
Incorporating Privileged Information to Improve Manifold Ordinal
Regression
M. P
´
erez-Ortiz, P. A. Guti
´
errez and C. Herv
´
as-Mart
´
ınez
University of C
´
ordoba, Dept. of Computer Science and Numerical Analysis,
Rabanales Campus, Albert Einstein Building, 14071 C
´
ordoba, Spain
Keywords:
Manifold Learning, Ordinal Regression, Privileged Information, Kernel Learning.
Abstract:
Manifold learning covers those learning algorithms where high-dimensional data is assumed to lie on a low-
dimensional manifold (usually nonlinear). Specific classification algorithms are able to preserve this manifold
structure. On the other hand, ordinal regression covers those learning problems where the objective is to
classify patterns into labels from a set of ordered categories. There have been very few works combining
both ordinal regression and manifold learning. Additionally, privileged information refers to some special
features which are available during classifier training, but not in the test phase. This paper contributes a
new algorithm for combining ordinal regression and manifold learning, based on the idea of constructing a
neighbourhood graph and obtaining the shortest path between all pairs of patterns. Moreover, we propose
to exploit privileged information during graph construction, in order to obtain a better representation of the
underlying manifold. The approach is tested with one synthetic experiment and 5 real ordinal datasets, showing
a promising potential.
1 INTRODUCTION
Ordinal regression is a learning task where the ob-
jective is to classify patterns into a set of prede-
fined labels, but the labels include an order (Car-
doso and da Costa, 2007; Chu and Keerthi, 2007; Li
and Lin, 2007). For example, for an age estimation
problem, people images could be classified into the
classes {newborn, baby, young,adult, senior}. These
categories are reflecting intervals of an actual latent
variable (the real age of the person) but, contrary to
standard regression, the latent variable is unobserv-
able. On the other hand, the order between the cat-
egories makes this problem different from standard
classification, and specific ordinal regression algo-
rithms try to improve the quality of the classifier by
introducing the order in the model and/or penalising
the different classification errors (the magnitude of
the error should be higher when the predicted class
if further to the actual class) (Lin and Li, 2012).
Different methods have been proposed to deal
with ordinal regression problems. Threshold mod-
els are one of the most popular approaches (McCul-
lagh, 1980; Verwaeren et al., 2012), where the or-
dinal regression problem is formulated as the prob-
lem of estimating a real valued function and a set
of Q − 1 thresholds (Q is the number of classes), in
such a way that one interval is assigned to each class
([−∞, b
1
), [b
1
, b
2
), . . . , [b
Q−1
, ∞)). This is the struc-
ture of the first specific model for ordinal regres-
sion, the proportional odds model (McCullagh, 1980),
which is an ordinal version of binary logistic regres-
sion. Later on, nonlinear threshold models have ap-
peared in the machine learning community, including
different adaptions of other methods to the ordinal set-
ting, such as support vector machines (R. Herbrich
and Obermayer, 2000; Shashua and Levin, 2003; Chu
and Keerthi, 2007), discriminant analysis (Sun et al.,
2010) or Gaussian processes (Chu and Ghahramani,
2005). Other works decompose the original ordinal
regression problem into several binary classification
ones, by sequentially dividing the ordinal scale in bi-
nary labels (Frank and Hall, 2001; Cheng et al., 2008;
Deng et al., 2010). Finally, a reduction framework
can be found in (Cardoso and da Costa, 2007; Lin and
Li, 2012), where ordinal regression is reduced to bi-
nary classification, but learning one single model for
the binary problem where the input patterns are repli-
cated, extended and weighted according to the ordinal
label.
In this paper, we consider a manifold learning ap-
proach for ordinal regression. The idea of manifold
187
Pérez-Ortiz M., A. Gutiérrez P. and Hervás-Martínez C..
Incorporating Privileged Information to Improve Manifold Ordinal Regression.
DOI: 10.5220/0005075801870194
In Proceedings of the International Conference on Neural Computation Theory and Applications (NCTA-2014), pages 187-194
ISBN: 978-989-758-054-3
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

learning is to uncover the nonlinear structure embed-
ded in a dataset, assuming that the high-dimensional
observations lie on or close to an intrinsically low-
dimensional manifold. There are different algorithms
to learn this kind of structures, including the iso-
metric feature mapping (Isomap) (Tenenbaum et al.,
2000) or Laplacian eigenmaps (Belkin and Niyogi,
2001). Based on them, other manifold learning
algorithms have been also proposed for classifica-
tion, such as locality preserving projections (He and
Niyogi, 2003) or the discriminant Laplacian embed-
ding (DLE) (Wang et al., 2010).
In the context of ordinal regression, manifold
learning has been considered in (Liu et al., 2011a;
Liu et al., 2011b) based on the idea of preserving
the intrinsic geometry of the data via the definition
of a neighbourhood graph which also preserves the
ordinal nature of the dataset. This graph is used to
construct an adjacency matrix by using a generalised
radial basis function. The Laplacian matrix is then
derived and used for the learning process. A related
method is proposed in (Liu et al., 2012), where several
projections are iteratively computed. Finally, rank-
ing on data manifolds is investigated in (Zhou et al.,
2004), although the problem is defined as ranking,
which is different from ordinal regression.
On the other hand, Vapnik and Vashist recently
proposed a framework to apply support vector ma-
chines (SVM) to those cases where privileged infor-
mation is available during the training phase, but not
during test (Vapnik and Vashist, 2009). This kind of
information can be found in many learning problems,
where training samples present some special features
which are not available during test because of their
cost or simply because it is not possible. For exam-
ple, suppose our goal is to find a rule that can pre-
dict outcome y of a treatment in a year given the cur-
rent symptoms x of a patient. At the training stage,
a doctor can also provide additional information x
∗
about the development of symptoms in three months,
six months, and nine months (Vapnik and Vashist,
2009). The algorithm in (Vapnik and Vashist, 2009)
was based on considering a slack model for this priv-
ileged information. Given that slacks are only con-
sidered during SVM optimisation and not included
in the final model, their approach was able to bene-
fit from this privileged information, mainly improving
the convergence of the learning algorithm.
In this paper, we extend the ordinal regression
manifold approach in (Liu et al., 2011b; Liu et al.,
2011a) by considering privileged information during
the neighbourhood graph construction. Under the as-
sumption that privileged features are useful for the
classification task, this approach would modify the
neighbourhood structure to better represent the learn-
ing task. Moreover, we also consider a different ap-
proach for constructing the final distance matrix (by
making use of the Dijkstra algorithm) and include this
information into a kernel function, in order to apply
support vector ordinal regression (Chu and Keerthi,
2007), as opposed to the ordinal discriminant-based
projection method in the original proposal. There-
fore, two main objectives can be found in this paper:
Firstly, to analyse whether it is feasible to reformu-
late the notion of similarity for kernel functions when
considering an ordinal manifold of the data and sec-
ondly, to study if the inclusion of privileged informa-
tion helps to improve the constructed model. The ap-
proach is tested in one synthetic dataset and 5 real
ones, showing a competitive performance.
The rest of the paper is organised as follows: Sec-
tion 2 presents the methodology proposed, while Sec-
tion 3 presents and discusses the experimental results.
The last section summarises the main contributions of
the paper.
2 METHODOLOGY
When dealing with multiclass classification, the goal
is to assign an input vector x to one of Q discrete
classes C
q
, q ∈ {1, . . . , Q}. To obtain the prediction
rule C : X → Y , we use an i.i.d. training sample X =
{x
i
, y
i
}
N
i=1
where N is the number of training patterns,
x
i
∈ X , y
i
∈ Y , X ⊂ R
d
is the d-dimensional input
space and Y = {C
1
, C
2
, . . . , C
K
} is the label space. We
are also provided a test set to obtain a reliable estima-
tion of the classification error, X
t
= {x
ti
, y
ti
}
N
t
i=1
, where
N
t
is the number of test patterns and x
ti
∈ X , y
ti
∈ Y .
Finally, many learning problems present some fea-
tures which are available during training but not in the
test phase. This privileged information complements
training data in such a way that the training sample
is X = {x
i
, x
∗
i
, y
i
}
N
i=1
, where x
i
∈ X , x
∗
i
∈ X
∗
, y
i
∈ Y
and X
∗
⊂ R
d
∗
is the d
∗
-dimensional input privileged
space. The test set is the same, given that privileged
information is not available when applying the classi-
fier.
Ordinal regression or ordinal classification are
those problems where patterns have to be classified
into naturally ordered labels. Consequently, the defi-
nition of this kind of problems is similar to the one in-
troduced in the previous paragraph, but incorporating
the following constraint: C
1
≺ C
2
≺ · ·· ≺ C
K
, where
≺ denotes this order information.
Considering this ordering scale, one of the main
hypothesis in ordinal regression is that the distance
to adjacent classes is lower than the distance to non-
NCTA2014-InternationalConferenceonNeuralComputationTheoryandApplications
188

adjacent classes. Therefore, it can be said that ideally
there exists a latent distance-based manifold of the
output variable that results in C
q
lying in the space be-
tween C
q−1
and C
q+1
. In this paper, we test two differ-
ent hypotheses. On the one hand and motivated by the
large amount of ordinal kernel methods in the litera-
ture (Chu and Ghahramani, 2005; Chu and Keerthi,
2007; Sun et al., 2010; Liu et al., 2012), we test
whether it is possible to include the manifold struc-
ture in the kernel matrix of kernel methods. Kernel
matrices can be seen as structures of data that contain
information about similarities among the patterns in a
dataset. This notion of similarity is usually based on
a distance relation between the patterns. Therefore,
this distance can be modified to consider the mani-
fold structure of the data. On the other hand, we test
whether the inclusion of privileged information in the
construction of the neighbourhood graph helps to im-
prove the robustness and efficiency of the classifica-
tion model. The following two subsections are related
to the first hypothesis, while the last subsection covers
the second one.
2.1 Constructing a Representative
Graph for the Ordinal Manifold
This subsection comprises some elementary notions
for constructing a representative graph for the or-
dinal manifold, which are used both in this paper
and the previous work (Liu et al., 2011a; Liu et al.,
2011b). Consider an undirected graph of N vertices,
G = (V, E), where V corresponds to the vertices of
the graph and E ⊆ [V ]
2
to the edges. In this case,
the set of the training patterns form the set of vertices,
V = {v
1
, v
2
, . . . , v
N
} = {x
1
, x
2
, . . . , x
N
}, and the differ-
ent edges connect pairs of patterns:
E = {e
i, j
} = {(v
i
, v
j
)} = {(x
i
, x
j
)}, (1)
where 1 ≤ i ≤ N and 1 ≤ j ≤ N. The set of edges is
obtained via a k-neighbourhood analysis of the data,
i.e. v
i
is connected to v
j
if x
i
is one of the k-nearest
neighbours of x
j
or viceversa. Instead of this or, we
could have considered the logical operator and, but
we introduce this relaxed version of the neighbour-
ing structure to prevent unconnected regions in the
dataset. Note that if v
i
is connected to v
j
, there exist
e
i, j
such that e
i, j
∈ E. For the purpose of construct-
ing the neighbourhood graph, the Euclidean distance
is used as the weight function (i.e. the one used for
the neighbourhood analysis):
f (e
i, j
) = d(x
i
, x
j
) = ||x
i
− x
j
||
2
, (2)
being || · ||
2
the L
2
-norm operator.
As we aim to preserve the ordinal structure of the
manifold, we could try to enlarge the locality between
different ranks, as done in (Liu et al., 2011b). To do
so, we can include a weight parameter w for the dis-
tances in such a way that these weights reflect the rank
differences between data points:
w
i, j
= |y
i
− y
j
| + 1. (3)
This weight information is applied to the distance
function as follows: d(x
i
, x
j
) = w
i, j
· ||x
i
− x
j
||
2
. The
possibility of considering these weights is explored
in the experiments of this paper (i.e. we consider
both the weighted and unweighted versions of the pro-
posal). Recall that this transformation of the distances
is done before constructing the neighbourhood graph.
2.2 Including Graph Shortest Paths in
the Kernel Matrix
Usually, for manifold learning algorithms, an adja-
cency matrix is used for the learning process (which
is the underlying idea in (Liu et al., 2011a; Liu et al.,
2011b)). In this paper, however, we try to anal-
yse whether it is feasible to reformulate the notion
of similarity for kernel functions when considering
an ordinal manifold of the data. The main idea is
to use the graph information obtained in the previ-
ous step to locate the different patterns in the un-
derlying ordinal manifold of the data. To do so, we
use the shortest path of the graph in order to pro-
vide a more smooth approach for the distances (as op-
posed to other manifold-based techniques where non-
connected points are assumed to present an infinite
distance).
In graph theory, the shortest path problem is the
problem of finding a path between two vertices in a
graph such that the sum of the weights of its con-
stituent edges is minimised. As said, the constructed
graph is undirected, so the notion of path is defined
as a sequence of z vertices from v
1
to v
z
, p
1z
=
(v
1
, v
2
, . . . , v
z
) ∈ V
z
, such that v
i
is adjacent to v
i+1
for 1 ≤ i < z (and therefore e
i,i+1
exists). Moreover,
given a real-valued weight function f : E → R (as
said, the weighted or unweighted Euclidean distance)
that assigns a cost to each edge and an undirected
graph G, the shortest path from v to v
0
is the path
p
1,z
= (v
1
, . . . , v
z
) (where v
1
= v and v
z
= v
0
) that over
all possible paths minimises the sum
∑
z−1
i=1
f (e
i,i+1
),
where e
i,i+1
∈ E.
To compute the distance from one data pattern x
i
to the rest but taking into account the manifold struc-
ture, we can compute the shortest paths from the ver-
tex v
i
to all the rest of vertices considering the well-
known Dijkstra’s algorithm (Dijkstra, 1959). Denote
by P the set of paths obtained from this process, where
IncorporatingPrivilegedInformationtoImproveManifoldOrdinalRegression
189
−1 −0.5 0 0.5 1 1.5 2
−1
−0.5
0
0.5
1
1.5
2
−1
0
1
2
−1
0
1
2
0
10
20
30
40
x
y
y
x
z
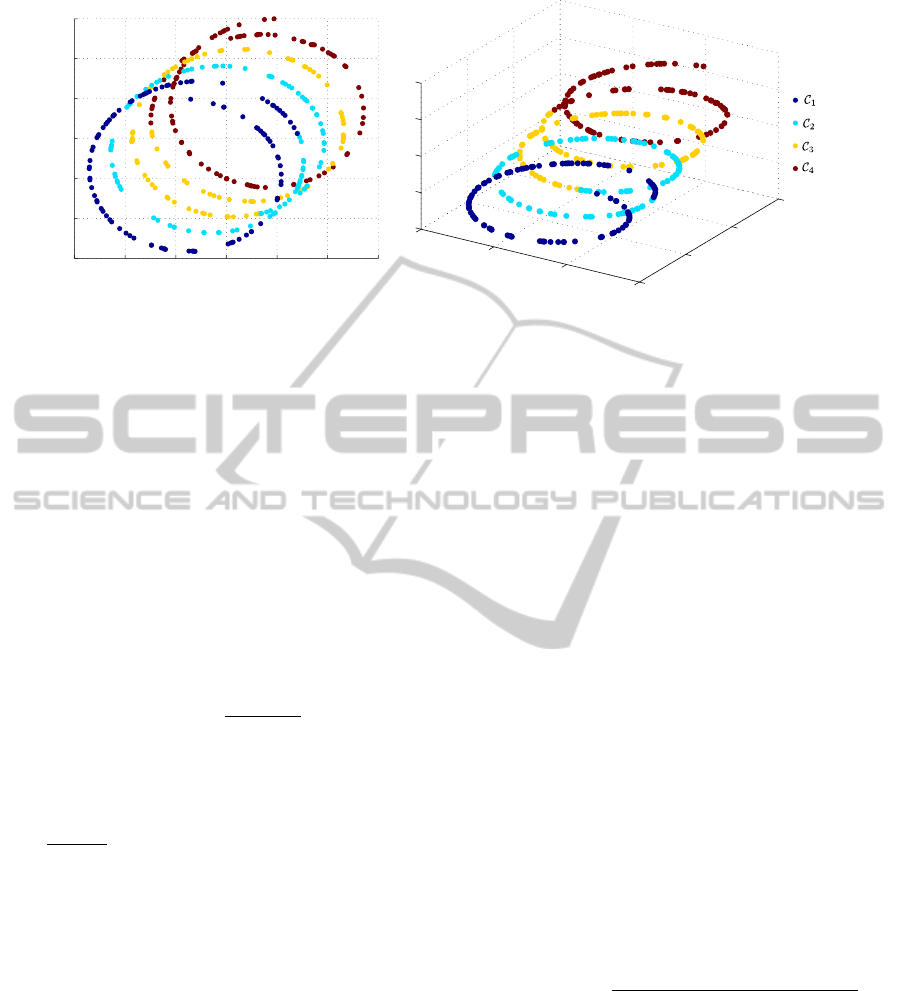
Figure 1: Representation of the spiral synthetic ordinal dataset. Left plot: Original dataset without privileged information.
Right plot: Dataset including the privileged information as an additional feature. It can be seen that this privileged information
improves the potential separability of the data.
p
i, j
∈ P is the shortest path between v
i
and v
j
. There-
fore, the distance from any two points x
i
and x
j
in the
training set is:
d(x
i
, x
j
) =
z−1
∑
h=1
f (e
h,h+1
), v
1
= x
i
, v
z
= x
j
. (4)
where z is the length of the path between x
i
and x
j
.
Note that d(x
i
, x
j
) = w
i, j
·||x
i
−x
j
||
2
if x
i
is one of the
nearest neighbours of x
j
. Therefore, to introduce the
information of the location of each data point in the
manifold in the kernel matrix, we modify the kernel
function as follows:
k(x
i
, x
j
) = exp
−
d(x
i
, x
j
)
2
2σ
2
, (5)
where d(x
i
, x
j
) is defined as in Eq. (4) and σ is
the kernel parameter, as opposed to using the stan-
dard Gaussian kernel with the L
2
-norm: k(x
i
, x
j
) =
exp
−
||x
i
−x
j
||
2
2
2σ
2
. Note that this kernel matrix will
still be positive semidefinite given that the only in-
formation changed is the distance function.
The kernel matrix obtained by this process is the
one used for the training step. For the test phase, we
first compute the distance from each test pattern x
ti
to
its nearest neighbour in training x
j
and then, sum this
distance to the shortest paths from x
j
to the rest of
training patterns. Consequently, the distance between
a test point x
ti
and all training points is:
d(x
ti
, x
z
) = d(x
ti
, x
j
) + d(x
j
, x
z
), (6)
for 1 ≤ i ≤ N
t
and 1 ≤ z ≤ N.
This idea for the test phase corresponds to locate
the test pattern in the graph and use the shortest paths
information to compute the distance to the whole set
of training patterns.
2.3 Including Privileged Information in
the Graph
In order to motivate the inclusion of privileged infor-
mation during manifold learning, Figure 1 represents
a synthetic dataset presenting an ordinal manifold-
based structure where the label of points is assigned
according to the z coordinate. Data points lie on a
leaning 3-dimensional spiral and labels are ordinal,
with four classes C
1
, C
2
, C
3
and C
4
. The Figure 1 also
includes the projection over x and y coordinates. As
can be seen, z coordinate is crucial to obtain a neigh-
bourhood graph able to help in the ordinal classifica-
tion task. Considering this z value as privileged in-
formation during graph construction would allow the
classification of patterns, even when only x and y fea-
tures are available during the test phase.
The privileged information can be easily included
during distance calculation to construct a neighbour-
hood graph which takes into account this additional
information. We can make use of the privileged fea-
tures in the real-valued weight function f that assigns
a value to edges of the graph:
f
∗
(e
i, j
) = ||(x
i
, x
∗
i
) − (x
j
, x
∗
j
)||
2
(7)
=
v
u
u
t
d
∑
s=1
(x
is
− x
js
)
2
+
d
∗
∑
s=1
(x
∗
is
− x
∗
js
)
2
.
The whole process of neighbourhood analysis and
shortest path computation is reformulated to work
with this real-valued weight function. When consid-
ering this weight function, f
∗
(e
i, j
), the distance func-
tion on Eq. (4) will be d
∗
(x
i
, x
∗
i
), (x
j
, x
∗
j
)
and will
be applied to the kernel function on Eq. (6). For the
test phase, the privileged information is only consid-
NCTA2014-InternationalConferenceonNeuralComputationTheoryandApplications
190

ered for the graph that has been previously learnt, i.e.:
d
x
ti
, (x
z
, x
∗
z
)
= ||x
ti
− x
j
||
2
+ d
∗
(x
j
, x
∗
j
), (x
z
, x
∗
z
)
,
where 1 ≤ z ≤ N and x
j
is the closest training point
from the test point evaluated x
ti
.
3 EXPERIMENTS
The proposed methodologies are based on generat-
ing a modified version of the kernel matrix (by ex-
ploiting the neighbourhood graph of the data), so they
can be applied to any kernel classifier. In this way,
we have considered the Support Vector Ordinal Re-
gression with Implicit Constraints (SVORIM) (Chu
and Keerthi, 2007), as it is one of the best perform-
ing threshold models for ordinal regression (Guti
´
errez
et al., 2012). 5 benchmark ordinal regression datasets
have been used for the analysis, which are taken from
publicly available repositories
1
(Asuncion and New-
man, 2007; PASCAL, 2011). Additionally, a more
controlled environment is provided by the spiral
dataset, introduced in Section 2.3. Table 1 shows the
characteristics of the evaluated datasets, where it can
be checked that number of classes varies between 3
and 5.
In the experiments, we evaluate two different fac-
tors:
• The introduction of ordinal costs for penalising
distances during the construction of the graph. Or-
dinal costs are based on the absolute cost. This
factor will be used to confirm whether these costs
are really useful for ordinal regression, as dis-
cussed in previous works (Liu et al., 2011b; Liu
et al., 2011a).
• The improvement obtained by the privileged in-
formation. The graph will be constructed with
and without privileged information to evaluate if
the additional variables improve the quality of the
model.
The most common evaluation measures for ordi-
nal regression are the Mean absolute error (MAE) and
the accuracy ratio (Acc) (Guti
´
errez et al., 2012; Bac-
cianella et al., 2009; Cruz-Ram
´
ırez et al., 2014). The
MAE measure is used when the costs of different mis-
classification errors is not constant:
MAE =
1
N
t
N
t
∑
i=1
|y
ti
− ˆy
ti
|, (8)
1
Note that many of these datasets are frequently treated
as nominal ones, without taking into account the order
scale.
where ˆy
ti
is the label predicted for x
ti
. MAE values
range from 0 to Q − 1 (Baccianella et al., 2009).
Regarding the experimental setup, the datasets
were divided 30 times using a holdout stratified tech-
nique with a 75% of the patterns for training and the
remaining 25% for test. The splits of each holdout
are the same for all the algorithms and one model is
obtained for each training set and evaluated in the test
set. The average test evaluation measures and the cor-
responding standard deviations are finally reported as
the summary of the algorithm performance.
We use the standard Gaussian kernel for all the
methods. Model selection is accomplished by cross-
validating the hyperparameters of the algorithms con-
sidering only the training data (with a 5-fold cross-
validation). The measure used to select the best pa-
rameter combination is MAE. The two parameters
to be optimised are the kernel width (σ) and the cost
parameter (C), both being selected within the values
σ,C ∈ {10
−3
, 10
−2
, . . . , 10
3
}. The number of nearest
neighbours to be considered during graph construc-
tion is k = 3. In those cases that a pattern is not con-
nected to any other ones for the current value of k, we
increase k until all patterns are connected to at least
one.
For the spiral dataset, privileged information is
the z coordinate. For the rest of datasets, we apply the
Relief feature selection algorithm (Kira and Rendell,
1992) over the training set to sort the features by their
relevance. We select half of the features (the most
relevant ones) as privileged information (x
∗
) and the
rest as the original information (x).
3.1 Results
Table 2 shows the test results for the 6 ordinal datasets
considered in terms of Acc and MAE. The best result
for each dataset is in bold face and the second one in
italics. From this Table, we can outline several con-
clusions:
• When considering the ordinal weights, the Acc
and MAE results are always improved by the
privileged information. However, if the costs
are not included, there are some datasets where
the privileged information does not improve
the results (bondrate, contact-lenses and
squash-unstored). Given that the cross-
validation criterion is the MAE (which is based
on an absolute cost loss), we conclude that us-
ing these weights is necessary to properly obtain
a benefit from the privileged information.
• From all the combinations, considering privileged
information and ordinal weights is the best one,
IncorporatingPrivilegedInformationtoImproveManifoldOrdinalRegression
191

Table 1: Characteristics of the six datasets used for the experiments: number of instances (Size), inputs (#In.), classes (#Out.)
and patterns per-class (#PPC)
Dataset Size #In. #Out. #PPC
bondrate 57 37 5 (6, 33, 12, 5, 1)
contact-lenses 24 6 3 (15, 5, 4)
pasture 36 25 3 (12, 12, 12)
spiral 400 3 4 (50, 50, 50, 50)
squash-unstored 52 52 3 (24, 24, 4)
tae 151 54 3 (49, 50, 52)
Table 2: Test results obtained for the different datasets (Mean± Standard Deviation of the 30 splits) by considering all the
different manifold classification algorithms based on SVORIM.
Acc MAE
Privileged Information Privileged Information
Dataset Ordinal Weights No Yes No Yes
bondrate No 57.28 ± 3.82 56.54 ± 6.50 0.6272 ± 0.0647 0.6296 ± 0.0893
Yes 56.54 ± 5.02 58.52 ± 5.34 0.6346 ± 0.0676 0.6123 ± 0.0996
contact-lenses No 61.11 ± 10.11 61.11 ±10.11 0.5500 ± 0.0892 0.5500 ± 0.0892
Yes 58.89 ± 12.17 62.22 ± 8.68 0.5722 ± 0.1132 0.5389 ± 0.0717
pasture No 48.89 ± 14.76 51.85 ± 14.69 0.5370 ± 0.1600 0.5074 ± 0.1450
Yes 42.96 ± 15.91 43.70 ± 16.49 0.6037 ± 0.1668 0.6000 ± 0.1716
spiral No 82.37 ± 4.16 87.80 ± 2.70 0.2260 ± 0.0589 0.1867 ± 0.0505
Yes 85.03 ± 3.62 87.90 ± 2.76 0.2120 ± 0.0567 0.1857 ± 0.0520
squash-unstored No 52.56 ± 13.71 50.77 ± 10.42 0.4795 ± 0.1452 0.4949 ± 0.1082
Yes 49.74 ± 9.84 51.54 ± 11.45 0.5077 ± 0.0960 0.4897 ± 0.1115
tae No 35.35 ± 8.62 35.53 ± 8.40 0.6570 ± 0.0867 0.6526 ± 0.0783
Yes 34.91 ± 6.66 35.53 ± 8.40 0.6754 ± 0.0783 0.6500 ± 0.0770
obtaining the best results in four datasets and the
second one in another.
• The most clear contribution of the privileged in-
formation is obtained for the spiral dataset. This
is due to the fact in this more controlled envi-
ronment data clearly belong to a low dimensional
manifold and the class label is assigned accord-
ing to the privileged information (z value). For
the rest of datasets, the privileged information has
been selected according to the Relief algorithm,
which has known limitations. Nevertheless, there
are some datasets where the contribution of priv-
ileged information is still quite noticeable (e.g.
bondrate and contact-lenses).
• The original SVORIM algorithm (without using
a manifold assumption) was run for the spiral
dataset and the same configuration, leading to a
performance of Acc = 78.80 ± 3.53 and MAE =
0.2617 ± 0.0467. It is noticeable that these values
are worse than the ones obtained by the manifold
proposals in this paper.
4 CONCLUSIONS
This paper considers a new approach to face ordi-
nal regression problems based on manifold learning.
This approach is based on constructing a neighbour-
hood graph with the purpose of obtaining the intrin-
sic structure of the data. The main paper contribution
is that this neighbourhood graph can be improved by
the use of privileged information, information that is
available during training but not in the test phase.
The algorithm is applied to 5 ordinal classification
real problems and one synthetic dataset. When com-
bined with SVORIM, the results of this paper confirm
that privileged information is able to improve general-
isation results for almost all the cases considered. The
distances used in the kernel matrices are obtained us-
ing the privileged features, which (under the assump-
tion that privileged information is really informative)
better reflects the data structure.
Several future research directions are still open
from the work in this paper. First of all, more datasets
should be considered, including datasets with a higher
number of patterns and with a more clear manifold
NCTA2014-InternationalConferenceonNeuralComputationTheoryandApplications
192

structure. For example, the experiments considered in
(Liu et al., 2011b) cover the UMIST face, MovieLens
and the USPS datasets, which are known to contain
an underlying manifold structure. The problem is that
meaningful privileged information has to be found
for these problems. Secondly, the methods should
be compared against standard manifold classifiers to
check their performance. Finally, alternative kernel
methods apart from SVORIM could be considered to-
gether with the proposals in this paper.
ACKNOWLEDGEMENTS
This work has been subsidized by the TIN2011-22794
project of the Spanish Ministerial Commission of Sci-
ence and Technology (MICYT), FEDER funds and
the P11-TIC-7508 project of the “Junta de Andaluc
´
ıa”
(Spain).
REFERENCES
Asuncion, A. and Newman, D. (2007). UCI machine learn-
ing repository.
Baccianella, S., Esuli, A., and Sebastiani, F. (2009). Evalu-
ation measures for ordinal regression. In Proceedings
of the Ninth International Conference on Intelligent
Systems Design and Applications (ISDA 09), pages
283–287, Pisa, Italy.
Belkin, M. and Niyogi, P. (2001). Laplacian eigenmaps and
spectral techniques for embedding and clustering. In
NIPS, volume 14, pages 585–591.
Cardoso, J. S. and da Costa, J. F. P. (2007). Learning to clas-
sify ordinal data: The data replication method. Jour-
nal of Machine Learning Research, 8:1393–1429.
Cheng, J., Wang, Z., and Pollastri, G. (2008). A neural net-
work approach to ordinal regression. In Proceedings
of the IEEE International Joint Conference on Neu-
ral Networks (IJCNN2008, IEEE World Congress on
Computational Intelligence), pages 1279–1284. IEEE
Press.
Chu, W. and Ghahramani, Z. (2005). Gaussian processes
for ordinal regression. Journal of Machine Learning
Research, 6:1019–1041.
Chu, W. and Keerthi, S. S. (2007). Support vector ordinal
regression. Neural Computation, 19(3):792–815.
Cruz-Ram
´
ırez, M., Herv
´
as-Mart
´
ınez, C., S
´
anchez-
Monedero, J., and Guti
´
errez, P. A. (2014). Metrics
to guide a multi-objective evolutionary algorithm for
ordinal classification. Neurocomputing, 135:21–31.
Deng, W.-Y., Zheng, Q.-H., Lian, S., Chen, L., and Wang,
X. (2010). Ordinal extreme learning machine. Neuro-
computation, 74(1-3):447–456.
Dijkstra, E. W. (1959). A note on two problems in connex-
ion with graphs. Numerische mathematik, 1(1):269–
271.
Frank, E. and Hall, M. (2001). A simple approach to ordi-
nal classification. In Proc. of the 12th Eur. Conf. on
Machine Learning, pages 145–156.
Guti
´
errez, P. A., P
´
erez-Ortiz, M., Fernandez-Navarro,
F., S
´
anchez-Monedero, J., and Herv
´
as-Mart
´
ınez, C.
(2012). An Experimental Study of Different Ordi-
nal Regression Methods and Measures. In 7th Inter-
national Conference on Hybrid Artificial Intelligence
Systems (HAIS), volume 7209 of Lecture Notes in
Computer Science, pages 296–307.
He, X. and Niyogi, P. (2003). Locality preserving projec-
tions. In NIPS, volume 16, pages 234–241.
Kira, K. and Rendell, L. A. (1992). The feature selection
problem: Traditional methods and a new algorithm.
In AAAI, pages 129–134.
Li, L. and Lin, H.-T. (2007). Ordinal Regression by Ex-
tended Binary Classification. In Advances in Neural
Inform. Processing Syst. 19.
Lin, H.-T. and Li, L. (2012). Reduction from cost-sensitive
ordinal ranking to weighted binary classification. Neu-
ral Computation, 24(5):1329–1367.
Liu, Y., Liu, Y., and Chan, K. C. C. (2011a). Ordinal regres-
sion via manifold learning. In Burgard, W. and Roth,
D., editors, Proceedings of the 25th AAAI Conference
on Artificial Intelligence (AAAI’11), pages 398–403.
AAAI Press.
Liu, Y., Liu, Y., Chan, K. C. C., and Zhang, J. (2012).
Neighborhood preserving ordinal regression. In Pro-
ceedings of the 4th International Conference on Inter-
net Multimedia Computing and Service (ICIMCS12),
pages 119–122, New York, NY, USA. ACM.
Liu, Y., Liu, Y., Zhong, S., and Chan, K. C. (2011b).
Semi-supervised manifold ordinal regression for im-
age ranking. In Proceedings of the 19th ACM inter-
national conference on Multimedia (ACM MM2011),
pages 1393–1396, New York, NY, USA. ACM.
McCullagh, P. (1980). Regression models for ordinal data.
Journal of the Royal Statistical Society, 42(2):109–
142.
PASCAL (2011). Pascal (pattern analysis, statistical mod-
elling and computational learning) machine learning
benchmarks repository.
R. Herbrich, T. G. and Obermayer, K. (2000). Large mar-
gin rank boundaries for ordinal regression. In Smola,
A., Bartlett, P., Sch
¨
olkopf, B., and Schuurmans, D.,
editors, Advances in Large Margin Classifiers, pages
115–132. MIT Press.
Shashua, A. and Levin, A. (2003). Ranking with large mar-
gin principle: Two approaches. In Advances in Neural
Information Processing Systems (NIPS), pages 937–
944. MIT Press, Cambridge.
Sun, B.-Y., Li, J., Wu, D. D., Zhang, X.-M., and Li, W.-B.
(2010). Kernel discriminant learning for ordinal re-
gression. IEEE Transactions on Knowledge and Data
Engineering, 22:906–910.
Tenenbaum, J. B., De Silva, V., and Langford, J. C. (2000).
A global geometric framework for nonlinear dimen-
sionality reduction. Science, 290(5500):2319–2323.
Vapnik, V. and Vashist, A. (2009). A new learning
IncorporatingPrivilegedInformationtoImproveManifoldOrdinalRegression
193

paradigm: Learning using privileged information.
Neural Networks, 22(5–6):544–557.
Verwaeren, J., Waegeman, W., and De Baets, B. (2012).
Learning partial ordinal class memberships with
kernel-based proportional odds models. Computa-
tional Statistics & Data Analysis, 56(4):928–942.
Wang, H., Huang, H., and Ding, C. H. (2010). Discriminant
laplacian embedding. In AAAI.
Zhou, D., Weston, J., Gretton, A., Bousquet, O., and
Sch
¨
olkopf, B. (2004). Ranking on data manifolds. In
Proceedings of the Seventeenth Annual Conference on
Neural Information Processing Systems (NIPS2003),
pages 169–176.
NCTA2014-InternationalConferenceonNeuralComputationTheoryandApplications
194
