
K-MEANS
BASED APPROACH
FOR OLAP DIMENSION UPDATES
Fadila Bentayeb
ERIC, University of Lyon Lumi
`
ere Lyon2, 5 avenue Pierre Mend
`
es-France
69676 Bron Cedex, France
Keywords:
OLAP, data warehouse, schema evolution, clustering, k-means, analysis level, dimension hierarchy.
Abstract:
Actual data warehouses models usually consider OLAP dimensions as static entities. However, in practice,
structural changes of dimensions schema are often necessary to adapt the multidimensional database to chang-
ing requirements. This paper presents a new structural update operator for OLAP dimensions, named Rollup-
WithKmeans based on k-means clustering method. This operator allows to create a new level to which, a
pre-existent level in an OLAP dimension hierarchy rolls up. To define the domain of the new level and the
aggregation function from an existing level to the new level, our operator classifies all instances of an existing
level into k clusters with the k-means clustering algorithm. To choose features for k-means clustering, we pro-
pose two solutions. The first solution uses descriptors of the pre-existent level in its dimension table while the
second one proposes to describe the new level by measures attributes in the fact table. Moreover, we carried
out some experimentations within Oracle 10 g DBMS which validated the relevance of our approach.
1 INTRODUCTION
A data warehouse is a consolidated view of enter-
prise data, used to analyze facts on various dimen-
sions. The granularity levels of each dimension are
fixed during the design of the data warehouse system.
After deployment, these dimensions remain static be-
cause schema evolution is poorly supported in cur-
rent OLAP (On-Line Analytical Processing) models.
Thus, some new requirements are not satisfied and
some trends are not explored.
To consider this problem, two categories of re-
search emerged. There are works which propose a
temporal multidimensional data model (Vaisman and
Mendelzon, 2000; Bliujute et al., 1998; Morzy and
Wrembel, ; Morzy and Wrembel, 2004). These works
manage and keep the evolutions history by times-
tamping relations over levels (Vaisman and Mendel-
zon, 2000), data warehouse versions (Morzy and
Wrembel, ) or data themselves (Bliujute et al., 1998).
Other works propose to extend the multidimensional
algebra with a set of schema evolution operators
(Blaschka et al., 1999; Hurtado et al., 1999; Pourab-
bas and Rafanelli, 1999).
In this paper, we propose a schema evolution operator
allowing relevant structural updates on dimension hi-
erarchies, named RollupWithKmeans. Given a hierar-
chical level l
n
, our operator RollupWithKmeans clas-
sifies its instances by using k-means clustering algo-
rithm. A new hierarchical level l
new
is then created by
applying a rollup function which relates the instances
of level l
n
with the instances of level l
new
(the domain
of the new level is composed of k instances represent-
ing the k obtained clusters). The choice of k-means
method is justified by its low algorithmic complexity
(linear) and by the format of its results (a partition).
With regard to the feature selection, we propose two
heuristics. The first heuristic uses directly attributes
that describe the level l
n
to be classified while the sec-
ond heuristic uses measures attributes on the fact table
aggregated over the level l
n
. By using the first heuris-
tic, RollupWithKmeans gives the natural classification
of a dimension level while the second heuristic shows
facts trends compared to a dimension level. To val-
idate our approach and show its relevance, we per-
formed experimentations within Oracle 10 g DBMS
(DataBase Management System). The remainder of
this paper is organized as follows. Section 2 presents
related work about schema evolution on data ware-
houses. Section 3 details our k-means-based approach
for schema evolution in data warehouses. Section 4
presents the experimentations we performed to vali-
date our approach. Section 5 concludes our paper and
presents some perspectives.
531
Bentayeb F. (2008).
K-MEANS BASED APPROACH FOR OLAP DIMENSION UPDATES.
In Proceedings of the Tenth International Conference on Enterprise Information Systems - DISI, pages 531-534
DOI: 10.5220/0001717905310534
Copyright
c
SciTePress
2 RELATED WORK
In the context of data warehouses evolution, two cat-
egories of research emerged: the first one recom-
mends extending the multidimensional algebra with
a set of schema evolution operators while the second
proposes temporal multidimensional data models.
Schema Evolution Operators. Hurtado et al.
proposed a formal model of dimension updates in a
multidimensional model, covering updates to the do-
mains of the dimensions and structural updates to the
dimension hierarchies with a collection of primitive
operators to perform these updates (Hurtado et al., ;
Hurtado et al., 1999). For example, they propose the
generalize operator which creates a new level l
new
, to
which a pre-existent one, l
n
, rolls up. Blaschka et al.
improves works of Hurtado et al. by proposing a set
of operators independent of every logical and physical
model of the data warehouse (Blaschka et al., 1999).
Temporal Multidimensional Models. In tempo-
ral multidimensional database, the idea is to keep evo-
lution history by using timestamps. Thus, Vaisman et
al. proposed the TOLAP (Temporal OLAP) (Vaisman
and Mendelzon, 2000). In TOLAP, a dimension is de-
signed with a DAG (directed acyclic graph) where a
node represents a level and an edge represents a re-
lation between two adjacent levels. In the TOLAP
graph, edges are stamped with a time interval repre-
senting the validity period of the aggregation link. A
similar approach is proposed by Bliujute et al. with
the “Temporal Star Schema” (Bliujute et al., 1998).
Morzy et al. proposed a multiversion data warehouse
(Morzy and Wrembel, ; Morzy and Wrembel, 2004).
With this versioning approach, a new version of the
data warehouse is physically created when changes
occur. These timestamps are then used to identify
the good versions which will satisfy each analysis re-
quest.
3 K-MEANS BASED APPROACH
FOR DIMENSION UPDATES
3.1 K-means
K-means is known as a partitional clustering method
that allows to classify a given data set X through
k clusters fixed a priori (Forgy, 1965; Bradley and
Fayyad, 1998; Likas et al., 2003). The main idea is
to define k centroids, one for each cluster, and then
assign each point to one of the k clusters so as to min-
imize a measure of dispersion within the clusters.
Among existing clustering methods, we chose k-
means for its low and linear algorithmic complexity
and for its result format (a partition). Indeed, we think
that these two characteristics are important for OLAP
analysis and dimension updates in data warehouses.
3.2 Illustrative Example
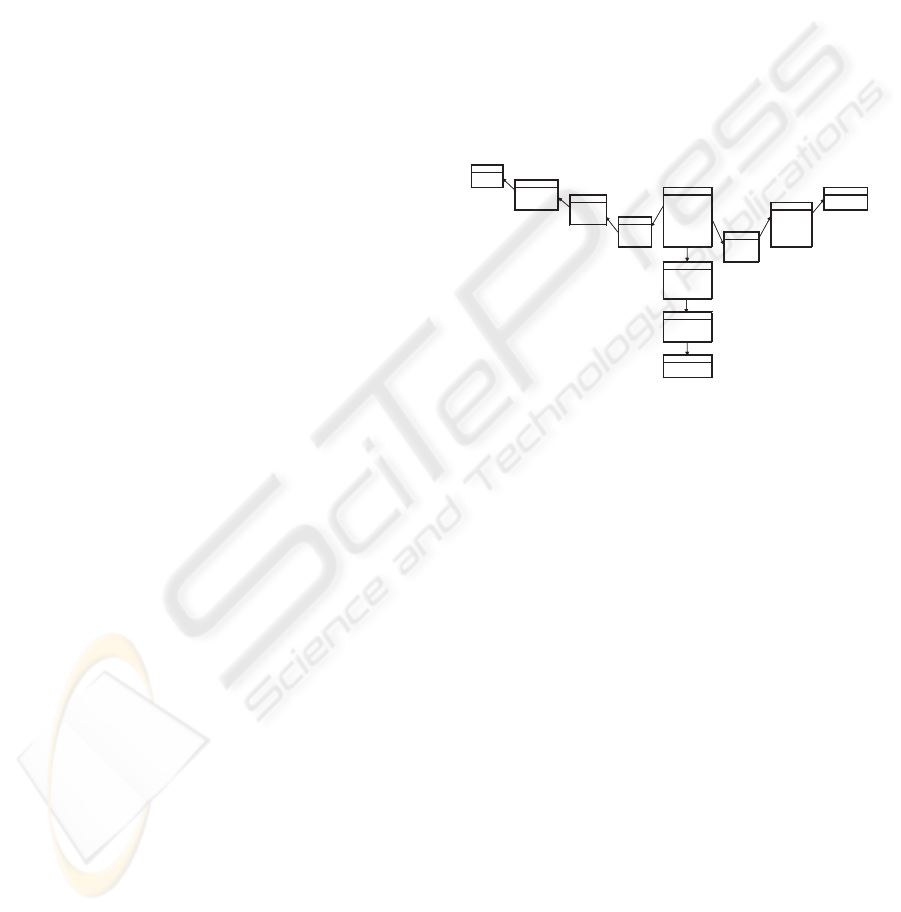
Let us consider a sales data warehouse (figure 1).
This data warehouse contains two measures: sales
income and sold quantity. These measures can be
studied on three dimensions: “Time”, “Product” and
“Region”. The hierarchy of the Region dimension has
three levels: store, city and country. In the same way,
the Product dimension consists of three levels: prod-
uct, product category and product family. In addi-
tion, Time dimension is organized following four lev-
els: week, month, quarter and year.
YEAR
PK_YEAR
YEAR QUARTER
PK_QUARTER
SALES COUNTRY
QUARTER MONTH PK_SALES
PK_COUNTRY
YEAR
PK_MONTH
WEEK CITY COUNTRY
MONTH PRODUCT
PK_CITY
QUARTER
WEEK STORE
CITY
PK_WEEK
COUNTRY
WEEK SALESINCOME STORE AREA
MONTH
SOLDQUANTITY
PK_STORE
POPULATION
STORE
CITY
PRODUCT
PK_PRODUCT
PRODUCT
CATEGORY
PRICE
CATEGORY
PK_CATEGORY
CATEGORY
FAMILY
FAMILY
PK_FAMILY
FAMILY
Figure 1: Schema of the sales data warehouse.
3.3 Principle of Our Approach
In our approach, we are distinguished from the ex-
isting ones by the use of data mining techniques to
perform data warehouse schema evolution. Gener-
ally, to carry out OLAP analyses, the user generates
a data cube by selecting dimension level(s) and mea-
sure(s) which will satisfy its needs. Then, the user
explores the obtained cube to detect similarities in
facts and dimension instances. For that, he exploits
the different levels within a dimension. To help him
in this step, we propose a schema evolution operator
RollupWithKmeans allowing to create a new hierar-
chy level by using a clustering algorithm. Our idea
is to add a new level, l
new
, to which a pre-existent
one, l
n
, rolls up. To achieve our objective, our oper-
ator classifies initially the instances of the level l
n
by
using the k-means clustering algorithm. The opera-
tor RollupWithKmeans creates then the new level l
new
composed of the k instances corresponding to the k
obtained clusters. Finally, RollupWithKmeans defines
a rollup function between level l
n
and level l
new
by
relating the instances of the levels l
n
and l
new
accord-
ing to the k-means clustering result. The originality
of our schema evolution approach is that our rollup
ICEIS 2008 - International Conference on Enterprise Information Systems
532
function f
l
new
l
n
is generated automatically by using k-
means clustering method.
3.4 Feature Selection
To choose features on which k-means will classify the
instances set of the level l
n
, we consider two strategies
to explore a data cube efficiently.
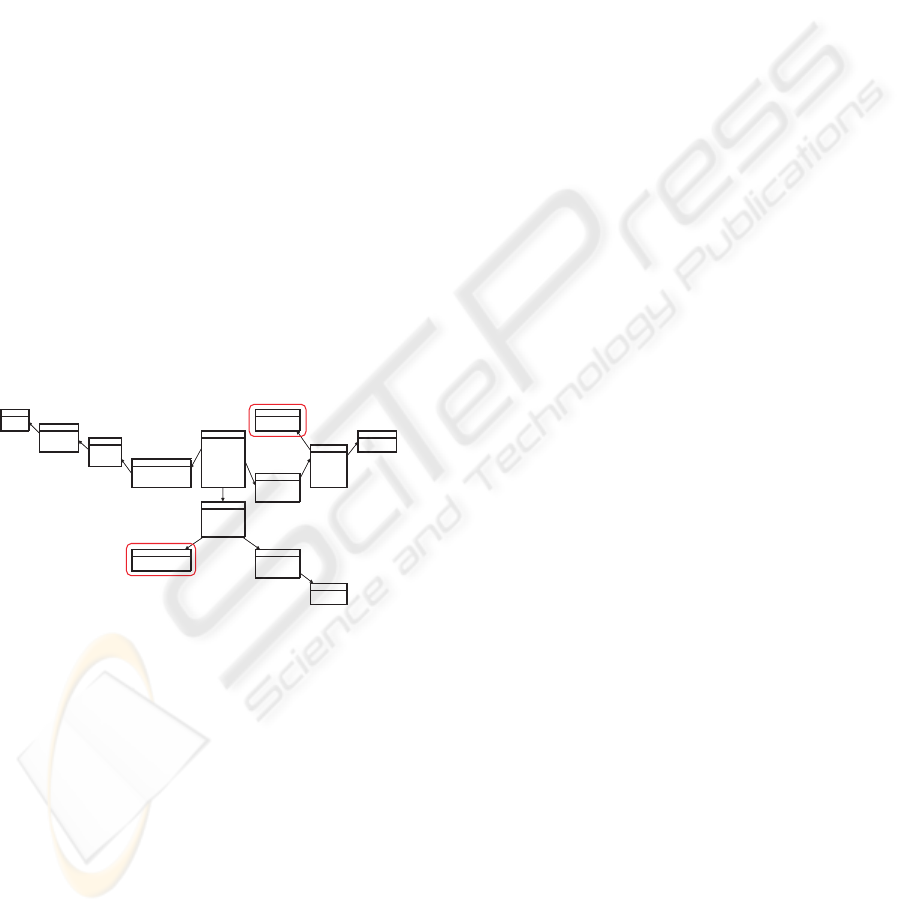
1. Dimension attributes features. For example, to an-
swer the question “Is it necessary to close shops
which make few sales?”, we study the sales in-
comes through the Region dimension. To improve
analyses, we may feel the need to aggregate cities
according to their size. Hence, we create a new
level which groups the instances of the city level
in small, average or big city (figure 2).
2. Measures attributes features. Assume that the
analysis objective of the user is to find a prod-
uct grouping according to the sales. We sum-
marize then sales income and sold quantity mea-
sures on the product level of the Product dimen-
sion and perform the k-means onto the obtained
aggregates. The new level is then created (figure
2).
YEAR CITY GROUP
PK_YEAR PK_CITYGROUP
YEAR QUARTER DESCRIPTION
PK_QUARTER
SALES COUNTRY
QUARTER MONTH PK_SALES
PK_COUNTRY
YEAR
PK_MONTH
WEEK CITY COUNTRY
MONTH PRODUCT
PK_CITY
QUARTER
WEEK STORE
CITY
PK_WEEK
COUNTRY
WEEK SALESINCOME STORE AREA
MONTH
SOLDQUANTITY
PK_STORE
POPULATION
STORE
CITY
PRODUCT
PK_PRODUCT
PRODUCT
CATEGORY
PRICE
PRODUCT GROUP CATEGORY
PK_PRODUCTGROUP PK_CATEGORY
DESCRIPTION CATEGORY
FAMILY
FAMILY
PK_FAMILY
FAMILY
Figure 2: Sales data warehouse with additional “Product
Group” and “City Group” levels.
3.5 Algorithm
Inputs: A dimension D = (L,¹), a level l
n
∈ L, a
level l
new
/∈ L, a positive integer k ≥ 2 representing the
modality number of l
new
, and a variable dataSource
that can take two values: F (for fact) or D (for dimen-
sion).
Step 1: Generating a learning set X
l
n
from the in-
stances of the pre-existent analysis level l
n
. If the
value of the dataSource variable equals to D, the pop-
ulation X
l
n
is described directly by the attributes of the
dimension D. Otherwise, X
l
n
is generated by execut-
ing the operation CUBE(F, l).
Step 2: Clustering. During this step, the algorithm
applies the k-means clustering method on the learning
set X
l
n
.
Step 3: Creation of the new level. This step material-
izes the new hierarchy level l
new
in the data warehouse
schema by using the rollup function f
l
new
l
n
generated
during the previous step.
4 IMPLEMENTATION AND
EXPERIMENTATIONS
We implemented the k-prototypes algorithm by us-
ing PL/SQL stored procedures inside the Oracle 10g
DBMS. K-prototypes is a variant of the k-means
method allowing large datasets clustering with mixed
numeric and categorical values (Huang, 1997). In
our implementation, datasets are stored within a re-
lational table. After clustering process, schema evo-
lution is then performed by using SQL operators: the
new level is created with the CREATE TABLE com-
mand and the rollup function is established with a
primary key/foreign key association between the new
and the existing levels.
We carried out some experimentations under the
emode data warehouse. Emode is an e-trade data
warehouse which is used as demonstration database
for the tool “BusinessObject 5.1.6”. We standardized
the schema of this data warehouse to obtain the di-
agram of figure 2. Thus, the sales fact table stores
89200 records and the product level of the Product
dimension contains 213 instances. According to our
two heuristics of “feature selection”, we defined two
scenarii:
1. Creation of a product price grouping level which
classifies the 213 articles according to their price
into 3 clusters. Hence, we can analyze the influ-
ence of the prices on sales (Figure 4).
2. Creation of another level product sales grouping
which gathers the products according to sales into
4 clusters. Hence, we can analyze the sales trend
according to sales information (Figure 5).
The figure 3 shows the results of the two scenarii.
K-MEANS BASED APPROACH FOR OLAP DIMENSION UPDATES
533

“Product” level
Product
Price Sales
C1
C2
Average priceRangeClass
Scenario1: “price range” analysis level
Scenario2: “products according to the sales” analysis level
RangeDescriptionClass
products
products
products
product
Figure 3: Results of the two scenarii.
price range
price range
s
a
l
e
s
s
a
l
e
s
year
Quantity sold per price category and year
Quantity sold per price category
Figure 4: Sales trend according to the “product price group-
ing” level.
Trends by group of articles and by yearTrends by group of articles
Figure 5: Sales trend according to the “product sales group-
ing” level.
5 CONCLUSIONS
In this paper, we proposed an original approach which
consists in using data mining techniques as aggrega-
tion operators to update dimension hierarchies in data
warehouses. Indeed, in certain cases, one can need to
define other semantic aggregates than those defined
in the design step of the data warehouse. We defined
then a new structural update operator, named Rollup-
WithKmeans for OLAP dimensions based on both the
k-means clustering method and the hierarchical rela-
tionship which links a child member to a parent mem-
ber in a dimension hierarchy. Our operator Rollup-
WithKmeans applied the k-means method to extract
semantic relations from either dimension descriptors
or measures to enrich hierarchies by creating new ag-
gregation levels. Decision makers will thus be able to
achieve their information needs for analyses. To vali-
date our approach, we carried out some experimenta-
tions which showed the relevance of our approach.
To generalize our approach, we plan to use the Ag-
glomerative Hierarchical Clustering (AHC) method
to create not only a new hierarchy level but a complete
dimension hierarchy. Indeed, AHC method creates a
hierarchy of partitions under the form of a tree which
coincides with the format of the dimension hierarchy
in data warehouses models.
REFERENCES
Blaschka, M., Sapia, C., and H
¨
ofling, G. (1999). On schema
evolution in multidimensional databases. In DaWaK
1999, pages 153–164.
Bliujute, R., Saltennis, S., Slivinskas, G., and Jensen, C.
(1998). Systematic change management in dimen-
sional data warehousing. Technical report, University
of Arizona.
Bradley, P. and Fayyad, U. (1998). Refining initial points
for k-means clustering. In ICML, pages 91–99.
Forgy, E. (1965). Cluster analysis of multivariate data: effi-
ciency versus interpretability of classification. In Bio-
metrics num 21, pages 768–780.
Huang, Z. (1997). Clustering large data sets with mixed
numeric and categorical values. In First Pacific-Asia
Conference on Knowledge Discovery and Data Min-
ing.
Hurtado, C., Mendelzon, A., and Vaisman, A. Maintaining
data cubes under dimension updates.
Hurtado, C., Mendelzon, A., and Vaisman, A. (1999). Up-
dating olap dimensions. In DOLAP 1999, pages 60–
66.
Likas, A., Vlassis, N., and Verbeek, J. (2003). The global k-
means clustering algorithm. Pattern Recognition Let-
ters 36(2)
, pages 451–461.
Morzy, T. and Wrembel, R. Modeling a multiversion data
warehouse: A formal approach.
Morzy, T. and Wrembel, R. (2004). On querying versions of
multiversion data warehouse. In DOLAP 2004, pages
92–101.
Pourabbas, E. and Rafanelli, M. (1999). Characterization of
hierarchies and some operators in olap environment.
In DOLAP 1999, pages 54–59.
Vaisman, A. and Mendelzon, A. (2000). Temporal queries
in olap. In VLDB 2000.
ICEIS 2008 - International Conference on Enterprise Information Systems
534
