
Speaker State Recognition: Feature Selection Method based on
Self-adjusting Multi-criteria Evolutionary Algorithms
Roman Sergienko
1
and Elena Loseva
2
1
Institute of Communications Engineering, Ulm University, Albert-Einstein-Allee 43, Ulm, Germany
2
Department of System Analysis and Operation Research, Siberian State Aerospace University, Krasnoyaskiy Rabochiy
Avenue 31, Krasnoyarsk, Russian Federation
Keywords: Emotion Recognition, Gender Identification, Neural Network, Multi-criteria Genetic Programming, Feature
Selection, Speech Analysis.
Abstract: In supervised learning scenarios there are different existing methods for solving a task of feature selection
for automatic speaker state analysis; many of them achieved reasonable results. Feature selection in
unsupervised learning scenarios is a more complicated problem, due to the absence of class labels that
would guide the search for relevant information. Supervised feature selection methods are “wrapper”
techniques that require a learning algorithm to evaluate the candidate feature subsets; unsupervised feature
selection methods are “filters” which are independent of any learning algorithm. However, they are usually
performed separately from each other. In this paper, we propose a method which can be performed in
supervised and unsupervised forms simultaneously based on multi-criteria evolutionary procedure which
consists of two stages: self-adjusting multi-criteria genetic algorithm and self-adjusting multi-criteria
genetic programming. The proposed approach was compared with different methods for feature selection on
four audio corpora for speaker emotion recognition and for speaker gender identification. The obtained
results showed that the developed technique provides to increase emotion recognition performance by up to
46.5% and by up to 20.5% for the gender identification task in terms of accuracy.
1 INTRODUCTION
Speaker state analysis problems such as speaker
emotion recognition and speaker gender
identification are complicated and challenged
classification problems due to the high
dimensionality. For solving such classification
problems it is necessary to perform determination of
irrelevant features (attributes) in data sets (feature
selection). All data may have consequences of
effects such as noise (natural factor), voice distortion
(human factor); the attributes may have a low level
of variation, correlate with each other that leads to a
deterioration of the classification performance. If
standard techniques of feature selection do not
demonstrate sufficient effectiveness, an alternative
way is an application of the methods based on
evolutionary techniques that are effective for high-
dimensional and poorly structured problems.
The proposed approach for feature selection
includes two stages with two evolutionary
algorithms: modified genetic algorithm and genetic
programming. First stage is the pre-processing
procedure with modified genetic algorithm (Pre-
processing with Sorting - PS) using multi-criteria
optimization as an unsupervised feature selection
algorithm and the second stage is the multi-criteria
genetic programming (MCGP) with an artificial
neural network (ANN) as a supervised feature
selection algorithm, where structure of ANN models
by genetic programming (GP) procedure are created.
The optimization of the ANN structure with
choosing optimal amount of neurons and layers was
proposed in (Loseva, 2015a). In fact, the efficiency
of GP applications depends on its parameters and
setting reasonable parameters requires the expert
knowledge. Therefore, we also proposed a new self-
adjusting procedure, which allows choosing the
optimal combination of evolutionary operators (EO)
automatically. This self-adjusting procedure is a
modification of the existing self-tuning and self-
configuring evolutionary approaches that are
presented in (Sergienko and Semenkin, 2010;
Semenkin and Semenkina, 2012).
Sergienko, R. and Loseva, E.
Speaker State Recognition: Feature Selection Method based on Self-adjusting Multi-criteria Evolutionary Algorithms.
DOI: 10.5220/0005946801230129
In Proceedings of the 13th International Conference on Informatics in Control, Automation and Robotics (ICINCO 2016) - Volume 1, pages 123-129
ISBN: 978-989-758-198-4
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
123

We investigate the efficiency of the proposed
algorithmic schemes on the sets of acoustical data
for speaker state recognition problems (emotion
recognition and gender identification) which reflect
one of the main questions in the area of human-
machine communications. It turns out that by using
the proposed evolutionary technique we could
significantly improve efficiency of the recognition
tasks.
This paper is organized as follows: related done
works are listed in Section 2. Section 3 describes the
proposed approach for feature selection using multi-
criteria evolutionary algorithms (GA, GP) with six
criteria of efficiency. In Section 4 all used databases
are described. All experiments in this work on the
comparative analysis of the novel hybrid method and
other methods for feature selection are presented in
Section 5. Conclusions and directions for future
work are presented in Section 6.
2 SIGNIFICANT RELATED
WORK
Various classifiers (support vector machine, linear
discriminant analysis, naive Bayes, decision tree,
multi-layer perceptron) for speaker state recognition
problems were compared in (Loseva, 2014) on
Berlin, UUDB, LEGO databases of emotional
speech (see Section 4). These results showed the
highest value (maximum) of precision using ANN
classifiers and one-criterion genetic algorithm
(OGA) for feature selection (Loseva, 2014). Also the
results of emotion recognition with feature selection
have been presented in (Sidorov et al., 2014). The
authors have achieved the high value of precision on
the databases Berlin, UUDB, LEGO with different
methods of feature selection such as: one-criterion
Genetic Algorithm (OGA) (Holland, 1975),
Principal Component Analysis (PCA) (Akthar and
Hahne, 2012), Information Gain Ratio (IGR) as it
was done in (Polzehl et al., 2011) and SPEA (Zitzler
and Thiele, 1999) using Multi-layer Perceptron
(MLP) as a classifier. In this research the authors
noted that the reduced with the SPEA method
feature set was a twice less than the original
dimensionality.
3 HYBRID ALGORITHM FOR
FEATURE SELECTION
3.1 Self-adjusting Multi-criteria
Modified Genetic Algorithm
In (Holland, 1975) basic algorithmic scheme of GA
is presented. The first stage of PS method is a
preprocessing of initial feature set from the database.
Selection on the first stage is based on estimating
statistical metrics such as Variation level, Distance
between clusters (Venkatadri and Srinivasa, 2010),
Laplacian Score (He et al., 2005), which
characterize the data set quality by its power of
locality preserving. The fitness functions are
follows:
The first fitness function - Variation level:
,
1
1
2
1
r
r
FitGA
(1)
where
2
r
- dispersion value of r - th feature.
The second fitness function - Laplacian
Score: Let L
r
denote the Laplacian Score of the r-th
feature. Let f
ri
denote the i-th sample of the r-th
feature, i=1,…,m. Laplacian Score calculates as
follows:
1. Construct a nearest neighbor graph G with m
nodes. The i-th node corresponds to x
i
. Put an edge
between nodes i and j if x
i
and x
j
are “close”, i.e. x
i
is
among k nearest neighbors of x
j
, or x
j
is among k
nearest neighbors of x
i
. When the label information
is available, one can put an edge between two nodes
sharing the same label.
2. If nodes i and j are connected, put:
,
,0
,
||||
otherweise
jie
S
t
xx
ij
ji
(2)
where t is a suitable constant. The weight matrix S of
the graph models is the local structure of the data
space.
3. For the r-th feature, we define:
,],...,,,[
321
T
rmrrrr
fffff
),1( SdiagD
,]1,...,1[1
T
,SDL
(3)
where the matrix L is often called graph Laplacian
(Fan and Chung., 1992). Recall that given a data set,
we construct a weighted graph G with edges
connecting nearby points to each other. S
ij
evaluates
the similarity between the i-th and j-th nodes. Thus,
the importance of a feature can be thought of as the
ICINCO 2016 - 13th International Conference on Informatics in Control, Automation and Robotics
124
degree it respects the graph structure. To be specific,
a “good” feature should the one on which two data
points are close to each other if and only if there is
an edge between these two points.
Laplacian Score calculates by formula (4):
,
)(
)(
2
r
ij
ijrjri
r
fVar
Sff
L
(4)
where Var(f
r
) is the estimated variance of the r-th
feature.
Therefore, the second fitness function r-th
feature by formula (5) is calculated:
,
2
rr
LFitGA
(5)
Third fitness function - Distance between
clusters (DC):
,
||||
1
||||
1k
21
1k1
2
3
K
kk
K
X
p
k
kk
p
r
xx
K
X
xx
FitGA
k
(6)
where
k
g
x
is g-th object for k-th class, x
k
is the
central object, X
k
- amount of object k-th class,
K
-
amount of classes.
As a feature selection technique on this stage we
use a multi-criteria modified genetic algorithm
operating with binary strings, where unit and zero
correspond to a relative attribute and an irrelative
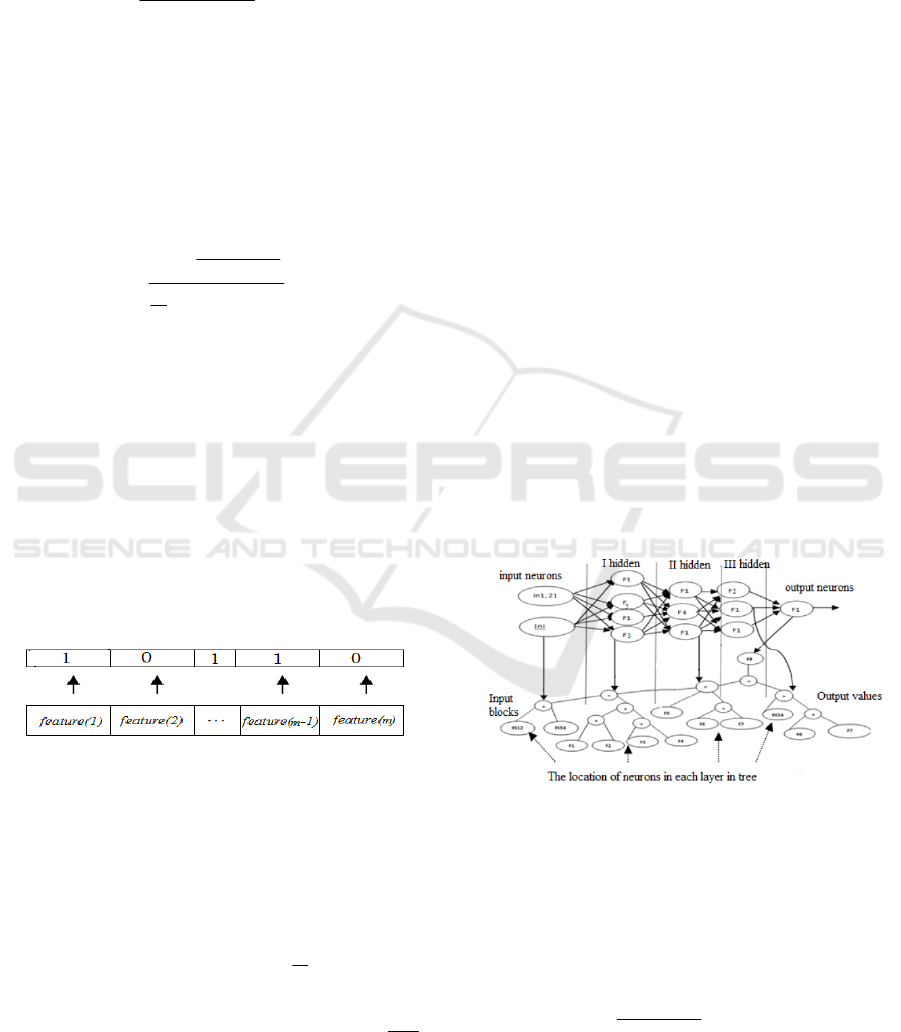
one respectively. Each feature is the individual from
initial population (initial feature set), which is sorted
by the PS procedure after estimation as "1" -
effective, "0" - not effective, as it in Figure 1 is
presented.
Figure 1: The representation of the determination
effectiveness of features in population by PS procedure.
The PS procedure works as follows:
1. Estimate criteria values for all individuals
from the current population.
2. To calculate average value of efficiency
each feature from initial feature set by formula (7):
, ;
11
R
A
FValueFitA
R
r
F
f
f
r
(7)
where
K
- amount of classes, R- amount of features,
r
f
Fit
- fitness function of
r
- th feature,
Ff ,1
,
F
-amount of fitness function.
3. To sort features as "0" - not effective, if
A>Value, and "1" - effective, if A<=Value.
4. To select features with rang "1" to
intermediate population (set).
3.2 Self-adjusting Multi-criteria
Genetic Programming
In the second stage, the MCGP algorithm using self-
adjusting technique is applied. The selected on the
first stage feature subset is the total feature set for
selection procedure on this stage. After working
MCGP the found by the algorithm features are the
final subset of features.
In (Koza, 1992) the basic scheme of genetic
programming is presented. In the MCGP method
the ANN classifiers is used as a learning algorithm.
In our evolutionary procedure we use genetic
programming operating with trees (tree encoding).
The ANN model is encoded into the tree. A tree is a
directed graph consists of nodes and end vertex
(leaves). In nodes may stay one operator from the
multiplicity F {+, <} and there are objects from the
multiplicity T {IN
1
, IN
2
, IN
3
,..., IN
n
- input neurons
(feature subsets), F
1
, F
2
, F
3
, F
4
..., F
N
- activation
functions (neurons)} in the leaves. Each input
neuron corresponds to one feature. The operator "+"
from multiplicity F indicates formation all neurons
in one layer and the operator "<" indicates formation
all layers in ANN (Figure 2).
Figure 2: Schematic representation ANN in tree.
In this case we introduce the three-criteria model,
specifically, Pair correlation level, Complexity of
ANN structure and Classification accuracy are used
as optimized criteria:
The first fitness function: Pair correlation
level:
max,
measure1
1
1
FitGP
(8)
where "measure" is a maximum of pair correlation
values between input neurons in ANN:
Speaker State Recognition: Feature Selection Method based on Self-adjusting Multi-criteria Evolutionary Algorithms
125
),max(corr measure
t
(9)
where corr
t
is pair correlation value of two (x
t
,y
t
)
ANN input neurons,
T1,t
T - amount of all
possible pairs of ANN input neurons.
corr
t
by
formula (10) is calculated:
,
)()(
))((
22
M
i
tt
i
M
i
tt
i
M
i
tt
i
tt
i
t
yyxx
yyxx
corr
(10)
where M - amount of objects in x
t
.
The second fitness function: Classification
accuracy:
,
2
V
P
FitGP
(11)
where P is the amount of correctly classified objects;
V is the amount of classified objects.
The third fitness function: Complexity of
ANN structure:
,
1
1
11
3
L
i
Lii
lNNNNnFitGP
(12)
where n is the amount of input neurons; N
i
is the
amount of neurons in the i-th layer; i is the number
of hidden layers; L is the amount of hidden layers in
ANN; l is the amount of output neurons in ANN.
In evolutionary algorithms there are different
types of operators and necessary to do different
initial settings. To avoid choosing the algorithm
settings it is reasonable to apply the self-adjusting
procedure. The developed approach (MCGP) works
as follows:
Step 1. Initialization
Create a population of individuals. Each
individual is a tree as a representation of ANN.
Step 2. Weight factors optimization
Optimization of the neural network weighting
factors by OGA. The criterion for stopping the OGA
is the maximum value of classification accuracy.
Step 3. Choosing evolutionary operators
In this step all combinations of EO have equal
probabilities of being selected. In other step is
necessary to recalculate probability values for new
combinations of EO. All combinations with different
types of operators were formed: two types of
selection operators (tournament, proportion), two
types of mutation operators (strong, weak) and one
type for recombination (one-point) were used.
Step 4. Evaluation of criteria values
Estimate criteria values for all individuals from
the current population.
Step 5. Generation of new solutions
Selection two individuals for recombination
by VEGA (Vector Evaluated Genetic Algorithm)
method (Ashish and Satchidanada, 2004).
Recombination of two selected individuals
for creation a new descendant.
Mutation of a descendant.
Evaluation a new descendant.
Compilation new population (solutions) by
each created descendant.
Step 6. Resources reallocation
Choose a new combination of EO by
recalculation of the probability values. For
recalculation need to estimate the EO combination
effectiveness by formula (13) for each descendant,
which was created by this EO combination:
,
1
_
11
p
I
d
F
f
d
f
p
p
FitGP
I
OperFit
(13)
where Fit
d
f
is fitness f-th descendent by d-th
criterion; I
p
is amount of descendants which were
created by chosen variant of EO combination.
The number of added fitness functions may be
different; it depends on the algorithm. After
comparing values (Fit_Oper
p
), the variant of EO
with highest value calls a “priority” variant. A
combination of EO with the lowest probability value
changes on the “priority” variant. The recalculation
of probabilities is implemented for each iteration of
the algorithm. If all combinations on a "priority"
Figure 3: Schematic representation of the PS+MCGP
algorithm.
ICINCO 2016 - 13th International Conference on Informatics in Control, Automation and Robotics
126

option have been replaced, all probability values are
cleared. New variants of EO combination are
generated again.
Step 7. Stopping Criterion
Check the stop-criterion: if it is true, then
complete the working of MCGP and select the best
individual as a representation of ANN from
population, otherwise continue from the second step.
The chosen best ANN is the model with relevant set
of features, which equals to the set of input neurons
in ANN.
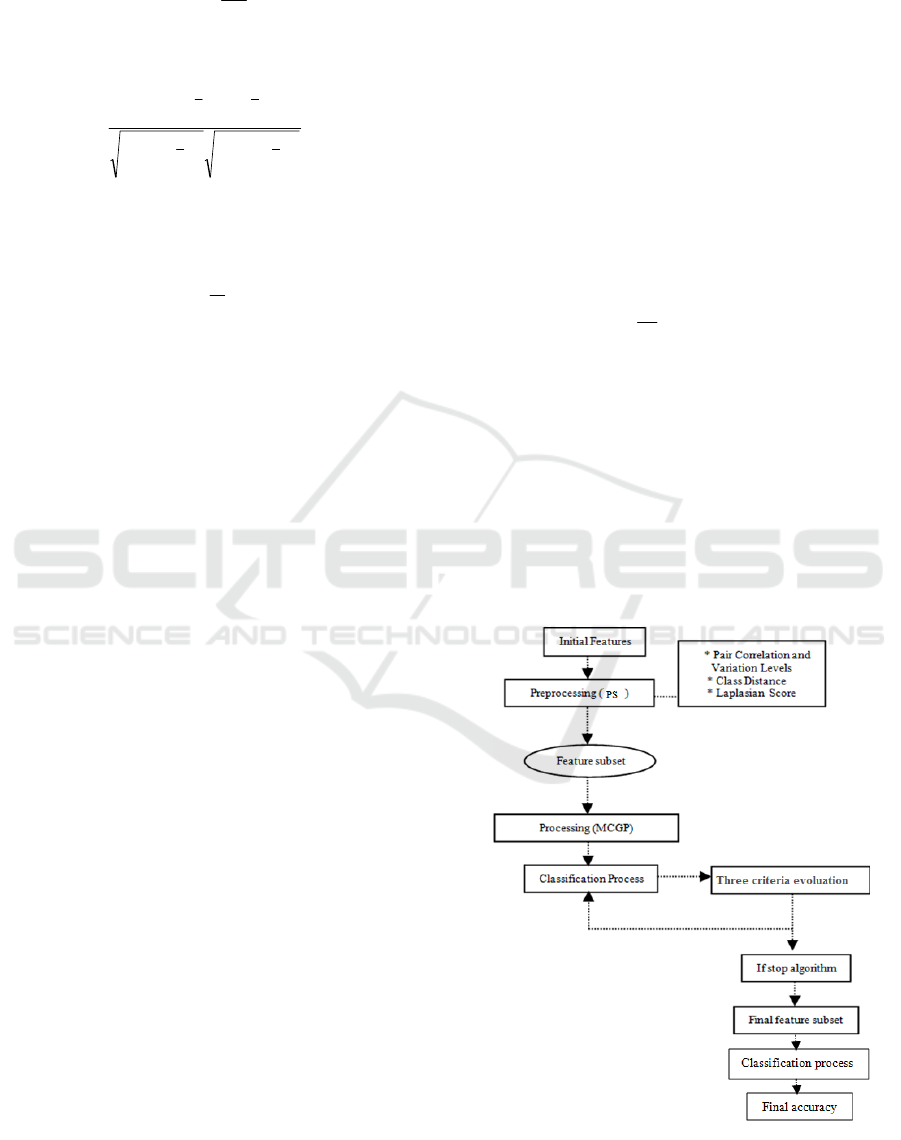
Both described stages are called as a PS+MCGP
algorithm. The schematic representation of the
PS+MCGP algorithm is presented in Figure 3.
4 DATABASES
In the study a number of speech databases have been
used and this section provides their brief description.
The Berlin emotional database (Burkhardt et al.,
2005) was recorded at the Technical University of
Berlin and consists of labeled emotional German
utterances which were spoken by 10 actors (5
female). Each utterance has one of the following
emotional labels: neutral, anger, fear, joy, sadness,
boredom or disgust.
The UUDB (The Utsunomiya University Spoken
Dialogue Database for Paralinguistic Information
Studies) database (Mori et al., 2011) consists of
spontaneous Japanese human-human speech. The
task-oriented dialogue was produced by seven pairs
of speakers (12 female) resulted in 4,737 utterances
in total. Emotional labels for each utterance were
created by three annotators on a five-dimensional
emotional basis (interest, credibility, dominance,
arousal, and pleasantness). For this work, only
pleasantness (or evaluation) and the arousal axes are
used.
The LEGO emotion database (Schmitt et al.,
2012) comprises non-acted American English
utterances extracted from an automated bus
information system of the Carnegie Mellon
University in Pittsburgh, USA. The utterances are
requests to the Interactive Voice Response system
spoken by real users with real concerns. Each
utterance is annotated with one of the following
emotional labels: angry, slightly angry, very angry,
neutral, friendly, and non-speech (critical noisy
recordings or just silence). In this study different
ranges of anger have been merged into single class
and friendly utterances have been deleted. These
preprocessing results are represented as a 3-classes
emotion classification task.
The RSDB (Russian Sound Data Base) (Loseva,
2015b) was created, which consists of voices of
people from 14 to 18 and from 19 to 60 years old
both human`s gender (man, woman). Each utterance
is annotated with one of the following emotional
labels: angry, neutral, happy. The database was
created in Krasnoyarsk on the recording studio
"WAVE" in 2014.
5 EXPERIMENTS AND RESULTS
To estimate the performance of the PS+MCGP
usage in speech-based recognition problems, a
number of experiments were conducted. The
proposed approach was applied for all considered
databases. The following methods for feature
selection were also applied in this study: OGA, IGR.
These methods have been included to conduct
classification experiments with Sequential Minimal
Optimization (SMO) (Platt, 1998). The conventional
OGA-based feature selection is used as the
supervised technique. From early works (Liu et al.,
2001), (Golub et al., 1999), (Nguyen and Rocke,
2002), it is obvious that best accuracy for cross-
validation from training set is used as a classification
accuracy. Therefore, in this study we used the OGA
procedure, with one-criteria for testing data as
mentioned in equation (14):
),(indaccuracyFitness
(14)
where is the accuracy (ind) is the cross-validation
accuracy of the SMO classifier trained using the
feature subset of training data represented by ind.
In order to provide statistical comparison of the
proposed methods, the classification procedure was
tested several times (15 times). Firstly, it was
fulfilled by SMO (without feature selection) and
secondly by the earlier proposed methods (Brester et
al., 2014). In order to determine the number of
selected features using the IGR method, a grid bases
consist of Russian human speech. A statistical
description of the used corpora can be found in
Table 1.
Table 1: Databases description.
Data
base
Language
Data
base
size
Features
Emotion
classes
Speak
ers
Berlin German 535 45 7 10
UUDB Japanese 1514 45 4 10
LEGO English 4827 29 5 291
RSDB Russian 800 20 3 300
Speaker State Recognition: Feature Selection Method based on Self-adjusting Multi-criteria Evolutionary Algorithms
127

Table 2: Average accuracy for emotion recognition.
Data
base
Baseline
SMO
SMO
IGR
SMO
OGA
SMO
PS+MCGP
Berlin 12.99 16.9(35) 15.1(26)
25.1(23)
UUDB 86.04 85.5(40) 83.3(30)
87.7(25)
LEGO 13.46 20.3(19) 20.7(15)
45.2(16)
RSDB 32.38 23.8(15) 34.4(12)
80.9(10)
Table 3: Average accuracy for gender identification.
Data
base
Baseline
SMO
SMO
IGR
SMO
OGA
SMO
PS+MCGP
Berlin 24.30
99.1(38)
21.3(25) 92.5(24)
UUDB 34.77 65.4(39) 31.8(28)
87.1(26)
LEGO 36.89 61.2(17) 64.6(18)
70.3 (15)
RSDB 53.89 73.6(16) 52.8(15)
94.1(12)
The optimization technique with 10 steps was
applied, i.e. for Berlin database: first 5, 10, 20, ..., 45
features. The data sets were randomly divided into
training and test samples in a proportion of 80 -
20%. In all experiments PS+MCGPs were provided
with an equal amount of resources. The final
solution is the relevant feature set that is determined
by amount of input neurons in ANN in the second
part of the described algorithm. Tables 2 and 3
contain the relative classification accuracy for the
described corpora. In parentheses there is the
average number of selected features (Tables 2, 3).
The columns entitled SMO Baseline contain results
which were achieved with the baseline feature
selection methods. Similarly, the columns titled
SMO PS+MCGP, SMO IGR and SMO OGA
contain results obtained with PS+MCGP, IGR, OGA
feature selection procedures correspondingly.
6 CONCLUSIONS AND FUTURE
WORK
An application of the proposed hybrid algorithm in
order to select the relevant features and maximize
the accuracy of particular tasks could decrease the
number of features and increase the accuracy of the
system simultaneously. In most of the cases, the
PS+MCGP approach outperforms other algorithms.
Also the MCGP approach is able to create (select)
the optimal variant of the ANN classifier which
could be applied for improving effectiveness of
speaker state recognition problems. It should be
noted that the number of selected features using the
IGR, OGA methods is quite high. It means that in
some cases the number of features was equal to 41,
i.e. an optimal modeling procedure has been
conducted without feature selection at all.
The usage of effective classifiers may improve
the performance of the proposed approach. Thus, it
is important to estimate efficiency of classifiers in
cooperation with feature selection algorithms for
comprehensive improvement of recognition systems.
Additionally, the proposed approach can be
applied to improve the effectiveness of „real-time”
(on-line) systems. On-line processes always
accompany by different types of effects such as
noise, voice distortion, etc. that should be processed
in real time. Therefore, it can be useful to involve
the developed algorithm into on-line systems. For
example, the proposed approach can be applied for
improving real-time recognition of a psycho-
emotional state of a human. We assume, a study in
this direction allows creating a state recognition
procedure for real-time systems more accurate.
REFERENCES
Akthar, F. and Hahne, C., 2012. Rapid Miner 5 Operator
reference, Rapid-I. Dortmund. pages 25-55.
Ashish, G. and Satchidanada D., 2004. Evolutionary
Algorithm for Multi-Criterion Optimization: A Survey.
In International Journal of Computing & Information
Science. vol. 2, no. 1. pages 43-45.
Brester, Ch., Sidorov, M., Semenkin, E., 2014. Acoustic
Emotion Recognition: Two Ways of Features
Selection Based on Self-Adaptive Multi-Objective
Genetic Algorithm. In Informatics in Control,
Automation and Robotics. ICINCO`14. pages 851 -
855.
Burkhardt, F., Paeschke, A., Rolfes M., Sendlmeier, W. F.,
Weiss, B., 2005. A database of german emotional
speech. In Interspeech. pages 1517–1520.
Fan, R. K. and Chung, Spectral, 1997. Graph Theory. In
Regional Conference Series in Mathematics. no. 92.
pages 2-5.
Golub, T. R., Slonim D. K., Tomayo, P., Huard, C.,
Gaasenbeek M., Mesirov J. P., Coller, H., Loh, M. L.,
Downing J. R., Caligiuri, M. A., Bloofield, C. D. and
Lander, E. S. 1999. Molecular classification of cancer:
Class discovery and class prediction by gene
expression monitoring. In Science. vol. 286. pages
531-537.
He, X., Cai, D., and Niyogi, P., 2005. Learning a
Laplacian Score for Feature Selection. In Advances in
Neural Information Processing Systems 18. NIPS.
pages 14-14.
Holland, J. H., 1975. Adaptation in Natural and Artificial
System. In University of Michigan Press. pages 18-35.
Koza, J.R., 1992. Genetic Programming: On the
Programming of Computers by Means of Natural
Selection, MIT Press. London. pages 109-120.
Liu, J., Iba, H. and Ishizuka, M. 2001. Selecting
informative genes with parallel genetic algorithms in
ICINCO 2016 - 13th International Conference on Informatics in Control, Automation and Robotics
128

tissue classification. In Genome Informatics. vol. 12,
pages 14-23.
Loseva, E. D., 2014. Recognition of human`s emotion,
gender and age for the functioning of the system
"Smart House". In Fundamental computer science,
information technology and management of systems:
realities and prospects. FIIT, pages 239 - 249.
Loseva, E. D., 2015a. Ensembles of neural network
models using multi-criteria self-configuring genetic
programming. In Actual problems of aviation and
cosmonautics. APAC. Part 1. pages 340-343.
Loseva, E. D., 2015b. Application of ten algorithm for
optimization of the support vector machine parameters
and for optimization of feature selection process in the
task of recognition human`s gender and age. In XII
International scientific-practical conference.
MCSR. Part 7. pages 132-136.
Mori, H., Satake, T., Nakamura, M., and Kasuya, H.,
2011. Constructing a spoken dialogue corpus for
studying paralinguistic information in expressive
conversation and analyzing its statistical/acoustic
characteristics. Speech Communication. pages 36-50.
Nguyen, V. D. and Rocke, D. M. 2002. Tumor
classification by partial least squares using microarray
gene expression data. In Bioinformatics. vol. 8. no. 1.
pages 39-50.
Platt., J. 1998. Sequential Minimal Optimization: A Fast
Algorithm for Training Support Vector Machines. In
Microsoft Research. pages 1-21.
Polzehl, T., Schmitt, A., and Metze, F., 2011. Salient
features for anger recognition in german and english
ivr portals. In Minker, W., Lee, G. G., Nakamura, S.,
and Mariani, J., editors, Spoken Dialogue Systems
Technology and Design. Springer New York, 1
st
edition. pages 83–105.
Schmitt, A., Ultes, S., and Minker, W., 2012. A
parameterized and annotated corpus of the cmu let’s
go bus information system. In International
Conference on Language Resources and Evaluation.
LREC. pages 208-217.
Semenkin, E. and Semenkina M., 2012. Self-configuring
genetic programming algorithm with modified
uniform crossover. IEEE Congress on Evolutionary
Computation 2012.
Sergienko, R. and Semenkin, E, 2010. Competitive
cooperation for strategy adaptation in coevolutionary
genetic algorithm for constrained optimization. IEEE
Congress on Evolutionary Computation 2010.
Sidorov, M., Brester, Ch., Semenkin, E., and Minker, W.,
2014. Speaker State Recognition with Neural
Network-based Classification and Self-adaptive
Heuristic Feature Selection. 11th International
Conference Informatics in Control, Automation and
Robotics. ICINCO`14. Vol. 1. pages 699 - 703.
Venkatadri, M. and Srinivasa R. K., 2010. A
multiobjective genetic algorithm for feature selection
in data mining. International Journal of Computer
Science and Information Technologies. vol. 1, no. 5.
pages 443–448.
Zitzler, E. and Thiele, L., 1999. Multiobjective
evolutionary algorithms: A comparative case study
and the strength pareto approach. In Evolutionary
Computation. IEEET. no. 3(4). pages 257–271.
Speaker State Recognition: Feature Selection Method based on Self-adjusting Multi-criteria Evolutionary Algorithms
129
