
Discriminative Sequence Back-constrained GP-LVM for MOCAP based
Action Recognition
Valsamis Ntouskos, Panagiotis Papadakis and Fiora Pirri
ALCOR Lab, Department CCME, Sapienza, University of Rome, Rome, Italy
Keywords:
Action Recognition, Motion Capture Sequences, Manifold Learning, GPLVM.
Abstract:
In this paper we address the problem of human action recognition within Motion Capture sequences. We
introduce a method based on Gaussian Process Latent Variable Models and Alignment Kernels. We build a
new discriminative latent variable model with back-constraints induced by the similarity of the original se-
quences. We compare the proposed method with a standard sequence classification method based on Dynamic
Time Warping and with the recently introduced V-GPDS model which is able to model highly dimensional
dynamical systems. The proposed methodology exhibits high performance even for datasets that have not been
manually preprocessed while it further allows fast inference by exploiting the back constraints.
1 INTRODUCTION
Human action recognition is one of the most challeng-
ing applications in the field of computer vision. It re-
quires to infer an action model from an observed mo-
tion sequence, hence it requires the solution of an in-
verse problem (Poggio, 1985). Furthermore, the com-
plete modelling process is composed of several inter-
mediate stages, namely: data acquisition, that in gen-
eral requires a sophisticated technology, motion anal-
ysis and segmentation into individual actions, align-
ment between sequences and classification with re-
spect to a given taxonomy. While all these stages are
computationally expensive the main goal remains to
obtain real-time recognition.
In this paper, we address the alignment and classi-
fication part of the complete pipeline. Namely, we
assume that a sequence that captures an individual
action is already available and the task is to recog-
nize the performed action. To this end we introduce
a model based on the Gaussian Process Latent Vari-
able Model (GP-LVM) and the Back-Constrained GP-
LVM introduced in (Lawrence, 2003) and (Lawrence
and Qui
˜
nonero Candela, 2006) respectively, and ex-
tend it for the application of action recognition, ex-
ploiting the strength of a lower dimensional mani-
fold. In detail, we derive a discriminative, proba-
bilistic dimensionality reduction model for mapping
motion capture sequences in a low dimensional la-
tent space which assists the action classification pro-
cess. The proposed model introduces a latent space
featuring a fixed set of actions, from motion capture
(MoCap) data, and constrains feature distances in data
space to be suitably projected in the latent space, in
order to preserve the clustering of common patterns.
This ensures a discriminative power to the GP-LVM
model and it also exploits the characteristic property
of action sequences of being reducible to a lower di-
mensional manifold (Ntouskos et al., 2012).
We organize the remainder of this paper as fol-
lows: In Section 2 we briefly review recent works on
action recognition based on MoCap sequences and di-
mensionality reduction, showing the major trends of
research in this field. In Section 3 we unfold the the-
oretical foundation of GP-LVM on which our model
is based, in Section 4 we present our discriminative
model and in Section 5 we demonstrate the latent
space structure recovered by the proposed model and
examine its performance on human action classifica-
tion. We compare our method with a sequence classi-
fication method based on Dynamic Time Warping as
well as the Variational Gaussian Process Dynamical
Systems (Damianou et al., 2011) recently proposed
for modelling high dimensional dynamical systems.
We conclude our work by discussing possible exten-
sions.
2 RELATED WORK
The problem of human action recognition has been
addressed from a plurality of perspectives that range
from stochastic and volumetric to non-parametric
87
Ntouskos V., Papadakis P. and Pirri F. (2013).
Discriminative Sequence Back-constrained GP-LVM for MOCAP based Action Recognition.
In Proceedings of the 2nd International Conference on Pattern Recognition Applications and Methods, pages 87-96
DOI: 10.5220/0004268600870096
Copyright
c
SciTePress

models, the latter being most commonly employed.
Extended reviews on human motion analysis and ac-
tion recognition can be found in (Aggarwal and Cai,
1999), (Moeslund et al., 2006) and (Turaga et al.,
2008).
A distinctive branch of research concerns ap-
proaches that address the problem of modelling and
recognizing human motion by learning the structure
of the low dimensional manifold where it resides,
and by recovering a mapping between the high di-
mensional observations and the manifold. Our focus
mainly resides onto this category of methods and in
particular to those wherein actions have been captured
as MoCap sequences, a data representation that has
lately been gaining momentum and led to the prolifer-
ation of human action repositories. In the following,
we briefly review a number of works that are repre-
sentative of this area and within the same spirit of the
proposed approach.
In (Gong and Medioni, 2011) the authors consider
MoCap sequences and they learn the structure of a
unidimensional smooth manifold by applying the ten-
sor voting technique (Mordohai and Medioni, 2010).
A motion distance score is used to compute the sim-
ilarity between the actions recorded in two different
sequences. The setting provides the possibility to
compare also actions extracted from videos with ac-
tions taken from MoCap sequences.
In (Zhang and Fan, 2011) the authors consider a
two dimensional manifold with a toroidal topology
in order to estimate human motion. They build on
the idea of Gaussian Process Latent Variable Models
(GP-LVM) (Lawrence, 2003) to identify a manifold
which jointly captures gait and pose, via three dif-
ferent models. They introduce a new model (JGPM)
which they compare to two constrained latent variable
models based on GP-LVM and Local Linear GP-LVM
(Urtasun et al., 2008) respectively.
In (Taylor et al., 2006) the authors propose a non-
linear generative model for human motion data that
considers binary latent variables. The introduced ar-
chitecture makes on-line inference efficient and al-
lows for a simple approximate learning procedure.
The method’s performance is evaluated by synthesiz-
ing various motion sequences and by performing on-
line filling in of data lost during motion capture.
Following a different perspective, in (Sheikh et al.,
2005) the authors explore the space of actions,
spanned by a set of action-bases, to identify some ac-
tion invariants with respect to viewpoint, execution
rate and subject’s body shape. Action recognition is
performed for a constrained set of actions and the re-
sults show that it is possible to correctly classify most
of these actions using the proposed method.
The redundancy of the original representation of
MoCap sequences is also exploited in (Li et al., 2010)
where a compressive sensing method is introduced.
The authors argued that human actions are sparse in
the action space domain as well as the time domain,
and therefore they seeked a sparse representation. The
introduced sparse representation could assist in dif-
ferent applications regarding MoCap data like motion
approximation, compression, action retrieval and ac-
tion classification.
Finally, in (Yao et al., 2011) (see also (Yao et al.,
2010) and (Waltisberg et al., 2010)) the authors exam-
ine whether and to what extent the use of information
about the subject’s pose assists recognition. In this
case, several pose-based features are used, based on
the relative pose features introduced in (M
¨
uller et al.,
2005) and (M
¨
uller, 2007). Their results suggest that
knowing the pose of the subject leads to better re-
sults, in terms of classification rate. It is also shown,
that pose based features alone are usually sufficient,
as their combination with appearance based features
did not appear to increase classification rate.
3 GAUSSIAN PROCESS LATENT
VARIABLE MODELS
A Gaussian process is a collection of random vari-
ables such that any finite collection of them has
a Gaussian distribution (Rasmussen and Williams,
2006). Namely, a random variable of a Gaussian
process is f (x
i
) = GP (µ(x
i
), k(x
i
, x
j
)), with µ and
k(x, x
0
) the mean and covariance function of the pro-
cess respectively, indexed over the set X of all the pos-
sible inputs. The Gaussian process is a non paramet-
ric prior for the random variable f (x
i
) where x
i
is the
deterministic input, as it is assumed to be observed.
Gaussian processes have been successfully used for
both regression and classification tasks.
In (Lawrence, 2003) it is shown that Principal
Component Analysis (PCA) can be interpreted as a
product of Gaussian processes mapping latent-space
points to points in data-space, when the covariance
function is linear; instead, when a non-linear covari-
ance function is used such as an RBF kernel then
the mapping is non-linear. Lawrence shows the ad-
vantages in using Gaussian Processes Latent Vari-
able Models (GP-LVM); for example, for optimiza-
tion purposes, the data can be divided in active and
inactive, according to some rule. Then, since points
in the inactive set project into the data-space as Gaus-
sian distributions, due to the properties of the variance
the likelihood of each data point can be optimized in-
dependently.
ICPRAM2013-InternationalConferenceonPatternRecognitionApplicationsandMethods
88

Figure 1: Rendered poses of a subject performing a “fight-
ing” action taken from a MoCap sequence (courtesy of (mo-
capdata.com, 2011)).
In addition to the advantage in terms of visual-
ization and computation, highlighted in (Lawrence,
2003) GP-LVM turns out to be a powerful unsuper-
vised learning algorithm. Indeed, GP-LVM can man-
age, via the non-linear mapping of the latent vari-
ables to the data-space, noisy or incomplete input
data, when Gaussian processes are used as non para-
metric priors.
At this point, we introduce some preliminary def-
initions that we will refer throughout the following
sections
Let Y be the normalized data in R
N×d
, for ex-
ample specifying the pose of a silhouette element in
space (see Figure 1), with respect to a coordinate
frame; let X be the mapped positions in latent-space,
with X ∈ R
N×q
, with q ≤ d. Let f be a mapping, such
that:
y
n j
= f (x
n
, w
j
) + ε
n j
, (1)
Here, y
n j
the element of the n-th row and j-th col-
umn of Y, ε
n j
denoting noise and x
n
the n-th row of
X, and w
j
the parameters of the mapping f . Given
a Gaussian process as a prior on f , when the prior
is the same on each of the f functions one obtains
(Lawrence, 2003):
p(Y|X, θ) =
d
∏
j=1
N (y
j
|0, K) (2)
Here, y
j
is the j-th column of Y and K is the N × N
kernel of the Gaussian process. Equation 2 suggests
a conditional independence of the data space dimen-
sions given the latent space representation.
Learning amounts to maximizing the likelihood
with respect to the position of the latent variables X
and θ, the parameters of the kernel:
L(X, θ) = −
d
2
log|K| −
1
2
Tr
K
−1
YY
>
(3)
In order to optimize the non-linear model, it is
necessary to initialize the model by setting the initial
values for the positions of the latent-space points, and
the hyperparameters of the model as well as perform
an iterative minimization of the objective function, by
using a gradient based optimization algorithm. As the
model is non-linear, it is subject to local-minima, so
the initialization of the positions of the latent-space
points is crucial. When non-linear dimensionality re-
duction methods are used for the initialization, like lo-
cal linear embedding (LLE) (Roweis and Saul, 2000)
or ISOMAP (Tenenbaum et al., 2000), it is expected
that the structure of the manifold is more accurately
recovered. GP-LVM have been exploited in many ap-
plications as for example in (Urtasun et al., 2006),
(Urtasun and Darrell, 2007), (Urtasun et al., 2008)
and (Wang et al., 2006).
4 DISCRIMINATIVE SEQUENCE
BACK-CONSTRAINED GP-LVM
As mentioned in the previous sections, models from
the family of GP-LVM methods are well suited for
predicting missing values or missing samples of time
sequences. However, they do not seem to perform
equally well when they are used for clustering and
classification problems, particularly for time-series
data. This handicap of the classical GP-LVM methods
can be also witnessed by observing the latent-space
representations of the data.
One can notice that recovering the structure of
a common latent-space of a set of sequences, their
latent space representations are scattered across the
latent-space and no relation is evident between se-
quences corresponding to the same action. This is due
to the fact that standard GP-LVM models do not pro-
vide a mechanism to encourage neighboring points
to be placed closer to each other in the latent-space,
while the same also holds at the level of individual
sequences.
In cases where local distances in data-space pro-
vide some information regarding the intra-class vari-
ation, these can be directly used in the GP-LVM
model, in order to provide a common latent-space rep-
resentation better suited for classification purposes.
Lawrence and Qui
˜
nonero-Candela in (Lawrence and
Qui
˜
nonero Candela, 2006) have introduced Back-
Constrained GP-LVM which considers local dis-
tances in the data-space. The GP-LVM model pro-
vides a direct mapping from the latent-space to the
data-space by means of a product of Gaussian pro-
cesses. Each of these processes refers to a different
dimension of the data-space and it is governed by the
coordinates of the latent-points. In order to obtain a
smooth mapping in the opposite direction, the authors
in (Lawrence and Qui
˜
nonero Candela, 2006) propose
to construct this mapping by means of a kernel based
DiscriminativeSequenceBack-constrainedGP-LVMforMOCAPbasedActionRecognition
89

regression. Adopting this technique, the latent points
are constrained to be the product of a smooth mapping
from the data-space. This enforces small distances
in data-space to lead to small distances between the
neighboring points in the latent-space. The smooth-
ness of the mapping from the data-space to the latent-
space is determined by the kernel function. An in-
teresting property in the construction of an inverse
mapping from the data-space to the latent-space, is
the possibility to estimate the latent-position of a new
data point without the need of re-optimisation.
The previous method cannot be directly applied
on data originating from sequences, as it is expected
that individual elements of a sequence do not provide
sufficient information regarding the characteristics of
the entire sequence. Building on the same principle,
namely the use of local distances in the data-space
as back-constraints, we formulate a GP-LVM variant
which considers entire sequences rather than individ-
ual data points.
Before introducing our model, we briefly review
the Dynamic Time Warping (DTW) algorithm, as
well as a set of sequence alignment kernels based on
DTW and its variations, which will be used for the
derivation our model.
4.1 Dynamic Time Warping and
Sequence Alignment Kernel
Dynamic Time Warping is used to match two time
dependent sequences by nonlinearly warping the one
against the other. Let us consider two vector se-
quences Y = (y
1
, . . . , y
N
) with N ∈ N and Z =
(z
1
, . . . , z
M
) with M ∈ N. Each vector in the se-
quence belongs to a n-dimensional feature space F
so y
n
, z
m
∈ F . A local distance measure is defined to
compare a pair of features, provided by an appropriate
kernel function:
κ : F × F → R
+
(4)
A warping path is a sequence p = (p
1
, . . . , p
L
)
where each element is a tuple p
l
= (n
l
, m
l
). The total
cost of a warping path p, according to the predefined
distance measure, is:
c
p
(y
n
, z
m
) =
L
∑
l=1
κ(y
n
l
, z
m
l
) (5)
The Dynamic Time Warping distance between
two sequences is defined as the minimal total cost
among all possible warping paths. To obtain this
value we have to solve the following optimization
problem:
DTW (Y, Z) = min
p
{
c
p
(Y, Z)
}
(6)
We can also identify an optimal warping path (not
necessarily unique):
p
∗
= argmin
p
{
c
p
(Y, Z)
}
(7)
The DTW distance is well-defined, even though
there may exist many warping paths of minimal total
cost. Moreover, it is symmetric if the distance mea-
sure is also symmetric but it does not define a proper
metric, as it does not satisfy the triangle inequality.
In order to apply DTW on MoCap sequences, we
must first define the local cost measure κ. Two pop-
ular choices are to use the sum of the geodesic dis-
tances between the unit-quaternions representing the
joint angles, as well as the optimal alignment distance
between the three dimensional positions of the joints
(M
¨
uller, 2007).
Based on the notions of the DTW distance and the
optimal warping path, alignment kernels have been
proposed which consider entire sequences as a whole
((Shimodaira et al., 2001), (Bahlmann et al., 2002)
and (Cuturi et al., 2006)).
4.2 Sequence Back-constrained
GP-LVM
In order to be able to ensure that data instances, which
are close to each other in the data-space, are mapped
to positions which are close also in the latent-space,
we apply a similarity measure for comparing different
sequences and identify a characteristic feature, sum-
marizing the entire sequence. Once these conditions
are accommodated, we can enforce a clustering of the
sequences in the latent-space, governed by their re-
spective similarity, which will enable a more accurate
classification of a new sequence.
Here we consider that each frame of a motion se-
quence is represented as a d-dimensional array. An
entire sequence, with index s, is represented thus by a
set of d dimensional arrays of cardinality L
s
, form-
ing a matrix Y
s
∈ R
L
s
×d
. A collection of S mo-
tion sequences is represented as the concatenation of
the respective sub-matrices forming the data-matrix
Y ∈ R
N×d
, with N =
∑
S
s=1
L
s
. The set J
s
contains the
indices of the s
th
sequence in the data matrix. The
corresponding representation of the data-points in the
q dimensional latent-space form a matrix X ∈ R
N×q
.
We also consider the coordinates of the centroid of
the latent-space representation of the s
th
sequence, de-
fined as:
µ
sq
=
1
L
s
∑
n∈J
s
x
nq
(8)
ICPRAM2013-InternationalConferenceonPatternRecognitionApplicationsandMethods
90

The likelihood of the GP-LVM model is given by
Equation 3. The centroid of the latent positions of the
data points are taken to be the characteristic feature
of the sequence. Therefore, we require that the local
distances between the sequences in data-space, com-
puted via the DTW technique, are preserved in latent-
space; thus they are specified as the distances between
the centroids µ
s
. Hence, we consider a mapping to the
latent-space governed by an alignment kernel k:
g
q
(Y
s
) =
S
∑
m=1
a
mq
k(Y
s
, Y
m
) (9)
The degree to which the local distances in the
data-space are preserved depends on the particular
characteristics of the kernel employed for the map-
ping.
Instead of maximizing the likelihood of the origi-
nal GP-LVM model, now he have to maximize a con-
strained likelihood.
Each of the S · q constraints can be written as:
g
q
(Y
s
) − µ
sq
= 0 (10)
Maximizing the constrained likelihood of the
model, we expect to obtain a latent-space representa-
tion, where similar sequences are clustered together,
with respect to the representation obtained by the
original model. Another important advantage of this
approach is that we can use the inverse mapping re-
covered in the learning phase for the purposes of fast
inference. In this way, we avoid the costly operation
of re-optimisation, which otherwise would be neces-
sary to obtain the latent-space representation of new
sequences.
Up to this point, we did not consider the labels
of each type of sequence. In the following section,
we modify our model by replacing the Gaussian prior
with a prior which will make the model more discrim-
inative.
4.3 Discriminative Sequence
Back-constrained GP-LVM
Discriminative GP-LVM (D-GPLVM) has been orig-
inally introduced in (Urtasun and Darrell, 2007). In
order to make the Sequence Back-Constrained GP-
LVM (SB-GPLVM) model more discriminative, we
can consider a measure of the between-group vari-
ation and the within-group separation. Referring to
Fisher’s Discriminant Analysis, in case we need to
estimate a linear projection of the data, such that an
optimal separation is achieved, we need to maximize
the ratio of the between-group-sum of squares to the
within-group-sum of squares.
We thus seek the direction of projection given
by the vector a which provides a good separation
of the data. Denoting as X = [x
1
, . . . , x
N
]
T
the low
dimensional representation of the data points Y =
[y
1
, . . . , y
N
]
T
, the between-group-sum of squares is
given as:
a
T
Ba =
C
∑
c=1
N
c
N
a
T
(µ
c
− µ
0
)(µ
c
− µ
0
)
T
a (11)
The within-group-sum of squares is given as:
a
T
Wa =
1
N
C
∑
c=1
N
c
∑
n=1
a
T
(x
(c)
n
− µ
c
)(x
(c)
n
− µ
c
)
T
a (12)
Here X
(c)
= [x
(c)
1
, . . . , x
(c)
N
c
]
T
are the N
c
points which
belong to the class c, µ
c
is the mean of the elements
of class c and µ
0
is the mean computed over all the
points.
The criterion used for maximizing between-group
separability and minimizing within-group variability
is the following (H
¨
ardle and Simar, 2003):
J(X) = Tr(W
−1
B) (13)
Based on the previous discussion, in order to
transform the SB-GPLVM model making it discrim-
inative, it is necessary to replace the Gaussian prior
with a prior which depends on Equation (13). This
prior takes the following form:
p(X) =
1
C
p
exp
n
−
γ
2
J
−1
o
(14)
where C
p
is a normalization constant and γ represents
the scaling factor of the prior.
The log likelihood associated with the discrimina-
tive model becomes:
L = −
d
2
log|K| −
1
2
Tr
K
−1
YY
T
−
γ
2
Tr
B
−1
W
(15)
The parameter γ controls the relative importance
of the discriminative prior and it reflects the ability of
the model, to be more discriminative or more gener-
alizing, according to the value it takes.
4.4 Classification based on
D-SBGPLVM
In order to classify a new sequence according to the
Discriminative SB-GPLVM model (D-SBGPLVM), it
is necessary first to compute the latent representation
of the data points belonging to the sequence. Let Y
∗
DiscriminativeSequenceBack-constrainedGP-LVMforMOCAPbasedActionRecognition
91

be the data-space representation of the new sequence.
The corresponding latent-space representation X
∗
can
be estimated by maximizing p(Y
∗
, X
∗
|X, Y, θ).
Alternatively we can perform inference by only
using the position of the centroid of the latent repre-
sentation of the test sequence. The new sequence’s
centroid in latent-space can be estimated orders of
magnitude faster by making use of the sequence back-
constraints introduced in Section 4.2 (Equation 9).
Thus, the coordinates of the test sequence’s centroid,
in each dimension of the latent space are given by:
∀ q : µ
∗q
= g
q
(Y
∗
) =
S
∑
s=1
a
qs
k(Y
∗
, Y
s
) (16)
where µ
∗q
is the q
th
dimension coordinate of the cen-
troid µ
∗
of the test sequence. In this case, no mini-
mization is required and the time necessary for com-
puting the coordinates of the centroid of the test se-
quence, is practically equal to the time needed to com-
pute the kernel values.
At this point, any multi-class classification
method can be employed, in order to perform classifi-
cation. As the latent-space has a dimensionality much
smaller than the original data-space, it is expected that
classification is more robustly performed in the latent
representation of the sequences. Moreover, the pro-
posed method provides a concise way to classify se-
quences as a whole, as the model treats them explic-
itly as individual entities.
5 RESULTS
In this Section, we evaluate the ability of the Discrim-
inative Sequence Back-Constrained GP-LVM model
to provide a latent-space representation, that allows
robust and effective classification of human action se-
quences.
Evaluation on the HDM05 “Cuts” Dataset. Part
of the “Cuts” sequences, contained in the HDM05
(Muller et al., 2007) dataset, has been used for eval-
uating the model we propose, in comparison to other
methods which can be used for sequence classifica-
tion. This dataset includes the following actions:
• Clapping hands, 5 repetitions - 17 sequences
• Hopping on right leg, 3 repetitions - 12 sequences
• Kick with right foot in front, 2 repetitions - 15
sequences
• Running on place, 4 steps - 15 sequences
• Throwing high with right hand while standing -
14 sequences
• Walking starting with right foot, 4 steps - 16 se-
quences
The sequences are sampled with a frequency of
120 frames per second and are already accurately seg-
mented, in order to contain a single action with the
same number of repetitions.
The results of the proposed method are compared
with the classification results, obtained by directly us-
ing the DTW distances of the sequences in the data-
space, as well as using the highest class-conditional
densities obtained by the Variational Gaussian Pro-
cess Dynamical Systems (V-GPDS) method (Dami-
anou et al., 2011).
All results have been extracted by cross-
validation. Each experiment is performed by keep-
ing all action sequences of one of the five subjects as
test sequences and by using the sequences of the other
four subjects as training instances. Finally, the results
are averaged over the five individual experiments.
Table 1 gives the accuracy rate achieved with each
of these three methods for each action as well as in av-
erage. Regarding the results obtained by the proposed
method, relative features are used and the dimension-
ality of the latent-space space is fixed to four. More-
over, for the back-constraints the kernel proposed in
(Bahlmann et al., 2002) is considered and the initial
positions of the latent points are obtained by using
the Local Linear Embedding algorithm (Roweis and
Saul, 2000). Finally, classification in latent-space is
performed by SVMs using the RBF kernel function.
Figure 2 shows the corresponding confusion matrix
obtained by using the D-SBGPLVM model.
Table 1: Comparison of the classification results for the
HDM05 “Cuts” dataset.
DTW V-GPDS D-SBGPLVM
Clap 70.6% 16.7% 88.2%
Hop 100% 66.7% 83.3%
Kick 40.0% 33.3% 53.3%
Run 66.7% 33.3% 80.0%
Throw 64.3% 50.0% 78.6%
Walk 100% 83.3% 100%
Average 73.0% 47.2% 80.9%
One can see from the results provided in Table 1
that our method gives the best results on average as
well as for each individual type of action, except for
the actionHop. We observe that the classification ac-
curacy is relatively high for the DTW distance alone.
This is a particular case though, and it depends on the
ICPRAM2013-InternationalConferenceonPatternRecognitionApplicationsandMethods
92
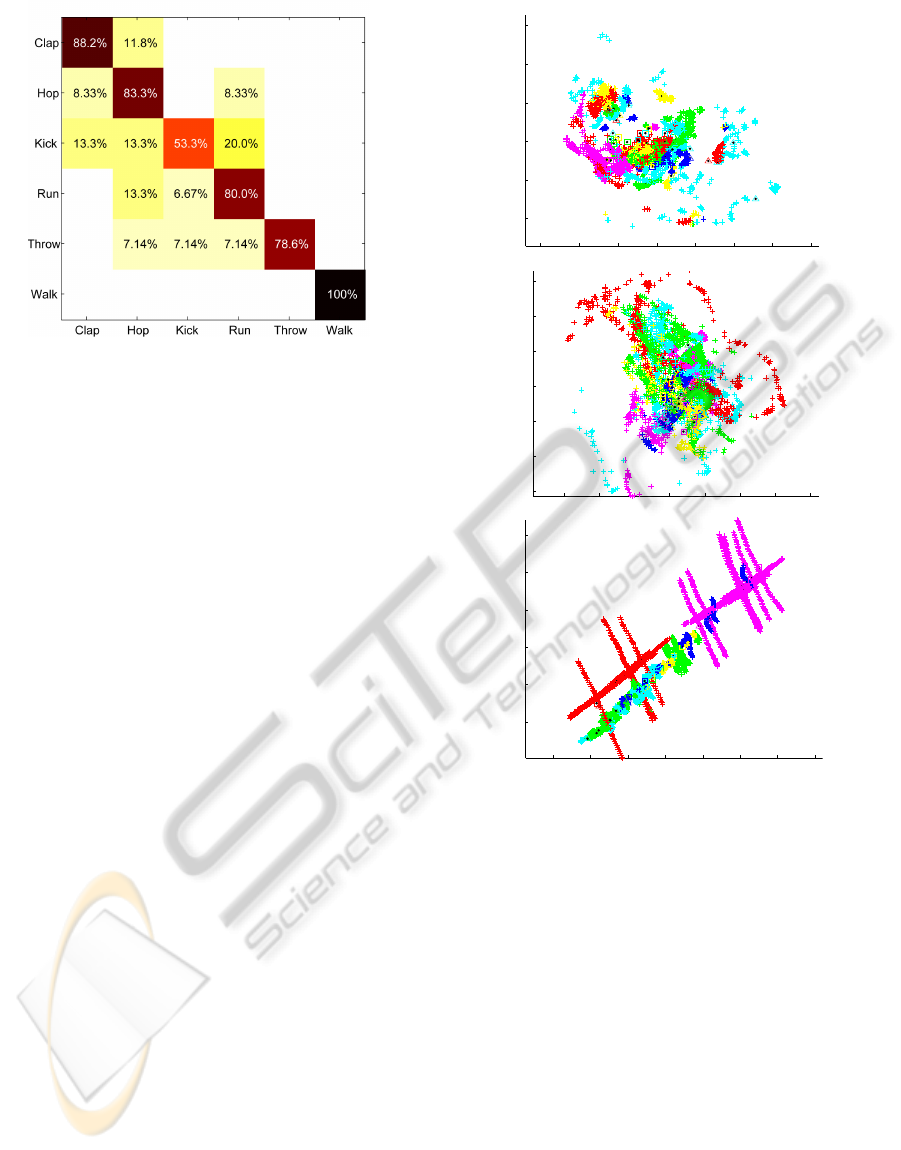
Figure 2: Confusion matrix by using D-SBGPLVM model
in combination with SVM on the HDM05 “Cuts” dataset.
Average accuracy: 80.9%.
fact that this dataset is specifically constructed in such
a way, that actions of the same kind can be aligned
perfectly or with a very small cost. This is due to
the fact that they are defined in a high level of detail
regarding their execution and they have been also ac-
curately segmented manually. Finally, similar actions
always start in the same way. Regarding classifica-
tion of human actions using the V-GPDS model, it is
necessary to train a different model for each individ-
ual type of action. After a model has been trained for
each type of action, it is possible to compute the class
conditional densities for the new sequence.
Strangely, the classification rate of the V-GPDS
model was not as high as expected considering that
the analogous model which does not consider time
dynamics (see (Titsias and Lawrence, 2010)), is re-
ported to provide good classification results (e.g. on
the USPS Handwritten Digits Dataset). Searching
the cause of this issue, we have noticed that mod-
els for certain actions tend to provide higher condi-
tional densities most of the time. Visually examining
the latent-space representations of these models, by
training them considering a three-dimensional latent-
space, we have also observed that these particular se-
quences cover a much greater portion of the latent-
space with respect to the other sequences. Further
investigation is needed in this direction, as the exper-
iments performed using V-GPDS were not sufficient
to derive safe conclusions.
In the case of D-SBGPLVM, the model is trained
by optimising the latent coordinates of the sequences
and the hyper-parameters of the model by using all
training sequences. By the optimisation process, we
recover also the parameters of the kernel based regres-
sion which forms the inverse mapping, the one from
the data-space to the latent-space. We provide some
−3 −2 −1 0 1 2 3 4
−2
−1
0
1
2
3
−1.5 −1 −0.5 0 0.5 1 1.5 2
−1.5
−1
−0.5
0
0.5
1
1.5
−6 −4 −2 0 2 4 6 8
−4
−2
0
2
4
6
Figure 3: Top Latent-space representation considering Eu-
ler Angles representation and PPCA initalization, Middle
Latent-space representation considering Unit-Quaternion
representation and PPCA initalization, Bottom Latent-
space representation considering 3D Point Cloud represen-
tation and PPCA initalization.
examples of bi-dimensional latent-spaces recovered
by training the model using sequences of the HDM05
“Cuts” dataset in Figures 3 and 4. In these figures,
each color corresponds to a different class of action,
crosses are the latent representations for each individ-
ual data point, triangles correspond to the centroids
of the training sequences and finally the squares cor-
respond to the estimated position of the testing se-
quences’ centroids, as they are computed using the
back-constraints. In Figure 3 the recovered latent-
spaces are shown for three different types of repre-
sentations considered for the sequences and by using
Probabilistic PCA, in order to retrieve initial values
for the latent points. In the case of Euler Angles
and Unit-Quaternions, one can notice that different
DiscriminativeSequenceBack-constrainedGP-LVMforMOCAPbasedActionRecognition
93

sequences are placed on top of each other and thus
we expect classification rates to be low. We expect
that this mainly depends on the high non-linearity of
the data-space and the fact the PPCA, being a linear
dimensionality reduction technique, is not able to pro-
vide suitable initial values for the latent points. As
our model is non-linear and it is optimized by using
a gradient based algorithm, it is susceptible to local
minima. However, in the case of 3D point cloud rep-
resentation, the data-space does not show excessive
non-linearity and even PPCA initialization seems to
be sufficient to recover a better structure for the latent-
space.
The case of Relative Features (as in (M
¨
uller, 2007)
but without discretization based on some threshold)
is examined in Figure 4. Relative features include for
example the distance between two specified joints, the
distance of a joint with respect to the plane defined by
three other, the angle between two successive joints
etc. Here we can better observe the impact of the ini-
tialization technique on the resulting structure of the
latent-space. It is evident that the use of more so-
phisticated non-linear dimensionality reduction tech-
niques to obtain the initial values, helps recovering a
better structure of the common latent-space.
Evaluation on Actions of the CMU Dataset Seven
actions from the CMU dataset (CMU, 2003) have
been also considered for evaluating the model we pro-
pose. This dataset includes the following actions:
• Walking - 15 sequences
• Running - 15 sequences
• Jumping - 15 sequences
• Sitting-Standing - 7 sequences
• Throwing-Tossing - 15 sequences
• Boxing - 9 sequences
• Dancing - 9 sequences
Each of these actions is performed from a dif-
ferent actor. Moreover, the actions have not been
hand-picked and their label only relies on the default
labelling provided by the publishers of the dataset.
Finally, motion sequences have not been manually
segmented. We perform classification instead by
just considering the first two seconds of each se-
quence. For these reasons, we can see that this dataset
represents a more challenging and realistic instance
of the action recognition problem. Five-fold cross-
validation has been used here for obtaining the final
classification results.
The classification accuracy achieved by the pro-
posed method, compared with the results of DTW
−14 −12 −10 −8 −6 −4 −2 0 2
−10
−8
−6
−4
−2
0
2
−12 −10 −8 −6 −4 −2 0 2
−10
−8
−6
−4
−2
0
−12 −10 −8 −6 −4 −2 0
−10
−9
−8
−7
−6
−5
−4
−3
−2
−1
0
Figure 4: Top Latent-space representation considering Rel-
ative features representation and PPCA initalization, Mid-
dle Latent-space representation considering Relative fea-
tures representation and LLE initalization, Bottom Latent-
space representation considering Relative features represen-
tation and ISOMAP initalization.
distances and V-GPDS method, are provided in Ta-
ble 2. Here, Euler angles are considered as features
provided to the D-SBGPLVM, while the rest of the
setting is the same with the one described for the
“Cuts” experiments. In Figure 5 we provide the cor-
responding confusion matrix and the overall classifi-
cation rate, when the D-SBGPLVM model is used.
We can observe here, that the results for the
“CMU” dataset are analogous to the ones correspond-
ing to the “Cuts” dataset. We expect that the lower
rate achieved in general by all algorithms mainly de-
pend on the particular difficulties which characterise
this dataset, as mentioned above. Considering this
difficulties, one can see that the proposed model gives
satisfying classification results. This also demon-
ICPRAM2013-InternationalConferenceonPatternRecognitionApplicationsandMethods
94

Table 2: Comparison of the classification results for the ac-
tions taken from CMU dataset.
DTW V-GPDS D-SBGPLVM
Walk 80.0% 40.0% 66.7%
Run 60.0% 40.0% 66.7%
Jump 86.7% 40.0% 73.3%
Throw-Toss 80.0% 40.0% 80.0%
Sit-Stand 46.7% 40.0% 80.0%
Box 100% 20.0% 80.0%
Dance 26.7% 80.0% 73.3%
Average 63.5% 42.9% 72.9%
Figure 5: Confusion matrix by using D-SBGPLVM model
in combination with SVM on the CMU dataset. Average
accuracy: 72.9%.
strates the generalization capabilities of the proposed
probabilistic model, which based on this characteris-
tic leads to an overall accuracy that exceeds the ac-
curacy achieved by the other two methods considered
here.
6 CONCLUSIONS
In this paper, we have introduced a novel GP-LVM
variant in order to recover the structure of a lower
dimensional manifold for a set of sequences of dif-
ferent types that attains increased classification accu-
racy by working in the low dimensional latent-space
instead of the original data-space. By exploiting the
inverse mapping, from the data-space to the latent-
space our approach is able to infer the class of a new
sequence within a few seconds using a contemporary
computer and a non-optimized implementation. This
provides a crucial advantage with respect to other GP-
LVM models which, by resorting to a new optimiza-
tion to obtain the latent-space representation of the
new data instances, require several minutes to com-
plete this task. We have further shown that the pro-
posed D-SBGPLVM model attains classification rate
equivalent to the current state-of-the-art when com-
bined with a standard classifier, as for example SVM,
for classification in the latent-space.
We have focused our work on sequences origi-
nating from motion capture datasets. However, we
expect to obtain satisfying results also by using se-
quences acquired by consumer depth cameras (e.g.
Kinect (Microsoft, 2010)). There is a series of prob-
lems which should be addressed though in this case.
The first regards the high level of noise of the data
acquired by using this type of devices. The induced
noise significantly degrades the quality of the data
which in turn impairs classification in contrast to the
case where highly accurate data obtained by profes-
sional 3D motion capture techniques, are used. We
have also found that sampling rate plays an important
role in the recognition accuracy and the fact that these
devices are limited to an acquisition rate of 30 frames
per second may render the classification process even
more difficult. Finally, the situation is further compli-
cated by the fact that using such devices, the acquired
skeleton may not be complete as some part of the per-
former’s body may lay outside the field of view of the
device.
Within the directions of our future work, we fur-
ther consider the combination of the proposed method
with a pose recovery algorithm. In this way, it would
be possible to train the model by using action se-
quences taken from a MoCap dataset and classify se-
quences recovered from videos by means of the pose
recovery algorithm. This would further allow us to
perform action recognition from 2D video sequences
as well.
ACKNOWLEDGEMENTS
This paper describes research done under the EU-FP7
ICT 247870 NIFTI project.
REFERENCES
Aggarwal, J. K. and Cai, Q. (1999). Human motion anal-
ysis: A review. Computer Vision and Image Under-
standing, 73(3):428–440.
Bahlmann, C., Haasdonk, B., and Burkhardt, H. (2002).
On-line handwriting recognition with support vector
machines-a kernel approach. In International Work-
shop on Frontiers in Handwriting Recognition, pages
49–54.
CMU (2003). Carnegie-mellon mocap database. http://
mocap.cs.cmu.edu/.
DiscriminativeSequenceBack-constrainedGP-LVMforMOCAPbasedActionRecognition
95

Cuturi, M., Vert, J.-P., Birkenes, O., and Matsui, T. (2006).
A kernel for time series based on global alignments.
Compute Research Repository.
Damianou, A. C., Titsias, M. K., and Lawrence, N. D.
(2011). Variational gaussian process dynamical sys-
tems. In Neural Information Processing Systems Con-
ference, pages 2510–2518.
Gong, D. and Medioni, G. (2011). Dynamic manifold warp-
ing for view invariant action recognition. In Interna-
tional Conference on Computer Vision.
H
¨
ardle, W. and Simar, W. (2003). Applied Multivariate Sta-
tistical Analysis. Springer Verlag.
Lawrence, N. D. (2003). Gaussian process latent variable
models for visualisation of high dimensional data. In
Neural Information Processing Systems Conference.
Lawrence, N. D. and Qui
˜
nonero Candela, J. (2006). Lo-
cal distance preservation in the gp-lvm through back
constraints. In International Conference on Machine
learning, pages 513–520.
Li, Y., Ferm
¨
uller, C., Aloimonos, Y., and Ji, H. (2010).
Learning shift-invariant sparse representation of ac-
tions. In International Conference on Computer Vi-
sion and Pattern Recognition, pages 2630–2637.
Microsoft, C. (2010). Kinect. http://www.xbox.com/
en-US/kinect.
mocapdata.com (2011). Eyes, japan co. ltd. http://
www.mocapdata.com/.
Moeslund, T. B., Hilton, A., and Kr
¨
uger, V. (2006). A sur-
vey of advances in vision-based human motion cap-
ture and analysis. Computer Vision and Image Under-
standing, 104(2-3):90–126.
Mordohai, P. and Medioni, G. G. (2010). Dimension-
ality estimation, manifold learning and function ap-
proximation using tensor voting. Journal of Machine
Learning Research, 11:411–450.
M
¨
uller, M. (2007). Information Retrieval for Music and
Motion. Springer Verlag.
M
¨
uller, M., R
¨
oder, T., and Clausen, M. (2005). Efficient
content-based retrieval of motion capture data. In SIG-
GRAPH, pages 677–685.
Muller, M., Roder, T., Clausen, M., Eberhardt, B., Kr
¨
uger,
B., and Weber, A. (2007). Documentation mocap
database hdm05. Technical Report CG-2007-2, Uni-
versit
¨
at Bonn.
Ntouskos, V., Papadakis, P., and Pirri, F. (2012). A compre-
hensive analysis of human motion capture data for ac-
tion recognition. In Proceedings of the International
Conference on Computer Vision Theory and Applica-
tions, pages 647–652.
Poggio, T. (1985). Early vision: From computational struc-
ture to algorithms and parallel hardware. Computer
Vision, Graphics, and Image Processing, 31(2):139–
155.
Rasmussen, C. and Williams, C. (2006). Gaussian pro-
cesses for machine learning. Adaptive computation
and machine learning. MIT Press.
Roweis, S. and Saul, L. (2000). Nonlinear dimensional-
ity reduction by locally linear embedding. Science,
290(5500):2323–2326.
Sheikh, Y., Sheikh, M., and Shah, M. (2005). Exploring the
space of a human action. International Conference on
Computer Vision, 1:144–149.
Shimodaira, H., Noma, K., Nakai, M., and Sagayama, S.
(2001). Dynamic Time-Alignment Kernel in Support
Vector Machine. Neural Information Processing Sys-
tems Conference, 2:921–928.
Taylor, G. W., Hinton, G. E., and Roweis, S. T. (2006).
Modeling human motion using binary latent variables.
In Neural Information Processing Systems Confer-
ence, pages 1345–1352.
Tenenbaum, J. B., Silva, V. D., and Langford, J. C. (2000).
A global geometric framework for nonlinear dimen-
sionality reduction. Science.
Titsias, M. K. and Lawrence, N. D. (2010). Bayesian gaus-
sian process latent variable model. Journal of Ma-
chine Learning Research - Proceedings Track, 9:844–
851.
Turaga, P. K., Chellappa, R., Subrahmanian, V. S., and
Udrea, O. (2008). Machine recognition of human ac-
tivities: A survey. IEEE Transasctions on Circuits and
Systems for Video Technology, 18(11):1473–1488.
Urtasun, R. and Darrell, T. (2007). Discriminative gaussian
process latent variable model for classification. In In-
ternational Conference on Machine Learning, pages
927–934.
Urtasun, R., Fleet, D. J., and Fua, P. (2006). 3d people track-
ing with gaussian process dynamical models. In Inter-
national Conference on Computer Vision and Pattern
Recognition, pages 238–245.
Urtasun, R., Fleet, D. J., Geiger, A., Popovic, J., Dar-
rell, T., and Lawrence, N. D. (2008). Topologically-
constrained latent variable models. In International
Conference on Machine Learning, pages 1080–1087.
Waltisberg, D., Yao, A., Gall, J., and Van Gool, L. (2010).
Variations of a hough-voting action recognition sys-
tem. In International conference on Pattern Recogni-
tion, pages 306–312.
Wang, J. M., Fleet, D. J., and Hertzmann, A. (2006). Gaus-
sian process dynamical models. In Neural Information
Processing Systems Conference, volume 18, pages
1441–1448.
Yao, A., Gall, J., Fanelli, G., and Gool, L. V. (2011). Does
human action recognition benefit from pose estima-
tion? In British Machine Vision Conference, pages
67.1–67.11.
Yao, A., Gall, J., and Gool, L. J. V. (2010). A hough
transform-based voting framework for action recogni-
tion. In International Conference on Computer Vision
and Pattern Recognition, pages 2061–2068.
Zhang, X. and Fan, G. (2011). Joint gait-pose manifold for
video-based human motion estimation. In European
Conference on Computer Vision, pages 47–54.
ICPRAM2013-InternationalConferenceonPatternRecognitionApplicationsandMethods
96
