
UPDATABLE ISLAND REASONING FOR ALCHI-ONTOLOGIES
Sebastian Wandelt and Ralf Moeller
Institute of Software Systems, Hamburg University of Technology, Harburger Schlossstrasse 20, Hamburg, Germany
Keywords:
Description Logics, Reasoning, Scalability, Partitioning.
Abstract:
In the last years, the vision of the Semantic Web fostered the interest in reasoning over ever larger sets of
assertional statements in ontologies. It is easily conjectured that, soon, real-world ontologies will not fit into
main memory anymore. If this was the case, state-of-the-art description logic reasoning systems cannot deal
with these ontologies any longer, since they rely on in-memory structures.
We propose a way to overcome this problem by reducing instance checking for an individual in an ontology to
a (usually small) relevant subsets of assertional axioms. These subsets are computed based on a partitioning-
criteria. We propose a way to preserve the partitions while updating an ontology and thus enable stream like
reasoning for description logic ontologies. We think that this technique can support description logic systems
to deal with the upcoming large amounts of fluctuant assertional data.
1 INTRODUCTION
As the Semantic Web evolves, scalability of inference
techniques becomes increasingly important. Even for
basic description logic-based inference techniques,
e.g. instance checking, it is only recently understood
on how to perform reasoning on large ABoxes in an
efficient way. This is not yet the case for problems
that are too large to fit into main memory.
In this paper we present an approach to execute
efficient retrieval tests on ontologies, which do not fit
into main memory. Existing tableau-based descrip-
tion logic reasoning systems, e.g. Racer (Haarslev
and M
¨
oller, 2001), do not perform well in such sce-
narios since the implementation of tableau-algorithms
is usually built based on efficient in-memory struc-
tures. Our contribution is concerned with the fol-
lowing main objective: we want to partition the as-
sertional part of an ALC H I -ontology to more ef-
ficiently answer queries over partitions, instead of
the complete ABox. The idea is to split up redun-
dant/unimportant role assertions and then partition the
ABox based on individual connectedness.
Moreover, we focus on the problem of updating
ontologies. The idea is that a partitioning does not
need to be computed from the scratch whenever the
underlying ontology is changed. To solve that, we
propose partitioning-preserving transformations for
each possible syntactic update of an ontology (termi-
nological and assertional updates). We are convinced
that such an incremental approach is crucial to enable
stream-like processing of ontologies.
The remaining parts of the paper are structured as
follows. Section 2 introduces necessary formal no-
tions and gives an overview over Related Work. In
Section 3 we introduce the underlying partitioning
algorithm, and propose our partitioning-preserving
transformations in Section 4 (assertional updates) and
in Section 5 (terminological updates). We present our
preliminary implementation and evaluation in Section
6. The paper is concluded in Section 7.
Please note that all details, lemmata and proofs of
our paper can be found in an accompanying techni-
cal report(Nguyen, 2009). The present paper is rather
intended to give a general overview of our results so
far.
2 FOUNDATIONS
2.1 Description Logic ALC H I
We briefly recall syntax and semantics of the descrip-
tion logic ALC H I . For the details, please refer to
(Baader et al., 2007). We assume a collection of dis-
48
Wandelt S. and Moeller R. (2009).
UPDATABLE ISLAND REASONING FOR ALCHI-ONTOLOGIES.
In Proceedings of the International Conference on Knowledge Engineering and Ontology Development, pages 48-55
DOI: 10.5220/0002298700480055
Copyright
c
SciTePress

Figure 1: Guiding Example: ABox A
EX
for ontology O
EX
.
joint sets: a set of concept names N
CN
, a set of role
names N
RN
and a set of individual names N
I
. The
set of roles N
R
is N
RN
∪ {R
−
|R ∈ N
RN
}. The set of
ALC H I -concept descriptions is given by the follow-
ing grammar:
C, D ::=>|⊥|A|¬C|C u D|C t D|∀R.C|∃R.C
Where A ∈ N
CN
and R ∈ N
R
. With N
C
we denote
all atomic concepts, i.e. concept descriptions which
are concept names. For the semantics please refer to
(Baader et al., 2007).
A TBox is a set of so-called generalized concept
inclusions(GCIs) C v D. A RBox is a set of so-called
role inclusions R v S. An ABox is a set of so-called
concept and role assertions a : C and R(a,b). A on-
tology O consists of a 3-tuple hT ,R ,Ai, where T is
a TBox, R is a RBox and A is a ABox. We restrict
the concept assertions in A in such a way that each
concept description is an atomic concept or a negated
atomic concept. This is a common assumption, e.g.
in (Guo and Heflin, 2006), when dealing with large
assertional datasets in ontologies.
In the following we define an example ontology,
which is used throughout the remaining part of the pa-
per. The ontology is inspired by LUBM (Guo et al.,
2005), a benchmark-ontology in the setting of univer-
sities. Although this is a synthetic benchmark, sev-
eral (if not most) papers on scalability of ontological
reasoning consider it as a base reference. We take a
particular snapshot from the LUBM-ontology (TBox,
RBox and ABox) and adapt it for presentation pur-
poses. Please note that we do not claim that our snap-
shot is representative for LUBM.
Example 2.1. Let O
EX
= hT
EX
,R
EX
,A
EX
i, s.t.
T
EX
={
Chair ≡ ∃headO f.Department uPerson,Pro f essor v Faculty,
Book v Publication,
GraduateStudent v Student, Student ≡ Person u ∃takesCourse.Course,
> v ∀teacherO f .Course,∃teacherO f .> v Faculty,Faculty v Person,
> v ∀publicationAuthor
−
.(Book tCon f erencePaper)
}
R
EX
={headO f v worksFor,worksFor v memberO f ,memberO f
.
= member
−
}
A
EX
=see Figure 1
2.2 Related Work
Referring to Example 2.1, different kinds of partition-
ings can be, informally, summarized as follows:
• Naive partitioning: This partitioning is done in ex-
isting reasoning systems. The idea is that individ-
uals end up in the same partition, if there is a path
of role assertions connecting them. Usually many
individuals are connected to most other individu-
als in an ontology. This basic partitioning strategy
is often not enough. In our LUBM-example there
is only one partition, since each named individual
is connected via a path to each other named indi-
vidual.
• Extension in (Guo and Heflin, 2006): Since
suborganizationO f and teachingAssistentO f are
the only roles, which are not bound in a ∀-
constraint in T
EX
(please note that takesCourse
occurs indirectly in a ∀-constraint when the def-
inition of student is split up into two inclusions),
there are three partitions:
1. one partition containing university u1,
2. one partition containing graduate student g1
and
3. one partition containing all remaining individ-
uals
• Our proposal: a more fine-grained partitioning
(details see below). For example, the only sub-
concepts, which can be propagated over the role
teacherO f are ⊥ and Course. Now, since for
role assertion teacherO f (p1, c1), c1 is an explicit
instance of Course, i.e. the propagation is re-
dundant, we can informally speaking “split up”
the assertion to further increase granularity of
connectedness-based partitioning.
There exists further related work on scalable reason-
ing. In (Fokoue et al., 2006), the authors suggest a
scalable way to check consistency of ABoxes. The
idea is to merge edges in an ABox whenever consis-
tency is preserved. Their approach is query dependent
UPDATABLE ISLAND REASONING FOR ALCHI-ONTOLOGIES
49

and, informally speaking, orthogonal to partitioning
approaches.
Several papers discuss the transformation of an
ontology into datalog, e.g. (Motik et al., 2002), or
the use of novel less-deterministic hypertableau algo-
rithms(Motik et al., 2007), to perform scalable rea-
soning. Furthermore, (Stuckenschmidt and Klein,
2004) suggests to partition the terminological part of
an ontology, while we focus on the assertional part.
After all, we think that our work can be seen as
complementary to other work, since it can be easily
incorporated into existing algorithms. Furthermore
we are unique in focusing on updating partitions to
support stream-like processing.
3 ONTOLOGY PARTITIONING
We have initially proposed a method for role asser-
tion separability checking in (Wandelt and Moeller,
2008). For completeness we start with one definition
from (Wandelt and Moeller, 2008). The definition of
O-separability is used to determine the importance of
role assertions in a given ABox. Informally speak-
ing, the idea is that O-separable assertions will never
be used to propagate “complex and new information”
(see below) via role assertions.
Definition. Given an ontology O = hT , R ,Ai, a role
assertion R(a,b) is called O-separable, if we have
O is inconsistent ⇐⇒ hT ,R ,A
2
}i is inconsistent,
where
A
2
= A \ {R(a, b)} ∪ {R(a,i
1
),R(i
2
,b)}∪
{i
1
: C|b : C ∈ A} ∪ {i
2
: C|a : C ∈ A},
s.t. i
1
and i
2
are fresh individual names.
Now, we further extend our proposal by
partitioning-preserving update transformations. To d
so, we define a notion of ABox and Ontology parti-
tioning, which will be used in our update transforma-
tions below.
Definition. Given an ontology O = hT ,R ,Ai, an
ABox Partition for A is a tuple AP = hIN,Si such that
• IN ⊆ Inds(A) and
• S = {a : C|a ∈ M ∧ a : C ∈ A} ∪ {R(a, b)|(a ∈
IN ∨ b ∈ IN) ∧ R(a,b) ∈ A},
where M = {a|b ∈ IN ∧ (R(a,b) ∈ A ∨ R(b,a) ∈
A)} ∪ IN
We define two projection functions to obtain the
first and the second element in a partition-pair: let
π
IN
(AP) = IN, and π
S
(AP) = S. Informally speaking,
an ABox Partition is composed of two components.
The individual set IN, which contains the core
individuals of the partition, and the assertion set S
containing all the assertions needed in the partition.
If a is an individual in IN, then S contains all the
assertions involving a and all the concept assertions
involving all direct neighbours of a.
Definition. Given an ontology O = hT ,R ,Ai, an
ABox Individual Partitioning for A is a set P =
{ap
1
,.., ap
n
}, such that each ap
i
is an ABox Partition
for A and
1. For each ap
i
, ap
j
, (i 6= j) we have π
IN
(ap
i
) ∩
π
IN
(ap
j
) =
/
0
2. Ind(A) =
S
i=1..n
π
IN
(ap
i
)
3. A =
S
i=1..n
π
S
(ap
i
)
The definition states that all the partitions have
distinct core individual sets, the union of all the core
individual sets of all the partitions is exactly the indi-
vidual set of A, and the union of all the assertion sets
of all the partitions is the assertion set of A.
Since each individual is assigned to only one ABox
partition as a core individual, we define a function
φ
P
: Ind(A) → P that returns the partition for a given
individual a. If a /∈ Ind(A), then φ
P
(a) =
/
0. Next we
will define the partitioning for the ontology.
Definition. Given a consistent ontology
O = hT ,R ,Ai, an Ontology Partitioning for O
is a structure OP
O
= hT , R ,Pi, where P is an ABox
Partitioning for A such that for each individual
a ∈ Ind(A) and each atomic concept C we have
O a : C iff hT ,R ,π
S
(φ
P
(a))i a : C.
We use the O-separability, see (Wandelt and Moeller,
2008), of role assertions to determine the partitioning
of A. From the previous section, it holds that with the
partitioning an ABox based on the O-separability of
role assertions, the instance checking problem can be
solved with only one partition.
4 UPDATING THE ABOX
In this section, we will introduce means to preserve
a partitioning of an ontology under Syntactic ABox
Updates(Halashek-wiener et al., 2006). With syntac-
tic updates, there is no consistency checking when
adding a new assertion, and neither an enforcement
of non-entailment when removing. However, syntac-
tic updates are computationally easier to handle.
The general scenario for updating an ABox is as
follows: We assume to start with an empty ontology
(which has no assertions in the ABox), and its corre-
sponding partitioning. Then we build up step by step
KEOD 2009 - International Conference on Knowledge Engineering and Ontology Development
50

the partitioned ontology by use of our update trans-
formations.
For an empty ontology O = hT , R , {}i, the cor-
responding partitioning is OP
O
= hT ,R ,Pi where
P = {h{},{}i}. In the following we will use two up-
date functions, merge and reduce, to implement our
update transformations:
Definition. The result of the merge operation on a
set of ABox Partitions for A, Merge({ap
1
,.., ap
n
}),
is defined as the ABox Partition ap for A, s.t.
ap = h
S
i≤n
π
IN
(ap
i
),
S
i≤n
π
S
(ap
i
)i
Definition. The result of the reduce operation on an
ABox Partition for A, Reduce(pa), is defined as a set
of ABox Partition {ap
1
,.., ap
n
} built as follows:
1. For each R(a,b) ∈ π
S
(ap) do: if R(a,b)
is O-separable, then replace R(a,b) with
{R(a,b∗), R(a∗,b)} ∪ {a∗ : C|a : C ∈
π
S
(ap)} ∪ {b∗ : C|b : C ∈ π
S
(ap)}, where
a∗ and b∗ are fresh individual names for a and b.
2. Let {ap
1
,.., ap
n
} be the disconnected partitions in
ap.
3. Replace each a∗ in each ap
i
by a.
4. Replace each b∗ in each ap
i
by b.
The merge operation simply merges all the core
individual sets and the assertion sets of all the parti-
tions. The reduce operation, in the other hand, divides
an ABox Partition into smaller partitions based on O-
separability of role assertions.
The algorithm for updating ABoxes is illustrated
in Figure 2. It can be informally summarized as fol-
lows:
Adding a role assertion R(a,b): first we ensure that
partitions exist for both a and b (if not, create a new
partition). If a and b are in the same partition, then
the role assertion is just simply added to the partition.
If a and b are in two distinct partitions, and R(a, b) is
not O-separable, then the two partitions are merged.
Removing a role assertion R(a,b): if a and b are in
different partitions, then the role assertion is just sim-
ply removed from both partitions. If a and b are in
the same partition, then after removing the role asser-
tion the partition needs to be rechecked to see if the
removal of the role assertion causes the partition to be
reduce-able.
Adding a concept assertion C(a): first we ensure that
partition exists for individual a. Then we add concept
assertion C(a) to the partition of a (φ
P
(a)), and all
the partitions that contain any role assertion for a, to
maintain the data consistency between partitions.
Removing a concept assertion C(a): remove the con-
cept assertion from all the partitions containing it. Af-
ter that, all the role assertion involving a need to be
O-separability checked. If any of the role assertions
becomes O-inseparable due to the removal, then the
corresponding partitions need to be merged.
5 UPDATING THE TBOX
In the following, we give a rough sketch of the update
transformations. For details please refer to our tech-
nical report (Nguyen, 2009). We extend the definition
of the ∀-info structure from (Wandelt and Moeller,
2008), by introducing a reduced ∀-info structure and
an extended ∀-info structure.
Definition. A reduced ∀-info structure for ontology
O is a function e
∀
O
which is extend from ∀-info struc-
ture f
∀
O
such that for every role R:
e
∀
O
(R) = f
∀
O
(R)\{C
k
|∃C ∈ f
∀
O
: C @ C
k
}
Definition. An extended ∀-info structure for ontol-
ogy O is a function g
∀
O
which is extended from re-
duced ∀-info structure e
∀
O
as following:
• If e
∀
O
(R) = ∗ then g
∀
O
(R) = {h∗,∗i}
• Else If e
∀
O
(R) =
/
0 then g
∀
O
(R) = {h
/
0,
/
0i}
• Else g
∀
O
(R) = {hC
i
,Sub(C
i
)i}, with C
i
∈ e
∀
O
(R),
and Sub(C
i
) is the set of all the concepts that C
i
subsumes in the simple concept hierarchy H
S
.
We also denote π
C
(g
∀
O
(R)) ≡ {C
i
}, the set of all
C
i
appears in {hC
i
,Sub(C
i
)i} (which is e
∀
O
(R)); and
π
Sub,C
i
(g
∀
O
(R)) ≡ Sub(C
i
).
Informally speaking, the reduced ∀-info structure
contains only the bottommost concepts of the concept
hierarchy branches that appears in f
∀
O
, w.r.t. the sim-
ple concept hierarchy. On the other hand, an entry in
the extended ∀-info structure is a set, each element of
which is a tuples of a concept in e
∀
O
and the set of all
the children of that concept, w.r.t. the concept hierar-
chy.
Updating ABox assertions can lead to the merg-
ing/reducing involving one or two specific partitions
identified by the individuals in the updated assertions,
while updating in TBox and RBox rather causes the
merging/reducing in many pairs of partitions involv-
ing a certain set of role names. More formally speak-
ing, updating w.r.t TBox and RBox can affects a set
of role U
R
, such that for each R ∈ U
R
, and all indi-
vidual pairs {a,b},s.t.R(a,b) ∈ A, the status of the
role assertion R(a, b) might be changed (O-separable
to O-inseparable or vice versa). We call this role set
U
R
the changeable role set, and each R ∈ U
R
change-
able role.
We have derived the following algorithm for up-
dating a TBox and a RBox:
UPDATABLE ISLAND REASONING FOR ALCHI-ONTOLOGIES
51

Figure 2: Updating ABox.
• For each role R in new terminology T ∗, calculate
g
∀
O
(R) before updating and g
∀
O∗
(R) after updating.
– If(g
∀
O
(R) 6= g
∀
O
∗ (R)) then U
R
= U
R
∪ R
• For each R ∈ U
R
, and for each R(a,b):
– If R(a, b) is O-separable but not O∗-
separable then P = P\{φ
P
(a),φ
P
(b)} ∪
Merge(φ
P
(a),φ
P
(b))
– If R(a,b) is not O-separable but O∗-separable
then P = P\φ
P
(a) ∪ Reduce(φ
P
(a))
(*) O∗-separable is denoted for separable with respect to the new
ontology (after update), while O-separable is denoted for separable with
respect to the old ontology.
In the following, we will consider specific cases
of updating TBox, and the effects they make to the
extended ∀-info structure, and by this, compute the
changeable role set. Then, in case of a terminological
update, we have to check all role assertions, whose
role is an element of the changeable role set, for O-
separability.
5.1 Updating TBox - Concept Inclusions
Updating TBox by adding/removing a concept inclu-
sion might causes changes to g
∀
O
because
• if the concept inclusion adds A v B to the Con-
cept Hierarchy H
S
, and since the extended ∀-info
structure g
∀
O
is built based on H
S
, there probably
have changes in g
∀
O
.
• if the SNF, see (Wandelt and Moeller, 2008) for
details, of the added concept inclusion contains
one or more ∀-bound for a role R that doesn’t
existed in the old terminology (or does not exist
in updated terminology in case of removing con-
cept inclusion), then there is changes in the ∀-info
structure of the terminology, which also probably
causes changes in the extended ∀-info structure.
Thus, instead of recalculating the extend ∀-info struc-
ture, if we know that the update is of a concept inclu-
sion, then we just need to extract the infomation from
the added/removed concept inclusion itself to check if
it will cause changes in the g
∀
O
.
Before go into details how to decide the update role
set from the added/ removed concept inclusion, we
introduce some useful definitions.
KEOD 2009 - International Conference on Knowledge Engineering and Ontology Development
52
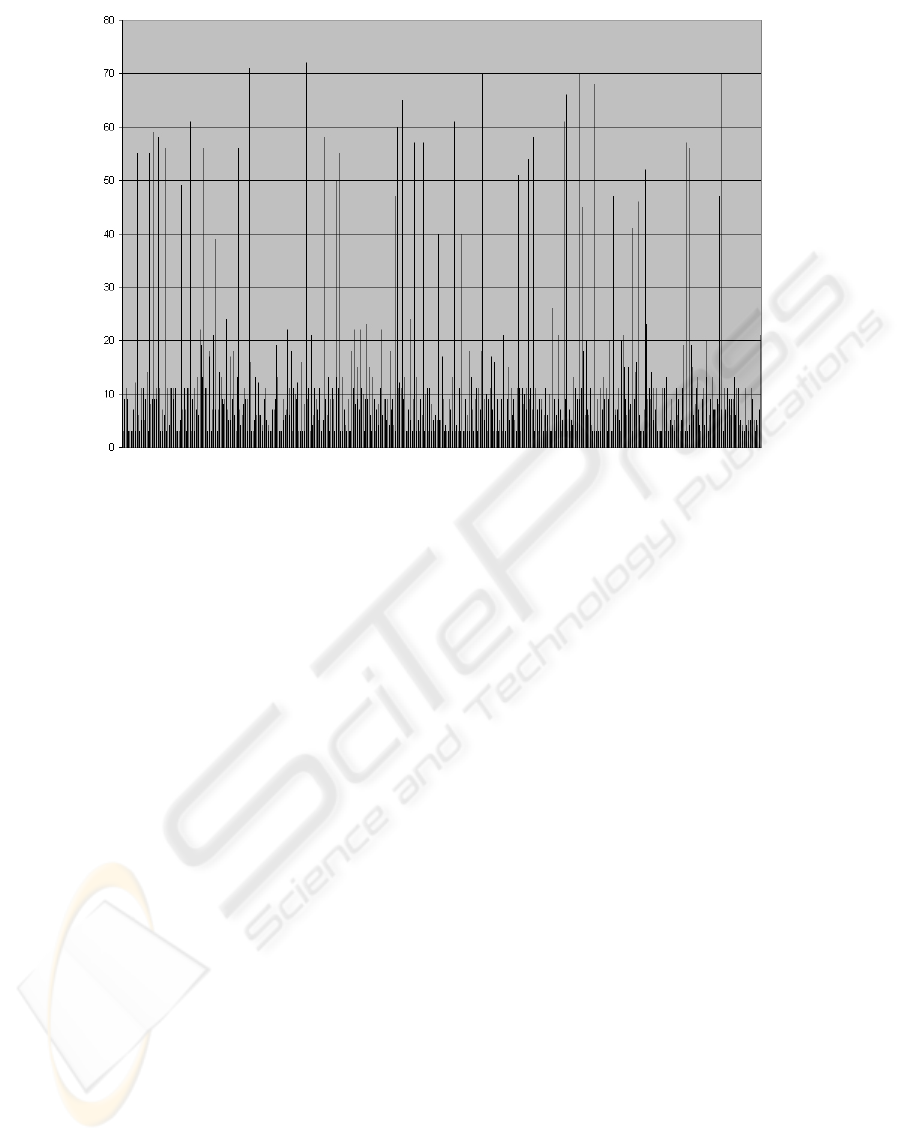
Figure 3: Assertion distribution among partitions in node 1 (3 nodes).
Definition. A ∀-info structure for a concept inclusion
C v D w.r.t O, written as f
∀
CvD,O
, is a function that
assigns to each role name R in SNF(C v D) one of
the following entries:
•
/
0 if we know that there is no ∀ constraint for R in
SNF(C v D).
• a set S of atomic concept or negation atomic con-
cept, s.t. there is no other than those in S that oc-
curs ∀-bound on R in SNF(C v D).
• ∗, if there are arbitrary complex ∀ constraints on
role R in SNF(C v D).
This definition is literally similar to the definition of
the ∀-info structure stated before, but for only one ax-
iom. From this, we also define the reduced ∀-info
structure for a concept inclusion w.r.t. ontology O and
extended ∀-info structure for a concept inclusion w.r.t.
ontology O in the same manner
Definition. A reduced ∀-info structure for a concept
inclusion C v D w.r.t. ontology O is a function e
∀
CvD,O
which is extend from ∀-info structure f
∀
CvD,O
such
that for every role R:
e
∀
CvD,O
(R) = f
∀
CvD,O
(R)\{C
k
|∃C ∈ f
∀
CvD,O
: C @ C
k
}
Definition. An extended ∀-info structure for a con-
cept inclusion C v D w.r.t. ontology O is a function
g
∀
CvD,O
which is extended from reduced ∀-info struc-
ture e
∀
CvD,O
as following:
• If e
∀
CvD,O
(R) = ∗ then g
∀
CvD,O
(R) = {h∗,∗i}
• Else If e
∀
CvD,O
(R) =
/
0 then g
∀
CvD,O
(R) = {h
/
0,
/
0i}
• Else g
∀
CvD,O
(R) = {hC
i
,Sub(C
i
)i}, with C
i
∈
e
∀
CvD,O
(R), and Sub(C
i
) is the set of all the con-
cepts that C
i
subsumes in the simple concept hier-
archy H
S
.
And we have the following detailed algorithm
for calculating the update role set in case of
adding/removing a concept inclusion:
• Adding a concept inclusion C v D
– For each A v B that is added to the concept hi-
erarchy:
∗ for any role R that B ∈ g
∀
O
(R), U
R
= U
R
∪ R
– For each R s.t. g
∀
CvD,O∗
(R) 6=
/
0 ∧g
∀
CvD,O∗
(R) *
g
∀
O
(R), U
R
= U
R
∪ R
• Removing a concept inclusion C v D
– For each A v B that is removed to the concept
hierarchy:
∗ for any role R that B ∈ g
∀
O
(R), U
R
= U
R
∪ R
– For each R s.t. g
∀
CvD,O∗
(R) 6=
/
0 ∧g
∀
CvD,O∗
(R) *
g
∀
O∗
(R), U
R
= U
R
∪ R
Here, we denote with O the ontology before updating
and with O∗ the ontology after updating.
5.2 Updating RBox - Role Inclusions
Adding/removing a role inclusion has a quite obvious
effect: it might change the role hierarchy. Since the ∀-
info structure of the ontology is calculated using role
taxonomy, this will change the ∀-info structure, and
UPDATABLE ISLAND REASONING FOR ALCHI-ONTOLOGIES
53

Table 1: Partitions and assertions distribution among 3 nodes.
Node Total Partitions Total Assertions Assertions/partition min max
1 518 6089 11.7548 3 72
2 518 6822 13.1699 3 1596
3 518 5702 11.0077 3 77
Table 2: Partitions and assertions distribution among 6 nodes.
Node Total Partition Total Assertion Assertion/partition min max
1 260 2989 11.4962 3 70
2 259 4129 15.9421 3 1596
3 259 2864 11.0579 3 77
4 258 3100 12.0155 3 72
5 259 2693 10.3977 3 76
6 259 2838 10.9575 3 74
also the extended ∀-info structure. In the following,
we present a way to determine the update role set
• Adding a role inclusion R v S
– if g
∀
O
(S) * g
∀
O
(R) then for all sub role V of R
(V v R), U
R
= U
R
∪V
• Removing a role inclusion R v S
– if g
∀
O
(S) * g
∀
O∗
(R) then for all sub role V of R
(V v R), U
R
= U
R
∪V
5.3 Updating RBox - Role Inverses
Adding/removing a role inverse, on the other hand,
might change the ∀-bound for both roles involving the
inverse role. This causes the changes for the ∀-info
structure of both roles, which also alters their extend
∀-info structure, thus we have following algorithm for
calculating update role set:
• Adding a role inverse pair R = Inv(S)
– for all role V v R, U
R
= U
R
∪V
– for all role W v S, U
R
= U
R
∪W
• Removing a role inverse pair R = Inv(S)
– for all role V v R, U
R
= U
R
∪V
– for all role W v S, U
R
= U
R
∪W
6 DISTRIBUTED STORAGE
SYSTEM AND PRELIMINARY
EVALUATION
We have implemented the above algorithms in a Java
program and performed initial tests on LUBM. The
first test is composed of a server and 3 nodes. For
the system performance, our test program was able to
load 400-500 LUBM-ABox/TBox assertions per sec-
ond. This is just an average value. From our expe-
rience, ABox assertions turn out to be loaded much
faster, while TBox assertions slow the system down.
The reasons for that behaviour have already been in-
dicated above.
Besides system performance, another factor we
want to evaluate is the distribution of the data among
nodes. The data collected using three nodes is shown
in Table ??. It is easy to see that the number of parti-
tions in the 3 nodes are somehow equally distributed.
Figure 3 illustrates the distribution of the asser-
tions in the partitions on the first node. As shown in
the figure, the number of assertions is quite different
between partitions. These differences actually illus-
trate the structure of the test data.
We also ran the testing with four, five and six
nodes to collect distribution data. The distribution
is somehow similar to the case of 3 nodes. Table 2
listed the data collected for six nodes. The data dis-
tribution in our test is somehow nice, with the equally
distribution of the partitions among nodes. However,
this is the result of some synthetic benchmark data,
which does not introduce many merging between par-
titions. Running our algorithm on more complex data,
the partition allocation policy can be a critical factor
deciding the system performance.
7 CONCLUSIONS
We have introduced means to reason over ALC H I -
ontologies, which have large amounts of assertional
information. Our updatable partitioning approach al-
lows state-of-the-art description logic reasoner to load
only relevant subsets of the ABox to perform sound
KEOD 2009 - International Conference on Knowledge Engineering and Ontology Development
54

and complete reasoning. In particular, we have pro-
posed a set of partitioning-preserving update trans-
formations, which can be run on demand. Our tech-
niques are being incorporated into the description
logic reasoner RACER(Haarslev and M
¨
oller, 2001),
to enable more scalable reasoning in the future.
In future work, we will investigate the applica-
bility of our proposal to more expressive description
logics, e.g. SHIQ. The extension for transitive roles
is straightforward. The incorporation of min/max-
cardinality constraints in a naive way can be done as
well. However, it has to be investigated, whether the
average partition size with these naive extensions is
still small enough to be feasible in practice. Further-
more, we intend to perform more evaluation on real-
world ontologies to provide detailed timing statistics.
Especially the case of boot strapping the assertional
part of an ontology needs further investigation.
REFERENCES
Baader, F., Calvanese, D., McGuinness, D. L., Nardi, D.,
and Patel-Schneider, P. F. (2007). The Description
Logic Handbook. Cambridge University Press, New
York, NY, USA.
Fokoue, A., Kershenbaum, A., Ma, L., Patel, C., Schonberg,
E., and Srinivas, K. (2006). Using Abstract Evalua-
tion in ABox Reasoning. In SSWS 2006, pages 61–74,
Athens, GA, USA.
Guo, Y. and Heflin, J. (2006). A Scalable Approach for
Partitioning OWL Knowledge Bases. In SSWS 2006,
Athens, GA, USA.
Guo, Y., Pan, Z., and Heflin, J. (2005). Lubm: A benchmark
for owl knowledge base systems. J. Web Sem., 3(2-
3):158–182.
Haarslev, V. and M
¨
oller, R. (2001). Description of the racer
system and its applications. In Proceedings Inter-
national Workshop on Description Logics (DL-2001),
Stanford, USA, 1.-3. August, pages 131–141.
Halashek-wiener, C., Parsia, B., and Sirin, E. (2006).
Description logics reasoning with syntactic updates.
In In Proc. of the 5th Int. Conf. on Ontologies,
Databases, and Applications of Semantics (ODBASE
2006. Sringer Verlag.
Motik, B., Oberle, D., Staab, S., Studer, R., and Volz, R.
(2002). Kaon server architecture. WonderWeb Deliv-
erable D5. http://wonderweb.semanticweb.org.
Motik, B., Shearer, R., and Horrocks, I. (2007). Optimized
reasoning in description logics using hypertableaux.
In Pfenning, F., editor, CADE, volume 4603 of Lecture
Notes in Computer Science, pages 67–83. Springer.
Nguyen, A. N. (2009). Distributed storage system
for description logic knowledge bases. In Tech-
nical Report. http://www.sts.tu-harburg.de/ wan-
delt/research/NgocThesis.pdf.
Stuckenschmidt, H. and Klein, M. (2004). Structure-based
partitioning of large class hierarchies. In International
Semantic Web Conference.
Wandelt, S. and Moeller, R. (2008). Island reasoning for
alchi ontologies. In Eschenbach, C. and Grninger,
M., editors, FOIS, volume 183 of Frontiers in Arti-
ficial Intelligence and Applications, pages 164–177.
IOS Press.
UPDATABLE ISLAND REASONING FOR ALCHI-ONTOLOGIES
55
