
Personalized, Affect and Performance-driven Computer-based Learning
Christos Athanasiadis, Enrique Hortal, Dimitrios Koutsoukos,
Carmen Zarco Lens and Stylianos Asteriadis
Department of Data Science and Knowledge Engineering, Maastricht University, St. Servaasklooster 39, 6211 TE
Maastricht, Netherlands
Keywords:
Computer-based Education, E-learning, Personalization, Collaborative Filtering, Association Rules, Recom-
mendation Systems.
Abstract:
The growing prevalence of Internet during the last decades has made e-learning systems and Computer-based
Education (CBE) widely accessible to a great amount of people with different backgrounds and competences.
Due to these rapid advances in computer technologies, there has been a great shift from conventional, low in-
teraction and printed learning content to high-level, computerized interactions for Computer-based Education.
The above has led to the need for personalized systems, able to adapt their content for a variety of learner’s
abilities and skills. A key factor in content personalization is the degree to which the material itself keeps
learners engaged over the course of the interaction: a CBE system has to cater for enough flexibility and be
endowed with the ability to infer the degree to which the learner is engaged in the interaction and also be in
the position to take decisions regarding the triggering of those adaptation mechanics that will keep the learner
in a state of high engagement, maximizing, thus, the knowledge acquisition. A straightforward approach in
content adaptation is the monitoring of levels of engagement, frustration and boredom in a learner and the
subsequent adaptation of challenge levels imposed by the learning material. In this paper, we investigate the
use of Collaborative Filtering, in order to build a content adaptation mechanism, based on recommendations
on learner affect states. We showcase results on an interface developed specifically for the purposes of this
research. The system’s objective is to offer optimized sessions to the learners and improve their knowledge
acquisition during the interaction with the system.
1 INTRODUCTION
The increasing popularity of technology and the
amount of available resources on the Web, especially
for Computer-based Education (e-learning systems,
serious games, on-line courses) has made imperative
the use of personalized systems that will be able to
adjust their content to cover a wide range of needs in
education. In order to handle the needs of all pos-
sible learners, Collaborative Filtering (CF) and rec-
ommendation systems are scientific domains with a
great potential to be applied in order to generate ro-
bust and efficient adaptive systems. In this paper, a
novel, Computer-based Education recommender sys-
tem is proposed, with final scope to take advantage of
learner cognitive and affective states and, thus, opti-
mize and personalize the delivery of content. Further-
more, a serious game called “Learnin’ platform” was
created for the purposes of this research, as a testbed
platform, in order to perform the evaluation of our
concept.
Every time new learners are interacting with the
“Learnin’ platform”, the game engine, ideally, should
re-direct them to the level of difficulty in which the
learners will be more engaged and help them remain
to their state of flow. The term flow was introduced
in (Csikszentmihalyi, 1975), (Nakamura and Csik-
szentmihalyi, 2014), (Csikszentmihalyi, 1996). It was
used to describe the positive feelings and the enjoy-
able experiences of individuals during the execution
of a task. By definition, flow is the psychological
state in which an individual experiences motivation,
efficiency and happiness. A system that motivates
students to continue and enjoy the learning process
is a critical point in Computer-based Education and
it is the case study of this paper. The learning ex-
perience can be represented by two dimensions, the
skill of the learners and the challenge presented to
them. Achieving a balance between these two pa-
rameters, a positive effect on the educational process
132
Athanasiadis, C., Hortal, E., Koutsoukos, D., Lens, C. and Asteriadis, S.
Personalized, Affect and Performance-driven Computer-based Lear ning.
DOI: 10.5220/0006331201320139
In Proceedings of the 9th International Conference on Computer Supported Education (CSEDU 2017) - Volume 1, pages 132-139
ISBN: 978-989-758-239-4
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
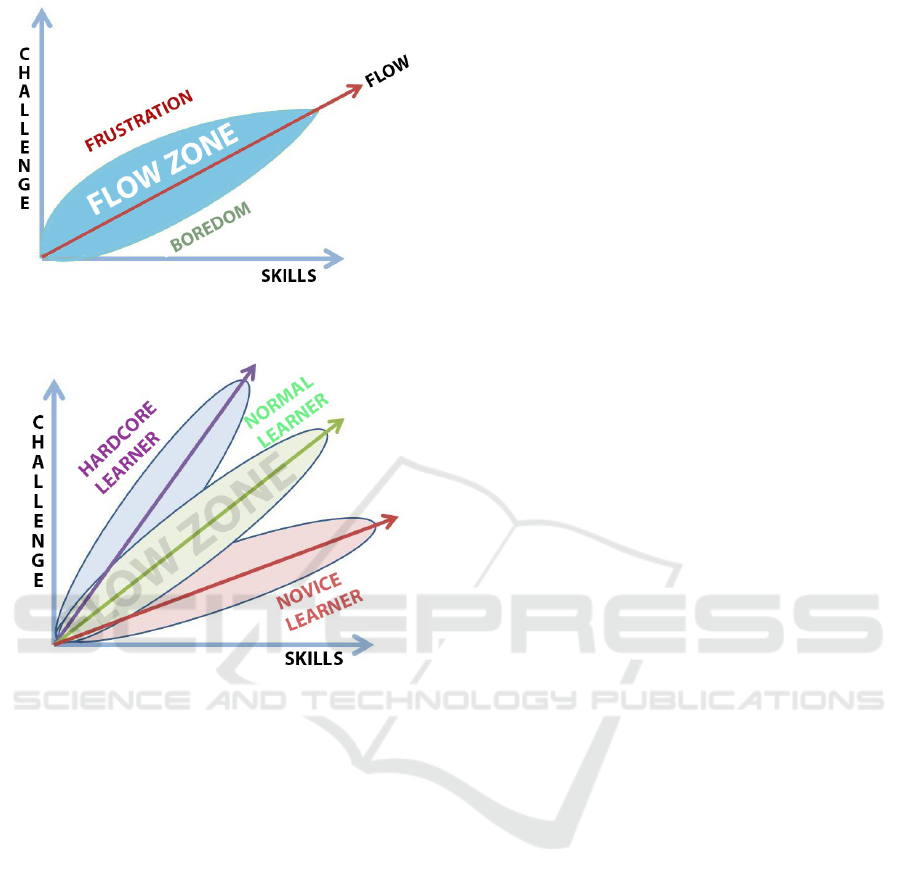
Figure 1: 2D flow zone model with platform competence
and learner skills.
Figure 2: Different flow zones for different learners.
can be provoked, allowing a higher engagement in
the learning activity and improving concentration, in-
volvement and happiness of the learners. The incor-
rect selection of learning content could provoke frus-
tration or boredom, depending on whether the chal-
lenge presented is too high or too low respectively.
These two important variables are examined in this
study. Fig. 1 depicts the correlation of learner skills
and platform challenge. Different learners have dif-
ferent learning flow zones and the system has to de-
tect those different zones and to recommend different
learning content accordingly. Fig. 2 illustrates the
flow zone for different learners.
The contribution of this paper is two-fold: firstly,
we propose the adoption of learners’ affective states
as the explicit voting for the recommendation systems
and, secondly, a novel database is introduced, in order
to evaluate the proposed technique. The implemented
CF will propose to new learners levels of difficulty
which will keep them in their flow zone.
The structure of the remainder of this paper is
as follows: In Section 2, the related work for CBE,
recommendation systems and flow theory in educa-
tion is presented. Section 3 describes the collabora-
tive filtering algorithm used for evaluating upon the
database and creating the personalization system for
the “Learnin’ platform” and the baseline algorithms
used for evaluation as well. Section 4 describes the
“Learnin’ platform” which was used as a testbed plat-
form for evaluating the proposed algorithm and for
creating our database while in Section 5 the database
architecture is described. In Section 6, experimental
results from the proposed algorithm are shown. Fi-
nally, Section 7 contains the conclusion of this study.
2 RELATED WORK
Our work relates to several areas of research such as
personalization in Computer-based Education (Mil-
icevic et al., 2011), recommendation systems (Y. Ko-
ren and Volinsky, 2009), (Sun et al., 2014) and theory
of flow (Liao, 2006). Several approaches within the
Computer-based Education community implemented
recommendations systems algorithms such as collab-
orative filtering (Y. Koren and Volinsky, 2009) with
goal to personalize systems to a plethora of individ-
ual needs and skills.
Recommender systems (RSs) play an increasingly
important role in our daily lives. They use prefer-
ences of a large bank of users to help individuals
identify content of interest, from a great plethora of
choices more effectively. RSs’ goal is to automati-
cally propose to a user items that might be of interest
to him/her. They have been successfully applied on
Computer-based Education for recommending which
learning content is sufficient for learners to study next
and contribute to learners progress towards particu-
lar goals (Milicevic et al., 2011), (Segal et al., 2014),
(Bachari et al., 2011).
Collaborative Filtering was previously used in the
educational domain for personalizing learner profiles
(Bobadilla et al., 2009). CF can be defined as follow-
ing: Given a matrix R that represents a known set of
M learners (users) preferences to N items (e-learning
content), recommend to each user a list of items that
are ranked in a descending order of relevance to the
users interest. Up to our knowledge, this is the first
time that the combination of CF algorithms and af-
fective states as explicit preferences is implemented.
A lot of works can be found in the literature con-
sidering recommender systems and collaborative fil-
tering. Among them, probably the most popular, is
the work done by Koren et al (Y. Koren and Volin-
sky, 2009). In this work, the implementation of Sin-
gular Value Decomposition (SVD)-based Matrix Fac-
torization (MF) in order to create a recommender sys-
Personalized, Affect and Performance-driven Computer-based Learning
133

tem using Netflix database. MF algorithm decom-
poses the rating matrix into user and item latent matri-
ces. The re-decomposed matrix can be used for find-
ing the votes for the unknown items for every user.
Cross-validation methodology was applied, for tun-
ing λ, which is a parameter used during the MF op-
timization and helps the system avoiding over-fitting.
Furthermore, authors tried to address items and user
progress over time by making use of temporal dynam-
ics and applying user and item biases deviations to the
re-decomposition of the rating matrix. The proposed
system won the 2007 and 2008 Progress Prize of Net-
flix challenge.
In (Salakhutdinov and Mnih, 2011), authors pro-
posed a probabilistic matrix factorization (PMF), for
decomposing the rating matrix of users-items using
the Neflix database. A probabilistic way to tune the
regularization parameter λ for the matrix decomposi-
tion was proposed. Finally, they combined the PMF
model with Restricted Boltzmann Machines models
in order to improve the performance of the system.
Their approach was proved to perform well on very
sparse and imbalanced datasets and in handling the
over-fitting problem of the optimization as well.
In (Milicevic et al., 2011), authors proposed a pro-
gramming tutoring system called “Protus”, developed
for teaching Java programming language. The main
scope of “Protus” is to recommend the best possible
material for the e-learners based on their background
and skills. The proposed system consists of three ba-
sic modules. When learners were registered to the
system, a short survey was performed with aim to re-
flect their preferred learning style. Then, a cluster-
ing technique is applied in order to create clusters of
learners based on their learning style. Finally Aprio-
riAll algorithm (Tong and Pi-lian, 2007) was used to
find frequent sequences of learning materials patterns
in each learning style and make the recommendation
accordingly. These generate recommendations based
on the collaborative filtering approach.
In (Segal et al., 2014), authors proposed “Edu-
Rank”, a system for personalizing educational con-
tent for learners, which combines collaborative filter-
ing and social choice theory. The algorithm constructs
a difficulty ranking over questions and aggregates the
ranking of similar students, as measured by different
aspects of their performance on past questions such
as grades, number of retries and time spent solving
questions. Thus, the first step of the algorithm is to
estimate the similarity of learners and then, combine
the rankings of the similar users to propose it to the
target user.
In (Bachari et al., 2011), authors presented three
main models to achieve the goal of personalization,
which are domain model, tutor model, and student
model. The domain model contains the knowledge
about the learning content structure such as chapters
and topics of different subjects while student model
holds the learners characteristic including their pref-
erences, identity. These can be used to adapt the con-
tent and teaching styles. This research has added
tutor model to enhance the personalization system
from the previous research. The tutor model repre-
sents the teacher’s knowledge for teaching each con-
cept. The decision and identification model used in
this work was based on Dynamic Bayesian Network
(DBN). DBNs were used with a goal to introduce to
the learner the contents and materials of interested in
according to the score obtained by the learner using
the Myers-Briggs Type Indicator (MBTI) test.
In (Bergner et al., 2012), authors proposed a
model-based estimator of accuracy levels of learn-
ers performance and skill levels on real and simu-
lated datasets. Furthermore, they established a rela-
tionship between collaborative filtering and Item Re-
sponse Theory methods and demonstrated this rela-
tionship empirically.
In (Toscher and Jahrer, 2009), authors make use of
KDD Cup 2010, an educational database (J.Stamper
et al., 2010) which contains questions from algebra
topic in several steps and difficulty and the learner
performance as well (answer, time spent etc.). Au-
thors implemented several methods to model the
database. Firstly, they applied K-Nearest Neigh-
bors in order to find the most similar users. Au-
thors also implemented Singular Value Decomposi-
tion (SVD) in order to decompose the matrix of users
and questions-steps using stochastic gradient descent.
Authors found out that SVD does not work well with
sparse data so they proposed an enhanced algorithm,
called Factor Model (FM) in which they add bias
models (as in (Y. Koren and Volinsky, 2009)) in the
re-decomposition of the user-steps matrix. Finally, a
Neural Network architecture called Restricted Boltz-
mann Machines was applied to ensemble the men-
tioned models.
In (Liao, 2006), a study of flow theory in human
computer interaction was performed. This study con-
sists of two main models: Firstly, an empirical inves-
tigation of the theoretical construct of flow theory in
Computer-based Education which tried to identify the
main components of flow during the learning process
and, secondly, a study of the impact of interaction be-
tween three different categories of flow. Those cate-
gories were: learner to instructor interactions, learner-
learner interactions and finally learner-interface inter-
actions.
CSEDU 2017 - 9th International Conference on Computer Supported Education
134

3 RECOMMENDATION
SYSTEMS
The novelty of the proposed research is mainly due
to the adoption of learners’ affective states as explicit
preferences for the recommendation systems and col-
laborative filtering. In order to consider the affective
state of the user in the approach presented in that
work, a relevant parameter has been defined. This
parameter merges the values derived from the the-
ory of flow (Liao, 2006) (namely, boredom, frustra-
tion and engagement) in a single value, formalized by
a so called energy function. This function is based
on an assumption that learners are remained in their
flow state when they are more engaged while bore-
dom and frustration adversely affect it (Csikszentmi-
halyi, 1991), which is also depicted in Figure 1. When
learners are in flow zone, psychic entropies like frus-
tration and boredom are not occur while engagement
is maximized. Thereby, the introduced energy func-
tion concatenates the three affective states into one
value. Thus, the following formula was applied us-
ing the learner annotations in order to concatenate the
affective states:
f
i
(l) = C + α × E
i
(l) + β × B
i
(l) + γ × F
i
(l) (1)
Where l corresponds to the learning session, i is
learner’s unique id and E, B, F the affective state
levels (Engagement, Boredom, Frustration) and they
take values from 0-5, while parameters α, β, γ are
tuned to α = 1, β = −1, γ = −1. The static term C
was introduced in order to keep the energy function
positive. A default value was set to C = 10. This
was done due to the implementation of Non Negative
Matrix Factorization. The scope of this study is to re-
direct learners to levels of difficulty in which their en-
ergy function will be maximized. In order to achieve
so, Non-Negative Matrix Factorization is applied with
scope to optimize the energy function for each learner.
3.1 Non-Negative Matrix Factorization
As soon as the concatenation between the affective
states was performed, the personalization system was
ready to be trained using the database as is described
in Section 5. A separation of learning sessions among
the different subjects was applied. For each subject, a
2-dimensional matrix was constructed (with learners
as rows and levels of difficulty as columns, represent-
ing the challenge presented to the them). Each matrix
contained the energy function value for all learners as
explicit preference to 9 different levels of difficulty.
For every subject a matrix was constructed with size
31 × 9, where 31 is the total number of the learners
and 9 is the number of difficulty levels for every sub-
ject.
Subsequently, the next step was the implementa-
tion of the Matrix Factorization algorithm (Lee and
Seung, 2001) (Lee and Seung, 1999). MF is a linear
algebra algorithm which, given a matrix R of learners
voting preferences over a plethora of items, and a de-
sired rank k, its endeavor is to decompose the matrix
into W and H, so as the matrix A ≈ W H to be a good
approximation of matrix R. This matrix approxima-
tion A can be used in order to make recommendations
to the learner for the unknown items (levels of diffi-
culty) of the matrix. Factorization works based on the
following principle - that both the user and the items
from matrix R should be represented in the same way.
MF maps learners and items into a common space
“k”. The rank space “k” is also mentioned in the liter-
ature as latent factors. High correlation between item
and user latent factors can lead to a recommendation
for the learner. In this study we made use of Non-
Negative Matrix Factorization (NMF) method, which
is summarized below:
- Given a non negative matrix R, the goal of NMF
is to minimize ||R −W H||
2
with respect to W, H
with the constraint to be that W, H > 0 .
- NMF is a nonconvex problem.
- NMF is in fact a SVD based algorithm .
- For Non-negative Data, NMF provides better In-
terpretation of Lower Rank Approximation.
- The main difference with the SVD is that both W ,
H are mandatorily positive.
- SVD yields unique factors whereas NMF factors
are non-unique. This makes NMF more suitable
for privacy protection algorithms.
- The non-negativity rules of NMF algorithm
makes the resulting matrices easier to inspect.
Since the problem is not exactly solvable in gen-
eral, it is commonly approximated numerically.
For the sake of this proposed system, a python im-
plementation of Non-Negative Matrix Factorization
(NMF) was applied. The objective function of the
minimization problem that was implemented is the
following:
f = 0.5∗||R−W H||
2
F
+α∗λ∗||W ||
1
+α∗λ∗||H||
1
+0.5∗α∗(1−λ)∗||W ||
2
F
+0.5∗α∗(1−λ)∗||H||
2
F
(2)
where λ is parameter that helps avoid the over-
fitting, α a constant that multiplies the regularization
terms and F stands for Forbenius norm. Additional
Personalized, Affect and Performance-driven Computer-based Learning
135

info about the optimization equation can be found
here
1
.
In our system, matrix R contains the energy func-
tion values of the learners over the several difficulty
levels. The re-decomposed matrix A ≈ W H can con-
ceal hidden values of energy function values in un-
known levels of difficulty for learners in the database,
as well as, for new learners that will interact with our
“Learnin’ platform”. When a new learner enters into
the platform, and after every performed session, the
system’s target is: By making use of the provided an-
notation (for affective states) to estimate what the en-
ergy function values of the learner will be for the rest
of the difficulty levels. The NMF algorithm is im-
plemented using the database matrix, enlarged with
the addition of the new learner’s vector (contained the
energy function values gathered so far). The recom-
mendation for a new learner then can be formalized
as follows:
a
ik
= w
ik
∗ h
kr
(3)
where w
ir
are the latent factors of the learner and
h
rk
are the latent factors of the levels of difficulty. The
above formula approximates learner i energy function
value for the specific difficulty level r. In the end,
the system always re-directs the learner to that level
of difficulty k with the highest approximated energy
function.
4 “LEARNIN’ PLATFORM”
The testbed platform used in our study is a serious
game called “Learnin’ platform” developed specifi-
cally for the purposes of this research from Maas-
tricht University. The original “Learnin’ platform” is
available on Github
2
. The platform consists of two
major functionalities: 1. The teacher account func-
tionality, with which tutor has the ability to add new
subjects and questions of varying types, levels of dif-
ficulty and also tune maximum available time for the
answer to be given by the student, 2. The student ac-
count functionality which performs the learning ses-
sions of “Learnin’ platform”. The learner entering
with student credentials can choose between 4 differ-
ent default subjects (“Math”, “Sports”, “Geography”,
“History”). For the purpose of data acquisition, every
time the learner is playing a specific subject, the level
of difficulty is changing randomly. The levels of diffi-
culty are in total 9 (from 1-9). Throughout the learn-
ing session, the learner is informed about the current
1
http://scikit-learn.org/stable/modules/generated/
sklearn.decomposition.NMF.html
2
https://github.com/kristosh/Mathisis-platform
level, the current score and the time left for answer-
ing the question. A detailed description of the testbed
platform interfaces is the following:
- An introduction interface, where the two differ-
ent accounts (teacher and student) are presented
in two different buttons, (Fig. 3).
- When the learner presses the student scene button,
the Log in/Sign up interface is presented.
- Students add their information (demographics) in
sign up scene in order to be able to login.
- Subsequently, students are directed to subject in-
terface where they can choose a subject among
4 different courses (“Math”, “History”, “Sports”,
“Geography”) and then they can start a new game.
- Then, the learning session begins and the learners
have to answer 7 different questions (Fig. 4).
- During the learning session, questions, the possi-
ble answers and a status bar with information for
the learning session is rendered to the learner.
- During the learning sessions, different sounds and
emoticons are used with scope to provoke and
boost learners reactions.
- After each session, learners were asked to anno-
tate their affective states, levels of engagement,
boredom and frustration in scale of 0-5.
- The next scene is the result panel interface, which
informs learners about their performance during
the session.
- Finally, learner has the choice to either logout or
continue with a new session. In the latter case,
learner has to choose a subject and to start the new
session.
- Teacher interfaces are not presented since this is
out of the scope of this study.
The core idea of this paper is to introduce a per-
sonalization mechanism that will change the diffi-
culty levels of the system automatically based on the
flow of the learner that interacts with the platform.
Thereby, “Learnin’ platform” was developed firstly
for the data gathering process, and secondly for the
implementation of our personalization mechanism. In
the following section the data architecture used for
training our algorithm is presented.
5 DATASET ARCHITECURE
The dataset consists of students from Maastricht
University, Netherlands, who voluntarily played our
“Learnin’ platform”. They were bachelor and master
CSEDU 2017 - 9th International Conference on Computer Supported Education
136
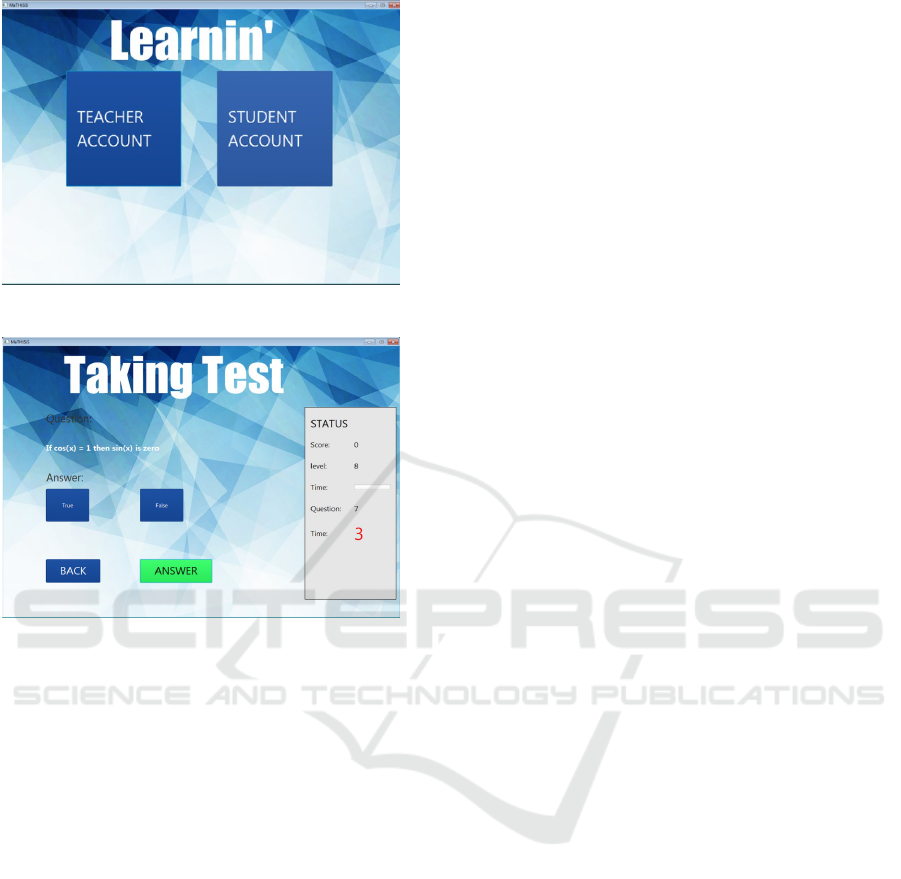
Figure 3: Learnin’ lntroduction interface.
Figure 4: Learnin’ learning session interface.
students 21±7 years old with technical background.
For every student, 4 learning sessions of 4 different
courses were captured. After each learning session,
users were asked to assess the degree of engagement,
frustration and boredom they experienced. The as-
sessments were given in the form of ratings from 0
to 5. The analysis presented in this paper is based on
31 users (19 males and 12 females) playing 16 learn-
ing sessions from our “Learnin’ platform”. The light-
ing conditions during the capturing procedure were
typical for an office environment and a Logitech HD
720p camera was used. The visual feedback of the
learners captured for future work and further analysis
of learners affective states. The database protocol for
gathering the data was inspired from the works done
in (Yannakakis et al., 2009) (Shaker et al., 2011).
- Firstly, a small oral introduction to the partici-
pants was performed with some information about
the procedure that would be followed.
- Participants were told that during the experiment
they will have to play 16 learning sessions in total.
- The duration for the whole experiment per each
participant was 26±5 minutes.
- Due to time limitations, students were asked to
play just 4 sessions per subject.
- The system automatically changed the difficulty
levels based on the performance of the learners.
- In order to acquire data from different levels of
difficulty, the approach applied is based on the
score obtained in the previous session. Initially,
the first level is chosen randomly between levels 1
to 3. Afterwards, the increase of the level is based
on the score obtained by the user. In this way, the
user is asked to answer questions related to levels
4 or 5, 6 or 7 and 8 or 9, depending on whether
the learner passed or failed the previous test.
The “Learnin’ platform” consists of two SQLITE
databases. Firstly, a database which contains all the
questions of the platform and secondly a database
which contains all the information about the learners
during the learning sessions.
6 EXPERIMENTAL RESULTS
This section discusses the findings which emerged
from the evaluation of the algorithm, described in sec-
tion 3. The core experiment setup of this work, is
the following: 31-fold cross validation was performed
for each of the 4 datasets for the different subjects.
Cross-validation randomly splits the dataset 31 times
into two sets: the training set and the evaluation set
(30 samples for training and 1 sample for testing).
In the evaluating sample, randomly, an energy func-
tion value was deliberately removed and the evalua-
tion scope’s was to estimate this missing value. Table
1 and as well as, Figs. 5, 6, 7, 8 render the root mean
square error between the initial value we removed
from evaluating set for all subjects and the approxi-
mation value introduced from NMF algorithm (for all
subjects) for several values of rank k after cross vali-
dation. An exhaustive search was performed in order
to calculate the best parameters of NMF. In Table 2,
the chosen parameters for NMF are illustrated.
Experimental results for NMF algorithm, con-
cealed a promising approximation of the hidden en-
ergy function values during the cross-validation pro-
cess. Thereby, a striking observation which emerged
from the research done in this work was that Non-
Negative Matrix Factorization could be successfully
applied as a recommendation system in our “Learnin’
platform” (and therefore in Computer-based Educa-
tion systems) efficiently estimating the energy func-
tion values of the learners affective states. Further-
more, the whole procedure of NMF energy value es-
timator could lead to optimized selection of levels of
difficulty based solely on affective state knowledge.
Personalized, Affect and Performance-driven Computer-based Learning
137
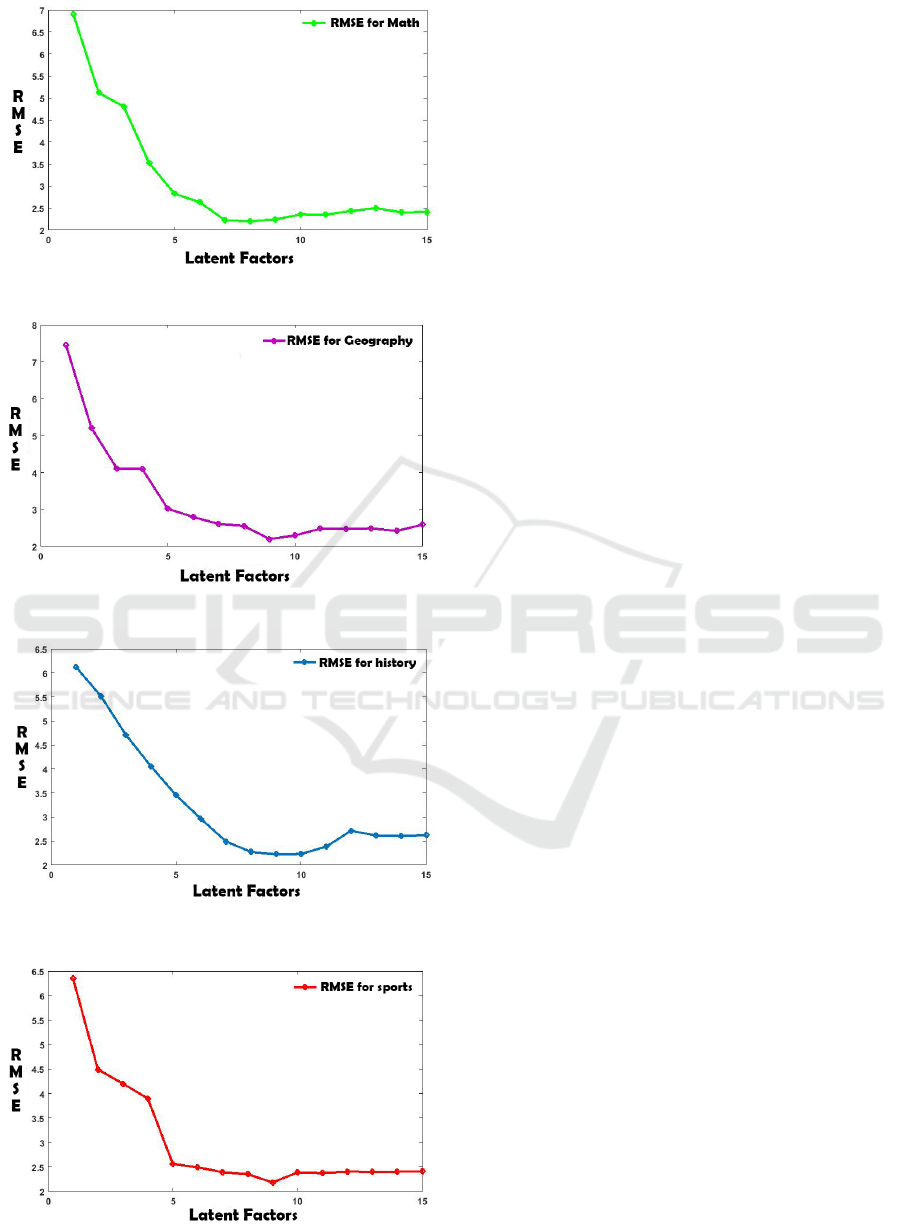
Figure 5: Root mean square error for the subject Math.
Figure 6: Root mean square error for the subject Geography.
Figure 7: Root mean square error for the subject History.
Figure 8: Root mean square error for the subject Sports.
7 CONCLUSIONS & FUTURE
WORK
The presented study introduced several noteworthy
contributions to the domains of recommendations sys-
tems in education. Firstly, up to our knowledge, this
was the first study performed on learners affective
states and Non-Negative Matrix Factorization during
the interaction with Computer-based Education. We
made use of learner affective states as the user explicit
preferences over a set of learning content. A Collabo-
rative Filtering algorithm called Non-Negative Matrix
Factorization was implemented in order to develop
our system by taking advantage of learners affec-
tive states when interacting with the system’s learn-
ing content. Secondly, a novel database for evalua-
tion of the applied technique was introduced. The re-
sults of this study show that NMF algorithm could
be successfully applied to the constructed database
with scope to generate a robust and efficient person-
alised Computer-based Education system. Further-
more, the novel serious game that used for gather-
ing the database is presented. The outcome of this
study also introduced a link between theory of flow
and recommendation systems and it will serve as a
base for future studies about the relationship of com-
puter vision-based affective states of a learner and
the calculated learners’ latent factors from decompo-
sition algorithms. The proposed NMF algorithm, can
substitute the current platform’s functionality for the
difficulty-level shift after each learning session. Fi-
nally, future work will be focus on enhancement of
the affective states annotation by incorporating key
moments detection and annotate those moments auto-
matically with an emotion recognition module which
could make use of Deep learning architectures.
ACKNOWLEDGMENT
This work was supported by the Horizon 2020 funded
project MaTHiSiS (Managing Affective-learning
THrough Intelligent atoms and Smart InteractionS)
nr. 687772 (http://www.mathisis-project.eu/).
CSEDU 2017 - 9th International Conference on Computer Supported Education
138

Table 1: RMSE for NMF, after cross-validation.
Subject k=3 k=5 k=7 k=9 k=11 k=13 k=15
History 4.708 3.454 2.489 2.223 2.380 2.615 2.622
Sports 4.203 2.563 2.392 2.184 2.374 2.399 2.408
Math 4.803 2.830 2.227 2.243 2.352 2.497 2.412
Geography 4.112 3.022 2.611 2.201 2.481 2.489 2.588
Table 2: Chosen parameters for NMF.
alpha 0,1
l1 ratio 0,6.
solver cd
random state 0
REFERENCES
Bachari, E., Abelwahed, H., and Adnani, M. (2011). E-
learning personalization based on dynamic learners
preference.
Bergner, Y., Droschler, S., Kortemeyer, G., Rayyan, S.,
Seaton, D., and Protchard, D. (2012). Model-based
collaborative filtering analysis of student response
data:Machien learning item response theory. EDM,
pages 95-102.
Bobadilla, J., Serradilla, F., and Hernando, A. (2009). Col-
laborative filtering adapted to recommender systems
of e-learning. Know.-Based Syst., 22(4):261–265.
Csikszentmihalyi, M. (1975). Beyond Boredom and Anx-
iety. The Jossey-Bass behavioral science series.
Jossey-Bass Publishers.
Csikszentmihalyi, M. (1991). Flow: The Psychology of Op-
timal Experience. Harper Perennial, New York, NY.
Csikszentmihalyi, M. (1996). Creativity: Flow and the Psy-
chology of Discovery and Invention. Modern classics.
HarperCollinsPublishers.
J.Stamper, Niculescu-Mizil, A., Ritter, S., Gor-
don, G., and Koedinger, K. R. (2010). Data
set from KDD Cup 2010 Educational Data
Mining Challenge. EDM, pages 95-102,
http://pslcdatashop.web.cmu.edu/KDDCup/downloads.jsp.
Lee, D. and Seung, H. S. (1999). Learning the parts of
objects by nonnegative matrix factorization. Nature,
401:788–791.
Lee, D. and Seung, H. S. (2001). Algorithms for non-
negative matrix factorization. In Leen, T. K., Diet-
terich, T. G., and Tresp, V., editors, Advances in Neu-
ral Information Processing Systems 13, pages 556–
562. MIT Press.
Liao, L. F. (2006). A flow theory perspective on learner mo-
tivation and behavior in distance education. Distance
Education, 27(1):45–62.
Milicevic, A. K., Vesin, B., Ivanovi, M., and Budimac, Z.
(2011). E-learning personalization based on hybrid
recommendation strategy and learning style identifi-
cation. Computers and Education, 56(3):885 – 899.
Nakamura, J. and Csikszentmihalyi, M. (2014). The Con-
cept of Flow, pages 239–263. Springer Netherlands,
Dordrecht.
Salakhutdinov, R. and Mnih, A. (2011). Probabilistic Ma-
trix Factorization.
Segal, A., Katzir, Z., Y. Gal, G. S., and Shapira, B. (2014).
Edurank: A collaborative filtering approach to person-
alization in e-learning.
Shaker, N., Asteriadis, S., Yannakakis, G., and Karpouzis,
K. (2011). A Game-Based Corpus for Analysing the
Interplay between Game Context and Player Expe-
rience, pages 547–556. Springer Berlin Heidelberg,
Berlin, Heidelberg.
Sun, J. Z., Parthasarathy, D., and Varshney, K. R. (2014).
Collaborative kalman filtering for dynamic matrix fac-
torization. IEEE Transactions on Signal Processing,
62(14):3499–3509.
Tong, W. and Pi-lian, H. (2007). Web log mining by an im-
proved aprioriall algorithm. International Journal of
Computer, Electrical, Automation, Control and Infor-
mation Engineering, 1(4):1046 – 1049.
Toscher, A. and Jahrer, M. (2009). Collaborative Filtering
Applied to Educational Data Mining. Journal of Ma-
chine Learning.
Y. Koren, R. B. and Volinsky, C. (2009). Matrix factoriza-
tion techniques for recommender systems. Computer,
42(8):30–37.
Yannakakis, G. N., Maragoudakis, M., and Hallam, J.
(2009). Preference learning for cognitive modeling: A
case study on entertainment preferences. IEEE Trans-
actions on Systems, Man, and Cybernetics - Part A:
Systems and Humans, 39(6):1165–1175.
Personalized, Affect and Performance-driven Computer-based Learning
139
