
Data Quality Sensitivity Analysis on Aggregate Indicators
Mario Mezzanzanica, Roberto Boselli, Mirko Cesarini and Fabio Mercorio
Department of Statistics, C.R.I.S.P. Research Centre, University of Milan Bicocca, Milan, Italy
Keywords:
Data Quality, Data Cleansing, Sensitivity Analysis, Inconsistent Databases, Aggregate Indicators, Uncertainty
Assessment.
Abstract:
Decision making activities stress data and information quality requirements. The quality of data sources is
frequently very poor, therefore a cleansing process is required before using such data for decision making
processes. When alternative (and more trusted) data sources are not available data can be cleansed only us-
ing business rules derived from domain knowledge. Business rules focus on fixing inconsistencies, but an
inconsistency can be cleansed in different ways (i.e. the correction can be not deterministic), therefore the
choice on how to cleanse data can (even strongly) affect the aggregate values computed for decision making
purposes. The paper proposes a methodology exploiting Finite State Systems to quantitatively estimate how
computed variables and indicators might be affected by the uncertainty related to low data quality, indepen-
dently from the data cleansing methodology used. The methodology has been implemented and tested on a
real case scenario providing effective results.
1 INTRODUCTION
Several studies, e.g. (Batini and Scannapieco, 2006;
Strong et al., 1997; Redman, 1998), report that en-
terprise databases and public administration archives
suffer from poor data quality, therefore data assess-
ment and (in case) cleansing activities are required
before data can be used for decision making. The best
solution for improving data quality would be cleans-
ing a database relying on the comparison with differ-
ent (and more trusted) data sources. Unfortunately
this is rarely feasible. An alternative solution is to col-
lect real data and then to use it for comparison, how-
ever this approach may be extremely expensive. Data
cleansing using rules derivedfrom domain knowledge
(business rules) is the most frequently adopted solu-
tion when the previously described approachesare not
feasible. Business rules focus on consistency check-
ing and corrective actions are implemented when an
inconsistency is found. Such actions may modify,
delete or add data to the existing databases.
Data quality is a general concept and it can be de-
scribed by many dimensions, e.g., accuracy, and con-
sistency, accessibility. The reader is referred to (Ba-
tini and Scannapieco, 2006)) for a complete survey. In
this paper we focus on consistency, which (according
to the previously cited survey) is a dimension describ-
ing the violation of semantic rules defined over a set
of data items, where items can be tuples of relational
databases.
Consider the dataset in Tab. 1 showing a cruise
ship travel plan. The ship usually travels by sea, then
stops at intermediate destinations (port of calls), mak-
ing a checkin when entering the harbour and a check-
out when exiting from it.
An example of low data quality is the missing de-
parture date from Lisbon, since there is no checkout
from the Lisbon’s harbour.
Table 1: Travel plan of a cruise ship.
ShipID City Date Event Type
S01 Venice 12th April 2011 checkin
S01 Venice 15st April 2011 checkout
S01 Lisbon 30th April 2011 checkin
S01 Barcelona 5th May 2011 checkin
S01 Barcelona 8nd May 2011 checkout
...
Such inconsistencies should be fixed before us-
ing data for decision making activities. The depar-
ture from Lisbon might be set on May 3
rd
, e.g. by
observing that the ship usually stays in the harbour
for 3 days. Of course, there is no certainty of having
guessed the real value (unless the real and correct data
can be obtained in some way), the ship could have de-
parted either on the 1
st
, or on the 2
nd
, or on May the
4
th
, etc.
97
Mezzanzanica M., Boselli R., Cesarini M. and Mercorio F..
Data Quality Sensitivity Analysis on Aggregate Indicators.
DOI: 10.5220/0004040300970108
In Proceedings of the International Conference on Data Technologies and Applications (DATA-2012), pages 97-108
ISBN: 978-989-8565-18-1
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

Focusing on an indicator like active travel days
(i.e., the number of day spent by the ship on the sea),
missing dates create uncertainty, their impact on the
indicator should be carefully evaluated when a lot of
wrong dates are detected and (important) business de-
cisions will be based thereon. Hereafter the term in-
dicator will be used to refer to any kind of aggregate
information derived from database contents.
The work presented in this paper describes a
methodology (focusing on data consistency check
based on formal methods) for executing a sensitivity
analysis on indicators computed on possibly inconsis-
tent data.
1.1 Related Work
Data quality is a large and complex domain as re-
ported in (Batini et al., 2009). The work presented
in this paper can be framed on the data cleansing field
(also called data cleaning or scrubbing) which deals
with detecting and removing errors and inconsisten-
cies from data in order to improve the quality of data
(Rahm and Do, 2000).
Works on repair focus on finding a consistent
database and minimally different from the origi-
nal one, however the authors of (Chomicki and
Marcinkowski, 2005) state that computational in-
tractability affects algorithms used for performing
minimal-change integrity maintenance.
Consistent query answering approaches focus
on finding consistent answers from inconsistent
databases, whereas an answer is considered consis-
tent when it appears in every possible repair of the
original database (Arenas et al., 1999). The authors
of (Arenas et al., 2003) investigate how to compute
the range of possible value results that an aggregate
query can return from an inconsistent database.
The latter work shows a lot of similarities with the
one presented in this paper: both focus on evaluat-
ing the range of possible values that an aggregate in-
dicator may assume. However (Arenas et al., 2003)
focuses only on the SQL aggregate functions (MIN,
MAX, COUNT, SUM, and AVG) while the approach
described in this paper can be easily generalised to
a broader set of indicators/aggregate functions. Fur-
thermore, as the authors state, the computation of ag-
gregate queries in such context is an intractable prob-
lem when two or more functional dependencies are
used (Arenas et al., 2003). Unfortunately this is the
case of many real world domain consistency problem
(as the one described in Sec. 4).
In (Embury et al., 2001) the authors identify data
integration conflicts exploiting a formal model built
upon rules derived from domain knowledge. Integrity
checking and repairing techniques are used to detect
the data violating the model. However the authors
outline that exploiting the latter technique for repair-
ing a complete database (and not a single transaction)
requires to look for repairs on a very large combinato-
rial search space since transaction analysis cannot be
used to prune it.
Many cleansing tools and database systems ex-
ploit integrity analysis (including relational integrity)
for identifying errors. While data integrity analysis
can uncover a number of possible errors in a data set,
it does not address complex ones (Maletic and Mar-
cus, 2000).
Some research activities, e.g. (Fan et al., 2008),
focus on expanding integrity constraints paradigms to
deal with a broader set of errors by introducing condi-
tional functional dependencies, i.e. functional depen-
dencies holding only on a subset of tuples identified
by a specific condition. However conflicts may arise
among the several dependencies, and their discovery
may be an intractable problem. Furthermore con-
straints checking that involves different tuples (e.g.
like the examples showed in Tab. 1 and in Sec. 4) can
result in a very complex and large set of conditional
functional dependencies.
In (Arasu and Kaushik, 2009) “augmented context
free grammars” are used to extract information from
attributes, and to subsequently cleanse data. Such ap-
proach mainly focuses on the attribute level, whilst
the work presented in this paper focuses on set-of-
events semantics and consistency.
“Learning based methods” can be used for data
cleansing. Possible techniques and approaches are:
unsupervised learning, statistical methods, data pro-
filing tools exploiting integrity constraints, range and
threshold checking, pattern recognition, clustering
methodologies, and rule discovery from sequential
data (Mayfield et al., 2009; Sang Hyun et al., 2001).
Such techniques may guess wrong information e.g.
(the next is an overstated example), they might er-
roneously conclude that double entries are fine in a
database containing a lot of incorrect double entries.
These methods can improve their performance in re-
sponse to human feedbacks. However the model that
is built during the learning phase by these techniques
can’t be easily accessed by domain experts. In this
paper we explore a different approach where consis-
tency models are explicitly built and validated by do-
main experts.
Correction steps (also known as imputation or
data editing) are performed in the statistical domain
without altering the collected data statistical parame-
ters (Fellegi and Holt, 1976). Not altering the statis-
tical parameters is required to make inferences from
DATA2012-InternationalConferenceonDataTechnologiesandApplications
98

the sample data about the whole population. How-
ever, in a scenario where datasets covering the whole
population are available (e.g. public administration
databases), inference is no more a strong requirement,
whilst data cleansing is paramount.
Many data cleansing toolkits have been proposed
for implementing, filtering, and transforming rules
over data. A survey can be found in (Galhardas et al.,
2000; M¨uller and Freytag, 2003). A detailed survey
of those tools is outside the scope of the paper, here
it is enough to summarise that they implement in sev-
eral ways the theoretical approaches described in this
section.
1.2 Contribution
The contribution of our work is twofold: from one
side we propose a methodology to quantitatively es-
timate the impact that uncertainty (due to low data
quality) can have on indicators computed on cleansed
data. On the other side this methodology has been im-
plemented and validated against a real-world domain
application.
For the sake of clarity, in Sec. 2 we briefly in-
troduce how formal methods can be used to verify
database consistency. Sec. 3 describes the proposed
methodology to perform sensitivity analysis on indi-
cators derived from low quality databases, while in
Sec. 4 a real scenario is introduced and the results ob-
tained are outlined. Finally, Sec. 5 draws some con-
clusion and outlines the future work.
2 DATA CONSISTENCY
THROUGH FORMAL
METHODS
The idea behind this paper draws on the work of
(Mezzanzanica et al., 2011) where a database con-
tent is mapped onto a set of events (called Finite State
Event Database), a formal model modeling the con-
sistent evolution of data is built, and the data is val-
idated against the model by using model checking
techniques. Generally speaking, an event (or transi-
tion) in a system represents a change that may oc-
cur in the system state as a consequence of an ac-
tion. In (Mezzanzanica et al., 2011) the authors map a
database record onto an event and the attributes of the
record onto the event information. As a consequence,
consistency verification can be turned into a model
checking problem, which allows one to exploit the
formalisation and the computational power of Model
Checking techniques. Due to the space limitation we
cannot deeply describe the details of their techniques.
However, since in the paper we often refer to the con-
cept of Finite State Event Database, we formalise the
following:
Definition 1 (Finite State Event Database). Let E =
{e
1
, . . . , e
n
} be a finite set of events, and let ⋚ a to-
tal order operator such that e
1
⋚ e
2
⋚ . .. ⋚ e
n
, then
a Finite State Event Dataset (FSED) is a dataset S
whose content is an ⋚-ordered sequence of events
ε = e
1
, . . . , e
n
. Then, a Finite State Event Database
(FSEDB) is the union of FSEDs as
S
k
i=1
S
i
where k ≥
1. By abuse of notation we also denote ε = e
1
, . . . , e
n
as FSED.
The following example should clarify the matter.
Let us consider the Cruise Ship Travel Plan as pre-
sented in Table 1, and let us focus on the overall
cruise duration indicator. In this case, given a set
of events E, a generic event e
i
∈ E may be mapped
to the attributes ShipID, City, Date, and Event Type,
namely e
i
= (ShipID
i
,City
i
, Date
i
, EType
i
). More-
over, the binary operator ≤ defined over the event’s
attribute Date is used to generate an ordered sequence
of events, that is ∀e
i
, e
j
∈ E, e
i
≤ e
j
iff Date
e
i
≤
Date
e
j
. Finally, a simply consistency property could
be “if a ship checks in to a harbour A, then it must
check out before checking in to a different harbour“.
Fig. 1 shows an automaton modelling our example.
The system state is composed by the pos variable
(only one) which describes the ship’s position (i.e.,
sea when the ship is travelling, harbour when it is in
a port of call). Consistency verification for this ex-
ample can be turned into finding out if an event-flow-
compatible-path does exist in the automaton of Fig. 1
e.g., checkin, checkin is not a feasible path for the sys-
tem.
In this paper we perform a sensitivity analysis (see
Sec. 3) on the impact of possible corrections in sce-
narios similar to the one just introduced.
on the sea
pos=sea
start
in the harbour
pos=harbour
EType
i
= checkin
EType
i
= checkout
Figure 1: The automaton for the travel plan of a cruise ship
example.
3 DATA QUALITY SENSITIVITY
ANALYSIS
This Section will outline how to carry out indicator
sensitivity analysis on Finite State Event Databases.
It is worth noting that a Finite State Event Database
DataQualitySensitivityAnalysisonAggregateIndicators
99

is made by one or more Finite State Event Dataset.
Data consistency is checked, and for each inconsis-
tent dataset two cleansed versions are derived which
respectively minimise and maximise a reference in-
dicator. The analysis is allways performed having
an indicator as a reference. Cleansing is not always
deterministic, since several cleansed and consistent
versions can be derived from an original inconsistent
dataset. In the cruise example of Tab. 1, the departure
date from Lisbon can be set on any date from 30
th
April 2011 to 5
th
May 2011 (for simplicity it is not
considered the ship travel time which would narrow
the choice).
Informally speaking, the sensitivity analysis on
the indicator active traveldays is carried out as fol-
lows. Two timetables are selected among the set
of possible corrections: the former where the miss-
ing departure date is set on the 30
th
April 2011 (this
choice maximises the travel days) and the latter where
the departure date is set on the 5
th
May 2011 (this
choice minimises the travel days). The two datasets
are labelled respectively upper bound case and lower
bound case cleansed dataset (UB and LB case respec-
tively).
In our example one intervention is enough to
make the sequence consistent, i.e., inserting the
event e
4
= (S01, Lisbon, X, checkout) where X ∈
[30th April 2011,. . . , 5th May 2011]. Hence, the Lis-
bon to Barcelona travel days value (used to compute
the overall active traveldays) can range between 1
and 6 days.
In this example each ship timetable is a Finite
State Event Dataset, and for each of them an upper
and lower bound case is generated. For simplicity an
upper and lower bound case is generated also for con-
sistent timetable, in this case they are both equals to
the original one. The average values of respectively
the UB and LB cases (of all the ships travel plans) are
computed and then compared. The gap between the
two average values tell us how the indicator is sensi-
ble to the uncertainty caused by the missing data.
This approach cannot discover all the differences
among the database data and the “real world data”,
indeed a completely missing sequence of data can’t
be detected by consistency checking. Nevertheless,
in the example reported in Tab. 1 the sensitivity anal-
ysis based on UB and LB case derivation can provide
useful information to quantitative estimate the impact
that uncertainty may have on aggregate indicators.
3.1 Exploring the Datasets Tree
We introduce ccheck(FSED): a function that checks
the consistency of a Finite State Event Dataset (or a
subset thereof). In case of inconsistency the func-
tion returns a pair composed by (1) the error code
(describing the error type) and (2) the index identi-
fying the minimal sequence of events being consis-
tent. The functions is implemented by making use
Model Checking, analogously to the work described
in (Mezzanzanica et al., 2011).
Now we are in state to introduce how the UB
(upper bound) and LB (lower bound) case cleansed
dataset are generated. For each sequence where an
inconsistency is detected, the event subsequent to
the detection point is labelled as Consistency Failure
Point (CFP). The CFP event is not necessarily the re-
sponsible of the consistency failure, but it is the point
where the failure emerges.
For the sake of clarity, the semantics of ccheck and
CFP are formally defined as follows.
Definition 2 (ccheck). Let S be a FSED and let
ε = e
1
, . . . , e
n
be a sequence of events according to
Definition 1, then ccheck : FSED → N × N returns
the pair < i, er > where:
1. i is the index of a minimal subsequence ε
1,i
=
e
1
, . . . , e
i
such that ε
1,i+1
is inconsistent while ∀ j :
j ≤ i ≤ n, the subsequences ε
1, j
are consistent.
2. er is zero if ε
1,n
is consistent, otherwise it is a nat-
ural number which uniquely describes the incon-
sistency error code of the sequence ε
1,i+1
.
Then, we can defineCFP
S
as the index of the event
after the shortest consistent subsequence. By abuse of
notation, we denote the index i of the pair returned as
first{ccheck(S)} whilst second{ccheck(S)} denotes
the element er. According to this notation CFP
S
=
first{ccheck(S)} + 1.
The error code previously introduced is used to
select the corrective actions to be executed. The se-
mantic of the error codes and the implementation of
corrective actions are domain dependent. Indeed, one
can insert new events, delete, or change existing ones
or a combination thereof. For each CFP several cor-
rectiveactions can be implemented to fix the inconsis-
tency, generating in this way several cleansed versions
of the original dataset. For each of them, the consis-
tency check has to be repeated again, since other CFPs
can be detected in the remainder of the sequence. The
process is executed recursively until a (most proba-
bly very large) set of completely cleansed datasets are
generated. The case that maximises (minimises) the
reference indicator is selected as the UB (LB) case,
the remaining cases are discarded. An example of this
process is showed in Fig. 2.
The tree of cleansed datasets showed in Fig. 2
can grow exponentially, thus making the problem in-
tractable. Nevertheless, several simplifications both
DATA2012-InternationalConferenceonDataTechnologiesandApplications
100

CFP
1
CFP
2
CFP
2
CFP
3
CFP
k
CFP
i
✔
CFP
j
✔
✔
✔
✔
✔ ✔
✔
LB
UB
Figure 2: Example of dataset correction tree exploration.
Leaf nodes represent a cleansed generated dataset whilst
non-leaf nodes represent datasets where CFPs still need to
be addressed.
domain independent and dependent can be used to
make the algorithm more scalable. An example is
provided in Subsec. 3.2. More precisely, a Corrective
Event for a CFP can be defined as follows.
Definition 3 (Corrective Event for a CFP). Let S
be a FSED whose content is a sequence of events
ε = e
1
, . . . , e
n
according to definition 1. Moreover,
let CFP
S
be a Consistency Failure Point for S. Then
e
j
is a corrective event for CFP
S
if the new dataset
S
′
= S ∪ {e
j
} satisfies CFP
S
′
> CFP
S
. That is ei-
ther ε
′
= e
1
, . . . , e
j
, . . . , e
i
, . . . , e
n
is consistent (i.e.,
first{ccheck(S
′
)} = n) or S
′
has aCFP
S
′
that appears
later than CFP
S
.
It is worth noting that some domains may require
to define a set of corrective events for a CFP (i.e.,
more than one event could be required to fix an in-
consistency). To this regard, the Def. 3 can be easily
adapted to deal with a set of corrective events instead
of a single one.
The process of deriving a consistent sequence of
events from an inconsistent one is largely domain
dependent. However some general practice can be
identified. Fixing an inconsistency may require to
add or delete events. Focusing on adding events to
a sequence, a trivial implementation could be to try
adding events in all the possible places and then to
check for each attempt if the resulting sequence has
been fixed, i.e. if the new sequence is consistent or a
new CFP is found after the original one (who disap-
peared). Another common techniques (which is used
when the time dimension has to be estimated for the
event to be inserted) is to try placing an event at the
beginning and at the end of a time slot (this is the ap-
proach used for estimating the cruise boat UB and LB
departure date in the example previously described).
Now it will be illustrated how the sensitivity anal-
ysis is performed and how the possible correction tree
is explored (an example of correction tree is depicted
in Figure 2), the pseudo-code of the sensitivity algo-
rithm is split in Algorithms 1 and 2 for the sake of
clarity.
Algorithm 1 focuses on a FSEDB S and, for each
inconsistent FSED S
i
, it calls Algorithm 2 to cleanse
the dataset (lines 6-8). The Algorithm 2 takes as in-
put the dataset S
i
and its CFP
S
i
. Then it generates
the possible instances S
′
i
as a result of all the possible
intervention activities. The consistency of each gen-
erated S
′
i
is checked as follows:
• S
′
i
is completely consistent (line 4). In this case it
is added to S
consistent
i
.
• S
′
i
is still inconsistent but a new emerged CFP
occurs later than the previous one. That is the
previous inconsistency has been fixed, but a new
one has emerged in the remainder of the sequence
(line 6). Then the algorithm recursively calls
SENSITIVITY on the new instance S
′
i
trying to fix
it.
• S
′
i
is still inconsistent but the correction has gener-
ated a new CFP before the previous one (i.e., the
corrective action has made the situation worse). In
this case the corrective action is discarded.
At the end of this computation, the set S
consistent
i
con-
tains all the consistent instances generated for S
i
(i.e.,
the leaf nodes of Figure 2). Then, Algorithm 2
chooses the LB (UB) cleansed version by looking for
the lower (upper) indicator value (lines 11-12).
Algorithm 1: Main algorithm.
Input: S //A FSEDB according to Def 1
ccheck //According to Def 2
ind //An indicator satisfying Property 1
1: for all S
i
∈ S do
2: lower
S
i
←
/
0; //global lower value for S
i
3: upper
S
i
←
/
0; //global upper value for S
i
4: S
consistent
i
←
/
0; //global set of consist. S
i
5: CFP
S
i
← first{ccheck(S
i
)} + 1;
6: if (CFP
S
i
≤ n) //S
i
is not consistent then
7: if (do not use the simplification of Sec. 3.2) then
8: SENSITIVITY(S
i
,CFP
S
i
);
9: else
10: SENSSIMPLIFIED(S
i
,CFP
S
i
,LB case);
11: SENSSIMPLIFIED(S
i
,CFP
S
i
,UB case);
3.2 An Algorithm Simplification
A simplified version of the previously mentioned al-
gorithm can be used if two conditions are met on both
indicator and correction activities: 1) the sequence be-
ing evaluated can be partitioned into non-overlapping
subsequences which fully cover the original sequence
(e.g., like the subsequences ε
1
, ε
2
, . . . in Fig. 3); 2)
the computation of the indicator being evaluated can
DataQualitySensitivityAnalysisonAggregateIndicators
101

Algorithm 2: Sensitivity.
Input: S
i
, CFP
S
i
1: for all a
i
corrective action for S
i
do
2: S
′
i
← apply(a
i
, S
i
);
3: CFP
S
′
i
← first{ccheck(S
′
i
)} + 1;
4: if (CFP
S
′
i
= n+ 1) then
5: S
consistent
i
← S
consistent
i
∪ S
′
i
;
6: else if (CFP
S
′
i
> CFP
S
i
) then
7: SENSITIVITY(S
′
i
,CFP
S
′
i
);
8: else
9: //Discard the corrective action
10: for all S
′
i
∈ S
consistent
i
do
11: lower
S
i
← eval lower ind(S
′
i
, ind);
12: upper
S
i
← eval upper ind(S
′
i
, ind);
be parallelised over the subsequences identified in the
previous step. The latter is feasible when 2a) the in-
dicator is an additive function with respect to the sub-
sequences; and 2b) the corrections carried out within
a subsequence do not affect the corrections executed
on the other subsequences.
If all the two conditions hold then the inconsis-
tency fixing and the indicator computation tasks can
be independently executed within the boundaries of
each identified subsequence, thus greatly reducing the
computational effort. The condition 2a holds under
the hypothesis showed below:
Algorithm 3: SensSimplified.
Input: S
i
, CFP
S
i
, modality
1: S
LB
i
←
/
0; //the S
i
instance minimising ind.
2: S
UB
i
←
/
0; //the S
i
instance maximising ind.
3: for all a
i
corrective action for S
′
i
do
4: S
′
i
← apply(a
i
, S
i
);
5: CFP
S
′
i
← first{ccheck(S
′
i
)} + 1;
6: if (CFP
S
′
i
= n+ 1∨CFP
S
′
i
> CFP
S
i
) then
7: if S
′
i
minimises the indicator then
8: S
LB
i
← S
′
i
;
9: lower
S
i
← eval lower ind(S
′
i
, ind);
10: else if S
′
i
maximises the indicator then
11: S
UB
i
← S
′
i
;
12: upper
S
i
← eval upper ind(S
′
i
, ind);
13: else
14: //Discard the corrective action
15: if (modality = LB case ∧ S
LB
i
6=
/
0) then
16: CFP
S
LB
i
← first{ccheck(S
LB
i
)} + 1;
17: SENSSIMPLIFIED(S
LB
i
,CFP
S
LB
i
, modality);
18: else if (modality = UB case ∧ S
UB
i
6=
/
0) then
19: CFP
S
UB
i
← first{ccheck(S
UB
i
)} + 1;
20: SENSSIMPLIFIED(S
UB
i
,CFP
S
UB
i
, modality);
Property 1 (Additive Function). Let ε = e
1
, . . . , e
n
be a FSED (according to Def. 1) which can be par-
titioned into event subsequences such that ∪
m
i=1
ε
i
= ε,
and ∀i, j with i 6= j, ε
i
∩ ε
j
=
/
0, then a function
F : FSED → Z
+
is additive if F(ε) =
∑
m
i=1
F(ε
i
) with
m < n.
In order to define the next properties, we introduce
a relation between subsequences ε
1
, ε
2
such that ε
1
<
ε
2
iff ∀e
i
∈ ε
1
, e
j
∈ ε
2
, e
i
< e
j
.
Then condition 2b can be rephrased as follows:
cleansing a subsequence ε
i
has either no impact both
on the previous (i.e. the antecedents) and on the fol-
lowing (i.e. the subsequent) subsequences, or ev-
ery possible corrections inside a subsequence has the
same impact on the remaining future subsequences.
These can be summarised by saying that a cleansing
intervention should satisfy the properties “Preserving
a common future” and “not altering the past” more
formally defined below.
Property 2 (Preserving a Common Future). Every
correction of a CFP found inside a subsequence ε
i
must share a common future in all the subsequences
ε
k
where ε
k
> ε
i
. Note that this condition can be
easily satisfied if the FSS modelling the FSED is a
memoryless systems (Csiszar and K
¨
orner, 1981) e.g.,
a Markov process (Iosifescu, 1980). Under this hy-
pothesis, all the corrections done on a subsequence
will have a common future, if all of them will lead to
the same final state at the end of the sequence.
Property 3 (Not Altering the Past). Every correction
of Consistency Failure Points (in ε
i
) will not modify
prior subsequences ε
p
where ε
p
< ε
i
.
Claim 1 (Pruning Conditions). If Properties 1,2 and
3 hold for an indicator to be evaluated on a FSE
Dataset, then the UB / LB case search can exploit a
“divide et impera” paradigm (i.e. it can be computed
independently on each ε
i
).
Proof. Let ε
0
being a subsequence of S from the
beginning to the first CFP met. Only the cleansed
dataset of ε
0
that minimises the indicator (computed
on ε
0
) need to be expanded. Indeed Properties 2 and
3 ensure that not overlapping subsequences can be
cleansed independently, therefore the cleansed solu-
tion that minimises the global indicator must contain
the cleansed version of ε
0
that minimises the indicator
locally. To this regard, suppose, without loss of gen-
erality, that the cleansed dataset that minimises the
indicator computed for ε
0
is the leftmost child of the
top node in Fig. 2. All its siblings (successors of the
top node) and their related subtrees can therefore be
pruned.
Going further, let us suppose that a second CFP is
found. Let ε
1
be the sequence of events between the
first and the second CFP. Suppose, that the cleansed
version of ε
1
that minimises the indicator computed
DATA2012-InternationalConferenceonDataTechnologiesandApplications
102

locally is the leftmost successor node. This is the only
node that needs to be expanded, all its siblings can be
pruned. Without loss of generality, we can identify
the cleansed version of S
i
that minimises the indicator
as being always the leftmost node. Hence, the com-
pletely cleansed dataset that minimises the indicator is
the leftmost leaf, and the path to reach it goes through
all the leftmost nodes of the tree. Therefore, the path
to the cleansed dataset that minimises the indicator is
the path where each indicator computed locally on ε
i
is minimised. Note that the cleansed version of S
i
that
maximises the indicator can be obtained in a spec-
ular way. More generally, every node of the leftmost
(rightmost) path is the cleansed version of S
i
that min-
imises (maximises) the indicator. If the CFPs location
would be known a priory, the cleansed version of ev-
ery S
i
could be computed in parallel.
3.2.1 The Indicator Estimation
The simplified algorithm can be applied only to the
datasets where the corrections don’t violate proper-
ties 2 and 3. Conversely, a dataset violating proper-
ties 2 and 3 requires to explore all the feasible cor-
rected instances in search of the UB and LB values.
Unfortunately, this can lead to computational prob-
lems. To avoid this, a coarse-grained estimation of the
indicator can be executed, namely the estimation ap-
proach. The estimation approach does not try to make
the sequences consistent but estimates the UB and LB
values with a trivial method (domain dependent) re-
quiring a reasonable effort but at the price of provid-
ing a less precise estimation (i.e., enlarging the value
bounds). For the sake of clarity the two approaches
will be called respectively computation approach and
estimation approach.
e
0
CFP
1
CFP
2
CFP
3
CFP
4
CFP
5
a
1
a
2
a
3
PoR
unsafe unsafe unsafe safesafe
e
2
e
1
...
ε
1
ε
2
ε
3
ε
4
ε
5
a
5
Figure 3: An example of correction violating the property
“not altering the past”.
Consider the sequence of events reported in Fig. 3
which can be split into subsequences bounded by
CFPs (e.g., ε
1
, ε
2
, . .., ε
5
). The computation and
the estimation approaches can be jointly used, as de-
scribed in what follows (the analysis focuses on com-
puting the LB indicator value, the UB value can be
obtained specularly).
1) The computation approach is executed on the sub-
sequences and the results are investigated. The subse-
quences where the computation approach can be ap-
plied are marked as safe whilst the others are marked
as unsafe.
2) In subsequence ε
1
action a
1
is the correction (out
of several others) that minimises the indicator value
in the subsequence ε
1
. All the corrections of CFP
1
do
not violate neither the property 2 nor the property 3,
therefore this subsequence is marked as safe.
3) Focusing on ε
3
(the over next subsequence) the
correction of CFP
3
using action a
3
violates the prop-
erty 3 (not altering the past). Consequently the sce-
nario where the correction a
2
had been previously se-
lected and executed in ε
2
has changed and action a
2
might be no more the optimal choice for the CFP
2
.
The subsequence ε
2
is marked as unsafe and is no
more investigated, i.e. no effort is spent for finding a
corrective action that might fix ε
2
and CFP
2
. The un-
certainty that CFP
3
creates in its past can make very
difficult identifying the correction that minimises the
indicator value in ε
3
(a
3
may result not being anymore
the best choice), therefore ε
3
is no more investigated
and it is marked as unsafe too.
4) The uncertainty originated by ε
3
will propagate
in the remainder sequences until a point-of-reset is
found, i.e. an event from which the simplifying con-
ditions are satisfied again (properties 2 and 3) and
ends the uncertainty created by unsafe subsequences.
Looking at Fig. 2 this will happen when all the nodes
of a sub-tree (that can’t be pruned) will share a com-
mon future from the point-of-reset onward, therefore
it is enough to evaluate only one sub-subtree since all
the other siblings are similar. The criteria for identify-
ing points-of-reset are domain dependent, however as
a general rule, good candidates are points for which a
common future holds for every possible prior correc-
tion.
5) Subsequence ε
4
is marked as unsafe because the
events before the point-of-reset are affected by un-
certainty too, whilst ε
5
is marked as safe since it
doesn’t violate neither the property 2 nor the prop-
erty 3 and no uncertainty propagates from previous
subsequences.
6) Subsequences violating the property 2 can be man-
aged similarly: the subsequences will be marked as
unsafe until a point-of-reset is found. An example of
such error is showed in Fig. 5.
7) The indicator LB value is computed according to
the computation approach for the safe subsequences,
whilst the estimation approach is used for unsafe
ones. We recall that the indicator value can be com-
DataQualitySensitivityAnalysisonAggregateIndicators
103

puted for the whole sequence by summing the values
computed in each subsequence (i.e. the indicator is
addictive).
In a similar way The UB and LB values are com-
puted for each FSED composing the FSEDB. Then,
the average values of all the FSED UB and LB values
are computed and the gap is analyzed as described in
the example of Sec. 4.
The methodology introduced in this paper can be
used for estimating an indicator possible value ranges
on an inconsistent dataset. It is worth noting that
the term indicator refers to a general and domain-
dependent concept (e.g., they are widely used in many
fields as statistics, economics and business intelli-
gence). To give an example, in the context of data
quality an indicator can be used to measure and im-
prove the quality of the data (Wang et al., 1993) as
well as to assess the reliability of the results aris-
ing from the data uncertainty (Weidema and Wesns,
1996). Roughly speaking, an indicator is a function
able to represent or manipulate data so that operators
can assess and gain confidence with data (Weidema
and Wesns, 1996). As a consequence, an indicator
should have the same characteristics of a function,
e.g. being meaningful for the domain, having a rea-
sonable computation complexity, etc.
every possible inconsistency there is a finite set
of possible corrections). Moreover, if the indicator
satisfies the properties 1, 2, and 3 then the simplified
algorithm described in this subsection can be applied.
4 THE CASE OF “THE
WORKERS CAREER
ADMINISTRATIVE ARCHIVE”
The Italian labour law states that every time an em-
ployer hires or dismisses an employee, or a contract of
employment is modified (e.g. from part-time to full-
time, or from fixed-term to unlimited-term) a commu-
nication (Mandatory Communication) has to be sent
to a job registry. The registry is managed at provin-
cial level for several administrative tasks, every Ital-
ian province has its own job registry recording the
working history of its inhabitants (as a side effect).
In this scenario, the job registry data is analysed to
provide information to civil servants and policy mak-
ers. See (Martini and Mezzanzanica, 2009) for further
details.
For each worker, a mandatory notification (repre-
senting an event in our context) contains several data:
w id: it represents an id identifying the person in-
volved in the event;
e id: it represents an id identifying the communica-
tion;
e date: it is the event date;
e type: it describes the event type occurring to the
worker career. The event types are: the start or
the cessation of a working contract, the extension
of a fixed-term contract or the conversion from a
contract type to a different one;
c flag: it states whether the event is related to a full-
time (FT) or a part-time contract (PT);
empr id: it is used to uniquely identify the employer
involved in the event.
The evolution of a consistent worker’s career
along the time is described by a sequence of events
ordered with respect to e date. More precisely, in this
settings the FSED is the ordered set of events for a
given w id, whose union composes the FSEDB. Then,
consistency is related to the “correct” evolution of a
worker career, which can be inferred by the Italian
Labour Law and common practice. To this regard,
an employee can have only one full-time contract ac-
tive at a the same time; or an employee can not have
more than two part-time contracts (signed with differ-
ent companies).
For the sake of simplicity, we omit to describe
some trivial constraints which can be derived from the
ones above (e.g., a employee cannot have a cessation
event for a company for which he does not work, an
event can not be recorded twice, etc).
4.1 The Formal Model
The first step when dealing with FSS is the definition
of the system state, which in our settings represents
the worker career at a given time point.
It is composed by two elements: the list of compa-
nies for which the worker has an active contract (C[])
and the list of modalities for each contract (M[]). To
give an example, C[0] = 12, M[0] = PT models that
the worker has an active part-time contract with com-
pany 12.
The FSS describing a consistent career evolution
is showed in Figure 4. Note that, for the sake of clar-
ity, we omit to represent conversion events as well as
inconsistent states/transitions (e.g., the worker acti-
vating two full-time contracts), which are considered
in the consistency verification.
To give an example, a consistent career can evolve
signing a part-time contract with company i, then ac-
tivating a second part-time contract with company j,
continuing by closing the second part-time and then
DATA2012-InternationalConferenceonDataTechnologiesandApplications
104

unemp
C[] =
/
0
M[] =
/
0
start
emp
i
C[0] = empr id
e
i
M[0] = c
flag
e
i
emp
j
C[0] = empr id
e
i
M[0] = c
flag
e
j
emp
i, j
C[0] = empr id
e
i
M[0] = c
flag
e
i
C[1] = empr
id
e
i
M[1] = c
flag
e
j
emp
k
C[0] = empr id
e
k
M[0] = c
flag
e
k
e type
e
i
= st ∧ c
flag
e
i
= PT
e type
e
i
= cs∧ c
flag
e
i
= PT
e type
e
j
= st ∧ c
flag
e
j
= PT
e type
e
j
= cs∧ c
flag
e
j
= PT
e
type
e
i
= st ∧ c
flag
e
i
= PT
e
type
e
i
= cs∧ c
flag
e
i
= PT
e
type
e
j
= cs∧ c
flag
e
j
= PT
e
type
e
k
= st ∧ c
flag
e
k
= FT
e
type
e
k
= cs∧ c
flag
e
k
= FT
e type
e
i
= ex∧ c
flag
e
i
= PT
e type
e
k
= ex∧ c
flag
e
k
= FT
e type
e
j
= ex∧ c
flag
e
j
= PT
∨
e
type
e
i
= ex∧ c
flag
e
i
= PT
e type
e
j
= ex∧ c
flag
e
j
= PT
Figure 4: The FSS of a valid worker’s career where st = start, cs = cessation, cn = conversion and ex = extension.
reactivating the latter again (i.e., unemp, emp
i
, emp
i, j
,
emp
i
, emp
i, j
).
4.2 The Sensitivity Analysis
In this section we describe how the Algorithm pre-
sented in Sec. 3 is applied to the domain just intro-
duced. For the sake of clarity, we map the domain
topics on the concepts introduced in Sec. 3.
• An FSE Dataset is a sequence of Mandatory Com-
munications representing a worker career. Hence
the FSE Database is a collection of careers. We
refer to a worker career as S
i
.
• ccheck(S
i
) is a function that implements the FSS
depicted in Fig. 4 according to Def. 2. The func-
tion checks for career consistency and returns
both (1) the CFP and (2) the error code if an in-
consistency is found.
• ind(S
i
) is an indicator function which returns the
number of worked days for the career S
i
.
The consistency check showed that several errors
affect the career’s data (as illustrated in Sec. 4.3). We
identified a set of error types, and for each of them we
have implemented the respective corrective actions.
Recall that each inconsistency is an inadmissible tran-
sition in the automaton of Fig. 4. In order to clarify
the matter, we provide some examples of corrective
actions.
Er1: Two different full-time-job-start events are found
with no cessation in between. The corrective ac-
tion is to put a cessation event (for the first job) in
between.
Er2: A part-time-job-cessation event is found, but the
corresponding job-start event is missing. The cor-
rective action is to place a corresponding job-start
event somewhere before the cessation event.
Er3: A part-time-job-start (PT3) is found but two dif-
ferent part time jobs are ongoing (PT1 and PT2).
Two corrections are available: either to close PT1
or to close PT2 in both cases before the start of
PT3. These corrective actions are deeply ana-
lyzed in Fig. 5.
The sensitivity analysis is executed according to
the simplified algorithm described in Algorithm 3
which is more scalable with respect to the one de-
scribed in Sec. 3.1. Roughly speaking, for each career
S
i
the Algorithm MAIN executes twice SENSSIMPLI-
FIED to obtain the S
i
UB and LB indicator values (up-
per and lower bound respectively). More precisely:
1. ccheck(S
i
) is evaluated on the career S
i
; if an in-
consistency is found then the SENSSIMPLIFIED
on S
i
and the respective CFP
S
i
is called (for both
S
i
LB and UB cases). Algorithm 1 lines 10-11.
2. Looking at SENSSIMPLIFIED, all the feasible cor-
rective actions (suitable to fix the inconsistency)
DataQualitySensitivityAnalysisonAggregateIndicators
105
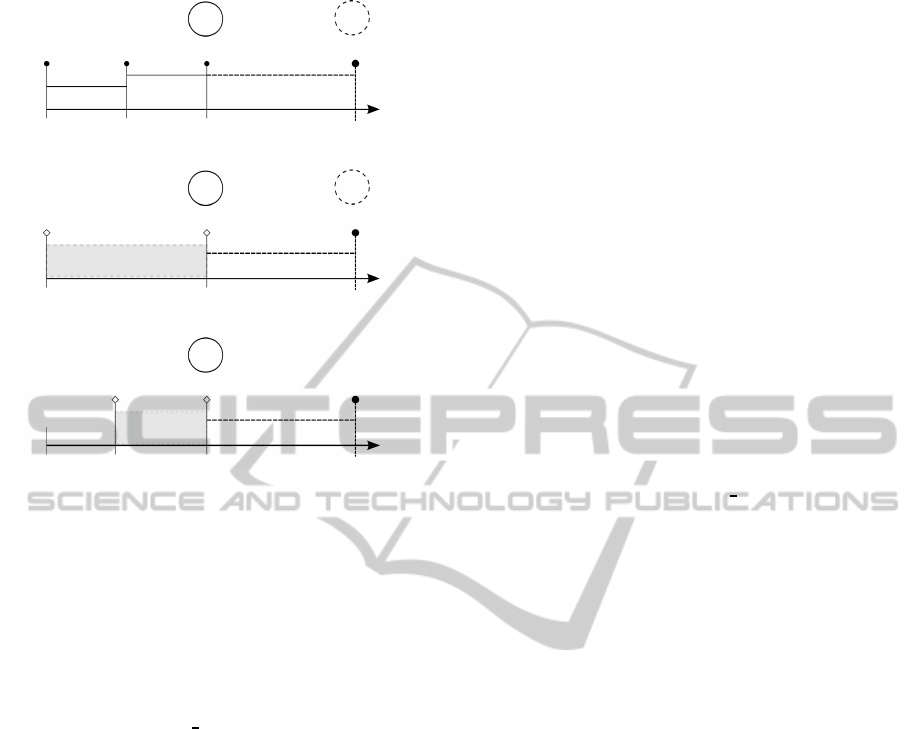
st
PT1
st
PT2
st
PT3
cs
PT1
emp
i
emp
i, j
emp
i, j
0
50 100 200
CFP
CFP
(a)
cs
PT1
cs
PT1
cs
PT1
emp
i, j
0
100 200
CFP
CFP
(b)
100 days
cs
PT2
cs
PT2
cs
PT1
emp
i, j
0
50 100 200
CFP
(c)
50 days
Figure 5: (a) A career affected by Er3, (b) Possible insertion
place of event closing first part time (PT
1
), (c) Possible in-
sertion place of event closing second part time (PT
2
). Note
that closing PT
2
will create no problem in the future while
closing PT
1
will originate an inconsistency when the real
PT
1
cessation will be met.
are applied, generating either a cleansed S
′
i
(if any)
or obtaining a new CFP for S
′
i
(lines 3-6).
3. The corrected instance that minimises (max-
imises) the working days indicator computed on
the sub-sequence before the CFP
S
i
is selected
(lines 7-12).
4. If we are looking for the LB (UB) case of S
i
then the new S
LB
i
(S
UB
i
) case will be expanded,
i.e. ccheck on S
LB
i
(S
UB
i
) will be executed looking
for further inconsistencies. This operation corre-
sponds to expanding the leftmost (rightmost) sub-
tree of Figure 2 (lines 15-20).
The hypothesis listed in Sec. 3.2 should be veri-
fied in order to guarantee that the simplified algorithm
produces the correct result. The career working days
indicator is an additive function (the demonstration is
trivial and therefore is omitted).
Given an error, every corrective action tries to
make the career subsequence before the CFP consis-
tent and leading to the same state, the automaton de-
scribing the sequence (Fig. 4) is memoryless (if we
don’t consider the state variables c[] and m[]). There-
fore all the corrections will have the same future, ex-
cluding one correction type that will be deeply de-
scribed later (it is the “Er3” and in this case the vari-
ables c[] and m[] are the responsible of violating the
property 2). Sequences affected by the latter correc-
tions are marked as unsafe. The “not altering the
past” property violation has been detected as follow.
Every time a correction has to be made to previous
sequences containing (fixed) CFPs, the subsequences
affected are marked as unsafe.
Subsequences following unsafe ones are checked
to verify if they have still to be considered unsafe.
The presence of Full Time contract start or cessation
events act as point-of-reset and they can be used to
bound the extent of unsafe sub-sequences. The ra-
tionale is that a full time contract prevents the con-
textual presence of other full time or part time con-
tracts, therefore 1) it ends the uncertainty caused by
previous errors and 2) forces all possible prior cor-
rections to share the same future. After all career
subsequences have been corrected and marked either
as safe or as unsafe, the indicator Upper and Lower
bounds are computed using the computation or the es-
timation approach respectively. Given a sub-sequence
covering (for example) 100 days, the estimation ap-
proach will estimate the working days as follows: 0 is
assumed as lower bound and 100 is assumed as upper
bound. The approach is very coarse grained but it is
also very fast. Hopefully the unsafe subsequences are
few with respect to the safe ones. The indicator value
for safe subsequences is computed by counting the
actual worked days. The UB and LB values are gen-
erated in this way. The whole career upper and lower
bound indicator values can be computed by summing
the subsequences corresponding values; then, the av-
erage value of all the careers UB (LB) cases is com-
puted. The more are the inconsistencies found in the
database and the larger will be the gap between the
UB and the LB average values. This gap can be inter-
preted as a measure of the uncertainty related to the
database inconsistency.
Now let’s consider the previously introduced Er3
error. As showed in Fig. 5, choosing to create the
cessation event either of Part Time 1 (Fig. 5(b)) or of
Part Time 2 (Fig. 5(c)) will create different versions
of the future. Indeed related corrective actions violate
the condition “preserving a common future”.
We will call unsafe careers hereafter to refer to all
the careers having at least one unsafe subsequence.
The unsafe careers are not negligible (in our case are
about 10% of the total), and then it is important to
evaluate the impact they can have on the indicator.
Next section will illustrate some resuls.
4.3 Experimental Results
We tested the Data Quality Sensitivity Analysis on
an Italian Province Administrative Database having
DATA2012-InternationalConferenceonDataTechnologiesandApplications
106

Table 2: Data quality sensitivity analysis experimental re-
sults considering (A) all careers i.e. using both the compu-
tation and the estimation approaches and (B) safe only ca-
reers using only the computation approach. Note that 4017
are the days between the 1
st
January 2000 and the 31
st
De-
cember 2010.
Average Working Days Results
Layer LB UB Modified Consistent Num
(a) 1,377 1,979 YES YES 82,989
(b) 1,383 1,383 NO YES 130,500
A (c) 0 4,017 NO NO 56
(d) 0 4,017 YES NO 887
(a) 1,633 1,942 YES YES 61,301
(b) 1,383 1,383 NO YES 130,500
B (c) 0 4,017 NO NO 56
(d) 0 4,017 YES NO 384
214, 432 careers (composed by 1, 248, 751 Mandatory
Notifications) observed between the 1
st
January 2000
and the 31
st
December 2010.
Tab. 2 summarises the sensitivity analysis statis-
tics. The part A considers all the careers (both safe
and unsafe) and the results are computed applying
both the computation and the estimation approach.
Part B of Tab. 2 excludes from the sensitivity anal-
ysis all the unsafe careers (i.e. careers having at least
one unsafe sub-sequence).
Tables 2 report the average value of the working
days variable for the best and worst cases layered by
the Consistent and Modified flags. The former means
that a career is consistent at the end of the correc-
tion process cause it was either initially consistent or
a consistent version has been generated. The Modified
flag states that at least one corrective action has been
applied on the career. Hence, looking at Table 2 row
(a) represents careers made consistent while (b) are
careers already consistent. Row (c) represents careers
for which no corrective action has been found whilst
the corrective actions were ineffective for careers in
row (d). It is worth to note that (b) refers to consistent
careers which don’t need to be fixed, consequently
there is no source of uncertainty and for this reason
Upper and Lower bound are equals. We computed a
sensitivity index SI of the working days variable as
SI =
∑
((UB−LB)·Num)
∑
(LB·Num)
. For the dataset which includes
unsafe careers we obtained a SI = 18.2%. Differently,
the SI for the dataset which excludes unsafe careers
is SI = 7.3%. The SI value could have been narrowed
by exploiting a more fine grained approach for esti-
mating the unsafe subsequences, but we won’t deeper
this topic. These results show that:
• The SI excluding unsafe careers is less than the
one which considers unsafe careers. This is
an expected result since the estimation approach
greatly contribute to enlarge the working days in-
dicator upper and lower bound distance.
• The impact of unsafe careers on the indicator
working days cannot be neglected. Furthermore,
if we apply the estimation approach without con-
sidering the point-of-resets, the SI grows up to
26%.
• Due to the inconsistency of the careers, data in-
dicators computed on the cleansed dataset are af-
fected by uncertainty. Nevertheless the sensitivity
analysis can be helpful to bound this uncertainty.
In our case, regardless the value of the SI, which
could be acceptable or not (according to the do-
main requirements), the SI represents a useful in-
formation for labour market analysts about the re-
liability of the working days indicator.
We implemented the Algorithms 1,2 and 3 in C++, us-
ing the BOOST library to interact with the DBMS. All
the experiments were performed on a 32 bits 2.2Ghz
CPU in about 1 hour using 200 MB of RAM.
5 CONCLUSIONS AND FUTURE
WORK
We have described how to perform the “Data Qual-
ity Sensitivity Analysis” to assess how uncertainty
(due to not deterministic corrections of inconsistent
data) can affect indicators computed on cleansed data.
This methodology has been implemented to quantita-
tively estimate how the inconsistencies present in a
real database can affect an aggregate indicator (i.e.
working days on a observed time slot) that is rele-
vant for statistics on the labour market place, since
several indicators are based on it. Although in our
work we have focused only on a specific indicator,
our approach can be easily extended to several ones
(compliant with the requirements showed in the pa-
per). The possibility to estimate how data cleansing
can affect indicators used for decision making is ex-
tremely valuable for decision makers. Our methodol-
ogy exploits the Finite State Systems and they proved
to be useful for modelling the domain rules and to au-
tomatically check data consistency. Furthermore the
approach presented in this paper can avoid the com-
putational issues affecting works dealing with indi-
cators computed upon inconsistent data (at the price
of more coarse grained evaluation). Currently the
ongoing research goes into the direction of exploit-
ing model checking to automatically identify possible
corrective actions starting from a Finite State System
that models a domain. As a future work we are going
DataQualitySensitivityAnalysisonAggregateIndicators
107

to investigate the issues arising when the methodol-
ogy proposed in this paper have to deal with indica-
tors and scenarios requiring an estimation of several
indicators to address inconsistencies (including possi-
ble complexity issues). We are also considering how
to exploit statistical information about the consistent
part of a dataset to narrow the bounds of the estimated
indicator. The dataset that has been described in this
paper cannot be shared due to privacy related issues.
We are working on building a fictitious dataset that
can be used as a testbed for comparing formal meth-
ods with other approaches (e.g. learning based meth-
ods) in the context of inconsistency detection and res-
olution.
ACKNOWLEDGEMENTS
The authors would like to thank the anonymous re-
viewers for their valuable comments and suggestions.
REFERENCES
Arasu, A. and Kaushik, R. (2009). A grammar-based en-
tity representation framework for data cleaning. In
Proceedings of the 35th SIGMOD international con-
ference on Management of data, pages 233–244.
Arenas, M., Bertossi, L., Chomicki, J., He, X., Raghavan,
V., and Spinrad, J. (2003). Scalar aggregation in in-
consistent databases. Theoretical Computer Science,
296(3):405–434.
Arenas, M., Bertossi, L. E., and Chomicki, J. (1999). Con-
sistent query answers in inconsistent databases. In
ACM Symp. on Principles of Database Systems, pages
68–79. ACM Press.
Batini, C., Cappiello, C., Francalanci, C., and Maurino, A.
(2009). Methodologies for Data Quality Assessment
and Improvement. ACM Comput. Surv., 41:16:1–
16:52.
Batini, C. and Scannapieco, M. (2006). Data Quality: Con-
cepts, Methodologies and Techniques. Data-Centric
Systems and Applications. Springer.
Chomicki, J. and Marcinkowski, J. (2005). Minimal-change
integrity maintenance using tuple deletions. Informa-
tion and Computation, 197(1-2):90–121.
Csiszar, I. and K¨orner, J. (1981). Information theory: cod-
ing theorems for discrete memoryless systems, volume
244. Academic press.
Embury, S., Brandt, S., Robinson, J., Sutherland, I., Bisby,
F., Gray, W., Jones, A., and White, R. (2001). Adapt-
ing integrity enforcement techniques for data recon-
ciliation. Information Systems, 26(8):657–689.
Fan, W., Geerts, F., and Jia, X. (2008). A Revival of In-
tegrity Constraints for Data Cleaning. Proc. VLDB
Endow., 1:1522–1523.
Fellegi, I. and Holt, D. (1976). A systematic approach to au-
tomatic edit and inputation. Journal of the American
Statistical association, 71(353):17–35.
Galhardas, H., Florescuand, D., Simon, E., and Shasha, D.
(2000). An extensible framework for data cleaning.
In Proceedings of ICDE ’00, pages 312–. IEEE Com-
puter Society.
Iosifescu, M. (1980). Finite Markov processes and their
applications. Wiley.
Maletic, J. and Marcus, A. (2000). Data cleansing: beyond
Integrity Analysis. In Proceedings of the Conference
on Information Quality, pages 200–209.
Martini, M. and Mezzanzanica, M. (2009). The Federal Ob-
servatory of the Labour Market in Lombardy: Models
and Methods for the Costruction of a Statistical In-
formation System for Data Analysis. In Larsen, C.,
Mevius, M., Kipper, J., and Schmid, A., editors, Infor-
mation Systems for Regional Labour Market Monitor-
ing - State of the Art and Prospectives. Rainer Hampp
Verlag.
Mayfield, C., Neville, J., and Prabhakar, S. (2009). A Sta-
tistical Method for Integrated Data Cleaning and Im-
putation. Technical Report CSD TR-09-008, Purdue
University.
Mezzanzanica, M., Boselli, R., Cesarini, M., and Merco-
rio, F. (2011). Data quality through model checking
techniques. In Gama, J., Bradley, E., and Hollm´en, J.,
editors, IDA, volume 7014 of Lecture Notes in Com-
puter Science, pages 270–281. Springer.
M¨uller, H. and Freytag, J.-C. (2003). Problems, Meth-
ods and Challenges in Comprehensive Data Cleans-
ing. Technical Report HUB-IB-164, Humboldt-
Universit¨at zu Berlin, Institut f¨ur Informatik.
Rahm, E. and Do, H. (2000). Data cleaning: Problems and
current approaches. IEEE Data Engineering Bulletin,
23(4):3–13.
Redman, T. C. (1998). The impact of poor data quality on
the typical enterprise. Commun. ACM, 41:79–82.
Sang Hyun, P., Wesley, W., et al. (2001). Discovering and
matching elastic rules from sequence databases. Fun-
damenta Informaticae, 47(1-2):75–90.
Strong, D. M., Lee, Y. W., and Wang, R. Y. (1997). Data
quality in context. Commun. ACM, 40(5):103–110.
Wang, R., Kon, H., and Madnick, S. (1993). Data quality
requirements analysis and modeling. In Data Engi-
neering, 1993. Proceedings. Ninth International Con-
ference on, pages 670–677.
Weidema, B. P. and Wesns, M. S. (1996). Data quality man-
agement for life cycle inventoriesan example of using
data quality indicators. Journal of Cleaner Produc-
tion, 4(34):167 – 174.
DATA2012-InternationalConferenceonDataTechnologiesandApplications
108
