
Handling Unbalanced Data in Nocturnal Epileptic Seizure Detection
using Accelerometers
Kris Cuppens
1,2
, Peter Karsmakers
1,2
, Anouk Van de Vel
3
, Bert Bonroy
1
, Milica Milosevic
2
,
Lieven Lagae
4
, Berten Ceulemans
3
, Sabine Van Huffel
2
and Bart Vanrumste
1,2
1
MOBILAB, Thomas More Kempen, Geel, Belgium
2
iMinds Future Health Departement, Biomed, SCD SISTA, Electrical Engineering (ESAT), KU Leuven, Leuven, Belgium
3
Department of Paediatrics, University Hospital Leuven, Leuven, Belgium
4
University Hospital Leuven, Leuven, Belgium
Keywords:
Epilepsy Detection, Acceleration Data, Unbalanced Data, Support Vector Machines.
Abstract:
Data of nocturnal movements in epileptic patients is marked by an imbalance due to the relative small number
of seizures compared to normal nocturnal movements. This makes developing a robust classifier more difficult,
especially with respect to reducing the number of false positives while keeping a high sensitivity. In this paper
we evaluated different ways to overcome this problem in our application, by using a different weighting of
classes and by resampling the minority class. Furthermore, as we only have a limited number of training
samples available per patient, additionally it was investigated in which manner the training set size affects
the results. We observed that oversampling gives a higher performance than only adjusting the weights of
both classes. Compared to its alternatives oversampling based on the probability density function gives the
best results. On 2 of 3 patients, this technique gives a sensitivity of 95% or more and a PPV more than 70%.
Furthermore, an increased imbalance in the dataset leads to lower performance, whereas the size of the dataset
has little influence.
1 INTRODUCTION
Epileptic seizures mainly occur as paroxysmal events,
which means that they occur at a sudden, unexpected
timing. The frequency of the seizures varies from pa-
tient to patient.
25% to 30% of epileptic patients can not be treated
by medication or surgery, they suffer from so called
refractory epilepsy (Chapman et al., 2011) (Dalton
et al., 2010). To be able to track the progress of the
disease and to alarm caregivers during a seizure, these
patients should be monitored.
The type of epileptic seizures we focus on are hy-
permotor seizures, which manifest themselves as vio-
lent, uncontrolled movements of the arms and or legs,
e.g. by making a pedalling movement (Azar et al.,
2008)(R
´
emi et al., 2011). The movements can last
from a couple of seconds to multiple minutes. Due
to the possible heavy movements the patients can in-
jure themselves or even die (Husain and Sinha, 2011).
Patients may suffer from confusion after a seizure,
and when they don’t, they often recall the seizure
as a ’strange feeling’ and need comforting (Tinuper
et al., 2005)(Tinuper et al., 2007). Therefore our aim
is to develop an automated system which can detect
seizures during sleep to alarm the parents or care-
givers if a seizure occurs. A second aim is to keep
track of the number of seizures the patient has during
the night.
Much more normal movements occur compared
to seizure data which leads to very unbalanced data
when modeling the movements of these patients. In
this paper we compare techniques compensating for
the highly unbalanced seizure data, to generate a
classification model that is able to detect epileptic
seizures. The patient group we focus on are chil-
dren as the prevalence of epilepsy in children is higher
and parents want to know when their child has a
seizure during the night. Furthermore during sleep
the convulsions occur more or less in a controlled re-
producible manner without too much interference of
other noise sources such as voluntary movement. For
recording the motion, the acceleration of the arms and
legs is recorded using 3D accelerometers. We want
to have a high sensitivity (preferably close to 100%)
with as little false positives as possible. But for our
447
Cuppens K., Karsmakers P., Van de Vel A., Bonroy B., Milosevic M., Lagae L., Ceulemans B., Van Huffel S. and Vanrumste B. (2013).
Handling Unbalanced Data in Nocturnal Epileptic Seizure Detection using Accelerometers.
In Proceedings of the 2nd International Conference on Pattern Recognition Applications and Methods, pages 447-452
DOI: 10.5220/0004264704470452
Copyright
c
SciTePress

Table 1: Overview of data available in the dataset.
Patient Nights of Hypermotor Normal
number monitoring seizures movements
A 2 9 287
B 5 26 784
C 2 7 381
Total 9 42 1452
application a high sensitivity is more important, as we
do not want to miss a possible violent movement.
To overcome the issue of imbalance, we evaluated
the following approaches
• use a weighting factor to train the SVM model,
• resample the training data by estimating the prob-
ability density function of the seizure data,
• resample the seizure data based on the SMOTE
technique (Chawla et al., 2002).
Note that undersampling of the majority class was
not considered due to the very limited number of mi-
nority class samples that were available. Furthermore
we evaluated the linear and the radial basis function
(RBF) kernel and the influence of the balance and the
number of training points on the performance of our
classifier.
He et al. (He, 2009) give an overview of the state-
of-the-art techniques that are used to overcome the is-
sue of imbalance. Next to the sampling methods that
we discuss in our paper, cost-sensitive methods that
give a different cost value to misclassifying instances
of different classes, and kernel-based methods are re-
viewed. But the former two dominate the research
efforts.
2 METHODS
2.1 Dataset Overview
In this study, we use a dataset of patients suffer-
ing from hypermotor seizures, similar to what we al-
ready described in previous studies (Cuppens et al.,
2009)(Cuppens et al., 2012), but in this study we only
selected patients with at least 4 hypermotor seizures
in our dataset, because for training and testing of the
classification model, we need at least 3 and 1 seizures
respectively. An overview of the dataset is shown in
Table 1. From the raw data, five features are extracted
to represent the data: the maximal resultant over both
arms, the mean standard deviation over all channels,
the length of the epoch, the mean root mean square
over all the channels and the minimal power in the
frequency band 1-3 Hz over all the channels.
The acquired data contains EEG and video which
is used for labeling of the data by the neurologists,
and 12 channel acceleration data sampled at 250 Hz
measured with 3D accelerometers at the four limbs.
Also ECG, EMG, EOG and audio are recorded, but
these modalities are not used in this study.
2.2 Test Outline
Different classification models are estimated using
state-of-the-art Support Vector Machine (SVM) in-
ference. For this purpose the freely available libsvm
(Chang and Lin, 2011) implementation was adopted
1
.
Two groups of related application specific tests were
setup in order to investigate: a) which alternative to
adjust model inference for the high class imbalance
performed best, b) the influence of the degree of class
imbalance on the classification results c) the influence
of the training set size on the results.
All the tests we perform, are conducted in a 10
fold randomization with different combinations of
seizures and normal movements. The tests are evalu-
ated using sensitivity (measure that indicates the per-
centage of seizures that is detected, also indicated as
recall), the positive predictive value (PPV, a measure
that indicates the percentage of true detections over all
detections, also indicated as precision) and specificity
(measure that indicates the number of true negatives
over all normal movements). The sensitivity and PPV
values are averaged over the 10 randomizations and
the standard deviation is calculated. Thanks to this
randomization the obtained results are less biased.
2.2.1 Methods for Coping with Class Imbalance
To overcome the issue of imbalance, we explored:
a) different weight factors the first applied to the er-
ror term in the SVM learning objective correspond-
ing to the positive examples and the second to that
corresponding to the examples of the negative class.
For this purpose a weight factor T is introduced
which balances the weights of the error terms for both
classes in the SVM objective. b) Resampling of the
minority class, using 1) sampling from a probability
density function estimated using the available minor-
ity examples 2) generating new minority class exam-
ples using the SMOTE technique.
Resampling based on the estimation of the proba-
bility density function estimates the distribution of the
seizure data points along every feature using a non-
parametric kernel density estimation, with a Gaussian
1
http://www.csie.ntu.edu.tw/˜cjlin/libsvm/
ICPRAM2013-InternationalConferenceonPatternRecognitionApplicationsandMethods
448

function as kernel and a bandwidth equal to the stan-
dard deviation of the seizure data. Based on this esti-
mated distribution, new points are randomly sampled.
The SMOTE technique generates new data points by
introducing synthetic examples along the line seg-
ments that connect minority class examples with their
k minority class nearest neighbors.
In a first series of tests, we used the same number
of seizures s and normal movements n for each pa-
tient in the training (s = 4, n = 190) and testing phase
(s = 2, n = 95), to investigate the performance of the
different approaches, and to be able to compare them
over all the patients. These movements were ran-
domly chosen from each patient but with a strict sepa-
ration between training and test set. We used this spe-
cific number of normal movement and seizures based
on the smallest numbers available for each patient, i.e.
7 seizures for patient C and 287 normal movements
for patient A. For each patient, we used two thirds of
the data for training and one third for testing.
In the training phase, we used a three-fold cross-
validation to find the optimal hyper-parameters for the
SVM classifier. These parameters include the regular-
ization parameter C, kernel parameter σ and weight
factor T . C affects the trade-off between complexity
and proportion of nonseparable samples (Cherkassky
and Mulier, 1998). If it is too large, we may overfit
and consequently store many support vectors, if it is
too small, too much smoothing may be applied giving
an underfit (Alpaydin, 2004). The kernel parameter σ
denotes the kernel width parameter. A larger σ leads
to a smoother fit. The weight factor T gives a lower
or higher weight to the error cost of the negative class,
in such a way that C
−
= C ·T and C
+
= C ·(1 −T ).
The different values we tested for the parameters are:
• C : e
−3,−2,...,6
• σ :
1
√
2
e
−2.5,−2,...,2
• T ∈ {0, 0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 0.7, 1}
The cost function gives a higher weight to the sen-
sitivity compared to the PPV more specific: cost =
−(2 ·sens +PPV ).
2.2.2 Influence of Class Imbalance
In the second series of tests, we use the optimal ap-
proach found in the first tests, and investigate the
influence of the number of training examples and
the balance on the performance of the classification
model. To investigate the influence of the balance,
we keep the number of seizures in the training set
fixed (4), and increase the number of normal move-
ment from 4 (equally balanced) to 190. The same ra-
tio is used in the test set.
2.2.3 Influence of Training Set Size
For the investigation on the influence of the number
of training samples, we keep the balance the same (1
seizure for 33 normal movements), and we test this for
2, 3 and 4 seizures in the training set, and 2 seizures
and 66 normal movements in the test set.
3 RESULTS
Table 2 shows the results of the SVM classifier us-
ing the different methods compensating for the im-
balance. To be able to compare the different meth-
ods, we calculated a cost value for each test, using
the same cost function for model selection cost =
−(2 ·sens + PPV ). This cost value is shown in the
last column of Table 2. Notice that the cost values
have a negative value, as a lower cost implies a bet-
ter performance. The higher the absolute value, the
better the classifier performs. In general, we can ob-
serve that the oversampling techniques work better
than only using a different weighting for both classes,
although this is mainly due to the low performance on
patient B. Furthermore, the density estimation over-
sampling gives better results than the SMOTE tech-
nique, although the PPV values of using SMOTE are
higher compared to the density estimation oversam-
pling. But the sensitivity of the latter is higher and
this sensitivity has a higher weight in the cost func-
tion. For this density estimation oversampling, the
linear kernel performs a little better than the RBF ker-
nel, as the absolute cost value of the former is higher.
To investigate the influence of the size of the train-
ing set and the balance in the data, we used the over-
sampling based on the probability density estimation
with the linear kernel. In the first test, we evaluated
three different sizes of training set with the same bal-
ance, and a test set with a fixed amount of data. Ta-
ble 3 shows the results of this test. We do not observe
a clear trend when a larger set of data is used. Al-
though there is a difference in performance in each
test with respect to the sensitivity and PPV for each
patient, the overall cost stays more or less the same.
Table 4 shows the results of the second test, where
we tested the influence of the balance of the dataset
on the performance. These results show that the bal-
ance of the dataset has a large influence on the per-
formance. When the number of seizures and normal
movements is equal, the performance is best, with a
sensitivity and PPV of 100.00% for patient A and C.
For patient B and for all patients combined, the values
are around 50.00% for the sensitivity and 85.00% or
higher for the PPV. But when the imbalance increases,
HandlingUnbalancedDatainNocturnalEpilepticSeizureDetectionusingAccelerometers
449

Table 2: Results of performance of SVM classifier using different methods to overcome the problem of imbalance.
Balance factor
linear n
◦
sens.(%) std. PPV.(%) std.(%) spec.(%) std.(%) -cost
kernel A 80.00 25.82 93.33 14.05 99.79 0.44 253.33
B 0.00 0.00 0.00 0.00 99.37 1.66 0.00
C 80.00 42.16 89.58 19.80 99.68 0.71 249.58
all 10.00 21.08 16.67 25.82 98.95 1.57 36.67 134.90
RBF n
◦
sens.(%) std.(%) PPV.(%) std.(%) spec.(%) std.(%) -cost
kernel A 90.00 21.08 90.00 16.10 99.68 0.51 270.00
B 5.00 15.81 25.00 50.00 99.68 0.51 35.00
C 50.00 52.70 100.00 0.00 100.00 0.00 200.00
all 15.00 24.15 14.29 20.25 98.21 1.79 44.29 137.32
Probability density estimation oversampling
linear n
◦
sens.(%) std.(%) PPV.(%) std.(%) spec.(%) std.(%) -cost
kernel A 90.00 21.08 68.67 29.15 98.63 1.41 248.67
B 70.00 34.96 12.44 6.50 88.95 3.92 152.44
C 100.00 0.00 83.33 22.22 99.37 0.89 283.33
all 65.00 24.15 12.90 5.84 89.47 4.30 142.90 206.84
RBF n
◦
sens.(%) std.(%) PPV.(%) std.(%) spec.(%) std.(%) -cost
kernel A 95.00 15.81 74.00 23.98 98.95 1.11 264.00
B 60.00 39.44 12.99 10.08 91.05 4.25 132.99
C 100.00 0.00 80.00 26.99 99.05 1.44 280.00
all 45.00 36.89 19.41 13.27 95.79 3.33 109.41 196.60
SMOTE oversampling
linear n
◦
sens.(%) std.(%) PPV.(%) std.(%) spec.(%) std.(%) -cost
kernel A 90.00 21.08 83.33 22.22 99.47 0.74 263.33
B 45.00 36.89 9.84 8.18 91.68 3.27 99.84
C 85.00 33.75 87.04 20.03 99.58 0.74 257.04
all 55.00 28.38 17.22 10.35 92.21 5.39 127.22 186.86
RBF n
◦
sens.(%) std.(%) PPV.(%) std.(%) spec.(%) std.(%) -cost
kernel A 90.00 21.08 75.67 26.44 99.05 1.16 255.67
B 30.00 25.82 15.59 19.47 95.68 3.42 75.59
C 80.00 34.96 87.04 20.03 99.58 0.74 247.04
all 45.00 28.38 16.58 14.53 94.00 3.75 106.58 171.22
Table 3: Results of performance using resampling based on a density estimation and a linear kernel in the SVM classifier.
This table shows the influence of different sizes of the training set.
Training: 2 seizures, 66 normal Test: 2 seizures, 66 normal
n
◦
sens.(%) std. PPV.(%) std.(%) spec.(%) std. -cost
A 95.00 15.81 81.67 19.95 99.09 1.06 271.67
B 65.00 33.75 18.15 9.38 90.30 6.32 148.15
C 100.00 0.00 83.33 17.57 99.24 0.80 283.33
all 70.00 34.96 22.65 11.18 92.73 3.96 162.65 216.45
Training: 3 seizures, 99 normal Test: 2 seizures, 66 normal
n
◦
sens.(%) std.(%) PPV.(%) std.(%) spec.(%) std.(%) -cost
A 90.00 21.08 76.67 21.08 98.79 1.20 256.67
B 75.00 35.36 14.70 7.00 87.27 2.49 164.70
C 100.00 0.00 66.67 19.25 98.18 1.20 266.67
all 65.00 33.75 22.99 14.18 92.12 5.09 152.99 210.26
Training: 4 seizures, 132 normal Test: 2 seizures, 66 normal
n
◦
sens.(%) std.(%) PPV.(%) std.(%) spec.(%) std.(%) -cost
A 90.00 21.08 76.67 22.50 98.94 1.02 256.67
B 70.00 34.96 15.82 11.21 86.82 7.92 155.82
C 100.00 0.00 70.00 21.94 98.33 1.33 270.00
all 70.00 25.82 21.03 12.13 89.85 4.90 161.03 210.88
we see a gradual reduction of the performance, which
is also reflected in the cost value for each test, which
increases from -244.72 when the dataset is balanced,
to -207.04 when the imbalance is largest (4 seizures
compared to 190 normal movements).
ICPRAM2013-InternationalConferenceonPatternRecognitionApplicationsandMethods
450
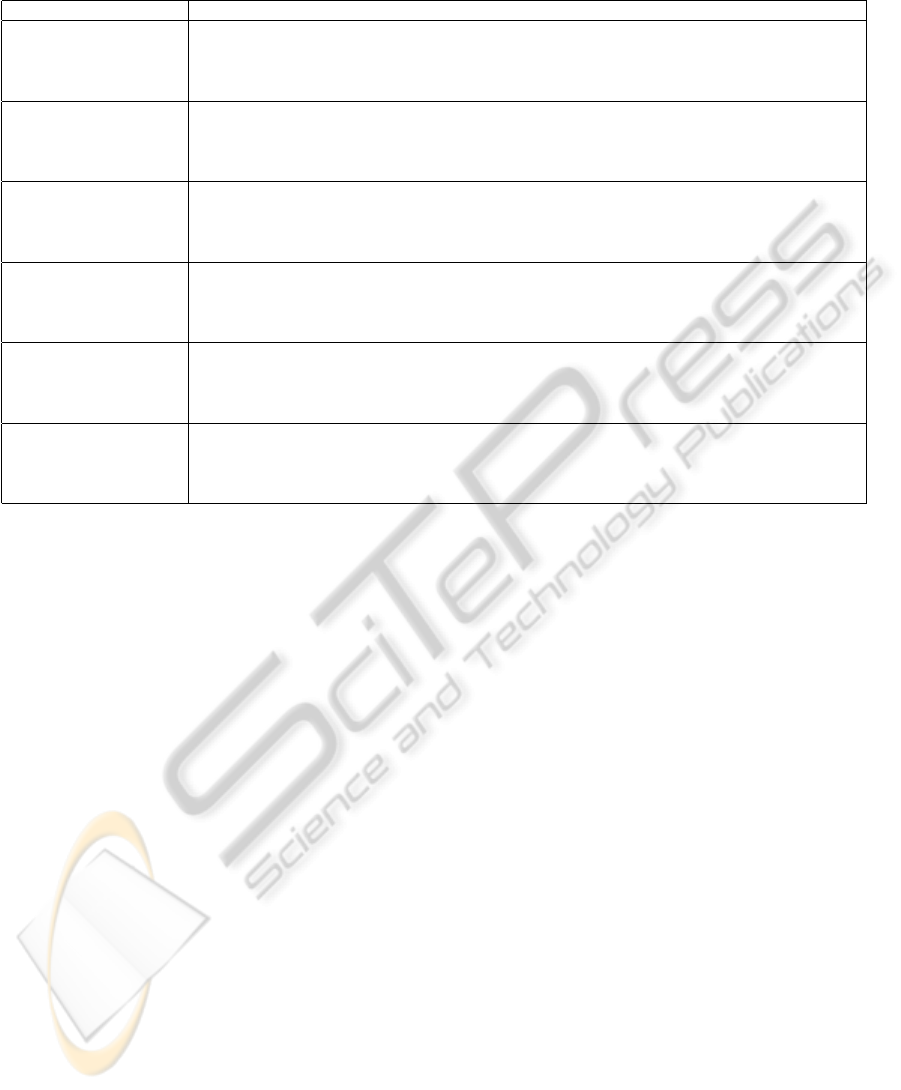
Table 4: Results of performance using resampling based on a density estimation and a linear kernel in the SVM classifier.
This table shows the influence of a different balance between seizures and normal movements in the training and test set.
n
◦
sens.(%) std.(%) PPV.(%) std.(%) spec.(%) std.(%) -cost
Training: A 100.00 0.00 100.00 0.00 100.00 0.00 300.00
4 seizures, 4 normal B 50.00 47.14 88.89 17.21 90.00 21.08 188.89
Test: C 100.00 0.00 100.00 0.00 100.00 0.00 300.00
2 seizures, 2 normal all 45.00 28.38 100.00 0.00 100.00 0.00 190.00 244.72
Training: A 95.00 15.81 100.00 0.00 100.00 0.00 290.00
4 seizures, 10 normal B 60.00 45.95 68.75 33.85 88.00 13.98 188.75
Test: C 100.00 0.00 100.00 0.00 100.00 0.00 300.00
2 seizures, 5 normal all 55.00 36.89 74.07 35.46 92.00 10.33 184.07 240.71
Training: A 95.00 15.81 90.00 16.10 98.00 3.22 280.00
4 seizures, 30 normal B 65.00 41.16 45.67 34.10 88.00 8.78 175.67
Test: C 100.00 0.00 100.00 0.00 100.00 0.00 300.00
2 seizures, 15 normal all 65.00 33.75 63.70 29.03 92.00 9.32 193.70 237.34
Training: A 95.00 15.81 90.00 16.10 99.14 1.38 280.00
4 seizures, 70 normal B 70.00 34.96 27.21 15.16 87.14 7.77 167.21
Test: C 100.00 0.00 78.33 23.64 97.71 2.63 278.33
2 seizures, 35 normal all 65.00 24.15 48.61 23.98 94.29 6.46 178.61 226.04
Training: A 90.00 21.08 76.67 22.50 98.94 1.02 256.67
4 seizures, 132 normal B 70.00 34.96 15.82 11.21 86.82 7.92 155.82
Test: C 100.00 0.00 70.00 21.94 98.33 1.33 270.00
2 seizures, 66 normal all 70.00 25.82 21.03 12.13 89.85 4.90 161.03 210.88
Training: A 90.00 21.08 68.67 29.15 98.63 1.41 248.67
4 seizures, 190 normal B 70.00 34.96 13.16 8.36 88.95 4.16 153.16
Test: C 100.00 0.00 83.33 22.22 99.37 0.89 283.33
2 seizures, 95 normal all 65.00 24.15 13.02 5.77 89.47 4.57 143.02 207.04
4 DISCUSSION
The oversampling methods give the best results.
However, we still observe that with an increasing
unbalance, the performance gets worse. It should
be noted that thanks to the oversampling, the SVM
model is still trained with an equally balanced train-
ing set, and that only the test set remains unbalanced.
When we test the statistical significance of the dif-
ference in methods to overcome the issue of imbal-
ance, we observe that in patient A non of the methods
or type of kernel in the SVM approach give a signif-
icant difference for either sensitivity or PPV. In pa-
tient B there is a significant difference (with p-values
lower than 0.05) between methods and kernels, ex-
cept for the difference in PPV for the type of kernel.
For patient C only the difference in sensitivity for the
method (not the kernel) is significant.
In most of the trials, the performance on patient B
is lower. This is due to the different clinical manifes-
tation of the seizures of this patient, which are clearly
shorter in time and lower in intensity.
Note that for the calculation of the performance
on all patients, the varying number of seizures per pa-
tient is not taken into account. This means that the
influence of patient B is higher than those of patient
A en C as 62% of the total seizures belong to patient
B (26 on a total of 42). This explains why the per-
formance of all patients combined is most of the time
very similar to the performance on patient B.
In the real setting the balance between epileptic
and normal movements can differ from patient to pa-
tient, and therefore influence the patient-specific per-
formance.
The number of seizures we collected is small for
some patients, which makes the training of an SVM
classifier more difficult if we want to make patient-
specific models. Although the results of the tests on
the influence of the dataset size indicated that there
is no big difference when changing the amount of
data. However, this statement needs to be interpreted
carefully since the number of seizures was too small
to draw any conclusions about the relation between
seizure set size and classification performance.
Due to the limited number of seizure examples,
the weighting method does not give very good results.
This can be explained by the fact that the number of
the support vector candidates is small, which reduces
the flexibility of setting the decision hyperplane. We
also noticed that the cost of most of the different pa-
rameter combinations (C, σ, T ) was the same when
using only the weighting of the classes. This means
that due to the limited number of training examples,
the hyper-parameters only have a small influence on
HandlingUnbalancedDatainNocturnalEpilepticSeizureDetectionusingAccelerometers
451

the decision hyperplane.
In our tests we used 2 seizures in the test set using
10 randomizations. Therefore, the resolution of the
sensitivity is only 5%. This is also visible in the tables
showing the results.
For using the SMOTE technique, we have only a
limited number of seizures in our setup when using
the 3-fold cross-validation in determining the optimal
parameters for the SVM. The new data points are gen-
erated on the line segments connecting the minority
class examples, but sometimes there is only one near-
est neighbor (for determining the line segments) for
generating new data points. This can explain why
the SMOTE technique gives lower results, although
it also works well for patient A and C.
We also evaluated a cost function taking into ac-
count the decision values of the SVM classification
(indicating the distance from the data points to the
decision plane). However, this did not give any better
results compared to our original cost function, in most
cases the performance was even lower.
5 CONCLUSIONS
We have tested different approaches to overcome
the imbalance problem in our application of detect-
ing nocturnal epileptic seizures in children using ac-
celerometers. Oversampling of the minority class
seems to give the best results, especially the density
estimation oversampling. On 2 of 3 patients, this tech-
nique gives a sensitivity of 95% or more and a PPV
more than 70%.
ACKNOWLEDGEMENTS
Research supported by Research Council KUL:
GOA-MANET, IWT: TBM070713-Accelero, Bel-
gian Federal Science Policy Office IUAP P6/04
(DYSCO, ’Dynamical systems, control and optimiza-
tion, 2007-2011); EU: Neuromath (COSTBM0601).
Kris Cuppens is funded by a Ph.D. grant of the
Agency for Innovation by Science and Technology
(IWT).
REFERENCES
Alpaydin, E. (2004). Introduction to Machine Learning.
MIT Press.
Azar, N. J., Tayah, T. F., Wang, L., Song, Y., and Abou-
Khalil, B. W. (2008). Postictal breathing pattern
distinguishes epileptic from nonepileptic convulsive
seizures. Epilepsia, 49(1):132–7.
Chang, C.-C. and Lin, C.-J. (2011). LIBSVM: A library
for support vector machines. ACM Transactions on
Intelligent Systems and Technology, 2:27:1–27:27.
Chapman, D., Panelli, R., Hanna, J., and Jeffs, T. (2011).
Sudden unexpected death in epilepsy: continuing the
global conversation. Camberwell, Australia.
Chawla, N., Bowyer, K., Hall, L., and Kegelmeyer, W.
(2002). SMOTE: Synthetic minority over-sampling
technique. Journal of Artificial Intelligence Research,
16:321–357.
Cherkassky, V. and Mulier, F. (1998). Learning from Data:
Concepts, Theory, and Methods. John Wiley & Sons.
Cuppens, K., Karsmakers, P., Van de Vel, A., Luca, S.,
Bonroy, B., Milosevic, M., Croonenborghs, T., Ceule-
mans, B., Lagae, L., Van Huffel, S., and Vanrumste,
B. (2012). Accelerometer based home monitoring for
detection of nocturnal hypermotor seizures based on
novelty detection. internal report.
Cuppens, K., Lagae, L., Ceulemans, B., Van Huffel, S.,
and Vanrumste, B. (2009). Detection of nocturnal
frontal lobe seizures in pediatric patients by means of
accelerometers: a first study. In Proc. of the Annual
International Conference of the IEEE Engineering in
Medicine and Biology Society (EMBC 2009), volume
1-20, pages 6608–6611.
Dalton, A., Patel, S., Chowdhury, A., Welsh, M., Pang, T.,
Schachter, S.,
´
Olaighin, G., and Bonato, P. (2010).
Detecting epileptic seizures using wearable sensor
technologies. In Proc. of the First AMA-IEEE Medical
Technology Conference on Individualized Healtcare.
He, H.and Garcia, E. (2009). Learning from imbalanced
data. IEEE Transactions on Knowledge and Data En-
gineering, 21:1263–1284.
Husain, A. M. and Sinha, S. R. (2011). Nocturnal epilepsy
in adults. J Clin Neurophysiol., 28(2):141–5.
R
´
emi, J., Silva Cunha, J. P., Vollmar, C., Topc¸u
˘
oglu, O. B.,
Meier, A., Ulowetz, S., Beleza, P., and Noachtar, S.
(2011). Quantitative movement analysis differentiates
focal seizures characterized by automatisms. Epilepsy
Behav., 20(4):642–7.
Tinuper, P., Provini, F., Bisulli, F., and Lugaresi, E. (2005).
Hyperkinetic manifestations in nocturnal frontal lobe
epilepsy. semeiological features and physiopathologi-
cal hypothesis. Neurol Sci., 26(suppl 3):210–4.
Tinuper, P., Provini, F., Bisulli, F., Vignatelli, L., Plazzi, G.,
Vetrugno, R., Montagna, P., and Lugaresi, E. (2007).
Movement disorders in sleep: guidelines for differen-
tiating epileptic from non-epileptic motor phenomena
arising from sleep. Sleep Med Rev., 11(4):255–67.
ICPRAM2013-InternationalConferenceonPatternRecognitionApplicationsandMethods
452
