
EFFICIENT LITERATURE RESEARCH
BASED ON SEMANTIC TAGNETS
Implemented and Evaluated for a German Text-corpus
Uta Christoph, Daniel G
¨
otten and Karl-Heinz Krempels
Informatik 4, Intelligent Distributed Systems Group, RWTH Aachen University, Aachen, Germany
Keywords:
Semantic networks, Literature research, Text corpus, Text analysis.
Abstract:
In this paper we present an approach that is capable to automatically generate semantic tagnets for given
sets of german tags (keywords) and an arbitrary text corpus using three different analysis methods. The
resulting tagnets are used to estimate similarities between texts that are manually tagged with the keywords
from the given tagset. Basically, this approach can be used in digital libraries to provide an efficient and
intuitive interface for literature research. Although it is mainly optimized for the german language the proposed
methods can easily be enhanced to generate tagnets for a given set of english keywords.
1 INTRODUCTION
Due to the large amount of data available in the world
wide web data structuring is an important topic to-
day. One famous approach is the semantic web as pro-
posed by Tim Berners-Lee (Berners-Lee et al., 2001).
The idea is to structure the available data by its se-
mantic meaning to provide much better access meth-
ods and possibilities for automatic analysis. Since no
suitable semantic wordnets are available for the ger-
man language the idea is to build a system that allows
to estimate semantic relations for a given set of ger-
man words. In the following an approach will be pre-
sented that structures keywords (tags) and documents
by their semantic information and similarities.
Normally, no semantic information is available for
information stored in digital libraries and solely sim-
ple search interfaces are provided that allow to search
for documents by its title or author names. Appar-
ently, research of similar documents is hard and time-
consuming in such cases. One approach to solve this
problem is to avail ss that are used to describe the
content of single documents and enable the search for
documents by their tags.
Although tags allow to categorize documents they
do not completely solve the problem described above
as illustrated by the following example. Given two
similar documents d
1
and d
2
annotated by tags from
two disjunct sets S
1
and S
2
. It might not be possi-
ble to recognize the similarities between d
1
and d
2
, if
no information about semantic relations between the
tags of both sets is given. Especially for a large set of
available similar tags to describe each document this
problem may occur quite frequently.
The presented approach is based on similarity
analysis of documents annotated manually with tags.
These document similarities are estimated by auto-
matically extracting semantic relations between the
tags of the given set. Both the given tags and the ex-
tracted relations form a network called tagnet. The
derived network of documents is called similarity net.
Apparently, both networks can be used to make liter-
ature research more efficient, by visualizing them in
a suitable way. The resulting system provides a quite
intuitive interface that enables non-technical users to
research literature by surfing through the similarity
net.
At first we discuss in Section 2 relevant problems
that may occur during automatic text analysis. We
show that these problems mainly result from morpho-
logical special cases of the german language. As pos-
sible solutions the approaches of lemmatization and
stemming will be discussed. Afterwards, the idea
of the implemented system (the tagnet builder) that
builds the described networks is introduced in Sec-
tion 3. Finally, the results are evaluated in Section 4.
48
Christoph U., GÃ˝utten D. and Krempels K.
EFFICIENT LITERATURE RESEARCH BASED ON SEMANTIC TAGNETS - Implemented and Evaluated for a German Text-corpus.
DOI: 10.5220/0002805400480054
In Proceedings of the 6th International Conference on Web Information Systems and Technology (WEBIST 2010), page
ISBN: 978-989-674-025-2
Copyright
c
2010 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2 PROBLEMS
Automatic approaches of text analysis are quite error-
prone without adaptation to a given scenario. Espe-
cially in the case of automatic text analysis of ger-
man
1
texts problems occur due to the morphological
special cases in the german language. Concerning
statistical approaches in text analysis three problems
have to be taken into account:
1. multilingualism
2. morphologicial special cases
3. understanding of texts
Since the considered corpus solely consists of german
texts we do not consider multilingualism for the mo-
ment. For this reason only the problems (2) and (3)
have to be discussed.
2.1 Morphological Special Cases
The main objective of the tagnet builder is the extrac-
tion of semantic information from keywords based on
statistical frequency analysis on the considered text
corpus. These frequencies have to be as accurate as
possible, so a reliable mapping of all given keywords
to unique stems is required. Furthermore, numbers
and stop words can be deleted, since they are not rel-
evant for the analysis.
2.1.1 Stemming
Stemming is an algorithmical approach for the esti-
mation of unambiguous stems for words of a given
language. A famous approach is the porter stem-
mer (Porter, 1980). An implementation for german
words based on this approach is available in terms of
Snowball
2
.
Unfortunately, stemming algorithms do not gen-
erate real stems, but unique pseudo stems by suffix
stripping based on predefined rules without consider-
ation of grammatical characteristics. Especially for
the case of german words two different words might
be mapped to one stem although there exists no se-
mantic similarity. Thus, this simple stemming ap-
proach may deteriorate the quality of the semantic
tagnet generated by the tagnet builder.
2.1.2 Lemmatization
To provide mappings to real stems lemmatization has
to be used. This lemmatization is often based on full-
form lexicons that have to be defined in prior. Un-
1
Or other inflectional complex languages.
2
http://snowball.tartarus.org
fortunately, no complete fullform lexicons are avail-
able for the german language due to the possibility of
compound words. This problem can be solved with
the help of a learning lemmatizer as it has been pro-
posed by P. Perera and R. Witt
´
e (Perera and Witte,
2005). Basically, this lemmatizer processes words in
three phases.
At first it checks if the current word already is part
of the existing fullform lexicon to lemmatize it imme-
diately by its corresponding stem. If the current word
is not part of the existing lexicon, it will be classified
with respect to its POS-Tags
3
. Then suitable rules for
suffix stripping will be applied to get candidate stems
that are returned and inserted into the lexicon
4
.
2.2 Understanding of Texts
Automatic understanding of texts is a complex prob-
lem and still a research topic today. Especially if fre-
quency analysis is used, problems may occur that are
referable to words with different meanings in subject
to the context.
The approach proposed in this paper will assume
that the tagnet builder is solely used for texts of one
topic. Thus, the described problem normally will not
occur in this scenario, but has to be addressed if texts
of different topics should be analysed.
3 APPROACH
Given an unstructured list of tags, the described sys-
tem is able to find semantic relations between these
tags and store them in a suitable database. Based on
this semantic tagnet text similarities can be calculated
for a corpus of tagged texts.
3.1 Tagnet Builder
The tagnet builder uses three different approaches to
gain as much information about semantic relations
between the given tags as possible. These three ap-
proaches are:
1. rule-based extraction of semantic relations
2. lexicon-based extraction of semantic relations
3. statistical estimation of semantic relations based
on occurrences in a given set of documents
In the following the approaches will be described in
detail.
3
Part-of-speech tagging basically denotes the tagging of
words with its grammatical characteristics.
4
The lexicon may contain intermediately wrong stems,
that will be corrected over time.
EFFICIENT LITERATURE RESEARCH BASED ON SEMANTIC TAGNETS - Implemented and Evaluated for a
German Text-corpus
49

3.1.1 Rule-based Approach
The problem of compound words has been mentioned
in the sections above. Nevertheless, analysis of such
compounds can be utilized as a first approach to rec-
ognize semantic relations between two words. As
an example, Fachsprache (terminology) and Sprache
(language) can be considered. Obviously, Sprache is
a suffix and hypernym
5
of Fachsprache.
A suffix matching based on regular expressions is
used to recognize such hypernym relations between
different tags. Analogously, semantic specification
relations, i.e. Fach (subject) specifies Fachtext
(specialized text) can be recognized by such an
approach. In this case prefix matching instead of
suffix matching has to be used. Nevertheless, this
simple matching approach results in so many wrong
matches, that it is not applicable.
Example. Given the two tags Text and Kontext
(context). The simple approach will recognize a
hypernym relation between these two tags although
this is an incorrect matching since no hypernym
relation exists in this case.
As a first solution a minimal string length δ of the
string before the suffix is demanded. Recalling the
example no semantic relation between Text, Kontext
or other similar tags will be detected for δ > 3. Since,
δ > 4 proved not to be useful, δ = 4 is assumed in the
following. Nevertheless, some correct matchings can-
not be recognized due to this restriction, but estima-
tions show that the number of not recognized existing
relations is rather small.
As a result the regular expression for the suffix
matching for a given alphabet Σ and a suffix s
1
can
be denoted as follows:
r
s
= ((((Σ+)-)+Σ
4
Σ*)+(Σ+ Σ+))s
1
(ε|en|e)
If w
1
∈ L(r
s
) for a given tag s
1
then a hypernym rela-
tion between s
1
and w
1
exists. Note that this regular
expression has already been adapted to several special
cases that occured in the given text-corpus. Further-
more, possible inflective suffixes have been removed
from s
1
in prior to match as much inflective forms
of the word w
1
as possible. Since this is an exclu-
sively rule-based approach, semantic relations can-
not be recognized for morphological special cases. If
such words should also be recognized a reliable lem-
matizer like the learning lemmatizer described above
is needed.
In contrast to this suffix matching, the identifica-
tion of specification relations is much more complex.
5
or generic term
This mainly results from two facts:
1. inflectional suffixes
2. erroneous splitting of compounds
In german verbs, nouns and adjectives can be used to
create compounds or specify other words. Often in-
flectional suffixes are removed in those cases. As an
example lesen (read) and Lesestrategie (reading strat-
egy) can be considered. Here, the suffix n is removed
before composing the two words lesen and Strategie
(strategy). Obviously, most of those semantic rela-
tions should be recognized by the tagnet builder.
Additionally, specification relations may be rec-
ognized wrongly because of equivocal compounds
that are mainly determined by the context. One ex-
ample is Texterkennung that can be decomposed to
Text-erkennung (text recognition) or Texter-kennung
(writer identification). In this case only the specifica-
tion relation between Text and Erkennung is correct,
but also the relation between Texter and Kennung will
be recognized. Unfortunately, this problem can solely
be solved by manually defined blacklists. Neverthe-
less, a filter can be defined that filters wrongly de-
tected relations, i.e. between Text and textualisieren
(textualize). This filter checks if for a candidate match
the remaining suffix is a known tag or word from a
given lexicons. Here, ualisieren is not contained in
the given lexicon and the relation will be discarded
correctly.
Finally, the regular expression can be denoted as
follows, where again inflective suffixes are removed
from s
1
and the expression is adapted to some special
cases:
r
p
= (Σ
4
Σ*-)*s
1
(ung|en|e|n|ε)(s|-|ε)Σ
3
Σ*
If w
1
∈ L(r
p
) for a given tag s
1
, than a candidate spec-
ification relation between s
1
and w
1
exists that has to
be filtered using the described filter afterwards.
3.1.2 Lexicon-based Approach
The rule-base approach is solely capable to recognize
hypernym and specification relations. Nevertheless,
semantic relations of other types should be identified
as well by the tagnet builder, i.e. schreiben (write) and
lesen (read). For this reason a lexicon-based approach
is presented, where Wikipedia
6
is used as the test lex-
icon. It is assumed that the given lexicon entries have
been normalized by the methods of stop word elimi-
nation and stemming described above.
The idea of the lexicon-based approach is to ex-
tract lexicon entries for each tag of the given set and
perform a frequency analysis for all other tags on
6
http://de.wikipedia.org/
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
50

these entries. Again, suffixes and prefixes have to be
considered during this analysis, but the general ap-
proach will be described first.
The main aspect of the lexicon-based approach is
to determine the strength of a semantic relation be-
tween tags. This significance is estimated based on
relative frequencies of tags in the given lexicon en-
tries. The relative frequency γ
0
s
1
,s
2
of a tag s
2
in the
lexicon entry l
s
1
for a given tag s
1
is defined as,
γ
0
s
1
,s
2
=
n
0
s
2
N
(1)
where n
0
s
2
denotes the absolute frequency of the cur-
rent tag s
2
in the lexicon entry. The relative frequency
is then derived by dividing n
0
s
2
by the total number of
words N in l
s
1
. In this simple approach n
0
s
2
is calcu-
lated as the frequency of all direct occurrences of s
2
in l
s
1
.
A further improvement can be achieved by split-
ting the lexicon entries in headlines and text blocks
and giving occurrences in the headlines a higher sig-
nificance than the ones in the text blocks. This is done
by a weight factor δ
1
∈ [0, 1]. The resulting enhanced
relative frequency γ
s
1
,s
2
is denoted as,
γ
s
1
,s
2
= δ
1
∗
n
t,s
2
N
t
+
n
h,s
2
N
h
(2)
where n
t,s
2
is the absolute frequency of s
2
in the text
blocks of l
s
1
. Analogously, n
h,s
2
is the absolute fre-
quency of s
2
in the headlines, N
t
denotes the num-
ber of words in the text blocks, and N
h
the number of
words in the headlines.
Much more information can be gained by consid-
ering occurrences of s
2
in l
s
1
as prefixe or suffix as
well. But occurrences as prefix generally not as rel-
evant as direct or suffix occurrences, since prefixes
normally just specify other words in the german lan-
guage. For this reason the enhanced approach is ex-
tended by a weight function which rates the different
occurrences in the text blocks by additional parame-
ters δ
2
and δ
3
. This distinction is only applied to text
blocks in the tagnet builder.
Thus, the enhanced relative frequency within the
text blocks n
t,s
2
is calculated by,
n
t,s
2
= n
direct
t,s
2
+ δ
2
∗ n
pre f ix
t,s
2
+ δ
3
∗ n
su f fix
t,s
2
(3)
where δ
2
and δ
3
are weight parameters for the ab-
solute frequencies as prefix and suffix, respectively.
This allows a much better estimation of semantic re-
lations between tags than the simple approach, since
language specific characteristics are taken into ac-
count.
3.1.3 Statistical Estimation
In contrast to the approaches described above it is also
possible to estimate semantic relations between tags
by frequency analysis on texts of a given corpus. Un-
fortunately, a large text corpus is needed for such sta-
tistical approaches in general. Hence, in Section 4.3
it was evaluated how the approach described below
works on a corpus of only 200 texts.
Our approach is composed of two estimation
steps.
1. estimation of the absolute tag frequencies in the
texts
2. estimation of possible semantic relations based on
these absolute frequencies
For step (1) basically the approaches described above
can be used, so that this step will be skipped here. In
the following it is assumed that for the given set of
tags S and all texts t
i
(i ∈ N)
n
t
i
(s
j
)∀s
j
∈ S
denotes the absolute tag frequency for tag s
j
in the
text t
i
with j ∈ {1 . . . |S|}. Based on these absolute
values it is possible to calculate relative tag frequen-
cies for all tags s
j
in the text t
i
by
n
0
t
i
(s
j
) =
n
t
i
(s
j
)
N
t
i
(4)
where N
t
i
= max(n
t
i
(s
1
), . . . , n
t
i
(s
|S|
)). These are used
to statistically estimate the significance of possibly
existing semantic relations between single tags.
Estimation of Possible Semantic Relations. For
all texts t
i
and a pair of tags (s
1
, s
2
) with s
1
, s
2
∈ S it is
checked, if n
t
(s
1
) > 0 and n
t
(s
2
) > 0 holds . The set of
all such texts is denoted as T. The strength of the sta-
tistical relations between these two tags δ
s
1
,s
2
is cal-
culated recursively for all texts t
i
∈ T (i ∈ {1 . . . |T |})
by
δ
(k)
s
1
,s
2
=
δ
(k−1)
s
1
,s
2
∗ k + n
0
t
k
(s
1
) ∗ n
0
t
k
(s
2
)
k + 1
(5)
where δ
(0)
s
1
,s
2
= 0, and 0 ≤ k ≤ |T |. The strength of a
possible semantic relation between to tags s
1
and s
2
is
than given by δ
s
1
,s
2
= δ
(|T |)
s
1
,s
2
.
This results in an histogram of all calculated pair-
wise statistical relations.
3.1.4 Result Combination
Finally, the tagnet builder combines the three result-
ing relation sets into one set containing the most rele-
vant relations of all three approaches. Since the qual-
ity of this final set mainly depends on the quality of
EFFICIENT LITERATURE RESEARCH BASED ON SEMANTIC TAGNETS - Implemented and Evaluated for a
German Text-corpus
51

all three sets, it is once again necessary to introduce
weight factors that allow to control the influence of a
base set on the final set. In case of relation duplicates
occuring in two different base sets the average of both
weighted qualities is calculated and stored as the new
relation quality in the final set.
3.2 Similarity Analysis
In contrast to other approaches which estimate text
similarities (Lee et al., 2005) our approach is based
on an uncertainty relation on tagsets S
1
and S
2
of two
texts t
1
and t
2
This solves the problem of disjunct
tagsets of similar texts and allows to estimate simi-
larity values in such cases. To realize the main ob-
jective of our approach the simple estimation is dis-
cussed first.
δ
0
t
1
,t
2
=
|S
1
∩ S
2
|
|S
1
∪ S
2
|
(6)
Obviously, no similarity can be calculated for disjunct
tagsets.
As a solution the tagsets S
1
and S
2
can be extended
by information gained from the generated semantic
tagnet. These new sets S
0
1
and S
0
2
are generated recur-
sively for a fixed number of recursion steps n
max
∈ N.
In each recursion step the neighbours of each tag in S
i
(i ∈ {1, 2}) are added to the sets S
0
i
. In our findings it
proved that n
max
> 4 is not useful. Thus, n
max
< 4 is
assumed in the following.
Although this idea already allows to calculate sim-
ilarities between two texts t
1
and t
2
with S
0
1
∩S
0
2
=
/
0 it
not yet satisfying, since no distinctions are made be-
tween the tags in the two sets S
0
1
and S
0
2
. For this rea-
son tag significances p
i, j
were introduced which de-
pend on the current recursion step n and manually de-
fined significances γ
r
for all considered relation types
r. The similarity of two texts t
1
and t
2
then can be
estimated as
δ
t
1
,t
2
=
1
2M
∗
N
∑
i=1
(p
1,i
+ p
2,i
) (7)
where N = |S
0
1
∩ S
0
2
| and M = |S
0
1
∪ S
0
2
|. For a given
threshold τ and a text t
1
all texts with δt
1
,t
i
>= τ (i ∈
{1, ··· , |T |},t
i
6= t
1
) can be queried.
4 EVALUATION
The described system has been implemented in Java
and evaluated on four different tagsets.
ipTS: This set contains 3087 tags that mainly are
part of the topic of text production and writing
research which are part of the ipTS
7
research
project. Note that this tagset has been prepro-
cessed in terms of removing wrong tags and ad-
justing flectional suffixes. Thus, the results were
somewhat better than the results of the three other
tagsets.
II: This set contains 2748 tags from the topic of in-
formatics
8
.
IDS: This set contains the 1769 most basic german
words
9
.
AMS
¨
O: This set contains more than 10 000 occupa-
tional qualifications of different topics and thus
is the most comprehensive tagset in this evalua-
tion
10
.
The evaluation was made by applying the imple-
mented system to these four tagsets. Subsequently the
generated semantic tagnets were checked for wrongly
recognized semantic relations. Since manual prepro-
cessing is unwanted, the ipTS tagset was the only pre-
processed set in this evaluation.
Fig. 1 depicts a part of a semantic tagnet visualiza-
tion (G
¨
otten, 2009) which was generated by the tagnet
builder from the ipTS tagset. The semantic tagnet was
embedded into the ipTS
11
project website to simplify
the literature research task for domain experts. The
arrows represent hyperonym relations between key-
words, while the undirected edges express generic se-
mantic relations.
4.1 Rule-based Approach
In the first evaluation step exclusively the rule-based
approach was considered. Table 1 contains the eval-
uation results of the rule-based approach on all four
tagsets. Obviously, the rule-based approach works
quite well for all given tagsets, since the accuracy is
smaller than 1% for most of the sets.
Table 1: Semantic relations extracted by rule-based ap-
proach.
Tagset Entries Relations Error Rate
ipTS 3807 1287 0,8 %
II 2748 1656 0,6 %
IDS 1769 502 0,4 %
AMS
¨
O 10 245 1760 1,5 %
7
http://www.ipts.rwth-aachen.de/
8
http://is.uni-sb.de/vibi/
9
http://www.ids-mannheim.de/oea/
10
http://www.ams.or.at/bis/
11
http://www.ipts.rwth-aachen.de/
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
52
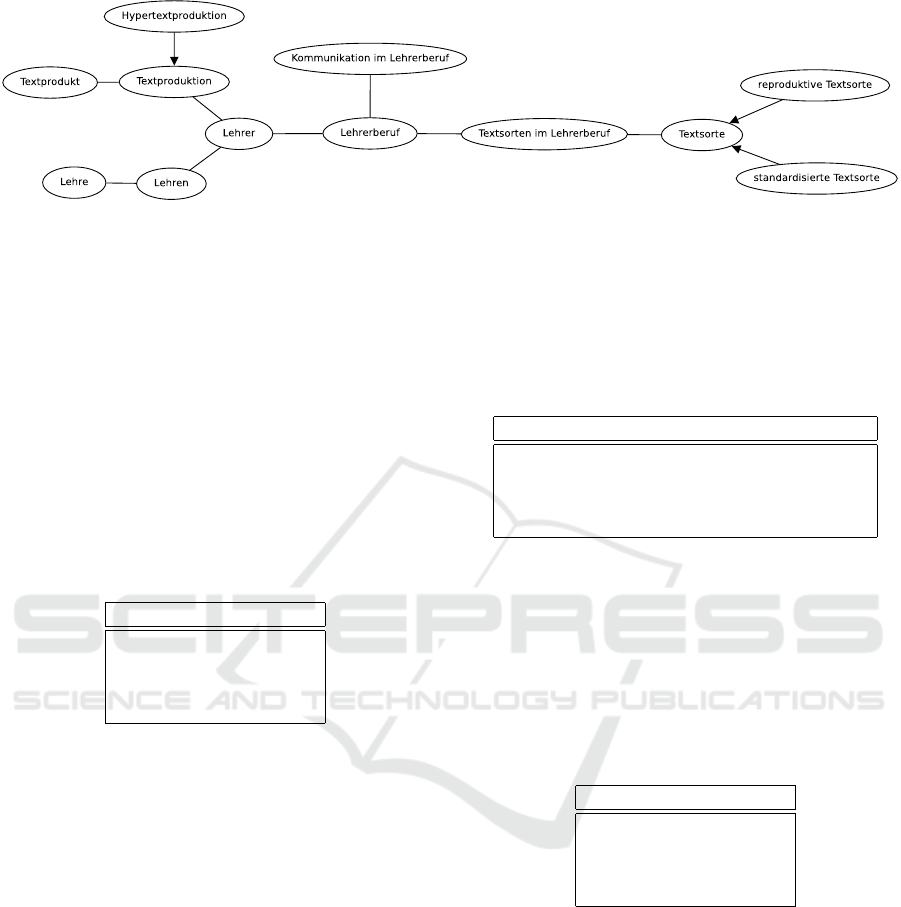
Figure 1: Part of the extracted semantic net.
Only for the AMS
¨
O tagset 1,5% semantic rela-
tions were recognized wrongly, due to the tags of dif-
ferent topics. Note that this accuracy does not con-
sider existing semantic relations between tags that are
not recognized. However, on average semantic rela-
tions between 33% of the given tags were recognized.
This is shown in Table 2.
In the first evaluation step exclusively the rule-
based approach is considered. Table 1 contains the
evaluation results of the rule-based approach on all
four tagsets. Obviously, the rule-based approach
works quite well for all given tagsets, since the ac-
curacy is smaller than 1% for most of the sets.
Table 2: Number of linked tags.
Tagset Linked tags
ipTS 30,4 % (1160)
II 51,6 % (1419)
IDS 29,5 % (522)
AMS
¨
O 20,7 % (2122)
The results illustrate the benefit of such a pattern-
based approach which estimates the possible seman-
tic relations between the tags in different sets in short
time. As an example the semantic relations for the
ipTS tagset were estimated in less than 20 seconds
on the testing machine, while the estimation on the
AMS
¨
O set only took 88 seconds. For a synthetic gen-
erated tagset the rule-based approach shows an almost
linear growth in runtime for large sets with more than
20 000 entries
4.2 Lexicon-based Approach
In contrast to this fast rule-based approach the
lexicon-based approach needs much more calculation
time (more than four hours). For all smaller sets the
calculation takes less than one hour. Although the cal-
culation time is much longer than in the rule-based
approach, the lexicon-based approach allows to rec-
ognize semantic relations between tags that cannot be
recognized by the plain rule-based approach as de-
scribed in Section 3.1.1.
Table 3 shows the numbers of extracted relations
for the given tagsets. In comparison to the rule-
based approach many more relations are extracted es-
pecially for the AMS
¨
O tagset.
Table 3: Semantic relations extracted by lexicon-based ap-
proach.
Tagset Entries Relations Error rate
ipTS 3807 2853 2,8 %
II 2748 3337 5,1 %
IDS 1769 1600 4,7 %
AMS
¨
O 10 245 5494 3,4 %
This mainly results from the type of the contained
tags in this set since there is a wide range of words or
concepts that describe similar processes or are some-
how related to each other. Consequently, the total
number of alike tags is higher for this lexicon-based
approach compared to the results of the rule-based ap-
proach as shown in Table 4.
Table 4: Number of linked tags.
Tagset Linked tags
ipTS 31,5 % (1198)
II 50,0 % (1376)
IDS 44,7 % (791)
AMS
¨
O 32,1 % (3286)
4.3 Statistical Approach
The statistical approach has solely been evaluated
for the ipTS set due to the lack of a suitable text
corpus for the other three tagsets. As expected a
very large number of candidate semantic relations
were extracted, but mostly with very small semantic
strengths. For a proper threshold only 3455 of more
than 400 000 candidate relations remained. Unfortu-
nately the number of wrongly recognized semantic re-
lations still were quite high (12%). However it was
possible to reduce the error rate to 4,7% by blacklist-
ing problematic tags. It is assumed that the result of
EFFICIENT LITERATURE RESEARCH BASED ON SEMANTIC TAGNETS - Implemented and Evaluated for a
German Text-corpus
53

the described statistical approach can be improved by
a larger text corpus.
5 CONCLUSIONS
An approach has been described that allows to effi-
ciently generate semantic tagnets for given unstruc-
tured lists of tags and an arbitrary text corpus. This
semantic tagnet can be used to estimate text similar-
ities for tagged texts in digital libraries to provide a
more intuitive way of literature research adapted to
the user’s cognitive model. In addition to this the gen-
erated semantic tagnet could be used to define ontolo-
gies or allow users to enhance the network using a
suitable interface similar to the idea of user feedback
as proposed in (Doan and McCann, 2003).
In a future version the tagnet builder may be en-
hanced by some components that allow to extract
synonym relations, too. One idea of a rule-based
approach has been proposed in (Ananthanarayanan
et al., 2008) for english words. This enhancement
would allow to store relations between tags in dif-
ferent languages to create a multilingual semantic net
that can be used for a digital library that stores texts
in different languages.
ACKNOWLEDGEMENTS
This research was funded in part by the DFG Cluster
of Excellence on Ultra-high Speed Information and
Communication (UMIC), German Research Founda-
tion grant DFG EXC 89, and by the German Research
Foundation grant for the Project Interdisciplinary Text
Production and Writing (ipTS
12
).
REFERENCES
Ananthanarayanan, R., Chenthamarakshan, V., Deshpande,
P. M., and Krishnapuram, R. (2008). Rule based syn-
onyms for entity extraction from noisy text. In AND
’08: Proceedings of the second workshop on Analyt-
ics for noisy unstructured text data, pages 31–38, New
York, NY, USA. ACM.
Barnett, B. (2009). Regular expressions,
http://www.grymoire.com/unix/regular.html.
Berners-Lee, T., Hendler, J., and Lassila, O. (2001). The se-
mantic web - a new form of web content that is mean-
ingful to computers will unleash a revolution of new
possibilities.
12
http://www.ipts.rwth-aachen.de/
Chaffin, R. (1992). The concept of a semantic relation. In
A. Lehrer, E. K., editor, Frames, Fields and Contrasts,
pages 253–288. Lawrence Erlbaum, Hillsdale, N.J.
Collins, A. and Quillian, M. (1969). Retrieval time from
semantic memory. Journal of Verbal Learning and
Verbal Behavior, 8(2):240–247.
Doan, A. and McCann, R. (2003). Building data integration
systems: A mass collaboration approach. In IIWeb,
pages 183–188.
Fellbaum, C., editor (1998). WordNet: An Electronic Lex-
ical Database (Language, Speech, and Communica-
tion). The MIT Press.
Gaizauskas, R. and Humphreys, K. (1997). Using a se-
mantic network for information extraction. Nat. Lang.
Eng., 3(2):147–169.
G
¨
otten, D. (2009). Semantische Schlagwortnetze zur ef-
fizienten Literaturrecherche. Master’s thesis, RWTH
Aachen University.
Harris, Z. (1985). In Katz, J. J., editor, The Philosophy of
linguistics, pages 26–47. Oxford University Press.
Harrison, M. A. (1978). Introduction to Formal Language
Theory. Addison-Wesley Longman Publishing Co.,
Inc., Boston, MA, USA.
Lee, M. D., Pincombe, B., and Welsh, M. (2005). An em-
pirical evaluation of models of text document simi-
larity. In Proceedings of the 27th Annual Conference
of the Cognitive Science Society, pages 1254–1259,
Mahwah, NJ. Erlbaum.
L
¨
obner, S. (2003). Semantik. Eine Einf
¨
uhrung.
Lovins, J. B. (1968). Development of a stemming algo-
rithm. Mechanical Translation and Computational
Linguistics, 11:22–31.
Perera, P. and Witte, R. (2005). A self-learning context-
aware lemmatizer for german. In Proceedings
of Human Language Technology Conference and
Conference on Empirical Methods in Natural Lan-
guage Processing, pages 636–643, Vancouver, British
Columbia, Canada. Association for Computational
Linguistics.
Porter, M. F. (1980). An algorithm for suffix stripping. Pro-
gram, 14(3):130–137.
Porter, M. F. (2009). German stemming algorithm.
Quillian, M. R. (1967). Word concepts: A theory and simu-
lation of some basic semantic capabilities. Behavioral
Science, 12:410–430.
Schmid, H. (1994). Probabilistic part-of-speech tagging us-
ing decision trees. In Proceedings of International
Conference on New Methods in Language Processing.
Schmid, H. (1995). Improvements in part-of-speech tagging
with an application to german. In In Proceedings of
the ACL SIGDAT-Workshop, pages 47–50.
Sowa, J., editor (1991). Principles of Semantic Net-
works: Explorations in the Representation of Knowl-
edge (Morgan Kaufmann Series in Representation and
Reasoning). Morgan Kaufmann Pub.
Sowa, J. (2009). Semantic networks,
http://www.jfsowa.com/pubs/semnet.htm.
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
54
