
→ dc
e
a
→ e
b,d
The Table 2 shows the set of proper implications,
from the formal context example (Table 1). For ex-
ample, in implication b,d → a, the set P is composed
by the set of attributes {b, d}, m = {a} and → sym-
bol represents the incidence. P and m are called as
Formal Concept Analysis Applied to Professional Social Networks Analysis
125
premise and conclusion. So the implication b,d → a,
can be read as the premise b,d implies in conclusion
a. It is important to note that, the conclusion a can
has more than one minimal premises. According to
Definition 2.2, the premises {e} and {b, d} are mini-
mal, and they can not be a subset of another premises
that imply in a. For example, the implication e → a
is a proper implication, but e, g → a is not a proper
implication.
3 RELATED WORK
Recently, several authors have applied FCA for social
networks analysis (Rome and Haralick, 2005; Snasel
et al., 2009; Stattner and Collard, 2012; Aufaure and
Le Grand, 2013; Banerjee et al., 2014; Krajˇci, 2014;
Atzmueller, 2015; Neznanov and Parinov, 2015; Sol-
dano et al., 2015). These works have been motivated
by the interest in understand and interpret social net-
works through mathematical formulation. The main
subjects are: social network representation as a con-
cept lattice, community detection, concepts mining,
ontology analysis and rule mining through implica-
tions.
In (Cordero et al., 2015), the authors proposed
knowledge-based model of influence applying FCA to
compute minimal generators and closed sets directly
from an implicational system, for obtain a structure
of user’s influence. The data was extracted from Twit-
ter social network, it was transformed into a formal
context and it was generated the Duquenne-Guigues
basis. In (Neto et al., 2015b), the author shows an ap-
proach to analyze a data base composed by internet’s
access logs. The authors apply the minimal set of im-
plications and complex networks theories to identify
substructures, that are not easily visualized with two-
mode networks. In (Jota Resende et al., 2015), the au-
thors propose an FCA-based approach to build canon-
ical models, which represents Orkut access’ patterns.
These papers resemble this work, because they also
talks about how to map social networks in terms of
objects and attributes, and extract knowledge through
implications rules set.
As this work, in Barysheva et al. (2015) the
authors apply FCA to identify interaction patterns
through data scraped from LinkedIn. They did not
work with professional competencies and proper im-
plications, like us, because their goal was classify
users’ behavior though their network interactions, and
the knowledge was extracted from conceptual lattice.
The papers of Li et al. (2016); Xu et al. (2014a);
Lorenzo et al. (2016) are the main works about ca-
reer trajectory analysis using LinkedIn data. Their
goal was model professional profiles and identify ca-
reer trajectories through temporal analysis. Even not
applying FCA, these authors apply data mining tech-
niques to identify professional career trajectories.
In general, the FCA has been applied to min-
ing social media, because the FCA theory presents
a formalism for the representation of network struc-
ture, behavior identification and knowledge extrac-
tion, through formal representation of problem do-
main from objects, attributes and their respective in-
cidences.
Our proposed approach combines techniques con-
ducted on formal concept analysis, patter mining and
model of professional competence.
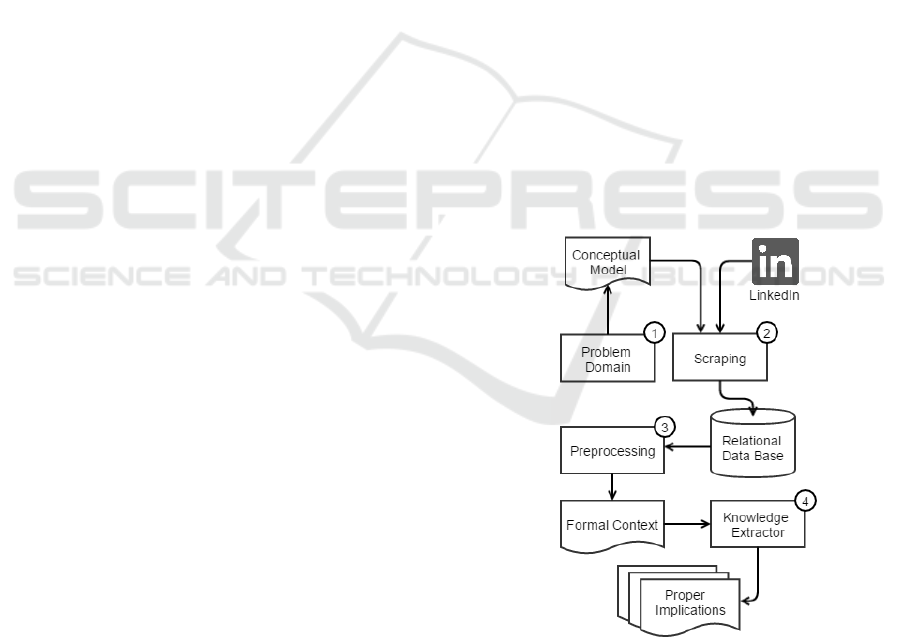
4 FCA-BASED APPROACH
In this article, the problem of analysis and representa-
tion of professional profiles in social networks, can be
grounded by building a conceptual model, that merge
the social network with professional skills theory, and
the transformation of this model to a formal context.
After scraping and pre-process the data to a formal
context, we can extract the set of implications to be
analyzed. The Figure 2 shows the methodology steps
proposed to analyze LinkedIn social network through
FCA.
Figure 2: Methodology based in FCA to SNA.
4.1 Problem Domain
According to Figure 2, the first step (1) was to con-
struct the conceptual model according to the problem
to be treated. In this case, the problem involves the
characterization of a person as a professional. We
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
126
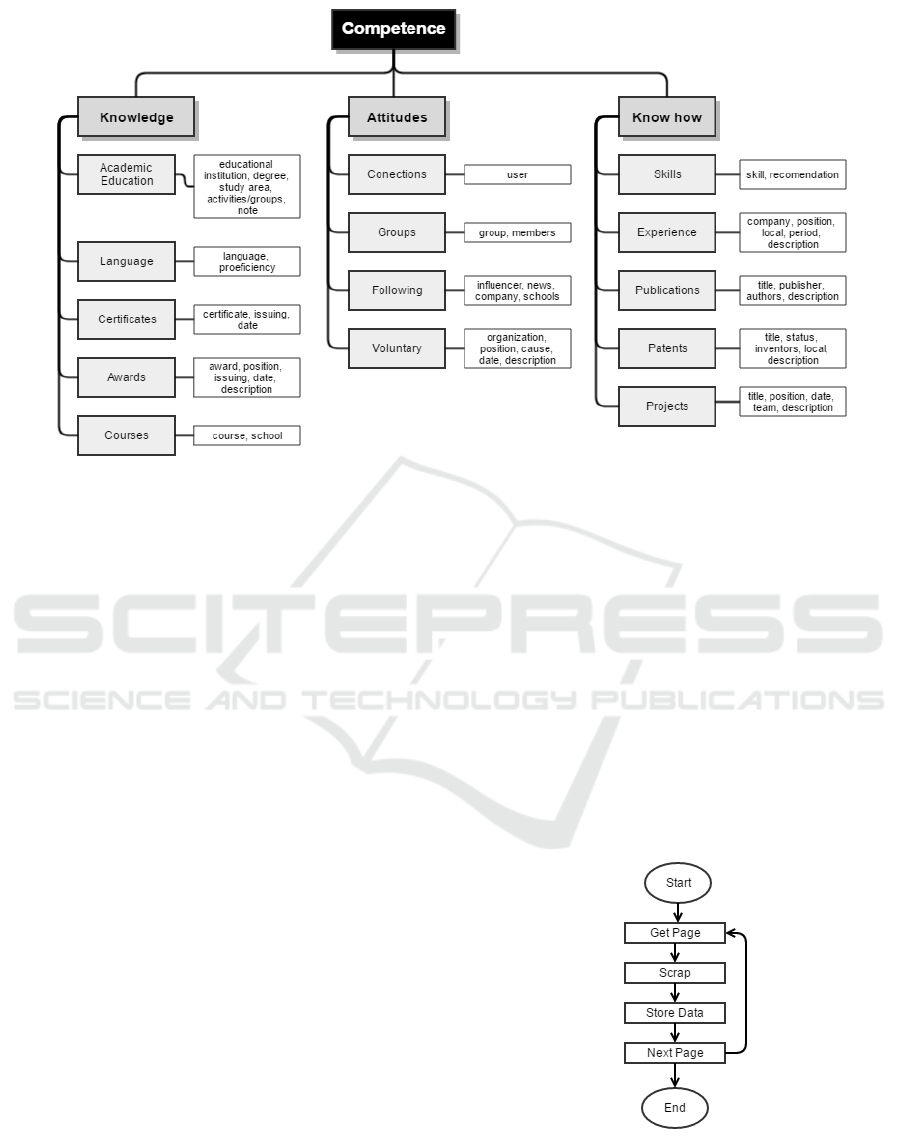
Figure 3: Professional identification through model of competence.
adopted the competence model proposed by Durand
(1998), because this model has greater acceptance
in both academic and business, since it seeks to in-
tegrate aspects related to this work, such as tech-
nical issues, cognition and attitudes (Brand˜ao and
Guimar˜aes, 2001). For Durand (1998), a professional
is characterized by his competence in accomplishing
a certain purpose. Competence is composed by three
dimensions: knowledge, attitudes and know how. The
dimensions are interdependent, because the behavior
of a professional is determined not only by his knowl-
edge but also by the attitudes and know how acquired
over time. The knowledge dimension is linked to
academic training and complementary courses. The
know how dimension is related to a person’s profes-
sional experiences. And finally, the attitude dimen-
sion is related to the way of people interact in their
professional environment.
The conceptual model was created from the clas-
sification of informational categories, based on the
model of competence. Figure 3 shows the domain
model for professional identification through model
of competence. The first level is related to the Com-
petence concept, in the second level is 3 dimensions,
in the third level is 14 aspects and in the fourth level
is 51 variables.
4.2 Scrapping
FCA techniques to social network analysis can yield
insights into user behaviors, detecting popular topics,
and discovering groups and communities with similar
characteristics. So, a task of gathering the data on a
specific subject is needed. In this case, the second step
(2) of the methodology represents the Scraping com-
ponent that is responsible for collecting the LinkedIn
user data.
The collection process was divided into two
phases. The first one selects the initial seeds, ran-
domly two user profiles were selected. This amount
of initial seed was satisfactory for the data collection
process, due to the total of profiles obtained being suf-
ficient for the study. It was defined that, as case study,
the data would be collected from people of Belo Hor-
izonte, Minas Gerais, Brazil and they must have at
least graduate courses in the information technology
(IT) area.
Figure 4: Scraping LinkedIn profile’s process.
The second phase goal is collect the public pro-
files. As the LinkedIn does not provide an API (Appli-
cation Programming Interface) to extract data directly
Formal Concept Analysis Applied to Professional Social Networks Analysis
127

from the server, an approach, known as open collec-
tion, has been adopted to extract data from users’ pub-
lic pages.
The Figure 4 exemplifies the flow of data collec-
tion process. The process starts by accessing a seed.
In the public profile there is a section denoted as “Peo-
ple also saw” - a list with the 10 most similar profiles
related to the visited profile (Xu et al., 2014b). The
collector looks up these addresses and verifies which
profiles meet the scope. Valid profiles are stored and
each one becomes a new seed to extract new links,
restarting the collection process until it reaches the
stop criterion. The stopping criterion is based on the
percentage of new profiles. Each iteration checks if
65% of the profiles were already in the database.
4.3 Preprocessing
The Preprocessing (3) component is responsible for
pre-processing the data extracted in the previous step.
In this work only the variables skills and experience
were considered. However, in future works, the other
dimensions will be included.
For the construction of the formal context, we con-
sidered, as attribute, each value of the competence
and experience variables. Each user (professional of
LinkedIn) is considered as an object. In the first ver-
sion of the formal context, 4000 attributes and 1280
objects were detected. As such values are texts and
LinkedIn allows users to fill the corresponding fields
with a free text, some problems have been detected.
In this case, it was necessary to create an ETL pro-
cess (Extract Transform Load) to clean and transform
the data, aiming to reduce the amount of attributes.
The ETL process consists of two stages. In
the first step, we applied basic procedures for string
cleaning, like: UTF-8 encoding correction, accent re-
moval,and standardization of all terms for the English
language through Google Translate API
1
. In the sec-
ond stage, we apply techniques to attribute reductions.
Such reductions were based on terms with semantic
relevance, in which the attributes skill and experience
could be reduced. For example, attributes as jpa, jsf
were renamed to java frameworks; attributes as de-
veloper, programmer, software developer, program
developer were renamed to software developer. The
vague nouns or trademark terms, as bachelor, engi-
neer, accessibility, microsoft, were removed, because
they are not relevant to our study.
At the end of the preprocessing step, a formal con-
text was created with 366 attributes and 970 objects,
which 61 attributes are related to experience and 305
to skills.
1
Translate API: https://cloud.google.com/translate/
4.4 Knowledge Extractor
The Impec (Taouil and Bastide, 2001) is the best-
known algorithm for extracting proper implications
from the formal context. This is due to the strategy
that the algorithm adopts at the moment in which it
finds the premises and their respective conclusions.
On the other hand, the strategy used, by the algo-
rithm, is computationally inefficient and it can not be
optimized or distributed. In some cases, only a few
context attributes are interesting to be in the conclu-
sion. The traditional algorithms only allow to gener-
ate the complete set, being necessary a step of filtering
the rules to select to those whose attributes of interest
appear as conclusion of the implications, occurring an
unnecessary computational effort.
Based on the problems described above, a new al-
gorithm was proposed to generate proper implications
from the formal context. The algorithm adopts an
easily scalable strategy and allows its proper impli-
cations to be generated from the attributes of interest
as a conclusion of implications. In general, the al-
gorithm receives a formal context as input, finds the
minimum premisses for each conclusion by combin-
ing attributes, applies a pruning heuristic, and uses the
derivation operators to validate the implications.
Input : Formal context (G,M,I)
Output: Set of proper implications I with
support greater than 1
1 I =
/
0
2 foreach m ∈ M do
3 P = m
′′
4 size = 1
5 Pa =
/
0
6 while size < |P| do
7 C =
P
size
8 P
C
= getCandidate(C,Pa)
9 foreach P1 ⊂ P
C
do
10 if P1
′
6=
/
0 and P1
′
⊂ m
′
then
11 Pa = Pa∪ {P1}
12 I = I ∪ {P1 → m}
13 end
14 end
15 size+ +
16 end
17 end
18 return I
Algorithm 1: Extract proper implications with support
greater than 1.
The pseudo-code of PropIm is given in Algo-
rithm 1. The main objective is to find implications
whose left side is minimal and the right side has only
one attribute. The algorithm needs a formal context
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
128
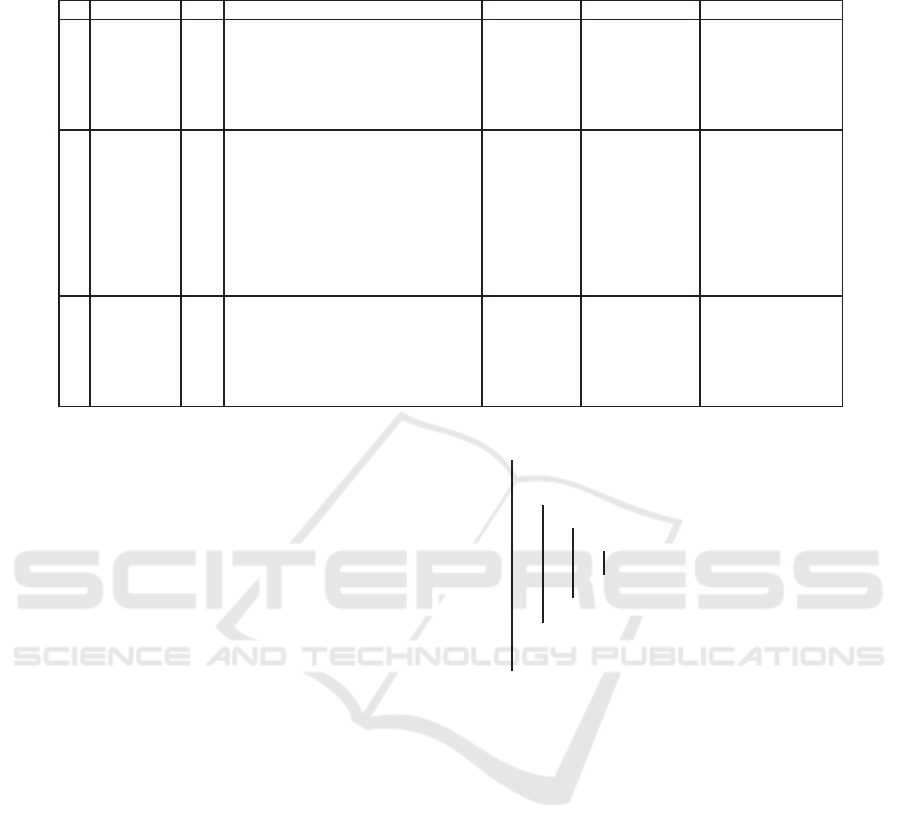
Table 3: Example of PropIm algorithm execution.
m P size C Pc Pa I
a {b, d, e, g} 1 {{b}, {d}, {e}, {g}} {{b},{d},
{e}, {g}}
{{e}} {{e-a}}
a {b,d,e,g} 2 {{bd}, {be}, {bg}, {de}, {dg},
{eg}}
{{bd},{bg},
{dg}}
{{e}, {bd}} {{e-a}, {bd-a}}
a {b,d,e,g} 3 {{bde}, {bdg}, {beg}, {deg}}
/
0
{{e},{bd}} {{e-a},{bd-a}}
a {b,d,e,g} 4 {{b,d,e,g}}
/
0
{{e}, {bd}} {{e-a},{bd-a}}
b {a,d,e,f,g} 1 {{a} , {d}, {e}, {f}, {g}} {{a},{d},
{e},{f},{g}}
{{a}, {e}, {f}} {{e-a}, {bd-a},
{a-b}, {e-b},
{f-b}}
b {a,d,e,f,g} 2 {{ad}, {ae}, {af}, {ag}, {de}, {df},
{dg}, {ef}, {eg}, {fg}}
{{dg}} {{a}, {e}, {f}} {{e-a}, {bd-a},
{a-b}, {e-b},
{f-b}}
b {a,d,e,f,g} 3 {{ade}, {adf}, {adg}, {aef},
{aeg}, {afg}, {def}, {deg}, {dfg},
{efg}}
/
0
{{a}, {e}, {f}} {{e-a}, {bd-a},
{a-b}, {e-b},
{f-b}}
c {d,g} 1 {{d}, {g}} {{d},{g}}
/
0
{{e-a},
{bd-a},{a-b},
{e-b}, {f-b}}
c {d,g} 2 {{dg}} {{dg}}
/
0
{{e-a}, {bd-a},
{a-b}, {e-b},
{f-b}}
(G,M,I) as input, and its output is a set of proper im-
plications. Line 1 initializes the set I with empty
set. The following loop (Lines 2-17) looks at each at-
tribute in the set M. We initially suppose that each
attribute m can be a conclusion for a set of premises.
For each m, we compute a left-hand side P1.
To reduce the searching space, the algorithm finds
the right side P for a left side m from a set of attributes
common to m objects. After, it finds sets of possible
premises for m based on P. The size counter deter-
mines the size of each premise, as the smallest possi-
ble size is 1 (an implication of type {b} → { a}), it is
initialized with 1 (Line 4).
A set of auxiliary premises Pa is used, where
all valid premises found leading to m conclusion are
stored (at Line 5 Pa is initialized as empty). In the
loop, from Lines 6-16, the set of minimum premises
is found and is bounded by |P|. In Line 7, the C set
gets all combinations of size size from elements in
P. In Line 8, the set of candidate premises is formed
through the function getCandidate which will be de-
scribed next.
Each candidate premise P1 ⊂ P
C
is checked to
ensure if the premise P1 and the conclusion m re-
sults in a valid proper implication. Case P1 6=
/
0 and
P ⊂ P1
′
, the premise p1 is added to the set of auxiliary
premises Pa and I = I ∪ {P1 → M} .
A neighborhood search heuristic was imple-
mented by the getCandidate (Pseudo-code in Algo-
rithm 2) function. The objective is to find, in the set of
C combinations, all subsets B that do not contain some
attribute that already belongs to some valid premise of
Pa. It receives, as parameter, the sets C and Pa, and
returns a set D of proper premises.
1 Function getCandidate (C,Pa)
2 D =
/
0
3 foreach a ∈ A|A ⊂ Pa do
4 foreach B ⊂ C do
5 if a /∈ B then
6 D = P
C
\ B
7 end
8 end
9 end
10 return D
Algorithm 2: Function getCandidate.
Table 3 shows the steps of PropIm algorithm,
on the example from Table 1. I contains ini-
tially
/
0. The first value to m is a (first attribute
from formal context) and m
′′
is the set of attributes
{b,d,e,g}. The size of combination sets is 1, so C =
{{b}, {d},{e},{g}}. Pa contains initially
/
0, C
/
0, so
the set of attributes returned by the function getCan-
didate is Pc = {{b},{d},{e},{g}}. For each subset
of Pc, only the element {e} attends the condition in
Line 10 (Algorithm 1), because {e}
′
= {17,20,23}
⊂ m
′
. The set {e} is added to Pa and the pair {e → a}
is added to I . When Pc is
/
0 and size is |P| the loop
to m = a is closed. So, the same steps happens for all
attributes, from formal context, imputed to m.
5 EXPERIMENTS
This section shows the procedures, adopted for run-
ning the experiments, and the analyses of results ob-
tained based in proposed FCA-based approach. The
Formal Concept Analysis Applied to Professional Social Networks Analysis
129

goal, of experiments, was to answer the following
questions:
• How do proper implications identify relations be-
tween skills and positions?
• Could we find intersections among sets of skills,
and what do these intersections represent?
5.1 Proper Implications to Competence
Identification
Among the 61 positions identified in Section 4.3, we
selected 20 positions and their 180 skills for analyze
the proper implications. In this case, the PropIm al-
gorithm extracted 895 proper implications related to
this reduced formal context. Figure 5, shows these
proper implications as a graph representation (proper
implications network). The central nodes are the po-
sitions and the edges represents the implications be-
tween premises (set of skills) and their conclusion
(position). In this study case, the graph representa-
tion helps us to analyze the distribution among sets of
skills and their respective positions.
In Figure 5 was highlighted some items related to
graph analysis:
• Central nodes density;
• Intersections among premises;
• Edges weight.
Figure 5: Proper implications network.
The central nodes density represents the diver-
sification of minimum sets of skills. The denser
nodes represents positions which have more diversi-
fication of minimum sets of skills. For example, the
highlighted node AD related to administrative direc-
tor position have 163 minimal sets of skills. Gen-
erally, the administrative director function is man-
age the company resources, like human, technolo-
gies and financial resources. The specific skills of
this professional can be different according to the
company industry, because he have to develop busi-
ness skills and know how about the company re-
sources. It is expected that administrative director de-
velop skills related to leadership, management, tech-
nology and communication. One of the proper im-
plications which represents this professional profile
is {entrepreneurship, human resources, information
management} → {administrative director}. Another
implication as {assets management, it governance,
leadership development, software development} →
{administrative director}, can represent a specific ad-
ministrative director from companies focused on soft-
ware development.
The less dense nodes represent jobs positions that
demand more specific sets of skills. For example the
ITC (IT consultant) node have only 3 sets of skills re-
lated to it. An IT consultant duties can vary depend-
ing on the nature of company’s project and client de-
sires. However, in general, this professional has skills
which combine IT and business knowledge. So, the
proper implication {ABAP
2
, agile methodology, BI
3
}
→ {it consultant} shows the common set of skills that
the IT consultants have.
The analysis related to intersection between
premises and edges weight will be discussed in the
next section (5.2).
5.2 Intersection between Skills and Job
Positions
According to Career Cast research (Cast, 2016), the
top 3 best jobs in Information Technology area is: data
scientist, information security analyst and software
engineer. From the set of proper implications, gen-
erated by PropIm algorithm, we filtered the top 3 jobs
positions, for analyze these jobs and identify the in-
tersection among their skills.
Figure 6 shows the top 3 job positions and the in-
tersections among their skills. The central nodes are
the top 3 positions, according to Career Cast ranking
(Cast, 2016): P
1
(data scientist), P
2
(information se-
curity analyst) and P
3
(software engineer). The edges
weight are the implication relative frequency. The rel-
ative frequency was calculated according to equation:
F =
F
i
F
p
, where F is the relative frequency, F
i
is the
2
ABAP: Advanced Business Application Programming
3
BI: Business Intelligence
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
130
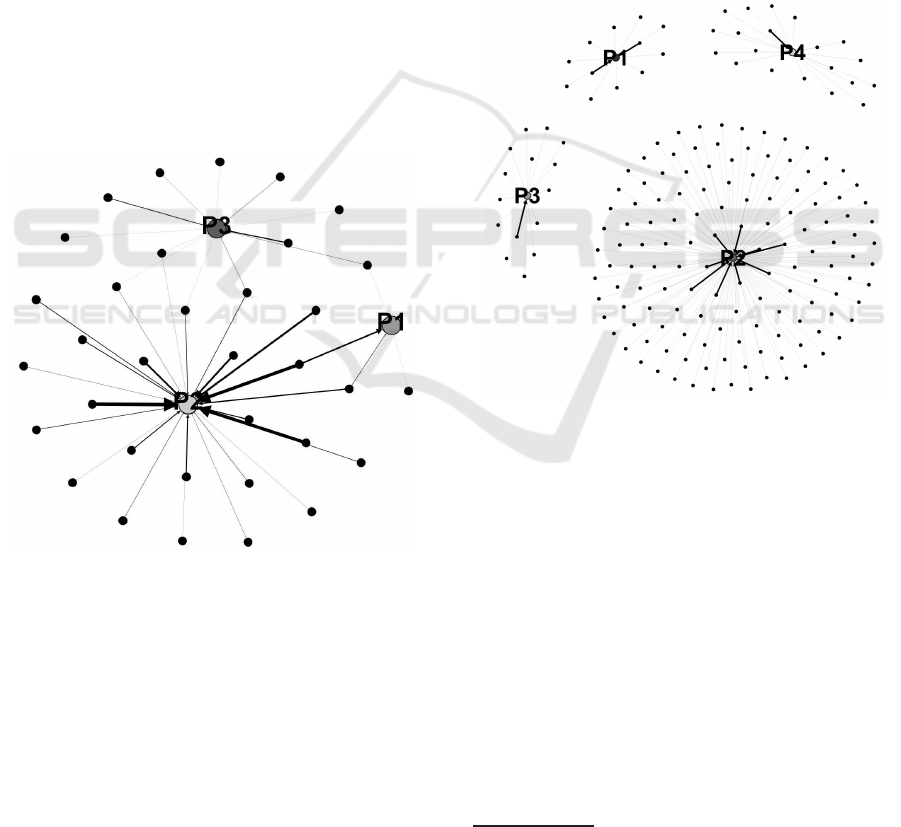
implication absolute frequency and F
p
is |m
′
|. For ex-
ample: the implication {C language} → {software
engineer} represents 31 objects (Fi) among 59 ob-
jects that have software engineer as incidence (Fp).
So, this implication relative frequency is 0.52. For
obtain the result as percentage is only multiply by
100, generating the relative frequency percentage of
52% to this proper implication in software engineer
set of implications. Therefore, the thicker edges rep-
resents implications with greater relative frequency. It
is important to note that, we applied the relative fre-
quency measure, because in this case, the frequency
represents the significance of an implication inside its
class. And the local significance is more relevant than
the implication support in the complete proper impli-
cations set. For example, the implication { java frame-
works} → {software engineer} has relative frequency
of 75.56%, and its support is 2.47%. In this example,
to analyze the relative frequency is more important
than the implication support, because the specific ob-
jective is identify the conditions to reach a software
engineer job. Is important to note that, in both cases
the confidence is 100%.
Figure 6: Top 3 jobs and their skills, where P
1
is data sci-
entist, P
2
is information security analyst and P
3
is software
engineer job position.
Figure 6 shows the intersections between the min-
imal sets of skills, considering the top 3 jobs positions
described above. In this case, the nodes P
1
and P
3
share four set of skills like {BI} → {security analyst}
and {BI} → {software engineer}. The nodes P
1
and
P
2
share two set of skills, like the proper implications
show: {agile methodology} → {data scientist} and
{agile methodology} → {information security ana-
lyst}. And, the nodes P
1
and P
3
share only one set of
skills, on {active directory
4
} → {data scientist} and
{active directory} → {software engineer}.
From these intersections, we observed that the
greater the intersections amount between skills sets,
more similar are the requirements to achieve a po-
sition. It would indicated possibilities to profes-
sional mobility among positions, when the set of skills
(premises) implies in several different positions (con-
clusions). So a professional could havecompetence to
assume different positions, because his skills could be
applied to different jobs. For example, in recruitment
and selection hiring process, this professional could
be compatible with several job vacancy, therefore he
could be more jobs opportunities. Another example
is the case when a professional needs change jobs, his
skills allow greater career mobility.
Figure 7: IT career hierarchical levels, where P
1
to P
4
rep-
resents the following job positions: P
1
is IT analyst, P
2
is IT
manager, P
3
is IT coordinator and P
4
is IT director.
Figure 7 shows 4 positions that represents differ-
ent hierarchical levels of IT career. The central nodes
represent these 4 positions: P
1
(IT analyst), P
2
(IT
coordinator), P
3
(IT manager) and P
4
(IT director).
The other nodes represent minimal sets of skills, and
edges represent implications. It is important to note
that, edges weight was calculated using the relative
frequency, previously described. From the figure we
could observe that there are disjoint sets and there
are not any intersections among positions. Accord-
ing to this hierarchy, P
1
and P
2
are positions related
to the early career, while P
3
and P
4
are positions hier-
archically superior. So, for P
1
was expected technical
skills like in the proper implication {.NET, automa-
4
Active directory: Microsoft tool kit for store and con-
trol information about network configurations.
Formal Concept Analysis Applied to Professional Social Networks Analysis
131

tion systems} → {IT analyst}. P
2
involves skills that
represent the transition between technical and man-
agerial level, like in the proper implication {.NET,
data base, ERP, it governance} → IT coordinator.
P
3
also involves skills related to hierarchical transi-
tion, but it was expected more managerial than tech-
nical skills, it could be expressed by the implication
{BPM
5
, cloud computing, CRM
6
} → IT manager. Fi-
nally, an IT director (P
4
) have to develop managerial
skills like was identified in implication {assets man-
agement, BI, business management, consulting} → IT
director. Then, for the professional get a career ad-
vancement, he have to develop skills of different na-
tures.
6 CONCLUSION AND FUTURE
WORKS
In this paper, we presented an FCA-based approach
to identify professional behavior through data scraped
from LinkedIn. Specifically, we apply proper impli-
cations to identify the minimum sets of skills that is
necessary for achieve a job position. In this case,
firstly, we model the problem domain to understand
the features which characterize a person as a pro-
fessional, according to model of competence. After,
we scraped data from LinkedIn, we applied prepro-
cessing techniques and transform this data into a for-
mal context. Finally, we extracted proper implica-
tions through PropIm algorithm and analyze the re-
sults through graph representations.
The main contributions of this paper were: a pro-
fessionals data set scraped from LinkedIn, a FCA-
based approach, and experiments set for apply FCA
to professional career analysis.
As part of FCA-based approach, we propose the
PropIm algorithm. The goal of PropIm algorithm is
extract proper implications with support greater than
zero. It was implemented applying pruning heuristics
and scalable strategy. In future works the algorithm
will be modified to run as a distributed application.
The problem’s order complexity to extract proper im-
plications from formal context is O(|M||I |(|G||M| +
|I ||M|)). The proposed algorithm also has exponen-
tial complexity, but the implemented strategy reduce
the computational effort computing only implications
with support greater than zero, and the pruning heuris-
tic reduce the possibilities of attributes combinations
into premises. Moreover, the initial loop allows pro-
cess the context in distributed way, because each con-
5
BPM: Business process management.
6
CRM: Customer relationship management
clusion from formal context can be processed sepa-
rately without causing loss of information in the final
set of proper implications.
The experiments answer the two questions:
• How do proper implications identify relations be-
tween skills and positions?
• Could we find intersections among sets of skills,
and what do these intersections represent?
In both questions, the proper implicationswas showed
as graph representation and the analysis is based in
central nodes density, intersections among premises
and edges weight. For the first question, experiments
show that denser nodes represent positions with more
diversification of minimum sets of skills, while less
dense nodes represent jobs that require more spe-
cific sets of skills. For the second question, experi-
ments show that there are intersections between sets
of skills from different jobs positions. These inter-
sections means that same set of skills is required for
different positions, which allows more professional
opportunities in different industries and more profes-
sional mobility. We also analyzed a set of positions
that compose a hierarchy of jobs in IT area. With this,
it was observed that disjointed sets were formed with-
out intersections between the skills, which shows that
for a professional to progress of career, it is necessary
to develop skills of different natures.
As future work, we intend to exploit other algo-
rithms, particularly those capable of obtaining the set
of implications from concept or the subset of formal
concepts as proposed by Dias (2016). Moreover, we
intend to implement the PropIm algorithm as a dis-
tributed application and compare several algorithms
to extract proper implications from formal context.
We also intend expand the experiments for all dimen-
sions from the professional model of competence.
ACKNOWLEDGEMENTS
The authors acknowledge the financial support re-
ceived from the Foundation for Research Support of
Minas Gerais state, FAPEMIG; the National Council
for Scientific and Technological Development, CNPq;
Coordination for the Improvement of Higher Educa-
tion Personnel, CAPES. We would also express grati-
tude to the Federal Service of Data Processing, SER-
PRO.
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
132

REFERENCES
Ali, S. S., Bentayeb, F., Missaoui, R., and Boussaid, O.
(2014). An Efficient Method for Community Detec-
tion Based on Formal Concept Analysis, pages 61–72.
Springer International Publishing, Cham.
Atzmueller, M. (2015). Subgroup and community analyt-
ics on attributed graphs. In Proceedings of the Work-
shop on Social Network Analysis using Formal Con-
cept Analysis.
Aufaure, M.-A. and Le Grand, B. (2013). Advances in fca-
based applications for social networks analysis. Int. J.
Concept. Struct. Smart Appl., 1(1):73–89.
Banerjee, S., Badr, Y., and Al-shammari, E. T. (2014). So-
cial Networks: A Framework of Computational Intel-
ligence, volume 526. Springer Berlin Heidelberg.
Barysheva, A., Golubtsova, A., and Yavorskiy, R. (2015).
Profiling less active users in online communities. In
Proceedings of the Workshop on Social Network Anal-
ysis using Formal Concept Analysis.
Bertet, K. and Monjardet, B. (2010). The multiple facets of
the canonical direct unit implicational basis. Theoret-
ical Computer Science, 411(22–24):2155 – 2166.
Brand˜ao, H. P. and Guimar˜aes, T. d. A. (2001). Gest˜ao de
competˆencias e gest˜ao de desempenho: tecnologias
distintas ou instrumentos de um mesmo construto?
Revista de Administrac¸˜ao de empresas, 41(1):8–15.
Cast, C. (2016). Jobs rated report 2016: Ranking 200 jobs.
Accessed in 2016-12-12.
Codocedo, V., Baixeries, J., Kaytoue, M., and Napoli, A.
(2016). Contributions to the formalization of order-
like dependencies using fca. In Proceedings of the 5th
International Workshop What can FCA do for Artifi-
cial Intelligence. CEUR-WS.
Cordero, P., Enciso, M., Mora, A., Ojeda-Aciego, M., and
Rossi, C. (2015). Knowledge discovery in social net-
works by using a logic-based treatment of implica-
tions. Know.-Based Syst., 87(C):16–25.
Cuvelier, E. and Aufaure, M.-A. (2011). A buzz and e-
reputation monitoring tool for twitter based on ga-
lois lattices. In Conceptual Structures for Discovering
Knowledge, pages 91–103. Springer, Berlin Heidel-
berg.
Dias, S. M. (2016). Reduc¸ ˜ao de Reticulados Conceituais
(Concept Lattice Reduction). PhD thesis, Department
of Computer Science of Federal University of Mi-
nas Gerais (UFMG), Belo Horizonte, Minas Gerais,
Brazil. In Portuguese.
Durand, T. (1998). Forms of incompetence. In Proceed-
ings Fourth International Conference on Competence-
Based Management. Oslo: Norwegian School of Man-
agement.
Ganter, B., Stumme, G., and Wille, R. (2005). Formal con-
cept analysis: foundations and applications, volume
3626. Springer Science & Business Media.
Ganter, B. and Wille, R. (2012). Formal concept analysis:
mathematical foundations. Springer Science & Busi-
ness Media.
Jota Resende, G., De Moraes, N. R., Dias, S. M., Mar-
ques Neto, H. T., and Zarate, L. E. (2015). Canonical
computational models based on formal concept anal-
ysis for social network analysis and representation. In
Web Services (ICWS), 2015 IEEE International Con-
ference on, pages 717–720. IEEE.
Kontopoulos, E., Berberidis, C., Dergiades, T., and Bassili-
ades, N. (2013). Ontology-based sentiment analysis
of twitter posts. Expert Systems with Applications,
40(10):4065 – 4074.
Krajˇci, S. (2014). Social Network and Formal Concept
Analysis, pages 41–61. Springer International Pub-
lishing, Cham.
Li, L., Zheng, G., Peltsverger, S., and Zhang, C. (2016).
Career trajectory analysis of information technology
alumni: A linkedin perspective. In Proceedings of the
17th Annual Conference on Information Technology
Education, SIGITE ’16, pages 2–6, New York, NY,
USA. ACM.
LinkedIn (2016). About linkedin. Accessed in 2016-12-02.
Lorenzo, E. R., Cordero, P., Enciso, M., Missaoui, R., and
Mora, A. (2016). Caisl: Simplification logic for con-
ditional attribute implications. In CLA.
Neto, S. M., Song, M., Dias, S., et al. (2015a). Min-
imal cover of implication rules to represent two
mode networks. In 2015 IEEE/WIC/ACM Interna-
tional Conference on Web Intelligence and Intelligent
Agent Technology (WI-IAT), volume 1, pages 211–
218. IEEE.
Neto, S. M., Song, M. A., Dias, S. M., and Z´arate, L. E.
(2015b). Using implications from fca to represent
a two mode network data. nternational Journal of
Software Engineering and Knowledge Engineering
(IJSEKE).
Neznanov, A. and Parinov, A. (2015). Analyzing social net-
works services using formal concept analysis research
toolbox. In Proceedings of the Workshop on Social
Network Analysis using Formal Concept Analysis.
Rome, J. E. and Haralick, R. M. (2005). Towards a Formal
Concept Analysis Approach to Exploring Communi-
ties on the World Wide Web, pages 33–48. Springer
Berlin Heidelberg, Berlin, Heidelberg.
Russell, M. A. (2013). Mining the Social Web: Data Mining
Facebook, Twitter, LinkedIn, Google+, GitHub, and
More. ” O’Reilly Media, Inc.”.
Snasel, V., Horak, Z., Kocibova, J., and Abraham,
A. (2009). Analyzing social networks using fca:
Complexity aspects. In Web Intelligence and In-
telligent Agent Technologies, 2009. WI-IAT ’09.
IEEE/WIC/ACM International Joint Conferences on,
volume 3, pages 38–41.
Soldano, H., Santini, G., and Bouthinon, D. (2015). Ab-
stract and local concepts in attributed networks. In
Proceedings of the Workshop on Social Network Anal-
ysis using Formal Concept Analysis.
Stattner, E. and Collard, M. (2012). Social-based con-
ceptual links: Conceptual analysis applied to social
networks. In Advances in Social Networks Analy-
sis and Mining (ASONAM), 2012 IEEE/ACM Interna-
tional Conference on, pages 25–29.
Taouil, R. and Bastide, Y. (2001). Computing Proper Impli-
cations. In Proceedings of the International Confer-
Formal Concept Analysis Applied to Professional Social Networks Analysis
133

ence on Conceptual Structures - ICCS, pages 46–61,
Stanford, CA US.
Xu, Y., Li, Z., Gupta, A., Bugdayci, A., and Bhasin, A.
(2014a). Modeling professional similarity by min-
ing professional career trajectories. In Proceedings of
the 20th ACM SIGKDD international conference on
Knowledge discovery and data mining, pages 1945–
1954. ACM.
Xu, Y., Li, Z., Gupta, A., Bugdayci, A., and Bhasin, A.
(2014b). Modeling professional similarity by min-
ing professional career trajectories. In Proceedings of
the 20th ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining, pages 1945–
1954. ACM.
ICEIS 2017 - 19th International Conference on Enterprise Information Systems
134
