
Process Mining through Tree Automata
Michal R. Przybylek
Faculty of Mathematics, Informatics and Mechanics, University of Warsaw, Warszawa, Poland
Keywords:
Evolutionary Algorithms, Process Mining, Theory Discovery, Tree Automata.
Abstract:
This paper introduces a new approach to mine business processes. We define bidirectional tree languages
together with their finite models and show how they represent business processes. Then we propose an evolu-
tionary heuristic based on skeletal algorithms to learn bidirectional tree automata. We show how the heuristic
can be used in process mining.
1 INTRODUCTION
”Nowadays, there is no longer any question
that the quality of a company’s business pro-
cesses has a crucial impact on its sales and
profits. The degree of innovation built into
these business processes, as well as their flex-
ibility and efficiency, are critically important
for the success of the company. The impor-
tance of business processes is further revealed
when their are considered as the link between
business and IT; business applications only
become business solutions when the processes
are supported efficiently. The essential task of
any standard business software is and always
will be to provide efficient support of internal
and external company processes.” — Torsten
Scholz
In order to survive in today’s global economy more
and more enterprises have to redesign their business
processes. The competitive market creates the de-
mand for high quality services at lower costs and with
shorter cycle times. In such an environment business
processes must be identified, described, understood
and analysed to find inefficiencies which cause finan-
cial losses.
One way to achieve this is by modelling. Busi-
ness modelling is the first step towards defining a soft-
ware system. It enables the company to look afresh at
how to improve organization and to discover the pro-
cesses that can be solved automatically by software
that will support the business. However, as it often
happens, such a developed model corresponds more
to how people think of the processes and how they
wish the processes would look like, then to the real
processes as they take place.
Another way is by extracting information from a
set of events gathered during executions of a process.
Process mining (van der Aalst, 2011; Valiant, 1984;
Weijters and van der Aalst, 2001; de Medeiros et al.,
2004; van der Aalst et al., 2000; van der Aalst et al.,
2006b; Wynn et al., 2004; van der Aalst et al., 2006a;
van der Aalst and M. Pesic, 2009; van der Aalst and
van Dongen, 2002; Wen et al., 2006; Ren et al., 2007)
is a growing technology in the context of business
process analysis. It aims at extracting this informa-
tion and using it to build a model. Process mining is
also useful to check if the “a priori model” reflects
the actual situation of executions of the processes. In
either case, the extracted knowledge about business
processes may be used to reorganize the processes to
reduce they time and cost for the enterprise.
The aim of this paper is to extend methods for ex-
ploration of business processes developed in (Przy-
bylek, 2013) to improve their effectiveness in a busi-
ness environment. We generalise finite automata to
bidirectional tree automata, which allow us to mine
parallel processes. Then we express the process of
learning bidirectional tree automata in terms of skele-
tal algorithms. We show sample applications of our
algorithms in mining business processes.
2 SKELETAL ALGORITHMS
Skeletal algorithms (Przybylek, 2013) are a new
branch of evolutionary metaheuristics (Bremermann,
1962; Friedberg, 1956; Friedberg et al., 1959;
Rechenberg, 1971; Holland, 1975) focused on data
and process mining. The basic idea behind the
152
R. Przybylek M..
Process Mining through Tree Automata.
DOI: 10.5220/0004555201520159
In Proceedings of the 5th International Joint Conference on Computational Intelligence (ECTA-2013), pages 152-159
ISBN: 978-989-8565-77-8
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

skeletal algorithm is to express a problem in terms
of congruences on a structure, build an initial set
of congruences, and improve it by taking limited
unions/intersections, until a suitable condition is
reached. Skeletal algorithms naturally arise in the
context of data/process mining, where the skeleton is
the “free” structure on initial data and a congruence
corresponds to similarities in the data. In such a con-
text, skeletal algorithms come equipped with fitness
functions measuring the complexity of a model.
Skeletal algorithms, search for a solution of a
problem in the set of quotients of a given structure
called the skeleton of the problem. More formally, let
S be a set, and denote by Eq(S) the set of equivalence
relations on S. If i ∈ S is any element, and A ∈ Eq(S)
then by [i]
A
we shall denote the abstraction class of i
in A — i.e. the set { j ∈ S : jAi}. We shall consider
the following skeletal operations on Eq(S):
1. Splitting
The operation split : {0,1}
S
×S ×Eq(S) → Eq(S)
takes a predicate P: S → {0,1}, an element i ∈ S,
an equivalence relation A ∈ Eq(S) and gives the
largest equivalence relation R contained in A and
satisfying: ∀
j∈[i]
A
iR j ⇒ P(i) = P( j). That is —
it splits the equivalence class [i]
A
on two classes:
one for the elements that satisfy P and the other of
the elements that do not.
2. Summing
The operation sum : S × S × Eq(S) → Eq(S) takes
two elements i, j ∈ S, an equivalence relation A ∈
Eq(S) and gives the smallest equivalence relation
R satisfying iR j and containing A. That is — it
merges the equivalence class [i]
A
with [ j]
A
.
3. Union
The operation union : S × Eq(S) × Eq(S) →
Eq(S)×Eq(S) takes one element i ∈ S, two equiv-
alence relations A,B ∈ Eq(S) and gives a pair
hR,Qi, where R is the smallest equivalence re-
lation satisfying ∀
j∈[i]
B
iR j and containing A, and
dually Q is the smallest equivalence relation sat-
isfying ∀
j∈[i]
A
iQ j and containing B. That is — it
merges the equivalence class corresponding to an
element in one relation, with all elements taken
from the equivalence class corresponding to the
same element in the other relation.
4. Intersection
The operation intersection: S × Eq(S) × Eq(S) →
Eq(S)× Eq(S) takes one element i ∈ S, two equiv-
alence relations A,B ∈ Eq(S) and gives a pair
hR,Qi, where R is the largest equivalence relation
satisfying ∀
x,y∈[i]
A
xRy ⇒ x,y ∈ [i]
B
∨x, y /∈ [i]
B
and
contained in A, and dually Q is the largest equiv-
alence relation satisfying ∀
x,y∈[i]
B
xQy ⇒ x,y ∈
[i]
A
∨x,y /∈ [i]
A
and contained in B. That is — it in-
tersects the equivalence class corresponding to an
element in one relation, with the equivalence class
corresponding to the same element in the other re-
lation.
Furthermore, we assume that there is also a fitness
function. There are many things that can be imple-
mented differently in various problems.
2.1 Construction of the Skeleton
As pointed out earlier, the skeleton of a problem
should correspond to the “free model” build upon
sample data. Observe, that it is really easy to plug
in the skeleton some priori knowledge about the so-
lution — we have to construct a congruence relation
induced by the priori knowledge and divide by it the
“free unrestricted model”. Also, this suggests the fol-
lowing optimization strategy — if the skeleton of a
problem is too big to efficiently apply the skeletal al-
gorithm, we may divide the skeleton on a family of
smaller skeletons, apply to each of them the skeletal
algorithm to find quotients of the model, glue back the
quotients and apply again the skeletal algorithm to the
glued skeleton.
2.2 Construction of the Initial
Population
Observe that any equivalence relation on a finite set S
may be constructed by successively applying sum op-
erations to the identity relation, and given any equiva-
lence relation on S, we may reach the identity relation
by successively applying split operations. Therefore,
every equivalence relation is constructible from any
equivalence relation with sum and split operations. If
no priori knowledge is available, we may build the ini-
tial population by successively applying to the iden-
tity relation both sum and split operations.
2.3 Selection of Operations
For all operations we have to choose one or more ele-
ments from the skeleton S, and additionally for a split
operation — a splitting predicate P: S → {0,1}. In
most cases these choices have to reflect the structure
of the skeleton — i.e. if our models have an alge-
braic or coalgebraic structure, then to obtain a quo-
tient model, we have to divide the skeleton by an
equivalence relation preserving this structure, that is,
by a congruence. The easiest way to obtain a congru-
ence is to choose operations that map congruences to
congruences. Another approach is to allow operations
that move out congruences from they class, but then
ProcessMiningthroughTreeAutomata
153

“improve them” to congruences, or just punish them
in the intermediate step by the fitness function.
2.4 Choosing appropriate Fitness
Function
Data and process mining problems frequently come
equipped with a natural fitness function measuring
the total complexity of data given a particular model.
One of the crucial conditions that such a function has
to satisfy is the ability to easily adjust its value on a
model obtained by applying skeletal operations.
2.5 Creation of Next Population
There is a room for various approaches. We have ex-
perimented most successful with the following strat-
egy — append k-best congruences from the previous
population to the result of operations applied in the
former step of the algorithm.
3 TREE LANGUAGES AND TREE
AUTOMATA
Let us first recall the definition of an ordinary tree lan-
guage and automaton (Comon et al., 2007). A ranked
alphabet is a function arity : Σ → N from a finite set
of symbols Σ to the set of natural numbers N called
arities of the symbols. We shall write σ/k to indi-
cate that the arity of a symbol σ ∈ Σ is k ∈ N , that is
arity(σ) = k. One may think of a ranked alphabet as
of an algebraic signature — then a word over a ranked
alphabet is a ground term over corresponding signa-
ture.
Example 3.1 (Propositional logic). A ranked alpha-
bet of the propositional logic consists of symbols:
{⊥/0,>/0, ∨/2,∧/2, ¬/1,⇒/2}
Every propositional sentence like “> ∨ ¬⊥ ⇒ ⊥”
corresponds to a word over the above alphabet — in
this case to: “⇒ (∨(>,¬(⊥)),⊥)”, or writing in a
tree-like fashion:
⇒
∨
rr
e
e
e
e
e
e
e
e
⇒
⊥
,,
Y
Y
Y
Y
Y
Y
Y
Y
∨
>
uu
l
l
l
∨
¬
))
S
S
S
¬
⊥
Following (Comon et al., 2007) we define a finite
top-down tree automaton over arity : Σ → N as a tu-
ple A = hQ,q
s
,∆i, where Q is a set of states, q
s
∈ Q
is the initial state, and ∆ is the set of rewrite rules, or
transitions, of the type:
q
0
( f (x
1
,. .. ,x
n
)) → f (q
1
(x
1
),. .. ,q
n
(x
n
))
where f /n ∈ Σ and q
i
∈ Q for i = 0..n. The rewrite
rules are defined on the ranked alphabet arity : Σ → N
extended with q/1 for q ∈ Q. A word w is recognised
by automaton A if q
s
(w)
∆
∗
//
w, that is, if w may be
obtained from q
s
(w) by successively applying finitely
many rules from ∆.
We shall modify the definition of a tree automaton
in two directions. First, it will be more convenient to
associate symbols with states of an automaton, rather
then with transitions. Second, we extend the defini-
tion of a ranked alphabet to allow terms return multi-
ple results; moreover, to fit better the concept of busi-
ness processes, we identify terms that are equal up to
a permutation of their arguments and results.
Definition 3.1 (Ranked alphabet). A ranked alpha-
bet is a function biarity : Σ → N × N
+
. If the rank-
ing function is known from the context, we shall write
σ/i/ j ∈ Σ for a symbol σ ∈ Σ having input arity i and
output arity j; that is, if biarity(σ) = hi, ji.
A definition of a term is more subtle, so let us
first consider some special cases. By a multiset we
shall understand a function (−) from a set X to the
set of positive natural numbers N
+
— it assigns
to an element x ∈ X its number of occurrences x
in the multiset. If X is finite, then we shall write
{{x
1
,. .. ,x
1
,x
2
,. .. ,x
2
,. .. x
k
,. ..}}, where an element
x
k
∈ X occurs n-times when x = n, and call the multi-
set finite. For multisets we use the usual set-theoretic
operations ∪,∩,/ defined pointwise — with possible
extension or truncation of the domains.
A simple language over a ranked alphabet Σ is
the smallest set of pairs, called simple terms, con-
taining hσ/0/ j,
/
0i for each nullary symbol σ/0/ j ∈ Σ
and closed under the following operation: if σ/i/ j ∈
Σ and t
1
= hx
1
/i
1
/ j
1
,A
1
i,. .. ,t
k
= hx
k
/i
k
/ j
k
,A
k
i
are simple terms such that
∑
k
s=1
j
s
= i, then
hσ/i/ j,{{t
k
: 1 ≤ s ≤ k}}i is a simple term. For con-
venience we write σ{{t
1
,. .. ,t
k
}} for hσ/i/ j,{{t
k
: 1 ≤
s ≤ k}}i and call t
s
a subterm of σ{{t
1
,. .. ,t
k
}}.
Example 3.2 (Ordinary language). A word over an
ordinary alphabet Σ may be represented as a simple
term over the ranked alphabet biarity(σ) = (1,1) for
σ ∈ Σ and biarity(ε) = (0,1).
Example 3.3 (Ordinary tree language). A word over
an ordinary ranked alphabet may be represented as
a simple term over the ranked alphabet extended
with unary symbols n/1/1 for natural numbers n ∈
N indicating a position of an argument. A tree-
IJCCI2013-InternationalJointConferenceonComputationalIntelligence
154

representation of sentence “> ∨ ¬⊥ ⇒ ⊥” from Ex-
ample 3.1 have the following form:
⇒
0
rr
e
e
e
e
e
e
e
e
⇒
1
,,
Y
Y
Y
Y
Y
Y
Y
Y
0
∨
1
⊥
∨
0
uu
l
l
l
∨
1
))
S
S
S
0
>
1
¬
¬
⊥
Notice, that in every semantic of (any) propositional
calculus A ∨ B ≡ B ∨ A, therefore we may use this
knowledge on the syntax level and represent sentence
“> ∨ ¬⊥ ⇒ ⊥” in a more compact form — carrying
some extra information about possible models:
⇒
0
rr
e
e
e
e
e
e
e
e
⇒
1
,,
Y
Y
Y
Y
Y
Y
Y
Y
0
∨
1
⊥
∨
>
uu
l
l
l
∨
¬
))
S
S
S
¬
⊥
We extend the notion of a simple term to allow a
single term to be a subterm of more than one term.
Such extension would be trivial for ordinary terms,
but here, thanks to the ability of returning more than
one value, it gives us an extra power which is crucial
for representing business processes.
Definition 3.2 (Term). Let Σ be a ranked alphabet.
A term over Σ is a finite acyclic coalgebra hS, s
0
∈
S,subterm: S → N
+
S
,name : S → Σi satisfying the
following compatibility conditions:
∀
x∈S
∑
y∈S
subterm(x)(y) = name(x)
1
∀
y∈S\{s
0
}
∑
x∈S
subterm(x)(y) = name(y)
2
where subscripts
1
and
2
indicates projections on first
(i.e. input arity) and second (i.e. output arity) com-
ponent respectively Two terms hS, s
0
,subterm, namei
and hS
0
,s
0
0
,subterm
0
,name
0
i are equivalent if there ex-
ists an isomorphism of the coalgebras, that is, if there
exists a bijection σ : S → S
0
such that σ(s
0
) = s
0
0
,
N
+
σ
◦subterm ◦σ = subterm
0
and name ◦ σ = name
0
.
We shall not distinguish between equivalent
terms.
Example 3.4 (Simple term). Consider a simple term
t over a ranked alphabet Σ. It corresponds to the term
hS,s
0
∈ S,subterm: S → N
+
S
,name : S → Σi, where
S is the smallest multiset containing t and closed un-
der subterms, s
0
= t, name(σ{{t
1
,. .. ,t
k
}}) = σ and
subterm(σ{{t
1
,. .. ,t
k
}}) = {{t
1
,. .. ,t
k
}}.
In line with the above example, we shall gener-
ally represent a term as a sequence of equations (add
multiple variables, please):
σ
0
{{t
0,1
,.. . ,t
0,k
0
}} in free variables x
1
,.. . ,x
n
x
1
= σ
1
{{t
1,1
,.. . ,t
1,k
0
}} in free variables x
2
,.. . ,x
n
···
x
n
= σ
n
{{t
n,1
,.. . ,t
n,k
n
}} without free variables
where t
i, j
are simple terms and x
i
are multisets of vari-
ables.
Corollary 3.1. Terms are tantamount to finite sets of
equations of the form x = σ{{t
1
,. .. ,t
k
}} over simple
terms without cyclic dependencies of free variables.
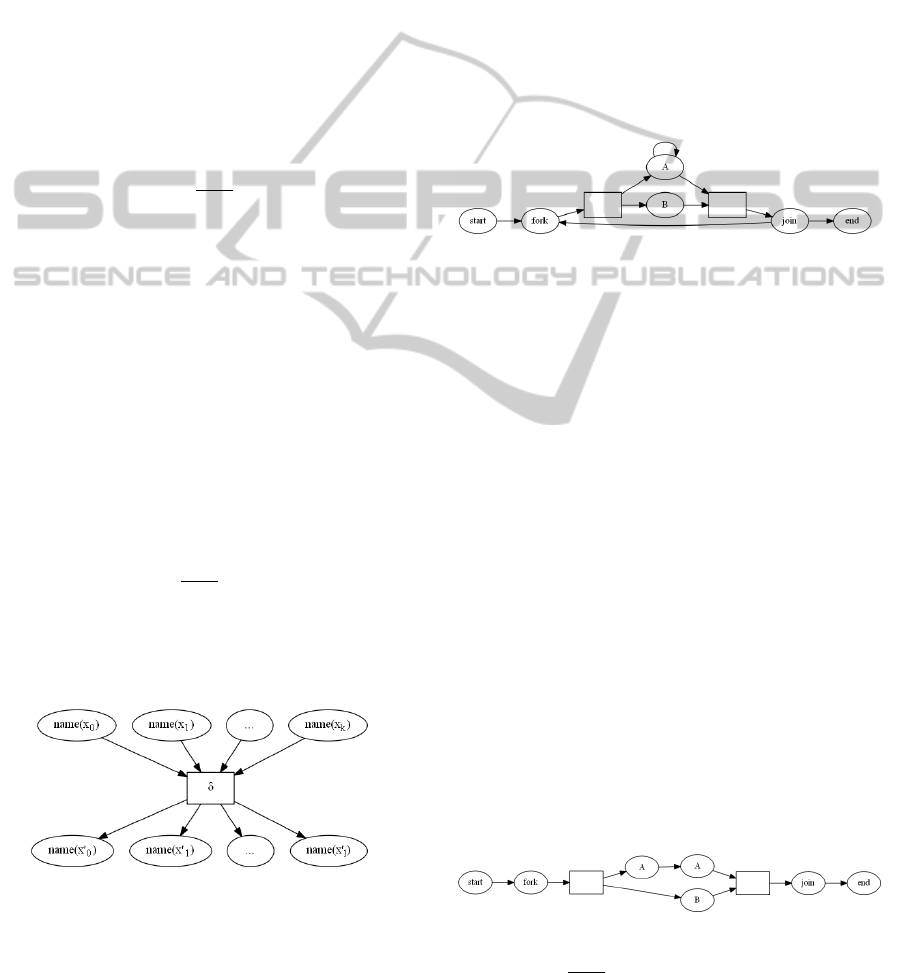
Example 3.5 (Terms from a business process). Con-
sider a business process:
A
start fork
//
fork
A
44
h
h
fork
B
**
V
V
A
join
**
V
V
B
join
44
h
h
join end
//
joinfork
ZZ
which starts in the “start” state and ends in the “end”
state. The semantics of the process is that one have to
preform simultaneously task B and at least one task
A and then either finish or repeat the whole process.
Some terms t
1
,t
2
,t
3
generated by this process are:
t
1
= start{{fork{{A{{x}},B{{x}}}}}}
x = join{{end}}
t
2
= start{{fork{{A{{A{{x}}}},B{{x}}}}}}
x = join{{end}}
t
3
= start{{fork{{A{{A{{A{{x}}}}}},B{{x}}}}}}
x = join{{fork{{A{{A{{x}}}},B{{y}}}}}}
y = join{{end}}
Generally, every term t generated by this process has
to be of the following form:
t = start{{fork{{A
k
1
{{x
1
}},B{{x
1
}}}}}}
x
1
= join{{fork{{A
k
2
{{x
2
}},B{{x
2
}}}}}}
·· ·
x
n−1
= join{{fork{{A
k
n
{{x
m
}},B{{x
m
}}}}}}
x
n
= join{{end}}
The whole business process cannot be represented as
a single term. One could write the following set of
equations:
t = start{{x}}
x = fork{{A{{y}},B{{z}}}}
y = A{{y}} ∨ y = z
z = join{{x}} ∨ z = join{{end}}
ProcessMiningthroughTreeAutomata
155
However, there is no term corresponding to this set —
there are cyclic dependencies between variables (for
example y depends on y, also x depends on z, z de-
pends on x), and there are disjunctions in the set of
equations.
Definition 3.3 (Tree Automaton.). A tree automa-
ton over a ranked alphabet Σ is a tuple A =
hQ,q
0
,∆, namei, where:
• Q is the set of states of the automaton
• q
0
∈ Q is the initial state of the automaton
• name is a function from set of states Q to Σ t
{ε/0/1}
• ∆ is a set of rewrite rules (transitions) of the form:
{{x
0
,. .. ,x
k
}}
δ
//
{{x
0
0
,. .. ,x
0
l
}}
with:
k
∑
i=0
name(x
i
)
1
=
l
∑
i=0
name(x
0
i
)
0
where x
0
,. .. ,x
k
,x
0
0
,. .. ,x
0
l
∈ Q.
Notice that in the above definition there is a single
initial state, but there are no final states — an automa-
ton finishes its run if it is in neither of the states.
Example 3.6 (Business process as tree automaton).
We shall use the following graphical representation
of a tree automaton: every state is denoted by a circle
with the letter associated to the state inside the circle,
every rule {{x
0
,. .. ,x
k
}}
δ
//
{{x
0
0
,. .. ,x
0
l
}} is denoted
by a rectangle (optionally with letter δ inside); more-
over this rectangle is connected by ingoing arrows
from circles denoting states {{x
0
,. .. ,x
k
}} and outgo-
ing arrows to circles denoting states {{x
0
0
,. .. ,x
0
l
}}:
For convenience we shell sometimes omit the inter-
mediating box of a singleton rule {{x}} → {{x
0
}} and
draw only a single arrow from the node representing
x to the node representing x
0
. The business process
from Example 3.5 defines over a signature Σ =
{start/1/0,fork/2/1,A/1/1, B/1/1, join/1/2,end/0/1}
an automaton hstart,Σ,∆, idi with rules ∆:
{{start}}
δ
1
→ {{fork}}
{{fork}}
δ
2
→ {{A,B}}
{{A}}
δ
3
→ {{A}}
{{A,B}}
δ
4
→ {{join}}
{{join}}
δ
5
→ {{fork}}
{{join}}
δ
6
→ {{end}}
{{end}}
δ
7
→ {{}}
which may be represented as:
Example 3.7 (Term as a skeletal tree automaton). The
automaton corresponding to a term t is constructed
in two steps. First we define the following automa-
ton. For every s ∈ S with name(s) = σ/i/ j define a
multiset:
E
s
= {{ε
s,1
,ε
s,2
,. .. ,ε
s, j
}}
and a rule:
{{s}} → E
s
and for every p ∈ S with k = subterm(p)(s) choose
any k-element subset X
p
of E
p
and put a rule:
[
p∈S
X
p
→ {{s}}
Then, for convenience, we simplify the automaton by
cutting at ε-states. That is: every pair of rules
X → {{Y,E}}
{{E}} → Z
where E consists only of ε-states, is replaced by a sin-
gle rule:
X → {{Y,Z}}
The next picture illustrates the skeletal automa-
ton constructed from term t
2
from Example 3.5.
Given a finite multiset X, a rule
{{x
0
,. .. ,x
k
}}
δ
//
{{x
0
0
,. .. ,x
0
l
}} is applicable to
X if {{x
0
,. .. ,x
k
}} is a multisubset of X. In
such a case we shall write δ[X] for the multiset
IJCCI2013-InternationalJointConferenceonComputationalIntelligence
156
(X\{{x
0
,. .. ,x
k
}}) ∪ {{x
0
0
,. .. ,x
0
l
}}. We say that a
term t = hS,s
0
,subterm
t
,name
t
i is recognised by an
automaton A = hQ,q
0
,∆
A
,name
A
i if there is a finite
sequence h{{q
0
}},{{q
0
7→ s
0
}}i = T
0
,T
1
,. .. ,T
n
=
h{{}},{{}}i with name(q
0
) = name(s
0
) satisfying for
all 0 < m < n the induction laws:
• T
m+1
= hδ[X
m
],π
m
[x
1
67→,.. . ,x
k
67→][x
0
1
7→ r
0
1
,.. . ,x
0
l
7→ r
0
l
]i
• hX
m
,π
m
i = T
m
• a rule {{x
0
,.. . ,x
k
}}
δ
//
{{x
0
0
,.. . ,x
0
l
}} ∈ ∆
A
is applicable
to X
m
and subterm
t
(π
m
(x
0
)) = subterm
t
(π
m
(x
1
)) = ··· =
subterm
t
(π
m
(x
k
)) = {{r
0
,.. . ,r
l
}}
• if name
A
(x
0
i
) = ε then r
0
i
= ε{{r
i
}}
• if name
A
(x
0
i
) 6= ε then name
t
(r
i
) = name
A
(x
0
i
) and r
0
i
= r
i
Notice that because X
n
= {{}}, the last applied rule
has to be of the form {{x
0
,. .. ,x
k
}}
δ
//
{{}} and due
to the compatibility condition on rules of a tree au-
tomaton:
k
∑
i=0
name
A
(x
i
)
1
= 0
which means that the states x
0
,. .. ,x
k
generate only
nullary letters. Therefore the corresponding subterms
{{π(x
0
),. .. ,π(x
k
)}} of t are nullary.
Example 3.8. Let us show that term t
2
from Example
3.5 is recognised by automaton hstart,Σ, ∆,idi from
Example 3.6. Since name(t
2
) = start = id(start) we
may put T
0
= h{{strat}},strat 7→ ti and consider the
following sequence:
• T
1
= h{{fork}},fork 7→
fork{{A{{A{{x}}}},B{{x}}}}i by δ
1
• T
2
= h{{A,B}},A 7→ A{{A{{x}}}},B 7→ B{{x}}i by
δ
2
• T
3
= h{{A,B}},A 7→ A{{A{{x}}}},B 7→ B{{x}}i by
δ
3
• T
4
= h{{A,B}}, A 7→ A{{x}},B 7→ B{{x}}i by δ
3
• T
5
= h{{join}},join 7→ join{{end}}i by δ
4
• T
6
= h{{end}},end 7→ endi by δ
6
• T
7
= h{{}},{{}}i by δ
7
it is easy to verify that each T
m
is constructed accord-
ing to the induction laws.
4 SKELETAL ALGORITHMS IN
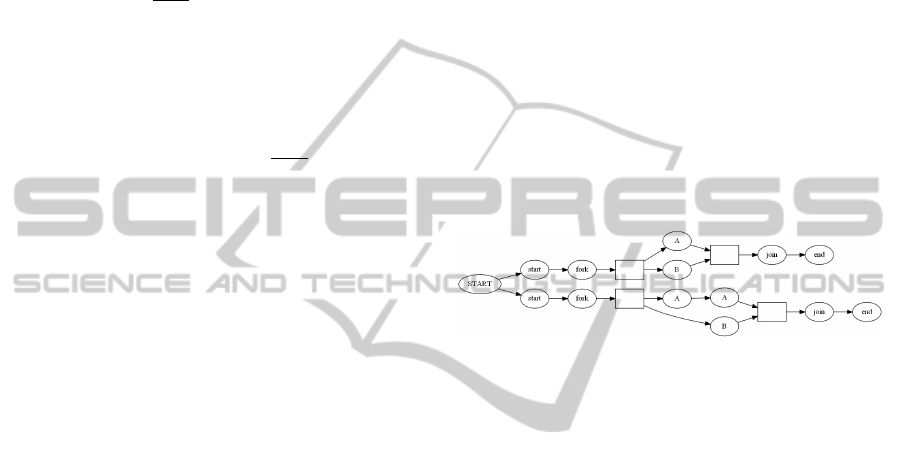
TREE MINING
Given a finite list K of sample terms over a common
alphabet Σ, we shall construct the skeletal automa-
ton skeleton(K) = hq
0
,S,∆,namei of K in the fol-
lowing way. For each term K
i
,0 ≤ i < length(K) let
skeleton(K
i
) = hq
i
0
,S
i
,∆
i
,name
i
i be the skeletal au-
tomaton of K
i
constructed like in Example 3.7, then:
• S = {START} t
S
i
S
i
• q
0
= START
• ∆ = {{{START}} → {{q
i
0
}}: 0 ≤ i < length(K)} t
S
i
∆
i
• name(q) =
START if q =
name
i
(q) if q ∈ S
i
That is skeleton(K) = hΣ,S,l,δi constructed as a dis-
joint union of skeletal automatons for t
k
enriched with
two states start and end. So the skeleton of a sam-
ple is just an automaton corresponding to the disjoint
union of skeletal automaton corresponding to each of
the terms enriched with a single starting state. Such
automaton describes the situation, where all actions
are different. Our algorithm will try to glue some ac-
tions that give the same output (shall search for the
best fitting automaton in the set of quotients of the
skeletal automaton). The next figure shows the skele-
tal automaton of the sample t
1
,t
2
from Example 3.7.
Given a finite list of sample data K, our search space
Eq(K) consists of all equivalence relations on the set
of states S of the skeletal automaton for K.
4.1 Skeletal Operations
1. Splitting
For a given congruence A, choose randomly a
state q ∈ skeleton(K) and make use of two types
of predicates
• split by output: P(p) ⇔ ∃
q
0
∈[q]
A
∃
X
δ
→Y
p ∈ X ∧ q
0
∈
Y
• split by input: P(p) ⇔ ∃
q
0
∈[q]
A
∃
X
δ
→Y
q
0
∈ X ∧ p ∈ Y
2. Summing
For a given congruence A, choose randomly two
states p,q such that name(p) = name(q).
3. Union/Intersection
Given two skeletons A,B choose randomly a state
q ∈ skeleton(K).
Let us note that by choosing states and predicates
according to the above description, all skeletal opera-
tions preserve congruences on skeleton(K).
ProcessMiningthroughTreeAutomata
157

4.2 Fitness
The idea behind the fitness function for bidirectional
tree automata is the same as for ordinary finite au-
tomata analysed in (Przybylek, 2013). The additional
difficulty comes here from two reasons: a bidirec-
tional tree automaton can be simultaneously in a mul-
tiset of states; moreover, two transitions may non-
trivially depend on each other. Formally, let us say
that two transitions X
δ
→ Y and X
0
δ
0
→ Y
0
are depended
on each other if X ∩X
0
6= {{}}, and are fully depended
if X = X
0
. Unfortunately, extending the Bayesian in-
terpretation to our framework yields a fitness function
that is impractical from the computational point of
view. For this reason we shall propose a fitness func-
tion that agrees with Bayesian interpretation only on
some practical class of bidirectional tree automata —
directed tree automata. A directed tree automaton is a
bidirectional tree automaton whose each pair of rules
is either fully depended or not depended. Now if δ is
a sequence of rules of a directed tree automaton, then
similarly to the Bayesian probability in (Przybylek,
2013), we may compute the probability of a multiset
of states X:
p
δ
(X) =
Γ(k)
Γ(n + k)
k
∏
i=1
c
c
i
i
where:
• k is the number of rules X
δ
i
→ Y for some Y of the
automaton
• c
i
is the total number of i-th rule X
δ
i
→ Y used in δ
• n =
∑
k
i=1
c
i
is the total number of rules of the form
X → Y for some Y used in δ
and the total distribution as:
p(δ) =
∏
X⊆S
p
δ
(X)
which corresponds to the complexity:
p(δ) = −
∑
X⊆S
log(p
δ
(X))
This complexity does not include any information
about the exact model of an automaton. Therefore,
we have to adjust it by adding “the code” of a model.
By using two-parts codes, we may write the fitness
function in the following form:
fitness(A) = length(skeleton(K)/A)−
∑
X⊆S
log(p
δ
(X))
where length(skeleton(K)/A) is the length of the quo-
tient of the skeletal automaton skeleton(K) by congru-
ence A under any reasonable coding, and S is the set
of states of the quotient automaton. For sample prob-
lems investigated in the next section, we chose this
length to be:
clog(|S|)|{hδ,xi: X
δ
→ Y ∈ ∆, 0 ≤ x < size(X) + size(Y)}|
for constant 1 ≤ c ≤ 2.
4.3 Bussiness Procces Mining
We shall start with a business process similar to one
investigated in Example 3.5, but extended with multi-
ple states generating the same action A:
A
start fork
//
fork
A
44
h
h
fork
B
--
Z
Z
Z
Z
Z
A A
//
A A
//
A
join
**
V
V
B
join
11
d
d
d
d
d
join end
//
joinfork
cc
This process starts in state start then performs si-
multaneously at least three tasks A and exactly one
task B, and then finishes in end state. Figures 1, 2, 3
shows automata mined from 1, 2, and 8 random sam-
ples (with equal probabilities) for fitness function de-
scribed in the previous section with c = 2.
Figure 1: Model discovered after seeing 1 sample, c = 2.
Figure 2: Model discovered after seeing 4 samples, c = 2.
Figure 3: Model discovered after seeing 10 samples, c = 2.
Notice that the first mined automaton correspond
to the minimal automaton recognizing any sample,
and after seeing 8 samples the initial model is fully
recovered. If we change our parameter c to 1, mean-
ing that the fitness function should less prefer small
models than we get automatons like in Figures 4, 5, 6.
Since the probability of generating 3 + n actions
A is exponentially small, for large number of samples
(in our case, 10), automata mined with c = 2 and c = 1
should be similar.
IJCCI2013-InternationalJointConferenceonComputationalIntelligence
158

Figure 4: Model discovered after seeing 1 sample, c = 1.
Figure 5: Model discovered after seeing 4 samples, c = 1.
Figure 6: Model discovered after seeing 10 samples, c = 1.
5 CONCLUSIONS
In this paper we defined bidirectional tree automata,
and showed how they can represent business process.
We adapted skeletal algorithms introduced in (Przy-
bylek, 2013) to mine bidirectional tree automata, re-
solving the problem of mining nodes that corresponds
to parallel executions of a process (i.e. AND-nodes).
In future works we will be mostly interested in vali-
dating the presented algorithms in industrial environ-
ment and apply them to real data.
REFERENCES
Bremermann, H. J. (1962). Optimization through evolution
and recombination. In Self-Organizing systems 1962,
edited M.C. Yovitts et al., page 93106, Washington.
Spartan Books.
Comon, H., Dauchet, M., Gilleron, R., L
¨
oding, C., Jacque-
mard, F., Lugiez, D., Tison, S., and Tommasi, M.
(2007). Tree automata techniques and applications.
de Medeiros, A., van Dongen, B., van der Aalst, W., and
Weijters, A. (2004). Process mining: Extending the
alpha-algorithm to mine short loops. In BETA Work-
ing Paper Series, Eindhoven. Eindhoven University of
Technology.
Friedberg, R. M. (1956). A learning machines part i. In IBM
Journal of Research and Development, volume 2.
Friedberg, R. M., Dunham, B., and North, J. H. (1959). A
learning machines part ii. In IBM Journal of Research
and Development, volume 3.
Holland, J. H. (1975). Adaption in natural and artificial sys-
tems. Ann Arbor. The University of Michigan Press.
Przybylek, M. R. (2013). Skeletal algorithms in process
mining. In Studies in Computational Intelligence, vol-
ume 465. Springer-Verlag.
Rechenberg, I. (1971). Evolutions strategie – optimierung
technischer systeme nach prinzipien der biologischen
evolution. In PhD thesis. Reprinted by Fromman-
Holzboog (1973).
Ren, C., Wen, L., Dong, J., Ding, H., Wang, W., and Qiu,
M. (2007). A novel approach for process mining based
on event types. In IEEE SCC 2007, pages 721–722.
Valiant, L. (1984). A theory of the learnable. In Communi-
cations of The ACM, volume 27.
van der Aalst, W. (2011). Process mining: Discovery,
conformance and enhancement of business processes.
Springer Verlag.
van der Aalst, W., de Medeiros, A. A., and Weijters, A.
(2006a). Process equivalence in the context of genetic
mining. In BPM Center Report BPM-06-15, BPMcen-
ter.org.
van der Aalst, W. and M. Pesic, M. S. (2009). Beyond pro-
cess mining: From the past to present and future. In
BPM Center Report BPM-09-18, BPMcenter.org.
van der Aalst, W., ter Hofstede, A., Kiepuszewski, B., and
Barros, A. (2000). Workflow patterns. In BPM Center
Report BPM-00-02, BPMcenter.org.
van der Aalst, W. and van Dongen, B. (2002). Discover-
ing workflow performance models from timed logs.
In Engineering and Deployment of Cooperative Infor-
mation Systems, pages 107–110.
van der Aalst, W., Weijters, A., and Maruster, L. (2006b).
Workflow mining: Discovering process models from
event logs. In BPM Center Report BPM-04-06, BPM-
center.org.
Weijters, A. and van der Aalst, W. (2001). Process min-
ing: Discovering workflow models from event-based
data. In Proceedings of the 13th Belgium-Netherlands
Conference on Artificial Intelligence, pages 283–290,
Maastricht. Springer Verlag.
Wen, L., Wang, J., and Sun, J. (2006). Detecting implicit
dependencies between tasks from event logs. In Lec-
ture Notes in Computer Science, volume 3841, pages
591–603.
Wynn, M., Edmond, D., van der Aalst, W., and ter Hofstede,
A. (2004). Achieving a general, formal and decidable
approach to the or-join in workflow using reset nets.
In BPM Center Report BPM-04-05, BPMcenter.org.
ProcessMiningthroughTreeAutomata
159
