
Cross-Sensor Iris Matching using Patch-based Hybrid Dictionary
Learning
Bo-Ren Zheng
1
, Dai-Yan Ji
2
and Yung-Hui Li
3
1
Department of Information Engineering and Computer Science, Feng Chia Univerisy, Taichung, Taiwan
2
Advanced Analog Technology, Inc., Hsinchu, Taiwan
3
Department of Computer Science and Information Engineering, National Central University, Taoyuan County, Taiwan
Keywords: Cross-Sensor Iris Matching, Patch-based Hybrid Dictionary, Sparse Representation.
Abstract: Recently, more and more new iris acquisition devices appear on the market. In practical situation, it is highly
possible that the iris images for training and testing are acquired by different iris image sensors. In that case,
the recognition rate will decrease a lot and become much worse than the one when both sets of images are
acquired by the same image sensors. Such issue is called “cross-sensor iris matching”. In this paper, we
propose a novel iris image hallucination method using a patch-based hybrid dictionary learning scheme which
is able to hallucinate iris images across different sensors. Thus, given an iris image in test stage which is
acquired by a new image sensor, a corresponding iris image will be hallucinated which looks as if it is
captured by the old image sensor used in training stage. By matching training images with hallucinated
images, the recognition rate can be enhanced. The experimental results show that the proposed method is
better than the baseline, which proves the effectiveness of the proposed image hallucination method.
1 INTRODUCTION
Iris recognition (Bowyer et al, 2008) has attracted
considerable attention for its practical applications.
The iris image sensor used to capture the texture of
iris is actually one of the most important issues in
iris recognition because images captured by different
sensors contain different visual characteristics. In the
practical applications, most of the time, it is
impossible to re-enroll a large number of users every
time when a new sensor is deployed. Therefore, one
often encounters such problem where iris images for
enrollment and testing are acquired by different
image sensors. We call this problem “cross-sensor
iris matching”.
1.1 Previous Work
Recent studies have addressed the issue of cross-
sensor iris matching, and indicated it indeed is an
important problem. Bowyer (2009), (Connaughton et
al., 2011) investigated the interoperability of iris
sensors from different manufacturers using multiple
available matching algorithms. Pillai (2014) used
kernel learning methods (Weinberger, 2004) for
learning transformations of having desired iris
properties.
2 PROPOSED METHOD
The existing work about cross-sensor iris matching,
though successful, however, is a method of high
computational complexity. In fact, cross-sensor
matching problem also occurred in other biometrics
modalities, for example, in face sketch recognition
(Li et al., 2006) (Li and Savvides, 2006). Inspired by
such solution in face sketch recognition, we propose
a novel patch-based hybrid dictionary learning
method using sparse representation to approach this
problem.
2.1 Training Stage
What we are trying to do in training stage is to build
a hybrid dictionary including both low quality and
high quality iris images so that later in testing stage
we can use this dictionary to hallucinate iris images
when we get a new testing image.
In our experiment, the high quality images are
captured by iris image sensor PIER 2.3
(Securimetrics pier device, securiMetrics Inc.) and
169
Zheng B., Ji D. and Li Y..
Cross-Sensor Iris Matching using Patch-based Hybrid Dictionary Learning.
DOI: 10.5220/0004868401690174
In Proceedings of the 16th International Conference on Enterprise Information Systems (ICEIS-2014), pages 169-174
ISBN: 978-989-758-028-4
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)
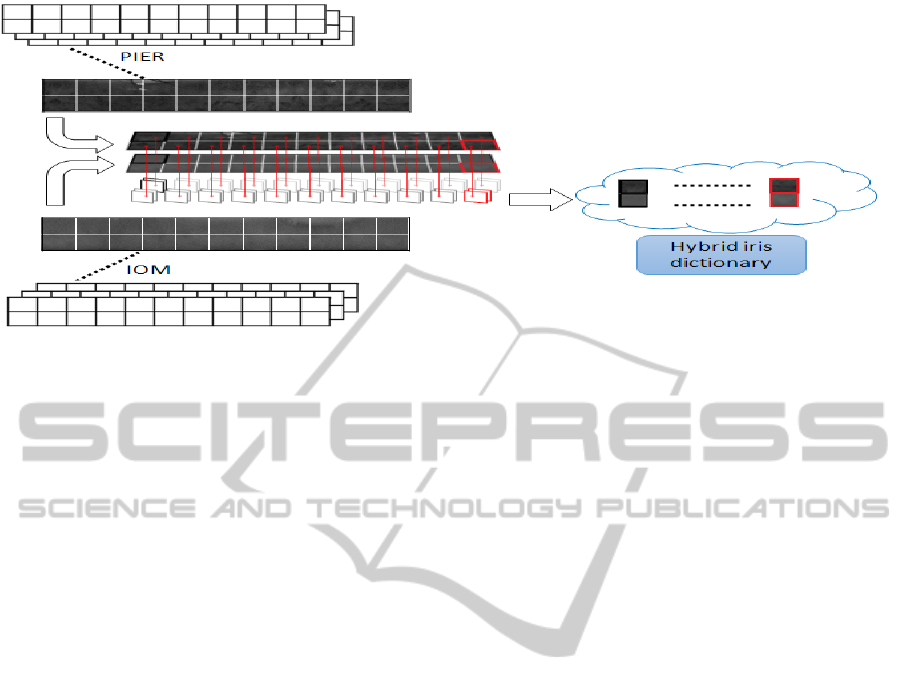
Figure 1: Illustration of experimental procedure during training stage.
the low quality images are captured by Iris-On-the-
Move system (IOM) (Matey et al., 2006). Training
data consists of a pair of PIER and IOM images
from each subject, for all subjects in the database.
We will assume that in the training stage, we
have corresponding image pairs captured from PIER
and IOM, respectively. In the test stage, we assume
that the test images are captured by IOM. Thus, the
targeted problem becomes, given test IOM image
(low quality), how to hallucinate its corresponding
image that looks as if it is captured by PIER (high
quality)?
In training stage, we perform the following steps.
First, given a pair of hybrid iris training images we
perform global alignment. A pair of hybrid iris
database that consists of two iris image sets,
captured by two iris image sensors A and B, we
denote these two datasets
and
. Specifically,
,
,…,
(1)
,
,…,
(2)
where
and
denotes the k
th
iris images in
image set
and
, respectively.
Second, hybrid iris training images are divided into
local patches. The patch-based hybrid iris database
is represented as P
A
and P
B
.
,
,…,
(3)
,
,…,
(4)
where
and
denotes the k
th
iris images
patch in image set
and
, respectively. Note
that N>>M.
Third, a hybrid dictionary comprises iris patches.
In this stage, we create a new hybrid patch set Θ
from
and
. Specifically,
Θ
,∀1
(5)
The set Θ can be viewed as iris image patch set in a
hybrid space, which is composed by combining
image patches from different optical sensors.
Therefore, in this work, we call Θ as “hybrid iris
dictionary”. Patches that belong to the same location
would be stored in the corresponding hybrid iris
dictionary. Figure 1 gives us a graphical illustration
of experimental procedure during training stage.
2.2 Testing Stage
During the test stage, we perform the following steps.
First, given a test iris image
captured by image
sensor B, our goal is to hallucinate its corresponding
image
so that it looks as if it is captured by
sensor A and has the same image quality as all
images in set
. Here the basic assumption is that
the image quality of set
is much higher than that
of
, therefore, in order to achieve higher
recognition rate, it is highly desired to hallucinate
based on the given image
.
Second, the given test image
is broken into
overlapped patches. We use sparse representation to
decompose each test patch
as a linear
combination of dictionary atoms. In mathematical
form, it can be described as:
min
‖
‖
‖
‖
(6)
The dictionary D in (6) comes from the lower
parts of the hybrid iris dictionary. According to
(Davis et al., 1997) (Pati et al., 1993), the coefficient
i
can be calculated by using Orthogonal Matching
Pursuit (OMP). The coefficient
contains
information indicating which atoms in D should be
used to reconstruct
, under the constraint that
the number of the reconstruction atoms is minimized.
ICEIS2014-16thInternationalConferenceonEnterpriseInformationSystems
170
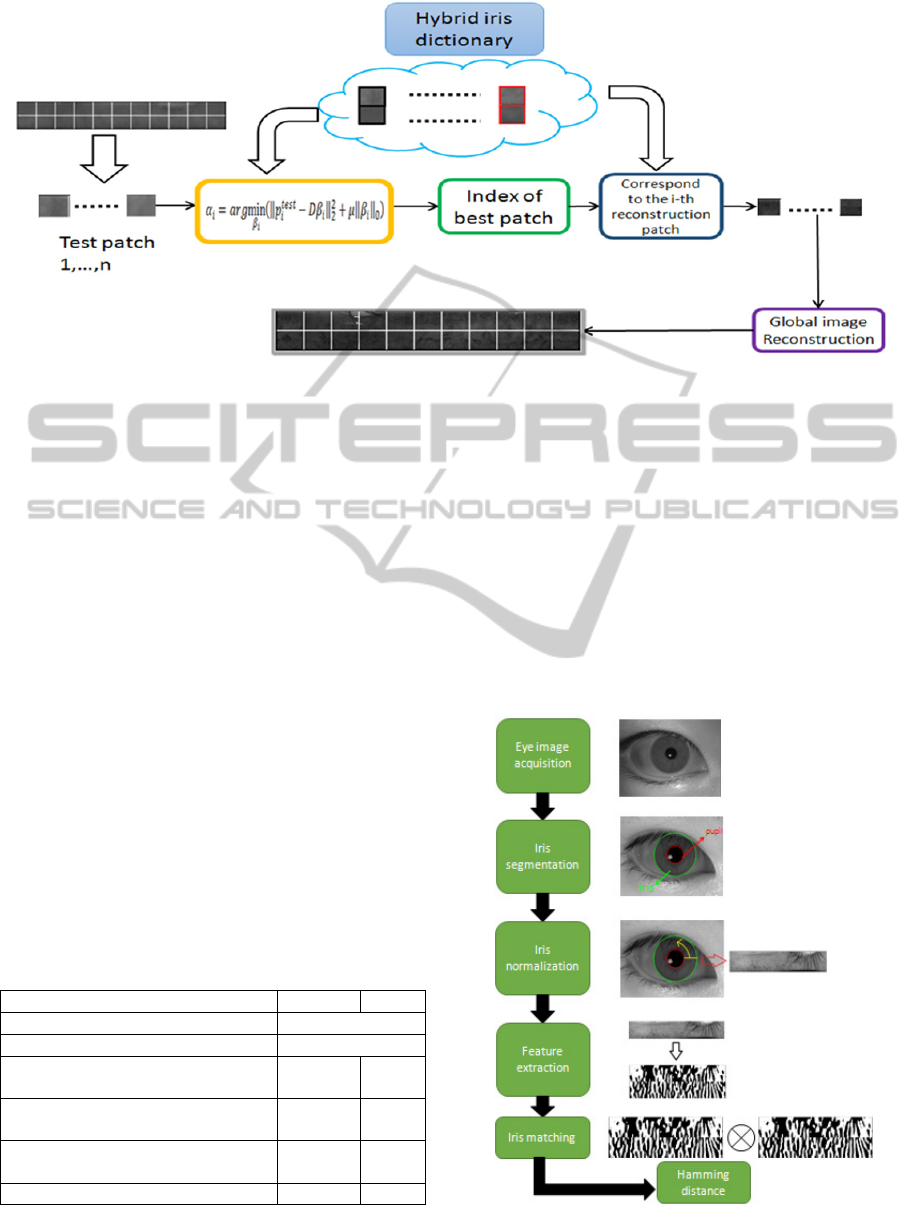
Figure 2: Illustration of experimental procedure during testing stage.
Therefore, we can look for which element in
i
has the highest value, and the index of this
element represent the index of the training patch
which has the highest resemblance to
in hybrid
iris dictionary. Suppose the index of the element
with the largest value in
is j, then we are
confident to declare that the atom
has the highest
resemblance to
. Using
which is the
counterpart of
in the upper part of the
heterogeneous dictionary Θ to represent
in
reconstructed space, and continuing applying such
method ∀1 , we can hallucinate the
corresponding high quality
using global image
reconstruction. Figure 2 illustrates the proposed
procedure during the testing stage. A testing image
belongs to low quality iris image captured by IOM
device is divided into a set of patches. Remember
that the size of the test patch must be consistent with
the size of the training patch in the hybrid iris
dictionary.
Table 1: Statistics about IOM and PIER.
Database Properties IOM PIER
Number of Iris Classes 111
Size of the Picture 640x480
Maximal Number of Images Per
Subject
54 3
Minimal Number of Images Per
Subject
10 3
Average Number of Images Per
Subject
24 3
Total Number of Images 2682 333
3 EXPERIMENT
3.1 A Typical Iris Recognition System
The process of a typical iris recognition system
consists of following stages: (1) Eye image
acquisition, (2) iris segmentation, (3) iris
normalization, (4) feature extraction, (5) iris
matching, and (6) calculate hamming distance.
Figure 3 shows the flow chart of a typical iris
recognition system.
Figure 3: The flow chart of the process of a typical iris
recognition system.
Cross-SensorIrisMatchingusingPatch-basedHybridDictionaryLearning
171
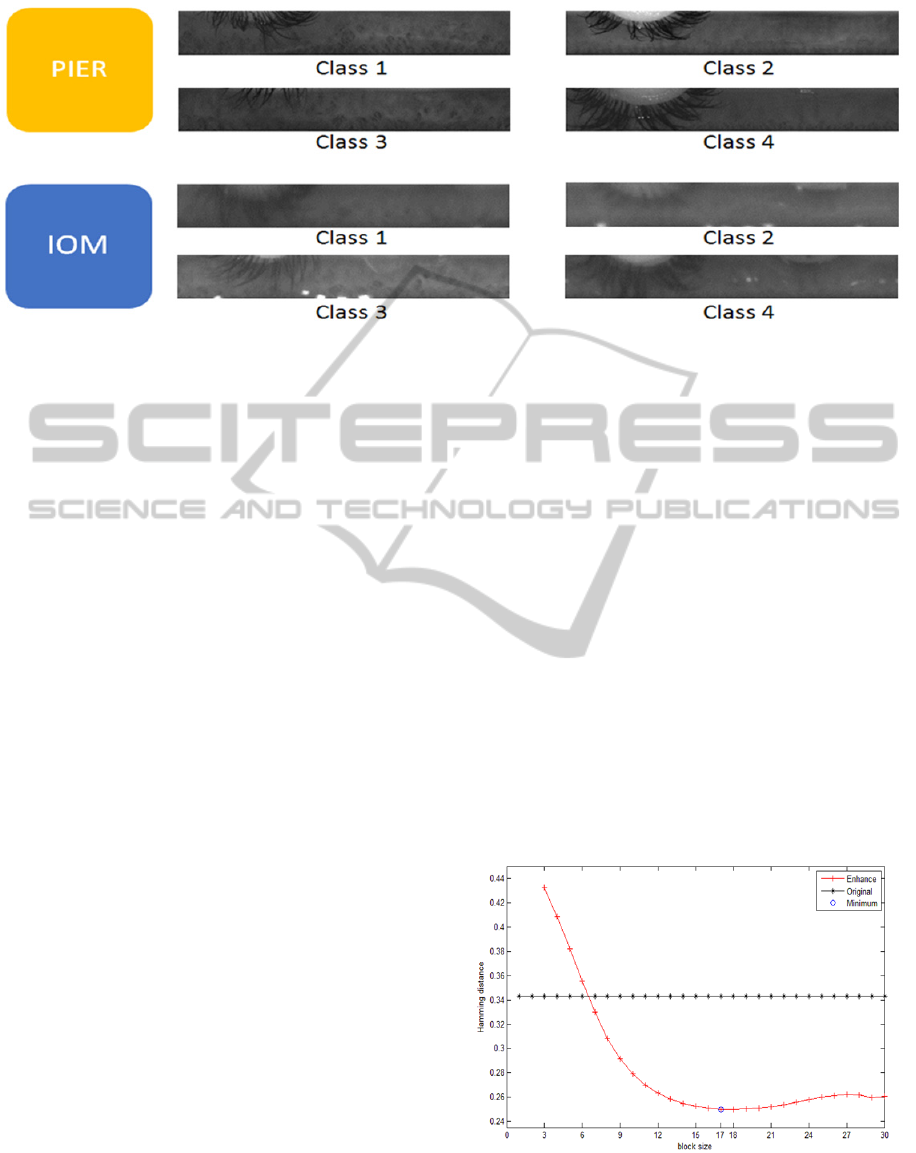
Figure 4: Illustration of the same iris class image captured by the PIER and IOM devices.
3.2 Database
In order to measure the iris recognition performance
based on the proposed patch-based hybrid dictionary
learning algorithm, experiments have to be
performed on databases which contain both high
quality and low quality iris images for the same iris
class. The database we used in our experiment
collected at Carnegie Mellon University during
March and April in 2009. The iris images are
captured by two kinds of iris acquisition devices: 1)
IOM (Matey et al., 2006), whose image quality is
low; 2) SecuriMetrics PIER 2.3 (Securimetrics pier
Device), whose image quality is better than IOM.
The details of the IOM and PIER database are given
in Table 1. Figure 4 illustrates the same iris class
image captured by the PIER and IOM devices.
From Figure 4, we can discover that the quality of
iris images captured by the PIER device is much
higher than that of iris images captured by the IOM
device in the same class.
3.3 Procedures
For training data, we choose the second picture of
PIER images and the third picture of IOM images
for each class. Therefore, we have a set of PIER iris
images
,
,…,
,
and a set of corresponding
IOM iris images
,
,…,
, where
and
is
column vector, derived from the
th
i
PIER and IOM
iris images, respectively. For test data, we choose all
IOM iris images except the third picture for each iris
class. We do following steps:
(1) All both training data and test data will be pre-
segmented and normalized to the size of 30x180.
(2) All training images are divided into patches and
stored in the corresponding hybrid dictionary.
(3) Let the set of the lower parts (captured by IOM
device) of each atom in the hybrid dictionary as
the dictionary
D of sparse representation.
(4) A test image can is divided into patches,
represented as
i
x
.
(5) Use OMP to calculate the coefficient
i
.
(6) Find the index of the best patch by locating the
highest value in
i
(7) Find the corresponding patch location, which
belong to upper parts captured by PIER device
in the hybrid dictionary.
(8) Corresponding patches of
i
y
will replace the
original test patches of
i
x
.
(9) Synthesize the high quality iris image by global
image reconstruction.
3.4 Results
Figure 5: Experimental result of patch size optimization.
ICEIS2014-16thInternationalConferenceonEnterpriseInformationSystems
172
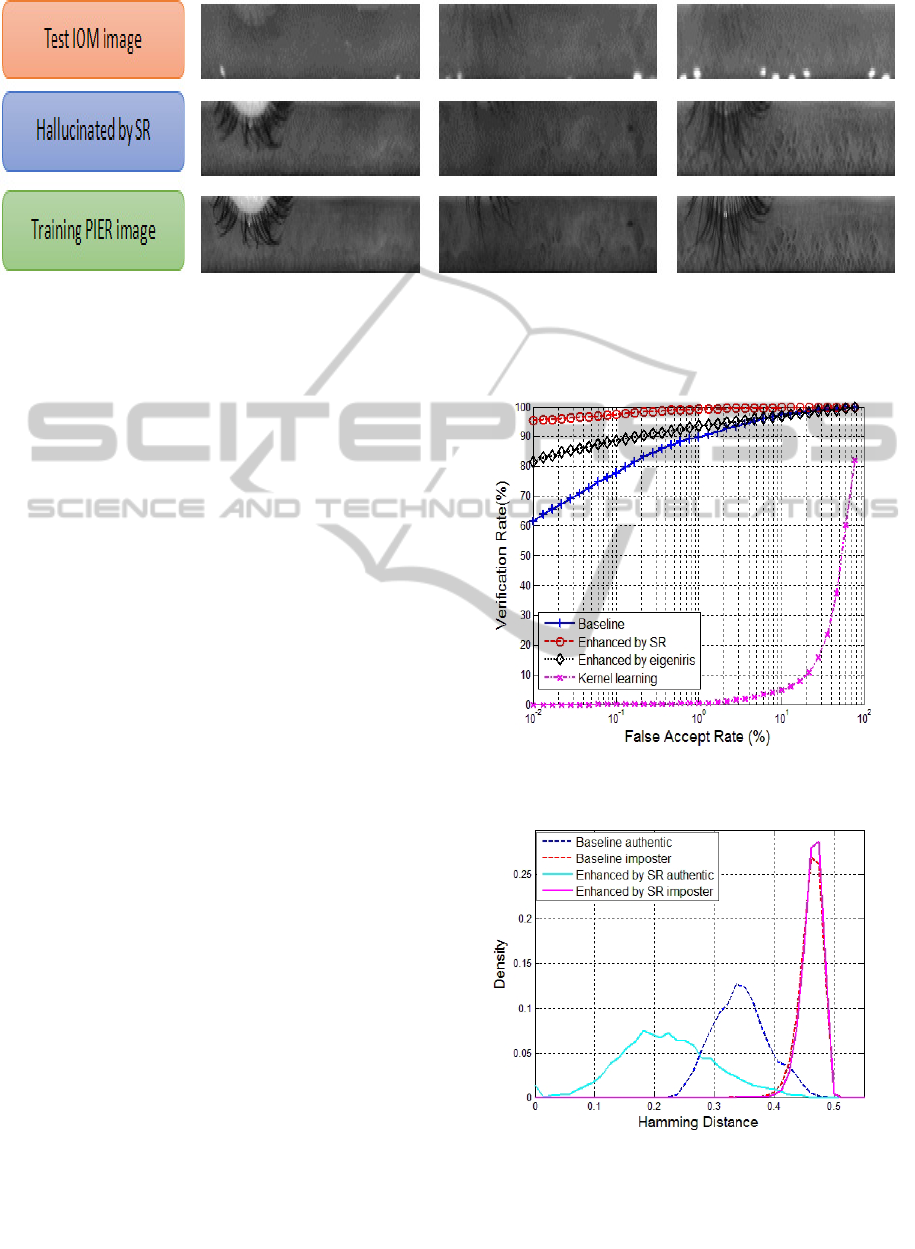
Figure 8: Illustration of experimental procedure during testing stage.
Because all training and test images are divided into
patches, the size of the patch may affect the
performance.
In order to analyze the accuracy of the size for
patch, we perform an experiment of patch size
optimization. The size of test patch ranges from 3x3
to 30x30 in the iris images. The value of Hamming
Distance (HD) for the training and testing matching
varies in different sizes as shown in Figure 5. We
can see that the best patch size for the proposed
method is 17x17, where HD reaches its minima.
In Figure 6, there are ROC curves that are based
on four different methods. The four algorithms and
experimental conditions we compared are
1. Gallery set: PIER images; probe set: IOM
images without any enhancement. This result
is served as “baseline”.
2. Gallery set: PIER images; probe set: IOM
images transformed by the eigeniris method
(which can be called hybrid subspace method
as well), as proposed in the work in (Li and
Savvides 2006).
3. Gallery set: PIER images; probe set: IOM
images. The matching score (normalized
Hamming distance) is adapted and
transformed using kernel learning method
(Pillai et al., 2014).
4. The proposed method using sparse
representation.
The blue curve represents the iris recognition
performance when directly matching training and
testing images without using any algorithm to
improve iris image quality. The red curve represents
the recognition performance after using the proposed
patch-based hybrid iris dictionary learning method
to enhance the test image quality. The black curve
shows the recognition performance after using
hybrid subspace method (Li and Savvides, 2006) to
hallucinate the image. The pink curve shows the
recognition performance after using kernel learning
(Pillai et al., 2014).
Figure 6: ROC curves comparison of the baseline ,
eigeniris, kernel learning, and the proposed method.
Figure 7: HD distribution of the large-scale iris
recognition experiment under baseline and the proposed
method.
We can see that when FAR =
2
10
%, the
Cross-SensorIrisMatchingusingPatch-basedHybridDictionaryLearning
173

verification rate of the proposed method achieves
95.45% which is superior than that of eigeniris about
81.57% and that of baseline about 61.48%, as show
in Figure 6. Moreover, we discover that the kernel
learning method in the cross-sensor iris matching
problem can not exhibit high recognition
performance.
Figure 7 shows the histogram of HD distribution
for the authentic and impostor comparison, before
(baseline) and after applying the proposed method.
We can see that the authentic score distribution
obviously being moved toward left side, while the
imposter score distribution remains almost the same.
Moreover, the EER of the proposed method achieves
0.8576%, compared to EER=4.7726% in the
baseline experiment. The results show that the two
distributions are moved further away from each
other, demonstrating the effectiveness of the
proposed method.
Figure 8 shows the example iris images
hallucinated by the proposed methods SR
(heterogeneous dictionary learning method using
sparse representation). From these three examples,
given test IOM image whose quality is low, we can
see that hybrid iris dictionary learning method using
sparse representation can synthesize high quality
image that look as if it is captured by the PIER
device.
4 CONCLUSIONS
In this paper, we propose a novel patch-based hybrid
iris dictionary learning method using sparse
representation to approach the issue of cross-sensor
iris matching. The proposed method achieves better
recognition performance for two situations: 1) the
iris images for training and testing are acquired by
different iris image sensors; 2) the training set
images have higher quality while the test images
have lower quality. Furthermore, the experimental
results shows the proposed method successfully
enhance the iris recognition performance in terms of
EER and separability of Hamming distance
distribution, as shown in Figure 6 and 7. Future
work includes using more delicate algorithm (for
example, k-SVD) for dictionary atom update and
collecting more heterogeneous iris images for large-
scale experiment.
ACKNOWLEDGEMENTS
This work was financially supported by the National
Science Council of Taiwan under contract no. NSC
102-2221-E-008 -115.
REFERENCES
K. W. Bowyer, 2008, K. Hollingsworth, and P. J. Flynn,
Image understanding for iris biometrics: A survey,
Computer Vision and Image Understanding, vol.110,
no.2, pp. 281-307.
K. Bowyer, S. Baker, A. Hentz, K. Hollingsworth, T.
Peters, and P. Flynn, 2009, Factors that degrade the
match distribution in iris biometrics, Identity in the
information Society, vol.2, no.3, pp. 327-343.
R. Connaughton, A. Sgroi, K. W. Bowyer, and P. J. Flynn,
2011, A cross-sensor evaluation of three commercial
iris cameras for iris biometrics, IEEE Computer
Society Workshop on Biometrics, pp. 90-97.
Pillai, M. Puertas, and R. Chellappa, 2014, "Cross-sensor
Iris Recognition through Kernel Learning," IEEE
Transactions on Pattern Analysis and Machine
Intelligence, vol.36, no. 1, pp. 73-85.
K. Q. Weinberger, F. Sha, and L. K. Saul, 2004, Learning
a kernel Matrix for nonlinear dimensionality reduction,
International Conference on Machine learning,
pp.839-846.
Y. Li, M. Savvides, and V. Bhagavatula, 2006,
Illumination Tolerant Face Recognition Using a Novel
Face From Sketch Synthesis Approach and Advanced
Correlation Filters, 2006 IEEE International
Conference on Acoustics, Speech and Signal
Processing, 2006. ICASSP 2006 Proceedings, vol.2,
no., pp. II, II, 14-19.
Y. Li and M. Savvides, 2006, Faces from sketches: a
subspace synthesis approach, Defense and Security
Symposium. International Society for Optics and
Photonics.
Securimetrics pier device, securiMetrics Inc., http://
www.securimetrics.com/solutions/pier.html.
J. Matey, O. Naroditsky, K. Hanna, R. Kolczynski, D.
LoIacono, S. Mangru, M. tinker, T.Zappia, and W.
Zhao, 2006, Iris on the move: Acquisition of images
for iris recognition in less constrained environments,
Proceedings of the IEEE, vol. 94, no.11, pp. 1936-
1947.
G. Davis, S. Mallat, and M. Avellaneda, Adaptive Greedy
Approximations, Constructive Approximation, vol. 13,
no. 1, pp.57-98, 1997.
Y. Pati, R. Rezaiifar, and P. Krihnaprassad, Orthogonal
Matching Pursuit: Recursive Function Approximation
with Applications to Wavelet Decomposition,
Conference Record of The Twenty-Seventh Asilomar
Conference on Signals, Systems and Computers, pp.
40-44, 1993.
ICEIS2014-16thInternationalConferenceonEnterpriseInformationSystems
174
