
RELATED WORD EXTRACTION FROM WIKIPEDIA FOR WEB
RETRIEVAL ASSISTANCE
Kentaro Hori
Graduate School of Information Science and Electrical Engineering, Kyushu University, Fukuoka City, Fukuoka, Japan
Tetsuya Oishi, Tsunenori Mine, Ryuzo Hasegawa, Hiroshi Fujita, and Miyuki Koshimura
Faculty of Information Science and Electrical Engineering, Kyushu University, Fukuoka, Japan
Keywords:
Wikipedia, Web retrieval.
Abstract:
This paper proposes a web retrieval system with extended queries generated from the contents of Wikipedia.By
using the extended queries, we aim to assist user in retrieving Web pages and acquiring knowledge. To extract
extended query items, we make much of hyperlinks in Wikipedia in addition to the related word extraction
algorithm. We evaluated the system through experimental use of it by several examinees and the questionnaires
to them. Experimental results show that our system works well for user’s retrieval and knowledge acquisition.
1 INTRODUCTION
In recent years, many people can access Web very
easily thanks to the vast spread of internet as well as
the availability of convenient search engines.
For instance, Google
1
, Yahoo
2
, and Goo
3
are
commonly used. Giving a few keywords, these sys-
tems retrieve such Web pages that users want to see
from among the huge databases residing on the inter-
net. Google, in particular, successfully presents us the
most suitable pages on the first page of the retrieval
results by applying the PageRank algorithm(Page and
Lopes, 1998) which evaluates relevance of pages
based on page links.
Even though, since the Web sources are so enor-
mous and constantly increasing, it is often the case
that we are not satisfied with the results given by
them.
As for a method to improve the retrieval results,
conjunctive query can be used. If you give multiple
keywords all of which are relevant to your query, you
will be able to obtain better retrieval results compared
to those obtained for a single keyword. However, it
may not always be the case that every keyword you
give is appropriate for your intended query. Even if
1
http://www.google.co.jp/
2
http://www.yahoo.co.jp/
3
http://www.goo.ne.jp/
the keywords are all relevant to the query, you may
not be always satisfied with the retrieved results. This
is because search engines will look over such Web
pages that are relevant to the query, but do not con-
tain any keyword in the query. Also, if the area within
which you want to look for some information is not
very familiar to you, you will be unable to give ap-
propriate keywords for your query. Thus, conjunctive
query is not enough.
To solve the problem, there have been many works
on such systems that can offer keywords relevant
to one given by the user, such as (Masada et al.,
2005)(Mano et al., 2003). In order to offer related
keywords, these systems require some additional in-
formation other than the keyword given by the user.
One method uses, as the additional information, the
retrieved results themselves that are obtained for the
initial query(Murata et al., 2008).
For instance, pseudofeedback methods take top
ten Web pages in the ranking of the results as the rel-
evant documents, and other Web pages as irrelevant
documents. Then, some related words are extracted
from the above classified documents. The advantage
of the method is that it does not add users burden,
and that it always returns some relevant results. How-
ever, these days, advanced services on the internet
such as blogs, bulletin boards, and online shopping
are becoming sources of tremendous information that
192
Hori K., Oishi T., Mine T., Hasegawa R., Fujita H. and Koshimura M. (2010).
RELATED WORD EXTRACTION FROM WIKIPEDIA FOR WEB RETRIEVAL ASSISTANCE.
In Proceedings of the 2nd International Conference on Agents and Artificial Intelligence - Agents, pages 192-199
DOI: 10.5220/0002728801920199
Copyright
c
SciTePress
would appear in the retrieval results as irrelevantones.
If these are ranked higher in the result list, and used as
the seemingly relevant documents for the pseudofeed-
back method, it would surely be the case that signif-
icant amount of irrelevant information is included in
the final results.
Therefore, we present a new method and a system
for related word extraction that uses Wikipedia
4
as the
information source. Wikipedia is a well known online
encyclopedia that is well organized with rich contents,
words, and internal links. Moreover, since it can eas-
ily be updated by anyone, many researchers have been
giving attention to it. Using Wikipedia, systems will
be able to remove irrelevant information from their
retrieval results, and improve the accuracy of the re-
sults especially when the area of interest is unfamiliar
to the user.
The problem with Wikipedia is as follows: it may
occur with high probability that the keyword given
by the user is absent in it, since the total amount
of information contained in Wikipedia is quite small
compared to those contained in whole Web pages on
the internet, and the users query may be exotic to
Wikipedia. So, we categorize queries in advance, and
build a most useful system for a user who wants to
use the Web as if it were a large virtual dictionary.
The usefulness is evaluated on the basis of accuracy
improvement and the quantity of information that is
new and interesting to the user.
2 RELATED WORK
Bedsides pseudofeedback, there are two more feed-
back methods called explicit feedback and implict
feedback. The former depends on the users evaluation
of documents, whereas the latter automatically col-
lects documents by analyzing users operations such
as scroll, click and zoom.
Another system uses personal information that re-
flects a user profile as an auxiliary information(Sieg
et al., 2007)(Yoshinori, 2004)(Qiu and Cho, 2006)D
Concretely a user profile will be derived from sched-
ules or some database containing his/her interests or
favorites. These help the system to offer related words
that meet his/her intention. For instance, when a user
wants to know about the weather forecast, the sys-
tem would examine just the regions which are near the
place where he/she lives. As far as the user wants such
information that is very specific to his/her interest, it
should be more appropriate to derive related words
from user profiles than to find out them from among
4
http://ja.wikipedia.org/
the Web that includes words from so many fields of
general interest. Yet these system would have some
difficulty to show relevant words when the user really
wants to obtain information quite new to him. This is
because there should be few information in the user
files which are supposed to suggest words about alien
culture, unseen incidents, and unfamiliar history, etc.
As for work concerning Wikipedia, Nakayama(Ito
et al., 2008) et.al. have succeeded in constructing
the association thesaurus dictionary for extracting re-
lated words from a given query. They calculate co-
occurrence of words that have links to other pages in
terms of the relatedness between those linked pages.
However, as Wikipedia’s internal links are provided
only arbitrarily by the author of that specific page,
some pages contain many links, others very few, or
even no internal link at all. In such a case, their sys-
tem will not work. On the other hand, our system
uses the related word extraction algorithm of our own
where all words, with or without linked words, are
taken into account, and free from the above problem.
The detail of the algorithm is described in section 5.
3 SYSTEM OVERVIEW
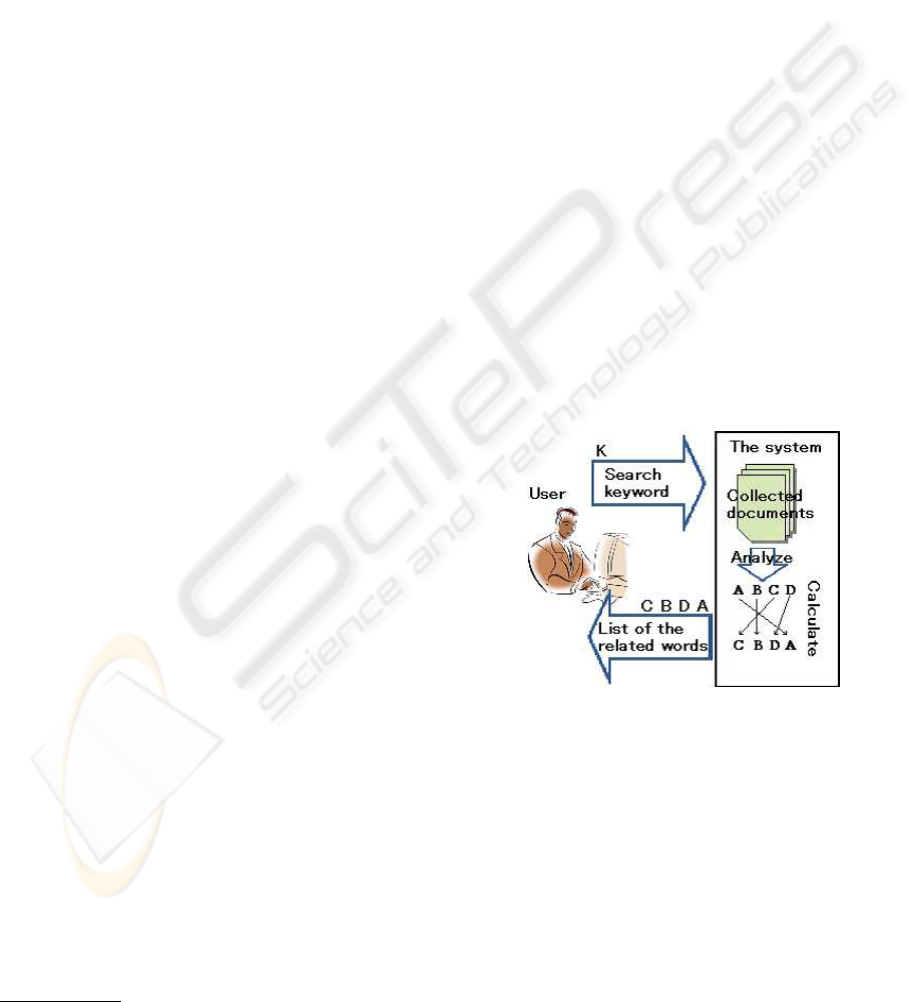
Figure 1 shows an overview of our system.
Figure 1: Image of system.
First, the user inputs a query, refereed as the initial
query, to the system. The goal of our system is to find
out related words for the query.
Second, the system collects documents called rel-
evant documents that are related to the initial query
and are used as sources for extracting related words.
Our system takes Wikipedia as a source of rele-
vant documents and extract some paragraphs from
Wikipedia pages that are related to the initial query.
The details will be described in section 4.
Third, the system performs morphological anal-
ysis on the above collected relevant documents by
RELATED WORD EXTRACTION FROM WIKIPEDIA FOR WEB RETRIEVAL ASSISTANCE
193

means of MeCab
5
. With MeCab it squeezes only
nouns from the documents, then discards words like
“something” or “anything” that are registered in the
system as unnecessary in advance. Furthermore, a
special rule is installed to it so that a connected word
like “graduation thesis” will not be broken apart into
two nouns “graduation” and “thesis.”
Finally, the system calculates for each of the
above obtained words an estimate value as the re-
lated word. There have been many works on the
way to do this. For instance, RSV (Robertson Se-
lection Value)(Robertson, 1990) algorithm considers
such words as more important that appear more often
(or less often) in relevant documents than in irrelevant
documents. RSV is not very suitable for our system,
since there is basically no way of providing irrelevant
documents. Therefore, we use a related word extrac-
tion algorithm(Kuramoto et al., 2007) of our own that
calculates the value of a word based on the notion of
distance between words in a document. We also make
some correction of the value of words on the basis of
internal links within Wikipedia. The details are de-
scribed in section 5.
4 OUR NEW METHOD
We use Wikipedia as the relevant document for our
system. The reason why we chose Wikipedia is as
follows.
• Wikipedia is one of the largest encyclopedias
on the Web having more than 590,000 Japanese
words (as of June, 2009).
• Its content is very rich
6
(Thomas, 2006).
• A number of people can easily access, even mod-
ify its content and make it always up-to-date.
4.1 Extraction Method
The way of collecting relevant sentences slightly dif-
fers according to the number of keywords in the initial
query.
Initial Query with One Keyword
Let the initial query be “A”. The system retrieves
Wikipedia to find an article on “A”. It extracts
the highest ranked page of the retrieved result and
searches for the paragraph where “A” appears in the
page. The extracted paragraph is used as a relevant
sentence.
5
http://mecab.sourceforge.net/
6
http://woy2007.sbcr.jp/
Initial Query with Two or More Keywords
Use the following elements.
• Q
i
(i = 1,··· ,n) :Given query
• P
Q
i
(i = 1,··· ,n) :Highest rank of result page of
Wikipedia retrieved by Q
i
• Extract(P,Q) :Extract from “P” the paragraph
where “Q” appears.
• ExSentence :Extraction result
Extracted sentence are expressed by the following ex-
pressions.
ExSentence =
n
∑
k=1
n
∑
j=1
( j 6= k)Extract(P
Q
j
,Q
k
)
+Extract(P
Q
1
∧Q
2
∧···∧Q
n
,Q
1
∧ Q
2
∧ · ·· ∧ Q
n
)
Let the initial query be “Q
1
Q
2
”. The system re-
trieves Wikipedia with three queries “Q
1
”, “Q
2
”, and
“Q
1
Q
2
”. It collects the highest ranked page for each
query. Let us call them “P
Q
1
”, “P
Q
2
”, and “P
Q
1
Q
2
”,
respectively. From “P
Q
1
” the paragraph where “Q
2
”
appears is extracted. From “P
Q
2
” the one where “Q
1
”
appears is extracted. From “P
Q
1
Q
2
” the one where
both “Q
1
” and “Q
2
” appear is extracted.
For instance, when the system retrieves with query
“Omelette seasoning”, “Omelette” is first retrieved
with Wikipedia. Since the page of “Omelette” be-
comes a hit, the system searches for a paragraph with
the word “Seasoning” in “Omelette” page. When it is
found, the paragraph with “Seasoning” is extracted as
a relevant sentence. Next, when the system retrieves
with “Seasoning”, the page of “Seasoned laver” be-
comes a hit. However, nothing is extracted because
there is no paragraph where word “Omelette” ex-
ists. Finally, it retrieves by “Omelette seasoning”, and
the page of “Omelet” becomes a hit. The paragraph
where both “Omelette” and “Seasoning” words exist
in this page is extracted. In this way, the extracted
paragraphs are assumed to be relevant sentences, and
the morphological analysis is performed. Figure 2
shows how the sentences containing the word “sea-
soning” are searched for, and the corresponding para-
graph is extracted.
Although for initial queries with three or more
keywords, a paragraph can be extracted as a relevant
sentence as well, we did not experiment. This is be-
cause such a query is issued with a clear purpose so
that we can get enough results, and the extraction time
increases greatly by the combination.
ICAART 2010 - 2nd International Conference on Agents and Artificial Intelligence
194

Figure 2: Actual extraction image.
5 RELATED LEVEL
CALCULATION OF WORD
5.1 Outline of the Algorithm
The algorithm extracts, from words appearing in the
text T, a group of words that are related to a given set
of keywords K, and thus are expected to be important
for K. Based on the distance from a keyword, we
evaluate each word in K or T, and form a set of words
to be output as a result of related word extraction.
The idea behind this algorithm is a distance be-
tween words. Concretely, it pays attention to the or-
der of words that appear in sentences, and it considers
the words that appears near to A to be relevant to A.
5.1.1 Notation
We define some symbols as follows:
• K: a set of keywords that give a basis for extract-
ing related words.
• T: a text to be given degrees of relation with K.
• k
i
(i = 1,· ·· ,m): m keywords appearing in K,
where the keywords k
1
,k
2
,··· ,k
m
appear in this
order.
• s
h
(h = 1,··· ,n): n sentences appearing in T,
where the sentences s
1
,s
2
,··· ,s
n
appear in this or-
der.
• F
k
i
(s
g
)(g = 1, ·· · , n): F
k
i
(s
g
) = 1when s
g
contains
key word k
i
, otherwise F
k
i
(s
g
) = 0.
• t
j
( j = 1,· ·· ,o): o words appearing in T, where
the words t
1
,t
2
,··· ,t
n
appear in this order.
t
j
represents a noun word extracted by performing
morphological analysis of words in the text T. The
extracted words are arranged in appearance order. In
case a word appears more than twice, these occur-
rences are considered to be different.
5.2 Evaluation of Word in Text
Evaluation of words in the text T is performed as fol-
lows:
1. Calculate basic value BV(s
h
) of s
h
( j = 1,· ·· ,n)
with k
i
(i = 1,··· , m) as a criterion.
2. Smooth BV(s
h
).
3. Calculate a final value V(t
j
) using word frequen-
cies.
5.2.1 Calculating BV(s
h
)
This algorithm evaluates the word based on key word
group K focusing on the distance between words that
appear in K and text T, and first calculates the evalu-
ation value that gives the basis.
We define BV
k
i
(s
h
) as the score of s
h
with respect
to k
i
.
BV
k
i
(s
h
) =
n
∑
g=1
(n− |g − h|)F
k
i
(s
g
) (1)
Here, |g − h| is a distance of s
h
and a sentence
in which k
i
appears. When k
p
appears in s
q
, |g −
h| = |q − q| and F
k
p
(s
q
) = 1, so BV
k
p
(s
q
) = n. For
the next sentences s
q+1
and s
q−1
, the distances are
|q− (q + 1)| = 1, |q − (q− 1)| = 1, respectively, and
thus BV
k
p
(s
q+1
) = BV
k
p
(s
q−1
) = n − 1. Note that
BV
k
i
(s
h
) takes a larger value, as s
h
gets closer to the
sentence in which k
i
appears.
After having calculated every BV
k
i
(s
h
) (i =
1,· ·· ,m), the algorithm calculates BV(s
h
) with the
following formula.
BV(s
h
) =
m
∑
i=1
BV
k
i
(s
h
) (2)
An example that calculates BV(s
h
) is shown in Ta-
ble 1, where keyword A appears twice in text T.
Table 1: An example of scoring sentences using distance.
keyword K A B
text T AFB ED AFC FE DE
BV
A
(s
h
) 8 8 8 6 4
BV
B
(s
h
) 5 4 3 2 1
BV(s
h
) 13 12 11 8 5
RELATED WORD EXTRACTION FROM WIKIPEDIA FOR WEB RETRIEVAL ASSISTANCE
195

5.2.2 Smoothing of BV(s
h
)
The above way of determining BV(s
h
) is unfair when
considering the position of sentence s
h
in T. For
s
h
(h = 1,n) appearing at the edge of T, the value
of BV
k
i
(s
h
) (j = 1 or n) ranges from 1 to n (1 ≤
BV
k
i
(s
h
) ≤ n), while for the word appearing in the
center of T, it ranges from n/2 to n (n/2 ≤ BV
k
i
(s
h
) ≤
n).
Thus, the expected values of BV(s
h
) differ de-
pending on the position h at which s
h
occurs. As
the word appearing in the center of T will be given
a larger value, a fair evaluation cannot be achieved.
To remedy this problem, we smooth the obtained
BV(s
h
) using EBV(h), the expected evaluation value
of s
h
at position h. EBV(h) is calculated as follows:
EBV(h) =
1
2n
n(n+ 2h− 1) − 2h(h− 1) (3)
where n is the total number of sentence occurrences in
T. Let EBV(s
h
) be the evaluation value after smooth-
ing. It is calculated using the following formula.
EBV(s
h
) =
BV(s
h
)
EBV(h)
(4)
Table 2 shows a process of getting EBV(s
h
) from
the given text T. Since EBV(h) is the expected eval-
uation value at position h, the value for the position
nearer the center (around h = n/2) becomes larger.
Naturally, both left and right sides are symmetrical
with respect to the center having a peak. As seen in
Table 2, by smoothing of BV(s
h
) with EBV(h), unfair
evaluation in BV(s
h
) is well remedied.
Table 2: An example of calculating EBV(s
h
) using the ex-
pected value EBV(h) at occurrence position h.
keyword K A B
text T AFB ED AFC FE DE
BV(s
h
) 13 12 11 8 5
EBV(h) 3 3.6 3.8 3.6 3
EBV(s
h
) 4.33 3.33 2.89 2.22 1.67
5.2.3 Calculating V
T
(t
j
)
In addition to the evaluation based on the distance
between sentences, we take into consideration the
concept of Term Frequency that is often used in the
TF/IDF method. In other words, the words which ap-
pear larger number of times in a text T should be more
important.
First, we compute the average AveEBV(t
j
) of the
expected evaluation values EBV(t
j
), for word t
j
that
appears several times.
For instance, if sentence s
a
and sentence s
b
(ab)
are identical with t
c
, AveEBV(t
c
) = (EBV(s
a
) +
EBV(s
b
))/2.
Of course, for the word t
j
(t
j
is a word in s
h
) that
appears only once in T, AveEBV(t
j
) = EBV(s
h
).
Moreover, we compute the weight W
T
(t
j
) using
the t f value of word t
j
as follows.
W
T
(t
j
) = 1+
t f(t
j
)
n
logt f(t
j
) (5)
Here, t f(t
j
) is the number of occurrences of word t
j
in the text T and n is the total number of occurrences
of words in T. Then by using AveEBV(t
j
) andW
T
(t
j
),
we calculate the evaluation value V
T
(t
j
) of t
j
in T as
follows.
V
T
(t
j
) = AveEBV(t
j
) ∗W
T
(t
j
) (6)
We assume that V
T
(t
j
) is the evaluation value of
word t
j
in text T in this algorithm. Table 3 shows
a process of calculating V
T
(t
j
). Because word C ap-
pears twice in text T, t f(C)is 2. As for other words,
the t f value is 1. Since W
T
(t
j
) is calculated using t f
values, the t f value is 1 for words which appear once,
and takes a value greater than 1 for words which ap-
pear twice or more.
Then the final evaluation value EBV(C) is calcu-
lated. We assume that the words in T are related to K
in the order of F, A, B, E, D and C.
Table 3: V
T
(t
j
) of each words.
keywordK A B
textT AFB ED AFC FE DE
EBV(s
h
) 4.33 1.67 2.11 2.22 2.67
word A B C D E F
AveEBV(t
j
) 3.61 4.33 2.11 1.67 2.50 2.56
t f(t
j
) 2 1 1 2 3 3
W
T
(t
j
) 1.28 1 1 1.28 1.66 1.66
V
T
(t
j
) 4.62 4.33 2.11 3.20 4.00 5.23
5.3 Correction by Internal Links of
Wikipedia
5.3.1 Outline
In addition, we pay attention to the hyperlink(internal
link) to another article in the article on Wikipedia.
This internal link can be arbitrarily set by the author
of the article, and the word to which an internal link
is set can be considered to be deeply related to the ar-
ticle, and thus an important word that you should pay
attention to. However, since an internal link can be
ICAART 2010 - 2nd International Conference on Agents and Artificial Intelligence
196

set arbitrarily it may not be related to the initial query.
Then, we calculate a degree of relevancy to the initial
query.
5.3.2 Computational Method
• LW
f
( f = 1cp): a word for which an internal link
is specified
• RWS(LW
f
): the evaluation value of LW
f
calcu-
lated by the related word extraction algorithm
• LW
f(k
i
)
: frequency that keyword k
i
appears in the
article to which the internal link of LW
f
points.
A final evaluation value is calculated from the
above-mentioned three items as follows.
• WikiEX(LW
f
) = log(Σ
m
i=1
LW
f(k
i
)
) + 1
• WordScore(LW
f
) = RWS(LW
f
) ∗WikiEX(LW
f
)
Since preliminary experiments show that LW
f
(k
i
)
ranges from 0 to 100 or more, we took the logarithm
to reduce an extreme evaluation value difference. We
take this WordScore(LW
f
) to be a final evaluation
value. For a word without having an internal link, its
evaluation value of the related word extraction algo-
rithm is assumed to be a final evaluation value.
6 CLASSIFICATION OF QUERY
We classify queries into the following three classes on
the basis of investigation by Andrei(Broder, 2002).
1. Navigational query
2. Transactional query
3. Informational query
A navigational query is the one for which just a
single page is to be sought after. For instance, by
giving “Google” as a query, most probably the user
would like to see the Google’s top page. This type
of queries need not to be augmented, as any existing
search engine can easily present satisfactory results
for them.
A transactional query is the one at which the user
would start taking some action such as shopping,
downloading, and looking for maps. For this type of
queries, it should be effective to perform query aug-
mentation based on user profiles as described in sec-
tion 2.
An informational query is the one about which the
user wants to obtain some knowledge. When the user
has a word unfamiliar to him/her and wants to know
about something concerning it, he/she would make a
query about the word to obtain its related information.
Actually, informational queries are the principal
subject of our system that are supposed to be treated
most effectively. Therefore, we concentrate on this
class of queries for our subject in the following ex-
periments.
About query classification, we plan to use the au-
tomatic classification technology like (Fujii, 2007) in
the future, but we manually classified the queries this
time.
7 EXPERIMENTS
We evaluate our system by comparing its results to
those obtained in [Goo] and [Web5]. [Goo] is a search
engine operated by NTT Resonant. We compare the
accuracy of results by our system to those obtained by
[Goo]. [Web5] is a data obtained for the Web pages
which are ranked in top five of the retrieval results for
an initial query and taken as relevant documents(Oishi
et al., 2008). We examine the accuracy of results
in terms of the difference of relevant documents, be-
tween those of [Web5] and Wikipedia pages used in
our system. The effectiveness of the related word
extraction algorithm itself has been demonstrated by
Oishi et.al.(Oishi et al., 2008) The accuracy of the re-
sults is measured in terms of MAP (Mean Average
Precision). AP (Average Precision) is the average of
ratios of the number of documents that user judges
good to the number of whole documents provided as
the result for the initial query. MAP is an average of
AP over a set of queries.
The AP is defined as follows:
Average Precision =
∑
L
r=1
I(r)P(r)
R
Where R is the total number of relevant docu-
ments; L is the number of results retrieved by a sys-
tem. In this experiment, we set L to 10 and R to
10, too; I(r) is 1 if the r-th ranked document is rele-
vant, and 0 otherwise; P(r) is
count(r)
r
; count(r) is the
number of relevant documents among r documents re-
turned by the system.
Figure 3 shows the result.
80 queries are used for this experiment. We con-
centrate on how much the accuracy of the retrieval re-
sults is improved compared to those obtained by an
existing engine. First, we calculate AP for the re-
sults given by Goo. Next, each query is classified
into 11 classes according to the value of AP, first 0,
second 0.1 or less, and so on, and finally 1.0 or less.
Then, we calculate MAP for each class of queries and
for each method being compared. We can say that
a MAP value given by any method for those queries
RELATED WORD EXTRACTION FROM WIKIPEDIA FOR WEB RETRIEVAL ASSISTANCE
197
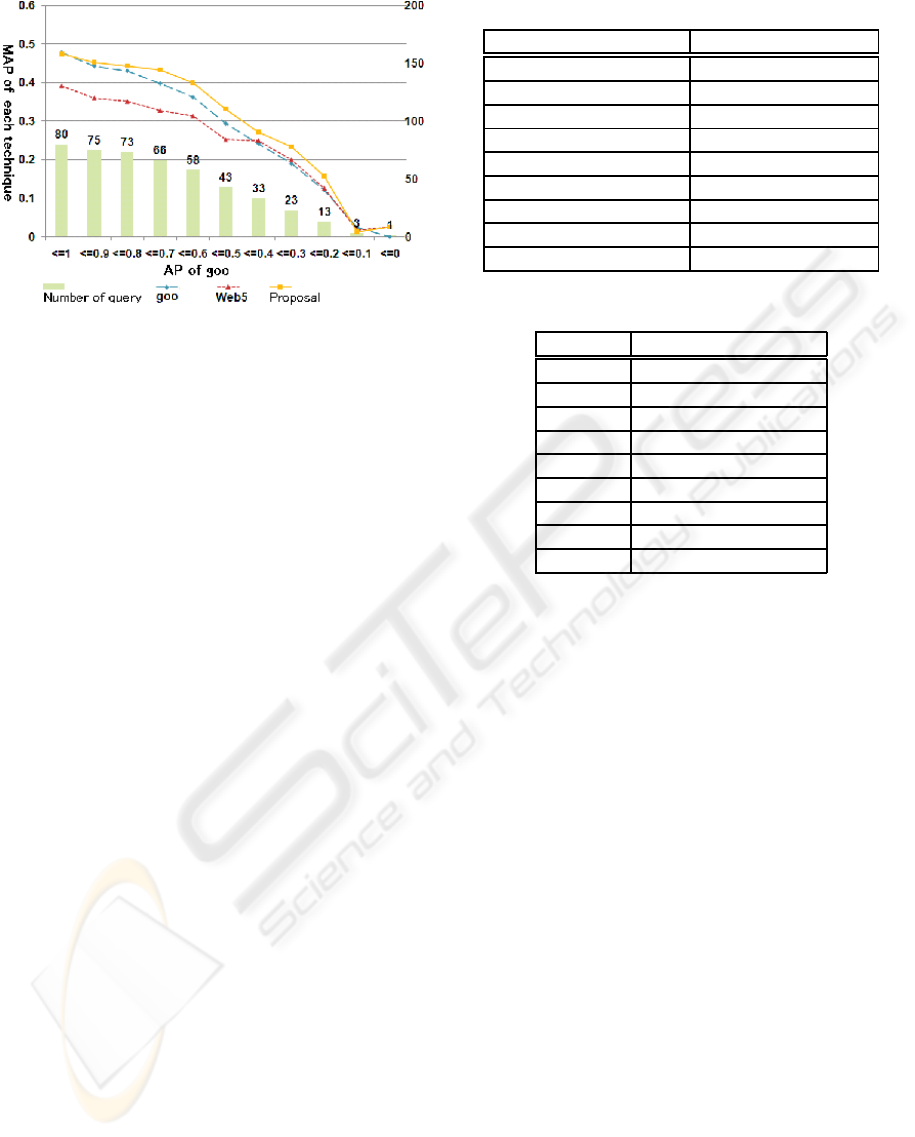
Figure 3: MAP for each AP of Goo.
having AP of less than 0.2 represents the accuracy of
the method when Goo gives poor results, and that any
MAP value for those queries having AP of less than
1.0 represents the overall accuracy of each method.
When Goo’s AP is high, or the initial retrieval re-
sult is satisfactory for a user, the accuracy will hardly
be improved. This is because adding a word to a very
good query would not change the initial result, or even
worse, degrade the result. As Goo’s AP decreases, the
accuracy of our method increases and becomes higher
than that of Goo. This demonstrates that the query
augmented by our method can reflect more clearly the
users intention of the retrieval than the initial query
does. The more accurate query is issued, the more
unnecessary information is excluded from the result.
Note also that many good related words can be ex-
tracted for informational queries, as a result of the
fact that Wikipedia is a kind of encyclopedia. On the
other hand, in another experiment where queries are
not classified, our method shows poorer results. Al-
though our method shows poor accuracy also for the
data where Goo’s AP is less than 0.1, we think it is
just deviation due to too small number of the test set.
8 DISCUSSION
A function similar to our related word presentation is
provided by Google. This is based on the retrieval
records of all users in the world. We compare the
related words given by Goole and those obtained by
our method.
Table 4 shows the results for the query “iPS cell”
for which a Japanese researcher won the Lasker prize
and was much taken about. Google shows up words
like Kyoto University and Yamanaka, who is the win-
ner of the Novel prize, as the related words for the
query word “iPS cell”. These words are just tempo-
Table 4: query:iPS cell.
Google Proposal
Problem Gene
Patent Establishment
wiki Group
Kyoto University Embryonic stem cell
Regenerative medicine Mouse
Nobel prize Success
Yamanaka Possible
Bayer Human
Embryonic stem cell introduce
Table 5: query:NP complete problem.
Google Proposal
Example Class NP
Polynomial
NP difficult
possible to return
Satisfiability problem
possible to reduce
Discovery
Theorem
Cook
rary. On the other hand, our method give words that
are more technical and relevant to the essential mean-
ing of the query word. As for another example, ta-
ble 5 shows the results for the query “NP complete
problem”, which is well known to people from the
engineering field whereas unfamiliar to ordinal peo-
ple. Google shows up just a single word as its related
word. This is because few people give the query to
Google, and the retrieval records are too small to ex-
tract related words. On the other hand, our method
can provide many related words since Wikipedia has
a good text concerning the NP complete problems.
9 CONCLUSIONS
Using Wikipedia as a source of relevant documents,
better words can be extracted compared to those ob-
tained by using retrieval results of conventionalsearch
engines like Goo. The results of our system would
be much better from the viewpoint of user in acquir-
ing knowledge. Also, compared to the related words
recommendation by Google, better words can be ex-
tracted especially when the initial keyword itself is
seldom used for a query, or it is just temporarily used
in a specific topic. This is because Google depends on
the record obtained from a large number of retrieval
results for anonymous people, whereas ours are based
ICAART 2010 - 2nd International Conference on Agents and Artificial Intelligence
198

on information that is more specific to the user.
This time, the extraction of the related word was
limited only to Japanese because we had experi-
mented by using goo, Mecab, and Japanese version
Wikipedia. In order to implement it with other lan-
guages, it is necessary to use Google as a search
engine, and also a morphological analysis tool and
Wikipedia for the other language being targeted.
Moreover, the algorithm used is designed based on
the feature of a Japanese syntax. So, when ap-
plying to other languages, we need the adjustment
of the parameters or the other algorithms such as
Strube(Strube.M and Ponzetto.S, 2006).
We are going to implement a user friendly inter-
face such that the user can retrieve by choosing the
related words offered by the system, and collect eval-
uation results.
In future research, we are going to give attention
to another characteristic of Wikipedia that it tends to
drive users to other area of interest as he/she goes
through the text in it. This will open up a new appli-
cation of the related word extraction method to some
kind of knowledge discovery.
ACKNOWLEDGEMENTS
This work was supported by KAKENHI(21500102).
REFERENCES
Broder, A. (2002). A taxonomy of web search. In SIGIR
Forum Vol.36,No.2. SIGIR.
Fujii, A. (2007). Modeling anchor text and classifying
queries in web retrieval. In internet conference2007.
in Japanese.
Ito, M., Nakayama, K., Hara, T., and Nishio, S. (2008).
A consideration of association thesaurus construction
based on link co-occurrence analysis considering sen-
tences. In DEWS2008. IEICE. in Japanese.
Kuramoto, S., Hasegawa, R., Fujita, H., Koshimura, M.,
and Mine, T. (2007). A method for query expan-
sion using the related word extraction algorithm. In
JAWS2007. SIG-ICS. in Japanese.
Mano, H., Itoh, H., and Ogawa, Y. (2003). Ranking re-
trieval in document retrieval. In Ricoh Technical Re-
port No.29. Ricoh. in Japanese.
Masada, T., Kanazawa, T., Takasu, A., and Adachi, J.
(2005). Improving web search by query expansion
with a small number of terms. In NTCIR-5 Workshop
Meeting. NTCIR. in Japanese.
Murata, N., Toda, H., Matsuura, Y., and Kataoka, R. (2008).
A query expansion method using access concentration
sites in search resul. In DBSJ Letters Vol.6, No.4,
pp.45-48. in Japanese.
Oishi, T., Kuramoto, S., Mine, T., Hasegawa, R., Fujita, H.,
and Koshimura, M. (2008). A method of query gener-
ation using the related word extraction algorithm. In
IPSJ SIG Notes 2008(56) pp.33-40. IPSJ. in Japanese.
Page, L. and Lopes, J. (1998). The pagerank citation rank-
ing: Bringing order to the web. In Technical Report.
Stanford University.
Qiu, F. and Cho, J. (2006). Automatic identification of
user interest for personalized search. In International
World Wide Web Conference. ACM.
Robertson, S. (1990). On term selection for query expan-
sion. In Journal of Documentation, 46, 4, pp. 359-364.
Sieg, A., Mobasher, B., and Burke., R. (2007). Web search
personalization with onotological user profiles. In In
Proc. of CIKM ’07. CIKM.
Strube.M and Ponzetto.S (2006). Wikirelate! computing se-
mantic relatedness using wikipedia. In AAAI pp.1419-
1424.
Thomas, C. (2006). An empirical examination of
wikipedia’s credibility. In First Monday.
Yoshinori, H. (2004). User profiling technique for infor-
mation recommendation and information filtering. In
Journal of Japanese Society for Artificial Intelligence
19(3) pp.365-372. JSAI. in Japanese.
RELATED WORD EXTRACTION FROM WIKIPEDIA FOR WEB RETRIEVAL ASSISTANCE
199
