Modeling the Serial Position Effect
Using the Emergent Neural Network Simulation System
Katherine Goodman
and John K. Bennett
ATLAS Institute, University of Colorado Boulder, Boulder, CO, U.S.A.
Key
words: Serial Position Effect (SPE), Primacy, Recency, Hippocampus, Emergent Neural Network Simulation
System, Leabra, Serial Recall, Working Memory.
Abstract: The Serial Position Effect (SPE) is a well-studied phenomenon in experimental psychology. SPE captures
the idea that, when subjects are asked to recall list items, they are more likely to remember the first items
and the last items, whether those items are numbers, non-words or elements of a story. Until recently, SPE
has been generally considered to rely upon a two-store memory model, i.e., primacy (remembering initial
items) and recency (remembering latter items) were thought to be the work of long term memory and short
term memory, respectively. This paper reports the results of a basic hippocampus simulation study using the
Leabra algorithm within the Emergent Neural Network Simulation System to model the SPE. Simulation
results demonstrate that both primacy and recency of the SPE in a serial recall task can be replicated using
only the hippocampus, suggesting that a one-store model of memory for this recall task is sufficient. It
remains to be seen if this simulation mirrors the actual biological mechanism utilized.
1 INTRODUCTION
In the process of investigating memory and learning,
neuroscientists and their predecessors have
discovered a number of memory biases that offer
clues as to the biological functioning of our brains
during memory and learning tasks. One such
memory bias is the Serial Position Effect (SPE), first
documented by Hermann Ebbinghaus in his seminal
work, Memory (1885/1913). SPE is a memory bias
for remembering early and late items in a list, and a
bias against recall of items from the middle. The
SPE is well-documented, with behavioural data
relating to remembering non-words (Gupta, 2005),
number sequences (Golob and Starr, 2004), and even
stories (Brodsky et al., 2003). The SPE has been
well-studied among healthy adults, and has also
been used to better understand child development
(Lehmann & Hasselhorn, 2010), aphasia (Brodsky et
al., 2003) and Alzheimer’s Disease (Bayley et al.,
2000).
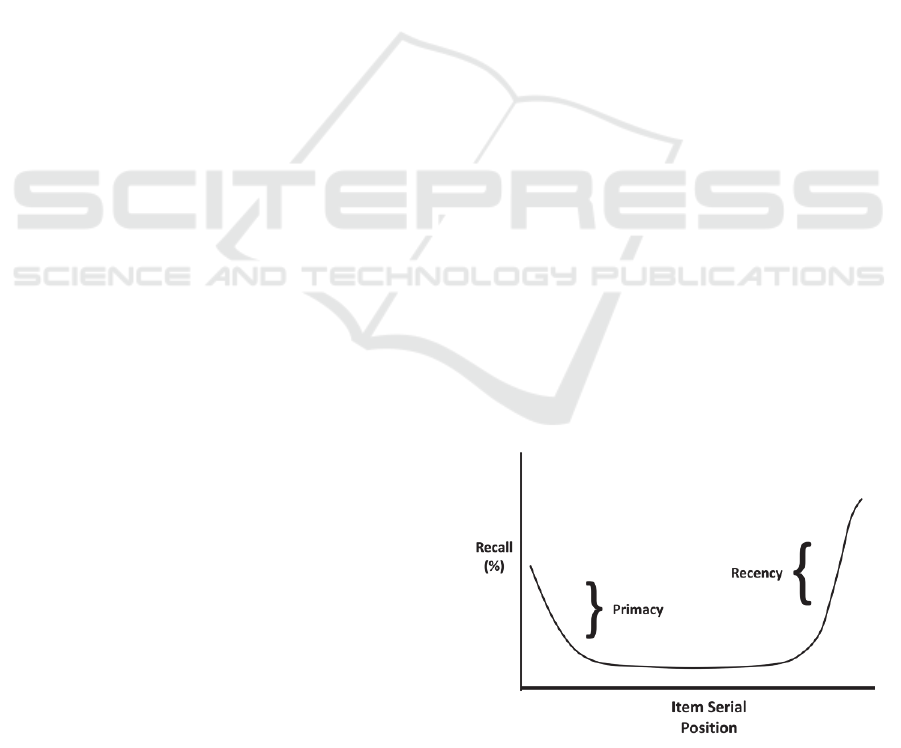
The classic graph of serial position data has the
U-shape shown in Figure 1. The early and late
effects are usually handled separately as primacy
and recency, as depicted in Figure 1. Some
researchers, dating back to at least Murdock (1962),
assign separate biological mechanisms for primacy
and recency, rather than one overall mechanism for
the SPE.
Figure 1: The Serial Position Effect Classic U Shape.
The two-store memory model has different
variations, but generally assigns primacy to a long-
term memory mechanism and recency to a short-
term memory mechanism. Gradually, short-term
memory has been replaced by the more complete
term working memory, referring to both the short-
term memory (storage) of information and the
manipulation of that information, which is required
by tasks such as serial recall, used to test SPE
(Baddeley & Hitch, 2010).
164
Goodman K. and K. Bennett J..
Modeling the Serial Position Effect - Using the Emergent Neural Network Simulation System.
DOI: 10.5220/0004802701640171
In Proceedings of the International Conference on Bioinformatics Models, Methods and Algorithms (BIOINFORMATICS-2014), pages 164-171
ISBN: 978-989-758-012-3
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

Differences in how well human subjects recall
items under various conditions, e.g., lag time
between training and testing, appear to support the
two-store models, since the variable conditions
affected primacy and recency to varying degrees. A
common argument for long-term memory being the
mechanism for primacy is the idea of rehearsal. As
subjects learn each item in the list, there may be the
opportunity to mentally repeat, or rehearse, the early
items in the list, making them more likely to be
committed to long term memory. (In fact, some
studies have required subjects to rehearse items
aloud.) Rehearsal is believed to transfer the items
into long term memory.
Recency, in terms of the SPE, is often argued to
be a result of the quick recall possible from working
memory, but this does not account for long-term
recency – that is, better recall of ending items in a
list after hours or even days (Howard & Kahana,
1999), or the various effects involving the ratio rule,
which “relates the recency effect in free recall to the
ratio of the duration of the inter-item presentation
interval (IPI) and the retention interval (RI)”
(Nairne, et al., 1997).
Newer understanding of the role of contextual
cues in memory tasks has strengthened support for a
one-store memory model, which can account for
both primacy and recency in the SPE (Polyn &
Kahana, 2008). Researchers are refining
computational models to explore these possible
mechanisms. For example, Sederberg et al. (2011)
explore the memory phenomenon of reconsolidation
using a “Temporal Context Model,” including
predictions regarding the SPE (p. 466). However, as
recently as 2008, there was still debate as to what,
exactly, these computational models represent. For
example, Usher, Davelaar, Haarmann, and Goshen-
Gottstein (2008) disputed Polyn and Kahana’s
results, to which Kahana, Sederberg, & Howard
(2008) replied, reasserting the validity of these
results.
To test these ideas, we developed a basic
hippocampus simulation study using the Emergent
Neural Network Simulation System to model the
SPE. The remainder of this paper describes this
experiment and its results. We observed that both
primacy and recency of the SPE in a serial recall
task can be replicated using only the hippocampus,
suggesting that a one-store model of memory for this
recall task is sufficient.
2 METHODOLOGY
2.1 General Approach
We tested the one-memory vs. two-memory SPE
theory using the Emergent neural modeling system.
Emergent is “a powerful tool for the simulation of
biologically plausible, complex neural systems”
(Aisa, Mingus, & O’Reilly, 2008, p. 1146), making
it a good tool for exploring the biological
mechanisms conjectured for various phenomena,
including SPE.
Biologically, working memory is associated with
active maintenance in the Prefrontal Cortex (PFC),
while encoding long term memories is more closely
associated with the hippocampus (O’Reilly et al.,
2012). We used the basic hippocampus simulation in
Emergent, and looked for differences in primacy and
recency effects that might suggest a difference in
underlying memory mechanisms. If primacy and
recency have similar biological mechanisms (such as
a one-store memory model would suggest), we
predicted that using only the hippocampus would
show both effects, while finding only one effect
(likely primacy) would tend to support the two-store
model.
2.1.1 Using Emergent
The Emergent Neural Network Simulation System
(Emergent) is “a powerful tool for the simulation of
biologically plausible, complex neural systems”
(Aisa, Mingus, & O’Reilly, 2008, p. 1146), making
it a useful tool for exploring the biological
mechanisms conjectured for various phenomena,
including SPE.
Emergent is a computational tool for modeling
the human brain and cognitive processes, intended
for use in both research and teaching. It is based in
part on its predecessors PDP and PDP++ (Parallel
Distributed Processing).
Using neural networks, Emergent allows users to
develop complex, layered system models, such as
those that might represent the human cognitive
processes, in order to test different theories about
how the brain functions. This process generally
involves training the network on sets of data, and
then testing the network on that data. The Emergent
graphical interface allows users to see each layer of
the model, in which “units” (colored squares
representing neurons or groups of neurons) are
activated, as well as projections between layers.
In Emergent, biologically-based models can be
built relatively quickly and tested against data from
ModelingtheSerialPositionEffect-UsingtheEmergentNeuralNetworkSimulationSystem
165

experimental psychology. For example, O’Reilly et
al. (2013) developed an object recognition model
within Emergent with layers and projections based
upon the relevant visual pathways in the brain. This
model, using biologically plausible learning
mechanisms, consistently recognizes 100 different
object categories, each with around 9 exemplars,
even with variations in lighting, location in the field
of vision, size, and rotation. This particular model
was also able to recognize partially occluded
objects.
For the purposes of teaching, the Emergent
website features a wikibook called Computational
Cognitive Neuroscience, that includes sample
simulations for each chapter (O’Reilly et al., 2012),
in the form of project files (*.proj). The research
reported here utilizes the available hippocampus
model, hipp.proj.
2.1.2 Leabra
The default algorithm in Emergent is called Leabra,
or local error-driven and biologically realistic
algorithm, initially developed by O’Reilly (1997).
This algorithm balances Hebbian and error-driven
learning. Leabra uses a variant of Hebbian learning
called self-organized learning, which is sometimes
characterized as ‘what fires together, wires
together,’ referring to the ability to learn
generalities. Error-driven learning in Leabra is based
upon the eXtended Contrastive Attractor Learning
(XCAL) rule that communicates error signals
through the network bidirectionally (O’Reilly et al.,
2012).
These two types of learning are layered over “a
biologically-based point-neuron activation function
with inhibitory competition dynamics” (O’Reilly et
al., 2012). These competition dynamics can be
implemented with kWTA (k-Winners-Take-All)
approximations or through inhibitory interneurons.
We utilized the kWTA approximations in this
project.
2.2 Methodology
We employed Emergent Version 6.1.0 and the basic
version of the hippocampus simulation that
accompanied the software (O’Reilly et al., 2012).
Figure 2 shows the layout of this simulation with
inputs from the Entorhinal Cortex (EC) going to the
Dentate Gyrus (DG) and to the different layers of the
cornu ammonis or CA, with outputs going to the EC
Output layer. A full list of the connections is
provided in Table 1.
Table 1: Connections Between the Layers in the
Hippocampus Simulation.
Layer
SendsTo ReceivesFrom
Input EC_in (none)
EC_in DG,CA1,CA3 Input,EC_out
DG CA3 EC_in
CA3 CA1,DG EC_in,DG
CA1 EC_out EC_in,CA3
EC_out EC_in CA1,EC_in
2.3 Design of the Baseline Simulation
Our experiments began with the hippocampus
simulation (hipp.proj). This basic simulation is
designed to train the network on the classic AB-AC
paired associate list learning task. This task is
particularly useful because it has been well-studied
in human experimentation (e.g. Barnes &
Underwood, 1959), and it caused difficulties for
early neural network models. As McCloskey and
Cohen showed, neural networks relying on back-
propagation experience catastrophic interference on
the AB-AC learning task (1989).
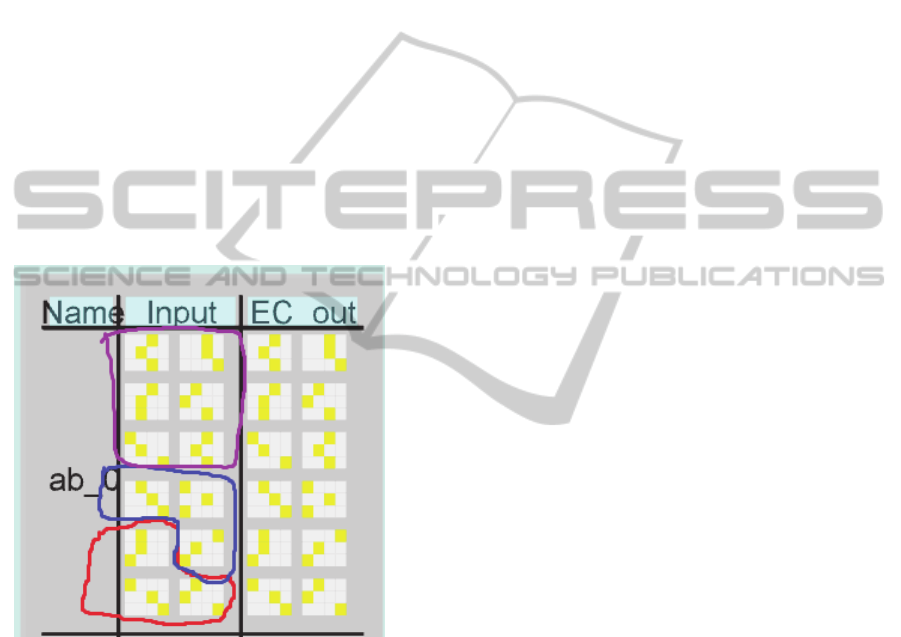
Figure 2: The basic hippocampus simulation within
Emergent. The Input Layer feeds directly into the
Entorhinal input layer (EC_in), which is encoded by the
Dentate Gryus (DG), the cornu ammonis area 3 (CA3),
and CA1. Memory retrieval is driven by connections from
CA1 back to the EC_out.
As initially designed, the simulation is trained on a
list of ten AB pairs (labeled ab_0 through ab_9) in
BIOINFORMATICS2014-InternationalConferenceonBioinformaticsModels,MethodsandAlgorithms
166
three sets of trials, then tested on those pairs by
removing the B units and allowing the network to
attempt to fill them in (see Figure 3).
That test is followed by the AC list and set of
novel lure items, to verify that the network is still
reacting as expected to new inputs. This full cycle
(three sets of training trials, one set of tests each for
AB, AC, and lure) is considered an epoch. For the
purposes of our experiments, time tested on the AC
list and lure items represented a time lag between
training on the AB list and recall of that list.
Because of that time lag and because the A items
are always presented in the original order, these
experiments mimic the serial delayed recall task, in
contrast to free recall and immediate recall. Weights
were initialized before starting each experiment. The
simulation was run for ten epochs.
Data sets for subsequent experiments were
manipulated by exporting the original dataset into a
spreadsheet, manually editing the AB context sets,
and importing the changed file into the model.
Figure 3: A single input AB pair within Emergent. A items
are circled in red; B items are circled in blue. During
memory retrieval, B items will be blank, and recalled (if
possible) from CA1 via EC_out . The top six groups of
units (circled in purple) are context. During baseline trials,
these were unique for each AB pair. Experiment 1 made
the context identical for all pairs except ab_0 and ab_9.
Experiment 2 made the context identical for sets of pairs,
while context for ab_0 and ab_9 remained unique.
2.4 Baseline – Unique Contexts
The simulation was run using the input data
“Train_AB” available within the simulation. After
opening the project file within Emergent, the
network weights were initialized. We used the
Step:Epoch function so that we could note results
after each epoch. On the third epoch, the network
had learned the AB list. We ran a total of ten epochs
to have a fair basis of comparison across
experiments.
2.5 Experiment 1 – Full Overlap
of Middle Contexts
The Train_AB input data file was copied from the
project file. Leaving the A and B inputs untouched,
the groups of context units were altered such that
ab_1 through ab_8 had the same context. Items ab_0
and ab_9 were unaltered. After uploading the new
data table into the project, the weights were
initialized, and we used the Step: Epoch function as
before for ten epochs.
2.6 Experiment 2 – Partial Overlap
of Middle Contexts
The Train_AB input data file was copied from the
project file. Leaving the A and B inputs untouched,
the context units were altered such that pairs of trials
now had the same context. For example, ab_1 and
ab_2 had the same context, ab_3 and ab_4 had the
same context, and so on. Items ab_0 and ab_9 were
unaltered. After uploading the new data table into
the project, the weights were initialized, and we used
the Step: Epoch function as before for ten epochs.
2.7 Experiment 3 – Full Overlap
of First Eight Contexts
At this point, we wanted to see if the order of the
items during testing was having any effect on the
results, or if results were from the uniqueness of the
contexts alone. In order to test whether being first
and last was truly having an effect in the network,
we took the data from Experiment 1, and simply
moved ab_0 to the end of the data set, relabeling the
items to match their new position. Thus, ab_0
through ab_7 now had identical contexts, ab_8 and
ab_9 were unique. As before, we initialized the
activation weights in the network and used the
Step:Epoch function to run ten epochs.
2.8 Experiment 4 – Permuted Full
Overlap
Finally, for comparison, we ran the same data as in
Experiment 1, with the data loop order parameter
changed from sequential to permuted. That is, during
testing trials, the items would be presented in a
different order from that of the training trials, thus
ModelingtheSerialPositionEffect-UsingtheEmergentNeuralNetworkSimulationSystem
167
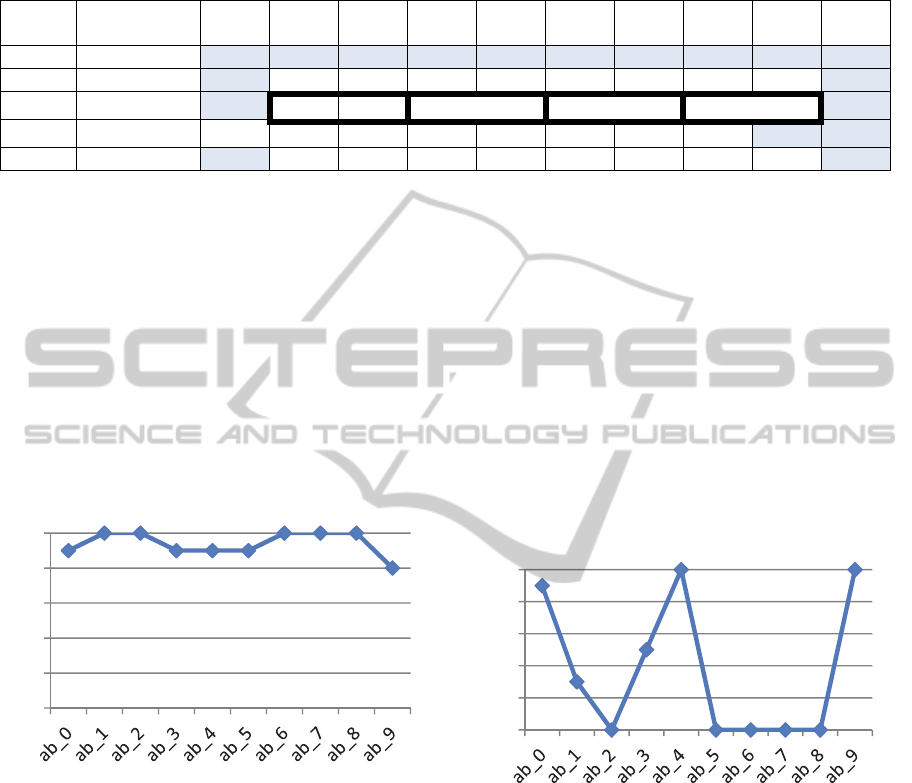
Table 2: For each experiment, the first column represents how well the network learned the AB list overall. Subsequent
columns show how often the network remembered the B portion of the AB pair out of 10 epochs (trials). Shaded cells
represent items with unique context. In Experiment 2, dark outlines group the items with duplicate context.
Best Epoch
Score
ab_0 ab_1 ab_2 ab_3 ab_4 ab_5 ab_6 ab_7 ab_8 ab_9
Baseline 100% 9 10 10 9 9 9 10 10 10 8
Exp.1 50% 9 3 0 5 10 0 0 0 0 10
Exp.2 70% 9 8 2 10 0 9 1 7 6 8
Exp.3 70% 9 8 2 6 3 4 0 0 0 10
Exp.4 50% 9 3 2 3 10 0 0 0 0 10
simulating a free recall task. As before, we
initialized the activation weights in the network and
used the Step:Epoch function to run ten epochs.
3 RESULTS
Results are summarized in Table 2. The baseline
version of the simulation was able to perfectly
remember the AB list by the third epoch. The last
list item (ab_9) was the last item learned. The graph
is almost the inverse of the classic SPE U-shape (see
Figure 4).
Figure 4: Results by list item pair for baseline simulation,
percent recalled. Each ab had unique context. Note that
ab_9 was the last item learned.
In Experiment 1, the simulation ran for ten epochs.
The highest percentage remembered correctly for
any given epoch was 50%, so at no time did it
achieve perfect recall, which the baseline simulation
did in three epochs. However, far more important in
understanding the SPE, were the results by list item
(see Figure 5). Here we see that the first and last
items (which had unique context) are more often
remembered than any item, with exception of ab_4.
Both primacy and recency effects were replicated by
this experiment.
In Experiment 2, the simulation ran for ten
epochs. The highest percentage remembered
correctly for any given epoch was 70%, an
improvement over Experiment 1, perhaps due to the
lower overlap in contexts. In terms of understanding
the SPE, the pairs sharing context exhibited an
interesting pattern (see Figure 6). Again, ab_0 and
ab_9 were recalled significantly more than the
overall average, 9/10 and 8/10 respectively, in
contrast to 5.4/10. Also, the initial trial in each pair
of identical-context trials outperformed the second
in every case. In the most extreme case, ab_3 was
recalled correctly in all 10 epochs, whereas ab_4
was never recalled. Again, primacy and recency
effects were replicated here, albeit complicated by
the strong results from each initial item in the same-
context paired trials.
Figure 5: Percent recalled by list item pair for Experiment
1, with all middle items having identical context.
In Experiment 3, the highest percentage remembered
correctly for any of the ten epochs was 70%, the
same result as Experiment 2. Once again ab_0 and
ab_9 were recalled better than other items, 9/10 and
10/10, in contrast to the overall average of 4.2/10
(See Figure 7.) As the first of the group of context-
overlapping items, recall of ab_0 appeared to
correspond with the results of Experiment 2, where
the first of each pair was recalled more often than
the second. What was unexpected was the network’s
complete failure to recall item ab_8 (which had a
unique context). Again, primacy and recency effects
were replicated, but the effect of unique context was
0
0,2
0,4
0,6
0,8
1
0
0,2
0,4
0,6
0,8
1
BIOINFORMATICS2014-InternationalConferenceonBioinformaticsModels,MethodsandAlgorithms
168
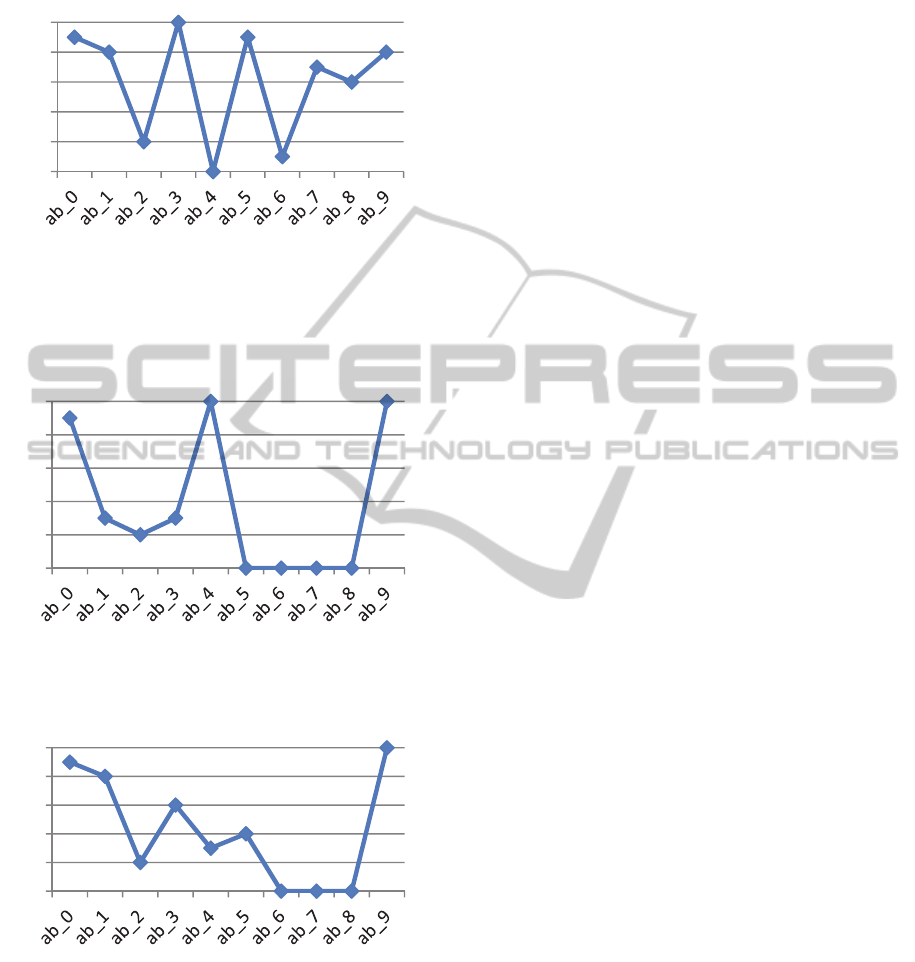
contradicted by the failure to recall uniquely-
contexted item ab_8.
Figure 6: Percentage of times recalled, by item for
Experiment 2, with context identical for pairs of trials.
Notice that the first of each pair is remembered more
easily than the second. For instance, ab_3 and ab_4 have
identical contexts; ab_3 was recalled in every epoch; ab_4
was never recalled.
Figure 7: Percent recalled in Experiment 3. Items ab_0 –
ab_7 had identical context. Notice that ab_8, with unique
context, is never recalled.
Figure 8: Percent recalled in the permuted order –
Experiment 4, simulating free recall. Only ab_0 and ab_9
had unique context.
In Experiment 4, the simulation ran for ten epochs.
Similar to Experiment 1, ab_0 and ab_9 had unique
contexts while ab-1 though ab_8 had identical
contexts. In contrast to the other experiments,
Experiment 4 had permuted testing order to simulate
free recall (see Figure 8). The highest percentage
remembered correctly for any given epoch was 50%,
making it similar to Experiment 1. The three best
recalled items were ab_0 (9/10), ab_4 (10/10) and
ab_9 (10/10), with the overall average as 3.7/10.
This suggests that uniqueness of contexts did
improve recall, in contrast to the results of
Experiment 3.
4 DISCUSSION
These results demonstrate that both primacy and
recency of the SPE in a serial recall task can be
replicated using only the hippocampus simulation, a
result suggesting that a one-store model of memory
for this recall task is sufficient. It remains to be seen
if this simulated model mirrors the actual biological
mechanisms utilized.
The results also suggest that both unique context
and order have impacts on recall in the network.
Certainly in Experiments 1 and 2, both primacy and
recency occurred, but the odd results in Experiment
3, where a unique-context item was never corrected
recalled (ab_8), and strong recall of a non-unique
item (ab_4) deserve closer examination.
At first we conjectured that the particular pattern
in ab_4 of Experiment 3 was distinctive in some way
not immediately apparent, similar to a human
subject finding pre-existing meaning in a random
string of numbers (such as a date), making it more
memorable. However, a comparison of the patterns
of each individual item against each of the others did
not reveal any outliers. In fact, if this sort of
“distinctiveness” of the A and B portions of the item
could have predicted the more “memorable” items,
ab_5 in Experiment 3 should have been successfully
recalled, as it has the least similarities with other
items.
We also compared each A portion of the item
against its own B portion. If a high similarity
between the two portions of each item were a
predictor of successful recall, then ab_6 and ab_7
should have been the most recalled items in
Experiment 3.
It could be argued that uniqueness (or
distinctiveness) and position are related. In trials
with human subjects, the first and last items in a list
have the distinction of being the “book ends”; their
context is unique by virtue of their positions.
Distinctive items are more easily remembered. That
is, in some sense, what the context represents in
these experiments. In the simulations, we sought to
recreate that distinctiveness by altering the groups of
context units for each list pair. However, recreating
0
0,2
0,4
0,6
0,8
1
0
2
4
6
8
10
0
2
4
6
8
10
ModelingtheSerialPositionEffect-UsingtheEmergentNeuralNetworkSimulationSystem
169

context analogous to the human perception of
context within the model is the big challenge. In
behavioural studies of context, the strongest cues are
often emotional ones such as fear (e.g. Rudy,
Barrientos & O’Reilly, 2002), and how to replicate
that neurobiological effect in the computational
models is not clear.
5 CONCLUSIONS
The Serial Position Effect has historically been
explained using a two-store memory model. Primacy
and recency were thought to be the work of long
term memory and working (short term) memory,
respectively. This paper has used simulation to
explore the theory that a one-store model of memory
can account fully for SPE. Simulation results
demonstrate that both primacy and recency of the
SPE in a serial recall task can be replicated using
only the hippocampus simulation, a result suggesting
that a one-store model of memory for this recall task
is sufficient.
While we deliberately restricted this work to the
hippocampus-only simulation in order to test the
one-store memory model of the SPE, future
computational simulations for the SPE should be
expanded to use the prefrontal cortex/hippocampus
combined simulation. As outlined in Atallah, Frank,
and O’Reilly (2004), memory encoding is
distributed, and memories are not “located” in either
the hippocampus or the cortex, but in both. A
connected PFC-hippocampus simulation would
allow this distributed model of memory to be more
thoroughly tested. The fact that the Serial Position
Effect is so thoroughly studied in experimental
psychology suggests that further investigation along
these lines will improve our understanding of the
biological mechanisms of memory.
ACKNOWLEDGEMENTS
The work presented in this paper was funded in part
by the ATLAS Institute at the University of
Colorado Boulder. The authors would like to thank
Randall O’Reilly, Laura Michaelson, and Seth Herd
for their assistance in using Emergent, as well as in
developing this project.
REFERENCES
Aisa, B., Mingus, B., and O'Reilly, R., 2008. The
emergent neural modeling system. Neural Networks,
21, 1045-1212.
Atallah, H. E., Frank, M. J., and O’Reilly, R. C., 2004.
Hippocampus, cortex, and basal ganglia: Insights from
computational models of complementary learning
systems. Neurobiology of Learning and Memory, 82
(2004), 253–267.
Baddeley, A., and Hitch, G. J., 2010. Working Memory.
Scholarpedia, 5(2):3015.
Barnes, J. M. & Underwood, B. J., 1959. Fate of first-list
associations in transfer theory. Journal of
experimental psychology, 58, pp.97–105.
Bayley, P. J., Salmon, D. P., Bondi, M.W., Bui, B. K.,
Olinchney, J., Delis, D. C., Thomas, R. G., Thal, L. J.,
2000. Comparison of the serial position effect in very
mild Alzheimer's disease, mild Alzheimer's disease,
and amnesia associated with electroconvulsive
therapy. Journal of the International
Neuropsychological Society, 6(03), 290-298.
Brodsky, M. B., McNeil, M. R., Doyle, P. J., Fossett, T.
D., Timm, N. H., & Park, G. H., 2003. Auditory Serial
Position Effects in Story Retelling for Non-Brain-
Injured Participants and Persons With
Aphasia. Journal Of Speech, Language & Hearing
Research, 46(5), 1124-1137.
Ebbinghaus, Hermann. 1885. Memory, A contribution to
experimental psychology. Translated from German by
H. A. Ruger and C. E. Bussenius, 1913. New York,
NY: Columbia University. Available at: Google
Books.
Golob, E. J., & Starr, A., 2004. Serial Position Effects in
Auditory Event-related Potentials during Working
Memory Retrieval. Journal of Cognitive Neuroscience
16(1), 40–52.
Gupta, P., 2005. Primacy and recency in nonword
repetition. Memory, 13(3/4), 318-324. doi:10.1080/
09658210344000350
Howard, M. W., & Kahana, M. J., 1999. Contextual
variability and serial position effects in free recall.
Journal Of Experimental Psychology. Learning,
Memory & Cognition, 25(4), 923.
Kahana, M. J., Sederberg, P. B., & Howard, M. W., 2008.
Putting Short-Term Memory Into Context: Reply to
Usher, Davelaar, Haarmann, and Goshen-Gottstein
(2008). Psychological Review, 115(4), 1119-1126.
doi:10.1037/a0013724
Lehmann, M., & Hasselhorn, M., 2010. The Dynamics of
Free Recall and Their Relation to Rehearsal Between 8
and 10 Years of Age. Child Development, 81(3), 1006-
1020. doi:10.1111/j.1467-8624.2010.01448.x
McCloskey, M. & Cohen, N., 1989. Catastrophic
interference in connectionist networks: The sequential
learning problem. The psychology of learning and
motivation, 24, pp.109–165. Available at: Google
Books.
Murdock, B. B., 1962. The serial position effect of free
recall. Journal of Experimental Psychology,
BIOINFORMATICS2014-InternationalConferenceonBioinformaticsModels,MethodsandAlgorithms
170

64(5),482–488.
Nairne, J. S., Neath, I., Serra, M., & Byun, E., 1997.
Positional Distinctiveness and the Ratio Rule in Free
Recall. Journal of Memory and Language 37() 155-
166.
O’Reilly, R. C., 1997. The LEABRA model of neural
interactions and learning in the neocortex. Dissertation
Abstracts International: Section B: The Sciences and
Engineering, 57, p.6792.
O'Reilly, R. C., Munakata, Y., Frank, M. J., Hazy, T. E.,
and Contributors, 2012. Computational Cognitive
Neuroscience. Wiki Book, 1st Edition. URL:
ccnbook.colorado.edu
O'Reilly, R.C., Wyatte, D., Herd, S., Mingus, B. & Jilk, D.
J., 2013. Recurrent Processing during Object
Recognition. Frontiers in Psychology, 4, 124.
Polyn, S. M., & Kahana, M. J., 2008. Memory search and
the neural representation of context. Trends in
Cognitive Sciences, 12(1), 24-30. doi:10.1016/
j.tics.2007.10.010
Sederberg, P.B., Gershman S. J. , Polyn S. M., & Norman,
K. A., 2011. Human memory reconsolidation can be
explained using the temporal context model.
Psychonomic Bulletin & Review, 2011 Jun;18(3):455-
68. doi: 10.3758/s13423-011-0086-9
Usher, M., Davelaar, E. J., Haarmann, H. J., & Goshen-
Gottstein, Y., 2008. Short-Term Memory After All:
Comment on Sederberg, Howard, and Kahana (2008).
Psychological Review, 115(4), 1108-1118.
doi:10.1037/a0013725
ModelingtheSerialPositionEffect-UsingtheEmergentNeuralNetworkSimulationSystem
171
