
TRUST MODEL FOR HIGH QUALITY RECOMMENDATION
G. Lenzini, N. Sahli and H. Eertink
Telematica Instituut, Brouwerijstraat 1, 7523 XC, Enschede, The Netherlands
Keywords:
Trust Model, Recommendation, Argumentation, Agent.
Abstract:
In this paper, we propose a trust management model for decentralised systems that improves the quality of rec-
ommendations that members of a virtual community get about the trustworthiness of objects. In our system, as
in well-known solutions, members of the community evaluate (i) the functional trust in an item by the analysis
of the object’s qualities, past experience, and recommendations and (ii) the referral trust in a recommender by
the analysis of the recommender’s qualities and reputation based on personal experience. Moreover, in our
trust model, each principal debates with its recommenders about the justifications given to support a recom-
mendation. Thus, the usefulness and the reliability of a recommendation depend also on the strength of the
arguments supporting the recommendation. A measure of this strength results after the member has played an
argumentation game with the recommender. Therefore, the recommendations that are taken into account are
those which better match the member’s profile and way of reasoning. Our trustworthiness evaluation algorithm
is context dependent and able to collect both direct and indirect information about trustees. Our trust model
is part of an agent-based architecture we propose for decentralised virtual communities. This architecture
provides our system with autonomy, unobtrusiveness, user mobility, and context-awareness.
1 INTRODUCTION
A virtual community (also e-community or on-line
community) is a group of socially interacting peo-
ple whose interaction is supported by computer sys-
tems (Preece, 2000). People interact primarily with
e-mails, chats, etc. rather than face to face. One
common application of virtual communities is sharing
opinions about objects of interest, for example rec-
ommendations and ratings. By using opinions, each
member can take a shortcut to items she/he likes with-
out having to try them or to experience many similar
items. Unsurprisingly, this facility has become popu-
lar on the Internet. “Amazon”, for example, rates each
item with stars. This overall rating is obtained by av-
eraging the ratings provided by users on the quality
of the product as a whole. Any member can write a
review. In IENS.nl, a Dutch site for rating restaurants,
and apart from the overall rating of a given restaurant,
a user can also rate/consult a refined set of criteria re-
lated to the restaurant such as quality of food, quality
of service, decor, and price. Such systems (i.e., Ama-
zon, IENS, e-Bay) are mainly centralised; they rely on
all peers’ ratings and give the same recommendations
to all peers. In these systems, the inference process
that leads to a recommendation (either in the form of
a rating or a suggestion) is usually hidden to the user.
It is not possible to perform a qualitative analysis on
the reliability of the suggestion provided nor on the
process that has been used to compose it. It is also
not possible to personalise the ratings w.r.t. the user’s
way of reasoning. As a consequence, a user who is
looking for a recommendation which fits his/her taste
must read a large number of reviews left by the other
users. In fact, she/he has to manually look for justifi-
cations that support the choice which better matches
his/her profile and expectations.
A decentralised approach has thus emerged as
a serious alternative (e.g., see (Sabater and Sierra,
2002; Miller et al., 2004; Teacy et al., 2005)). When
the trustworthiness and the personalisation of recom-
mendations is an issue of great concern, decentralisa-
tion might be more appropriate. In a decentralised ap-
proach the user only relies on recommendations sug-
gested by other peers in whom she/he trusts. We pro-
pose an agent-based decentralised system for trust-
based recommendations which goes farther than pre-
vious decentralised systems. Our system aims at im-
518
Lenzini G., Sahli N. and Eertink H. (2008).
TRUST MODEL FOR HIGH QUALITY RECOMMENDATION.
In Proceedings of the International Conference on Security and Cryptography, pages 518-528
DOI: 10.5220/0001921805180528
Copyright
c
SciTePress

proving the quality of recommendations. Since even
these recommenders could have different tastes and
different ways of judging, being trustworthy is not
enough to have suggestions accepted by the current
peer. Thus, we propose that the peer should also de-
bate with its recommenders about the arguments that
justify a recommendation in order to only select the
most likely appropriate (from this peer’s view point)
recommendations.
In this paper we focus on the argumentation pro-
cess and its impact on the trustworthiness of recom-
mendations. The remainder of the paper is organised
as follows. Section 2 gives an overview of the main
principles of our approach that are behind the qual-
ity of recommendations. Section 3 explains the rules
that model our trust evaluation system with focus on
the argumentation process. Section 4 explains how
to measure the “strength” of a recommendation. Sec-
tion 5 illustrates an example of the use of trust eval-
uation with argumentation. Section 6 presents the
agent-based architecture we propose to support our
trust model. Section 7 comments the related work and
Section 8 concludes the paper and points out the fu-
ture work.
2 OUR APPROACH
In (Lenzini et al., 2008) we presented a preliminary
solution to improve the quality of recommendations
in mobile and non-mobile open virtual communities.
A community is hosted in what we call a Virtual
Agora (in short, VA). A VA is a virtual open space
(e.g., web site, server) where active entities (e.g., con-
sumers) meet, interact, and share experiences about
items (e.g., goods, services) of interest. From this
point of view, many services already available match
the definition of a VA (e.g., the mentioned Amazon
and e-Bay). Moreover, a VA satisfies also the follow-
ing characteristics: (i) openness, entities from various
sources can freely join or leave at any time; (ii) decen-
tralisation, no central authority controls entities (but
we admit a certain centralised facility to search for
members, see Section 6), and (iii) persistence, enti-
ties (if desired) can be continuously available. In this
paper, we present an advanced solution for the im-
provement of the quality of recommendations within
a VA. It is based on the following three ideas:
(1) In the VA, each user is represented by a software
agent, called delegate agent, which behaves on
behalf of its user (even when the user is off-line)
(2) Each delegate agent maintains a personal regis-
ter of rated items (Register of Rated Items) and a
personal trust-weighted register of recommenders
(Register of (Un)Trusted Recommenders).
(3) When evaluating the trustworthiness of an item,
a delegate agent accepts only high quality recom-
mendations. The quality of a recommendation de-
pends upon both the referral trust of the source
(from this agent’s point of view) and the measure
of the “strength” of the arguments that support the
recommendation.
We now comment the three aforementioned ideas.
Point (1) concerns the architectural design of a
VA, which is part but not the main goal of this pa-
per. Briefly, peers need autonomy to be able to act on
behalf of their users. To design an effective VA which
fulfils this requirement, we chose an agent-based ar-
chitecture. Each peer is represented by a delegate
agent that once moved to the VA is constantly inter-
acting with the other delegate agents and updating its
user’s registers of trust. More details of the architec-
ture are given in Section 6.
Point (2) concerns the two trust-weighted regis-
ters that each delegate agent uses to evaluate the func-
tional trust on an item and the referral trust on a rec-
ommender. In the register called Register of Rated
Items (in short Trat), an agent keeps trace of the func-
tional trust in the items that it has evaluated so far,
directly (from personal experience), indirectly (re-
ported by other recommenders) or both. In the regis-
ter called Register of (Un)Trusted Recommenders (in
short Trec) an agent keeps trace of its referral trust on
other peers in giving recommendations. The two reg-
isters are initiated and updated according to rules that
are explained in Section 3.
Finally, point (3) regards the quality of recommen-
dation. When a peer (i.e., delegate agent) asks for
recommendations it evaluates the information it re-
ceives according to the referral trust of the source and
to the “appropriateness” of the recommendations with
respect to its profile, taste, and way or reasoning. The
delegate agent reaches this latter goal by “discussing”
with its recommenders about the arguments that they
provide to justify their recommendations. Eventually,
whether or not the agent accepts a recommendation,
depends upon both the warrant of the recommenda-
tion and the referral trust of the recommender. Thus,
“warranted” recommendations coming from not so
trustworthy members may be accepted, whereas “un-
warranted” recommendations coming from trustwor-
thy recommenders might be discarded. We believe
that an opinion built upon a small number of recom-
mendations of high quality is generally more useful
than a digest of anonymous, often contradicting, and
potentially unjustified recommendations.
TRUST MODEL FOR HIGH QUALITY RECOMMENDATION
519

3 TRUST RELATIONSHIPS
MANAGEMENT
This section explains our trust model and the algo-
rithm that a peer uses to build and to update its Trat
and Trec. The basic rules have already been presented
in (Lenzini et al., 2008). Here, we introduce and study
new rules whose goal is to quantify the quality of a
recommendation in the trust evaluation process. We
also present an implementation based on argumenta-
tion theory (e.g., see (Prakken, 2006)). We introduce
and discuss the concept of argumentation trust, which
we use as a measure of the recommendation strength.
To our best knowledge, the framework we present is
innovative and definitely more dynamic than our pre-
vious solution.
The attention to the justification of a recommenda-
tion comes from the need of distinguishing between a
measure of the reputation of a recommender (in giv-
ing honest recommendations) and the appropriateness
of a specific recommendation in a given context. For
example, even if peer B is renowned to be an expert in
restaurants (fact that she/he has proved many times),
her/his recommendation about going to the Italian
restaurant “La Barcarola” may be discarded by a prin-
cipal A if A and B have different opinions about what a
good Italian menu should be. What is excellent from
B’s view point could be inappropriate for A (which
has, in this particular context, different preferences).
On the other hand, A may accept the recommendation
of another peer D which is less qualified than B but
whose justification about going to the “L’Ostricaro”,
another Italian restaurant, better convinces A. Later,
when A effectively tries this restaurant and likes it, D
also sees its trustworthiness growing from A’s point of
view; D’s recommendation has perfectly satisfied A’s
expectations. It is worth noticing that B’s reputation
remains intact. A has no interest in saying that B is
a bad recommender only because A has not followed
B’s advice. It is not B’s reputation that in in ques-
tion here, but rather the justification that B gave about
her/his recommendation, which didn’t match A’s way
of reasoning from the beginning.
The Register of Rated Items of a member A (writ-
ten Trat(A)) is a set of trust relationships, written as
A
(i,m)
−−→
G;C
σ
b
Here, A is an agent and b is an item. All b’s that
are in Trat(A) have been evaluated by A directly, in-
directly, or both. The value m is a measure of the
functional trust (positive or negative) that A has in b.
The natural number i is a time-stamp from which to
deduce the age of the trust relation. The subscript G
is the set of recommendations and of recommenders
that have been consulted in composing m. The sub-
script C is the context in which the trust relation takes
or has taken place. This parameter makes the trust re-
lationship context-dependent. If b is a restaurant, for
example, one’s evaluation may change depending on
the social context of the user (e.g., with colleagues,
with partner, or with family). The subscript σ stands
for a trust aspect (called trust scope in (Jøsang et al.,
2006)). It represents the purpose of the trust relation.
In Trat(A) there is a multiplicity of trust relationships
between A and b for each aspect among σ
1
, σ
2
, etc.
To simplify our exposition, we consider only one σ
which we omit from our notation. Anyhow, it must
be clear that the overall trust relationship between A
and b depends upon all the trust aspects.
The Register of (Un)Trusted Recommenders of a
member A (called Trec(A)) contains trust relation-
ships written as
A
(i,ω)
==⇒
O
D
Here A and D are both agents. If a member D is in
Trec(A), this means that D’s trustworthiness has been
evaluated by A. The natural number i is a time-stamp,
and the value ω represents an amount of referral trust
that A has in D. Set O carries information about the
items that D has so far recommended to A and the
relative recommendations.
3.1 Trust Evaluation Algorithm
The process of trust evaluation is formalised with an
inference system, which is part of an agent A’s intel-
ligence. Figure 1 and 2 summarise the rules of the
inference system used to build Trat(A) and Trec(A),
respectively. Each trust evaluation rule, in A’s intelli-
gence, has form:
premises
conclusion
A conditions Premises are re-
quired in order to infer the conclusion. The inference
mechanism is processed if conditions (if present) are
fulfilled. The subscript, here a generic agent A, indi-
cates that this rule is applied by A. We will omit the
subscript in the rest of the paper since we present all
rules from A’s point of view.
As a matter of computation, we use two categories
of arrows, namely temporary (or tentative), written
•→ and •⇒ resp., and eventual (or conclusive), writ-
ten → and ⇒ respectively (see Figures 1 and 2). A
temporary trust relation emerges from an incomplete
trust evaluation; additional inputs can still affect the
trust value. An eventual trust relation indicates that
the trust evaluation has ended; no more input can
change the trust value for time i. The registers Trat(A)
and Trec(A) are composed of only eventual trust re-
lationships. In the following, we assume an algebra
SECRYPT 2008 - International Conference on Security and Cryptography
520

Bootstrapping (1)
(a)
[eval
A
({b
i
},C ) = m]
A•
(i,m)
−−−−−−→
{(A
i
,m)};C
b
(c)
[tag
i
A
(b,C ) = m]
A
(i,m)
−−−−−−→
{(A,m)};C
b
(b)
[eval
A
({b
0
i
:b
0
∼b},C ) = m]
A•
(i,m)
−−−−−−→
{(A
i
,m)};C
b
Recommendation (2)
(a)
A
(i,ω)
==⇒
−
D D
(i−1,m)
−−−−−−→
{(D,m)};C
b A
i,ω
0
(−−
−−+
D
A•
(i,ω
00
⊗m)
−−−−−−→
{(D,m)};C
b
i > 0
ω ⊕ ω
0
= ω
00
> ω
0
(b)
A
(i,ω)
==⇒
−
D D
(i−1,m)
−−−−−−→
{(D,m)};C
b
0
A
i,ω
0
(−−
−−+
D
A•
(i,ω
00
⊗(ω
(d(b
0
,b))
⊗ m))
−−−−−−−−−−−−−→
{(D,m)};C
b
b
0
∼ b, b
0
6= b
i > 0
ω ⊕ ω
0
= ω
00
> ω
0
(c)
A
(i,ω)
==⇒
−
D D
(i−1,m)
−−−−−−→
{(D,m)};C
0
b A
i,ω
0
(−−
−−+
D
A•
(i,ω
00
⊗(ω
(d(C
0
,C ))
⊗ m))
−−−−−−−−−−−−−−→
{(D,m)};C
b
C
0
∼ C , C
0
6= C
i > 0
ω ⊕ ω
0
= ω
00
> ω
0
(d)
A
(i,ω)
==⇒
−
D D
(i−1,m)
−−−−→
G;C
b A
i,ω
0
(−−
−−+
D
A•
(i,ω
00
⊗m)
−−−−−−→
{(D,m)};C
b
G 6= {(D,m)}
A 6∈ G
↓1
i > 0
ω ⊕ ω
0
= ω
00
> ω
0
Experience (3)
(a)
A
(k,m)
−−−−−−→
{(A,m)};C
b
A•
(i,ω⊗m)
−−−−−−→
{(A
k
,m)};C
b
ω = ω
i−k
k < i
(b)
A
(k,m)
−−−−−−→
{(A,m)};C
b
0
A•
(i,ω⊗(ω
0
⊗m))
−−−−−−−−−→
{(A
k
,m)};C
b
b
0
∼ b
b 6= b
0
ω
0
= ω
d(b
0
,b)
ω = ω
i−k
k < i
(c)
A
(k,m)
−−−−−−→
{(A,m)};C
0
b
A•
(i,ω
i−k
⊗(ω
d(C
0
,C )
⊗m))
−−−−−−−−−−−−−−→
{(A
k
,m)};C
b
C
0
∼ C
C 6= C
0
k < i
Finalising (4)
(a)
A•
(i,m)
−−−→
G;C
b A•
(i,m
0
)
−−−−→
G
0
;C
b
A•
(i,m⊕m
0
)
−−−−−−→
G∪G
0
;C
b
G
↓1
∩ G
↓1
=
/
0
(b)
A•
(i,m)
−−−→
G;C
b
A
(i,m)
−−−→
G;C
b
Figure 1: Inference rules for the management of agent-item trust relationships. The recommendation rules, whose title is
boxed, and their implementation (in terms of argumentation) form the original contribution of this paper.
(TValues,⊕,⊗,0, 1) of trust values. The binary oper-
ator ⊕ is used to merge trust values, whilst ⊗ to dis-
count trust. Values 0 and 1 are the respective neutral
elements. The literature offers many computational
models that are in principle applicable.
Building and Updating Trat. Referring to Figure 1,
rules (1.a)-(1.b) allow A to apply its own procedure
eval
A
(x,y) (whose concrete implementation is left
unspecified at this level of abstraction) to estimate b’s
trustworthiness. The procedure takes as input the fol-
lowing two parameters: b
i
, which with a little abuse
of notation represents the information available about
b at time i and in context C . In case of lack of infor-
mation about b, a witness b
0
(i.e., b
0
∼ b) can be used
instead of b. The label {(A
i
,m)}; C in the resulting
trust relationship records that the value m has been
calculated at time i and in context C . Rule (1.c) mod-
els the action of rating b which follows a direct expe-
rience. A uses the function tag
i
A
(x,y) to tag b at time
i and in context C . The trust relation that emerges af-
ter a tagging is an eventual relation; there is no need
of other information to evaluate b’s trustworthiness.
Rules (2.a)-(2.d) in Figure 1 describe how we
manage recommendations. These rules extend and
renew the corresponding rules we gave in (Lenzini
et al., 2008), where we allowed an agent A to accept
a recommendation when the recommender’s referral
trust is above a certain threshold and when the justifi-
cation given for the recommendation is accepted by A.
We had there no quantitative evaluation of the justifi-
cation of a recommendation. In Figure 1, instead, the
trustworthiness of D’s recommendation is evaluated
TRUST MODEL FOR HIGH QUALITY RECOMMENDATION
521

Bootstrapping (5)
(a)
[estimate
A
(D
i
) = ω]
A•
(i,ω)
==⇒
/
0
D
(b)
A
(i−1,ω)
====⇒
O
D
A•
(i,ω)
==⇒
O
D
i > 0
Update (6)
(a)
A•
(i,ω)
==⇒
O
D A
(i,m
0
)
−−−−−−−→
{(A
i
;m
0
)};C
b A
(k,m
00
)
−−−−→
G;C
b
A•
(i,inc(ω))
======⇒
O∪{(b,k)}
D
k ≤ i,
(b,k) 6∈ O
({(D,m)} ∈ G)∧
(m
0
∼ m)
(b)
A•
(i,ω)
==⇒
O
D A
(i,m
0
)
−−−−−−−→
{(A
i
;m
0
)};C
b A
(k,m
00
)
−−−−→
G;C
b
A•
(i,dec(ω))
======⇒
O∪{(b,k)}
D
k ≤ i,
(b,k) 6∈ O
({(D,m)} ∈ G)∧
(m
0
6∼ m)
Finalisation (7)
(a)
A•
(i,ω)
==⇒
O
D A•
(i,ω
0
)
===⇒
O
0
D
A•
(i,ω⊕ω
0
)
=====⇒
O∪O
0
D
O∩O
0
=
/
0
(b)
A•
(i,ω)
==⇒
O
D
A
(i,ω)
==⇒
O
D
Figure 2: Inference rules for managing agent-agent trust relationships.
by taking into account both the referral trust (that A
has already in D) and a measure of trust that emerges
from A’s analysis of the arguments that D gives to jus-
tify its recommendation. The relation A
i,ω
(−
−+
D indi-
cates that A’s evaluation of D’s recommendation (after
having discussed about its justification) is ω. We call
this value argumentation trust Section 4 explains how
we estimate argumentation trust. Function ω ⊕ ω
0
re-
flects a merged value between ω (argumentation trust)
and ω
0
(referral trust) in our algebra of trust values.
As a matter of example, it may happen that A accepts
a recommendation from a peer that is not so highly
trustworthy (e.g., a new member) but whose justifi-
cation is strong. Similarly, a recommendation that
comes from a highly trustworthy recommender but
whose justification is unconvincing, can be refused.
The resulting mechanism for (referral) trust evalua-
tion is more flexible. The “strength” of justifications
(given by a recommender) is thus as important as the
reputation of the recommender.
Rules (3.a)-(3-c) show how to use the experience
of A about b, or about some of b’s witnesses (i.e.,
b
0
∼ b), to evaluate b’s temporary trust. Information
related to the same context, or to a compatible con-
text (i.e., C
0
∼ C ), can also be considered. When
witnesses or compatible contexts are used, the past
experience is discounted depending on a measure of
distance between b
0
and b or between C
0
and C , re-
spectively (see also (Toivonen et al., 2006)).
Rule (4.a) describes how the temporary evalua-
tions collected by different sources can be merged.
The condition G
↓1
∩ G
0
↓1
=
/
0 informally says that the
sources must be disjointed to avoid interferences. Fi-
nally, rule (4.b) finalises the trust process. The tempo-
rary trust evaluation becomes eventual. The recom-
menders, as well as their recommendations that have
been used in estimating b’s trustworthiness,are logged
in G. They are used to update Trec(A) (see next para-
graphs).
Building and Updating Trec. Referring to Fig-
ure 2, rule (5.a) initiates Trec(A). D’s profile at time
i is evaluated by A with the function estimate
A
(x).
The value ω is an estimation of D’s referral trustwor-
thiness. Implementations of estimate
A
(x), out of
the scope of this paper, can be based on the amount
of “likelihood” between D and A for example, or on
the number of items that have been similarly ranked
by A and D. Rule (5.b) expresses that trust can be es-
timated by inheritance with a previous trust. Here we
do not model trust decay over time, or in other words
we do not discount a referral trust because of time.
Rule (6.a) and rule (6.b) say that A’s (referral)
trust in an agent D is increased (resp., decreased) for
each compatible (resp. incompatible) recommenda-
tion given by D. A recommendation is compatible
only in comparison with A’s personal experience (i.e.,
tagging). Here, overriding our notation, the symbol ∼
indicates the compatibility relation among opinions.
After A tags b, its trust in b is more based on facts
than on presumptions (according to our notation, this
is recognisable from the subscript {(A
i
,m)}). There-
fore, A is able to review the opinion she/he got via rec-
SECRYPT 2008 - International Conference on Security and Cryptography
522

ommendation and to modify her/his trust in the rec-
ommender accordingly. The comparison is context-
dependent. Rule (7.a) says that the temporary eval-
uations collected when updating the referral trust for
a recommender can be merged (operator ⊕) together.
A recommender might have given opinions on more
than one item and its overall referral trust depends
on the trust update for all of them. The condition
O ∩ O
0
=
/
0 ensures that the same update (per item)
is not considered twice. Finally, rule (7.b) finalises
the trust process. The temporary trust evaluation be-
comes eventual, and it will become part of Trat(A).
The items recommended along the way that con-
tributed to the referral trust are logged.
Implementation of the Model. To apply the rules
for Trat(A) and Trec(A) in an effective trust evalu-
ation algorithm, an order of preference among rules
is needed. Different ordering constraints reflect dif-
ferent attitudes in merging opinions and past expe-
riences. For example, an agent may prefer to first
collect all opinions, then to merge them, and finally
to consider her/his past experience. In rules (3.a)-
(3.c) for example, different constraints over the time
variable k guide the search strategy in the past (e.g.,
choosing a maximal k implies considering the most
recent experience). Discussing these choices is out of
the focus of this paper.
4 ARGUMENTATION TRUST
This section explains how we measure the strength
of a recommendation given a set of arguments. We
first remind the basic concepts of argumentation.In
logic and in artificial intelligence, argumentation is a
way of formalising common-sense reasoning. Cur-
rent implementations use both classical, monotonic,
logic and non-monotonic reasoning. Depending on
the implementation, an argument can be presented
as an inference tree, a deduction sequence, or a pair
(set of premises, conclusion). Most of the argumen-
tation systems can be characterised by five elements,
namely, (i) an underlying logical language, (ii) a con-
cept of argument, (iii) a concept of conflict between
arguments (which involves counter-arguments that at-
tack an original argument), (iv) a notion of defeat
among arguments, and (v) a notion of acceptability
of arguments according to a well-defined criterion.
A counter-argument can attack an original argu-
ment directly, its premises, or the rules that have
been used to prove it. The right definition of attack
depends on the chosen implementation. In (Benta-
har and Meyer, 2007), which uses an implementation
based on classical logic, a counter-argument negates
an original argument or one of its premises. In (Garcia
and Simari, 2002), where a Defeasible Logic (Nute,
1994) implementation is used, counter-arguments are
supported by stronger proofs or stronger knowledge
than those supporting an original argument.
Attached arguments can be defended, for example
by producing a counter-argument against the counter-
argument. This interaction is expressed through and
argumentation protocol, where attacks and defences
interleave until the original argument is accepted, re-
fused, or declared undecided. These three concepts
will be used to quantify the strength of a recommen-
dation (see Definition 1).
The integration we present is general and inde-
pendent from the implementation chosen for the ar-
gumentation system.
Definition 1 (Argumentation Trust) . Let us sup-
pose two agents, A and D, and an argumentation
system Γ. A and D run N argumentation proto-
cols to debate over the arguments that D provides
to justify her/his recommendation. Let N
a
, N
r
, N
u
(N
a
+ N
r
+ N
u
= N) be the number of D’s initial ar-
guments that A accepts, refuses, and neither accepts
nor refuses (i.e., undefined), respectively. Then the ar-
gumentation trust that A has on D is calculated with
the following function:
ω(N) =
N
N
au
+ N
r
+ (
1
N
au
+N
r
+1
)
(8)
where N
au
= N
a
+ N
u
is the number of arguments that
A has either accepted or not refused.
In (8), high trust values are reached with a high
number of not refused arguments. Thus, justifications
made of a large number of arguments can bring to
higher argumentation trust than justifications made of
a small number of arguments (see Figure 3).
Referring back to Figure 1, A
i,ω
(−
−+
D expresses that
A and D have run an argumentation protocol and, as a
result, A’s argumentation trust in D is ω(N) = ω.
5 RUNNING EXAMPLE
In this section we illustrate an example of trust evalu-
ation with argumentation. The argumentation game is
informally described. This means that this example is
not binded to a specific implementation. The instanti-
ation of argumentation into a formal scheme is left as
future work.
Let us assume that a member (Alice) of a slow
food community is looking for information about
TRUST MODEL FOR HIGH QUALITY RECOMMENDATION
523

0 2 4 6 8 10
Number of Arguments
0
0.2
0.4
0.6
0.8
1
Argumentation Trust
Figure 3: Graphic showing the argumentation trust function
when all, all but one, all but two arguments provided by D
are accepted by A, respectively (e.g., N
r
= 0,1,2 from top
to bottom). The more accepted arguments D provides the
higher its argumentation trust can be.
restaurant “La Bella Vita” (in short, b) in Amster-
dam. Alice wants to have a romantic dinner eating
Italian food. Her delegate agent A, which runs in
the Virtual Agora (i.e., the meeting infrastructure for
the slow food community), will collect information
about the trustworthiness of b. In the following, we
assume that the algebra of trust values is the real inter-
val [0,1] with a consensus operator x ⊕ y = (x + y)/2
and a discount operator x ⊗ y = x · y. Trust values in
[0,1] are informally read as follows: [0, 0.3] = distrust,
(0.3,0.5] = weak distrust, (0.5, 0.7] = weak trust, and
(0.7,1.0] = trust.
The goal of A is to evaluate the functional trust
of b at the current time (let us say w
4
). Formally, A
has to infer A
(w
4
,m)
−−−−→
G;C
b, where C is the social context
“romantic dinner”. By consulting its register of rated
items Trat(A), A finds out that: (i) it has never rated
b before, but that (ii) it has evaluated restaurant “La
Bella Vita” in Utrecht (in short, b
0
) which belongs to
the same franchising as b. This rating was registered
when Alice was in Utrecht last week (week w
3
) for
a romantic dinner. The stored rating (functional trust
in b
0
) is 0.8. Formally, this means that A
(w
3
,0.8)
−−−−−−−−→
{(A
w
3
,0.8)};C
b
0
∈ Trat(A).
Because b and b
0
belong to the same franchising
(i.e., b
0
∼ b), A estimates its trust in b by applying rule
(3.b). If we assume that the trust decay is ω
w
4
−w
3
=
1.0 (i.e., one week-old experience is fully significant)
and the discount due to the use of a witness ω
d(b
0
,b)
=
0.94 (i.e., the trust experience with a restaurant of the
same chain is quite significant), then A’s temporary
trust in b is 1.0 · (0.94 · 0.8) = 0.75. Formally:
A
(w
3
,0.8)
−−−−−−−−→
{(A
w
3
,0.8)};C
b
0
A•
(w
4
,0.75)
−−−−−−−−→
{(A
w
3
,0.75)};C
b
b
0
∼ b
ω
w
4
−w
3
= 1.0
ω
d(b
0
,b)
= 0.94
Agent A also looks for recommendation about
b. A finds out that (i) agent D, which is already in
Trec(A) and whose referral trust has been evaluated
0.8, recommends a rating 0.4 for b (i.e., according
to D, b is untrustworthy) (ii) agent E, which does
not belong to Trec(A) recommends a rating 0.8 for b
(i.e., E’s opinion is that b is a trustworthy restaurant).
Both agents mention the context “romantic dinner”.
By considering recommendations (i.e., rule (2.a)), A
can obtain two more instances A•
(w
4
,m)
−−−−→
G;C
b. Later, A
can merge them with the instance obtained by Alice’s
past experience. First, A needs to evaluate its refer-
ral trust in D and E for the current time w
4
. Because
A
w
3
,0.8
===⇒
O
D ∈ Trec(A), A can “refresh” its referral trust
by applying rules (5.b) and (7.b), as follows:
A
(w
3
,0.8)
====⇒
O
D
A•
(w
4
,0.8)
====⇒
O
D
A
(w
4
,0.8)
====⇒
O
D
Concerning E, A estimates its referral trust by ap-
plying rule (5.a) and later (7.b). If we assume that
estimate
A
(E) = 0.7, we have:
[estimate
A
(E) = 0.7]
A•
(w
4
,0.7)
====⇒
/
0
E
A
(w
4
,0.7)
====⇒
/
0
E
Without an analysis of justification, and if we sup-
pose that A only accepts recommendations coming
from members whose referral trust is over the thresh-
old w
0
= 0.69, A would accept both D’s and E’s rec-
ommendations. By discounting and merging the two
recommendations (rules (2.a) and (4.a)), the trust in b
would be (0.8 · 0.4 + 0.7 · 0.8)/2 = 0.44. This result
would be merged, by applying the same rules, with
the trust that A gets from Alice’s past experience. This
would make a final value of (0.75 + 0.44)/2 = 0.6.
Agent A would then finalise the trust evaluation pro-
cess (by rule 4.b). The final conclusion is that b is a
weak trustworthy restaurant. Alice, who prefers trust-
worthy restaurants, would thus decide not to try b.
However, if argumentation is used, the final judge-
ment could be different and more appropriate to Al-
ice’s profile. In this case, A evaluates the argumenta-
tion trust of D by asking for a justification about D’s
SECRYPT 2008 - International Conference on Security and Cryptography
524

low rating of 0.4. Different argumentation dialogues
take place between A and D, each for each aspects
that D has considered when composing its rating in b.
For example, the dialogue concerning the “ambiance”
informally appears like what follows:
A: why did you give 0.4?
(demand a justification)
D: I didn’t like the restaurant
because the restaurant was too quiet
(ground for a justification)
A: Yes, but this is romantic, isn’t it?
(counter-argument, demand a justification)
D: No, because there were too many moments
of silence between me and my partner
(ground for the justification)
A: I see, but this is not important for me
(rebuttal of argument)
Similar dialogues clarify the point of view of A and D
on two other aspects, namely, “quality of food” and
“price”. Let us suppose that only D’s justification
about the “quality of food” is accepted by A. Thus,
according to formula (8), the argumentation trust be-
tween A and D is 1/(3 +
1
4
) = 0.3 and A
w
4
,0.3
(−−−
−−−+
D.
When this value is “added” to the referral trust of D,
0.8, the resulting ω
00
is 0.55 (see rule (2.a)). Conse-
quently, D’s recommendation is not considered in this
tournament because it is below the threshold ω
0
.
On the contrary, after arguing with E, A accepts
all the arguments of E over “ambiance”, “quality of
food” and “price” (we do not show the dialogues
here). Agent A and E have a perfect match of opin-
ions, and the argumentation trust calculated with the
formula (8) is 3/(3 +
1
4
) = 0.9 and A
w
4
,0.9
(−−−
−−−+
E. When
this value is “added” to the referral trust of E, 0.7,
the resulting ω
00
= 0.7 ⊕ 0.9 is 0.8. The recommen-
dation of E is then accepted because it is above the
threshold ω
0
, and the temporary functional trust in b
is (0.9 · 0.8) = 0.72 according to rule (2.a) applied as
follows:
A
(w
4
,0.7)
====⇒
/
0
E E
(w
3
,0.8)
−−−−−→
(E,0.8);C
b A
w
4
,0.9
(−−−−
−−−−+
E
A•
w
4
,0.74
−−−−−→
(E,0.8);C
b
0.7 ⊕ 0.9 > 0.69
Finally, when this last value is merged with the trust
that A gets from Alice’s past experience, the final trust
is (0.75 + 0.72)/2 = 0.74 (rule (4.a)):
A•
(w
4
,0.75)
−−−−−−−−−→
{(A
w
3
,0.75)};C
b A•
(w
4
,0.72)
−−−−−−−−→
{(E,0.72)};C
b
A•
(w
4
,0.74)
−−−−−−−−−−−−−−→
{(A
w
3
,0.75),(E,0.72)};C
b
A
(w
4
,0.74)
−−−−−−−−−−−−−−→
{(A
w
3
,0.75),(E,0.72)};C
b
In this case, A’s suggestion is that b is trustworthy and
Alice will try restaurant b.
After trying restaurant b, Alice rates it 0.9 (rule
(1.c); she liked the romantic ambiance of the restau-
rant. Consequently, agent A raises the referral trust
of E, for example, from 0.7 to 0.75 (see rule (6.a)).
In contrast, D’s referral trust remains unchanged, be-
cause its recommendation has not been considered by
A. D still can suggest nice restaurants later on.
6 AGENT-BASED SYSTEM
ARCHITECTURE
In order to implement the proposed trust model, our
delegate agents need the following capabilities (i)
Reasoning: it should be able to evaluate trust values,
build and update its knowledge (TRat and TRec), and
argue with other peers; (ii) Autonomy: it has to pro-
cess the aforementioned tasks autonomously (without
any manual assistance from its user); and (ii) Context-
awareness: it needs to capture the context of its user,
which is needed to reason about the trust.
To fulfil the aforementioned requirements, we de-
sign the VA as an open multi-agent system (open
MAS) (Barber and Kim, 2002), which represents a
scalable and flexible system that matches our virtual
community concept. Moreover, the two main features
of open MAS members: (i) can freely join and leave
at any time and (ii) are owned by different stake-
holders with different aims and objectives, perfectly
fit the description of our VA’s delegate agents. How-
ever, our architecture is not completely decentralised.
In fact, we use a central component called Bulletin
Board which is in charge of keeping up-to-date the
list of present members (useful for members discov-
ery) and the list of items to be evaluated (see also Fig-
ure 5).
With respect to the internal architecture of del-
egate agents, we adopt a Belief-Desire-Intention
(BDI) (Rao and Georgeff, 1995). The BDI model
offers an interesting framework to design delibera-
tive agents which are able to act and interact au-
tonomously and according to their mental states. The
main components of the delegate agent’s architecture
are illustrated in Figure 4. Rounded rectangles rep-
resent processes while rectangles represent the differ-
ent data. In the “Memory” component, two different
shapes are used to show whether the data is an in-
put (e.g., Profile) or an output (e.g., Answer). In brief,
the “Goal Generator” (corresponding to Desires in the
BDI model) produces goals that the agent has to fol-
low. A goal could be: to answer a user’s (or peer)
request, to update its own TRat and TRec, etc. These
TRUST MODEL FOR HIGH QUALITY RECOMMENDATION
525
goals are also influenced by the “User Profile” (this
includes the user’s context). In order to fulfil these
Desires (or goals), the delegate agent has to formulate
a set of Intentions, which will become actions. These
Intentions are dictated and later executed by the “Rec-
ommender” and the “Argumentation Engine”. As a
result of these actions, the knowledge (here, TRat and
TRec) of the delegate agent is updated, which con-
stitutes the Beliefs of the agent. Based on these new
Beliefs, more Intentions have to be processed (if the
current goal is not yet satisfied) or a new goal is set
(or updated). The same cycle continues as long as
there are goals to be achieved. More details about this
architecture are available in (Sahli et al., 2008).
Goals
Generator
Memory
Communication
Component
User Profile Recommender
Argumentation
Engine
Beliefs
Generator
Beliefs (TVC
graph)
Info
Feedback/info
Info that needs
justification
Argument
Argument
Update
(learned)
Profile update
Initial goal
TVC graph
Ask agent/answer agent/ answer user
Goal
Trust rulesTrust Model
Trust rules
TVC graph
Profile
Inform community about user’s feedback
Request from
user/agent
Memory
Goals
Generator
Recommender
User Profile
Beliefs
(TRec/TRat)
Argumentation
Engine
Beliefs
Generator
TRec/TRat
Trust rules
Trust rules
Trust Model
updates
profile
TRec/TRat
Initial goal
Goals
User
Feedback
Profile
Request
Answer
Argument
Argument
Feedback
Feedback
profile
[if justification
needed]
Other Delegate Agents in
the Virtual Agora
Figure 4: The delegate agent’s BDI architecture.
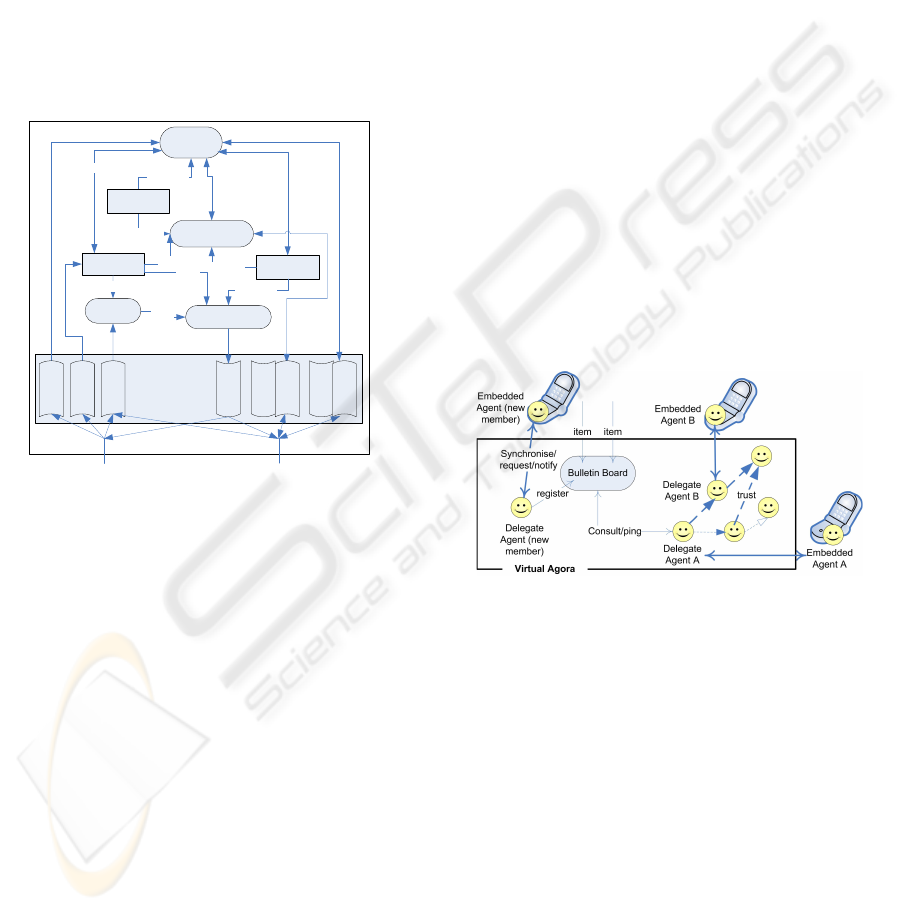
Extension to Mobile Users. We now demonstrate
the easy extensibility of our architecture to support
mobile users. Since delegate agents have to re-
quest/argue about opinions to ensure high-quality rec-
ommendations, they obviously require more interac-
tion. However, when users are mobile, exchanging
these messages between peers (mobile users) would
generate a large and costly wireless communication
traffic. It is thus necessary to avoid remote messages
as much as possible and allow most of communica-
tion to be held locally (peers exchanging messages
should be located at the same server). The VA con-
cept seems to be appropriate to fulfil this requirement
since it constitutes a meeting infrastructure where all
delegate agents can exchange local messages. But
how to make the link with mobile users? To achieve
this goal, we extend our agent-based architecture by
assigning a second agent (in addition to the delegate
agent) to each user (here mobile user). We call this
agent embedded agent. This light (has few data and
functionalities) agent is a proxy between the user and
the delegate agent. It is embedded in the mobile de-
vice of the user. It mainly (i) notifies delegate agent
about the user’s feedback, tags (e.g., ratings), changes
of interests or preferences, etc., and (ii) requests rec-
ommendations on behalf of the user. While delegate
agent is deliberative, embedded agent is more a reac-
tive agent. Indeed, it does not support any reasoning,
it is only making the bridge between the user and the
delegate agent and reacting to incoming events. The
architecture described previously is thus extended as
shown in Figure 5. More details about the internal ar-
chitecture of this agent are presented in (Sahli et al.,
2008).
Implementation. We have already implemented a
prototype of the VA. We chose JADEX as a devel-
opment environment. Besides the fact that JADEX is
built over the reliable environment Jade, it handles the
BDI concept which is very useful in our case to eas-
ily implement the VA’s members. We are currently
working in integrating the automatic capturing of the
user’s context to the architecture. We are also work-
ing on implementing the argumentation mechanism
as described in this paper.
Figure 5: Simplified architecture supporting mobile users.
7 RELATED WORK
Very few papers have addressed the use of argumenta-
tion in their trust models. Stranders (Stranders et al.,
2007) seems to be the first to use a form of argumenta-
tion for trust evaluation viewed as a decision process,
taking inspiration from (Amgoud and Prade, 2004).
Prade proposed a similar approach in (Prade, 2007).
However, in these systems, argumentation is an in-
ternal process (internal to each agent) used to sup-
port decision making. Each agent evaluates its trust
in a peer (or a source) according to a set of argu-
ments. In contrast, in our approach, each agent uses
argumentation as a negotiation mechanism with other
agents in order to debate about the “strength” of a
given item. To our knowledge, only Bentahar and
SECRYPT 2008 - International Conference on Security and Cryptography
526

Meyer (Bentahar and Meyer, 2007) have addressed an
argumentation-based negotiation to enhance the trust
model of agents. Their approach is, by the way, com-
plementary to ours. First the goal is to provide a se-
cure environment for agent negotiation within multi-
agent systems. Second, the overal trust degree of an
agent is estimated according to a probabilistic model
which depends upon the number of past and current
accepted arguments.
Our work is also related to numerous works that
have been addressing distributed trust management in
the last years. Our solution of making trust dependent
of past experience and recommendations is a com-
mon choice in distributed trust management (e.g., see
the surveys (Ruohomaa and Kutvonen, 2005; Jøsang
et al., 2005)).
Our design is also related to recommender sys-
tems and collaborative filter solutions. The abstract
functions we use to initiate trust (i.e., estimate,
eval) and to tag items (i.e., tag) find their concrete
counterpart in the solutions that exist to estimate the
trustworthiness of objects during the bootstrap phase
of trust. Again a pletora of research works is avail-
able in the literature. Quercia et al. propose to
use a user’s local information (on the ratings of its
past experiences) to estimate the trustworthiness of
an item (Quercia et al., 2007b). In (Quercia et al.,
2007a), they also design a distributed algorithm that
users can run to predict their referral trust in content
producers from whom they have never received con-
tent before. Both the solutions are suitable for mobile
devices, which make them attractive in our design.
Argumentation has been proposed to enhance
critic systems and recommender systems (Chesnevar
et al., 2006). Potential suggestions which follow a
user’s web query, are ordered by relevance. The rel-
evance relation is defined in terms of argumentation,
whose rules express the user preferences. Warranted
suggestions come first, then undecided followed by
defeated suggestions. Differently from our approach,
Defeasible Logic is used to express a user’s prefer-
ences, which can be quite naturally expressed as a de-
feasible reasoning. In this case, argumentation is not
a dialogue between two subjects (as in our approach)
but it is the result of attacks/defenses pairs that arise
in the subjective defeasible reasoning of a user when
she/he evaluate a piece of information retrieved from
the web. Argumentation has been also proposed in
agent systems to reason about desires of agents (Rot-
stein et al., 2007). Here, Defeasible Logic is used to
select, among a set of potentially conflicting agent’s
desires, an appropriate one that fits the particular sit-
uation of a given agent.
8 CONCLUSIONS AND FUTURE
WORK
In this paper, we enhance the decentralised recom-
mender system we proposed in (Lenzini et al., 2008)
by integrating argumentation into the trust model.
Within a virtual community of raters, a member can
thus select recommendations not only based on its
trust in these peers, but also on the justifications they
give. We thus make a member take advantage of rec-
ommendations coming from less trustworthy mem-
bers (e.g., those with which she/he has no direct ex-
perience) if they are strongly justified by convincing
arguments. As future work, we intend to propose a
full implementation of the argumentation model. This
implies finding a way to capture the user’s way of rea-
soning (in a user-friendly manner) and integrating the
output in the formal model. An eventual commercial-
isation of our recommender system will thus depend
on linking the formal model with the real data (cap-
tured from the user) via a user-friendly interface.
With respect to the supporting architecture, our
decentralised recommender system is designed based
on the agent paradigm. In fact, we model raters
by autonomous and unobtrusive agents, which frees
users from managing their trust in other members.
Moreover, if users are mobile, we decouple each
agent into two agents (delegate and embedded),
which dramatically reduces wireless traffic between
peers. We are currently working on integrating Con-
textWatcher (Koolwaaij et al., 2006) into our system
in order to effectively support the context. The Con-
textWatcher is a mobile application developed in our
research laboratory, and which aims at making it easy
for an end-user to automatically record, store, and use
context information. It automatically captures some
context aspects such as time, location, and social en-
vironment (of the end-user).
REFERENCES
Amgoud, L. and Prade, H. (2004). Using arguments for
making decisions: a possibilistic logic approach. In
Proc. of the 20th conference on Uncertainty in artifi-
cial intelligence AUAI’04, Banff, Canada, pages 10–
17. AUAI Press.
Barber, K. S. and Kim, J. (2002). Soft security: Isolat-
ing unreliable agents from society. In Proc. of the
5th Workshop on Deception, Fraud and Trust in Agent
Societies, AAMAS 2002, July 15-19, Bologna, Italy,
pages 8–17. ACM.
Bentahar, J. and Meyer, J. J. C. (2007). A new quantita-
tive trust model for negotiating agents using argumen-
tation. Int. Journal of Computer Science & Applica-
tions, 4(2):39–50.
TRUST MODEL FOR HIGH QUALITY RECOMMENDATION
527

Chesnevar, C. I., Maguitman, A. G., and Simari, G. R.
(2006). Argument-based critics and recommenders: a
qualitative perspective on user support systems. Data
Knowl. Eng., 59(2):293–319.
Garcia, A. and Simari, G. R. (2002). Defeasible logic pro-
gramming: An argumentative approach. Theory and
Practice of Logic Programming, 4(1):95–138.
Jøsang, A., Gray, L., and Kinateder, M. (2006). Simplifica-
tion and analysis of transitive trust networks. Web In-
telligence and Agent Systems Journal, 4(2):139–161.
Jøsang, A., Ismail, R., and Boyd, C. (2005). A survey of
trust and reputation systems for online service provi-
sion. Decision Support Systems. (available on line on
ScienceDirect) in press.
Koolwaaij, J., Tarlano, A., Luther, M., Nurmi, P., Mrohs, B.,
Battestini, A., and Vaidya, R. (2006). Contextwatcher
- sharing context information in everyday life. In Proc.
of the IASTED Int. Conf. on Web Technologies, Ap-
plications, and Services (WTAS2006), Calgary, CA,
pages 39–60. ACTA Press.
Lenzini, G., Sahli, N., and Eertink, H. (2008). Agents se-
lecting trustworthy recommenders in mobile virtual
communities. In Proc. of the 11th Int. Workshop on
Trust in Agent Societies (TRUST08), AAMAS 2008,
pages 94–104.
Miller, B., Konstan, J., and Riedl, J. (2004). Toward a per-
sonal recommender system. ACM Transactions on In-
formation Systems, 22(3):437–476.
Nute, D. (1994). Defeasible logic. In Gabbay, D., Hogger,
C. J., and Robinson, J. A., editors, Handbook of Logic
in Artificial Intelligence and Logic Programming, Vol-
ume 3: Nonmonotonic Reasoning and Uncertain Rea-
soning, pages 353–395. Oxford University Press, Ox-
ford.
Prade, H. (2007). A qualitative bipolar argumentative view
of trust. In Prade, H. and Subrahmanian, V. S., editors,
Proc. of the Int. Conf. on Scalable Uncertainty Man-
agement (SUM), Washington, 10-12 Oct 2007, DC,
USA, volume 4472 of LNAI, pages 268–276. Springer-
Verlag.
Prakken, H. (2006). Formal systems for persuasion dia-
logue. Knowledge Engineering Review, 21(2):163–
188.
Preece, J. (2000). Online Communities: Designing Usabil-
ity, Supporting Sociability. John Wiley and Sons.
Quercia, D., Hailes, S., and Capra, L. (2007a). Lightweight
distributed trust propagation. In Proc. of the 7
th
IEEE
International Conference on Data Mining, 28-31 Oct
2007, Omaha, NE, USA, pages 282–291. IEEE Com-
puter Society.
Quercia, D., Hailes, S., and Capra, L. (2007b). TRULLO
- local trust bootstrapping for ubiquitous devices. In
Proc. of the 4
th
IEEE International Conference on
Mobile and Ubiquitous Systems: Computing, Net-
working and Services (Mobiquitous), Philadelphia,
US.
Rao, A. S. and Georgeff, M. (1995). Bdi agents : from
theory to practice. In Proc. of the 1st Int. Conference
on Multi-Agent Systems (ICMAS95), June 12-14, San
Francisco, USA, pages 312–319. AAAI Press.
Rotstein, N. D., Garc
´
ıa, A. J., and Simari, G. (2007). Rea-
soning from desires to intentions, a dialectical frame-
work. In Proc. of the 22nd. AAAI Conference on Ar-
tificial Intelligence (AAAI 2007), Vancouver, Canada,
22-26 July 2007, pages 136–141. AAAI Press.
Ruohomaa, S. and Kutvonen, L. (2005). Trust manage-
ment survey. In Proc. of the iTrust 3rd Int. Conference
on Trust Management, 23-26, May, 2005, Rocquen-
court, France, volume 3477 of LNCS, pages 77–92.
Springer-Verlag.
Sabater, J. and Sierra, C. (2002). Social regret, a reputation
model based on social relations. SIGecom Exchanges,
3(1):44–56.
Sahli, N., Lenzini, G., and Eertink, H. (2008). Trustwor-
thy agent-based recommender system in a mobile p2p
environment. In Proc. of the 7th Int. Workshop on
Agents and Peer-to-Peer Computing (AP2PC08), AA-
MAS 2008, pages 1–11.
Stranders, R., de Weerdt, M., and Witteveen, C. (2007).
Fuzzy argumentation for trust. In Sadri, F. and Satoh,
K., editors, Proc. of the 8th Work. on Computational
Logic in Multi-Agent Systems (CLIMA VIII), 10-11
Sep 2007, Porto, Portugal, LNAI. Springer-Verlag.
(in press).
Teacy, W., Patel, J., Jennings, N., and Luck, M. (2005).
Coping with inaccurate reputation sources: Experi-
mental analysis of a probabilistic trust model. In Proc.
of the 4th Int. Joint Conf. AAMAS, pages 997–1004.
Toivonen, S., Lenzini, G., and Uusitalo, I. (2006). Context-
aware trustworthiness evaluation with indirect knowl-
edge. In Proc. of the 2nd Semantics Web Policy Work-
shop (SWPW 2006), CEUR Workshop Proceedings.
CEUR-WS.org.
SECRYPT 2008 - International Conference on Security and Cryptography
528
